基于BERT-CNN 编码特征融合的实体关系联合抽取方法
2023-05-30丁建立苏伟
丁建立,苏伟
(中国民航大学计算机科学与技术学院,天津 300300)
在“互联网+”时代,如何高效地组织信息以方便人们获取和使用,成为众多学者研究的课题。2012年,谷歌针对其搜索引擎优化提出了用于语义搜索的知识图谱,该技术常用于多源异构的数据融合,可为用户在海量信息中提供快速、准确的语义关联信息。作为知识图谱的基本组成单元,实体关系三元组的主要获取方式包括基于传统机器学习和基于深度学习的实体关系抽取。基于传统机器学习的实体关系抽取模型由于其前期需要人工设计特征与核函数,具有主观性强且工作量大的缺点,已逐渐被深度学习模型所取代。
依据实体和关系类型是否预定义,基于深度学习的实体关系抽取方法分为特定领域的实体关系抽取和开放领域的实体关系抽取。开放领域的实体关系抽取虽然不需要领域专家来预定义实体与关系类型,但需要应对自然语言中多种多样的实体和关系,且提取到的实体和关系还需进行预处理才能应用到下游任务。因此,特定领域的实体关系抽取仍然是目前主流的方法。早期特定领域的实体关系抽取会将实体识别与关系抽取作为两个子任务分开进行,也被称为流水线型的实体关系抽取。目前,基于该思想的实体关系抽取已经取得了较多成果[1-8]。但随着实体关系抽取问题被广泛关注,有学者发现流水线型的实体关系抽取会导致误差传播且子任务间的特征难以交互的问题。因此,基于联合学习思想的实体关系抽取被提出。文献[9-10]通过共享编码特征的方式,将实体关系抽取转换成序列标注问题;文献[11]将经典的机器翻译模型与注意力机制相结合,将预定义关系作为查询向量,引导模型进行对应关系实体对的抽取。
然而,以上实体关系联合抽取模型都将实体关系的联合抽取作为一个多分类问题,导致模型结构复杂,难以得到较高的准确率。文献[12]提出基于二分类级联关系抽取的CasRel 模型,并成功刷新了众多关系抽取数据集的榜单。但是,CasRel 模型存在4 个问题:①基于WordPiece 分词后的词片段序列在一定程度上模糊了词的边界信息;②采用主语在句中的开始位置向量和结束位置向量的均值作为主语特征向量,引入了噪声,影响特征分布;③采用主语特征向量与句子编码向量求和作为融合主语特征的句子编码向量(同问题②);④关系宾语预测时,没有考虑首尾位置预测任务中可能存在的交互信息。针对以上问题,提出基于预训练的BERT(bidirectional encoder representation from transformers)与CNN(convolutional neural network)编码特征融合的实体关系联合抽取方法,主要工作如下:
(1)在特征编码层,采用BERT-CNN 模型来替代BERT 模型对输入的词片段序列进行编码;
(2)替代CasRel 模型的均值特征融合,采用主语在句中的开始位置向量与结束位置向量乘积作为主语特征向量;
(3)替代CasRel 模型中求和方式的特征融合,采用主语特征向量与句子编码向量乘积作为融合主语特征的句子编码向量;
(4)为了增加预测关系宾语首尾位置信息的交互性,用一个全连接神经网络来同时预测其首尾位置信息。
1 编码特征融合的实体关系联合抽取
1.1 模型介绍
为更好地利用实体识别与关系抽取子任务之间的交互信息,鉴于二分类任务在多个领域中的优秀表现,提出基于BERT-CNN 编码特征融合的实体关系联合抽取方法。接下来,将从模型结构与模型算法描述两方面进行介绍。
首先是模型结构,图1 详细展示了模型内部结构及数据的转换流程。
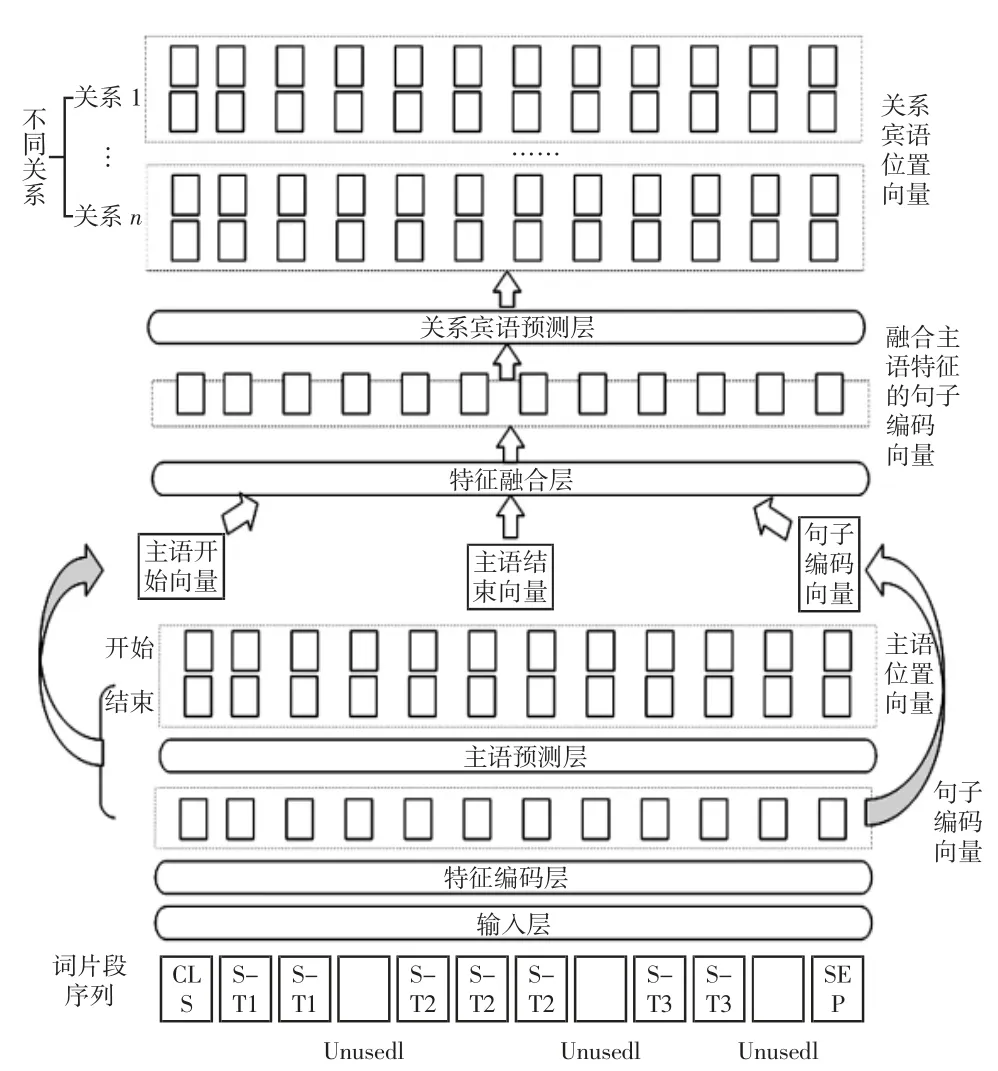
图1 模型框架图Fig.1 Frame diagram of model
依据数据处理流程,模型可分为以下5 个部分。
1)输入层
该层负责将输入句子通过WordPiece[13]算法转换为词片段序列。
2)特征编码层
该层负责对输入的词片段序列进行特征编码。区别于基础模型,本层的特征编码包含两个部分:①通过预训练的BERT 对输入内容提取上下文信息;②基于BERT 编码后的上下文特征,采用多个卷积神经网络过滤词边界信息。最后,将两部分特征拼接得到句子编码向量。
3)主语预测层
该层用于预测实体关系三元组的头部实体。其通过两个全连接神经网络预测主语的开始与结束位置。
4)特征融合层
该层负责对不同的特征向量进行特征组合,包含两个阶段:①通过预测的主语开始位置和结束位置在句子编码向量中索引得到主语开始向量和主语结束向量,对其进行特征组合得到主语特征向量;②通过对主语特征向量与句子编码向量进行特征组合,得到融合主语特征的句子编码向量。不同于基础模型,本模型为了保留更多基础向量特征,在两个阶段均采用乘积方式来进行特征融合。
5)关系宾语预测层
该层负责预测不同关系下对应宾语的首尾位置。不同于CasRel 模型,本层在预测关系宾语位置时,采用一个全连接神经网络来同时预测其首尾位置,加强了首尾位置任务间的信息交互。
模型的算法描述如下:
(1)模型的输入为包含待抽取实体关系三元组句子的词片段嵌入向量s 及其对应的标签(包括目标实体关系三元组的头部实体、尾部实体在词片段序列中的位置以及实体关系三元组对应关系的索引);
(2)在特征编码层,采用预训练模型BERT 对词片段嵌入向量s 进行编码得到融合上下文语义信息的特征向量t1,再使用3 个不同卷积核大小的CNN 来对t1进行一维卷积得到融合词边界信息的特征向量c1、c2、c3,然后将t1、c1、c2、c3进行向量拼接得到同时融合上下文信息和词边界信息的句子编码向量t2;
(3)主语预测层将句子编码向量t2输入到两个独立的全连接神经网络FCLayer 中去预测主语在词片段中的开始位置h1和结束位置h2;
(4)特征融合层通过h1和h2索引其在t2对应位置的字编码特征向量Shead与Stail,然后采用乘积方式的特征融合得到主语特征向量Ssub;
(5)在得到主语特征向量Ssub后,特征融合层将其与BERT-CNN 网络编码后的句子向量t2采用乘积方式的特征融合得到融合主语特征的句子编码特征向量Vsub;
(6)关系宾语预测层将Vsub输入到一个全连接神经网络FCLayer 中来同时预测不同关系所对应宾语在句子中可能的开始位置o1和结束位置o2,最终得到目标关系三元组。
1.2 BERT-CNN 特征编码网络
预训练语言模型BERT 是谷歌团队在2018 年提出的基于双向Transformer[13]的双向编码表示模型。不同于其他预训练模型,该模型凭借基于多头注意力机制的Transformer,在大规模语料库预训练下,能够较完整地获取句子的上下文信息特征并支持下游诸多NLP(natural language processing)任务的微调,极大地提升了NLP 领域中诸多任务的表现效果。预训练BERT模型的输入由以下3 部分组成。
(1)WordPiece Embedding:输入句子经WordPiece算法分词后的词片段嵌入向量s。
(2)Position Embedding:词片段嵌入向量s 中各词片段在句中的位置编码向量Q。
(3)Segment Embedding:用于区别不同句子的标志向量Eseg。
设BERT 的subword 词表大小为Nv,词嵌入维度为Ne,输入句子最大长度为NBert_max_len,词嵌入独热编码矩阵为Eone-hot-s,位置嵌入独热编码矩阵为Eone-hot-p,维度分别为(Nv,Ne)与(NBert_max_len,Ne),则BERT 输入序列x 和BERT 编码句子向量t1计算过程如下
然而,BERT 中WordPiece 嵌入会使得句子编码中词的界限模糊,对BERT 编码的句子向量主语首尾位置预测构成干扰。为避免该现象,将BERT 编码后的句子向量t1输入到不同卷积核大小的CNN 网络中,在句子维度进行一维卷积以增加词边界信息得到t2。其中,卷积神经网络的卷积核大小分别为1、3、5,卷积核数量均为64,该部分模型结构如图2 所示。
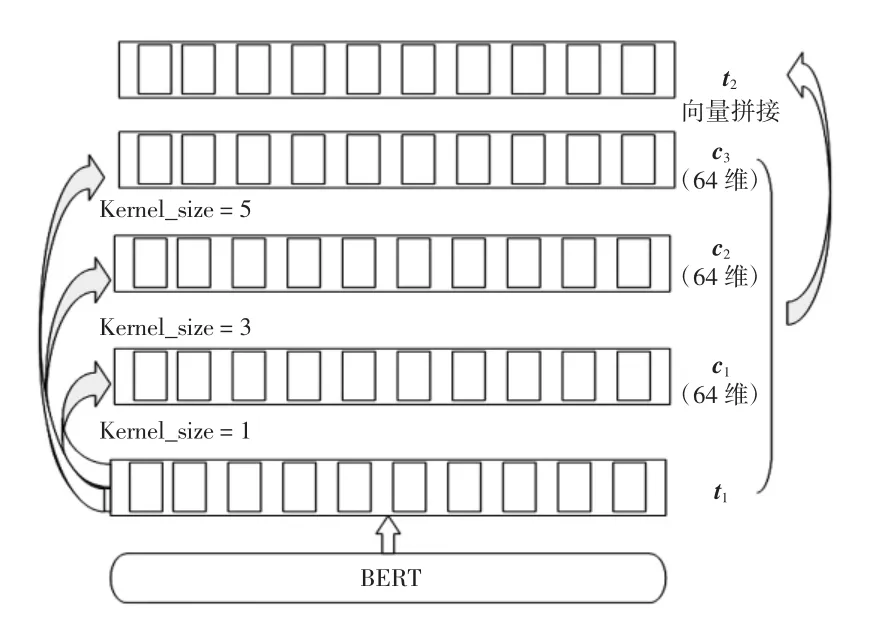
图2 特征编码层Fig.2 Feature coding layer
1.3 主语首尾向量的特征融合
为获得更好的主语特征向量,基于BERT-CNN 编码特征预测得到了实体关系三元组中头部实体的开始位置h1和结束位置h2,再根据预测得到的开始位置h1和结束位置h2来索引BERT-CNN 编码特征向量对应位置的向量Shead与Stail,对二者进行特征融合以表示主语特征向量Ssub,为关系宾语预测任务提供导向。针对该层,通过采用均值、乘积、差值、求和4 种不同方式的特征融合进行对比试验,最终选用乘积方式作为本模型中主语首尾向量的特征融合方式。
1.4 主语特征向量与句子编码向量的特征融合
为了在预测关系对应的尾部实体位置时能够考虑到主语特征,模型将句子编码向量t2与预测主语特征向量Ssub进行融合得到融合主语特征的句子编码向量Vsub。针对该部分,设置了基于注意力机制、求和与乘积方式的特征融合对比试验,并最终选用乘积方式来融合特征。
1.5 主语和关系宾语首尾位置预测
本模型将实体关系抽取任务视为一个基于句子编码特征识别主语和关系宾语位置信息的二分类任务,主语预测层和关系宾语预测层均采用全连接神经网络FCLayer 与激活函数Sigmod 来预测其对应的位置信息。在主语(关系宾语)的实体开始位置(结束位置)预测任务中,全连接神经网络将输出与句子长度相同的预测序列,默认预测序列中的概率值大于等于0.5 为1、小于0.5 为0,其中1 的位置表示该位置是头实体(尾实体)的开始位置(结束位置)。头实体与关系宾语位置预测公式如下
由于考虑到预测主语和关系宾语的首尾位置时,预测的主语(关系宾语)开始位置可能会影响到其结尾位置信息的预测,因此,该部分使用一个激活函数为Sigmod 的全连接神经网络来同时预测主语(关系宾语)的开始和结束位置。
2 数据集与评价指标的选择
2.1 数据集
文中使用的数据集是实体关系抽取任务的公共数据集NYT 与WebNLG。两个数据集中的实体关系三元组根据不同关系中是否共用头实体(尾实体)、同时共用头尾实体以及没有共用头尾实体分为SEO(single entity overlap)、EPO(entity pair overlap)、Normal 3 种类型,数据集所包含的训练集、测试集个数[14]如表1所示。
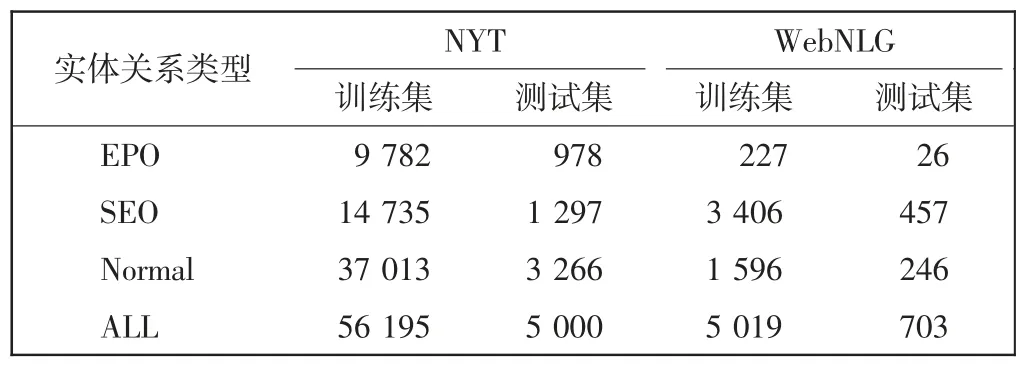
表1 数据集介绍Tab.1 Introduction of dataset
2.2 评价指标
为了便于与其他实体关系抽取模型进行性能对比,采用常见的评价指标,分别是准确率P、召回率R以及F1值,计算公式如下
式中:TP 表示预测的实体关系三元组中主语、关系及其对应的宾语同时被预测正确的个数;FP 表示预测的实体关系三元组中的主语、关系及其对应的宾语至少有1 个预测错误的个数;FN 表示目标实体关系三元组中未被模型正确预测到的个数。模型实际预测到的实体关系三元组数量为TP 与FP 之和,目标实体关系三元组数量为TP 与FN 之和。
3 实验与分析
模型针对内部各部分均尝试进行了优化实验。
3.1 实验环境与参数设置
模型实验的硬件环境:CPU 为i7-9750h;内存为频率2666MHz 的两条8G,共16G;GPU 为1660Ti-MaxQ;软件环境为Python3.7,PyCharm 编译器等。
在模型参数设置上,由于NYT 数据集较大导致模型训练时间相对较长,文中各部分的对比实验结果均基于WebNLG 数据集的验证集得到,实验参数设置如表2 所示。其中:Batch_size 表示一次训练包含的样本数量;Max_len 表示句子输入模型的最大长度;Learning rate 表示深度学习模型中调整各参数的初始比例;Drop-out rate 表示每次训练过程中不参加的神经元比例;Patience 表示在Early Stopping(早停,在过拟合之前提前终止训练)机制中,允许模型在优化器作用下找到更优解所能容忍的最大Epoch 个数;Optimizer 表示深度学习模型使用的优化器算法。

表2 实验参数设置Tab.2 Experimental parameter setting
3.2 实验结果分析
3.2.1 模型内部对比实验
模型内部对比实验是针对每层设置的不同对比实验,除对比实验层外,其余层结构与CasRel 模型结构一致。
1)特征编码层对比实验
针对该层,考虑到WordPiece 分词会将1 个词分为多个子词的情况,使用3 个不同卷积核大小的卷积神经网络在WordPiece 分词后的句子编码特征序列上进行一维卷积,得到c1、c2和c3,设卷积神经网络的卷积核个数为Filter_num,3 个特征向量的维度均为(Batch_size,Max_len,Filter_num)。针对卷积神经网络中不同卷积核大小与卷积核数量进行了对比实验,对比实验结果如表3 所示。实验序号5 为基于BERT 编码的句子特征向量用于实体关系抽取。
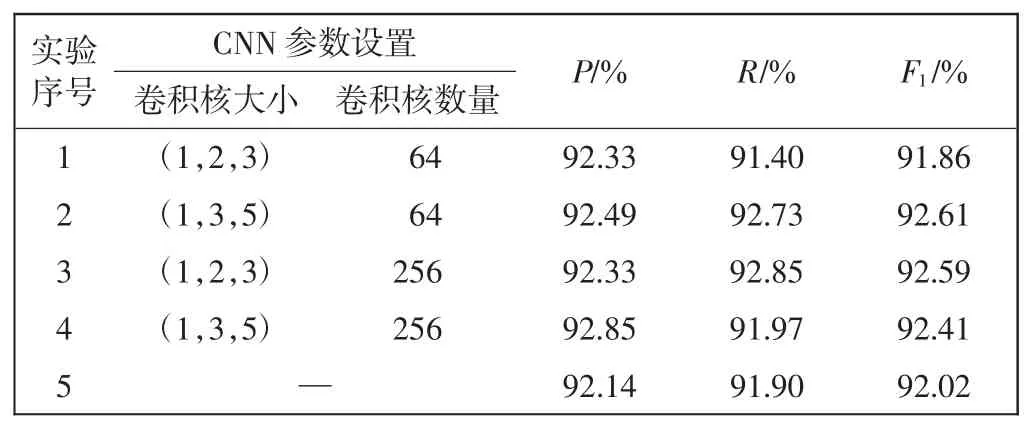
表3 特征编码层对比实验Tab.3 Comparison experiment for feature coding layer
由表3 可以看出,基于BERT-CNN 编码的句子特征向量优于单纯使用BERT 编码的句子特征向量,拥有更丰富的表征能力。此外,卷积神经网络的卷积核数与卷积核大小均对三元组抽取效果有影响,卷积核数量为(1,3,5),卷积核数量为64 在模型中获得更好的抽取效果。
2)主语预测层对比实验
由于在基于特征编码向量预测主语首尾位置任务中,预测的主语开始位置与主语结束位置可能会存在交互信息,针对是否使用同一神经网络来同时预测主语的首尾位置设置了对比实验。实验结果如表4所示。
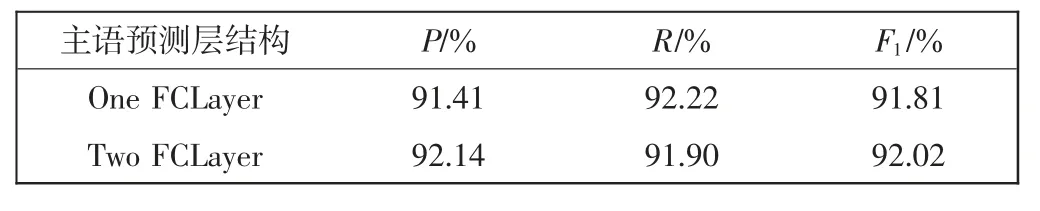
表4 主语预测层对比实验Tab.4 Comparison experiment for subject prediction layer
通过表4 可以看到,主语预测层使用两个独立的神经网络仍然优于使用一个神经网络,这表明使用同一个神经网络同时预测主语的开始和结束位置时存在干扰的情况,两个独立的神经网络能学习到更优的特征表示。
3)特征融合层对比实验
由于采用均值与求和方式的特征融合可能会对融合前特征产生负面影响,本研究尝试采用了其他方式的特征融合并设置对比实验。对比实验分为两个,分别是:①预测主语首尾向量的特征融合;②主语特征向量与句子编码向量的特征融合。在第2 个实验中,由于使用注意力机制来调整句子编码向量的结果较差,没有列入实验表格中。实验结果如表5 和表6 所示。
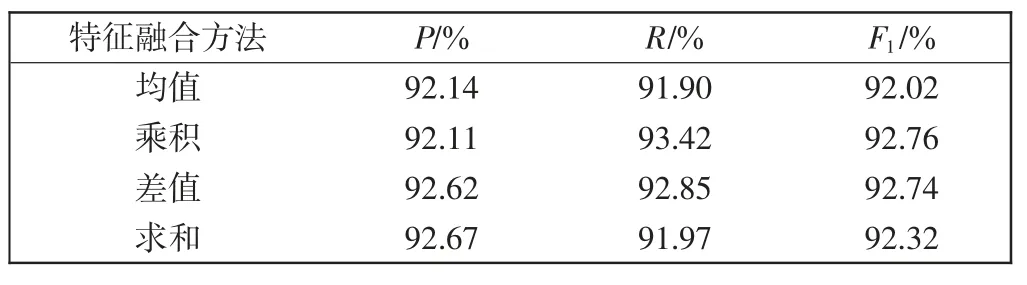
表5 主语首尾向量特征融合Tab.5 Feature fusion of head and tail vectors of the subject

表6 主语特征向量与句子编码向量特征融合Tab.6 Feature fusion of subject vector and sentence vector
通过对比表5 与表6 的实验结果,在主语首尾向量特征融合和主语特征向量与句子编码向量特征融合过程中,采用乘积方式能够高效捕捉到更有价值的信息,得到更好的融合向量。这是由于:①预训练语言模型BERT 由多个Transformer 组成,而每个Transformer 都包含Layer Normalizaiton层,其可以保证经过BERT 编码得到的融合上下文信息的字向量服从标准正态分布,因此Shead与Stail服从独立的标准正态分布,而其采用乘积方式融合依然可以保证特征向量服从标准正态分布,更易寻找到最优解;②乘积方式的特征融合更能体现原有特征之间的相关程度,如两对特征向量值分别为(0.9,0.1)与(0.5,0.5)时,在求和与均值方式的特征融合时,特征值融合后均表现等于1 与0.5,导致其之间的差异性被忽略;而在差值方式的特征融合时,融合后的特征值表现为0.8 与0,虽然从结果上看保留了原有特征之间的差异,但是特征值为0的概率增大,容易出现特征消失的情况;但是,在乘积方式的特征融合中,特征融合后表现为0.09 与0.25,不但保留了原有特征值之间的差异,还降低了特征值为0 时导致的特征消失情况发生。因此,采用乘积方式的特征融合更能保留原有特征之间的相关程度。
4)关系宾语预测层对比实验
由于该层任务和主语预测层任务相似,以是否使用同一神经网络来预测其开始和结束位置设置了对比实验,实验结果如表7 所示。

表7 关系宾语预测层对比实验Tab.7 Comparison experiment for relative object prediction layer
通过对表7 结果分析,在关系宾语首尾位置预测任务中预测关系宾语的开始位置与结束位置并不是相互独立的,存在交互信息,使用同一个神经网络更能捕捉关系宾语首尾的位置特征。
3.2.2 模型性能对比
根据上述各层的对比实验,确定最优模型结构如下。
特征编码层:使用基于BERT-CNN 的网络来进行特征编码,CNN 的卷积核个数为64,卷积核大小分别为1、3、5。
主语预测层:使用两个独立的全连接神经网络预测主语的开始和结束位置。
特征融合层:两次特征融合均采用乘积方式。
关系宾语预测层:使用一个全连接神经网络来同时预测关系宾语对应的开始和结束位置。
模型对比目前WebNLG 数据集上表现最好的实体关系抽取模型GraphRel[15]、CopyRRL[14]、CasRel[12]、TPLinker-BERT[16],其表现结果如表8 所示。
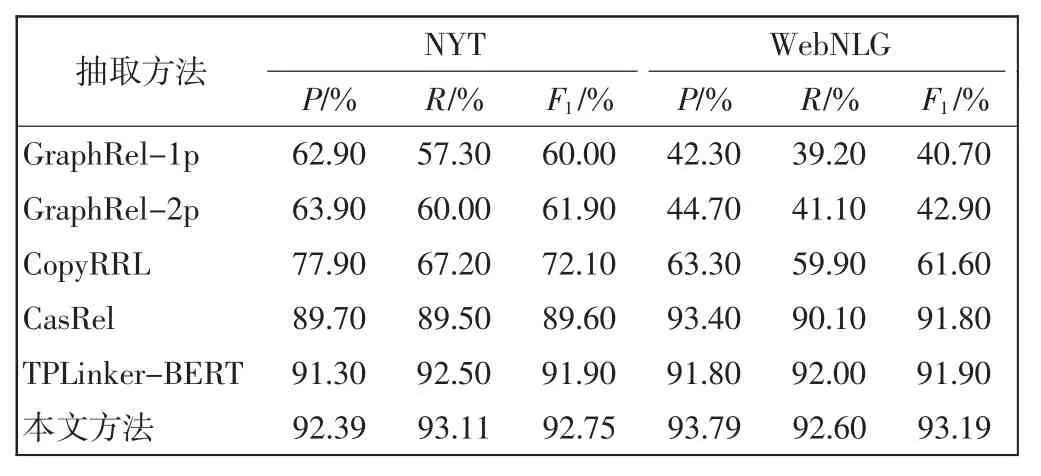
表8 模型对比实验Tab.8 Model comparison experiment
由表8 可以看出,本文方法在NYT 与WebNLG两个数据集上的综合评估指标F1分别达到了92.75%与93.19%,比基线模型CasRel 分别高3.15 个百分点与1.39 个百分点,并且对比同数据集上的其他最新模型,在准确率、召回率和F1值上均表现更优,更能胜任实体关系联合抽取任务,具有一定的实用价值。
4 结语
基于二分类任务在各领域中的优秀表现,提出基于BERT-CNN 编码特征融合的实体关系联合抽取方法:①基于BERT-CNN 网络编码输入句子的特征向量;②采用乘积方式来融合预测主语的首尾特征向量,再将融合的主语特征向量与句子编码向量使用乘积方式进行融合得到带有主语特征的句子编码向量;③使用一个全连接神经网络来充分利用关系宾语首尾位置预测中的交互信息。在CasRel 模型基础上进行了各层的不同实验对比,经过实验数据对比可知,本文方法在NYT 和WebNLG 数据集上表现效果优于当前最新模型,F1值分别达到了92.75%与93.19%。
实体关系抽取任务本质上是服务于知识图谱内容的构建。目前,本文方法虽然在关系抽取方面的多个数据集上表现突出,但由于其提取的实体必须在原句中存在,对数据集要求较高。因此,考虑在未来的研究中将风格翻译作为一个突破点,解耦算法对数据格式的依赖。
