双感知门控交互的多任务推荐模型
2023-06-07陈育康
林 建,吴 云,陈育康
贵州大学 计算机科学与技术学院,贵阳550025
+通信作者E-mail:wuyun_v@126.com
多任务学习(multi-task learning,MTL)[1]已成功地应用于许多推荐应用场景中。例如,在微视频的多任务推荐中,需要同时优化微视频的点赞、转发、关注和读评论等多目标任务。然而,像微视频这种的多任务推荐问题中,多任务之间复杂的相关性,使模型难以同时学习到每个任务的最优。在之前大多数的工作中,如多门混合专家(multi-gate mixture of experts,MMOE)[2]在硬参数[3]的基础上考虑使用门控来学习不同任务的参数,一定程度上解决了任务之间的冲突。MTL 模型往往会出现性能负迁移的问题。在PLE(progressive layered extraction)[4]中指出,一个任务的性能通常会通过降低其他一些任务的性能而得到提高,PLE将学习参数分离成共享和专有的方式,通过参数共享和专有参数学习到多任务中的共性和差异性。尽管这些经典的模型在多任务的表现中取得了较好的结果,然而过去的工作中没有探索底层特征学习的方式,另外多任务之间的参数经过门控网络后每个任务的参数是独立的,没有考虑到任务之间的学习参数可以互补。为了进一步有效解决多任务负迁移的问题,本文提出了一种双感知门控交互的多任务推荐模型(multi-task recommendation model of dual perception gated interaction,DPGIMTRM)。DPGI-MTRM模型具有多个任务共享的组件和任务特定的组件,主要包括双感知专家层、门控层、交互层、输出层。双感知专家层对输入特征学习不同层级的表示,从元素级和向量级的双感知方面提取更丰富的特征隐含表示。同时通过门控层来选择不同任务学习到的共享参数和特定任务参数。然后任务门控的输出经过交互层之后,提取多任务之间复杂的相关性。另外,在多任务优化中一个重要的问题就是多目标损失函数的优化。传统的解决方法采用手动设置不同任务的权重,这种靠经验去调节的参数不具有泛化性,难以解决不同的多任务的优化问题。本文使用梯度归一化的多目标函数优化方法,将不同任务类型、不同尺度的损失统一,使多个目标的优化较一致地收敛。
本文主要的贡献如下:(1)针对输入特征学习的方式,设计了双感知专家层提取更丰富的特征表达;(2)创造性地在特定任务门控网络的基础上设计了交互层,使特定任务得到更深层次的语义信息,利用多任务之间复杂的相关性来学习参数;(3)使用一种梯度归一化的多目标优化方法,将多个目标损失统一到同一尺度,使多个目标的优化较一致地收敛。
1 相关工作
近年来,深度神经网络(deep neural network,DNN)[5-7]模型已经成功地应用于许多现实大规模应用中,然而这些模型只能建立单个目标任务,面对多任务问题时需要建立多个模型。如推荐系统[8-9],这种推荐系统通常需要同时优化多个目标,往往只能对多个目标单独建立模型。例如,当向用户推荐观看微视频时,可能希望用户不仅浏览点击后点赞、关注,还希望用户浏览点击其他微视频,甚至对微视频进行读评论和转发。在同一个样本空间中,传统的方法创建了多个模型预测多个任务。这在大规模的推荐场景中是一项巨大的工作,在实际生产部署中也是耗费大量成本的。事实上,许多大规模的推荐系统已经采用了DNN模型的多任务学习。
推荐系统(recommender systems,RS)[10]需要结合各种用户反馈,以建模用户的兴趣,并最大限度地提高用户的参与度和满意度。然而,由于问题的高维性,用户满意度通常很难通过学习算法直接解决。同时,用户满意度和参与度有许多可以直接学习的主要因素,例如在微视频中,点击、完成、分享、点赞和评论等的可能性。因此,在RS中应用MTL来同时建模用户满意度或参与的多个方面的趋势越来越大。实际上,MTL已经是主要行业应用程序[11-13]的主流方法。文献[11-12]中的工作都使用了矩阵分解与序列学习相结合的联合训练方式构建点击率预测的多任务推荐模型,文献[13]采用MMOE 模型思想应用在视频的多任务推荐中。
硬参数共享[3],如图1(a)是最基本和最常用的MTL 结构,但任务之间直接共享参数,由于任务冲突,可能会发生负转移。为了处理任务冲突,交叉缝合网络[14]及闸网[2]两者都提出学习线性组合的权重,以有选择性地融合来自不同任务的表示。图1(b)针对不同的任务定义了特定任务的学习参数,同时保留共享的参数,但依然存在任务冲突的问题。图1(c)MMOE针对每个特定任务增加了一个门控网络,特定任务的门控对专家系统[15]进行选择,一定程度上解决了任务冲突,但模型的底层参数都是共享的,学习不到多任务的差异性,往往存在负迁移的问题。图1(d)的PLE 模型采用具有门结构的渐进路由机制,基于输入融合知识,实现了不同输入的自适应组合,然而PLE 模型忽略了任务之间带来的影响。尽管这些模型在解决推荐中的多任务问题提供了范式,但依然存在一些问题。首先,在底层参数学习时只得到单一的特征表达。另外,这些模型在多任务的复杂相关性上没有进行建模。本文提出了双感知专家层对特征提取得到两个层级的特征表达,同时设计门控交互层使得模型学习到多任务之间复杂的相关性。

图1 经典多任务学习模型的网络结构Fig. 1 Network structure of classic multi-task learning model
在共享参数和分离参数的模型结构中,每个任务的收敛程度不一致,使用简单的各个任务的损失总和作为优化目标不能提升多个任务的准确度。文献[16]提出了一种有原则的方法,结合多个损失函数,以同时学习多个目标使用同方差不确定性,将同方差不确定性解释为任务相关的权重,推导出一个有原则的多任务损失函数,该函数可以学习平衡各种回归和分类损失。文献[17]引入了一种随机多梯度下降方法来解决这个问题,通过梯度归一化,可以将不同尺度的目标组合成一个单一连贯的框架。
2 本文方法
2.1 问题定义
为了便于后续形式化描述,在此给出了一些会用到的符号。本文用X表示输入的特征向量,用Ek和Es分别表示任务专家系统和共享专家系统的输出,用表示多任务交互的输出,任务门控输出和共享专家门控输出分别用Gk和Gs表示,任务塔网络的输出用tk表示。本文的目标是构建一个多任务预测模型,yk表示每个特定任务的输出表示。
2.2 模型描述
多任务问题中受不同任务间的相关性的影响,多任务模型的效果往往不如对任务单独建立模型的效果好。现有的方法虽然将多任务的参数分离为共享参数和专有参数一定程度上解决了任务冲突和负迁移的问题,但是模型并没有考虑任务之间复杂的相关性,忽略了任务之间的联系。另外,对多任务模型中的门控输出没有考虑来自底层特征的输入影响。基于以上不足之处,本文提出了DPGI-MTRM模型。该模型考虑了底层输入特征对多任务的影响,在底层参数的学习中设计了双感知专家层(dual perception expert layer,DPE-Layer),从元素级和向量级对特征进行提取。同时,在门控网络的基础上,创新性地提出了门控交互层(gating interaction layer,GILayer),交互层将多个任务的门控输出进行元素相乘得到任务之间的交互相关值。另外,为了减少其他任务带来的冲突,通过残差的方式加上当前特定任务输出的值,最终得到特定任务的输出表示。在模型训练时,采用了梯度归一化多目标优化的方法对模型的参数进行优化,能够将不同尺度的梯度值归一化到统一尺度,减小了多目标中损失值差异较大带来的模型收敛问题。
DPGI-MTRM 模型结构如图2 所示,模型由DPGI 模块和Outputs 输出层构成,其中DPGI 模块包含双感知专家层(DPE-Layer)和门控交互层(GILayer),输出层对应不同任务的多层感知机输出预测模型。

图2 DPGI-MTRM模型Fig. 2 DPGI-MTRM model
2.3 双感知专家层
经典的多任务模型的底层参数包含共享参数和专有参数,门控模块利用这种专有和共享的参数来学习特定任务的输出,直接利用这种专家模块输出会导致底层参数对任务的噪音干扰。多任务之间的不确定性关系往往很难捕获,模型学习不到有益的参数就会带来负面的影响。IFMs(input-aware factorization machine for sparse prediction)[18]中指出特征的多层级表达可以提升推荐性能,根据不同的输入实例自适应地学习给定特征的灵活表示,将不同层级的输入因素重加权原始特征表示。多层级的特征表达从多方面学习特征的隐含表示,比单一的特征表达语义更加丰富。为了更好地使用共享参数和专有参数,在专家模块学习参数时,受IFMs工作的启发设计了双感知专家层。双感知专家层主要的作用是从特征的元素级和向量级两个层面得到多层级表达(多层级是元素级和向量级的统称),得到同一特征的不同表达形式。首先在特征向量级方面,根据Google 2017 年提出的注意力机制[19],特征向量计算过程如图3中Vector Wise Part所示,特征向量输出的自注意力值形式化定义如式(1)所示:
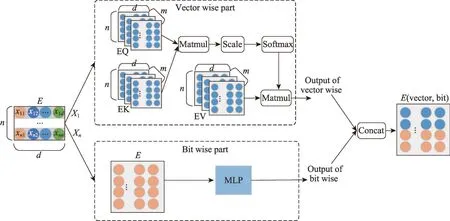
图3 双感知专家层Fig. 3 Dual perception expert layer
在特征元素级方面,利用多层感知机(multilayer perceptron,MLP)对元素级的特征进行提取,如图3中Bit Wise Part所示,元素级的特征输出如式(2)所示:
其中,δ(·)是非线性激活函数;是任务k可训练的权重矩阵,输出维度为d;bk是偏置参数。
利用多层感知机作为元素级特征的提取模型,可以得到更加复杂的特征表达形式,提升了模型的学习能力。
最后,将向量级的输出特征与元素级输出特征进行拼接作为下一步的输入。双感知专家层通过对特征多级别的提取之后,得到更丰富的特征表达,从而提升多任务差异性和共性的参数优化学习,减少负迁移问题。
2.4 门控交互层
在多任务模型中,大多数先进的模型都在结构上有特定任务的参数和多个任务共享的参数两部分。同时,对于各个任务的输出之前增加了一个门控网络,选择不同的专家模块来学习参数,如图4(a)所示。本文考虑了不同任务之间具有复杂的相关性,除了通过特定任务的双感知专家层学习特征差异性之外,同时利用任务之间不确定性的关系提升任务的性能。在通过门控网络学习任务特征的深层次的语义之后,将特定任务的门控输出与其他任务的门控输出经过交互层来捕获任务之间的相关性。多任务交互层结构图如图4(b)所示。多任务交互的输出形式化定义如式(3)所示:
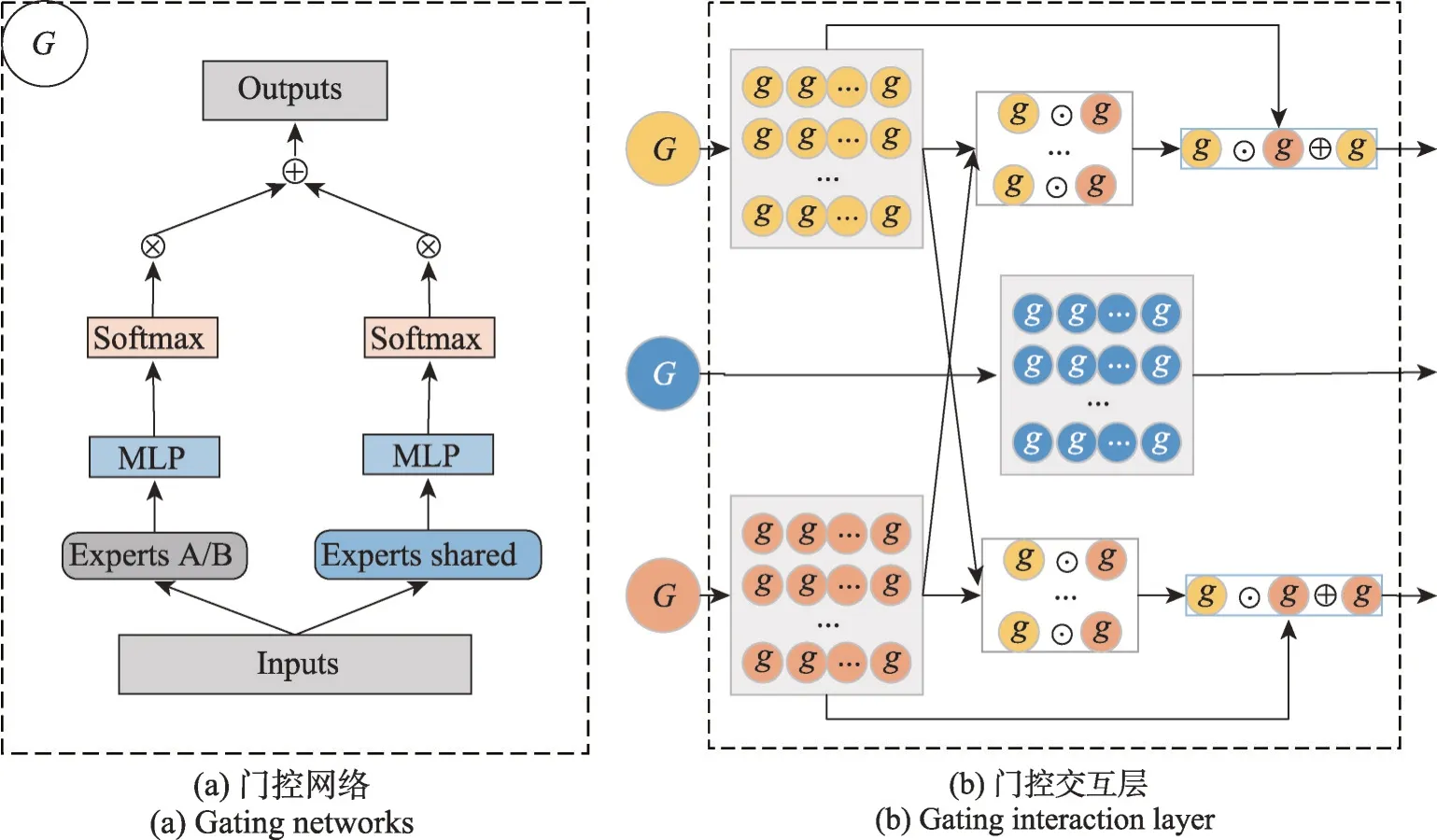
图4 门控网络和门控交互层Fig. 4 Gating networks and gating interaction layer
其中,Wm是交互模块输出的特征变换矩阵,符号⊙表示逐元素相乘,Gi是任务k之外的其他任务的门控输出。在式(3)中,Gk的形式化定义如式(4)所示:
其中,g(·)是门控输出的函数,这里使用多层感知机的神经网络,Wg表示神经网络的权重矩阵。和分别是任务k的专家模块输出和共享专家模块的输出。特别地,在共享门控中,包含了全部任务的专家模块和共享专家模块的输出作为输入,形式化定义如式(5)所示:
门控交互层渐进地学习了多任务的差异性的专有参数,利用任务之间的差异性建模了多任务之间复杂的相关性。同时,采用残差的方式加上原始特定任务学习到的专有参数。这样既保留了原有的任务特定参数,也利用了其他任务的复杂相关性。
2.5 损失函数优化
由前面几节的介绍,DPGI-MTRM模型的最后输出表示为模型中单个任务的损失函数为:
其中,∇θLk(·)是任务k的目标函数梯度,任务k的目标函数根据任务的输出类型决定,当为分类任务时目标函数为交叉熵损失函数,当为回归任务时目标函数为均方误差(MSE)。yk和y^k分别为任务k的目标真实值和目标预测值。综上,多任务模型最终的损失函数可以形式化定义为式(7)所示:
其中,∇θL(θ)是模型共同的梯度向量,K是多任务的目标数量。根据文献[20],多目标优化问题是一个帕累托求解的问题,文献中使用QCOP(quadratic constrained optimization problem)方法优化多个任务的损失权重wi。特别地,式(7)满足几个条件:(1)wi,wi+1,…,wK≥0;(2);(3)存在但是仅仅考虑单目标优化问题时,梯度为零是必要的条件。然而在多目标优化中,是多个目标梯度组合为零的问题。根据文献[21],帕累托的解是一个集合,优化多目标就是在解集里面寻找最优的一个。根据QCOP定义,考虑两个任务目标优化的情况下如式(8)所示,最后得到式(8)中w的一个解析解,如式(9)所示:
根据DPGI-MTRM模型的损失函数,使用梯度归一化的多目标优化算法得到DPGI-MTRM 模型参数的优化算法,如算法1所示。
算法1DPGI-MTRM参数优化算法
DPGI-MTRM 模型的参数优化主要来自双感知专家层和门控交互层的参数学习。双感知层从差异性和共性方面进行参数优化学习,门控交互层从差异性方面进行参数优化学习。
对比的基准模型中,参数差异性方面只有来自元素级的特征输入到门控网络中,参数共性也只是元素级的特征参数学习。本文提出的模型,首先在双感知专家层中,从元素级和向量级的双感知特征表达来学习底层参数的差异性,在参数量上主要增加来自计算向量级的部分,空间复杂度是d,d为输入维度。从时间复杂度上来看,提出的双感知层在元素级和向量级的计算是并行的,几乎不增加时间复杂度。其次在门控交互层中,每个任务门控网络单独学习到各自任务的差异性。从多方面学习到多任务参数差异性,提升了模型的泛化性。在参数共性上,双感知专家层得到两个层级的特征表达,得到丰富的特征语义,为门控交互层提供了增强型的特征表达输入。
3 实验
3.1 实验设置
所有实验均在Intel CoreTMi5-4690 CPU@3.5 GHz和16 GB 内存,11 GB 显存的GTX1080Ti 显卡的64位Ubuntu 系统中完成,所有代码均使用Python 语言编写,计算各评价指标依赖的是Python 的第三方库scikit-learn 0.23.2。本文模型基于Tensorflow 1.15 实现,使用Adam优化器进行训练,初始学习率设为1E-3且每隔25轮下降到原来的10%,训练模型100轮约需要3.5 h。
3.2 数据集
为了评估本文模型的性能,本文在Synthetic Data、Census-income(http://archive.ics.uci.edu/ml)和Ali-CCP(https://tianchi.aliyun.com/dataset/dataDetail?dataId=408)数据集上进行实验验证。
Synthetic Data 数据集是根据文献[22]的数据合成过程生成的,用来控制任务之间的相关性。按照标准正态分布随机采样αi和βi,并且设置c=1,m=10,d=512,分别生成相关性为0.20、0.50、0.75、1.00的两个目标的多任务样本,每个相关性生成100万个具有连续标签的样本数据。
Census-income 数据集是美国UCI 从1994 年人口普查收入数据库中提取的包含299 285 个美国成年人的人口统计信息,由40 个特征组成的数据集。从中选择两组多任务目标进行实验,多任务目标如表1 所示。具体地说,第一组任务中预测收入是否超过5 万美元和个人婚姻状况是否从未结婚;第二组任务将第一组的预测收入换为是否接受过高等教育;第三组任务是将第一组和第二组的首个任务进行组合。
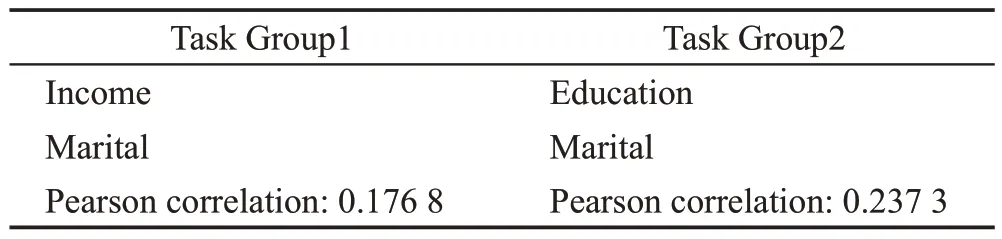
表1 Census-income多任务Table 1 Census-income multi-task
Ali-CCP 数据集是从淘宝的推荐系统中提取的8 400 万个样本的公共数据集,其中点击率(clickthrough rate,CTR)和转化率(conversion rate,CVR)是在此数据集上需要建模的点击和购买的两个任务目标。
3.3 评价指标
实验中将数据集按照8∶1∶1分为训练集、验证集和测试集。对于分类任务采用AUC 来评估模型的CTR 预测性能,对于回归任务采用MSE 作为评价指标,其中MSE的计算指标如下所示:
3.4 结果分析与比较
3.4.1 实验结果比较
表2 和图5 分别展示了本文在Census-income、Ali-CCP 以及Synthetic Data 数据集上两个评价指标AUC 和MSE 上的对比结果。使用MMOE 和PLE 作为对比模型,为了公平地比较模型的性能,对比模型和DPGI-MTRM 模型的专家数n设置为8,模型层数都为3。从表2 中看到,本文的模型在两个数据集上的AUC 指标表现都优于对比的模型。图5 展示了DPGI-MTRM 模型和对比模型在Synthetic Data 数据集上,在不同相关性任务上的MSE 表现。从图5 中可以看出本文方法具有明显的优势。

表2 Census-income和Ali-CCP 数据集上的实验结果(AUC)Table 2 Experimental results(AUC)on Census-income and Ali-CCP datasets
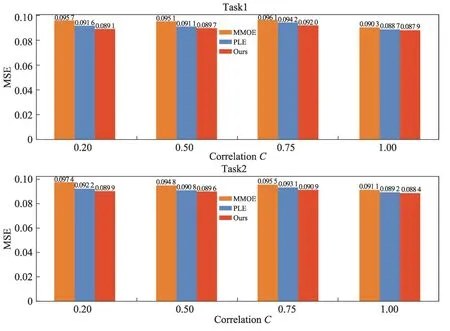
图5 Synthetic Data数据集上相关性多任务的实验结果Fig. 5 Experimental results of correlated multi-task on Synthetic Data dataset
3.4.2 各参数对模型的影响
DPGI-MTRM 模型里的参数专家数n是一个很重要的参数,用于对模型的宽度进行控制,能影响多任务的性能。图6(a)展示了不同n取值下,DPGIMTRM 模型在Census-income 数据集上预测Education 和Marital 多任务的AUC 表现性能。设置了4 组参数n分别进行实验,从图中可以看到,当n取12时,模型在AUC 指标上表现最好。模型的层数l同样是一个重要的参数,当l越大,模型在Census-income 数据集上的AUC 指标表现越好,考虑到模型参数量问题,实验分别设置了l取值为2、3、6、9 和12,且n=8。图6(b)展示了不同l取值下的AUC指标表现性能,可以看到当深度为6时,AUC表现最好,随着深度增加,模型表现逐渐变差,这是因为训练样本不足造成过拟合。

图6 参数n和l对模型的影响Fig. 6 Influence of parameters n and l on model
3.4.3 模型方法的消融实验
为了验证本文提出的双感知专家层和门控交互层对多任务中负迁移的有效解决,设置以下实验进行对比验证。
(1)将DPGI-MTRM模型去掉双感知专家层和门控交互层作为基线模型,记为Base 模型。在Base 模型基础上增加双感知专家层,记为Base-DP模型。两种模型在数据集Census-income 上的AUC 指标的表现如表3所示,可以看到使用了双感知专家层在AUC指标上对比Base 模型在第一组任务上最大提升了0.94%。使用了双感知专家层,让任务的共享参数和专有参数能更好地得到学习,从元素级和向量级得到参数的多层级优化,得到丰富的特征语义表达。由实验可以得出本文提出的双感知专家层,可以解决多任务中负迁移问题,从而提升多任务的性能。

表3 Census-income数据集上的实验结果(AUC)Table 3 Experimental results(AUC)on Census-income dataset
(2)对比Base模型,在Base模型的基础上增加门控交互层,记为Base-GI 模型。两种模型在数据集Census-income 上的AUC 指标的表现如表3 所示,可以看到使用了门控交互层在第一组任务上AUC指标最大提升了0.89%。设计的门控交互层,将多任务的专有参数渐进地优化学习,将第一阶段中双感知专家层学习的差异参数进一步优化。同时,使用任务之间差异性进行交互,对任务之间复杂相关性进行建模,增强了共性参数的优化学习。由实验可以得到本文提出的门控交互层,可以解决多任务中负迁移问题,从而提升多任务的性能。
(3)对比Base模型,在Base模型的基础上同时增加双感知专家层和交互层,即为DPGI-MTRM 模型。两种模型在数据集Census-income 上的AUC 指标的表现如表3 所示,可以看到AUC 指标最大提升了2.06%,由此可以得出本文提出的双感知门控交互的多任务推荐模型是有效可行的,能解决多任务负迁移问题。
4 结束语
为提升多任务推荐中点击率预测的准确性,解决多任务中负迁移的问题,本文提出了一种双感知门控交互的多任务推荐模型(DPGI-MTRM)。模型考虑到底层特征提取的方式,设计了双感知专家层,其得到元素级和向量级的双感知特征表达。同时针对多任务的负迁移问题,提出门控交互层,增强了多任务交互学习,有效利用了多任务的专有参数,从而提升多任务的模型性能。通过在三个数据集上的实验,结果表明提出的模型在预测准确性上较基准模型有明显的提升,验证了模型方法的有效性。
