基于多传感器融合的服务机器人避障系统
2023-05-30陈旭凤赵彦伟胡雪花张茜黄文静
陈旭凤 赵彦伟 胡雪花 张茜 黄文静


摘 要:当前服务型移动机器人在未知环境下,大多需要一直进行避障算法的计算,这会使得系统的能耗增高,工作效率降低。针对上述现状,本文设计了一种基于多传感器融合的服务机器人避障系统:利用彩色图像信息和相匹配的高质量深度场景图的信息,进行机器人与跟踪目标之间有无障碍物的判断,以及障碍物的动静态分类,并针对无障碍物、有静态障碍物与有动态障碍物的检测结果设计了不同的避障策略。
关键词:多传感器融合;障碍物检测;避障策略;服务机器人
大多数传统的跟踪方法只将彩色图像用于跟踪目标过程中,这可能会遭受到不断变化的环境,如光照变化、部分遮挡和背景杂波,导致所谓模型的漂移问题,而深度图像包含空间信息、深度图像编码这些问题的重要线索。在获取到跟踪目标所处的场景信息后,服务机器人仍然需要对所处环境中可能存在的障碍物进行检测,并对检测结果做出合理的避障行为。总而言之,当前服务型移动机器人在未知环境下的避障需要一直进行避障算法的计算,这会使得系统的能耗增高,工作效率降低。
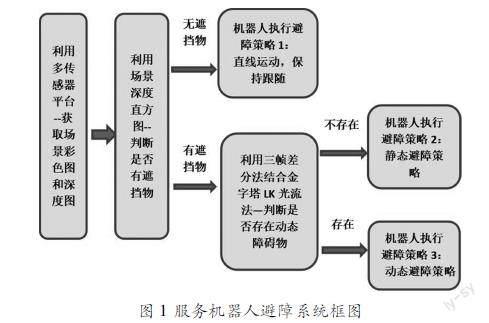
为了达到使服务机器人更好地跟踪服务对象的目的,本文设计了一种基于多传感器融合的服务机器人避障系统。该系统通过融合视觉和深度传感器进行场景信息的获取,对获取到的彩色和深度图像进行处理完成障碍物的检测和分类,针对不同类型的障碍物设计相应的机器人避障策略。系统框图如图1所示。
1 多传感器融合
1.1 服务机器人平台
本文研究基于ARTrobotROS全开放机器人套件开展,系统平台包含颜色摄像头(高分辨率)、深度摄像头(低分辨率;有效传感深度为1.2~3.5m)、麦克风阵列等,并提供人体跟随实例代码。其系统架构如图2所示。
1.2 彩色和深度传感器融合
笔者在前期工作中,融合其彩色视觉传感器和深度视觉传感器,构成了一个能获取到更高质量、分辨率更合理的场景深度图的深度成像系统,以便于后期基于此高质量的场景深度图进一步进行障碍物检测和避障策略的设计[1]。
2 障碍物检测
在基于TOF的快速加权中值滤波深度成像系统的支撑下,可以获取到机器人跟踪目标过程中通过摄像头系统得到的场景深度图。基于视觉和深度传感器融合的平台,可对跟踪过程中障碍物进行检测识别与分类。
2.1 检测有无障碍物
本方法主要采用深度直方图来判断是否有障碍物存在于机器人与跟踪目标之间[2]。
基于服务机器人跟踪目标过程中采用如下跟踪模块的前提:在第t帧中目标的位置A=(xt,yt,wt,ht),然后在目标位置附近提取一些正样本并在远离目标位置提取一些负样本。分别在彩色图像和深度图像中计算其特性来更新贝叶斯分类器的参数。在接下来的t+1帧,我们得到位置A周围的一些样本,把它们放进更新后的贝叶斯分类器。通过这种方法,分类器中得分最高的被认为是当前帧的目标位置(xt+1,yt+1,wt+1,ht+1)。
假设跟踪目标框在第一帧没有发生遮挡,则进行以下图像处理:(1)把跟踪目标所在的场景深度图进行预处理。把深度值归一化到0~255之间,越靠近相机则深度值越大。因此当发生遮挡时,遮挡物的深度值将大于目标的深度值。(2)计算跟踪目标框的深度直方图,并将目标深度值融合成一个高斯分布。因为一个目标中的深度值是连续的,所以在直方图中会有一个最大值的波峰,如图3左图所示(中间图像为深度图提取出来的跟踪目标)。(3)对于后续获得的每一帧,在得到跟踪目标的位置后,计算新一幀的深度直方图。(4)判断有无障碍物存在:如果出现了满足高斯分布均值和标准差特定条件[见公式(1)]的新的峰值,则认为遮挡发生,即在服务机器人与跟踪目标之间存在障碍物。如图3右图所示。
图3 左:深度图中跟踪目标框所得到的深度直方图(坐标系图中曲线为目标的深度高斯分布);中:深度直方图中的跟踪目标;右:遮挡出现时,深度直方图中出现新峰值
|μ-larg erdepthvalue|>2*σ(1)
2.2 障碍物动静态分类
基于前文对是否存在障碍物的判断进行后续障碍物分类:如果没有障碍物存在,则不需要对其类型进行判断;如果有障碍物存在,则需要进一步判断该障碍物的类型。
本文采用三帧差分法与金字塔LK光流法结合的方法[3],判断该障碍物是否为动态障碍物,并且得到该动态障碍物的具体区域,以便于后期的避障。若结果判定为动态,则指定机器人进行动态避障策略;否则指定机器人进行静态避障策略。
对三帧差分法处理结果再进行金字塔LK光流法的具体步骤如下:
(1)对机器人的视觉成像系统获取到的视频序列预处理、去噪。
(2)取视频序列的连续三帧图像Ii1(x,y)、Ii(x,y)、Ii+1(x,y),对Ii1(x,y)、Ii(x,y)做差分运算,得到帧差图像fi(x,y),对Ii(x,y)、Ii+1(x,y)做差分运算,得到帧差图像fi+1(x,y)。
(3)对帧差图像fi(x,y)、fi+1(x,y)做二值化处理之后再进行逻辑与操作,从而能够得到运动区域的图像J(x,y)。
(4)对J(x,y)建立金字塔模型JL,L=0,1,……,Lm。首先初始化金字塔最底层也就是Lm层的光流估计值gLm=[0 0]T,Lm层图像上特征点u的速度为uL=u2L。
(5)对图像JL求x、y的偏导数JLx、JLy,计算G=∑uLx+wx-uLx-w∑uLy+wy-uLx-wJ2xJxJyJxJyJ2y。
(6)初始化光流dLm=[0 0]T,求δI=JL(x,y)-JL(x+gLx,y+gLy),计算b=∑uLx+wx-uLx-w∑uLy+wy-uLx-wδI·IxδI·Iy。
(7)计算得到Lm层的光流值dL=G-1b,计算Lm1层的光流gL-1=2(gL+dL),以此类推得到最后的光流值d=g0+d0。
(8)图像P(x,y)的对应特征点为ν=u+d;最后得到运动目标图像P(x,y)。
在移动机器人跟随服务目标移动过程中,当检测到存在其他运动物体的有效图像时,将此次对遮挡物的判断分类为——动态障碍物,并执行“动态避障行为”;否则将此次对遮挡物的判断分类为——静态障碍物,并执行“静态避障行为”。
3 避障策略
基于障碍物的分类与多传感器深度成像系统所获取的数据,设计了应对跟踪过程中出现未知障碍物的避障策略。
3.1 机器人避障行为
针对前文工作对于障碍物的检测和分类,将获取到的场景图平均分为左中右视场[4]。移动机器人采用的避障行为主要设计思路为:前方无障碍物,直线运动;左前方有障碍物,右转;右前方有障碍物,左转。最终将避障策略的设计落实到机器人避障指令的关键为:确定机器人的左右轮速wl、wr和转动角速度θ。
本文设计的服务机器人避障策略主要分为以下三种行为:
(1)无障碍物出现——避障行为1:保持服务对象即跟踪目标在图像的中间视场,直线运动保持跟随;同時实时运行视觉传感器和障碍物检测算法。如果检测到有障碍物出现则进行障碍物的静动态判断,否则保持避障策略1行为。
(2)出现静态障碍物——避障行为2:根据场景的深度信息判断该障碍物的边界,并使移动机器人在以跟踪目标为主线的路径上进行角度微调,沿其边界绕路行走,直到障碍物识别结果为“无障碍物”为止。具体实施方法:根据多传感器系统获取到的修正(去噪+形态学处理)后的深度图,使用边缘检测算法,得到静态障碍物的边缘,结合从视场的深度直方图获取到的该障碍物与机器人的距离,对机器人进行合理的避障决策——①在距障碍物较远处可以保持直接跟踪;②到一定距离阈值处根据该静态障碍物的边缘进行左转或右转,从而达到避障的目的:本方法将场景平均分为左中右三视场,当障碍物在左或左中视场时,机器人右转;障碍物在右或右中视场时,机器人左转;障碍物在中视场时,机器人左转或右转避障皆可。
(3)出现动态障碍物——避障行为3:根据前文中障碍物检测算法得到了动态障碍物目标的位置与边缘,接着使用VFH算法进行机器人的实时动态避障。该算法将移动机器人运动场景的环境信息表征成若干个二维栅格系列,其中每个栅格都有一个概率值用来表示该像素点存在障碍物的可能性大小,即可信度CV(Certainty Value)。
具体实施方法如下:
①栅格向量化。对t时刻视频中的帧进行栅格向量化,使用的计算公式为:mi,j=(ci,j)2(a-bdi,j)。
移动机器人t+1的运动方向由t时与障碍物的相对位置依据下方公式而定:
βi,j=tan-1yj-y0xi-x0
其中,a、b是正常数,Ci,j为视频图像中栅格(i,j)的CV值,di,j是该栅格到机器人中心点的距离值,(x0,y0)是t时刻移动机器人中心点的绝对位置坐标,(xj,yj)是栅格的绝对位置。
②活动窗口分区。假设图像的分辨率为α,包括n=360α个区间,对于任意区间k,(k=0,1,2,...,n1),有k=int(βi,jα),其障碍密度hk=∑i,jmi,j。在此基础上可采用下述方法进行平滑处理:
h′k=hk-l+1+2hk-l+2+…+lhk+(l-1)hk+1+…+2hk+l-1+hk+l2l-1(2)
③确定移动机器人的运动方向θ。经上式(2)的计算能得到环境图像中每个分区障碍物的概率密度;采用概率密度与阈值τ对比,从而确定区间是否足够移动机器人行走,其中阈值需要提前设定。当障碍物的概率密度小于τ时,该区域为安全区域,当有连续多个区间(大多超过18个区间)都为安全区域时,则称这些区域为A,否则称之为B。A的最左边区间为kl,最右边区间为kr,此时移动机器人的运动方向为:
θ=12(kl+kr)
3.2 系统避障策略
本文所提出的避障策略方法概括如下:
STEP1:以特定时间间隔连续获取含跟踪目标在内的、同一场景的彩色图Image_color和深度图Image_depth,得到不同时刻相匹配的连续帧Image_color_t1、Image_color_t、Image_color_t+1和Image_depth_t1、Image_depth_t、Image_depth_t+1,并将场景平均分为左中右三视场。
STEP2:利用当前场景的深度直方图(由Image_depth_t计算得出)判断移动机器人与跟踪目标间是否有遮挡物。
(1)无遮挡物则归类为“无障碍物出现”,同时执行避障行为1;
(2)有遮挡物则归类为“有障碍物出现”,进入STEP3判断该遮挡物类型。
STEP3:使用三帧差分法与金字塔LK光流法结合判断是否存在动态障碍物。
(1)如果不存在运动物体的有效图像,则归类为“静态障碍物”,同时执行避障行为2。完成避障行为后返回STEP1。
(2)如果得到了运动物体的有效图像,则归类为“动态障碍物”,同时执行避障行为3:将移动机器人运动场景的环境信息表征成若干个二维栅格系列,其中每个栅格都用一个概率值(可信度CV)来表示该像素点存在障碍物的可能性大小,使用VFH算法进行机器人的实时动态避障——栅格向量化、活动窗口分区、确定移动机器人的运动方向。完成避障行为后返回STEP1。
4 结论
本文提出的避障系统具有以下优势:(1)基于彩色图像与深度图像的融合,能使获取到的障碍物的边缘更清晰;(2)通过对障碍物的识别分类的预判,与时刻进行未知环境下的避障算法相比,从一定程度上能够降低系统能耗,提升工作效率;(3)判断动态障碍物时,先对图像视频序列进行帧间差分运算,得到运动目标区域,再进行金字塔式的光流运算,这样既避免了光照环境对检测结果的影响,同时还可以检测到运动速度过大的目标。相比于传统的金字塔LK光流法,该算法的计算量较低,算法的处理速度较快,因而更加满足了系统对实时性的要求。
参考文献:
[1]陈旭凤,李玉龙,侯志奇,等.基于TOF的快速加权中值滤波深度成像系统[J].科技风,2019(26):3435.
[2]丁萍,宋砚.基于RGBD图像进行遮挡处理和恢复的目标跟踪方法,中国科技论文在线,http://www.paper.edu.cn.
[3]郝慧琴.基于单目视觉移动机器人的避障研究[D].中国优秀搏硕士学位论文全文数据库(硕士)信息科技辑,2016,08.
[4]陈至坤.基于光流法的移动机器人避障平衡策略的改进[J].华北理工大学学报(自然科学版),2018,40(2).
平台支撑:“河北省冶金工业过程数字化控制技术创新中心”支撑(平台编号:SG2021185);“河北省钢铁焦化企业污染治理技术创新中心”支撑(平台编号SG2020220)
基金项目:中央引导地方科技发展资金项目(项目编号:216Z1004G)
作者简介:陈旭凤(1991— ),女,汉族,河北定州人,硕士研究生,讲师,研究方向:人工智能、機器视觉。
*通讯作者:赵彦伟。
