基于双重匹配注意力网络的观点型阅读理解
2023-05-31蔡子阳陈志豪杨州苏艺淞廖祥文
蔡子阳,陈志豪,杨州,苏艺淞,廖祥文
(福州大学计算机与大数据学院,福州大学福建省网络计算与智能信息处理重点实验室,数字福建金融大数据研究所,福建 福州 350108)
0 引言
机器阅读理解(machine reading comprehension,MRC)旨在让模型能够对文章进行阅读,然后根据文章对问题进行回答[1].其中,是非类观点型阅读理解是针对观点极性进行分析的子任务,模型需要从文章中抽取与问题相关的观点证据,根据观点证据从“可以、不可以、无法确定”3种基本观点倾向中做出正确选择,其本质上是一个分类任务.相比于传统阅读理解任务,问题观点极性可能不会出现在对应文章中,需要进行推理才能获取,因此观点型阅读理解任务更具挑战性[2].
目前MRC工作主要可以分为3类: 1)基于深度学习的方法.将神经网络和注意力机制[3]进行结合,引入结构信息[4]等对文本语义信息进行建模,构造启发式文本表示.2)基于预训练加微调模式.许多模型[5-6]经过大规模数据集预训练之后,拥有强大的语义表示能力,能够极大提升各类NLP下游任务的效果,使其逐渐成为各类先进模型[7]的主干网络.3)基于文本语义匹配的方法.在预训练模型强大的语义表示能力基础上,利用多种注意力变体对问题和文章进行单向[8-9]或双向[10-11]匹配,强化问题文章之间的信息融合.目前观点型阅读理解还面临以下挑战[2]: 模型对于问题和文章的理解往往局限于部分文本片段之间的匹配关系,无法正确获取全局观点极性以及语义信息.因此,本研究提出一种基于双重匹配注意力网络的观点型MRC方法.具体来说,在对问题与文章的理解过程中,引入基于动态匹配和多维度匹配的双重匹配机制.动态匹配应用于捕捉全局观点信息,多维度匹配则致力于抽取不同层次语义信息,然后加入交互式多路注意力(interactive multiple attention,IMA)机制,将收集到的观点信息和语义信息通过注意力策略交互总结,共同构建问题和文章之间的信息关联,最终获取全局的观点极性.通过实验,证明该方法在观点型阅读理解任务上的有效性,同时这种基于匹配和交互的方法也为MRC问题的解决方案提供一种新思路.
1 相关工作
近年来,随着深度学习持续发展,以及各种大型数据集如SQuAD 2.0[1],ReCO[2]的提出,机器阅读理解任务的研究不断深入.目前的MRC方法主要从以下3个方面展开研究: 基于深度学习的方法、基于预训练微调模式和基于文本语义匹配的方法.
1) 基于深度学习的方法.深度学习的提出以及注意力机制的引入,极大地促进了自然语言处理模型的发展,涌现出许多表现出色模型.图注意力网络[4]将注意力与图结构进行融合,利用图中节点和边的关系高效地表达了文本语义信息,能够使信息的流动更加的有目的性、针对性;对文本表示添加文本实体图结构进而构建动态文本图,用以更新上下文嵌入表示的DCGN[12]模型.利用协同注意力学习问题和文章间的关联信息以及依赖关系并将其进行融合的CARC[13]模型.
2) 基于预训练加微调模式.在大型数据集上训练的模型,基于转换器的双向编码表征模型(bidirectional encoder representation from transformers,BERT)[5]就是典型例子,BERT对于自然语言处理任务的影响非常深远,后来许多预训练模型都是基于BERT所做出改进.如XLNet[6]结合了自回归和自编码的优点,将相对位置编码和片段循环机制进行集成,提出了Transformer-XL,使其在长文本处理上有非常好的表现.有了预训练模型,便可在下游任务根据特定任务进行微调,如以重叠窗口切割输入文本,并用递归方式传递文本片段信息从而赋予模型处理长文本能力的BERT-FRM模型[9].
3) 基于文本语义匹配的方法.文本之间的匹配主要是利用各类注意力机制变体计算文本之间相似性,对文本之间的上下文信息进行充分学习.如结合了按照行和列方式进行注意力计算、进而对模型预测出的答案进行再次验证的二维匹配模型 AOA Reader[10];先对问题、文章、选项三元组进行两两双向注意力匹配,然后配合段句选择和选项融合策略模拟人类思考,最后利用双向匹配模块预测答案的DCMN+[10]模型;结合动态双重注意力和多层级联答案预测、强化问题和文章信息融合、对答案进行多元化预测的 RikiNet模型.
总的来说,上述这些方法能够使用注意力机制捕捉到文本局部信息,但是未能综合全局语义信息,基于片面信息做出的预测,往往导致结果具有片面性.为了解决这个问题,本研究提出双重匹配和IMA方法,以预训练模型为基础,搭配两种不同匹配机制,结合交互式多路注意力机制,使模型对文本全局语义信息更加敏感,能够从多方面各角度理解文本,提取全局观点信息.
2 问题形式化描述
观点型阅读理解是指根据文章内容,从选项中选取符合问题的观点倾向,本质上是一个分类任务.任务形式化定义如下: 对于给定的文章(P)和对应的问题(Q),模型需要根据文章内容判断问题答案的观点倾向(A).文章P和问题Q是由若干个单词组成的一段文本序列,记为P={p1,p2,…,pm},Q={q1,q2,…,qn},pi和qi分别代表文章和问题中的单词;m和n分别代表文章和问题中单词数量.答案的观点倾向A={a1,a2,a3}为3种不同的观点类别,其中,a1、a2、a3分别对应: 是、否、不确定.模型最终目的就是要预测一个概率分布P(A|P,Q),即选出概率最大的ai作为最终预测结果.
3 模型
模型结构如图1所示,主要由以下4个模块组成: 1) 编码层.使用预训练模型BERT作为编码器,将输入的文章、问题、选项进行编码,得到各自包含上下文信息的表示.2) 双重匹配层.采用动态和多维度两种匹配机制分别抽取观点信息和语义信息,构建问题和文章的全局关联.3) 交互多路注意力层.利用不同多头注意力机制缩放点积注意力(scaled dot-product attention,SDA)和负注意力(minus attention,MA),从两个方向对文章和问题进行二次交互,获取问题启发式文章表示和文章启发式问题表示.4) 输出层.基于POI-Net网络,将文章和问题表示进行特征融合,获取全局观点信息,然后再结合选项表示中的观点信息进行推理预测,输出3种观点极性概率分布.全局语义信息的理解和抽取是现有观点型阅读理解问题的研究重点,所以本节主要对后3个模块依次进行说明.
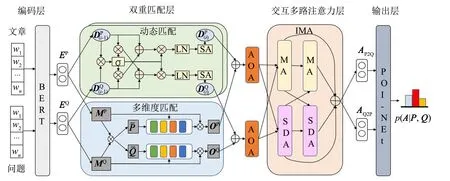
图1 模型整体结构图Fig.1 Overall structure of model
3.1 双重匹配层
双重匹配层能够对文本进行细粒度、全局化抽取,包含两种匹配机制: 动态匹配和多维度匹配.动态匹配通过迭代融合方式抽取全局观点信息,多维度匹配则是在不同层次的特征空间上计算语义信息,最后将两种信息拼接送入AOA模块进行二次信息筛选,得到两种信息的简单融合表示.
3.1.1动态匹配
动态双向匹配模块输入是问题表示EQ和文章表示EP,通过计算两者之间的关联矩阵进行信息交互,再经过自注意力机制控制信息融合.为了能够获取全局观点信息,本研究将这一过程进行迭代,每个迭代过程获取部分观点特征,将所有观点特征归纳生成全局观点信息.

(1)
得到权重矩阵之后,接下来就可以计算问题启发式文章表示.提取文章中与问题相关的信息,然后与原始问题表示相综合得到整体问题信息,接下来将相关问题信息融入到文章表示中,最后再进行自注意力计算得到问题启发式文章表示.即

(2)

(3)

3.1.2多维度匹配
该方法的输入为BERT输出的问题表示EQ和文章表示EP、先将两者进行线性映射得到MQ和MP,然后计算问题和文章之间的相似矩阵S.即
S=MP(MQ)T
(4)
同样的,对相似矩阵进行行和列归一化,再分别与原始问题和文章表示进行交互得到注意力信息.得到注意力信息后就能进行多维度匹配,将注意力信息与原始表示进行结合,在四种不同维度层次上进行交互,得到不同层次语义信息.
由于文本信息存在着噪声,在综合不同层次语义信息后,需要对语义信息进行过滤去噪,所以需要引入门控机制,对信息流进行控制.有门控机制对信息流进行过滤后,将信息与原始表示进行融合,得到新的表示.即
gP=Linear(CP)
(5)
OP=gPMP+(1-gP)CP
(6)
其中:gP是一个范围在0到1的系数;Linear(·)是线性映射函数.通过类似的方法,重复公式(5)~(6)可以获得问题表示OQ.
得到了两种匹配方法结果后,需要对结果进行二次筛选,检查信息有效性.使用的方法是AOA Reader,即将匹配结果各自送入AOA模块中进行信息二次过滤,然后进行拼接融合.则有
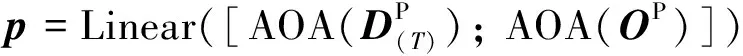
(7)
其中:p∈Rm×d代表最终文章表示;AOA(·)代表的是AOA Reader.通过类似方法,可以得到最终问题表示q∈Rn×d.经过了两种匹配方法筛选过滤后,问题和文章表示都包含了全局观点信息和多维度语义信息,接下来就要将两种信息进行深层次融合.
3.2 交互多路注意力层
交互多路注意力层模拟人类思考方式,对观点信息和语义信息进行深层次融合.使用两种不同注意力函数来实现交互多路注意力层: SDA和MA.首先需要将输入的Query、Key、Value对于不同注意力机制映射到不同的特征空间,然后再进行注意力计算.
对于SDA,其计算方式定义为
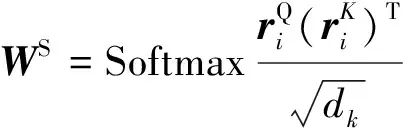
(8)

(9)

对于MA,其计算方式定义为

(10)

(11)

接下来在第一次注意力计算结果上进行交叉计算,即
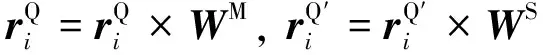
(12)

A=[AS+AS′;AM+AM′]
(13)
上述过程是一个方向的计算流程,如果只有单方向的计算则会损失文本语义信息,所以需要进行双向注意力机制,即问题对文章注意力,记为Q2P,以及文章对问题注意力,记为P2Q.对于Q2P的输入,k=q,v=p;而对于P2Q的输入,k=p,v=q.计算完多路注意力之后,再分别对结果进行最大池化,得到AQ2P和AP2Q.两个方向注意力计算能够同时提取文章和问题中的信息,确保模型提取信息全面性,消除预测片面性.
3.3 输出层
将交互式多路注意力层生成的表示经过POI-Net网络,进一步将问题和文章的信息进行特征融合,即
r=POI-Net(AQ2P,AP2Q)
(14)
其中: POI-Net(·)代表POI-Net网络,是一个轻量级的判别式阅读理解模型框架[14].
选项当中是有明确观点信息,将选项观点倾向与模型得到的全局观点信息进行对比结合,就能够进行推理判断.在编码层得到的选项表示EA∈R3×d代表3种不同观点倾向,将融合层得到的r与之对比,则有
c=CS(EA,r)
(15)
s=r×c
(16)
其中: CS(·)表示的是余弦相似度.通过选项表示辅助,计算观点极性概率分布情况,则有

(17)
概率最高选项作为最终预测答案.模型使用的损失函数为交叉熵函数,通过最小化交叉熵损失函数提升模型预测准确度,损失函数定义为
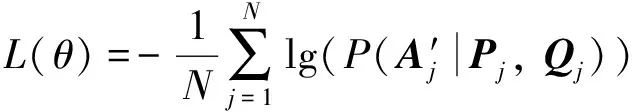
(18)

4 实验结果及分析
介绍实验所涉及数据集、评价指标、基准模型以及参数设置.通过与基准模型对比,展示本研究模型效果,并对各个模块及参数进行分析.
4.1 实验数据集
该实验在两个数据集上展开: ReCO[2]和Dureader[15].ReCO数据集是基于观点型问题的大型中文数据集,其中数据是来自搜狗搜索引擎中用户真实问题以及网页内容,经过人工核查组织得到.ReCO数据集大小如表1所示.Dureader数据集则是基于Dureader的中文观点型阅读理解数据集,数据样本是来自百度搜索引擎的用户搜索及文档,其相关数据亦列于表1.

表1 ReCO和Dureader数据集的统计信息
4.2 评价指标
采用分类问题常用评价指标来验证模型有效性,分别是准确率(accuracy,ACC)和加权宏F1值(Weighted-F1),准确率能够衡量模型总体正确率,F1值则兼顾召回率和精确率,并且考虑了不同样本之间的重要性,这两个指标能够全面评估模型性能.具体计算公式如下:
其中:N代表总样本数量;n代表预测正确样本数量;ni代表第i类样本数量;C表示分类总类别数量;Wi代表第i类样本数量占总样本数量的比重;F1i代表第i类F1值.
4.3 基准模型
为了验证模型有效性,选择以下几个基准模型进行对比实验.
1) BiDAF[9]是一个基于双向注意力流的网络.对所给文章和问题之间进行交互,将问题信息嵌入到文章中去,然后采用多阶段、层次化处理,使得可以捕获原文不同粒度特征.
2) DCMN+[10]是一个针对多项选择阅读理解任务的预训练微调方法.以大规模预训练模型作为前端编码器,使用双向匹配策略,对问题、选项、文章进行两两双向匹配,进一步提升模型的性能.
3) BERT[5]是一个大规模预训练语言表征模型.采用MLM方式进行预训练,并利用Transformer Encoder组件构建模型,生成深度双向语言表征.
4) POI-Net[14]是一个针对判别式阅读理解问题的轻量级网络.模型首先将词性信息融合到词的表示当中,然后通过预交互层抽取文本中关键信息;利用关键信息进行若干层次迭代,模拟人类对问题重复思考,最后经过注意力策略综合所有关键信息对问题答案进行预测.
4.4 模型参数设置

表2 模型的超参数值
本研究模型使用的编码器为BERTbase,在BERT生成的上下文表示上进行建模,然后经过微调得到最终模型.模型最大输入序列长度为512,即选项、问题、文章拼接总长度不超过512,超过512长度的样例做截断处理.模型中使用的优化器是AdamW优化器.具体超参数设置如表2所示.
4.5 实验结果
本小节对模型效果进行验证并加以分析,主要包括实验结果对比、消融实验结果以及动态匹配层数分析.
4.5.1实验结果对比
实验结果如表3所示,对比基准模型,本研究模型取得了更好结果,证明其有效性.相比于同样使用迭代匹配进行文本上下文信息抽取的POI-Net模型,本研究模型在ReCO数据集上准确率提升1.18%,F1值提升1.16%;在Dureader数据集上准确率提升0.84%,F1值提升0.75%.这是由于本研究提出的方法对文本信息进行更加细粒度划分,引入双重匹配机制分别处理文本观点信息和语义信息,同时使用IMA模拟人类对问题的重复思考过程,进一步过滤噪声信息,增强模型对文本整体上下文信息的感知,可以更加精确地抽取并利用观点证据进行观点倾向判断,从而取得较好效果.

表3 ReCO和Dureader数据集上的实验结果
4.5.2消融实验结果
为探究双重匹配策略是否比单重匹配方法效果更好,单独移除方法中的模块进行对比试验.实验分为3部分: 1) 对于动态匹配性能分析,探究动态匹配对于全局观点捕捉的作用;2) 对于多维度匹配性能的分析,探究多维度匹配对于模型对文本不同层次语义信息的理解,研究不同层次语义信息理解对于模型的影响;3) 对于IMA模块性能的分析,探究IMA机制对文本信息理解的影响.实验结果如表4所示,可以看到分别去除动态匹配模块、多维度匹配模块、IMA模块,都使模型性能有不同程度的下降,证明了3种模块对于解决观点型阅读理解问题都具有良好的效果.综合来看,只有将两种匹配机制结合起来,同时搭配交互式多路注意力机制,才能够充分利用文本上下文信息,加深模型对整体文本理解,从而使模型能够更加准确有效地对观点极性进行预测.

表4 不同模块对实验结果的影响
4.5.3动态匹配层数分析

图2 不同动态匹配层数的影响Fig.2 Influence of different dynamic matching layers
动态匹配模块是通过多层迭代,深化问题和文章间交互,从而实现全局观点信息提取,考虑到不同迭代层数对文本之间交互可能会起到不同作用,因此通过实验探究动态匹配模块迭代层数对于模型最终预测结果影响.
实验结果如图2所示,从图中可以看出双层迭代效果明显比单层迭代以及多层迭代更加突出,并且在双层之后模型性能呈现下降趋势.这可能是由于单层迭代对于文本匹配还停留在较为表面的层次,未充分理解文本,还不足以捕捉问题和文章全局观点信息;而多层迭代则过度关注全局观点信息,对文本过度解读,反而给已经有良好表现的文本表示带来干扰信息,因此导致模型预测性能下降.基于上述分析,本研究最终使用了双层动态匹配结构.
4.5.4多头注意力性能分析
IMA机制中的SDA和MA能够通过不同注意力头数在不同子空间中获取特征信息,为了探究其在本研究提出模型中的有效性,本节测试了不同注意力头数对模型预测性能的影响.实验结果如图3所示.

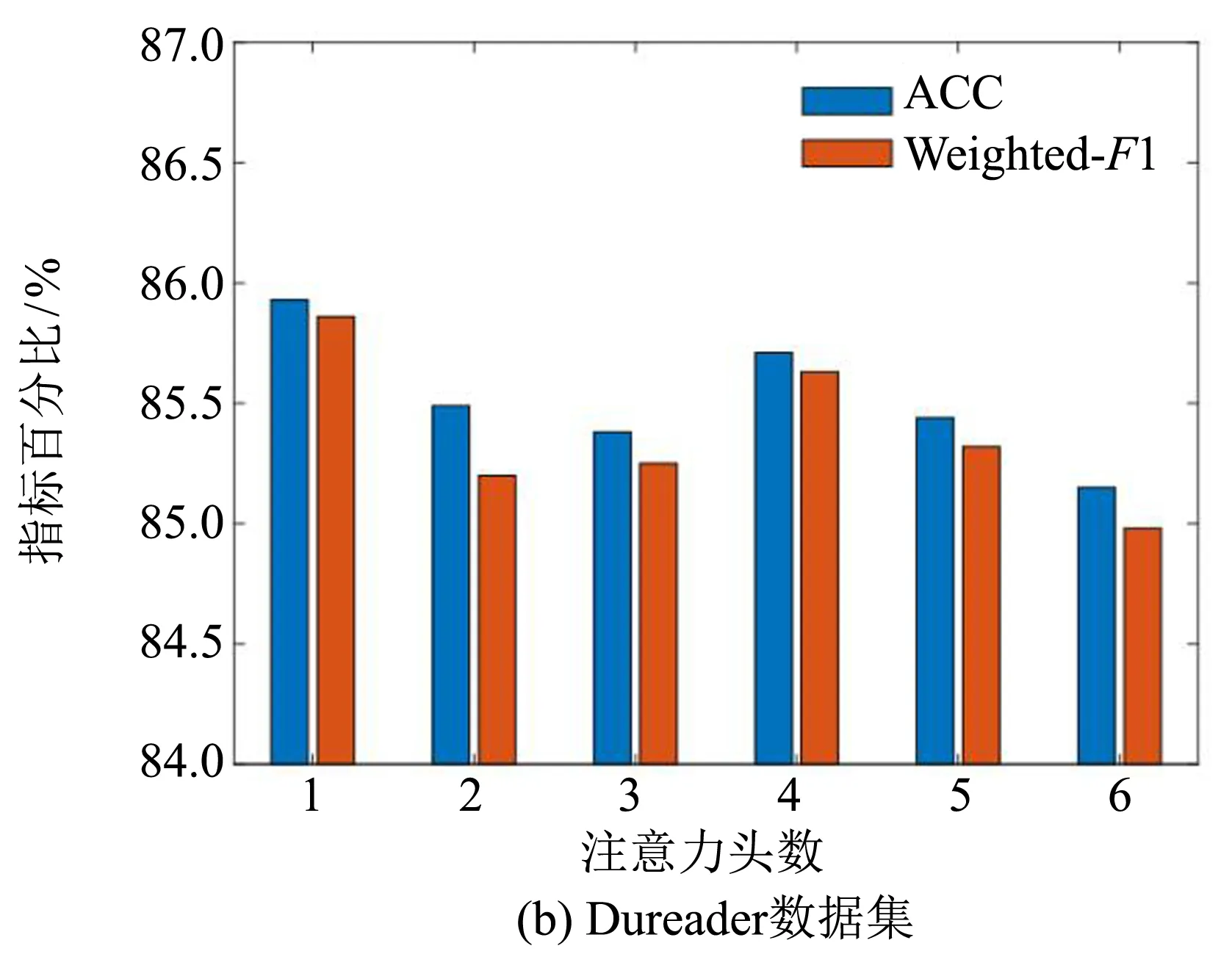
图3 不同注意力头数的影响
从图3中可以看到单注意力头对模型性能提升最为明显,随着注意力头数的增多模型效果呈现下降趋势.这可能是由于双重匹配已经在全局以及不同特征空间上进行信息抽取,所得到的信息较为充分完整,而多头注意力则会将完整信息进行分割,导致信息碎片化,不利于整体信息解读,因此使模型预测效果下降.基于上述分析,本研究最终使用了单注意力头的IMA机制.
5 结语
针对现有方法无法正确提取全局观点极性的问题,提出一种基于双重匹配注意力网络的模型.主要创新点在于提出动态匹配机制、多维度匹配机制及IMA机制,提取文本观点信息和语义信息,对文章和问题之间的关系进行全局多角度建模;充分挖掘二者间潜在特征信息,模拟人类思考模式对文本信息进行交互.在ReCO和Dureader两个大型观点型阅读理解数据集上的实验结果表明,对比基准模型,该模型有更好表现.此外,本研究还对双重匹配机制中各模块作用进行了分析,探究了动态匹配、多维度匹配和IMA对模型的影响,证明了3种机制的有效性.
