基于NATCA-Greater YOLO的航拍小目标检测
2023-05-30艾振华臧升睿陈敏陈倩倩迟洁茹杨国为于腾
艾振华 臧升睿 陈敏 陈倩倩 迟洁茹 杨国为 于腾


摘要:为解决通用目标检测模型在无人机航拍场景下存在的物体尺度变化剧烈及复杂的背景干扰等问题,本文主要对基于NATCA-Greater YOLO的航拍小目标检测进行研究。在特征提取网络的最后一层,加入邻域注意力转换器(neighborhood attention transformer,NAT),以保留足够的全局上下文信息,并提取更多不同的特征。同时,在特征融合网络(Neck)部分,加入坐标注意力(coordinate attention,CA)模块,以获取通道信息和更长范围的位置信息,将原卷积块中的激活函数替换为Meta-ACON,并使用NAT作为新网络的预测层,以VisDrone2019-DET目标检测数据集为基准,在VisDrone2019-DET-test-dev数据集上进行测试。为了评估NATCA-Greater YOLO模型在航拍小目标检测任务中的有效性,采用Faster R-CNN、RetinaNet和单步多框目标检测(single shot multiBox detector,SSD)等检测网络在测试集上进行对比检测。研究结果表明,NATCA-Greater YOLO检测的平均精度为42%,与最先进的检测网络TPH-YOLOv5相比,NATCA-Greater YOLO的检测精度提升了2.9%,说明该模型可以准确地定位并识别目标。该研究具有一定的创新性。
关键词:NAT; CA; Meta-ACON; 小目标檢测
中图分类号:TP391.41; TP183 文献标识码:A
文章编号:1006-9798(2023)02-0018-08; DOI:10.13306/j.1006-9798.2023.02.003
基金项目:山东省自然科学基金面上资助项目(ZR2021MF025); 国家自然科学基金面上资助项目(62172229)
作者简介:艾振华(1997-),男,硕士研究生,主要研究方向为计算机视觉和目标检测。
通信作者:于腾(1988-),男,博士,副教授,主要研究方向为机器学习、计算机视觉和人工智能等。Email:yutenghit@foxmail.com
近年来,无人机在农业、航空摄影、快速交付和监控等领域应用广泛,从这些平台获取收集到的视觉数据中,提取有效的特征信息变得越来越重要[1]。目标检测是最基本和最重要的任务,是目标追踪和行为识别等高级视觉任务的基石。目前,主流的目标检测框架主要分为Anchor-Based和Anchor-Free 2种方法,其中Anchor-Free方法是通过对关键点的定位和回归进行检测。CornerNet[2]是将物体检测作为一对关键点(边界框的左上角和右下角),然后根据距离对这些关键点进行分组,以获得最终检测结果。CenterNet[3]是预测物体的中心点,根据边界框的中心点回归每个对象对应的大小。Anchor-Based方法可分为二阶段网络和一阶段网络。SSD[4]和YOLO[5-7]是一阶段检测网络,检测速度快,但准确率较低。与一阶段网络相比,Faster R-CNN[8-9]、Cascade R-CNN[10]等二阶段检测器加入区域提案网络(region proposal network,RPN),生成约2 000个建议框,然后再对建议框分类和定位,虽然检测速度较慢,但准确率高。上述通用目标检测模型,虽然在MS COCO[11]、PASCAL VOC[12]和ImageNet[13]等传统数据集上取得了优异的表现,但对于VisDrone[14]和UAVDT[15]数据集,由于无人机拍摄的图像具有大量的小目标(尺寸小于32像素),包含很多复杂的背景信息,物体的尺寸变化剧烈,检测性能较差。DPNet[16]在骨干网络中加入了全局上下文(global context,GC)和可变形卷积(deformable convolution,DC),来提高卷积神经网络(convolution neural network,CNN)的特征提取能力。图像金字塔尺度归一化(scale normalization for image pyramids,SNIP)[17]将尺度归一化用于多尺度训练的图像金字塔。与通用目标检测模型相比,虽然上述模型在一定程度上提高了检测性能,但这些方法都是间接解决由小目标、复杂背景、物体尺寸跨度大导致的问题,没有一个具体的算法或结构,网络的适用性有限。视觉转换器(vision transformer,ViT)[18-19]中使用自注意力(self-attention,SA),可以保留不同图像块之间的位置信息,当拥有足够多的数据进行训练时,ViT的表现就会超过CNN,突破transformer,缺少归纳偏置的限制,对于航拍小样本,检测效果较差。滑窗转换器(swin transformer,ST)[20-21]将注意力计算限制在一个窗口中,滑窗操作等效于非重叠卷积,引入卷积神经网络局部性,与ViT相比,节省了计算量,但并未对小目标提出一个具体算法。基于此,本文在特征提取网络的最后一层加入NAT模块,并将原网络中的检测头换成NAT,NAT使用邻域注意力(neighborhood attention,NA)[22],与使用SA的ViT相比,NA直接将注意力操作范围限制到每个像素的邻域,将原始的全局注意力机制约束到局部窗口内的局部注意力,通过引入更多的局部偏置属性,提高在视觉任务上的表现。为了缓解2D池化导致的细节信息丢失,在特征融合网络中加入CA模块,与卷积块注意力模块(convolutional block attention module,CBAM)相比,CA将通道注意力分解为2个并行的1D特征编码过程,可以整合空间坐标信息,保留范围更广的位置信息。随着网络越来越深,图像分辨率也越来越低,过大的感受导致特征图上小目标占据的特征更少,影响检测结果,所以本文增加了一个检测头,与浅层特征图进行融合,并将预测层替换成NAT,提高了小目标检测的准确率。该研究对无人机目标检测算法的应用具有重要意义。
1 研究方法
1.1 整体网络架构
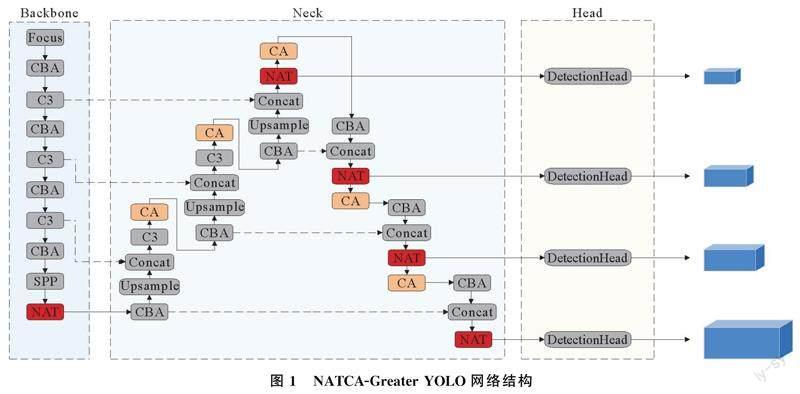
针对航拍小目标检测,本文设计了NATCA-Greater YOLO网络,网络整体结构包括特征提取(Backbone),特征融合(Neck)和预测层(Head)3部分。Backbone负责提取输入图像的特征,生成特征图;Neck负责利用Backbone阶段提取到的不同层级的特征进行聚合再处理;Head负责利用Neck聚合细化过的特征图,检测目标的位置和类别。NATCA-Greater YOLO网络结构如图1所示。
在NATCA-YOLOv5的特征提取层,使用Meta-ACON[23]激活函数,代替原网络中的SiLU激活函数,在SPP层后面,加入NAT,并将不同层级的特征输入到Neck部分,经过3次上采样之后,使用NAT代替原网络的预测层,4个预测层检测的目标尺寸由小到大。
1.2 邻域注意转换器
对于目标检测等视觉任务,图像的分辨率比分类任务大得多,对于航拍图像,图像分辨率较高,此时ViT中的SA机制会导致过高的复杂度和计算量,影响模型在视觉任务中的性能。卷积的性能多受益于归纳偏差,而SA是全局操作,虽然多层感知机(multi-layered perceptron,MLP)层具有局部性和平移不变性,但其他的归纳偏差必须通过大量数据来弥补,所以ViT模型在VisDrone小样本数据集上的效果较差。NAT是基于NA构建的新型分层视觉转换器,NAT网络结构如图2所示。
NAT延续分层的金字塔结构,每一层跟着一个下采样操作,来缩减一半的尺寸。与Swin 转换器[24]不同,NAT利用小内核卷积来嵌入和下采样,而不使用非重叠卷积。与ViT相比,NAT将SA替换成了NA,通过将全局注意力机制约束到局部窗口内的局部注意力,引入了更多的局部偏置属性,保证NAT在VisDrone等小样本数据集上也具有超越CNN的优异性能,表现出更强大的特征提取能力,保留更多的全局上下文信息。
NA是一种更简单、更灵活的视觉注意力机制,邻域注意力如图3所示。它强制要求键向量Key和值向量Value的选择来自于以问题向量Query为中心的邻域,与SA相比,NA减少了计算成本,而且引入类似于卷积的局部归纳偏差,当邻域大小达到最大值(即输入图像大小)时,NA就退化为SA。NAT使用重叠卷积,将特征映射在不同级别之间进行向下采样。
将特征图中的每个像素重复图3中的操作,对于不能居中的角像素,通过扩展邻域保持感受野的大小。例如L=3,每个query将以围绕它的9个key-value像素结束,即以query为中心的3×3网格。对于角像素,邻域也是一个3×3的网格,但query不在中心。
1.3 坐标注意力机制
CNN可以高效融合不同层级的特征信息,但随着网络的不断加深,池化操作导致丢失了通道之间和特征位置之间的细节信息。输入特征图经过卷积之后,每个位置都包含了原图像一个局部区域的信息,卷积块注意力模块(convolution block attention module,CBAM)是对每个位置的多个通道取最大值和平均值作为加权系数,但这种方式只考虑局部区域信息,无法获取长范围依赖的信息。坐标注意力机制将通道注意力分解为2个并行的一维特征编码,经过编码后,这2个特征图都含有特定方向信息,每个特征图都沿一个空间方向获取输入特征图中更长范围的信息,使模型可以更准确的定位,并识别目标区域。坐标注意力如图4所示。
对于通道注意力,将全局位置信息压缩到通道信息中,难以保持位置信息,所以先通过2个维度上的一维全局池化,可以获得该方向上更长的依赖信息,同时保持另一方向上的位置信息。对于输入x,(H,1)和(1,W)分别沿着水平坐标和垂直坐标对每个通道进行编码,即
式中,zhc为通道上的空间信息沿水平方向全局池化后的特征向量;zwc为通道上的空间信息沿垂直方向全局池化后的特征向量;xc为输入特征向量;W为特征图的宽度;H为特征图的高度。
将2个池化后的向量,沿着空间维度进行拼接,经过一个二维卷积减少通道数,降低模型复杂度,然后进行正则化和非线性激活,即
式中,f为输出特征图;δ为非线性激活函数;F1为正则化;zh为沿水平坐标进行编码的向量;zw为沿垂直坐标进行编码的向量。
f沿着空间维度分成了2个张量(c/r,1,H)和(c/r,1,w),然后分别经过卷积恢复到和输入xc相同的通道数,最后经过sigmoid归一化加权,即
式中,gh为与输入xc相同通道数的水平分量;Fh为水平方向上的正则化;fh为f的水平分量;gw为与输入xc相同通道数的垂直分量;Fw为垂直方向上的正则化;fw为f的垂直分量;σ为sigmoid激活函数。
将gh和gw等效为权重,沿着水平方向和垂直方向的注意同时应用于输入张量,得到坐标注意力为
式中,yci,j为像素(i,j)处的坐标注意力;ghc(i) 为水平方向上的等效权重;gwc(j) 为垂直方向上的等效权重。
在深层特征空间中,CA通过2个一维全局池化操作,使网络可以获得更大的感受野及编码准确的空间位置信息,对目标区域的检测和定位更加准确。
1.4 激活函数
為了提高模型的泛化能力,将原网络卷积模块中的激活函数换成Meta-ACON,它可以自适应的选择是否激活神经元,进一步提高网络精度。ReLU激活函数本身是一个MAX函数,只考虑2个输入量时,可微分变体平滑最大值为
其中,σ为sigmoid函数;β是一个平滑因子,当β趋近于无穷大时,Smooth Maximum为标准的MAX函数,当β为0时,Smooth Maximum为求算术平均。
Sβ0,x为平滑形式下的ReLU,在此基础上提出了激活或不激活(activate or not,ACON)系列的激活函数,其中ACON-C是最广泛的一种形式,即
式中,p1,p2使用的是2个可学习参数来自适应调整;ACON系列的激活函数通过β值控制是否激活神经元,所以计算通道级β的自适应函数为
式中,H为特征图的高;W为特征图的宽;xc,h,w表示通道数为c、高为h、宽为w的输入特征向量;σ为sigmoid激活函数;W1(c,c/r)和W2(c/r,c)用来节省参数量,通道数为c,缩放参数r设置为16。
分别对H,W维度求均值,然后通过2个1×1的卷积层,使每个通道的所有像素共享一个权重,并通过Meta-ACON提高网络的精度和泛化能力。
2 实验结果与分析
2.1 数据集
VisDrone2019-DET基准数据集有10 209张静态图像,这些图像是在无限制场景下,由无人机平台拍摄所得。其中,训练集有6 471张图片,验证集有548张图片,测试集有1 610张图片,测试挑战集有1 580张图片。无人机拍摄的图像比例差异巨大、背景干扰复杂、大部分物体都很小(小于32像素),而且视角多变,对于同一个物体,视角不同,也会存在很大的差别。
该数据集共有10类数据,数据整体分布不均衡,行人和轿车占比较大,VisDrone2019-DET数据分布如图5所示。本文中的所有模型,都是在训练集上进行训练,在测试集上进行评估。
2.2 评价指标
与MS COCO[7]中的评价指标类似,本文使用平均精度(mean average precision,mAP)来评估检测算法的结果,mAP是所有类别中统一步长为0.05的[0.50∶0.95]范围内所有10个交并比(intersection over union,IOU)阈值的平均值,将它作为算法检测的主要指标。
2.3 对比试验与消融试验
本文设计的算法基于PyTorch深度学习框架和YOLOv5实现,使用的显卡型号为NVIDIA GeForce RTX 2080Ti 11GB。模型训练时使用随机梯度下降(stochastic gradient descent,SGD)作为优化器,其权重衰减默认值为0.000 5,动量默认值为0.937。在模型初始训练中,首先进行3轮热身训练,热身过程中,优化器SGD的动量被设置为0.8,并使用一维线性差值,更新每次迭代的学习率。热身训练结束后,使用余弦退火函数,减小学习率,其中初始学习率为0.02,最小学习率为0.2×0.01,最后对模型进行100轮的训练。
为了评估NATCA-Greater YOLO模型在航拍小目标检测任务中的有效性,使用Faster R-CNN[8],RetinaNet[25],SSD[4],FCOS[26],DETR[27],TPH-YOLOv5[28]等检测网络,在测试集上进行对比检测,每个模型都使用mAP作为主要衡量指标,各模型平均精度对比结果如表1所示。由表1可以看出,与传统的CNN模型相比,NATCA-YOLOv5模型在航拍小目标检测任务中具有更强的泛化能力。
为了验证各个模块对NATCA-YOLOv5模型的作用,分别检验坐标注意模块、坐标注意力机制和Meta-ACON激活函数对结果的影响,各模型平均精度消融实验结果如表2所示。
由表2可以看出,YOLOv5网络是基础的模型结构,没有添加NAT模块和坐标注意力,卷积块中使用SiLU激活函数。在YOLOv5基础上,在Backbone的最后一层添加了NAT模块,并将原网络的预测层换成NAT模块,与YOLOv5相比,AP指标提升了10.4%。当Neck模块加入坐标注意力机制,并与添加CBAM注意力机制进行对比,发现CA模块在AP指标上提升了1.5%。将原网络中卷积层的激活函数换成Meta-ACON激活函数后,AP指标提升到42%。以上实验表明,在YOLOv5网络中,添加NAT模块和坐标注意力,并结合使用Meta-ACON激活函数,可以在航拍小样本数据集上的小目标检测任务中,提升模型的检测精度的准确率和泛化能力。
模型预测的准确率与召回率(precision recall,PR)曲线如图6所示。由图6可以看出,在YOLOv5网络基础上,添加NAT模块后,所有类别的AP指标均为39.3%,其中轿车的AP指标为76.8%,行人的AP指标为46%,在小样本数据集上也取得了较好的表现。加入卷积块注意力模块后,平均精度为39.7%,整体性能提升不大。加入坐标注意力后,在深层网络中,不仅可以获取不同通道间的信息,还可以通过位置编码,获得更长范围的信息,所有类别的AP指标均达到41.2%,其中轿车的AP指标为78.9%,行人的AP指标达到48.6%,与图6a相比,分别提升了2.1%和2.6%。
为了进一步提升模型的检测精度,将原网络卷积块中的激活函数替换为Meta-ACON,NATCA-Greater YOLO最终在所有类别上的AP指标达到42%,对于自行车、三轮车和带篷三轮车等样本较少和类别相似物体的检测有一定的提升。在不同场景下,NATCA-Greater YOLO的检测结果如图7所示。
由图7可以看出,本文提出的模型可有效检测到图7a中的密集小目标,排除了图7b图中矩形绿地背景的干扰,准确检测到了图7c图中不同尺度的目标。总之,在面对复杂背景干扰、小目标、物体尺寸跨度大的挑战下,NATCA-Greater YOLO模型可以准确地定位并识别目标。
3 结束语
本文主要对基于深度学习的航拍小目标检测进行研究。分析了通用目标检测模型和现有航拍目标检测模型的基本原理及局限性。同时,分析了航拍图像存在的大量小目标、目标尺寸跨度大、背景复杂等特点,通过比较现有航拍目标检测算法,在YOLOv5模型的基础上,提出了一个新的网络架构NATCA-Greater YOLO。对于小目标检测精度较差的问题,加入了鄰域注意力转换器,并从更浅层的网络提取特征信息进行预测。为进一步排除复杂背景信息的干扰,加入坐标注意力,保留全局和上下文信息。同时,为提高模型的泛化能力,改进了原网络的激活函数。实验结果表明,本文提出的网络模型拥有更强的视觉信息和特征提取能力,与通用目标检测网络相比,检测精度显著提升。虽然本算法在检测精度上有所提高,但对于类别相似的目标,检测效果并不好。该实验基于计算机环境,由于无人机体积小,计算资源和空间资源有限,当模型部署到无人机后,检测的速度和精度还有待提高。为了进一步深入研究本课题,接下来的工作主要围绕2个方面进行,一是改进算法,提高相似目标的检测精度;二是设计轻量化网络结构,在降低模型复杂度的同时,保持较高的检测精度。
參考文献:
[1] LAW H,DENG J. Cornernet:Detecting objects as paired keypoints[C]∥In European Conference on Computer Vision (ECCV) . Munich,Germany:Springer,2018:734-750.
[2] DUAN K,BAI S,XIE L,et al. Centernet:Keypoint triplets for object detection[C]∥IEEE/CVF international conference on computer vision. Seoul,Korea(South):IEEE/CVF,2019:6569-6578.
[3] LIU W,ANGUELOV D,ERHAN D,et al. Ssd:Single shot multibox detector[C]∥In European Conference on Computer Vision. Amsterdam,Netherlands:Springer,2016:21-37.
[4] REDMON J,DIVVALA S,GIRSHICK R,et al. You only look once:Unified,real-time object detection[C]∥IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,NV,USA:IEEE,2016 :779-788.
[5] REN S,HE K,GIRSHICK R,et al. Faster R-CNN:Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,39(6):1137-1149.
[6] CAI Z,VASCONCELOS N. Cascade R-CNN:Delving into high quality object detection[C]∥IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT,USA:IEEE,2018:6154-6162.
[7] LIN TY,MAIRE M,BELONGIE S,et al. Microsoft coco:Common objects in context[C]∥In European Conference on Computer Vision. Zürich,Switzerland:Springer,2014:740-755.
[8] EVERINGHAM M,VAN GOOL L,WILLIAMS C K,et al. The pascal visual object classes (voc) challenge[J]. International Journal of Computer Vision,2010,88(2):303-38.
[9] DENG J,DONG W,SOCHER R,et al. Imagenet:A large-scale hierarchical image database[C]∥In 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami,EL,USA:IEEE,2009:248-255.
[10] DU D,ZHU P,WEN L,et al. VisDrone-DET2019:The vision meets drone object detection in image challenge results[C]∥IEEE/CVF International Conference on Computer Vision Workshops. Seoul,Korea(South):IEEE/CVF,2019:19432701.
[11] DU D,QI Y,YU H,et al. The unmanned aerial vehicle benchmark:Object detection and tracking[C]∥European Conference on Computer vision (ECCV) . Munich,Germany:Springer,2018:370-386.
[12] DU D W,ZHU P F,WEN L Y,et al. VisDrone-DET2019:The vision meets drone object detection in image challenge results[C]∥IEEE/CVF International Conference on Computer Vision Workshops. Seoul,Korea(South):IEEE/CVF,2019:1-36.
[13] SINGH B,DAVIS L S. An analysis of scale invariance in object detection snip[C]∥IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT,USA:IEEE,2018:3578-3587.
[14] ARNAB A,DEHGHANI M,HEIGOLD G,et al. Vivit:A video vision transformer[C]∥IEEE/CVF international conference on computer vision. Montreal:IEEE/CVF,2021:6836-6846.
[15] LIU Z,LIN Y,CAO Y,et al. Swin transformer:Hierarchical vision transformer using shifted windows[C]∥IEEE/CVF International Conference on Computer Vision. Montreal,Canada:IEEE/CVF,2021:10012-10022.
[16] HASSANI A,WALTON S,LI J,et al. Neighborhood attention transformer[J]. arXiv preprint arXiv:2204. 07143,2022.
[17] MA N,ZHANG X,LIU M,et al. Activate or not:Learning customized activation[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition. Virtual:IEEE/CVF,2021:8032-8042.
[18] 宋譜怡,陈红,苟浩波. 改进YOLOv5s的无人机目标检测算法[J]. 计算机工程与应用,2023,59(1):108-116.
[19] LIN T Y,GOYAL P,GIRSHICK R,et al. Focal loss for dense object detection[C]∥IEEE International Conference on Computer Vision. Venice,Italy:IEEE,2017 :2980-2988.
[20] LIU W,ANGUELOV D,ERHAN D,et al. Ssd:Single shot multibox detector[C]∥In European Conference on Computer Vision. Amsterdam,Netherlands:Springer,2016 :21-23.
[21] TIAN Z,SHEN C,CHEN H,et al. Fcos:Fully convolutional one-stage object detection[C]∥IEEE/CVF International Conference on Computer Vision. Seoul,Korea(South):IEEE/CVF,2019 :9627-9636.
[22] CARION N,MASSA F,SYNNAEVE G,et al. End-to-end object detection with transformers[C]∥In European Conference on Computer Vision. Glasgow,US:Springer,2020:213-229.
[23] ZHU X K,LYU S,WANG X,et al. TPH-YOLOv5:Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios[C]∥IEEE/CVF International Conference on Computer Vision. Montreal,Canada:IEEE,2021:2778-2788.
[24] 刘芳,吴志威,杨安喆,等. 基于多尺度特征融合的自适应无人机目标检测[J]. 光学学报,2020,40(10):133-142.
[25] 祁江鑫,吴玲,卢发兴,等. 基于改进YOLOv4算法的无人机目标检测[J]. 兵器装备工程学报,2022,43(6):210-217.
[26] 田永林,王雨桐,王建功,等. 视觉Transformer研究的关键问题:现状及展望[J]. 自动化学报,2022,48(4):957-979.
[27] 桑军,郭沛,项志立,等. Faster-RCNN的车型识别分析[J]. 重庆大学学报(自然科学版),2017,40(7):32-36.
[28] 黄媛媛,熊文博,张宏伟,等. 基于U型Swin Transformer自编码器的色织物缺陷检测[J/OL]. 激光与光电子学进展:1-12[2023-03-23]. http:∥kns. cnki. net/kcms/detail/31. 1690.in. 20220927. 1957. html.
Abstract:In order to solve the problems of the general object detection model in the images captured by drones,including drastic scale variance and complex background interference,this paper focuses on the detection of small objects in aerial photography based on NATCA-Greater YOLO. We add neighborhood attention transformer (NAT) to the last layer of the feature extraction network to retain sufficient global context information and extract more different features. Meanwhile,in the feature fusion network (Neck) part,the coordinate attention (CA) module is added to obtain channel information and longer range location information,the activation function in the original convolutional block is replaced with Meta-ACON,and NAT is used as the prediction layer of the new network. Using the VisDrone2019-DET object detection dataset as a benchmark,tests were conducted on the VisDrone2019-DET-test-dev dataset. To evaluate the effectiveness of the NATCA-Greater YOLO model in the aerial photography small object detection task,detection networks such as Faster R-CNN,RetinaNet and SSD (single shot multiBox detector) were used for comparative testing on the test set. The results show that the average accuracy of NATCA-Greater YOLO detection is 42%,which is 2.9% improvement compared to the state-of-the-art detection network TPH-YOLOv5. This study is innovative.
Key words:NAT; CA; Meta-ACON; small object detection
