基于Resnet-Bert 网络模型的跨媒体检索方法*
2023-06-04闫盈盈洒科进
闫盈盈 曹 扬 洒科进 支 婷
(1.中电科大数据研究院有限公司 贵阳 550022)(2.提升政府治理能力大数据应用技术国家工程研究中心 贵阳 550022)
1 引言
检索是用户获取知识的常用方式之一,传统的跨媒体检索研究主要集中在以文搜图和以图搜文两种媒体数据之间。事实上,随着大数据时代的来临,人们通过互联网会产生大量的文本数据如新闻报道、微信聊天记录、弹幕等,图片数据如文章配图、医疗影像等,视频数据如抖音、快手等视频媒体软件数据、城市摄像头数据等,同时伴随着如微信语音、视频配音等音频信息。通常四种媒体常常会同时出现且语义具有相关性,但大多数跨媒体检索技术研究仅仅限于两种媒体数据之间,显然,这种搜索已经不能够满足人们日益增加的数据检索需求。提供高效的跨媒体检索方法满足人们精准且丰富的数据检索需求,提升用户的知识获取效率和检索体验是目前跨媒体检索技术的研究热点。
近年来,跨媒体检索受到了广泛的关注和研究,主要分为基于子空间学习的方法、基于哈希学习的方法以及基于深度学习的方法。基于子空间学习的方法中最常用的方法是典型相关分析(CCA)。Rasiwasia 等[1]将语义类别信息与CCA 进行结合,Hardoon 等[2]提出了一种基于高斯分布核函数的KCCA方法,Andrew等[3]提出了DCCA方法,该方法是一种参数化方法,可以通过深度网络灵活学习两种相关类型媒体之间的非线性变换。Gong等[4]提出了Multi-view CCA 将高层语义作为第3 个视角来扩展传统CCA 方法,李广丽等[5]利用Tag-rank 和典型性相关分析法(CCA)进行在线商品的跨媒体检索研究。基于哈希学习的跨媒体检索方法主要思想为通过学习哈希函数,将高维数据映射到二进制编码的海明空间,同时尽可能保留原始空间的相似结构[6],包括模态间检索方法IME[7]、潜在语义稀疏哈希方法LSSH[8]、多视角检索语义保持哈希方法SePH[9]、判别的跨模态哈希方法DHC[10]、线性跨模态哈希LCMH[11]、协同矩阵分解哈希CMFH[12]、语义相关最大化SCM[13]。在基于深度学习的跨媒体检索方法方面,Peng等[14]构建跨媒体层次化网络,通过两阶段的学习策略发现媒体内及媒体间关联关系,从而获得跨媒体信息的共享表征;Wei 等[15]提出了利用卷积神经网络视觉特征的跨媒体检索方法;Wang 等[16]提出基于生成对抗网络的了跨媒体检索方法(ACMR)。Huang等[17]提出了基于混合迁移网络的跨媒体统一表征方法,实现了不同媒体间的知识迁移。綦金玮等[18]利用两级循环神经网络建模不同媒体内及媒体间的细粒度上下文信息,然后引入注意力机制实现了精确的跨媒体关联关系挖掘。He 等[19]提出了一种基于Resnet 的细粒跨媒体统一表征模型FGCrossNet,实现了基于四种媒体类型数据的跨媒体检索。
本文致力于四种模态的跨媒体检索方法的研究,提出了基于Resnet-Bert 网络模型的跨媒体检索方法,旨在解决目前仅使用两种模态进行检索导致的用户检索体验不佳以及四种模态检索精度不高,效果不好的问题。
2 本文方法
2.1 基于类别标签的跨媒体统一表征模型
跨媒体统一表征是跨媒体检索的重要研究基础,将不同媒体类型数据的特征表示映射到同一个共享子空间,从而跨越异构鸿沟,实现语义关联。本文提出的跨媒体检索基于图1 所示的跨媒体统一表征思想。

图1 基于类别标签的跨媒体统一表征模型(以5种类别为例)
如图1 所示,展示了基于类别标签的跨媒体统一表征模型。该模型包括两个步骤。首先,将图像、视频、音频以及文本媒体类型数据分别通过深度学习、机器学习等方法进行特征提取,分别形成各自的类别空间,图中各媒体类型的坐标轴数目分别表示不同的类别标签,空间点代表数据的类别特征向量。其次,将各媒体类型数据的类别特征向量表示映射到同一个类别子空间中,从而实现跨媒体数据的统一表征。基于该表征思想,能够简洁高效地实现不同类型的媒体数据语义关联和检索计算。
2.2 Resnet-Bert网络模型
针对当前跨模态检索存在的媒体类型较少以及跨媒体检索效果不佳的问题,提出了一种基于Resnet-Bert网络模型的跨媒体检索方法,利用卷积神经网络模型Resnet[20]良好的图像编码能力与自然语言处理模型Bert[21]良好的文本编码能力,在图像、视频、音频以及文本四种媒体类型数据之间建立了基于类别标签的跨媒体统一表征共享空间,通过不同模态间信息互补与增强,实现跨媒体信息语义的迁移辅助与关联理解,使得模型具有较好的表达能力。本文方法的网络结构如图2所示。

图2 Resnet-Bert网络模型图
如图2 所示,对于图像、视频以及音频三种媒体的数据,统一构建基于Resnet50 的卷积神经网络。对于文本数据,构建基于Bert 的网络模型,在输出层,形成基于图像、视频、文本及音频的跨媒体统一表征类别标签空间。
2.3 损失函数
本文利用两种损失函数驱动Resnet-Bert 模型的学习,分别为交叉熵损失函数与中心损失函数。交叉熵损失函数是利用交叉熵计算各媒体类型的类别特征表示与正确的标签向量之间的差异,并将各媒体的损失函数求和。其定义如下所示:
其中,l(xk,yk)是交叉熵损失函数。I、V、A 以及T 分别表示图像、视频、音频以及文本媒体类型。以图像为例,NI 表示训练集中图像的总数量,表示模型学习的第k 个图像数据的类别特征,表示第k 个图像数据的真实标签。NV 表示视频分帧后的所有的帧的总数量。
中心损失函数希望每个样本的特征离特征中心的距离的平方和越小越好,即中心损失函数用于减少类内差异,能够把同一类的样本之间的距离拉近一些,使其相似性变大。中心损失含函数的定义如下:
其中,xk表示属于第yk个类的第k 个训练样本的特征表示,该处的训练样本是可以是任何媒体数据类型。N 表示所有媒体训练数据的总个数。cyk表示第yk个类别的特征中心。
3 实验
3.1 跨媒体数据及预处理
按照文献[19]介绍的四种类型媒体数据采集与预处理情况,本文通过爬虫、下载等多种方式,获得了主题相关、语义一致且标签相同的四种跨媒体数据。该数据包括图像、视频、音频、文本四种媒体类型,每种媒体类型均包括200 种鸟类。其中图像数据为CUB-200-2011数据集[22],共11788幅图片,5994 张训练集和5794 张测试集。视频数据采用YouTube Birds 数据集[23],训练集为12666 个视频,测试集为5864个视频。文本数据集[19]为4000篇训练集和4000个测试集。音频数据[19]包括6000个训练频谱图和6000 个测试频谱图。其中,图像CUB-200-2011 数据是通过相关网站下载获得,视频YouTube Birds 数据是通过爬虫方式获得。文本和音频数据由北京大学多媒体信息处理研究室(MIPL)实验室提供。图像、音频及文本的数据标签与数据呈现一一对应关系。视频数据的标签与视频数目呈现一一对应关系。对采集的跨媒体数据进行数据清洗和转换,形成可用干净的数据。由于YouTube Birds 视频具有时间序列信息,因此需要进一步进行处理。根据文献[19]对于鸟类数据集的预处理情况,将爬取的视频分别利用python脚本进行分帧实验,每个视频获取50 帧,剔除无用帧和质量较低的帧,最终保留每个视频为25 个帧,即25 幅图像。每个音频数据为通过傅里叶变换技术转化得到的频谱图,将频谱图作为该模型的音频输入数据。
3.2 评价指标
为了充分评估本文方法的有效性,在上述数据集上使用精确率(Precious,P)指标和平均精度均值(Mean Average Precision,MAP)指标。其中,前者用于衡量训练、验证与测试效果,后者用于衡量跨媒体检索效果。
1)精确率指标P。P 指标用于衡量模型在给定数据集上的训练和验证效果,将实际的数据标签与模型的输出标签进行比较,能够直观地展示模型效果。其计算公式如下所示:
其中,TP 为预测标签与实际标签相同的数据数目,FP为预测标签与实际类别标签不同的数据,P值越高越好。
2)平均精度均值指标MAP。MAP为跨媒体检索的常用评价指标,利用测试集中的一种媒体的数据作为查询集合来检索另一种媒体类型的数据,如果返回结果中的数据和查询数据属于同一个类别标签则为相关,否则为不相关。给定一个查询(图片或文本或视频或音频)和返回的R 个检索结果,则精度均值为
其中,T 为检索结果中与查询相关数据的个数,P(r)为返回的前r个数据的准确率,即相关的数据所占的被分数,如果第r 个数据与查询数据相关则δ(r)为1,否则δ(r)为0。然后通过对查询集中的所有查询的AP 值求平均值来计算MAP 的值。该指标能够同时兼顾返回结果的排序以及准确率,在信息检索领域被广泛使用。MAP 值越大,算法准确性越好。
3.3 系统框架搭建
本文选用深度学习框架Pytorch 搭建本文提出的Resnet-Bert网络模型,Python 的版本为3.6,实验均在64 位的Ubuntu16.04 操作系统下完成。本文提出的Resnet-Bert 网络模型,使用的Resnet 网络模型为Resnet50,学习率learning-rate 设置为0.001,轮数epoch 的设置为50,最小批次batchsize设置为4,动量momentum设置为0.9。加载Reset在ImageNet 数据集上的预训练模型,将图像数据、视频数据与音频数据输入到Resnet中进行模型微调,得到符合样本数据的网络模型参数。加载谷歌提供的Bert 预训练模型“uncased_L-12_H-768_A-12”,将文本数据输入到Bert 中进行训练,得到符合训练数据的Bert 的网络模型参数。本文在网络模型训练之前,对图像数据、处理后的视频数据以及音频数据采用了数据增强的策略,包括数据的中心化、随机缩放、中心裁剪等,输入Resnet50的数据尺寸为448*448。对于输入Bert 模型的文本数据,固定了文本的长度为80,采用“短补长切”的方法进行处理。
3.4 实验对比及结果分析
实验对比了文献[19]提出的FGCrossNet 模型。该模型使用4 种跨媒体类型数据,基于Resnet50 模型实现了跨媒体数据的统一表征和检索。
基于Resnet-Bert 的跨媒体检索实验,包括两个步骤。第一个步骤为训练与验证。在处理后的跨媒体训练数据集上进行模型的训练,并在测试集上进行测试,利用精确率指标P 衡量模型学习效果。第二个步骤为检索。将测试集输入模型中,得到图像、视频、音频以及文本数据的类别标签特征表示,利用MAP 指标衡量各媒体之间的检索效果。表1 展示了在Resnet-Bert 模型上训练和测试的效果。

表1 在Resnet和Resnet-Bert模型上的训练与测试效果
由上表,我们可以得到如下结论。
1)基于Resnet 网络模型的跨媒体数据的训练与测试,图像、视频以及音频数据的验证效果较高,但是文本验证效果较差,主要原因为文本媒体类型在使用卷积神经网络时,特征提取效果不佳。
2)使用自然语言处理模型Bert 进行文本类别标签特征的提取,使用在视觉方面处理较好的卷积神经网络Resnet进行图像、视频以及音频特征的提取,极大地提高了各模态的分类准确率,尤其是文本模态的准确率,为进一步的跨模态检索奠定了坚实的基础。
3)对比使用单一交叉熵损失函数LCRO,同时使用LCRO和LCEN的验证效果更好,说明中心损失函数LCEN能够有效提高测试效果。
利用训练步骤学习到的Resnet 模型和Bert 模型,在测试集上实现跨媒体数据的统一表征,得到类别空间的特征向量和预测类别标签,并与正确的标签进行对比分析。表2 展示了利用MAP 指标衡量的各检索任务效果。
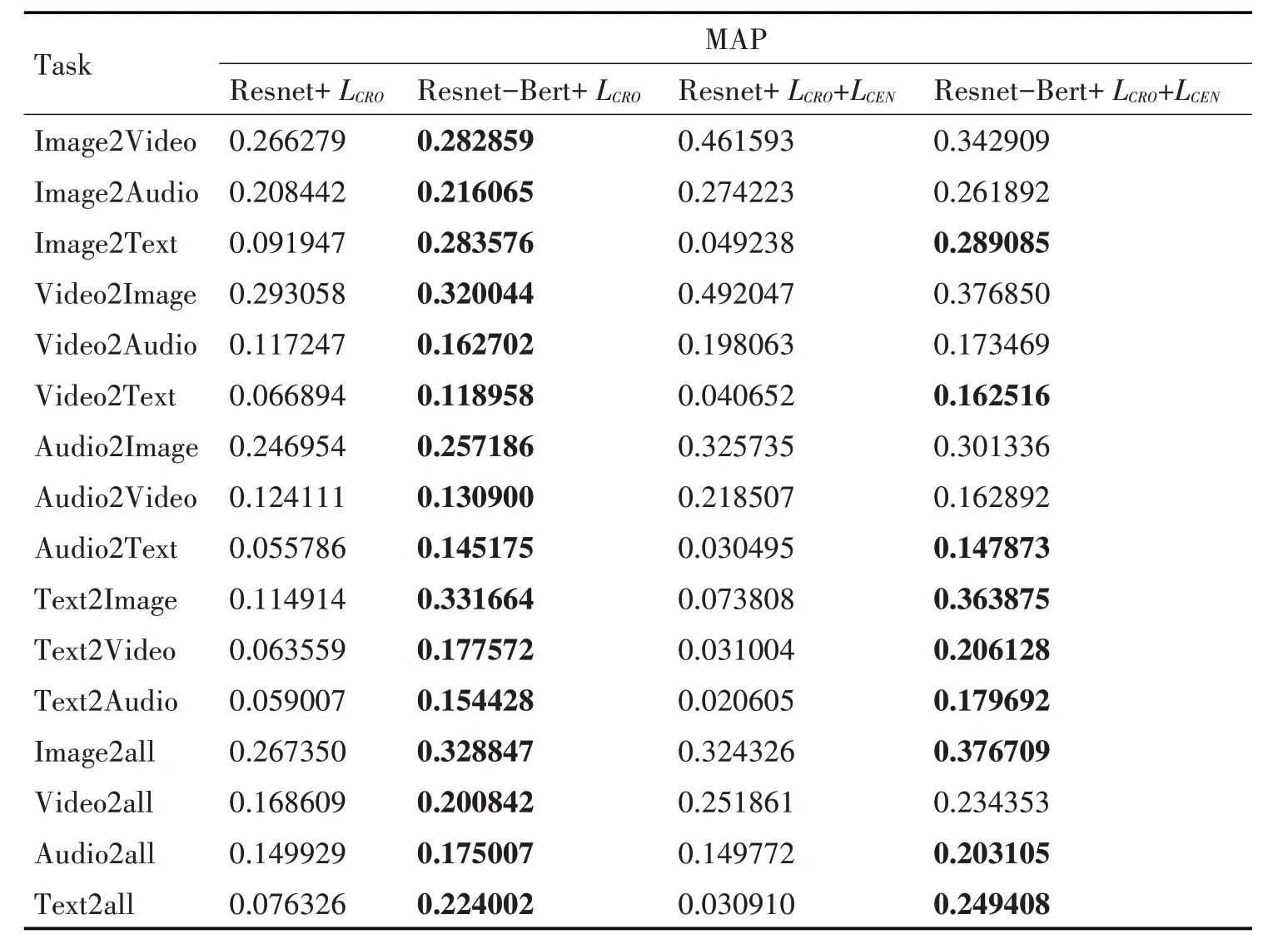
表2 基于Resnet-Bert网咯模型的跨媒体检索效果
如表2所示,我们可以发现:
1)利用交叉熵损失函数LCRO的Resnet-Bert 模型的检索效果高于单一使用Resnet 模型的检索效果,尤其是与文本相关的Image2Text、Audio2Text、Video2Text、Text2Image、Text2Video、Text2Audio 以及Text2all,MAP 值平均提升了0.1 以上,提升效果显著,主要原因为利用Bert 模型之后,文本的特征表示能力得到较大的提升;除文本相关的其余检索效果也有不同程度的上浮,主要原因为文本、图像、视频以及音频等特征表示信息通过交叉损失函数的不断降低,实现了信息的媒体间辅助迁移和关联学习。
2)在交叉损失函数LCRO的基础上,引入中心损失函数LCEN后,Resnet-Bert 网络模型的检索效果均好于单一使用LCRO的检索效果,主要原因是LCRO考虑的为类间差异,LCEN考虑的为类内差距,文献[19,24]研究显示两者的搭配对于单一损失函数使用具有较大的提升作用。
3)基于交叉损失函数LCRO和中心损失函数LCEN的Resnet-Bert 网络模型在文本相关检索效果方面明显好于Resnet网络模型,但是图像、音频、视频的相互检索方面却小于Resnet模型的效果,一个可能的原因Bert 模型的引入,LCEN的类中心向量的不断向文本特征拟合更新,类别区分度较低的特征向量进行了错误的类别选择。
利用Resnet-Bert 网络模型获得四种媒体类别标签的特征表示之后,通过余弦相似度计算等度量方法,进而实现不同媒体类型的相互检索与应用。
4 结语
本文针对跨模态检索研究中媒体数目较少以及检索效果不佳的问题,提出了一种基于Resnet-Bert 网络模型的跨媒体检索方法。该方法利用卷积神经网络模型Resnet获取视频、音频和图像的特征表达,利用Bert 模型获取文本的特征表达,通过类别标签空间实现了跨媒体数据的统一表征。在公开数据集上进行实验,采用精确率P 和平均精度均值MAP 作为评价指标,证明本文提出的Resnet-Bert网络模型在跨媒体检索效果方面,尤其是文本检索效果方面具有较好的提升作用。未来我们将尝试构建基于特定场景且与工程实践相结合的四种跨媒体类型数据集,并继续研究基于深度学习的统一表征模型提高跨媒体检索效果。
