基于校友数据的大学生就业影响因素加权随机森林模型
2023-05-30王小龙穆芸菲朱玥祺寇子若谢佳美李涓涓郭晓明
王小龙 穆芸菲 朱玥祺 寇子若 谢佳美 李涓涓 郭晓明


摘要:为了更好地分析利用校友经济新形势下的就业数据,建立了影响大学生就业因素的加权随机森林模型。首先对影响就业的因素进行排序,然后通过加权随机森林模型,准确预测在校生未来就业情况,在此基础上充分利用校友资源并搭建平台为学生就业创造机遇,加强与校友之间的联系,有效推进大学生就业工作。以某大学部分校友数据为实例,得到构建的模型预测准确率为82.3%。
关键词:校友资源;加权随机森林;算法实现;就业预测;小程序
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)01-0081-04
在当今就业形势越发严峻,及我国社会主义市场经济体系下,高校也逐渐形成以市场为向导、毕业生与用人单位之間的双向选择[1]。在校生就业经验不足,且信息素质较低,如何判断信息真伪性、有效性及如何分析整合信息,对在校生是巨大考验,而毕业校友分布于各行各业中,恰好能够提供高效资源[2]。为充分利用校友资源,考虑互联网成本低、及时性、范围广的特点,采用网络作为交流手段,为高校人才交流大大降低成本[3]。
如何提高校友数据利用水平,对于高校人才培养和发展建设,校友关系网建设与学校的可持续建设具有重要的现实意义。近几年关于大学生就业预测的研究中,主要使用的方法有Logistic回归模型[4]、基于决策树算法[5-6]、数据挖掘技术[7-8]和层次聚类等机器学习方法[9-10],对就业影响因素进行一系列分析,为在校学生的发展和毕业去向提供可靠参考。
受上述方法启发,本文收集到某高校4000份毕业生就业数据,通过数据处理后分析其中553名毕业生特征及就业情况,在随机森林算法的基础上,提出采用加权随机森林对大学生就业因素进行分析及预测,可有效提高预测准确率,并搭建小程序平台,将预测结果与校友资源联系,提供高效资源,拓宽就业途径。
数据挖掘任务可以是描述性的或预测性的,描述性数据挖掘通常使用关联规则挖掘、聚类等技术来发现及分析隐藏在大数据集中的信息,帮助智能决策;预测数据挖掘使用规则集、决策树、神经网络和支持向量机等构建模型来预测新数据集的类别。
本文通过建立校友的信息库,包括学籍、专业、成绩及科研竞赛能力指标及就业等信息智能动态[4],利用逻辑推导、机器学习、分析量化,完善数据库中的校友信息,同时对校友的专业、从事行业及薪资目标等相关信息行为进行挖掘与需求分析,构建出符合在校学生需求的行为模式,对其可能从事的工作及活动进行预测,并基于预测结果进行精准校友信息推送。
1 数据处理
本文以西安某高校部分毕业生的就业数据和基本信息为研究对象,从2000—2020年毕业生中按年份随机抽取,再对数据进行清理,消除缺失值的数据,更正不一致的数据,识别异常值以及删除重复数据后,共提取553条有效记录。主要使用学位、学校类型、专业类型、成绩及科研竞赛能力、家庭背景、户口性质、单位类型、发展前景、是否专业对口、是否达到薪资期望10类对择业影响较大的属性。
由于数据项目各属性间不是简单的映射关系, 因此为了便于模型的建立, 将定性数据均改为数值型数据。考虑到本文中属性种类较多,因此采用一种比one-hot法更为紧凑的编码方式,如对于学历属性, 00表示学士学位、01表示硕士学位, 10表示博士学位。根据上述规则, 处理所有属性的结果如表1:
其中,专业类别描述如表2:
同理,对于户口性质:A7=0表示该学生为农村户口,A7=1表示城市户口。对于家庭背景:A8=0表示该学生家庭背景较差即家庭人均年收入1.5万元以下,A8=1表示家庭背景较好即家庭人均年收入1.5万元以上。对于成绩及科研竞赛能力:A9=1表示该学生成绩处于专业前50%或在各类竞赛中取得过较高奖项,A9=0表示成绩较差且不曾在科研竞赛中取得成果或奖项。
对于即就业情况属性进行定义及处理:
其中,专业对口描述如下:
基于行业和专业的定义,判断从事行业或职位于专业是否相关,即学生在学校学习的专业类别与之后从事行业所需要专业技能,是否存在直接相关性。例如,本科学习的是信息技术类专业,之后进入计算机行业从事技术开发人员便为行业与专业相关,反之若进入经济行业,从事工商管理工作,则为行业与专业不相关。即R1=0表示该学生就业后从事行业或职位与专业不相关;R1=1表示从事行业或职位与专业相关。
发展前景描述如下:
发展前景是一个岗位能赋予个人提升的空间,依据当下普遍情况对所收集数据中的岗位进行划分,例如,某中小企业普通员工或管培生,该岗位能赋予个人提升的空间较小,因此定义为发展空间较小。即R2=0表示该生所在行业为或职位可发展空间较小;R2=1表示所在行业为或职位有较好前景。
单位性质描述如下:
龙头企业是指对于同行业其他企业具有深刻影响力、召唤力、一定示范作用和指导作用,并对本地区、本行业、本国做出较为突出贡献的企业。例如,数据中的京东物流、华为技术有限公司等。反之,通过企查查及天眼查等平台调研,将营业收入500万元以下的定义为小微型企业,例如,数据中某西安留学机构或某小型自媒体公司。即R3=0表示该学生从事自由职业或所在单位为小型公司,较不稳定;R3=1表示所在单位为国企或某行业龙头企业,较为稳定。
薪资期望描述如下:
预期薪资则是新人在步入行业之初,对于因向所在的组织或企业提供劳务而获得的各种形式的酬劳的期望,如果所给薪资达到或者超于期望,则表示预期薪资达标。即R4=0表示不能达到预期薪金期望;R4=1表示可以达到预期薪金期望。
2 加权随机森林模型
在基于机器学习模型的研究中,关于数据分类及数据挖掘的研究有很多,但针对将高校学生求职相关行为数据与校友资源联系的探讨较少。在查阅相关文献后,通过对基本分类算法的对比和分析[15],发现随机森林(Random Forest,RF)模型对于本研究数据集具有较优的分类准确率。
梯度提升技术常被用于机器学习中的回归和分类问题,其原理为:如果预测模型每个步骤的损失函数都是基于梯度产生的,那么它每个步骤产生预测模型称为弱预测模型(例如决策树模型),然后将弱预测模型以集合的形式再次生成预测模型,该过程称为梯度提升技术。即如果一个问题有一个弱预测模型,那么通过升级技术可以得到一个强预测模型[16]。
本文主要采用基于Bagging策略的加权随机森林算法[17],其原理为:首先,用Bootstrap采样法从样本集中生成n个训练样本集,并分别在每一个训练样本集中随机选择K个属性,其次从这K个属性中选择出最佳的 [k≤K]个属性作为分割属性,以这些选出的分割属性为节点,创建决策树(单训练样本集的结果如图1所示),最后由n棵决策树生成随机森林。由于在随机森林构建的过程中,各決策树之间没有相关关系,所以对每棵决策树的叶节点进行加权处理,再并行处理上述步骤,直至可以形成权重达标的随机森林模型。
3.1 加权随机森林预测过程
本文将根据分类能力设定相应决策树的权重,通过二次训练构造改进的加权随机森林模型。其训练流程图如图2所示。
加权随机森林的构建流程为:首先将训练样本集引入,并用Bootstrap自助法在这些训练样本集中有放回随机抽取k个样本集,组成k棵决策树,同时,若存在未被抽取的样本,则用其构建单棵决策树;如果最终形成的决策树个数等于集合数,则对该决策树进行二次训练,否则选择新的决策树个数,再重复上述步骤直至个数达标。二次训练时,首先设置每个叶节点的投票权重初始值为0.5,随后将一组完整训练样本集输入到每个决策树中;当样本到达叶节点后,再根据正确样本数与总样本数的比值再一次调整叶节点权重;重复上述步骤直至叶节点权重达标。最后由生成的决策树及其达标权重构成加权随机森林,再运用生成的加权随机森林对待分类样本进行分类或预测。
3.2 结果分析
本文对于专业类别、学历、户口性质、家庭背景及成绩及科研竞赛能力五个学生自身属性利用随机森林算法进行计算,其中树的数量这一参数设置为1000,得到特征重要性评分:专业:0.120961;学历:0.345027;家庭背景:0.223205;户口性质:0.078136;成绩及科研竞赛能力:0.226671。其类似决策树回溯的取值,从叶子收敛到根,根部重要程度高于叶子。
可以看出特征选择分数从高到低排列为学历、成绩及科研竞赛能力、家庭背景、专业类别、户口性质,将各特征重要性结果进行可视化后得到图3。
首先对数据进行预处理,使得数据更加有效的被模型或者评估器识别。按照特征重要性进行排序,此处选择前三的特征,并将每个特征值归一化;将原始数据进行线性变换到[0,1]区间,进行标准化处理以加速收敛,并开始对模型进行训练。根据其特征对专业对口、薪金期望等利用RF算法进行预测。将处理后的576组数据划分训练、实验、测试集进行训练后,得到模型的准确率为: RandomForest: 0.823, 即输入个人特征后, 通过该加权随机森林模型得到的未来就业属性具有82.3%的准确率。
通过上述模型得到结论: 首先,学生的学历对于未来就业时所在单位类型、能否专业对口、具有良好发展前景且达到薪资期望影响最大,具体来说,学历越高则越有可能在专业对口领域就业于国企或龙头企业,且具有良好发展前景容易达到薪资期望。其次,成绩及科研竞赛能力和家庭背景的影响较大,良好的成绩或优秀的科研竞赛经历更容易争取到优质就业岗位,而良好的家庭背景在学生就业抉择时可以给予一定的外部支持和机遇;然后,专业对于未来就业影响所占比重较小;最后,户口性质影响最小。
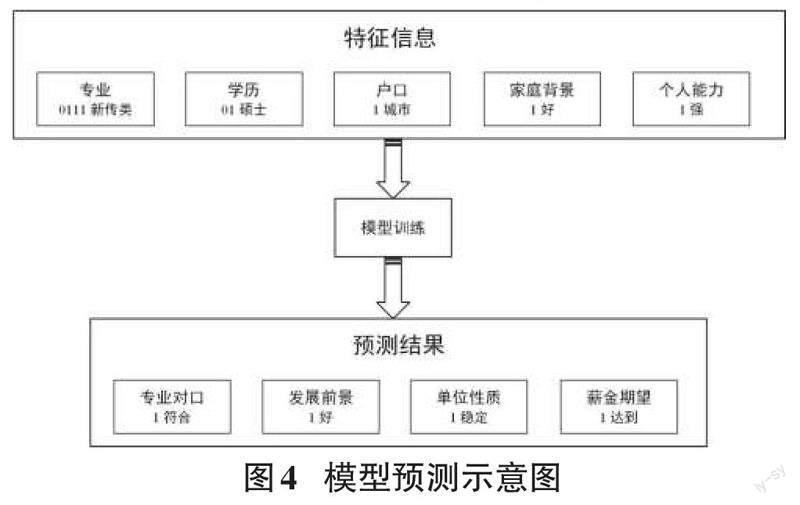
随着后续数据量的增加,预测的准确率也将逐步提升。例如,输入个人特征:新传类专业、硕士学历、城市户口、家庭背景较好、成绩及科研竞赛能力较强,则通过模型训练得到就业属性的预测结果:未来能够在专业对口领域就业、达到薪资期望,所在单位更可能是国企或龙头企业,具有较好发展前景,其结果如图4。
通过实验分析及结果可以看出,基于加权随机森林的分析方法完成了对学生就业情况的预测,结果与现实情况较为符合,学生可以根据自身的属性得到自己未来最有可能的就业情况,有针对性地进行自我提升。
3.3 加权随机森林模型评价
对于分类问题,应用随机森林不仅可以评估各个特征在分类问题上所占权重,即反应各属性的重要程度,而且数据中的异常值或缺失值对随机森林的影响并不明显,具有较好的分类结果;但当训练数据噪声较大时,容易产生过度拟合现象。本论文使用了加权随机森林算法,通过引入二次训练对投票权重进行修正,进而使得分类器的分类性能更加高效,具有更高的准确率。
为直观展示本文中加权随机森林方法的预测性能,随机森林方法及决策树方法进行对比,采用三种方法的预测高校学生就业属性的准确率如图5。对比结果有效验证采用加权随机森林方法的结果相比于另两种方法与实际情况更接近,具有更优越的预测性能。
3.4 校友行为大数据关联及交互
此外,还可以根据校友特征进行数据挖掘,以此实现更加精准的推荐和校友关系网的相关构建;并且采用聚合的方法提取较复杂校友信息中的主要特征,然后对这些特征进行深层次、多属性的聚合和挖掘,构建校友关系网络;同时还可以将相关企业的人事招聘信息、产品信息以及优秀毕业校友的相关活动信息及时地并且精准地推荐给用户。未来还可以进行针对性的引导、消息推送和跟踪服务,增强校友之间工作的广度和深度。
通过初期的需求分析,平台选用了微信小程序这一成熟的体系开发,同时建立相应的微信公众号来方便平台推广和用户使用。该平台在前端交互页面设有条件筛选、质量分析、校友互通、趋势研判这四大核心功能模块,用户可以提供学号、入学毕业年份、姓名等个人信息完成初始化,以此使用相应的信息智能筛选、分析和预测服务。其中趋势研判模块可以基于用户的初始化信息来预测未来的发展前景、就业单位是否稳定以及能否获得期望薪资。
与其他类似平台相比,本平台基于微信小程序、公众号这一套成熟的体系开发,既方便积累用户和快速传播,又降低了开发和维护的成本。与一般就业平台相比,本平台基于机器学习对海量校友资源信息进行智能分析并训练预测模型,提高了用户搜寻信息的效率,还可以让用户评估个人状态,预测未来就业状况,帮助用户明确当下的学习和发展的方向,提高未来的就业成功率。就平台发展性而言,本平台会在用户允许的前提下收集信息,扩充校友资源数据库增强评估的全面性,并训练相应模型提高预测的准确率。就平台影响而言,本平台可以充分调动和利用校友资源为学生就业创造机遇,加强在校生与校友之间的联系,提高学校的知名度和影响力,前景可观。
4 结论
现有的大学生就业预测较少有使用随机森林算法,且没有与校友资源联系并进一步通过平台实现。本文采用加权随机森林模型,提高了算法预测准确性,对就业影响因素进行一系列分析,为在校学生的发展和毕业去向提供可靠参考。同时并搭建小程序平台,将预测结果与校友资源联系,提供高效资源,拓宽在校生就业途径,促进在校生求职方向的明确。
未来将通过小程序平台继续收集信息,进一步扩充校友资源数据库,通过增加属性标签改进模型预测精度,增强评估的全面性。
参考文献:
[1] 沈华荣,林琰旻.新形势下构建母校与校友发展共同体促进就业新模式探讨——以浙江大学校友企业总部经济园为例[J].科教文汇(下旬刊),2020(4):15-16.
[2] 杨敬超,杨彩霞,杨旻谛,等.大数据背景下校友资源智能共享平台建设[J].办公自动化,2020,25(18):62-64.
[3] 封志彬.基于发挥校友作用拓宽就业途径的思考[J].产业与科技论坛,2022,21(1):212-213.
[4] 郑兰,刘翎雁,秦昔兰.基于Logistic回归模型的数学专业大学生择业就业对比分析[J].考试周刊,2016(55):55-56.
[5] 桑海风,姜鸣地,路钟乔,等.基于决策树的大学生职位晋升影响因素数据挖掘算法[J].北华大学学报(自然科学版),2019,20(6):836-840.
[6] 张光荣.基于决策树算法和关联规则分析方法的学生就业数据分析[D].西安:陕西师范大学,2014.
[7] 李亚东.数据挖掘技术在高职院校学生就业指导中的应用研究[J].创新创业理论研究与实践,2019,2(17):149-150.
[8] 黄博宇.数据挖掘的大学毕业生就业预测研究[J].微型电脑应用,2021,37(11):171-173.
[9] 谷月.基于机器学习算法的高校学生就业去向预测[J].微型电脑应用,2022,38(2):172-175.
[10] 李路瑶.基于层次聚类的大学生就业去向短期预测系统[J].吉林大学学报(信息科学版),2022,40(1):64-70.
[11] 宋家琦,邵忠刚.“校友推荐”就业平台的研发及其前景分析[J].信息通信,2018,31(11):263-264.
[12] 杨敬超,杨彩霞,杨旻谛,等.大数据背景下校友资源智能共享平台建设[J].办公自动化,2020,25(18):62-64.
[13] 熊露露,王方士.高職学生就业因素分析与就业预测模型构建[J].现代计算机,2021,27(33):39-43.
[14] 罗雪梅,韩存鸽,卓杰.关于高校就业预测模型应用研究[J].长江信息通信,2021,34(11):102-104.
[15] 徐秀娟,白玉林,徐璐,等.恶劣天气情况下基于随机森林算法的交通流量预测[J].陕西师范大学学报(自然科学版),2020,48(2):25-31.
[16] 王宇燕,王杜娟,王延章,等.改进随机森林的集成分类方法预测结直肠癌存活性[J].管理科学,2017,30(1):95-106.
[17] 杨飚,尚秀伟.加权随机森林算法研究[J].微型机与应用,2016,35(3):28-30.
【通联编辑:李雅琪】
