nPSA:一种面向TSN 芯片的低延时确定性交换架构
2023-06-07付文文刘汝霖姜旭艳孙志刚
付文文 刘汝霖 全 巍 姜旭艳 孙志刚,2
1 (国防科技大学计算机学院 长沙 410073)
2 (并行与分布处理国防科技重点实验室(国防科技大学)长沙 410073)
在工业自动化、自动驾驶等实时领域,总线技术已逐渐达到带宽瓶颈,无法承载日益增长的流量规模,并且各总线技术互不兼容,制约了其发展前景[1-2].由于以太网具有高带宽与良好兼容性的特点,工业界和学术界期望采用以太网技术弥补总线技术的不足.然而,以太网“尽力而为”的转发模式容易导致帧丢失或经历不确定的传输延时,这使其难以满足实时应用的实时性和确定性要求.因此相关工作组在传统以太网标准基础上扩展时间同步和时间感知整形内容,制定了时间敏感网络(time-sensitive networking,TSN)标准[3].
在TSN 系统中,为了保证关键流量传输延时的确定性和实时性,TSN 规划工具需要预先为关键流量规划其在每个节点的发送时间.其中关键流量是被调度的对象,因此也称被调度流量(scheduled traffic,ST).规划发送时间时,规划工具将重负载情况下ST帧在各节点中可能经历的最大交换延时作为规划算法的输入参数[4].节点的最大交换延时与相邻节点发送时间的间隔呈正相关关系(具体分析见1.1 节).为了缩短相邻节点的发送时间间隔以实现更低的传输延时,进而满足TSN 应用对传输延时的苛刻要求(如汽车自动化中的动力系统和底盘控制要求传输延时小于10 μs[5]),TSN 交换芯片设计时需要以最小化最大交换延时为重要目标.
当前的商用TSN 交换芯片(如BROADCOM 公司的BCM53154[6]芯片)一般沿用以太网中主流的单流水线交换架构(1-pipeline switching architecture,1PSA)[7-8].在1PSA 架构中,所有端口的帧共享一条处理流水线,这使得不同端口的帧因竞争流水线的处理资源而在流水线入口处发生完整帧阻塞问题,产生阻塞延时.最大阻塞延时与端口类型、流水线工作频率和处理位宽等因素相关.以2× 10 Gbps+8× 1 Gbps端口组合的TSN 芯片为例,假设流水线的工作频率为125 MHz,处理位宽为256 b,帧在该芯片中可能经历的最大阻塞延时超过24 μs(具体分析见1.2 节).这导致基于1PSA 架构的TSN 交换芯片的最大交换延时难以降低,并且需要消耗大量的存储资源缓存阻塞延时内到达的帧数据(下文简称该缓存为阻塞缓存).
针对已存在的问题,本文面向TSN 芯片提出了一种超低阻塞的多流水线交换架构(n-pipeline switching architecture,nPSA).根据TSN 标准描述[3],TSN 的许多功能(如整形调度、帧抢占、帧复制与消除)适合在各端口逻辑中部署,在单流水线中实现和管理复杂.因此nPSA 架构为每个端口都实例化一条独享的处理流水线,可消除1PSA 架构中在流水线入口处的阻塞问题.而且为了提升存储资源的利用率和降低功耗,nPSA 采用集中式共享存储结构,即所有端口的帧共享集中缓冲区(具体分析见1.3 节).这使得nPSA 架构的多条流水线需要竞争集中缓冲区,进而引入新的nPSA 阻塞问题.
为了最小化因竞争集中缓冲区而产生的阻塞延时和阻塞缓存,nPSA 架构通过基于时分复用的访存机制将1PSA 架构中的完整帧阻塞问题优化成切片阻塞问题.该访存机制的基本思想包括:1)各流水线累积接收的数据量达到切片寄存器的容量时(切片寄存器容纳的数据量远小于完整帧的数据量)便可写入集中缓冲区;2)各流水线写入/读取集中缓冲区的时隙由算法预先规划好,可保证访存操作有序无冲突地进行.此外,为了能使该访存机制运行,本文提出了加权轮询式时隙分配算法(weighted roundrobin slot allocation algorithm, WRRSA).该算法可灵活地求解不同端口组合下各流水线访问集中缓冲区的时隙分配方案.
然后,本文从理论维度比较nPSA 和1PSA 架构在多种典型的芯片配置下产生的最大阻塞延时和阻塞缓存所需的存储资源.理论评估结果表示nPSA 架构产生的最大阻塞延时和所需的阻塞缓存容量比1PSA 架构低2 个数量级.nPSA 架构和WRRSA 算法在OpenTSN 开源芯片[9-10]和“枫林一号”ASIC 芯片[11]中得到应用.为了证实理论评估结果,本文对Open-TSN 芯片(基于FPGA 实现)和“枫林一号”芯片的最大交换延时进行实测.测试结果显示在不同流量负载下,长度为64 B 的ST 帧在OpenTSN 芯片和“枫林一号”芯片的最大交换延时(头进头出)分别为1648 ns 和698 ns(其中最大阻塞延时都为72 ns).与基于1PSA 架构的TSN 交换芯片的理论值相比,最大交换延时分别降低约88%和95%.而且OpenTSN 芯片和“枫林一号”芯片的阻塞缓存容量都为2.25 Kb,与基于1PSA 架构的TSN 芯片的理论值相比都降低约97%.此外,本文分别基于OpenTSN 芯片和“枫林一号”芯片(ASIC 芯片验证板)搭建了支持混合优先级流量传输的真实环境并进行实验.实验结果显示OpenTSN 芯片和“枫林一号”芯片可为ST 流量提供亚微秒级确定性和微秒级实时性传输服务,满足现有TSN 场景对确定性和实时性的需求.
本文主要贡献有4 点:
1)面向TSN 芯片提出了一种多流水线交换架构nPSA,有效降低最大交换延时和存储资源消耗;
2)提出了基于时分复用的访存机制,以保证各流水线能够超低阻塞地访问集中缓冲区;
3)提出了加权轮询式时隙分配算法,以求解不同端口组合下的时隙分配方案;
4)在真实的TSN 芯片中对nPSA 架构进行实践,并通过实验证明了其优点.
1 背景与挑战
1.1 最大交换延时作用分析
与软件定义网络(software defined network,SDN)[12]类似,TSN 系统一般采用控制平面与数据平面解耦的网络架构.控制平面为所有ST 帧规划其在各节点的发送时间;数据平面根据规划结果执行相应的按时转发操作.
发送时间的规划粒度是规划算法的重要参数,直接影响算法的计算复杂性和可规划的ST 流量规模.根据现有的规划算法,发送时间的规划粒度可分为时间颗粒(time granularity,TG)和时间槽(time slot,TS)2 类.基于时间颗粒的规划算法一般以数十纳秒至1 μs 为时间单元[3,13],允许ST 帧在相邻节点传输时占用多个时间单元.而基于时间槽的规划算法将时间跨度增大,保证在任意相邻节点中1 个时间槽最多传输1 个ST 帧,且保证在相邻节点中当前时间槽在上游节点发送的ST 帧能够在下一时间槽从下游节点中发出.时间槽的设置一般为数十微秒[4].
为了对基于2 种粒度的规划算法性能进行深入比较,本文设置如图1(a)所示的实验场景,其中f1和f2为ST 流.面向该场景,基于2 种粒度的规划结果分别如图1(b)(以时间颗粒为规划粒度)和图1(c)(以时间槽为规划粒度)的甘特图所示,通过比较可直接得出2 个结论.
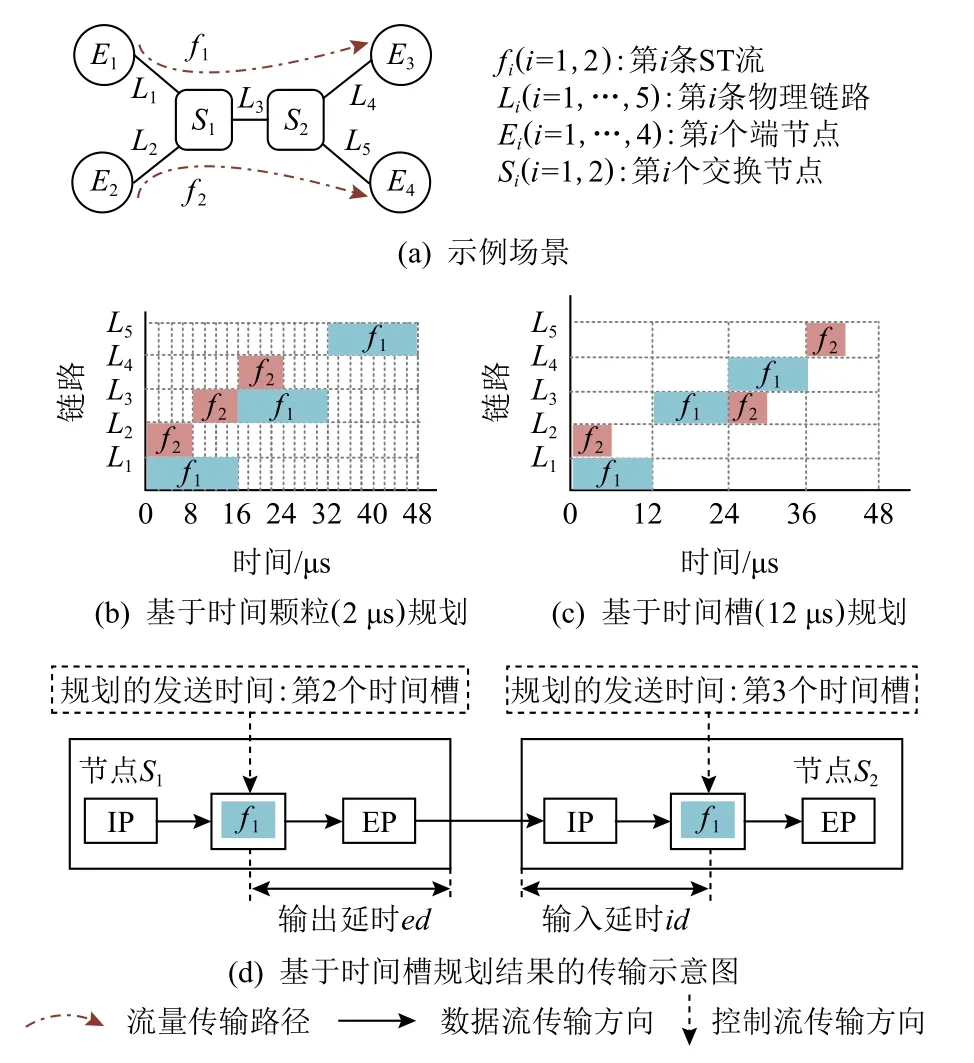
Fig.1 TSN planning results and transmission scenario图1 TSN 规划结果与传输场景
1)在基于时间颗粒的规划算法中,发送时间的可选解远多于基于时间槽的规划算法,即图1(b)中横坐标的值域远大于图1(c),进而可知图1(b)的计算复杂性远高于图1(c).此外,时间颗粒比时间槽的粒度更细.在相同的规划周期内,基于时间颗粒的规划算法会生成规模更大的规划表,进而需要更多的片上存储资源.
2)基于时间槽的规划算法可调度的ST 流规模更小.由于1 个时间槽只能传输1 个ST 帧,且时间槽的设置面向最长的ST 帧,因此传输ST 短帧时,ST流量对链路带宽的利用率较低.例如,当f1的报文长度是f2的2 倍时,图1(c)中ST 帧在第1 个时间槽对链路L2的带宽利用率仅为50%.
由于TSN 技术继承以太网技术的高带宽特性,且替代目标为低带宽的总线技术,因此大多数TSN场景中,ST 流量带宽占链路带宽的比例很小[1,5].这使得基于时间槽的规划算法的理论缺点在众多实际TSN 场景中可忽视.因此,基于时间槽的规划算法成为TSN 规划算法的主要趋势.
根据基于时间槽的规划算法性质(在相邻节点中,当前时间槽在上游节点发送的ST 帧,能够在下一时间槽从下游节点中发出),当ST 帧在下游节点的发送时间槽始终比上游节点的发送时间槽大1时,相邻节点的发送时间间隔最小,且端到端传输延时最小.最小端到端传输延时的取值范围为((h-1)×VTS,(h+1)×VTS),其中h为传输路径中交换节点的数量,VTS为时间槽的取值,进而可知ST 帧的最小端到端传输延时与时间槽的取值呈线性正相关关系.因此为了满足汽车动力系统和底盘控制等TSN应用对传输延时的苛刻要求,时间槽的取值需要尽可能小.
由于当前时间槽在上游节点发送的ST 帧能够在下一时间槽从下游节点中发出(如图1(d)中ST 帧在第2 个时间槽从上游节点S1发出,在第3 个时间槽从下游节点S2发出),时间槽的取值需要满足式(1)中所示的约束.
其中,S1.edmax为节点S1的最大输出延时(帧开始被调度至该帧开始输出到链路中可能经历的最大延时),S2.idmax为节点S2的最大输入延时(帧开始输入到芯片至该帧开始写入集中缓冲区中可能经历的最大延时).δ为相邻节点的时钟误差.Gb为用于消除非ST帧对ST 帧确定性干扰的保护带[14].L为报文长度,r为链路速率.式(1)表示时间槽的取值需要大于上游节点的最大输出延时、下游节点的最大输入延时、相邻节点时钟误差、保护带和发送延时(L/r)之和.
式(1)中芯片相关的参数包括idmax,edmax,δ.由于时钟同步的相关研究众多,且同步精度δ一般维持在数十纳秒级[15-16],对时间槽的取值影响比较小,本文面向TSN 芯片设计聚焦于降低idmax和edmax取值.由于idmax和edmax是芯片最大交换延时的组成部分,因此TSN芯片需要以最小化最大交换延时为重要设计目标.
1.2 1PSA 交换架构的传输延时分析
目前TSN 芯片沿用以太网芯片中主流的1PSA交换架构,如图2 所示.1PSA 架构使用单流水线处理所有端口输入的帧,这使得从不同端口同时输入的帧在流水线入口处相互阻塞.
Fig.2 1PSA switching architecture图2 1PSA 交换架构
例如,帧A和帧B同时分别从不同端口输入.2个帧竞争共享流水线的方式理论上可分为2 种:1)切片轮询(slice round-robin,SRR).该方式需要将帧A和帧B都切分成若干切片.流水线轮询调度帧A和帧B的切片.2)完整帧轮询(frame round-robin,FRR),即流水线调度完整帧A(或帧B)的所有数据后才会调度另一个帧.由于单流水线无法识别未携带帧首部的切片,而且给每个切片增加首部信息会使额外增加的资源过多(增加的资源包括首部添加逻辑、首部消除逻辑、存储首部信息的寄存器等),因此传统以太网交换芯片采用FRR 的方式分配流水线资源[8].然而该方式必然使帧B(或帧A)经历另一个帧的阻塞延时(设为DFRR),即等待另一个帧传输完所需的时间.
连续工作模式公平调度算法下[17],帧在汇聚时的阻塞延时DFRR(帧在输入队列中头进头出的延时)满足式(2)所示的关系式,关系式中使用的参数含义如表1 所示,详细证明见附录A 的定理A1.

Table 1 Related Parameters of DFRR in 1PSA表1 1PSA 中的DFRR 相关参数
每个端口需要在帧汇聚处设置一个输入队列作为阻塞缓存.为了保证在连续工作模式公平调度算法下,当帧在端口i的输入队列中无溢出时,该输入队列的容量Ci满足式(3)所示关系式, 详细证明见附录A 的定理A2.
以2× 10 Gbps+8× 1 Gbps 端口的TSN 芯片为例,为了保证所有端口能够线速传输,1PSA 架构中单流水线的处理速率(f×B)需要大于或等于所有端口的速率之和(28 Gbps).根据式(2)可知,流水线的处理速率越快,即f和B越大,阻塞延时DFRR越小.然而,功耗与f呈正相关关系[18],因此f不能设置过大.而且B越大,消耗的资源也相应地增加.假设该芯片f=125 MHz,B= 256 b,处理速率为32 Gbps.此外,TSN 芯片支持的最大帧长度为1518 B.根据式(2)可计算出DFRR的理论最大值,约24.18 μs.这使得DFRR成为芯片最大交换延时的主要部分,进而导致1PSA 交换架构的最大交换延时难以降低.而且根据式(3),该TSN芯片中每个万兆端口对应的阻塞缓存容量应设置为10.8 KB,每个千兆端口对应的阻塞缓存容量应设置为3.1 KB.这使得基于1PSA 交换架构的TSN 芯片需要消耗大量宝贵的片上存储资源.
1.3 TSN 交换架构设计思路与挑战
根据TSN 标准描述,TSN 功能(如帧复制与消除、帧剥夺、整形调度等)适合在TSN 芯片的端口逻辑中部署.因此TSN 芯片适合为每个端口部署一条独享的流水线,以降低上述TSN 功能实现和管理的复杂性,而且实例化多条流水线可消除1PSA 架构中的阻塞延时.
此外为了提升存储资源利用率,TSN 交换架构一般采用共享存储结构[19],即所有端口的帧共享缓冲区,而且TSN 芯片常用于原味替代现有的以太网或总线芯片.在这些场景中TSN 芯片继续使用被替代芯片的电源,使功耗高于被替代芯片的TSN 芯片难以适用于此类场景.由于分布式共享存储结构允许多个读写操作同时进行,这使其峰值功耗远大于集中式共享存储结构.并且集中式共享存储结构的实现和管理复杂性远低于分布式共享存储结构,这些使集中式共享存储结构在TSN 交换设备中更适用.
在集中式共享存储结构中,所有端口的帧共享集中缓冲区,这使得实例化多条流水线需要竞争共享缓冲区,引入新的阻塞延时与阻塞缓存.为了降低因竞争缓冲区而产生的阻塞延时并降低阻塞缓存容量,基于集中式共享存储的多流水线交换架构需要解决2 个挑战.
挑战1:如何保证各流水线超低阻塞地访问集中缓冲区.从不同端口同时输入的帧都需要写入集中缓冲区,然而缓冲区仅有单或双访问接口.若不对帧的访存操作进行控制,则不同端口输入的帧可能相互阻塞,产生类似于1PSA 交换架构中的阻塞延时,进而无法有效地降低芯片内的最大交换延时.
挑战2:如何适配不同场景下芯片端口(或流水线)数量和处理速率的多样性.为了适配不同TSN 芯片中端口(或流水线)数量和处理速率的多样性,TSN 交换架构急需一种灵活的算法为各端口(或流水线)合理地分配集中缓冲区的访问带宽.
为了解决这2 个挑战,本文面向TSN 交换芯片提出一种基于时分复用访存的多流水线交换架构(nPSA),并为该架构设计了一种加权轮询式时隙分配算法(WRRSA).
2 nPSA 架构设计
如图3 所示,nPSA 架构的基本组成包括输入流水线(ingress pipeline,IP)、基于时分复用的切片汇聚(slice-based time division multiplexing,STDM)集中缓冲区(Buf)、切片分派和输出流水线(egress pipeline,EP).其中,IP 完成帧接收与解析等操作;STDM 缓存从IP 输入的帧切片,并基于时分复用的方式往集中缓冲区中写入缓存的切片;集中缓冲区Buf 存储所有端口输入的帧数据;切片分派通过时分复用的方式从集中缓冲区中读取帧数据,并将帧数据传输给各EP(由于切片分派原理与STDM 类似,本文不对其展开描述);EP 完成队列门控和调度输出等功能.
Fig.3 nPSA switching architecture图3 nPSA 交换架构
通过与1PSA 架构进行比较,nPSA 架构的主要包括2 点特点:
1)nPSA 架构为每个端口实例化一条独享的流水线.虽然实例化多条流水线理论上使流水线中逻辑资源的消耗增加,但是nPSA 架构消除了1PSA 架构中各端口的输入队列,可有效节省存储资源.而且,由于TSN 功能(队列整形调度、帧剥夺),nPSA 大多适合在各端口逻辑中部署,通过逐端口的流水线实现TSN 功能可有效降低实现和管理复杂性.此外,TSN 流水线的处理逻辑简单,无须集成以太网中复杂的IP 层查表功能.这些使得与1PSA 架构相比,nPSA架构虽然增加逻辑资源,但是大幅降低存储资源,整体上有利于减小芯片面积.
2)nPSA 架构使用STDM 逻辑处理各流水线的数据汇聚,将帧阻塞问题优化成切片阻塞问题,即将阻塞延时由1PSA 架构中的DFRR优化为DSTDM.在1PSA 架构中,为了单流水线能够识别各端口输入的帧数据,1PSA 架构中的汇聚逻辑必须缓存完整的帧后才能往后传输.而nPSA 架构中的STDM 逻辑只需缓存帧切片,无须缓存整个帧.这是因为nPSA 架构的缓冲区管理逻辑可通过帧数据的载体识别帧切片的来源.而1PSA 架构中各端口输入的帧在单流水线中混合后,其缓冲区管理逻辑无法通过载体识别未携带首部信息的帧切片来源.
由于nPSA 架构采用集中存储结构缓存所有端口的帧数据,这使得多条流水线需要竞争集中存储资源.为了在竞争存储资源时保证各流水线进行超低阻塞的访存操作(挑战1),nPSA 架构集成了基于时分复用的访存机制.而且,为了灵活适配流水线数量和速率的多样性(挑战2),本文为访存机制搭配了WRRSA 算法.
3 关键技术
3.1 基于时分复用的访存机制
nPSA 交换架构通过基于时分复用的访存机制实现超低的阻塞延时与阻塞缓存容量.该访存机制的主要思想包括:1)通过为每条流水线合理地分配访问集中缓冲区的时隙,保证每个时隙仅被1 条流水线独享,进而消除访存冲突;2)通过切片轮询替换完整帧轮询,大幅降低阻塞延时与阻塞缓存的容量;3)通过流水线的序号识别切片来源,消除为识别切片来源而消耗的额外的资源.
基于时分复用的访存机制涉及的核心组件如图4(a)所示,包括时隙分配向量、时隙分配控制、切片写入控制(slice write control,SWC)和切片写入仲裁(slice write arbitrate,SWA).
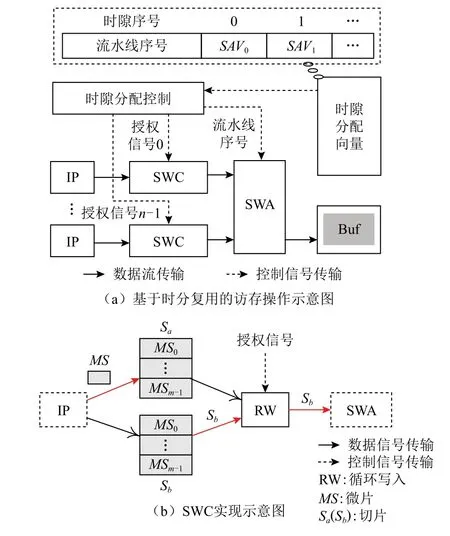
Fig.4 STDM-based memory access mechanism图4 基于STDM 的访存机制
时隙分配向量表示在每个时隙中,SWA 应该调度哪条流水线输入的帧数据.如图4(a)所示,向量内容为流水线序号,地址信息为时隙序号.向量中的地址数量为时隙分配操作循环1 次所需的时隙数量,设为轮询周期snperiod.snperiod通过式(4)获取.
Vtotal为各流水线(或端口)的速率之和,gcd(V[0],V[1],…,V[N-1])为所有流水线速率的最大公约数.例如,在8× 1 Gbps+2× 10 Gbps 的端口组合中,端口速率的最大公约数为1024Mbps(由于目前端口速率单位一般是百兆、千兆或万兆,因此最大公约数使用Mbps 作为单位),snperiod=28.而且为了提升时隙分配的粒度,时隙设置为缓冲区管理逻辑的硬件时钟周期.例如,缓冲区管理逻辑工作在125 MHz 频率下,其硬件时钟周期为8 ns,即时隙为8 ns.
时隙分配控制逻辑用以接收时隙分配向量,并根据时隙分配向量对SWA 和SWC 进行控制.控制的具体方式为在每个时隙中,时隙分配控制逻辑从向量中获取下一时隙应该调度的流水线序号.然后,时隙分配控制逻辑给流水线序号对应的SWC 发送有效的授权信号,并且通知SWA 在下一时隙应该调度的流水线序号.
SWC 主要包括循环输入寄存器组(如Sa和Sb)和循环写入(recurrent writing,RW)逻辑.如图4(b)所示,SWC 使用循环输入寄存器组存储对应流水线输入的微片(micro-slice,MS).MS 的位宽为BMS,即对应流水线1 个时钟周期处理的数据量.MS 用于组成切片,Sa(sb)的位宽为BS,即缓冲区管理和RW1 个时钟周期处理的数据量.BS与BMS的关系满足BS=m×BMS(m为正整数).例如,在8× 1 Gbps+2× 10 Gbps 的端口组合中,千兆端口对应的IP 和EP 工作频率为125 MHz,万兆端口对应的IP 和EP 工作频率为156.25 MHz,缓冲区管理逻辑的工作频率为256 MHz;则千兆端口对应的MS 位宽为8 b,万兆端口对应的MS 位宽为64 b,缓冲区管理逻辑的处理位宽为128 b,即切片位宽BS为128 b.
当RW 逻辑从时隙分配控制逻辑接收到有效的授权信号时,才可输出循环输入寄存器中的数据.输出方式采用循环输出,即本次输出了 Sb中的数据,下次只能输出 Sa中的数据,并不断循环.并且只有当目标寄存器的数据已满时,才允许输出该寄存器内的数据.输出时,RW 逻辑将寄存器中的数据转发给SWA,并等待其接收.
SWA 接收时隙分配控制逻辑传输的流水线序号,在下一时隙从该流水线序号对应的SWC 逻辑中接收帧数据.帧数据接收成功后,SWA 将该数据直接写入集中缓冲区中,并返回成功信号给SWC 逻辑.
3.2 加权轮询式时隙分配算法(WRRSA)
基于芯片端口配置的多样性,nPSA 架构的访存机制需要搭配合适的时隙分配算法以生成时隙分配向量.该时隙分配算法的设计前提是保证各流水线无中断地输出任意帧,并且保证帧数据不会在循环寄存器中溢出.基于此,WRRSA 算法的设计思包括:
1)各流水线访问集中缓冲区的时隙数量比例等于相应流水线速率占流水线总速率的比例.例如,10 Gbps流水线分配的时隙数量是1 Gbps 流水线的10 倍.
2)各流水线分配的时隙均匀分布.为了减少循环寄存器组的存储容量,各流水线分配的时隙需要均匀分布以降低时隙间隔的最大值.
WRRSA 算法的详细描述见算法1,其相关参数见表2.

Table 2 Related Parameters of WRRSA Algorithm表2 WRRSA 算法相关参数
基于算法1 描述,在8× 1 Gbps+2× 10 Gbps 的端口组合中,且缓冲区管理逻辑的处理速率为32 Gbps 时,WRRSA 算法为该TSN 芯片计算出的时隙分配向量如式(5)所示,其中序号1 和2 表示2 个万兆端口对应的流水线序号,3~10 表示8 个千兆端口对应的流水线序号.轮询周期(snperiod)为28,千兆端口的时隙间隔为28,万兆端口分配的时隙间隔为3.
WRRSA 算法具有3 个特性,特性证明见附录A.
1)nPSA 架构的最大阻塞延时(即DSTDM的最大值)为snperiod个时隙.在8× 1 Gbps+2× 10 Gbps 端口组合的TSN 芯片中,DSTDM的最大值为28 个时隙.
2)帧数据在循环输入寄存器组中无溢出的充分必要条件是循环输入寄存器组中寄存器的数量不小于2.
3)帧传输不中断的充分必要条件是SWC 中循环输出寄存器组中寄存器的数量不小于2.
4 实 现
为了验证nPSA 架构的优点,OpenTSN 开源芯片(基于FPGA 实现)和“枫林一号”ASIC 芯片对其进行了实践.
1)OpenTSN 芯片.该芯片实现架构如图5(a)所示,其核心组成包括IP(输入流水线)、配置管理、时分复用访存、时间同步和EP(输出流水线).其开源代码和设计文档见文献[9].
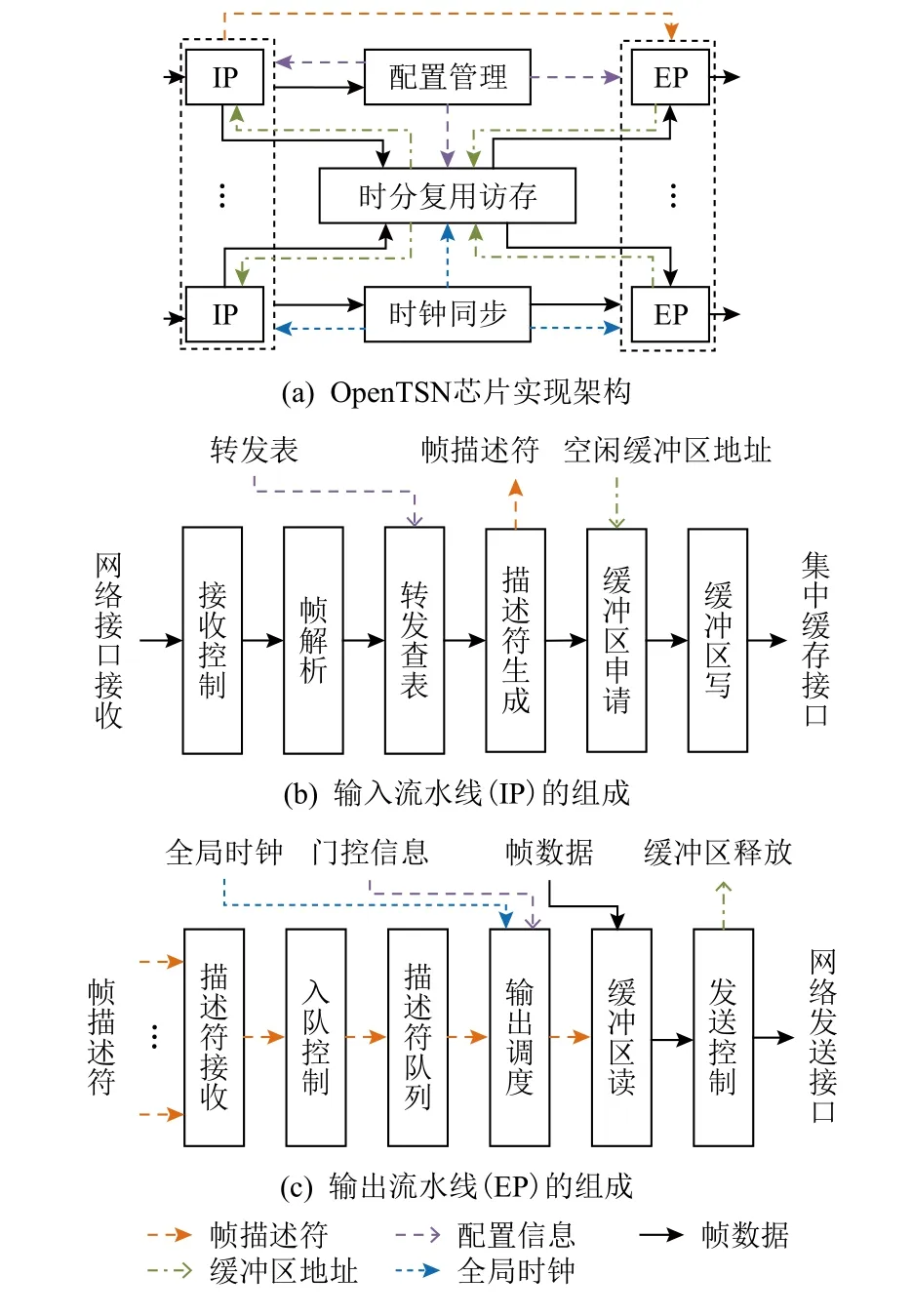
Fig.5 OpenTSN chip implementation图5 OpenTSN 芯片实现
IP 的组成如图5(b)所示,包括接收控制、帧解析、转发查表、描述符生成、缓冲区申请、缓冲区写模块.IP 负责将配置帧、同步帧和数据帧解析后分别转发给配置管理、时间同步和时分复用访存模块,并且提取数据帧的描述符(包含对应帧的关键信息组)转发给EP;配置管理通过解析配置帧获取配置内容,并将配置内容写入对应寄存器或表;时分复用访存完成多条流水线的访存操作;时间同步为IP,EP 和时分复用访存逻辑提供全局统一的时间;EP 的组成如图5(c)所示,包括描述符接收、入队控制、描述符队列、输出调度、缓冲区读、发送控制模块.其主要负责根据接收的帧描述符提取对应的数据帧并按照规划的时间输出.
为了测试nPSA 架构中每条TSN 流水线所需的逻辑资源,本文基于FPGA 实现了OpenTSN 开源芯片逻辑.OpenTSN 芯片具有9 个千兆接口,资源消耗如表3 所示.其中每条输入与输出流水线消耗的自适应查找表(adaptive look-up table)ALUT、寄存器、自适应逻辑模块(adaptive logic module, ALM)资源都小于对应总资源的8%,且存储块数量仅消耗13 584,仅占芯片总存储块的1.6%.
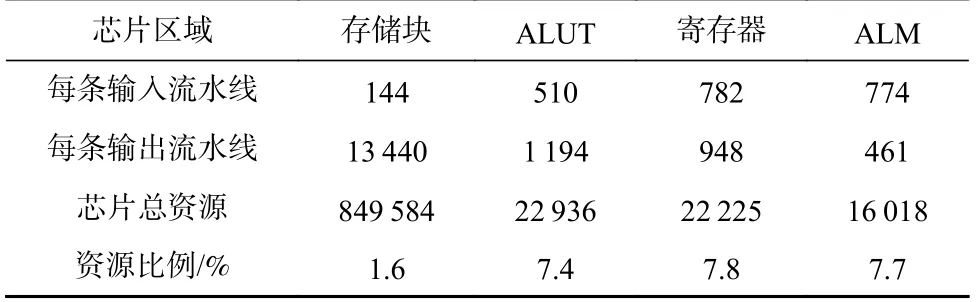
Table 3 Resource Consumption of OpenTSN Chip表3 OpenTSN 芯片资源消耗
2)“枫林一号”芯片.“枫林一号”的芯片架构与设计思路见文献[11].“枫林一号”芯片具有9 个千兆端口.其采用国产130 nm 工艺流片,芯片封装为256引脚QFP 封装,面积仅为9 nm× 9 nm,峰值功耗仅为0.46 W.
5 评 估
5.1 理论评估
通过对1PSA 架构和nPSA 架构进行比较可知,1PSA 架构的阻塞延时DFRR和nPSA 架构的阻塞延时DSTDM是2 种架构交换延时的主要变量因素.为了证明nPSA 架构可有效降低1PSA 架构的最大交换延时,本文基于4 种典型的TSN 芯片设置对2 种架构的最大阻塞延时进行量化比较.量化结果如表4 所示.在4 种典型的TSN 芯片端口设置中,与1PSA 架构的DFRR最大值相比,nPSA 架构的DSTDM最大值可降低2个数量级.

Table 4 Comparison of Theoretical Blocking Delay Between 1PSA Architecture and nPSA Architecture表4 1PSA 架构和nPSA 架构的理论阻塞延时比较
本文基于上述4 种典型的TSN 芯片设置,对2种架构所需的阻塞缓存容量进行量化比较.量化结果如表5 所示,与1PSA 架构阻塞缓存需要消耗的存储容量相比,nPSA 架构也可降低2 个数量级.

Table 5 Comparison of Theoretical Blocking Cache Capacity Between 1PSA Architecture and nPSA Architecture表5 1PSA 架构和nPSA 架构的理论阻塞缓存容量比较
5.2 实验评估
OpenTSN 芯片和“枫林一号”芯片HX-DS09 都具有9 个千兆端口.OpenTSN 芯片和中“枫林一号”芯片每条流水线的工作频率和位宽分别为125 MHz和8 b,且缓冲区管理逻辑的工作频率和位宽分别为125 MHz 和128 b.
1)最大交换延时.为了验证nPSA 架构的优点,本文首先对OpenTSN 芯片和“枫林一号”芯片的最大交换延时进行实测.最大交换延时是芯片能力参数,不是组网时的网络延时参数,因此测量拓扑和被测芯片的实际部署拓扑可不同.测试拓扑为被测芯片与测试仪直连.具体测试步骤为在1 个测试端口中输入一条恒定的ST 流量,帧长度为1 500 B.同时,向其他所有个端口都输入动态的背景流量,且背景流量帧长度也为1 500 B.所有流量的输出端口号与其输入端口号相同,且通过设置保证帧能够即到即走.测试时长1 h,其实验结果如表6 所示,ST 帧在芯片内经历的最大交换延时与其他端口传输的流量无关(即最大交换延时具有确定性),在OpenTSN 芯片和“枫林一号”芯片中的最大交换延时(头进头出)分别为1648 ns 和698 ns,其中最大阻塞延时都为72 ns.根据式(2)、基于1PSA 交换架构的相同TSN 芯片(具有相同的端口、处理频率和位宽)的阻塞延时DFRR的理论最大值约为13.6 μs.因此OpenTSN 芯片和“枫林一号”芯片的最大交换延时分别降低约88%和95%.

Table 6 Comparison of Maximum Switching Delay of Two Chips表6 2 块芯片的最大交换延时比较
由表6 可证明,与1PSA 架构相比,nPSA 架构可有效降低TSN 芯片的最大交换延时.
2)端到端传输延时.本文通过验证OpenTSN 芯片和“枫林一号”的实时性和确定性以证明nPSA 架构的可行性.本文基于OpenTSN 芯片构建了如图6所示的真实测试环境.该环境包括2 块OpenTSN 芯片(基于FPGA 实现)、2 台测试仪和3 台PC 终端.其中测试仪1 发出1 条ST 流(ST1)和1 条BE 流(BE1,传统以太网中尽力而为的流量,作为背景流),测试仪2 也发出1 条ST 流(ST2)和一条BE 流(BE2).4 条流量的传输路径如图6 所示.
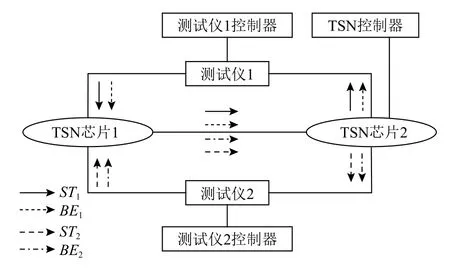
Fig.6 OpenTSN experiment topology图6 OpenTSN 实验拓扑
在OpenTSN 实验1 中,流特征如表7 所示.最长的ST 报文为128 B,在1 Gbps 链路的传输时间为(报文长度/链路速率)为1 μs.背景流(BE1,BE2)的报文长度为128 B,因此背景流对ST 帧确定性的干扰最大为1 μs(=128 B/1 Gbps),进而需要设置1 μs 的保护带.此外2 块TSN 芯片的时钟同步精度时钟维持在100 ns以内,且OpenTSN 芯片的最大交换延时为1648 ns.根据式(1),本实验将时间槽设置为4 μs.

Table 7 Flow Characteristics of OpenTSN Experiment 1表7 OpenTSN 实验1 的流量特征
在OpenTSN 实验1 中,ST 报文在门控周期的第0 个时间槽(0~4 μs)从测试仪中发出.2 块TSN 芯片的门控表如表8 所示,即2 条ST 流期望在第1 个时间槽(4~8 μs)从TSN 芯片1 发出,在第2 个时间槽(8~12 μs)从TSN 芯片2 发出.

Table 8 Gate Control List of OpenTSN Experiment 1表8 OpenTSN 实验1 的芯片门控列表
OpenTSN 实验1 的结果如图7 所示,ST1的端到端传输延时在8 337~8 825 ns 的范围内波动,其传输延时抖动小于600 ns.ST2的端到端传输延时在8 201~9 177 ns 的范围内波动,其传输延时抖动小于1 000 ns.该实验结果表明ST 报文在测试仪至TSN 芯片1 链路中的传输时间(包括在下游节点的缓存时间)为0~4 μs,在TSN 芯片1 至TSN 芯片2 链路的传输时间为4~8 μs,在TSN 芯片2 至测试仪链路的传输时间为8 μs 以后,与预期结果一致.
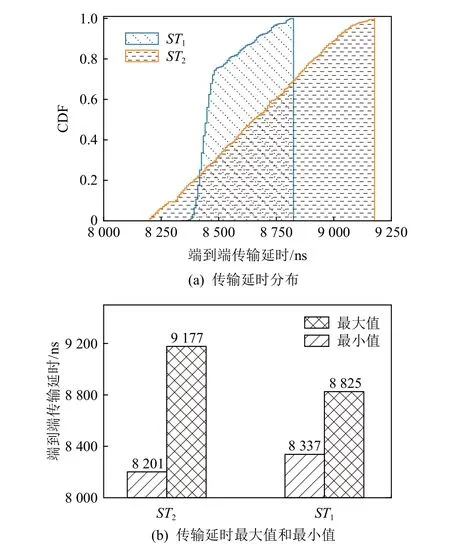
Fig.7 End-to-end transmission delay of OpenTSN experiment 1图7 OpenTSN 实验1 的端到端传输延时
OpenTSN 实验2 中测试流量的流量特征如表9所示.按照式(1),该实验通过调整报文长度修改时间槽的取值.在该实验中,最长的ST 报文为512 B,在1 Gbps 链路的传输时间(报文长度/链路速率)为4 μs.背景流(BE1,BE2)的报文长度为1280 B,因此背景流对ST 帧确定性的干扰最大为10 μs(=1280 B/1 Gbps),进而需要设置10 μs 的保护带.此外OpenTSN 芯片的同步精度为100 ns.根据式(1),本实验将时间槽设置为16 μs.
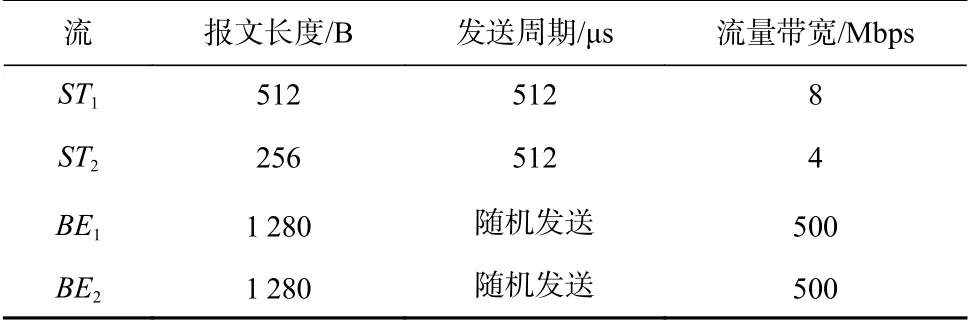
Table 9 Flow Characteristics of OpenTSN Experiment 2表9 OpenTSN 实验2 的流量特征
ST 报文在测试仪的发送时间和2 块TSN 芯片的门控表的设置与OpenTSN 实验1 相同.OpenTSN 实验2 的测试结果如图8 所示.与预期一致,ST1的端到端传输延时围为33 885~34 005 ns,ST2的端到端传输延时围为33 881~33 972 ns.2 条ST 流的传输延时抖动都维持在0.2 μs 以内.

Fig.8 End-to-end transmission delay of OpenTSN experiment 2图8 OpenTSN 实验2 的端到端传输延时
本文构建了包含2 块“枫林一号”芯片HX-DS09验证板、4 台PC 机、1 台示波器、2 个网络摄像头和1 台测试仪的真实环境,如图9 所示.网络摄像头1向对应的视频接收端发送视频流(BE1流量),带宽为5 Mbps;网络摄像头2 向相应接收端发送的视频流(BE2流量),带宽也为5 Mbps;测试仪往验证板1 注入3 条ST 流(ST1,ST2,ST3),剩余带宽发送BE3流量.3 条ST 流的流向相同,都先后经过TSN 芯片1、TSN芯片2,最后返回测试仪.实验场景中所有链路带宽为1 Gbps.
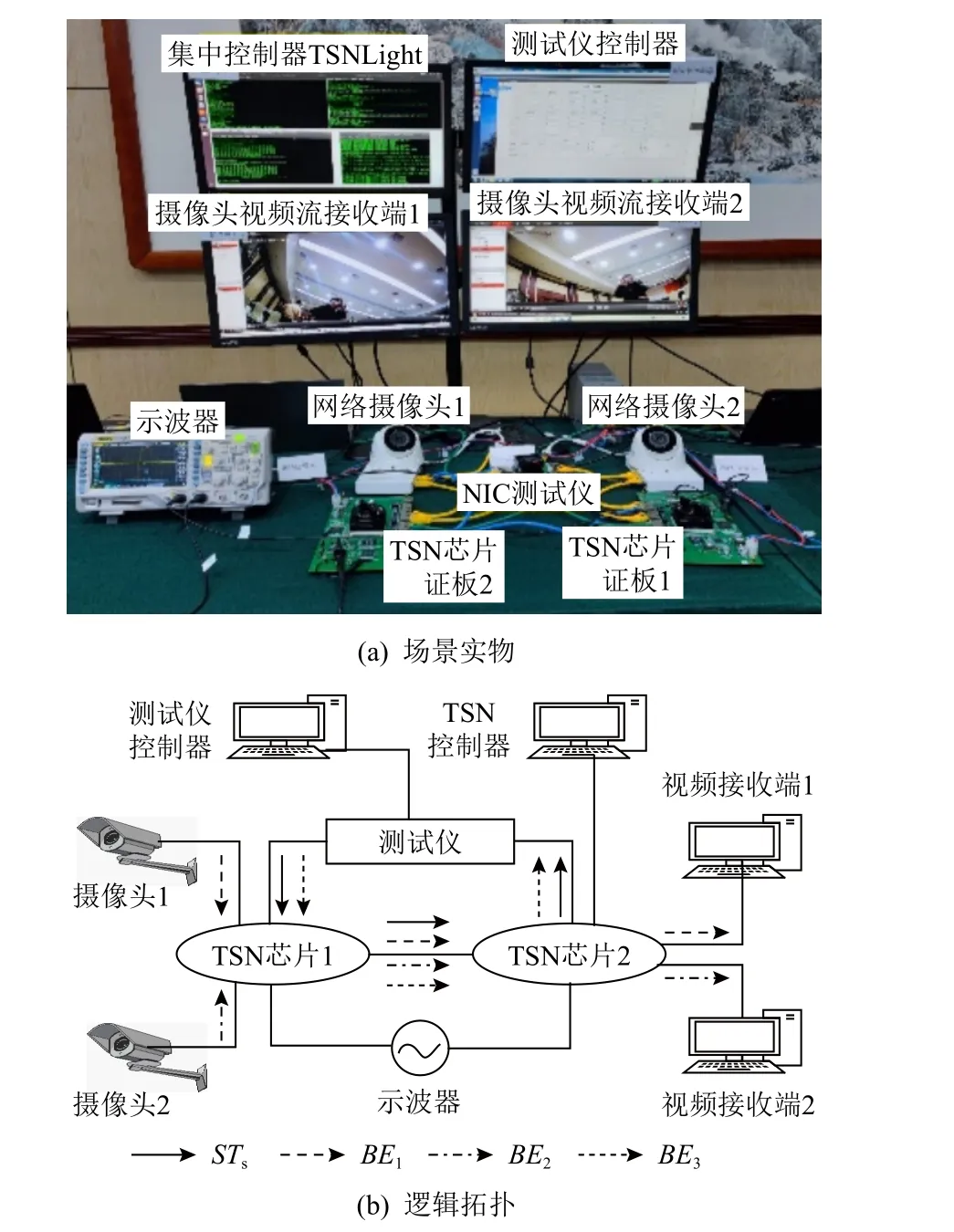
Fig.9 HX-DS09 experiment topology图9 HX-DS09 实验拓扑
每条ST 流的报文长度为128 B,在1 Gbps 链路的传输时间(报文长度/链路速率)为1 μs.而且“枫林一号”将所有长报文切成多个64~128 B 的切片,因此切片对ST 帧确定性的干扰最大为1 μs(=128 B/1 Gbps),进而需要设置1 μs 的保护带.此外,2 块TSN芯片的时钟同步精度时钟维持在100 ns 以内.根据式(1),本实验将时间槽设置为4 μs.
为了降低端到端传输延时,这3 条ST 流在TSN芯片1 中规划在第1 个时间槽(0~4 μs)发送,在TSN芯片2 中规划的发送时间为第2 个时间槽(4~8 μs).本实验在每条ST 流中随机采样100 个报文获取其端到端传输延时.如图10 所示,所有报文的最大端到端传输延时为6.42 μs,其抖动为0.35 μs.这与端到端传输延时的理论值保持一致.

Fig.10 End-to-end transmission delay of HX-DS09 experiment图10 HX-DS09 实验的端到端传输延时
上述关于端到端传输延时的测试结果可证明,nPSA 架构通过降低TSN 芯片的最大交换延时,以允许更小的时间槽,进而实现微秒级或数十微秒级的端到端传输延时.
6 相关工作
由于TSN 标准仅在逻辑层面描述TSN 技术,未对实现相关的交换架构进行规定.因此TSN 芯片采用的交换架构是可以自定义的.目前商用TSN 交换芯片(如BROADCOM 公司的BCM53154,BCM53156,BCM53158 芯片[6])沿用以太网交换芯片中的1PSA架构,其最大交换延时高的特点使其难以适用于对实时性具有苛刻要求的TSN 应用.
优化1PSA 交换架构的目标和以太网芯片中使用直通式交换架构替代存储转发式交换架构的目标不同.直通式交换架构通过消除完整帧写入与读取的过程,降低芯片的最小交换延时[20-21].然而,本文优化1PSA 交换架构的目标是最小化最大交换延时.
文献[22]提出一种基于交叉开关矩阵(crossbar)的分布式共享缓冲区架构(DSB),其通过物理隔离的方式避免多端口帧同时访问同一共享缓冲区,具体为将同时输入的帧映射至不同的缓冲区中进行写入操作,进而消除访存冲突.与nPSA 架构相比,DSB 架构可消除阻塞延时和阻塞缓存.但是多块缓冲区同时写入数据会使芯片的峰值功耗急剧增加.TSN 芯片在许多场景中用于原味替代现有的以太网或总线芯片.在这些场景中TSN 芯片继续使用被替代芯片的电源,这使得高功耗的TSN 芯片难以适用于此类场景.此外由于ST 帧需要按时发送,为了支持较长时间的ST 帧缓存,DSB 的共享缓冲区需要消耗大量珍贵的片上存储资源.因此基于交叉电路的DSB 架构不适用于TSN 芯片.
文献[23]对DSB 架构进行优化,提出一种面向TSN 交换芯片的时间触发交换架构(SMS).该架构对ST 流量和非ST 流量使用单独的共享缓冲区,并且从降低存储资源消耗和提升ST 帧的错误容忍角度设置访存机制.这与本文降低最大化交换延时的初衷截然不同,因此文献[23]的访存机制并不能直接用以指导本文访存机制的设计.
7 总 结
本文面向TSN 芯片针对1PSA 架构中存在的阻塞延时过大问题,提出了多流水线交换架构nPSA.nPSA 架构通过基于时分复用的访存机制保证各流水线超低阻塞地访问集中缓冲区.另外,针对不同应用场景对端口多样性的需求,本文提出了一种加权轮询式时隙分配算法WRRSA,能够快速地为各流水线分配访问集中缓冲区的时隙.最后,通过理论分析和芯片实测,本文对nPSA 架构的性能优点进行了验证,证明该架构及WRRSA 算法在降低最大交换延时和减少资源消耗方面具有显著优势.
作者贡献声明:付文文负责全文框架设计;刘汝霖负责论文撰写;全巍负责实验设计;姜旭艳负责实验实现和分析;孙志刚提出论文构思.
