一种基于持久化栈的返回地址预测器
2023-06-07谭弘泽
谭弘泽 王 剑
(处理器芯片全国重点实验室(中国科学院计算技术研究所)北京 100190)
(中国科学院大学 北京 100049)
分支预测普遍应用于现代CPU 设计,为处理器提供对分支指令行为的猜测,允许处理器并行执行分支之后的指令,从而可提高其指令级并行性,是一项重要而传统的性能优化技术,至今仍受学术界和工业界的关注[1-3].一旦发生错误预测,处理器需要清除其指令执行路径在错误预测后的部分.这些需被清除的部分为错误预测路径,会浪费执行资源和功耗.高准确率的分支预测可在减少功耗浪费的同时保护指令级并行有效性,从而充分释放硬件资源的工作潜力,使处理器获得性能和功耗方面的双重好处.此外,由于超标量技术提升了处理器指令带宽,乱序执行技术需要通过指令调度窗口发挥作用,这些被普遍采用的技术进一步提高了现代处理器对分支预测的准确率要求.
在所预测分支当中,一类特殊的分支为过程返回,由于其返回地址遵循后入先出的顺序,具有高度的可预测性[4].通过对调用栈的模拟,其专用预测器将过程返回与其调用一一匹配,可有效利用其可预测性,从而被称为返回地址栈(return-address stack,RAS)[5].由于仅需按照先验规则匹配返回地址,无需学习有关分支模式的后验知识,该类预测器拥有理论准确率高和存储资源需求小的特点.
实际上,处理器环境限制了过程返回的预测准确率,导致RAS 难以充分利用上述可预测性,所包含4 类限制因素[6]如表1 所示.其中,错误路径指处理器在错误分支后取出的多余指令,可产生对RAS的污染,导致过程返回预测错误.

Table 1 Limiting Factors of RAS Accuracy表1 RAS 准确率的限制因素
1 相关工作
1.1 指 令
RAS 可通过指令识别函数调用并对函数返回进行预测.这依赖于现代指令集架构(instruction set architecture,ISA)在应用程序二进制接口(application binary interface,ABI)中为函数调用和返回定义了标准行为.例如,根据各自的ABI 标准,RISCV[7]、OpenRISC[8]和LoongArch[9]等架构都允许RAS 通过指令识别函数调用并对函数返回进行预测.其中,各架构中指令对应的RAS 操作如表2 所示.本文不增加特殊指令,保证设计可以应用在各架构中.
1.2 功能分类
若按照功能进行分类,RAS 存在分支预测和安全检测2 类应用方向:
1)分支预测方向较为传统,通常保证软件透明性,关注面积资源的利用.此类设计可通过后备预测[10]方法复用间接跳转预测取得性能提升,其涉及文献[4-5,10-14].
2)安全检测方向主要将RAS 用于栈溢出攻击的检测,其涉及文献[6,15-21].在此方向,RAS 需要对比确认栈空间返回地址的完整性.其中,文献[16-21]都使用非猜测RAS,其更新和存储与用于分支预测的RAS相独立.文献[6]通过影子状态寄存器(shadow state register,SSR)的配合实现了同时允许分支预测和安全检测的RAS.SRAS[17](secure returnaddress stack)和RASE[6](return-address stack engine)等设计通过与内存交换数据消除栈溢出和上下文切换问题,但需要操作系统内核支持.
本文主要探讨用于分支预测的RAS,不引入编译器和内核修改,保证设计便于工业界使用.
1.3 存储结构
若根据栈的存储结构进行分类,RAS 包含传统栈和持久化栈[22]2 类:
1)传统栈按照栈深度存储返回地址.当传统栈弹出返回地址后,新写入的返回地址可覆盖其原有的内容,节约存储空间.然而,猜测执行可能导致有效返回地址则被错误地覆盖,从而引起误预测污染.Skadron 等人[12]和Wang 等人[14]提出了对传统栈地址被污染的修复方案,但在面积开销过大的同时仍有性能损失.Sun 等人[13]通过在预测和提交阶段各存储一套返回地址,实现了返回地址修复,但在乱序处理器中无法准确修复返回地址.
2)持久化栈按照进入顺序存储返回地址.与传统栈相反,持久化栈先弹出再写入的新返回地址不会覆盖原先栈顶,而是占用新的存储空间.不同于传统栈,持久化栈的溢出是根据嵌套个数而非嵌套层数,即只要函数调用的嵌套个数超过容量就会发生溢出.Jourdan 等人[11]所提出的设计直接使用持久化栈进行预测,虽然避免了误预测污染,但是遭受了更严重的栈溢出问题.
传统栈和持久化栈可以相互搭配.Park 等人[6]利用SSR 存储对RAS 的修改,从而在允许RAS 使用最新信息的同时避免了误预测污染.
1.4 对 比
表3 总结对比了各RAS 结构的特征,可分为4类问题.

Table 3 Comparison of RAS Structures表3 RAS 结构对比
1)早期RAS 设计[4-5,11-12]受溢出和误预测污染影响,准确率表现不佳.
2)后续RAS 设计[13-14]提高了RAS 的准确率,但对处理器提了更多的限制.
3)文献[6]通过SSR 保证了RAS 准确,但其SSR保存全部飞行指令返回地址的特性要求更大的存储空间.
4)非猜测RAS[16-21]使用独立与分支预测的存储空间,存在信息冗余.
为解决这4 类问题,本文提出了一种基于持久化栈的返回地址预测器——混合返回地址栈(hybrid returnaddress stack,HRAS).HRAS 对处理器不存在如文献[13-14]的限制问题.类似于结合RAS 和SSR[6]的设计,本文结合传统栈、持久化栈和后备预测[10]3 种预测方式,同时解耦传统栈和持久化栈2 部分设计,不必保存全部飞行指令返回地址.在此设计的基础上,本文定量分析返回地址误预测的来源,提出一种RAS 同面积准确率的优化方式.此外,传统栈部分非猜测更新的特性允许与用于安全检测的非猜测RAS[16-21]共用存储空间.
2 HRAS 结构设计
2.1 HRAS 结构总览
HRAS 包含提交栈(retired stack,RS)和猜测队列(speculative queue,SQ)2 个子模块,总体结构如图1所示.HRAS 通过将子模块预测与间接跳转预测相结合.子模块预测通过组合可在及时更新的同时提供精确的错误路径恢复,间接跳转预测缓解了RAS 的容量限制.
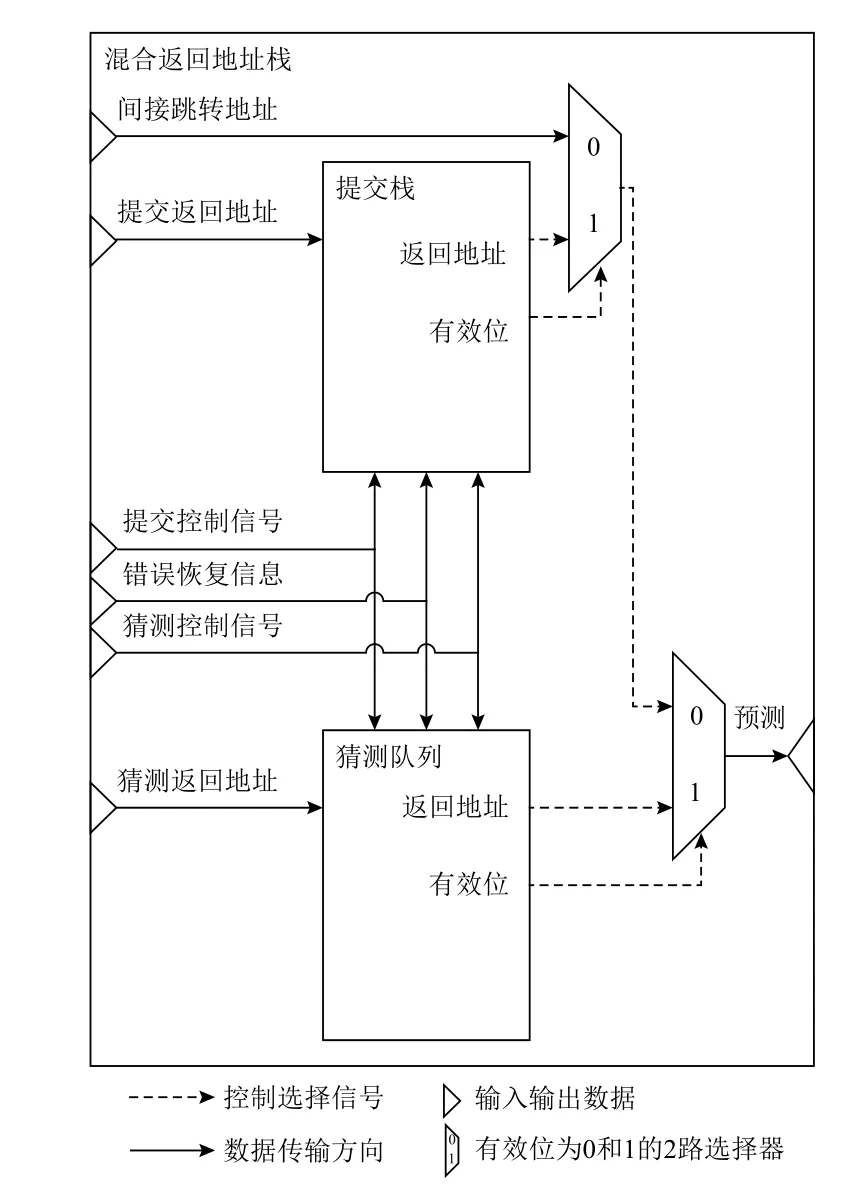
Fig.1 The overall structure of HRAS图1 HRAS 总体结构
HRAS 根据处理器猜测和提交阶段的特点为子模块选择了高效的数据结构.处于猜测阶段的指令可被随时取消.当处理器取消部分指令时,为防止错误路径污染,RAS 需要将栈状态恢复为所取消指令的对应版本.而可持久化栈能以最小的存储空间保留栈的中间版本并通过指针指示当前版本.通过采用这一数据结构,SQ 可通过指针实现栈版本的精确恢复.与此相反,提交阶段的指令总是精确的,不会被取消.根据这一特点,RS 可采用传统栈结构,回收历史版本的存储资源.
2.2 RS
RS 存储已提交返回地址,采用传统栈结构,根据过程的调用和返回加减栈顶指针,通过将更新推迟到提交阶段避免错误路径污染,包含写栈顶(top of stack to write,TOSW)指针、读栈顶(top of stack to read,TOSR)指针、栈底(bottom of stack,BOS)指针、提交表和溢出判断逻辑5 部分,其结构如图2 所示.
为在猜测阶段提供预测,RS 根据猜测控制信号更新选择TOSR 指针,追踪猜测阶段的过程调用栈层次,根据TOSR 指针读出用于预测的返回地址.为清除错误路径污染,RS 根据错误恢复信息或TOSW 指针恢复其TOSR 指针,保证无猜测过程调用或返回时其读写指针相同.只要中间实际执行的指令不会导致溢出,无论内部嵌套的过程调用或返回是否提交、无论中间有无错误预测路径,RS 总能根据TOSR 指针读出正确的返回地址.例如,错误预测路径产生的返回地址D,E被取消,而TOSR 也被恢复到指向返回地址C.此时,无论C是否已提交,只要执行流再次返回到了需要返回地址B的位置,RS 就能根据TOSR提供所需返回地址.
RS 通过溢出判断逻辑检查其指针的相对位置关系,从而检测返回地址的有效性,在SQ 无效的情况下为HRAS 提供用于选择最终预测结果的有效位.栈的最新和最旧有效元素分别由其TOSW 指针和BOS指针指示.其BOS 指针根据栈的溢出和下溢出被相应加减.二者形成的有效区间(BOS, TOSW]表示了有效返回地址范围,可用于溢出判断逻辑,根据TOSR 指针判断返回地址有效性,从而在其失效时,HRAS 可借助间接跳转地址尝试修复返回地址.
2.3 SQ
SQ 存储未提交返回地址,采用支持精确恢复的持久化栈结构,通过增量更新维护了猜测执行中栈的各个版本,避免对旧有数据的修改,包含队尾指针、队首指针、栈顶[11](top of stack,TOS)指针、猜测表和溢出判断逻辑5 部分,其结构如图3 所示.其中,队尾指针、队首指针和猜测表组成一个循环队列,其元素可通过NOS 指针链接为单向链表,而其TOS 指针指向链式栈的当前栈顶.

Fig.3 The structure of SQ图3 SQ 结构
由于猜测表仅存储未提交返回地址,其循环队列元素的生命周期从进入猜测执行开始到退出猜测执行结束.在收到猜测过程调用信号时,为存储新的猜测返回地址,SQ 分配新的结点并将之入队,即在将队尾指针加1 的同时,将结点写入原队尾指针指向的表项.由于指令提交时顺序和取指时相同,结点遵守先入先出的顺序,从而,当收到提交过程调用信号时,SQ 通过将队首指针加1 依次令队首结点出队.此外,当复位或例外等事件发生时,由于处理器不再有任何未提交的指令,SQ 清空其循环队列.
循环队列中的链式栈表示了逻辑RAS,通过TOS指针指示其栈顶,可提供用于预测的返回地址.在取指阶段,当过程调用时,SQ 创建新的结点,并将TOS指针指向该结点.其NOS 指针指向原栈顶,即原TOS 指针所指.而当过程返回时,SQ 可根据TOS 指针读出当前栈顶结点并将其返回地址用于预测,为实现弹栈操作,仅需将其TOS 指针指回其读出的NOS 指针.例如,若SQ 中当前链式栈栈顶返回地址为D,而新的猜测返回地址为E,则其新建结点存储返回地址E和指向D所在表项的指针&D.此后,过程返回可将新结点的NOS 指针&D重新恢复到其TOS 指针,从而重新读出正确的返回地址D.在弹栈后,SQ 队尾不变,栈顶返回地址恢复为D.
SQ 在队列中分配结点,通过指针链接栈结构,实质上是一种持久化栈结构,可通过指针精确恢复其状态,无需恢复其猜测表数据,可节约功耗和硬件复杂度.作为持久化栈,SQ 可通过TOS 指针访问栈的中间版本,使得其找回逻辑栈版本只需恢复TOS指针.与此同时,为保证取指时进入SQ 的返回地址可在提交时按序退出,通过在分支误预测后恢复队尾指针,该设计可回收队尾的无效结点.以图3为例,猜测表通过4 个结点分别表示了(D),(E,D),(F,D),(G,F,D)4 个版本的逻辑栈.若从当前状态取消1 次弹栈操作,SQ 仅需将TOS 指针从&F恢复为&G.从而,其逻辑栈内容会被从(F,D)恢复为(G,F,D).又如,若从当前状态取消2 次压栈操作,SQ 仅需在恢复TOS 指针的同时再将队尾指针从&G后恢复为&E后.
应该借这辆车,能多装人。北美洲多米尼加警察巡逻时发现一辆可疑车辆,命令所有乘客下车。这个过程让所有人大吃一惊,一辆小小的轿车乘坐了18个人,而世界纪录才17人!
为提供返回地址的选择依据,SQ 通过溢出判断逻辑计算有效位.其队尾指针和队首指针分别指示了循环队列的队尾和队首,标记了其有效区域.有效位有效即TOS 指针位于循环队列有效区域,可表明所读出返回地址尚未被提交.其中,猜测表项数无需超过其有效区域最大项数,即处理器猜测执行的分支指令容纳数量.然而,当猜测表项数较少时,循环队列新分配的队尾元素可能覆盖队首元素,导致返回地址失效.为检测此类溢出,SQ 可通过额外引入的Max 指针[10]记录SQ 队尾的覆盖位置,并在栈顶处于被覆盖但尚未被提交的情况下无效化RS 的预测.
2.4 HRAS 结果选择
HRAS 最终预测结果选自SQ、RS 和间接跳转预测器3 处.其选择根据预设优先级和子模块判断的有效性.如果SQ 的返回地址有效,那么当前栈层次的最新返回地址就是SQ 的返回地址,从而选择逻辑会优先使用来自SQ 的返回地址;否则当前栈层次的最新返回地址已提交,从而选择逻辑需要从RS 获取返回地址.然而,当二者无法提供有效的返回地址时,选择逻辑使用外部的间接跳转地址作为补充.
利用选择逻辑,HRAS 可通过猜测和提交2 阶段更新信息相互补充,结合传统栈、持久化栈和间接跳转预测器3 种结构的优点准确预测返回地址.猜测更新具有及时性,但需要栈支持版本恢复.借助于持久化栈结构,通过留存猜测阶段指令执行窗口中可被恢复的返回地址,SQ 支持了对栈的恢复.注意到指令一经提交则不再会被取消,RAS 不再需要栈的历史版本,其额外留存返回地址的特性会浪费存储空间.利用提交阶段的更新信号的准确性,RS 避免了对可恢复性的要求,从而可以采用更加紧凑的传统栈结构.此外,当容量不足导致HRAS 失效时,间接跳转预测器可根据失效的返回指令地址补充预测,从而缓解深层次过程调用返回的HRAS 失效.
3 实验及数据分析
3.1 实验配置
本文性能评估工作基于EVE(emulation verification engineering)仿真加速器.其中,EVE 仿真加速器是新思科技公司旗下一款硬件验证仿真加速平台,已被全世界重要的半导体和电子系统公司所采用,可通过挂载文件系统在操作系统中运行若干中小型测试程序[23].该平台可搭载DDR3(double data rate 3)-1000双通道内存,仿真一款商业CPU 核心,启动Linux 操作系统并运行基准测试,从而准确地反映处理器结构和操作系统行为等实际因素对返回预测的影响,并保证仿真时间可控.
该商业CPU 核心基于LoongArch 指令集,其基本配置如表4 所述,可为本设计提供真实的处理器核环境.

Table 4 Basic Configuration Simulated by EVE表4 EVE 仿真基础配置
为反映实际应用负载中返回地址的预测准确率及其对性能的影响,本文选择标准性能评估公司(Standard Performance Evaluation Corporation,SPEC)CPU 2000 基准测试,在真机上预先编译其所有基准测试程序.所用编译器版本为GCC(GNU compiler collection)8.3.0.所用编译选项统一为“-Ofast -static”.为节约测试时间,本文主要对比其中过程返回次数最多的9 个基准测试.如无特殊说明,下文中平均返回误预测率均指以上9 个基准测试过程返回每千条指令误预测(mis-predictions per kilo instructions,MPKI)的算术平均值.
为评估获取各个基准测试程序的运行时间和返回MPKI,本文通过perf 工具获取了运行时间、动态指令数、过程返回次数和过程返回误预测次数等性能事件计数.其中,perf 是Linux 操作系统下的一款众所周知的性能分析工具,其基于处理器硬件计数器.
基于上述评估平台,本文测试了实际场景中的RAS 的MPKI.
3.2 重要性分析
本节分析实际系统运行测试时返回MPKI 对性能的影响,从而说明返回预测对处理器性能的重要性.
图4 分析了返回MPKI 对处理器每周期指令数(instructions per cycle,IPC)的影响,显示了返回地址预测对性能的重要性.其中,为了分析从包含随机因素的数据中提取RAS 结构设计对性能的统计影响,该分析采用了线性回归法.实验表明,当返回MPKI值在0.2 以内时,返回MPKI 值每增加1 可为该处理器的每周期指令数带来约0.07 的损失.即平均每次误预测约消耗23 个时钟周期,其平均延迟明显大于流水线深度.由于乱序处理器中返回指令前后的其他指令存在并行性,分支误预测的实际性能损失除分支的执行延迟外,还包含所破坏的并行性.若设计在误预测时检测栈溢出攻击,每次返回误预测的开销可达500 个时钟周期[16].
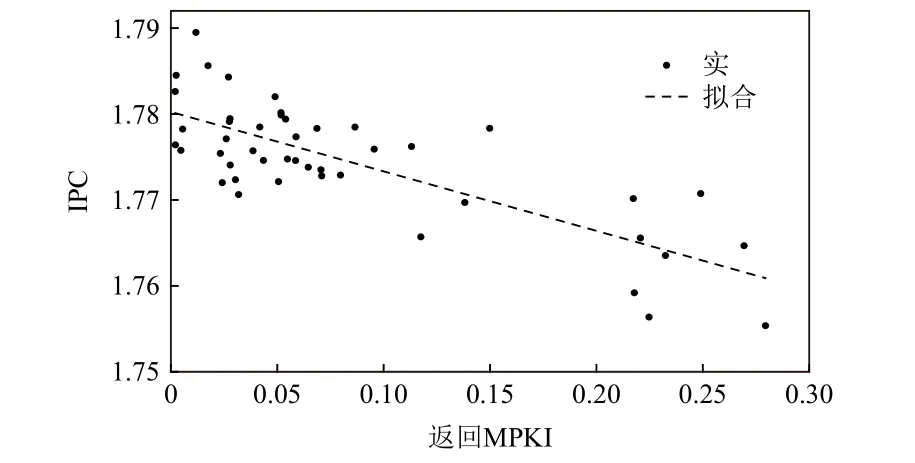
Fig.4 IPC comparison on different return MPKI values图4 不同返回MPKI 值的IPC 比较
3.3 性能分析
首先,本节对函数返回进行分类,提出一种返回误预测的分解方式.然后,本节评估了RS 项数和SQ项数分别对2 类函数返回误预测的影响.最后,本节验证了所提分解方式并优化了HRAS 的等面积性能.
函数返回指令可根据其对应调用指令提交的时间顺序分为长距离和短距离2 种延迟类型.其中,长距离返回指直到对应调用指令提交后才需要进行预测的返回指令,短距离返回反之.在本设计中,长、短距离返回分别需要由RS 和SQ 进行预测.若忽略返回地址预测对返回指令延迟类型的影响,各返回指令可被固定划分为长、短距离返回,从而其误预测率MRS与MSQ分别只与RS 和SQ 的项数NRS和NSQ相关.因此,HRAS 的总误预测率M近似分解为误预测率MRS与MSQ之和,有
为提高等面积性能,HRAS 需要为SQ 和RS 合理分配存储空间,使得总项数NRS+NSQ一定时总误预测率M最低.根据式(1)分解关系,本文可分别测试RS 项数和SQ 项数与误预测的关系,并以此计算出最小化总误预测率的项数取值.
在RS 项数固定为32 的情况下,图5 对比了不同SQ项数的返回MPKI 值.测试结果显示,SQ=8 时即可正确猜测实际测试中的短距离返回,而项数更小的SQ 会开始产生误预测,并在项数减少到4 时产生的MPKI 值为0.05.因此,根据评估结果,即使每4 条飞行分支指令共享1 项猜测表,SQ 都能给出正确的预测结果.相比为每条分支指令存储1 个返回地址的设计[6,12,14],该设计只需25%的存储空间.
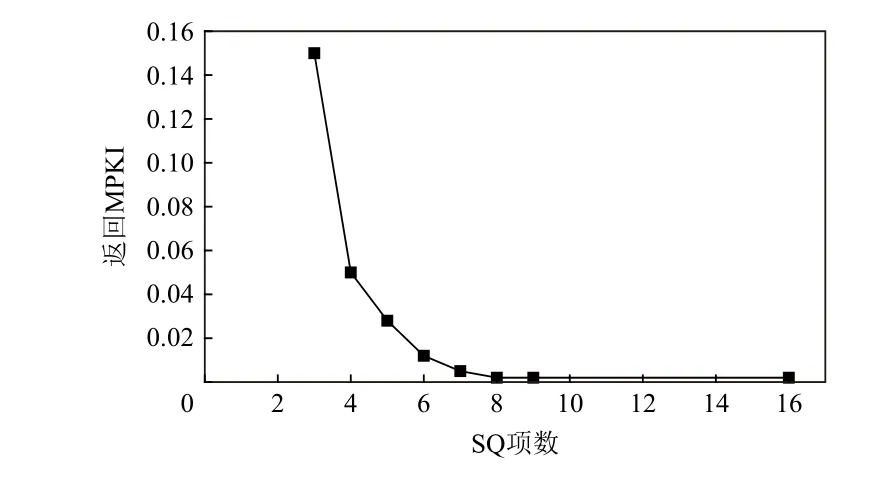
Fig.5 Return MPKI values comparison on different numbers of SQ图5 不同SQ 项数的返回MPKI 值比较
在SQ 项数固定为16 的情况下,图6 对比了RS不同项数的返回MPKI 值.结果显示,RS 项数的增加可有效抑制栈溢出,其返回MPKI 值在项数为32 时可降至0.002.
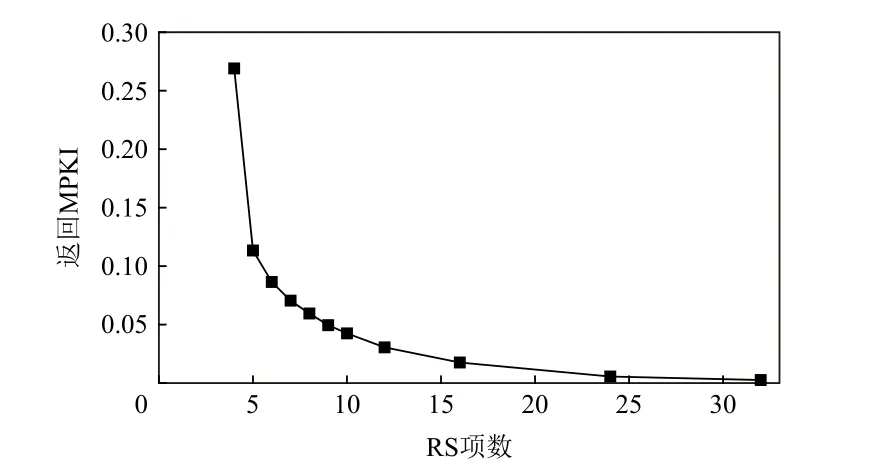
Fig.6 Return MPKI values comparison on different numbers of RS图6 RS 不同项数的返回MPKI 值比较
配合图5、6 的数据,本文通过测试其他配置的MPKI 验证了式(1)的分解关系.实验表明,在所测范围内,其预估的MPKI 值相比于实际的MPKI 值误差小3%,远小于项数变化带来的MPKI 变化,适用于项数配置的选取.进而,本文估计了使得MPKI 值最低的存储项数配置并验证了其MPKI 符合预期.所得各规模HRAS 中RS 和SQ 的最优配置如表5 所示.

Table 5 Best Configures of RS and SQ on Different Sizes of HRAS表5 各规模HRAS 中RS 和SQ 的最优配置
为进一步分析HRAS 产生误预测的原因,本文对仿真加速器波形进行了离线分析.结果表明,所测系统在时钟中断时的上下文切换会污染RAS.若要消除此类误预测,RS 需要独立存储内核和用户的返回地址.鉴于此类误预测的MIPKI 值已经不足0.001,本文没有分离内核和用户的返回地址存储.
3.4 性能对比
本节将HRAS 与已知设计进行了性能对比.根据该处理器的条件,在现有设计中进行了筛选.SCRAS相比CTRAS,同面积时MPKI 值更高[10],无需重复测试.由于本处理器集成时的适配问题,本文也不测试其他设计.HRAS 存在的问题为:
1)文献[13]要求处理器顺序执行分支指令;
2)文献[14]要求处理器支持暂停取指的功能;
3)文献[6]要求操作系统内核支持;
4)文献[16-21]不适用于分支预测.
综上所述,在本商用处理器核中可用的SOTA 方案包括搭配了后备预测[10]的简单RAS[4-5]和CTRAS[12]2 种设计.本文根据文献描述对其进行了实现.
图7 对比了HRAS、简单RAS 和CTRAS 在项数同为32 时的返回MPKI.在全部SPEC CPU 2000 基准测试中,254.gap 是过程返回预测最为困难的测试.在该测试中,HRAS 的MPKI 值仅为0.01,相比其他预测器降低了90%以上.综上所述,HRAS 可有效利用过程返回的可预测性,在任何测试中均比现有RAS 设计具有更高的等面积准确率.
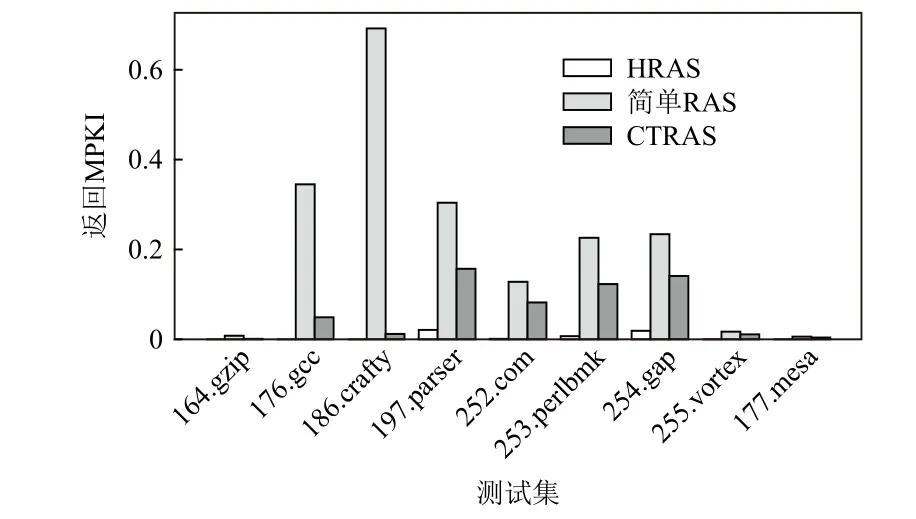
Fig.7 Returning MPKI values comparison among different RAS implementations图7 各RAS 实现的返回MPKI 值比较
根据设计编译器的时序检查,RAS 设计均不影响处理器的时序关键路径,不会限制所测处理器的主频.这主要基于访问延迟和流水线结构2 方面因素.在访问延迟方面,HRAS 与其他可用现有方案一样可并行进行溢出检测与返回地址读取,且相比处理器中物理寄存器堆等其他结构延迟明显较小;在结构方面,RAS 可提前将栈顶返回地址锁存到寄存器中用于预测,使得其访问延迟不影响外部结构.
3.5 开销对比
为准确评估RAS 电路实现的面积,假设其目标频率为2.0 GHz,基于设计编译器(design compiler, DC)以28 nm 工艺综合了简单RAS、CTRAS-1、CTRS-2和HRAS,并进行了面积评估.而所评估项数介于8~32 之间,为处理器中的典型项数[10].
图8 对比了多种RAS 设计在不同面积配置下的MPKI.其中,HRAS 采用如表5 的最优配置.在面积约为4.5×103μm2时,HRAS 相比于简单RAS,MPKI可降低约52%.在面积约为1.1×104μm2时,HRAS 相比简单RAS 和CTRAS,MPKI 可分别降低约99%和96%.对比结果表明,HRAS 在相同面积下具有最高准确率.
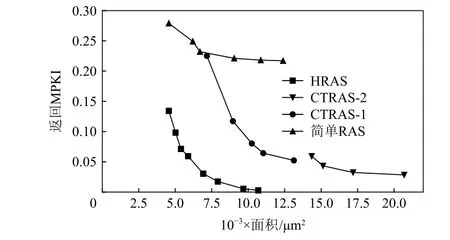
Fig.8 Return MPKI values comparison on different areas of RAS implementations图8 各RAS 实现在不同面积配置下的返回MPKI 值比较
相比现有设计,HRAS 具有更好的可扩展性.由于更激进的现代乱序处理器可容纳多达100 条分支,设计应尽量减少每条分支固定的存储开销.HRAS 对处理器检查点的存储需求与简单RAS 相近,无需为每条分支存储返回地址,可避免在处理器规模扩展时引入过多硬件资源开销.此外,由于RS 在提交时更新的特性,可以与用于栈溢出攻击检测的RAS[16-21]共享存储空间.
相比现有设计,HRAS 在同等准确率时系统开销更小.相比文献 [13],HRAS 无需限制处理器分支指令的执行顺序,适用于现代的乱序处理器.相比文献 [14],HRAS 避免了多周期修复带来的额外阻塞控制,简化了处理器的设计要求.相比文献 [6],HRAS由纯硬件实现,无需操作系统支持,相比本研究所用处理器的取指模块,即使将返回MPKI 降至0.01 以下,HRAS 仍仅需其面积的4%.
相比其他设计,HRAS 在功耗方面没有明显缺点.由于分猜测和提交2 阶段存储,HRAS 在每次过程调用时需要2 次写,而在每次过程返回时需要同时读2 张表.相比于简单RAS,HRAS 虽然增加了动态功耗,但是其带来的准确率提高能够降低整个处理器核在错误路径上所消耗的能量.相比于CTRAS,HRAS 将对处理器检查点返回地址的读写换为了对SQ 的读写,不会增加动态功耗.
以上分析和DC 评估实验的结果表明,HRAS 在同准确率时面积最小,同面积时准确率最高,且具有可扩展性.
4 总结与展望
本文提出了一种混合返回地址栈(HRAS),其基于可持久化栈实现了精确恢复,结合传统栈结构实现了高效的返回地址存储,并基于实际的处理器核和操作系统测试环境对其进行了评估.结果表明,该返回地址栈可消除错误路径污染,从而充分利用过程返回的可预测性,在1.1×104μm2的设计面积下相比现有RAS 降低96%的返回误预测,同面积每周期指令数相比带后备预测的简单RAS 可提升1%.
作者贡献声明:谭弘泽负责全文的设计和实现,以及文章的撰写和修改;王剑提出指导意见.
