一种基于多特征融合与压缩激励模型的音乐主旋律提取算法
2023-06-07何丽刘浩
何 丽 刘 浩
(北方工业大学信息学院 北京 100144)
0 引 言
音乐信息检索技术(Music Information Research,MIR)是用计算机技术对数字音乐进行处理的一系列技术方法,其中的研究方向之一是对音乐旋律提取。音乐旋律提取技术可以应用在音乐分析[1]、音准分析[2]和模式分析[3]等场景中。
随着技术的发展,深度学习技术在自然语言处理、视频及图像处理领域都取得了十分显著的成果。Lu等[4]结合了文献[5-6]的方法,将图像语义分割模型引入到音乐旋律提取问题中。结果表明此方法可有效降低虚警率,在一些数据集上接近最佳性能。
目前,很多研究将传统的声学特征与深度学习结合使用。色度特征是一种表示音级的特征,在音乐的和弦检测中有十分重要的作用。梅尔倒谱系数是一种表示人声的特征,广泛应用在自动语音识别中。以上两种特征可以有效地表示音乐主旋律的音级和流行歌曲中的人声旋律。
本文以文献[4]为基线,使用Segmentation模型,将梅尔倒谱系数和色度特征以多通道的方式融入原始数据中,使输入数据包含音级和人声信息。实验表明,加入特征后模型训练的收敛速度加快。此外,本文使用元数据集70%的数据就可以接近基线的效果。为了学习不同特征的权重,本文将压缩激励模型加入到Segmentation模型中。实验表明,加入SEBlock的多特征融合模型相比基线有1.1%的整体准确率提升。同时相比无SEBlock的多特征融合带来1.5%的虚警率下降。
1 相关工作
目前,深度学习的方法在音乐信息检索研究中的比重逐渐增加,很多研究采用了传统声学特征和深度学习技术结合的研究方法。
传统旋律提取的算法通常是基于信号对音频信号进行分析,通过挖掘不同的特征以提升音乐旋律提取的效果,例如音高显著度计算[1]是通过音高显著度函数追踪并定位主旋律。一些研究从数据处理入手[8-9],包括加强旋律的分量[8]、减少伴奏分量[9]等。另外,文献[10-13]提出计算旋律泛音振幅的加权和,文献[14]通过检测泛音的显著度计算主基频。
用于该领域的深度学习技术主要为深度神经网络(DNN)和卷积神经网络(CNN)。Choi等[2]利用深度神经网络学习到半音级别的特征,在此基础上对频谱图进行针对音高的波峰识别。该文献中搜集了大量易于获取的MIDI文件进行数据转换作为训练数据的扩充,希望解决训练数据不足的问题。文献[6]中,利用了目标跟踪检测的方法,搭建了patch-based CNN结构,解决了CNN模型中细粒度较大的问题。Lu等[4]用大量MIDI文件训练渐进神经网络(PNN),再对segmentation模型做迁移学习。该方法可有效降低虚警率、提升召回率(VR),但准确率提升较小,并且需要额外的数据处理及模型融合操作,效率略低。本文以Segmentation模型为基线,提出了融合了Chroma Feature和MFCC的主旋律提取算法,并在模型中加入SEBlock提升训练效果。
2 多特征融合与压缩激励模型的音乐主旋律提取算法
2.1 多特征融合
2.1.1原始数据表示
原始数据使用GC特征,GC是一种基于时间序列的音高检测数据特征[14-18],GCOS特征改变了频率在GC中的比重[19]。GC和GCOS是两种互补的特征:GC关注基础频率和复调频率;GCOS表示的是基础频率和自频率。GC和GCOS可通过傅里叶变换和非线性激活函数计算得到。计算过程如下:

(1)
(2)
(3)

(4)
式中:n代表时间;k、q代表时刻n的音频频率;X表示经过STFT计算的音频信号;F表示DFT矩阵;Wf和Wt表示两个高通滤波器;ReLU()是一个线性修正单元,本文设置参数(γ0,γ1,γ2)=(0.24,0.6,1)。
GC与GCOS相乘作为本文的原始数据,过程如式(5)所示。
(5)

(6)
ftri=4(flog-21)
(7)
为了便于计算,本文将频率转化为对数频率(式(7)),再通过352维的三角滤波器(Triangular Filters)(式(6))将频率控制在27.5 Hz到4 487 Hz之间。
2.1.2色度特征
文献[21-22]中详细地阐述了音频的色度特征的计算过程。Chroma Feature主要表示为色度向量(Chroma Vector)和色度图(Chroma Gram)。色度向量表示的是在一个时刻对应的音级;而色度图是将色度向量按时间排列,组成的二维图像。
Chroma Feature的求解过程如图1所示,首先将原始数据转化至频域,再进行数据预处理,之后进行曲调计算和音高显著度计算,再对数据进行归一化,最后对数据进行平滑处理得到色度图。本文使用librosa工具生成色度图。通常色度向量的维度设置为12,本文为将色度特征数据与GC和GCOS进行数据对齐,将Chroma Vector的维度定为352维,即提升了色度图对音级表示的密度。

图1 Chroma Feature的求解流程
2.1.3梅尔倒谱系数
梅尔倒谱系数是一种广泛应用在自动语音识别和说话人识别中的特征。文献[23]详细描述了MFCC的计算过程。加入MFCC可以更好地提取包含人声的旋律,对于流行音乐的音乐特征提取有积极作用。本文针对训练需要,进行了数据对齐操作,将MFCC调整至352维。MFCC将按照如下过程计算。
1) 预加重。预加重的作用是补偿高频分量、提高音频的高频分辨率,本质是用高通滤波器对信号进行滤波。函数如下:
(8)
x′=x(n)-∂x(n-1)
(9)
式中:Z{x(n)}表示原始音频信号变换到Z域的信号;Z{x′(n)}为预加重后音频信号x′(n)变换到Z域的信号;n代表时间点;∂表示预加重因数。
2) 分帧。将信号按固定长度划分,每段信号长度约为20 ms至30 ms。
3) 加窗。为提高每帧音频信号左右连续性,对分帧后的信号进行加窗操作,本文使用的是汉明窗(Hamming Window)。
(10)
4) 快速傅里叶变换。对时间窗内的信号做快速傅里叶变换(FFT)将时域信息转换为频域信息,得到的信号如下:
对于高校的篮球运动的体育教师来说,他们本身是教师,因此常规上课内容是不能被忽视的,在这样的情况下如何协调好运动训练和文化教育的关系尤为关键,既不能一直教学篮球,也不能过于拖泥带水。高校应该从实际的角度出发,探讨运动训练和文化教育融合的良好途径,切实根据不同学生的情况来进行针对性的文化教育。
(11)
式中:m=0,1,…,N-1。
之后计算能量谱e(m):

(12)
5) 计算对数能量。经过以上步骤,梅尔滤波器组会计算各通道能量。
(13)
式中:M是Mel窗口数量;Wi(j)为第i个通道的三角带通滤波器。
(14)
6) 对数和余弦变换(DCT):
(15)
式中:k=1,2…,D,D是特征向量的维度。
上述Chroma Feature和MFCC的提取过程均需要进行短时傅里叶变换以及音频采样,本文的详细参数如表1所示。

表1 采样参数
2.2 融合压缩激励模型的卷积神经网络
2.2.1DeepLabV3
Segmentation模型[4]是基于DeepLabV3[24-25]实现的,该模型目前在语义分割任务中取得了显著的效果。模型采用了基于卷积神经网络的编码器-解码器(Encoder-Decoder)结构,如图2所示。图2中Encoder部分使用了残差模块(ResNet)。DeepLabV3的特点是使用了空洞卷积(Dilated Convolution,Dilated Conv)和金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)。空洞卷积如式(16)所示,相比最大池化(Max Pooling)可以扩大感受野,并且不会损失信息。
(16)

图2 DeepLabV3
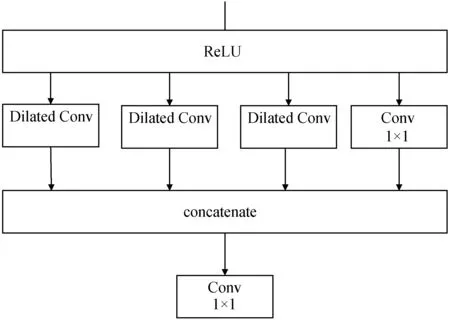
图3 金字塔池化层
金字塔池化结构如图3所示,该结构可以解决空洞卷积在高采样率下有效权重变小的问题。残差模块如图4所示。

图4 残差模块
2.2.2压缩-激励模型
压缩-激励网络(Squeeze-Excitation Network,SENet)[26]是将注意力机制作用在图像的通道(Channel)上,即学习到不同特征的权重。整体结构如图5所示,SENet核心是压缩-激励模块(Squeeze-and-Excitation Block,SEBlock),过程分为压缩(Squeeze)和激励(Excitation)两步。输入如式(17)、式(18)所示。
Ftri:X→U,X∈RWt×Ht×Ct,U∈RWt×Ht×Ct
(17)
式中:Ftri代表原网络,在本文中对应残差模块。
(18)
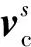

图5 压缩-激励机制
(1) 压缩模块。在经过SEBlock转换之后,各个数据单元不能利用单元以外的纹理信息。压缩全局空间信息,得到一个通道描述器可有效避免该类问题。在本文中此步骤对应全局池化操作。
(19)
(2) 激励模块。本文的Excitation对应两个全连接层。式(19)代表全连接操作,W1维度是C/r×C,r为特征缩放参数,该步骤的目的是减少通道数量降低计算量,本文将r设为16。式(20)代表对W1使用ReLU函数。式(21)代表全连接层,W2的维度是C×C/r,将特征图还原成原始维度。
经以上计算得到权重张量。输出数据经过Sigmoid函数进行归一化。最终将权重作用在原数据上需要矩阵相乘。
zc=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(20)
式中:g表示W2δ(W1z)计算过的中间函数,δ表示ReLU函数。
Xc=Fscale(uc,sc)=scuc
(21)
本文在模型encoder部分的残差模块中都加入了SEBlock,结构如图6所示。实验表明该机制可以提升模型准确率,并降低虚警率(VFA)。

图6 SEBlock
3 实 验
3.1 数据集
本文选择MIR1K作为训练数据集,该数据集包含了1 000个中文流行歌曲的片段。在特征提取时,本文对音频进行了采样操作,因此标签也需要与采样后的音频对齐。本文将训练数据的70%作为训练集,剩余的30%作为测试集。
测试数据方面,本文选择了ADC2004和MIREX05数据集。MIREX05数据集包含了13个音乐片段,风格包括流行音乐和纯音乐。ADC2004包含了15个音乐片段,风格包括纯音乐、歌剧等。
3.2 评价标准
旋律提取的任务主要有两个:
1) 估计旋律的音高。当预测值和参考值的差值在0.5个半音之内,则认为旋律音高估计正确,反之则认为旋律音高估计错误。
2) 旋律活动检测,判断当前帧是否为旋律帧。
旋律检测任务的评价指标如表2所示,其中:GU表示参考结果的非旋律帧;GV表示参考结果的旋律帧;DU表示检测结果中的无旋律帧;DV表示检测结果中的旋律帧;TF表示非旋律帧被正确检测的数量;FN表示有旋律帧错误检测的数量;TP表示旋律帧正确检测的数量;FP表示无旋律帧错误检测的数量;TPC表示旋律帧音高正确检测的数量;FPC表示无旋律帧音高错误检测的数量;TPCch表示旋律帧音级正确检测的数量;FPCch表示无旋律帧音级错误检测的数量。

表2 评价指标
3.3 实验设计
为验证本文方法对音乐旋律提取的效果有积极作用,并且可以减少训练数据、缩短训练时间,实验设计如下:
1) 使用Segmentation模型,在特征提取的步骤中分别加入Chroma Feature、MFCC,再将二者同时加入,使用Segmentation模型分别进行训练。
2) 在Segmentation模型中的每个残差模块加入SEBlock。之后在特征提取的步骤中分别加入Chroma特征、MFCC再将二者同时加入,使用加入SEBlock的Segmentation模型分别进行训练。
3) 使用70%的数据训练,对比多特征融合模型、Segmentation模型的性能。
本文采用的对比算法为:MCDNN算法[27]、Patch-CNN[19]、DSM[28]、MD&MR[29]算法。其中,Segmentation算法[3]为本文的基线研究,将作为本文添加Chroma和MFCC特征以及引入SEBlock的有效性的基准对比。本文使用的平台是1080Ti,32 GB的RAM,Centos7操作系统,Python 3.6,MATLAB 2019。深度学习框架为Keras,以TensorFlow 1.6作为后台。音频数据处理使用librosa工具,实验结果评估使用mir_eval工具。
3.4 实验结果分析
1) 特征融合对训练数据量及训练速度的影响。本文在加入MFCC和Chroma Feature后,用原训练集的70%进行训练。实验结果如表3所示,在MIREX05数据集上,各项指标接近使用全部训练集训练的Segmentation模型。OA和RPA下降在1百分点以内,而VR下降了1.4百分点,VFA上升了3.8百分点,RCA相比基线模型反而上升了0.2百分点。在ADC2004数据集上,RCA下降了0.8百分点,其他指标降幅均在1.5百分点以内,OA降幅达到2.2百分点,VFA上升4.2百分点。由此可见,加入MFCC和Chroma Feature后,在准确率方面可以用较少的数据达到接近基线准确率的效果。

表3 加入多特征后用70%的训练数据与基线模型
特征融合还有利于提升训练速度。如图7、图8所示,加入MFCC和Chroma Feature后收敛速度明显提升。
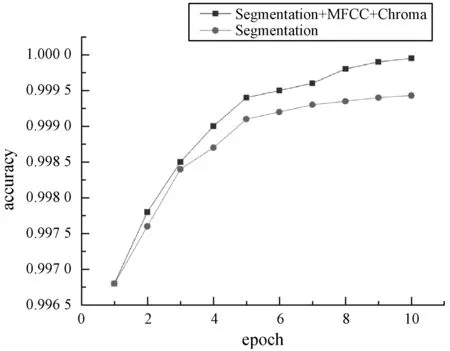
图7 准确率收敛曲线

图8 损失函数收敛曲线
2) 特征对各评价指标的影响。根据表4、表5中的结果,本文方法对MIREX05数据集提升较大。加入MFCC对OA和RCA提升效果较弱,与Segmentation的结果基本一致,RPA提升了0.9百分点。RPA用于判定音高准确度,而MFCC作为一种人工设计的声学特征,主要用于人声的语音识别,所以对于带有人声的音频更为敏感,对流行音乐的音高识别也会更准确。
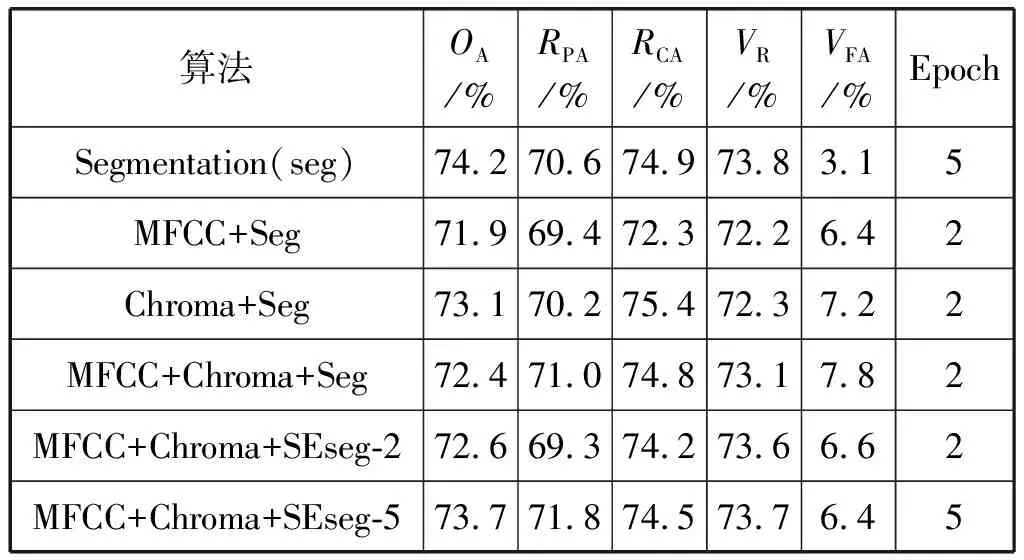
表4 ADC2004

表5 MIREX05
加入Chroma Feature对RPA和RCA有一定的提升。其中RCA相比基线提升了1.1百分点。因为Chroma Feature本身就是关于音度的特征,RCA同样是用于评判音度准确率的标准。此外,Chroma Feature常用于和弦检测,对音高的识别也有一定帮助。Chroma Feature有一个潜在的风险,该特征可能对伴奏旋律同样敏感,从而影响对主旋律的提取。
同时加入MFCC和Chroma对OA仅有0.3百分点的提升,RCA增幅达到1百分点。
3) 与其他方法的对比。本文使用了实验效果较好方案:同时加入MFCC、Chroma和SEBlock的方案与其他方法进行对比。
本文对比的几种方法为:MCDNN算法[27]、Patch-CNN[19]、DSM[28]、MD&MR[29]算法。上述四种方法皆为近五年较为先进的方法。从表6中可以看出,本文方法在VFA、OA上有一定的竞争力,其中OA和结果最优的方法相差2百分点以内。相对于发表时间相对较早的Patch-CNN、DSM、MCDNN在ADC2004数据集获得了0.6百分点至2.9百分点的优势。而VFA的效果较好,除MD&MR以外,在和其他方法的比对中展现出了较为明显的优势。然而这种优势得益于本文继承了基线研究Segmentation算法的部分思路,该算法的一大优势就是大幅度降低VFA。

表6 方法对比ADC2004
其余的指标中,RCA、RPA、VR指标与其他方法的差距在于Chroma特征和MFCC特征结合的方式。本文将处理好的Chroma和MFCC特征直接与网络得到的特征图进行叠加并输入到SEBlock模块中,三者在特征描述方面并未做到对齐,从而影响了实际效果。
MD&MR(Multi-Dilation and Multi-Resolution)为最新的一种音乐主旋律提取算法,模拟了人耳识别主旋律的过程,将提取过程最终转换为低层特征与高层特征提取并结合的方式。如表7所示,在MIREX05数据集上OA、RPA、RCA、VFA均取得最高分。其中特征融合的方式也是值得本文学习的一点。

表7 方法对比MIREX05
以上实验证明多特征融合对提升模型效果有积极作用,在某些指标上可以接近一些先进方法,但相比于目前最新的方法仍然存在明显差距。
4) SEBlock的影响。如表4、表5所示,最终本文在多特征融合后的模型中加入SEBlock,效果有所下降,这是因为加入SEBlock的模型需要更长的训练时间。因此本文将训练时间延长至5个周期。效果优于无SEBlock的多特征融合模型。在MIREX05上的测试结果比基线的OA提升1.1百分点。此外,在同时拥有MFCC、Chroma的情况下加入SEBlock后比无SEBlock的VFA下降1.8百分点左右。
综上所述,在MIREX05数据集上,加入MFCC和Chroma Feature可以提升Segmentation模型的OA、RPA、RCA。加入SEBlock后可以进一步提升上述三个指标,并且可以降低VFA,但VFA仍略高于基线。在ADC2004数据集上本文方法可以达到与基线接近的效果,因为该数据集中有大量的歌剧类的音频,而本文的训练集全部为流行音乐。
4 结 语
本文主要研究多特征融合与SEBlock在音乐旋律提取任务中的作用。为提升音乐旋律提取效果,本文使用Segmentation模型,在原始数据中加入了MFCC和Chroma Feature,又在此基础上加入了SEBlock进行训练。实验结果表明,在MIREX05数据集的测试中,加入MFCC和Chroma Feature对结果都有一定的提升,并且可以只用70%的数据达到接近基线准确率。此外,加入SEBlock可以更好地进行多特征数据的模型训练,对OA、RPA、RCA有所提升,并且可以缓解特征融合后VFA升高的问题。然而,本文研究针对各项指标的提升幅度较小,并且本文的研究在ADC2004数据集上表现欠佳,与最高水平仍存在一定差距,说明本文研究对不同风格的音乐普适性不强。在未来的工作中,计划丰富训练数据的类型,设计一些其他的声学特征加入输入数据中。
