样本不平衡下基于自定步调集成的液压系统智能诊断方法
2023-06-01苏颖迪沈建军
苏颖迪, 贾 峰, 杨 飞, 沈建军
(1.长安大学道路施工技术与装备教育部重点实验室, 陕西西安 710064; 2.林德液压(中国)有限公司, 山东潍坊 261061)
引言
液压传动装置结构紧凑、质量轻、体积小,实现自润滑、过载保护,传递功率多,输出力矩大,工作平稳,换向冲击小,在运动过程中能实现无级调速,加之与电气配合可实现顺序动作及远程自动化控制,因而,被广泛应用于工程机械、航空航天等领域中。目前随着现代控制系统的设备复杂化和规模大型化,液压系统作为复杂系统的子系统,其工作性能对主系统的效率、功能有着很大的影响,因此对其进行合理的故障诊断是关键问题之一[1]。液压系统的故障多由液压装置、工作介质、原动机、系统老化等引发,具有多发性、隐蔽性、不确定性、交叉性等特点,增加了液压系统故障诊断的难度。过去技术人员靠简单仪器和直接观察积累的经验诊断,随着人工智能技术和大数据综合端分析的发展及监测数据的累积,智能故障诊断方法成为液压故障诊断的新生力量[2]。
近年来,魏晓良等[3]采用卷积神经网络用于高速轴向柱塞泵的空化智能故障诊断;张轩等[4]针对液压系统内泄漏的故障诊断,提出了降维谱聚类的智能诊断方法;邱寒雨等[5]提出优化BP神经网络的方法,用于快速起竖装置的液压系统故障诊断;赵华等[6]采用故障树方法对重型液压机进行了故障诊断;张良等[7]提出将局部特征尺度分解(Local Characteristic-scale Decomposition,LCD)模糊熵和流行学习结合进行特征提取用于智能故障诊断中;LEI Yafei等[8]将PCA与XGBoost结合对液压换向阀进行故障诊断。然而,上述文献没有考虑到液压故障样本的不平衡性。在生产实际中,液压系统所采集的故障数据数量远少于正常数据[9],不同类型的液压故障发生频率也不同,样本分布产生严重的不平衡性。在样本不平衡的情况下,智能诊断模型往往容易学习到样本充裕的液压系统健康状态的诊断规则,忽略样本匮乏的健康状态诊断规则,致使样本充裕的健康状态过表达,样本匮乏的健康状态欠表达,导致训练得到的智能诊断模型在样本不平衡下的诊断精度下降。此外,现有的一些用于不平衡学习的方法可能更加注重于类别之间的不平衡,而忽视了类别之间的重叠分布,导致在高度不平衡、有噪声的液压故障诊断数据中效果不佳。
针对上述诊断过程中的问题,本研究引入“分类硬度”的概念[10]。分类硬度代表分类器正确识别故障类别的难易程度,其分布包含着诊断过程难度的信息。例如,故障数据中的噪声信号可能具有较大的硬度值,其次,故障类别重叠的程度越大硬度值越大。硬度分布的优势在于对不平衡的数据集提供更好的重采样策略,获得更好的诊断性能。基于上述概念,本研究提出基于自定步调集成(Self-paced Ensemble,SPE)的液压系统智能诊断方法。在重采样层面,提出方法不是简单地平衡各故障类别的数据或通过直接分配权重,而是考虑分类硬度在数据集上的分布,并根据硬度分布迭代地选择最详实的多数数据样本;其次,欠采样的策略由自定步调程序控制,这种自定步调的过程使模型逐渐关注更难的故障数据样本。实验中,通过对液压系统中不同故障数据集进行诊断并与其他方法对比,结果表明,该方法能够很好的实现液压系统的故障诊断,且效果优于一些传统方法。
1 基础理论
1.1 集成学习
在液压系统故障诊断中需要对样本数据分类以确定健康状态和故障类型,然而使用单一分类器进行分类可能会产生欠拟合或者过拟合的问题,为了获得诊断精度较高的模型,通过集成学习将个体分类器形成一个集成诊断模型来改善故障诊断的结果。
p(hi(x)≠f(x))=ε
(1)
若使用投票法的结合策略集成n个基分类器,则集成分类器H(x)的分类结果为:
假设各基分类器的错误率相互独立,由Hoeffding不等式可知,集成分类器的错误率为:
由式(3)可以看到,基分类器数目n增大时集成分类器的错误率不断降低,最终趋近于0,因此建立集成诊断模型的诊断效果明显优于单个诊断模型。
1.2 分类硬度分布
定义H为分类硬度函数,其中H可以是任何“可分解”的误差函数,即整体误差通过单个样本误差的总和来计算。假设F是一个经过训练的分类器,使用F(x)来表示分类器的输出概率x是一个正实例。则样本(x,y)相对于F的分类硬度定义为H(x,y,F)。
在液压系统故障数据集类别不平衡的情况下,分类硬度填补了类别不平衡率和诊断难度之间的差距。大多数情况下,即使有相同的不平衡率,不同的诊断任务也可能表现出截然不同的困难。图1展示了基于不同分类器的故障数据集的分类硬度。在图1a中,数据集由2个互不影响的类别组成,不平衡率的增长不会对诊断的难度产生太大影响;而在图 1d中,数据集是由几个重叠的类别组成,随着不平衡率的增长, 其诊断难度不断增大, 然而,不平衡率并不能很好地反映出诊断任务的难度。随着不平衡率的增大,图 1e和图 1f中的硬样本数量急剧增加,而图1b和图1c中的硬样本数量保持不变。因此,分类硬度包含故障数据集中的更多信息,并更好地指示当前诊断任务的难度。

图1 不同的类别不平衡水平下重叠和非重叠数据集的比较
由图1可知,根据其硬度值将诊断过程中的数据分为3种数据样本,即普通样本、噪声样本和边界样本[10]。
一般来说,大多数数据样本都是普通样本,可以根据当前模型进行很好的分类,如图1e和图1f中的圆形样本,每一个样本都只能产生微小的硬度。然而,由于样本数量多,总体贡献不容忽视。对于这类样本,在重采样时只需要保留一小部分样本来代表其相应分布的“骨架”,以防止过拟合,然后删除大部分样本,因为已经可以通过这一小部分样本很好地学习以进行诊断。
其次,少部分样本为噪声样本,例如图1中的五边形样本,尽管数量很少,但每一种都有很大的硬度值,因此,总贡献可能非常巨大。这些噪声样本通常是由不可区分的重叠或异常值引起的,强制诊断模型学习这些样本可能会导致严重的过度拟合。
将其余的样本,归类为边界样本。边界样本是诊断过程中信息量最大的数据样本,如图1所示,正方形样本非常接近当前模型的决策边界,增大边界样本的权重通常有助于进一步提高诊断模型的性能。
2 自定步调集成诊断方法
将SPE方法[10]用于液压系统不平衡的故障数据集中进行智能诊断,可以提高任何基分类器(例如C4.5,SVM,GBDT和神经网络)在诊断过程的性能,同时具有非常高的诊断效率。与现有诊断方法相比,SPE具有准确、快速、鲁棒性好和自适应等优点,与当前流行的方法不同,提出方法不需要任何预定义的距离度量,其诊断过程如图2所示。首先将多数类样本集根据不同的硬度等级分为k个容器,然后欠采样策略尝试均衡化每个容器对分类硬度的贡献,即重采样后每个容器中的样本硬度总和一致。在训练过程中不断更新自步因子,用来降低样本数量过多的容器的采样权重;经过n次迭代形成最终的集成诊断模型。
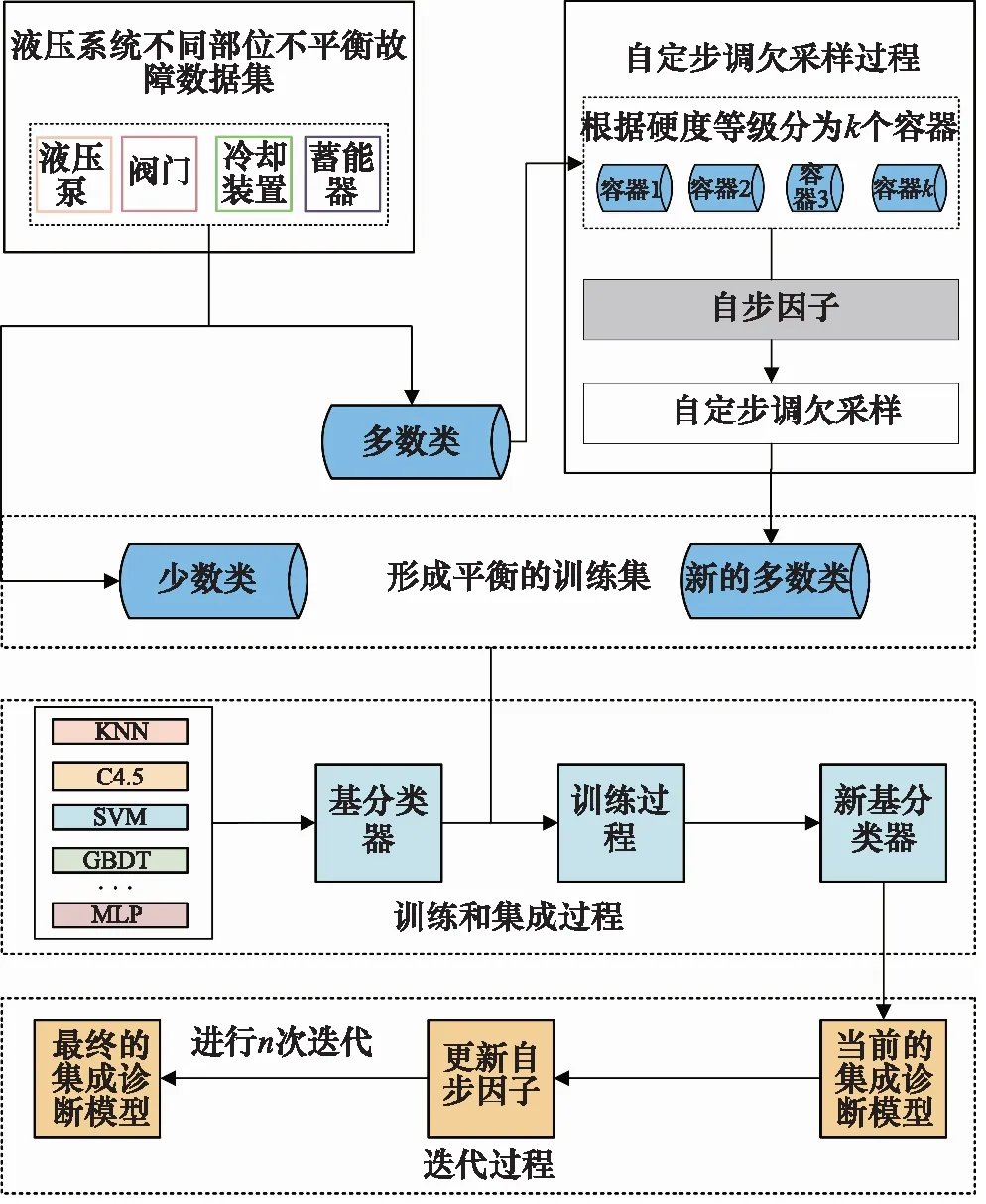
图2 自定步调集成诊断方法
2.1 自定步调欠采样
提出方法的核心目标是设计一种新的欠采样机制,以减少琐碎样本和噪声样本的影响,同时扩大边界样本的重要性。因此,引入“硬度协调”的概念和一个自定步调的训练程序,以实现这一目标。
1) 硬度协调
根据硬度值将液压系统不平衡数据集中的多数类样品分成k个容器,其中k是一个超参数。每个容器指示一个特定的硬度等级,通过保持每个容器中的总硬度贡献相同,将多数类样本欠采样到一个平衡的数据集中。这种方法在基于梯度的优化被称为“协调”,其协调了神经网络批量训练中的梯度贡献。在提出方法中,采用了类似的想法来协调第一次迭代中的硬度,但并不是简单的在所有迭代中使用硬度。主要原因是,由于集成诊断模型会逐渐适应故障数据集,在诊断过程中,普通样本的数量会增加,简单的协调硬度贡献仍然会留下许多微不足道的样本。这些样本在以后的迭代中大大减慢了诊断过程,因为其提供的信息较少,因此,引入“自步因子”,在采样条件下执行自配速协调。
2) 自步因子
在均衡每个容器的硬度贡献过程中,自步因子α用来逐渐降低样本数量多的容器的样本概率,并控制降低的水平。当α变大时,更多地关注硬度高的样品,而不是简单的硬度贡献。在最初的几次迭代中,诊断模型主要关注那些信息丰富的边界样本,因此异常样本和噪声样本对模型的泛化能力没有太大影响。同时,在α非常大的后期迭代中,诊断模型仍然保留了相当一部分普通样本,这有效地防止了其过拟合。
2.2 诊断过程
记液压系统样本不平衡数据集X的类别为t,其类别样本集为C1,C2,…,Ct,其中样本数量最少的类别子集为Cm的样本数量为:
对多数类样本进行随机欠采样,记多数类样本集Cq在采样的过程中所生成的新子集为Nq,q=1,2,…,t将新子集样本数量记为|Y|,则:
|Y|=|X|
(5)
将采样过程的多数类样本集Nq与少数类样本子集Cm结合成平衡样本子集Dm,即:
Dm={Cm,Nq}
(6)
使用平衡样本子集Dm进行训练得到基分类器f0,则定义第j(j=1,2,…,n)次迭代时的集成分类器为:
之后定义Bi为第i个容器的硬度值,则:

H∈[0,1]
(8)
根据第j次迭代的硬度分布H(x,y,Fj)将多数类样本集Nm分为k个容器:B1,B2,…,Bk,平均第i(i=1,…,k)个容器的硬度贡献:
hi=∑s∈BiH(xs,ys,Fj)/|Bi|
(9)
定义第一次迭代时自步长因子为0,最后一次迭代为∞,迭代过程中不断更新自步长因子:
则第i个容器的非标准化采样权重为:
从第i个容器中进行欠采样,欠采样的样本数目为:
最后使用新得到的欠采样子集训练基分类器fi,则最终的集成诊断模型为:
2.3 模型评估指标
传统的分类学习中,常用精确度作为评价指标,精确度表示分类正确的样本在总样本数量的比例,但在样本不平衡的情况下,通常主要关心样本少的那一类是否分类正确,而如果分类器将所有样例都划分为数目多的那一类,就能达到很高的精确度,但实际该分类器没有任何效果。在液压系统的样本不平衡时,可以使用混淆矩阵、精准率、召回率、F1值作为诊断方法的评估指标。
将液压系统不平衡的故障数据集根据真实类别和通过集成诊断模型预测的类别可化分为真正例(TP)、假正例(FP)、真反例(TN)、假反例(FN)4个样本子集。
精准率可定义为:
召回率定义为:
F1值定义为:
3 实验与分析
3.1 数据集描述
使用UCI公开数据集[11]对提出方法进行验证,该数据集通过多个传感器对液压实验台进行监测来获取,实验台由一次工作回路和二次冷却过滤回路组成,并通过油箱连接。系统循环重复恒定负载循环(持续60s),并测量压力、体积流量和温度等过程值,同时4个液压元件(冷却器、阀、泵和蓄能器)的状态是定量变化的[11],其液压系统如图3、图4所示。
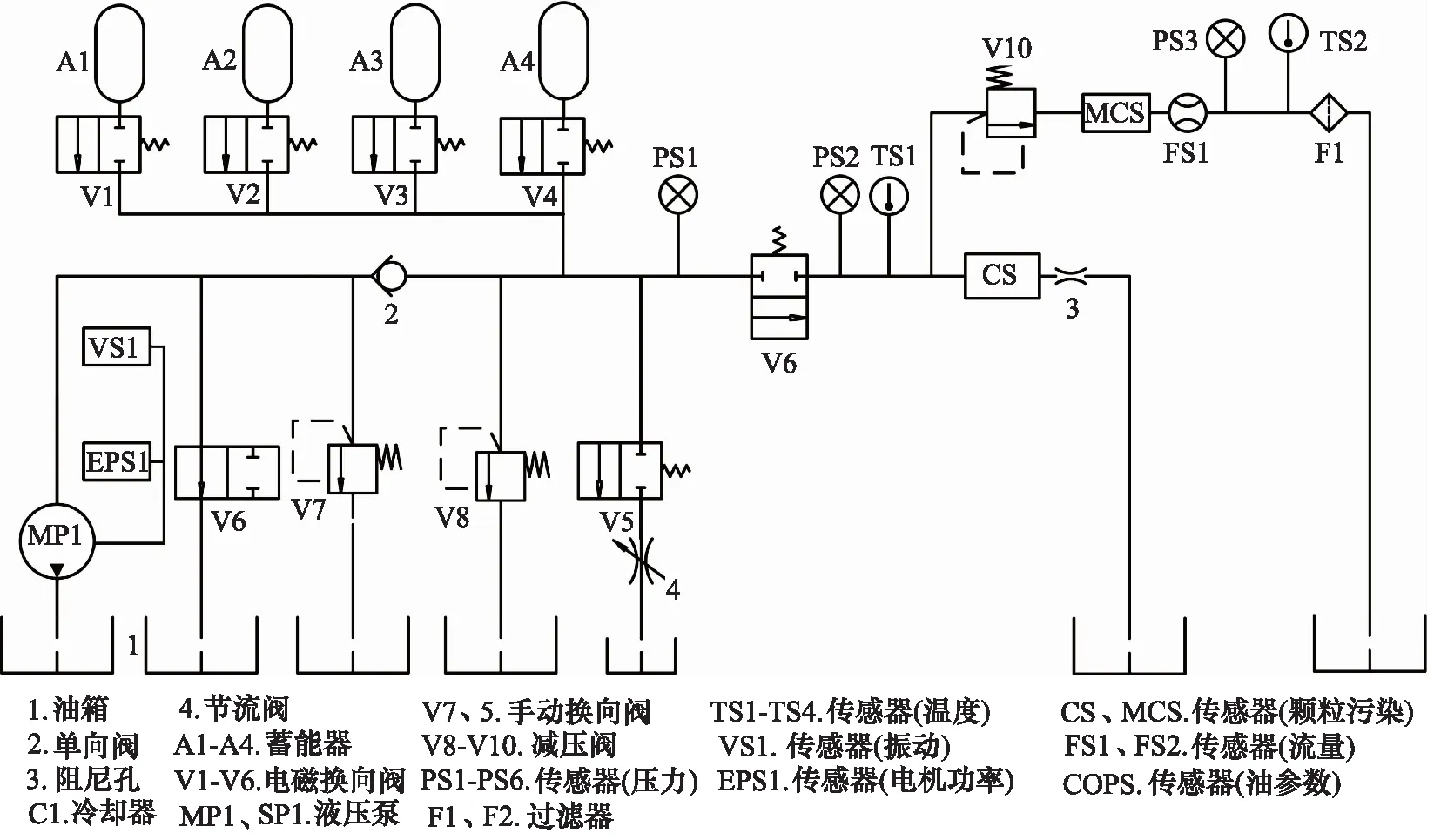
图3 液压系统主泵MP1回路

图4 液压系统带有冷却器C1的冷却和过滤回路
液压系统故障数据通过多个传感器获取,实验使用的传感器情况如表1所示。通过传感器分别获取了液压泵、冷却装置、蓄能器、 阀门等4个不同部件的数据样本,其所对应的标签及样本数量情况如表2所示。后续实验将50%样本划分为训练集,剩余50%划分为测试集。
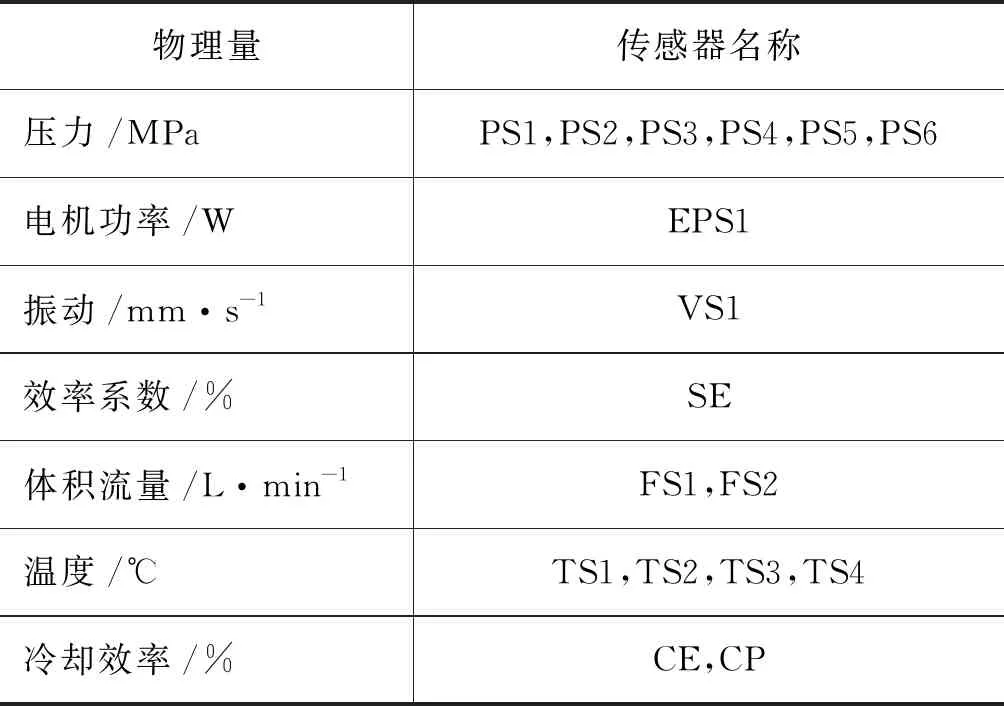
表1 传感器情况
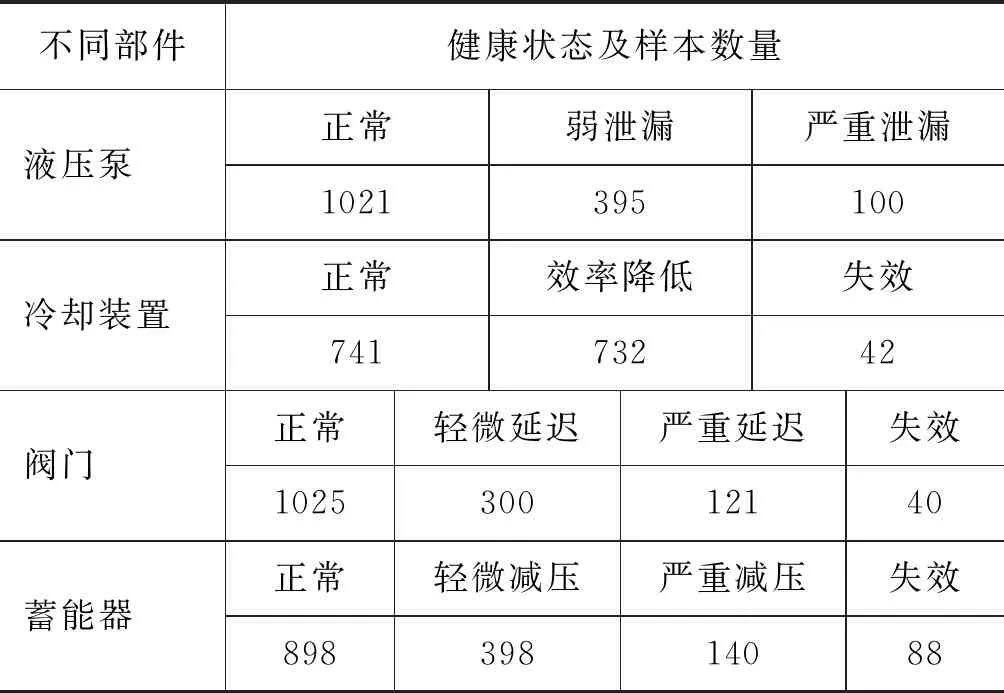
表2 数据集描述
3.2 实验分析
分别在液压系统4个不同部件进行多组不同的实验与其他不平衡样本下的诊断方法进行比较,并以多种评估指标来评估实验结果,以证明提出方法的可行性。
1) 实验1
本次实验分别在液压系统4个不同部件使用提出方法进行故障诊断,以证实提出方法适用性。图5为4个部件诊断结果。

图5 不同部件数据集的故障识别混淆矩阵
从图5可以看到使用提出方法对液压系统不同部件的诊断结果其平均精度都达到了92%以上,其中液压泵的平均精度为94.6%,冷却装置为98.0%,阀门为92.5%,蓄能器为92.5%;并且各部件的不同故障类别的识别精度也基本在90%以上。这表明提出方法对于液压系统不同部件的健康状态以及故障类型的识别均有很好的效果,因此可以适用于液压系统各不同部件。
此外,在方法介绍中提到自步因子是提出方法非常重要的因素,因此分别在4个部件进行实验,来说明自步因子对诊断精度di的影响,结果如图6所示。可以看到,随着自步因子迭代次数的增加,4个部件的诊断精度在不断提高,但同时精度上升的幅度在减小,表明自步因子迭代次数越多诊断精度越高,但迭代次数达到一定的次数,诊断精度上升趋于平稳。这是因为,随着自步因子迭代次数的增加,诊断模型更多的关注硬度高的样本,因此诊断精度在迭代的前、中期提升明显,在后期提升逐渐平稳。

图6 不同部件的诊断精度与自步因子的关系
2) 实验2
上述实验中,已经证实了提出方法可以用在液压系统不同的部件中,由于篇幅有限,后续实验以液压泵数据集为例。
本次实验将所提出方法与常用的不平衡学习的诊断方法进行比较,以F1值作为评估指标,这些方法具体如下:领域清理(Neighborhood Cleaning Rule Based Under-sampling,NCL)[12];合成少数类过采样法(Synthetic Minority Over-sampling Technique,SMOTE)[13];简易集成法(Easy)[14];平衡级联(Cascade)[14]。
此外,提出的SPE方法能够与任何类型的基分类器一起工作,并以特定于模型的方式优化最终的诊断性能。因此,引入了5个标准的基分类器来测试不同不平衡学习方法的有效性和适用性:K近邻(K-Nearest Neighbors,KNN)[15]、决策树(Decision Tree,DT)[16]、支持向量机(Support Vector Machine,SVM)[17]、多层感知机(Multi-Layer Perceptron,MLP)[18]、随机森林(Random Forest,RF)[19]。
从表3可以看到,SPE在使用5种不同基分类器的液压泵故障数据集上诊断结果始终优于其他方法。其中的一些方法当与特定分类器(如SMOTE+KNN,NCL+RandForest)合作时,基于距离的重采样会导致较差的结果,忽视基分类器能力的差异是导致这些重采样方法效果不佳的主要原因。与其他方法相比,不平衡学习方法Easy和Cascade获得了更好、更鲁棒的性能,但仍然比提出的集成诊断方法SPE差。综上可以得出,SPE可以与不同的基分类器配合用于液压系统的故障诊断中且诊断效果好,相较于一些常用的处理样本不平衡的诊断方法,诊断效果更优。

表3 不同基分类器下各不平衡学习方法在液压泵故障数据集的诊断结果
3) 实验3
上述实验验证了在不同基分类器下提出方法诊断效果优于其他用于不平衡学习的诊断方法。本次实验设置在不同的基分类器数量下,将提出方法与4种基于集成学习的故障诊断方法进行比较,并以精准率、召回率和F1作为评估标准。
2种基于欠采样集成的方法:RUSBoost[20],使用随机欠采样(Random Under-sampling,RUS)和自适应提升算法(AdaBoost),通过删除多数类样本来更好地对少数类进行建模使数据平衡达到诊断的目的;UnderBagging[21],使用随机欠采样获得每一个用于装袋的Bagging[22],然后建构集成诊断模型。
2种基于过采样的集成方法:SMOTEBoost[23],在AdaBoost管道的每次迭代中,应用SMOTE生成新的少数类样本;SMOTEBagging[24],结合了SMOTE与Bagging,先使用SMOTE生成少数类数据,然后应用Bagging集成进行诊断。
如表4所示,可以看到与其他2种基于欠采样的集成诊断方法相比,SPE在3个评估标准上有显著优势;与2种基于过采样的集成方法相比,SPE的评估效果虽然略好,但由于过采样的方法在高不平衡率下需要生成大量新样本,因此增加了诊断时间,导致诊断效率低下。此外,可以看到随着基分类器数量的增长,诊断的精确度在不断上升,正如式(3)所示,“好而多”的基分类器有助于集成模型的诊断结果,因此可以在适当的诊断时间下选择更高的基分类器数量。
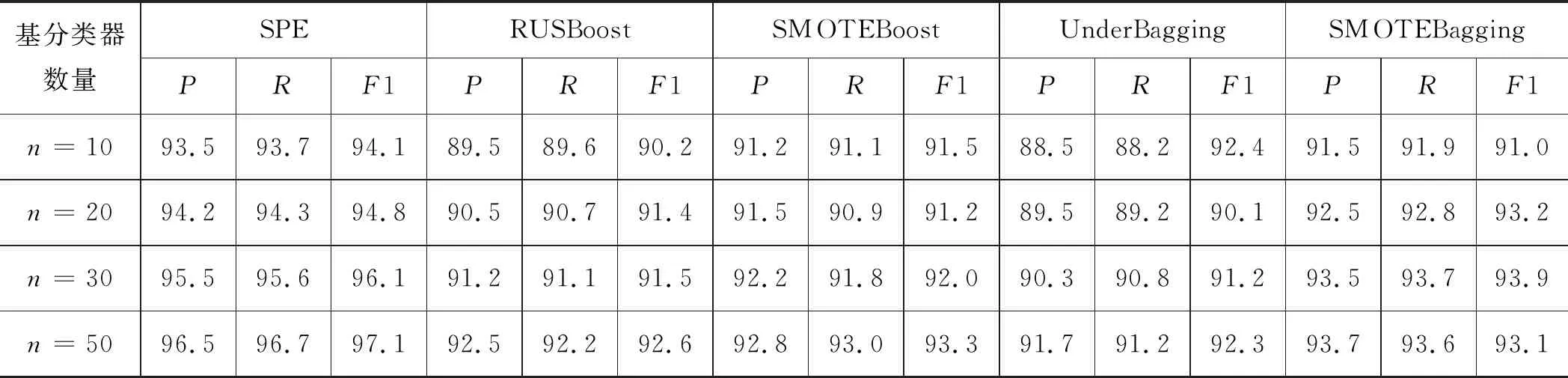
表4 5种基于集成学习的不平衡故障诊断方法不同基分类器数量下液压泵故障数据的诊断结果
4 结论
(1) 针对液压系统故障诊断的样本不平衡问题,本研究提出了一种SPE的液压系统智能诊断方法,引入了分类硬度分布的概念,通过根据多数类样本的分类硬度实现自定步调的欠采样, 并更新自步因子进行多次迭代实现最终的集成诊断模型,与传统诊断方法相比,SPE不需要任何预定义的距离度量或计算,因此更易于应用,诊断效果也更好;
(2) 使用UCI公开的液压数据集,分别作用于液压泵、冷却装置、阀门、蓄能器4个部件中进行实验,验证了提出方法的可行性,且与传统诊断方法相比,提高了诊断的精度。
