基于机器学习的直播电商客户流失风险预测
2023-06-06李翠萍

摘要:客户流失是互联网电商企业面临的重要问题之一,及时预测和挽留流失客户对企业提高经济效益具有重要作用。本文基于决策树、支持向量机和XGBoost三种机器学习算法,从客户画像特征、行为特征、情感特征和价值特征四个方面选取指标构建模型并评价,以对比不同模型在同一个数据集上的预测结果。结果表明,集成算法XGBoost模型表现最佳,客户情感价值特征对流失客户预测的贡献度最大,并由此提出相应的客户挽留对策。
关键词:机器学习;直播电商;客户流失;预测模型
引言
随着互联网技术的发展,直播电商平台如雨后春笋般涌现,如淘宝、抖音、快手、小红书等。客户可选择的直播平台和直播内容越来越多。流量大小对客户订单数量有直接影响,客户流失在直播电商中屡见不鲜。提高客户流失预测精度,建立客户流失预警机制,及时维系和挽留客户,有助于直播电商企业降低客户维系成本,提高企业经济效益。
1. 国内外研究现状
机器学习方法作为人工智能的核心算法,在客户流失问题的研究中被广泛应用。国外学者对于客户流失(Customer Churn)的研究大多集中在电信领域,研究方法大多采用机器学习方法。Sudharsan等(2022)[1]提出了一种新的框架,发现S-RNN可以用来对客户按流失和正常客户进行分类,并对流失客户通过分析网络利用率实施保留措施。Abdelrahim等(2019)[2]融合采用决策树、随机森林、梯度增强机器树“GBM”和极端梯度增强“XGBOOST”四种算法构建电信客户流失预测模型,发现应用XGBOOST算法获得了最佳结果。Adnan等(2019)[3]重点关注跨公司客户流失预测问题,采用机器学习算法构建CCCP(Cross-Company Churn Prediction)模型,在电信行业公开数据集上验证,结果表明大多数数据转换方法显著提高了CCCP的性能,而Z-Score数据转换方法不能获得更好的结果。
国内学者对客户流失的研究方法大多数采用数据挖掘技术。刘松(2022)[4]分析了银行客户流失预测模型的可解释性,发现深度神经网络预测准确性更高。薛冰(2022)[5]运用多模型融合的方法预测电信运营商客户流失,发现融合模型算法有利于提高模型的准确性和可用性。郑桂钖、徐宽(2022)[6]基于数据的高维时序特征构建直播行业客户流失预测模型,结果表明在补充了时序特征后的融合特征模型预测效果有显著提升。黄栩(2019)[7]研究软件APP的客户流失问题,实验结果表明模型的结果预测准确率都在90%以上,具有很好的预测效果。钟文鑫(2018)[8]研究陌生人社交APP客户流失预测问题,四种机器学习算法构建对比模型,发现XGBoost模型的表现结果更佳。
综上所述,客户流失问题受到了国内外学者的广泛关注,数据挖掘的机器學习算法是研究此类问题最常用的方法。
2. 数据处理与特征工程
2.1 数据说明
本研究数据集来源于某电子商务平台电子产品销售直播的客户特征数据,共包含5630条数据记录。因变量为流失标志(Churn),1表示流失客户,0表示未流失客户,自变量为平台使用期限、客户首选登录设备、城市级别等17个特征。
2.2 数据预处理
由于原始数据存在缺失、样本不均衡等问题,为了模型分析的准确性,本研究运用Python3.7工具在anaconda环境下填充缺失值、转换数据类型、独热编码和smote过采样。
2.2.1 缺失值处理
经检测发现,变量Tenure、Warehouse ToHome等6个变量存在200条以上的缺失数据,考虑到样本体量较小,本文所选部分模型对缺失数据依赖度较高,故采用中位数和众数来填充缺失值。
2.2.2 数据转换
通过观察原始数据可以发现,PreferredLoginDevice、MaritalStatus、Gender、PreferedOrderCat四个变量的值为字符串类型,为了建模和分析方便,本文将字符型变量转换为数值型变量,转换规则如表1所示。
转换后的数据不具有有序性特征,例如性别变量中的0和1,仅表示男性和女性的客户群划分,本文选取独热编码(One-Hot Encoding)技术、运用scikit-learn库中的OneHotEncoder模块对这类数据进行重新编码,防止数据间的大小关系参与运算,合理地计算特征之间的距离。独热编码后,数据集由原来的17个变量扩展到28个。
2.2.3 样本不均衡处理
本研究选取的流失客户样本数量为948,非流失客户样本数量为4682,比例为1:4.9。一般来说,当流失客户与非流失客户数据比例为1:2或1:3时,模型效果较好[9]。侯俞安(2022)在研究个人信用风险评估时采用SMOTE算法训练不平衡样本数据集,模型取得了更好的效果[10]。本文采用SMOTE方法,将流失客户样本扩展到与非流失客户大致相当的比例。SMOTE算法根据少数类样本人工合成新样本,对少数类样本每个样本x,从它的K近邻中随机选一个样本y,然后在x,y连线上随机选取一点作为新合成的样本。这种合成新样本的过采样方法可以降低过拟合的风险。构建新样本的公式如下:
2.3 客户特征模型
客户画像是了解客户的关键步骤,平台可以根据画像特征实施精准营销策略,提升客户满意度,降低流失的可能性。客户行为特征反映了客户的使用习惯,通过客户行为数据可以挖掘内容偏好、发掘客户兴趣点、预警客户流失。客户对商品服务的满意度评分和投诉情况直接反映了客户的情感状态。张梅英(2022)认为满意度对忠诚度和购买意愿有正向影响,满意度较高的客户流失的可能性较小[11]。RFM模型是客户价值衡量的理论基础,该模型由最近一次消费R(Recency)、消费频率F(Frequency)和消费金额M(Monetary)构成,一般来说,消费时间较远、消费频次较低、但消费金额较高的客户,很可能是已经流失或者即将流失的客户,应当实施挽留措施。本文筛选的客户特征及含义如表2所示。
3. 模型选择与实验结果
3.1 算法选择与模型构建
预测客户流失属于二分类问题,分类准确性的关键在于算法的选取。本文采用Python3.7软件进行机器学习建模,在anaconda环境下运行。首先使用留出法将数据集划分为测试集(20%)和训练集(80%),然后使用sklearn工具包分别建立决策树、支持向量机和XGBoost算法模型。
3.1.1 决策树模型构建
决策树是一种、应用广泛的机器学习算法,可以用来解决分类和回归问题。目前主流的决策树算法有基于信息熵的ID3算法、C4.5算法和基于基尼系数的CART算法。信息熵表示随机变量不确定性的度量,不确定性越大得到的熵值越大,假定当前样本集合D中第k个样本所占的比例为(k=1,2,…,|y|),则D的信息熵定义为
本文运用sklearn工具包中的Decision TreeClassifier分类器,在默认参数下创建模型,模型最佳预测准确率达88%,AUC得分为0.84。但是模型的可解释性和分类精度之间是一种权衡[12],最佳预测效果下模型的可解释性不高。为了提高树模型的可解释性,可以通过限制最大深度和最大叶子结点的数量简化模型。
3.1.2 支持向量机模型构建
支持向量机(Support Vector Machine,SVM)是通过寻找超平面对样本进行分割从而实现分类或预测的算法,分割样本的原则是使间隔最大化,寻找最大间隔的支持向量。支持向量机的核决定了如何投影到更高维的空间,核函数的参数决定了边界的形状,正则化参数C表示单个数据点对模型的影响程度,C越小表示模型越简单。本文运用sklearn工具包中的SVC模块创建支持向量机模型,所选择的核函数为RBF径向基核,惩罚系数为20,运行多次以后模型的准确率为86.9%,AUC得分为0.88。
3.1.3 XGBoost模型构建
XGBoost(eXtreme Gradient Boosting)又叫极度梯度提升树,是boosting算法的一种实现方式。其主要目标是降低模型的误差,因此采用多个基学习器,下一个学习器是学习前面基学习器的结果的差值,通过多个学习器的学习,不断降低模型值和实际值的差。本文采用XGBoost库中的XGBClassifier分类器构建模型,为了提升模型的效果,将子决策树的最大深度限制为10,目标函数参数设为binary:logistic,用于训练的子样本占总样本的比例设为0.8,特征随机采样的比例设为0.8,模型预测准确率为90.5%,AUC得分为0.93。
3.2 模型评估指标选择
本文采用二分類问题的混淆矩阵对模型进行综合评价。对于二分类问题,可以将样本根据真实情况和学习器的预测结果分为真正例(TP)、真反例(TN)、假正例(FP)、假反例(FN),分类结果的混淆矩阵如表3所示。
查准率P(precision)与查全率R(recall)的定义分别为
F1评分法可以更便捷地综合评价查准率和查全率,F1的计算公式为
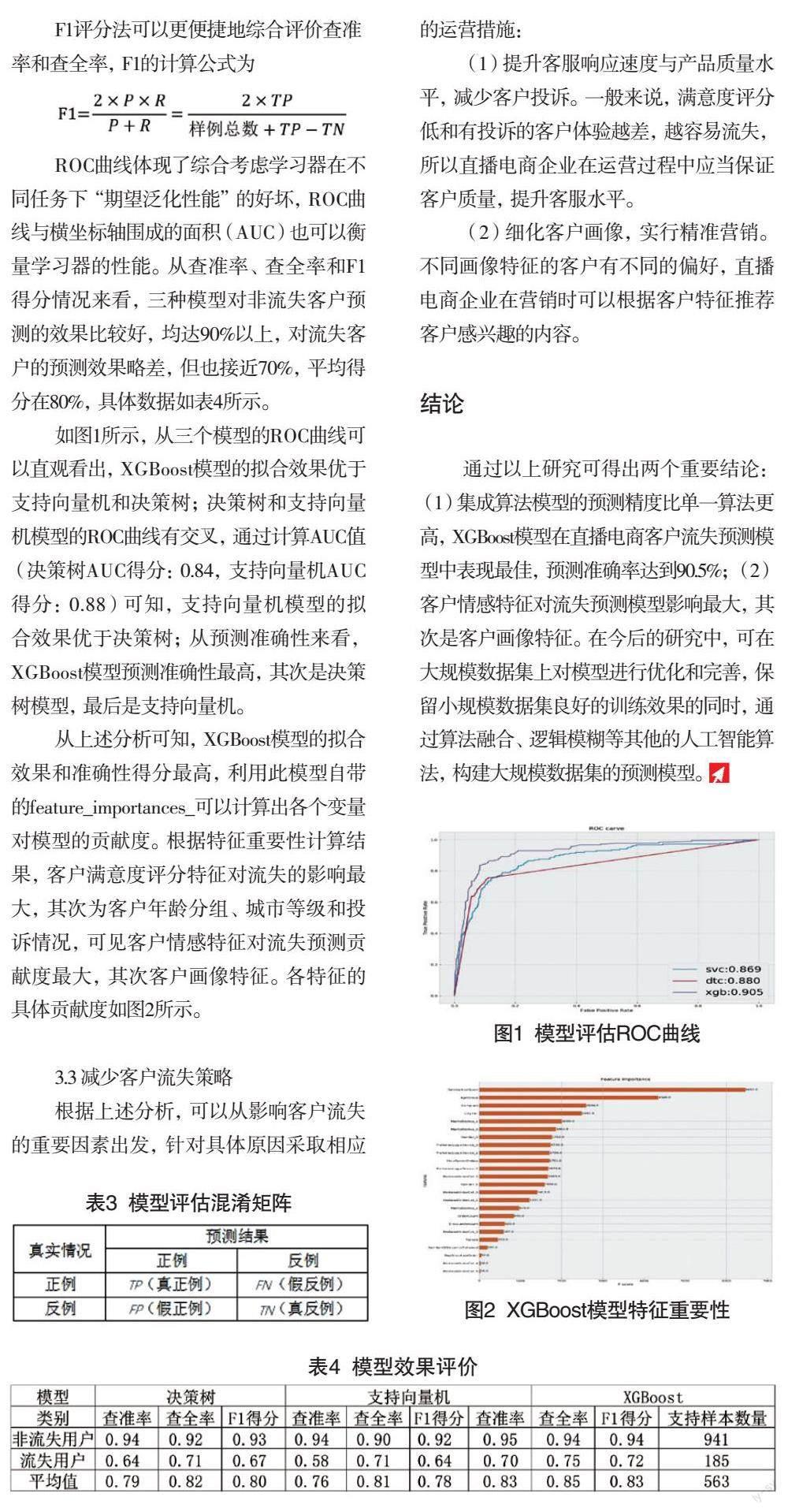
ROC曲线体现了综合考虑学习器在不同任务下“期望泛化性能”的好坏,ROC曲线与横坐标轴围成的面积(AUC)也可以衡量学习器的性能。从查准率、查全率和F1得分情况来看,三种模型对非流失客户预测的效果比较好,均达90%以上,对流失客户的预测效果略差,但也接近70%,平均得分在80%,具体数据如表4所示。
如图1所示,从三个模型的ROC曲线可以直观看出,XGBoost模型的拟合效果优于支持向量机和决策树;决策树和支持向量机模型的ROC曲线有交叉,通过计算AUC值(决策树AUC得分:0.84,支持向量机AUC得分:0.88)可知,支持向量机模型的拟合效果优于决策树;从预测准确性来看,XGBoost模型预测准确性最高,其次是决策树模型,最后是支持向量机。
从上述分析可知,XGBoost模型的拟合效果和准确性得分最高,利用此模型自带的feature_importances_可以计算出各个变量对模型的贡献度。根据特征重要性计算结果,客户满意度评分特征对流失的影响最大,其次为客户年龄分组、城市等级和投诉情况,可见客户情感特征对流失预测贡献度最大,其次客户画像特征。各特征的具体贡献度如图2所示。
3.3 减少客户流失策略
根据上述分析,可以从影响客户流失的重要因素出发,针对具体原因采取相应的运营措施:
(1)提升客服响应速度与产品质量水平,减少客户投诉。一般来说,满意度评分低和有投诉的客户体验越差,越容易流失,所以直播电商企业在运营过程中应当保证客户质量,提升客服水平。
(2)细化客户画像,实行精准营销。不同画像特征的客户有不同的偏好,直播电商企业在营销时可以根据客户特征推荐客户感兴趣的内容。
结论
通过以上研究可得出两个重要结论:(1)集成算法模型的预测精度比单一算法更高,XGBoost模型在直播电商客户流失预测模型中表现最佳,预测准确率达到90.5%;(2)客户情感特征对流失预测模型影响最大,其次是客户画像特征。在今后的研究中,可在大规模数据集上对模型进行优化和完善,保留小规模数据集良好的训练效果的同时,通过算法融合、逻辑模糊等其他的人工智能算法,构建大规模数据集的预测模型。
参考文献:
[1]Sudharsan R,Ganesh EN.A Swish RNN based customer churn prediction for the telecom industry with a novel feature selection strategy[J].Connection Science,2022,34(1):1855-1876.
[2]Ahmad AK,Jafar A,Aljoumaa K.Customer churn prediction in telecom using machine learning in big data platform[J].Journal of Big Data, 2019,6(1).
[3]Amin A,Shah B,Khattak AM,et al.Cross-company customer churn prediction in telecommunication: A comparison of data transformation methods[J].International Journal of Information Management,2019,(46):304-319.
[4]刘松.基于深度学习的银行客户流失预测问题研究[D].贵阳:贵州大学,2022.
[5]薛冰.基于多模型融合的电信运营商客户流失预测研究[D].大连:东北财经大学,2022.
[6]郑桂钖,徐宽.基于高维时序特征补充的直播行业用户流失预测模型[J].科技与创新,2022,(23):56-61.
[7]黄栩.基于机器学习算法建立用户流失预警模型[J].电子制作,2019,(16):49-51.
[8]钟文鑫.基于数据挖掘的陌生人社交APP用户流失预测模型研究[D].北京:首都经济贸易大学, 2018.
[9]邢绍艳,朱学芳.付费知识直播用户流失预测实证研究[J].信息資源管理学报,2022,12(4):121-130,140.
[10]侯俞安.基于SMOTE—贝叶斯网络的商业银行风险评估模型研究[D].上海:东华大学,2022.
[11]张梅英.迁移理论视角下零售电商平台消费者重复购买意愿的影响机制研究[J].商业经济研究,2022,(4):85-88.
[12]Baryannis G,Dani S,Antoniou G.Predicting supply chain risks using machine learning:The trade-off between performance and interpretability[J].Future Generation Computer Systems,2019,101(C):993-1004.
作者简介:李翠萍,硕士研究生,研究方向:数字经济。
