CNN-BiLSTM-Attention 模型在大规模计算系统故障预测的应用研究*
2023-06-04裴向东乔钢柱
员 民 裴向东 乔钢柱 王 莲
(1.太原科技大学计算机科学与技术学院 太原 030024)(2.山西超级计算中心 吕梁 033000)
1 引言
中国的大规模计算系统研究属于世界领先水平,超级计算机的性能在不断提升的同时,带来的系统规模和复杂度不断增加,即系统规模和复杂度的增长仍远远超过系统部件可靠性的改善。E 级高性能计算机的平均无故障时间(Mean Time Between Failure,MTBF)只有一个小时[1],高性能计算机系统庞大、组成及运行逻辑复杂,导致系统故障频繁发生,且故障发生后难以发现、定位、诊断、分析和调试[2]。
故障的解决方式分为了主动容错和被动容错两种[4],主动容错是在未发生故障之前就进行故障的排错,能提高系统自身的可靠性,降低系统容错的开销,而故障预测是主动容错的前提和基础。在此将通过山西省超级计算中心的天河二号系统故障日志对此话题展开探讨。该文研究的数据是异构计算系统的故障日志数据,结合基于时序特征的数据特点,制定对应预测机制进行研究[3]。
国内外学者已从预测机制方向对大规模故障数据做了大量研究:通过计算概率[4]及相关分数进行故障预测;Gainaru[5]等提出基于信号的故障预测方法;利用前置条件if-then 判断故障发生,如Watanabe[6]等对故障日志信息分组,利用贝叶斯原理判断故障;Das[7]等使用短语似然估计的方法对故障日志进行挖掘。现如今机器学习[8]发展迅速,便于对日志数据的特征进行提取,Chen[9]等利用RNN 算法预测作业故障概率;Zhu 等[10]使用支持向量机和神经网络算法预测硬盘故障发生的概率;Nie等[11]通过分析GPU运行温度、功率和误差的相关性,提出了一种基于神经网络的预测方法;Islam[12]等提出使用LSTM 进行预测,优点在于节约了系统资源。这些方法尽管解决了特征提取的问题,但无法获取故障之间的依赖关系,预测准确率较低。
目前深度学习对故障日志特征提取具有良好的分类性能和可伸缩性能,综合分析后提出CNN-BiLSTM-Attention 的故障预测模型,相较于传统的机器学习方法,该模型具有特征易提取、时间序列特征敏感度高以及对局部特征提取充分等优势,实验结果表明,该模型在天河二号异构计算系统的故障时间和故障节点预测上都有很高的精度和泛化性。
2 方法理论
该文采用的方法是先通过HDBSCAN 聚类算法将有相同特征的故障日志分组放在一起,然后利用CNN-BiLSTM-Attention模型进行预测。
2.1 HDBSCAN聚类
HDBSCAN聚类算法是结合DBSCAN算法和层次聚类算法的一种方法[13]。DBSCAN 聚类算法将密度堆积的散点标记为一类,而密度较低的散点称为噪声点,此算法可以将此类噪声数据排除,但DBSCAN 算法无法在不同密度的数据中识别集群,且聚类过程中需要两个参数进行调整,过程繁琐,为解决上述问题,HDBSCAN 聚类算法引入层次聚类的思想,该算法重新定义测量两点之间距离的方法,计算公式为
HDBSCAN聚类算法使用最小生成树来构建点与点之间的层次树模型,使得该算法仅需调整最小簇的数量(min_cluster_size),避免复杂的调参过程,提升聚类准确性和适用范围。
2.2 CNN-BiLSTM-Attention模型
2.2.1 CNN
模型的第一层为CNN 层,通过卷积层中的一些滤波器对故障日志局部特征进行提取,卷积层有很多卷积核,每个卷积核都有可接受的字段,并应用于输入的完整深度[14]。每层卷积都利用修正后的线性单元(ReLU)激活函数进行,公式如下:
经过激活函数修改负值,解决梯度消失和梯度爆炸问题,特征映射由滤波器生成,公式如下:
其中,ynm为卷积层m 中第n 个滤波器的输出;f()为激活函数,wnim为卷积核的权值,bnm为偏置,x 为输入的特征向量。
2.2.2 LSTM
由于时序特征是故障日志的关键信息,而RNN 对于处理序列特征信息非常有效,为解决RNN 模型梯度爆炸和梯度消失的问题[15]引入LSTM模型。LSTM引入一组存储单元,允许在训练过程中在一时间节点忘记历史信息以及允许更新存储单元,所以LSTM 更有利于处理较长距离的信息,对时间敏感的数据有很大的优势。其结构图如图1所示。
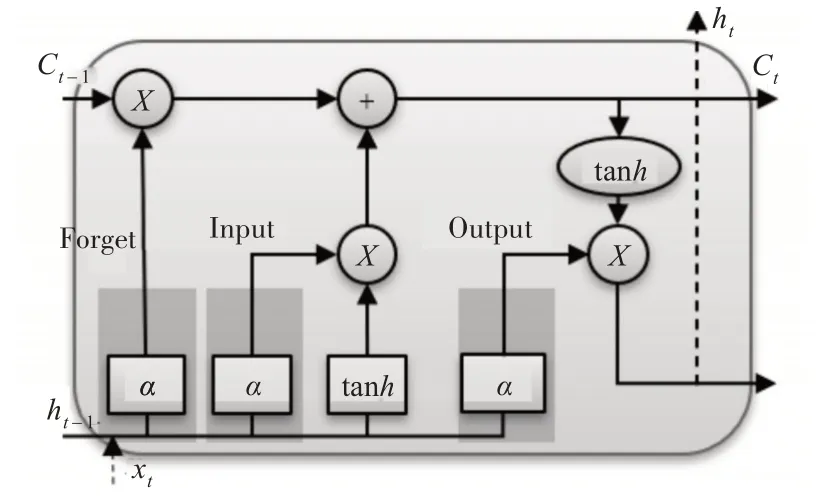
图1 LSTM细胞结构
如图,LSTM单元中有四个重要的变量,即内部存储器、遗忘门、输入门、输出门[12]。具体过程为首先是经过遗忘门,遗忘门决定上次细胞状态Ct-1所存储的信息量,当前时刻输入量为xt,其中Forget记为ft;然后计算输入门中的信息,也就是Input中所需要保留的信息,记为it,并保留临时细胞状态at;接下来,计算当前细胞状态Ct;最后计算输出门和现在时刻的隐藏层状态ht。计算公式如下:
其中α表示sigmoid 函数,bf、bi、bo和ba表示输出偏差。此处建立的模型采用的双向输入长短期记忆循环网络层,这样可以从正反两个方向学习时间序列特征,更有利于特征提取[16]。
2.2.3 注意力机制(Attention)
注意力机制的思想是通过增加焦点来对重要信息进行识别[17],忽略其他不重要的信息,更加关注重要信息。
首先,Kt表示经过CNN 和BiLSTM 模型处理后的输出,计算Kt的得分st,得到Kt对输出值影响的比重;然后利用Softmax 函数对st进行归一化处理,得到注意力权值at;最后用权值系数at和输入向量kt计算得出加权特征ot,计算公式如下:
其中,Wh为权值,bh为偏置。
2.2.4 模型结构
通过CNN 发现大规模计算系统故障日志数据中明显的特征,并提取故障特征;再利用BiLSTM正反两个方向输入CNN 中得到的特征数据,提取具有时间序列的故障特征;最后用注意力机制可以得到对结果影响较大的特征,提高了故障预测的精度,具体结构如图2所示。
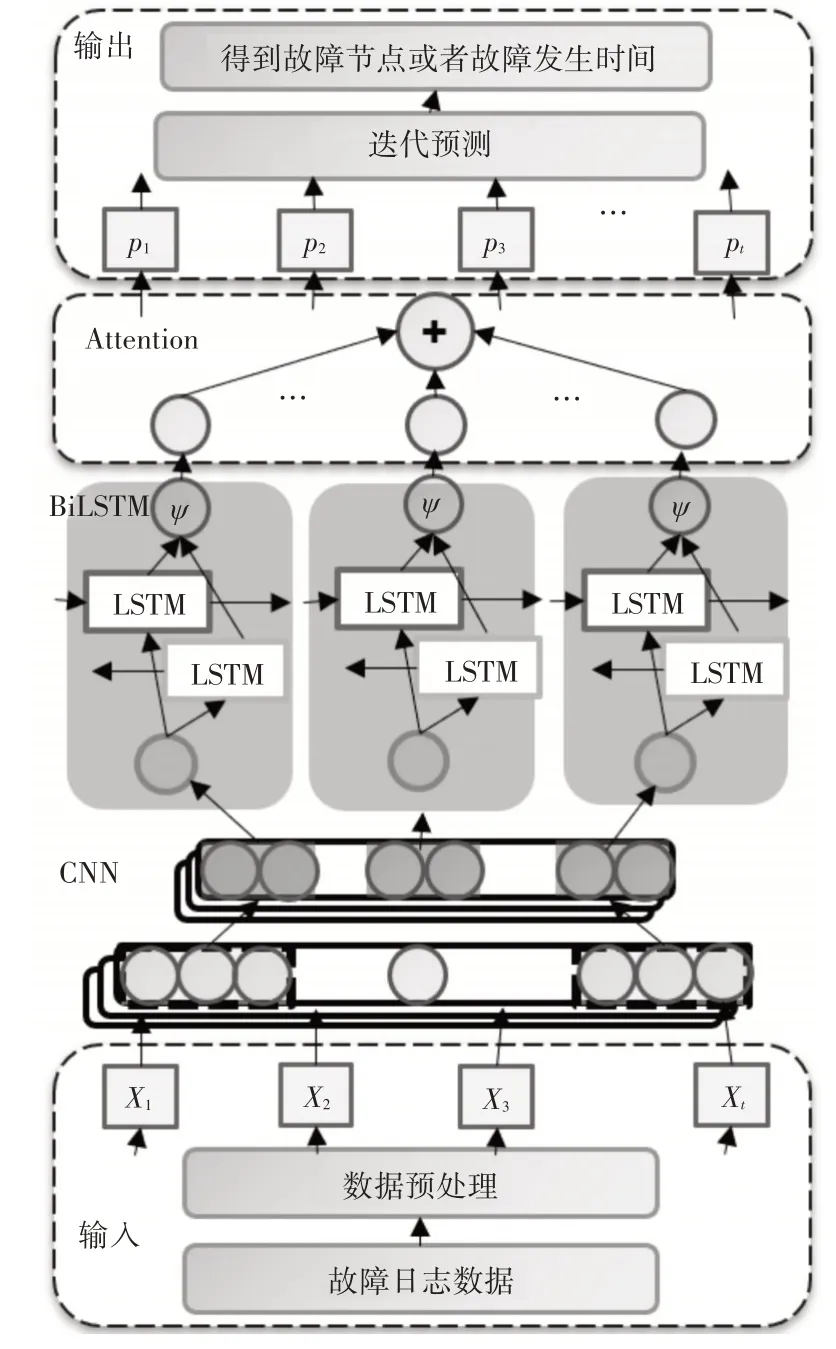
图2 CNN-BiLSTM-Attention模型结构图
3 实验设计
本章节主要介绍实验的处理过程:实验数据的预处理,对实验数据的时空分布进行分析,HDBSCAN聚类的结果以及模型参数的选择。
3.1 实验数据处理
实验数据来源于山西省超级计算中心的天河二号系统2016 年1 月18 日~2017 年12 月6 日的故障日志,导出为csv(逗号分隔值文件)文件,共包含208718121 条故障日志,将无效字段去除,最后得到拥有9字段的故障日志信息,如图3所示。

图3 故障日志信息
3.2 故障时空分析
通过对Mohammed 等[18]对国外大规模计算系统的组件故障分布的研究,得出结论大规模计算系统的故障日志数据在时空分布具有相似性,不符合正态分布。
对于系统故障空间上分布图,由于该大规模计算系统中空间关系为4节点组成1个计算单元。据此空间关系,得到故障空间上的概率密度图,如图4 所示。从图中也可以验证上述结论,即故障空间分布不服从正态分布。
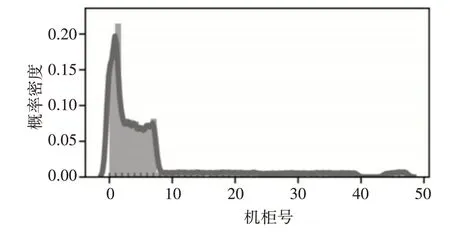
图4 故障空间概率图
对于系统故障时间上的分布图,由于故障发生具有不确定性,所以故障时间预测其实是预测两个故障节点之间的时间,通过分析后,得到故障时间分布特点如图5 所示,可以看出也并非正态分布,验证了Mohammed等的结论。
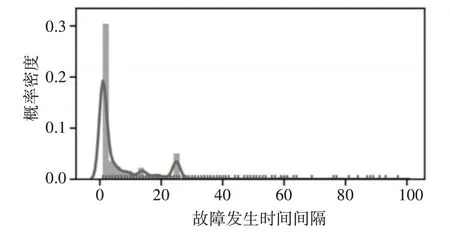
图5 故障时间概率图
3.3 HDBSCAN聚类
为了将具有相同特征的数据聚集在一起,提高模型预测的精度,通过对比实验将min_cluster_size设置为300000 时得到噪声点最少,最后得到五个不同类型的簇,聚类结果分布如图6所示。
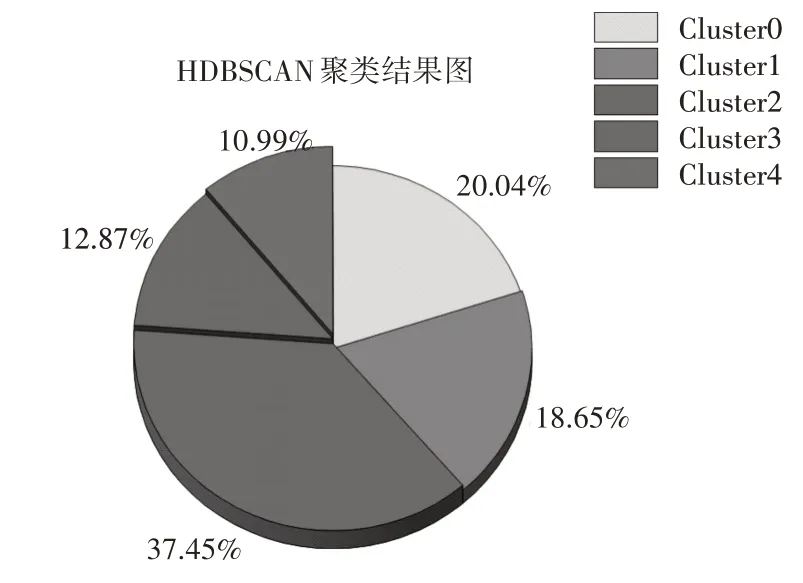
图6 聚类结果分布饼图
根据分布图可以看出,Cluster2数据最多,占了37.45%,接下来Cluster0 占比20.04%,Cluster4 占比最少占10.99%。
根据故障发生的优先级来看,故障优先级共分为6个等级,但由于Priority0、Priority1和Priority2一共有2000 多条信息,因为数量较少,所以将这些故障优先级统一划分为other。从图7 故障发生优先级的数量可以看出,优先级越高,发生概率越大,故障严重程度越低。

图7 各个故障优先级数据分布图
根据每个聚类类别进行分析,如图8,Cluster0中主要包含故障优先级高的other,说明其中发生的都是严重的故障;Cluster1、Cluster2 和Cluster3 中发生故障多是Priority5 的数据,是故障程度较低的数据;Cluster4相对于其他簇更为复杂,各种程度都有分布。
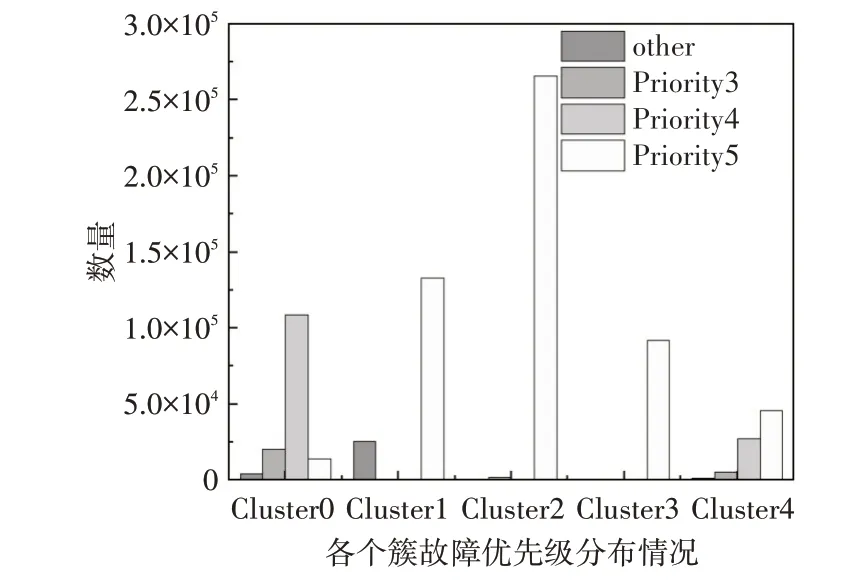
图8 各个簇故障优先级分布图
对于故障发生的设备位置来进行统计,共有7种设备位置,记作Facility0 到Facility6,由于Facility1 和Facility6 分别只有51 条和54 条,说明这两个设备不会经常发生故障;而主要发生故障的设备是其他五项,其中最易发生故障的是设备Facility5,说明Facility5在高性能计算中易出现故障,如图9。
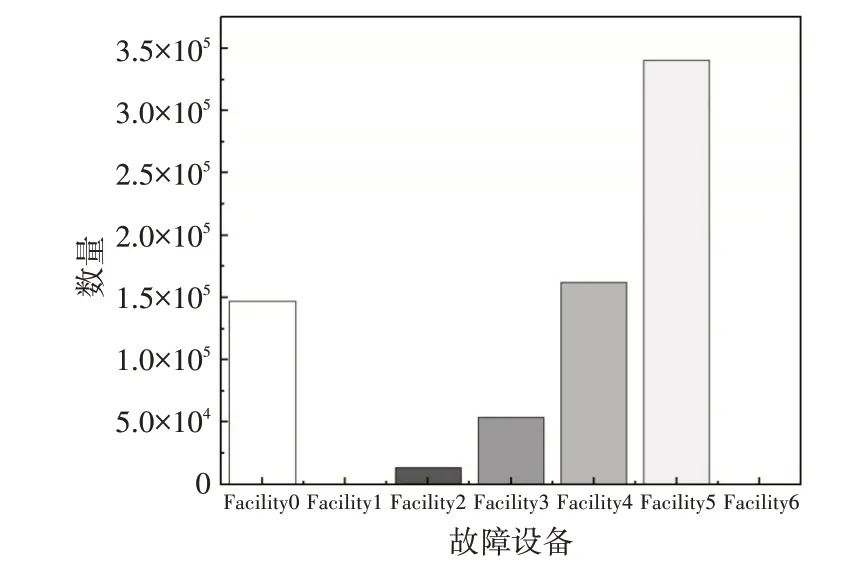
图9 各个故障设备分布图
对每个簇故障发生设备处作图进行对比,将故障设备记为Facility0 到Facility4 这五种。从图10可以看出,Cluster0 的故障多发生在Facility0;而Cluster1 上故障多发生在Facility3 和Facility4;Cluster2 发生故障设备都在Facility4 上,占75.8%;Cluster3 发生故障设备都在Facility3 和Facility4 上;Cluster4情况复杂,发生故障位置均有分布。
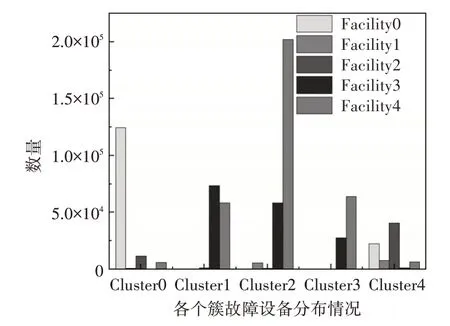
图10 各个簇故障设备分布图
以上可以说明,经过HDBSCAN 聚类后,Cluster0 和Cluster4 的数据相对于复杂,而Cluster1、Cluster2和Cluster3中的数据组成相对简单。
3.4 预测模型的参数选择
将得到的数据通过sklearn 的预处理方法将数据中非数值部分进行编码处理,再进行归一化处理,转化为监督学习。
在回归实验中,CNN-BiLSTM-Attention 模型需要预测两种不同的结果,相对于故障时间的预测,故障节点的预测更为复杂,因为预测结果有9948 个节点,则两种预测模型参数设置需要有所改变,如表1和表2所示,其中预测故障节点的模型多一层Dense 层,作用是防止过拟合,其他的参数,包括batch 为72,利用fig()函数模块中的validation_data 参数,标记出损失函数,最后利用matplotlib绘制出损失函数图像。

表1 故障时间预测模型超参数表
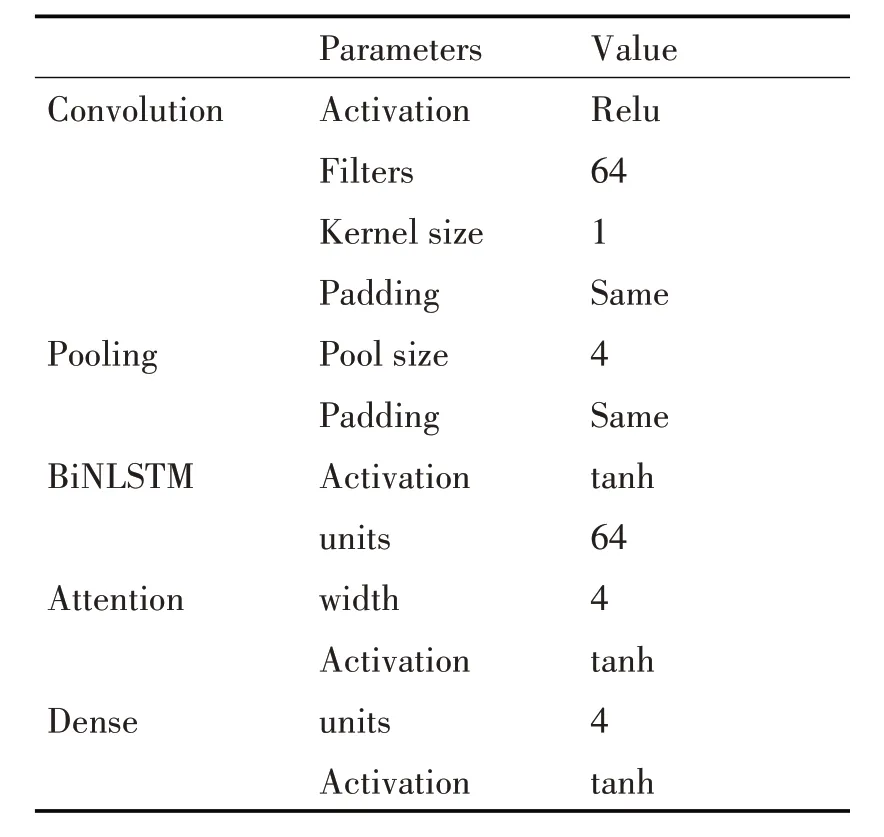
表2 故障节点位置预测模型超参数
损失函数为MAE,epoch 为50,数据中4/5 为训练数据,1/5 为预测数据。对于预测模型梯度优化问题,文中采用Adam 算法,该算法融合了AdaGrad和RMSprop算法的优点,可以为不同参数计算适应性学习率,而且占用更少的存储资源,对比其他算法,Adam在实际应用中表现更好[14]。
4 实验说明
实验环境配置:Inter(R)Core(TM)i7-10750H CPU@2.60GHz(12CPUs),RAM 16GB,NVIDIA Ge-Force RTX3060,Python3.9、TensorFlow2.6、scikitlearn1.0,对所有模型均采用以上配置环境。
预测故障发生时间以及故障发生节点两个目标,通过平均绝对误差(MAE)和均方根误差(RMSE)作为统计性能指标对结果进行评价[19]。上述指标计算公式如下:
4.1 故障时间预测
对故障时间进行预测,通过CNN-BiLSTM-Attention 模型对未聚类数据和各簇的数据中故障时间进行预测,从图11中的6张训练和测试损失函数图中得出以下结论,在故障时间预测上,聚类后的数据效果要优于未聚类的数据。
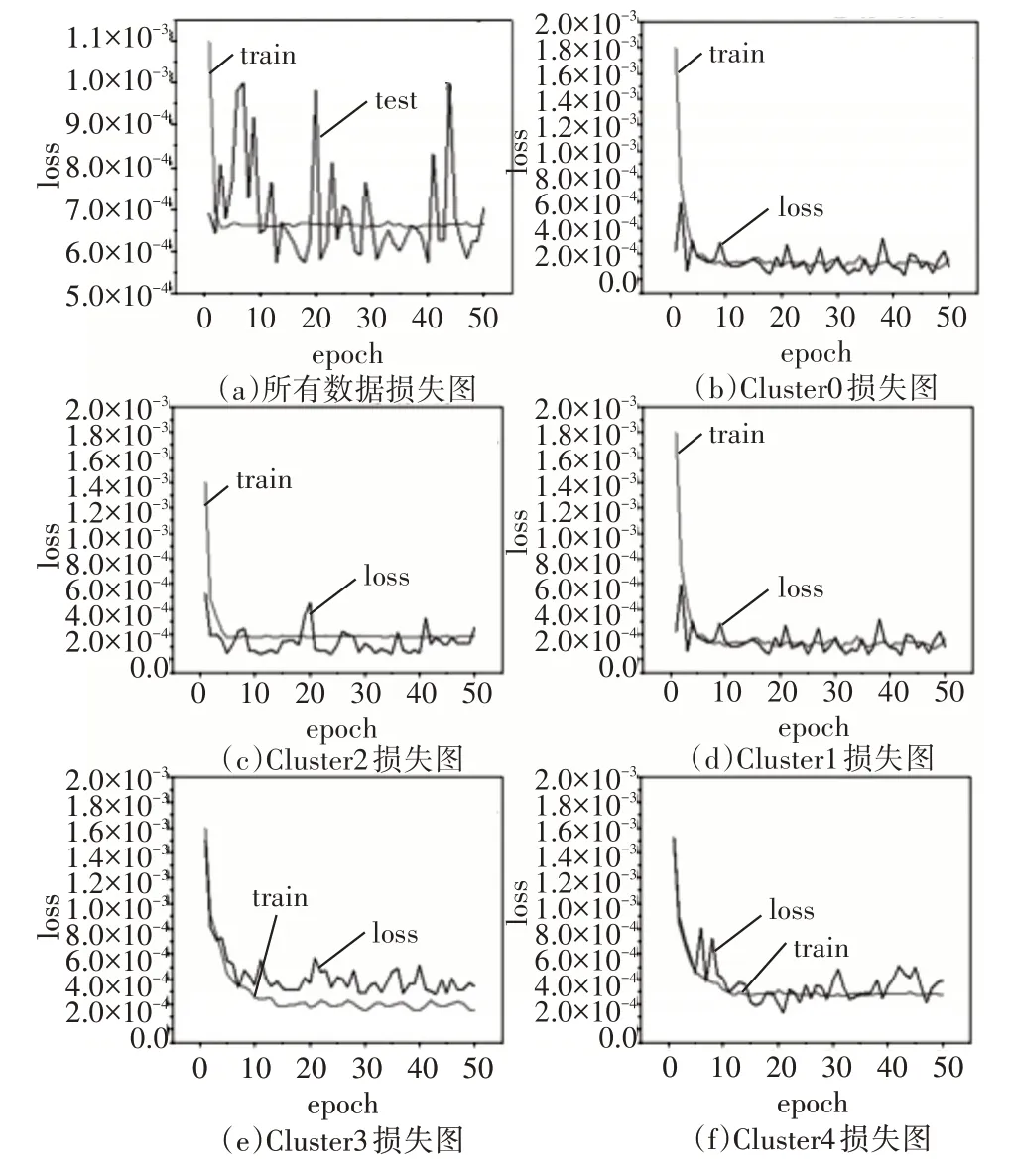
图11 预测故障时间训练和测试loss图
利用模型对未聚类数据以及聚类后数据分别进行预测,所得MAE 值最低是数据组成相对简单的Cluster3 的0.011 到最高是数据组成相对复杂的Cluster0 的0.249,所得RMSE 同样从数据组成相对简单的Cluster3 的0.135 到数据组成相对复杂的Cluster0的2.199,如表3所示,说明该模型有很好的泛化能力,预测效果很好。
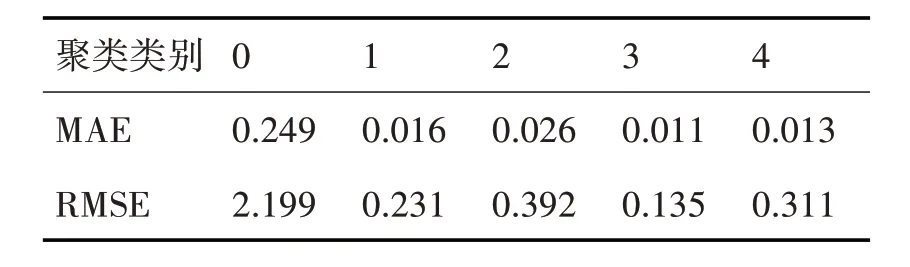
表3 模型对各类故障时间预测的评价指标
4.2 故障节点预测
对故障节点位置进行预测,预测难度比故障时间预测要大,但本模型也有不错的表现。从图12训练和预测损失图可以看出,经过聚类后的数据故障节点位置预测结果更好。
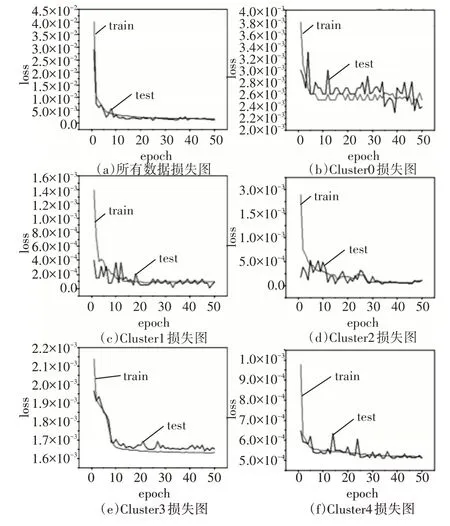
图12 预测故障节点训练和测试loss图
未经过HDBSCAN 聚类的数据,预测准确率为83.2%。利用模型对各个聚类类别分别进行预测,MAE 值、RMSE 值和准确值如表4 所示,从表中的准确率也可以看出,通过HDBSCAN 聚类后的数据预测效果明显更好。同时从各个簇的MAE 值不超过6.60,RMSE值不超过9.55,充分说明了该模型在故障节点预测上也有很好的泛化能力,预测效果同样很好。
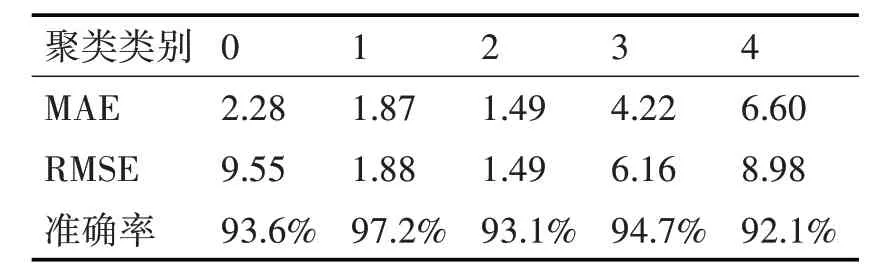
表4 模型对各类故障节点预测的评价指标
4.3 模型对比
表5 总结了CNN-BiLSTM-Attention 模型与其他模型的对比,数据使用组成相对复杂的cluster1中的数据,预测故障节点的位置,训练过程中均采用batch为256,epoch为50,其他变量均相同。

表5 CNN-BiLSTM-Attention模型的性能以及与其他模型的对比
从表5 中可以看出,其他五个模型相比,预测结果有了显著的提高。其重要原因在于CNN-BiLSTM-Attention 不仅可以很好地挖掘故障日志中的时序特征,而且注意力机制能更好地处理特征信息。因此与其他模型相比,该文提出的模型在预测大规模计算系统故障方面,优势明显。
5 结语
该模型在大规模计算系统故障预测中取得了较好的效果,对于故障发生时间预测的RMSE 值可低至0.031;对于故障发生的节点位置预测精度平均可达90%以上,这说明该模型具有很好的预测能力。未来该方法可以迁移到E 级计算机的建设和应用中,以提高系统的可靠性。
该文中的模型是基于历史故障日志数据进行预测,但在实际运行环境中需要对系统进行更低延时的数据进行故障预测,才能更有实用价值。在后续的研究中,将会进一步改进故障预测分类的细粒度和精准度,实现迁移性良好的轻量化故障预测的应用。
