基于潜在因子多样性的非负矩阵分解协同过滤模型
2023-05-30陶名康王新利宋燕
陶名康 王新利 宋燕


摘要:基于非负矩阵分解的协同过滤模型在高维稀疏数据的预测和填补上十分有效,该模型具有推荐个性化、有效利用其他相似用户回馈信息的优点,但也存在预测精度较低等不足。针对用户或项目在不同情景下的评分差异性,提出了一种改进的基于潜在因子多样性的非负矩阵分解的协同过滤模型。该模型充分考虑在不同情境下,用户和项目潜在特征矩阵的多样性,在模型的训练中,采用了单元素非负乘法更新规则和交替方向法,保证了目标矩阵的非负性,且提高了模型的收敛率。在真实的工业数据集上的实验结果表明,相比于经典的非负矩阵分解模型,该模型的预测精度有了明显提高。
关键词:协同过滤;特征矩阵多样性;非负矩阵分解;非负乘法更新;交替方向法
中图分类号:TP 391
文献标志码:A
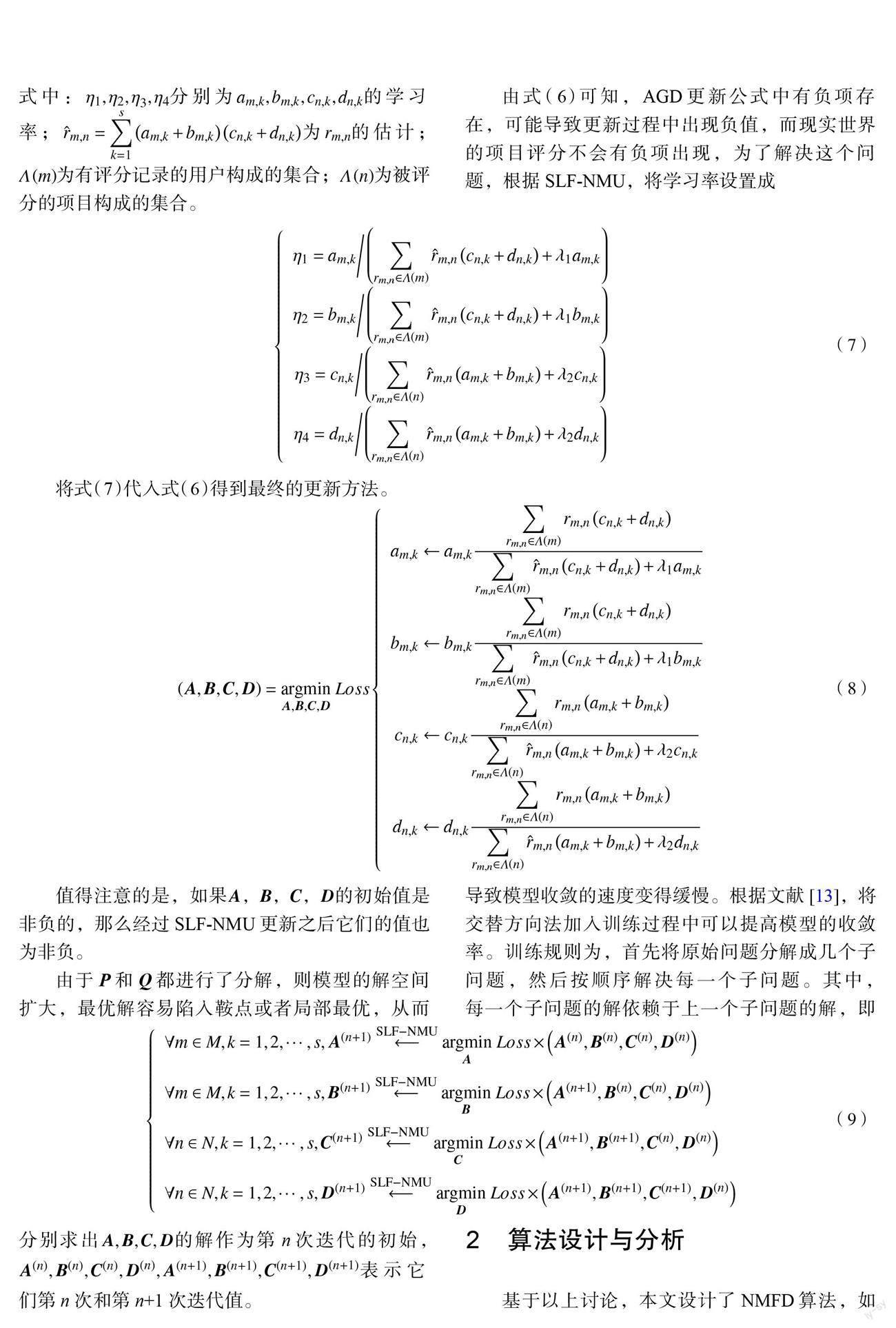
随着互联网技术的快速发展,很多领域都产生了海量数据,在对这些大数据进行分析与挖掘的过程中,推荐系统是一种广泛采用的技术。推荐系统是一个学习系统,包括用户、项目和用户对项目的评分3种基本成分。它通过对已有评分数据的学习,获得用户的行为偏好,建立用户和项目之间的关系,为用户提供个性化的推荐,使得用户更快速简便地找到自己所需要的信息,从而促进点击和购买行为的发生[1-2]。协同过滤推荐[3]是推荐系统中应用最广泛的推荐算法之一,一般分为3种类型:基于用户( user-based)的协同过滤、基于项目( item-based)的协同过滤、基于模型( model-based)的协同过滤。基于用户的协同过滤[4]通过计算用户和用户之间的相似度,找出相似用户偏好的项目,并预测目标用户对相应项目的评分,把评分最高的若干个项目推荐给用户。而基于项目的协同过滤[5]则是通过考虑项目和项目之间的相似度,然后根据预测评分进行推荐。基于模型的协同过滤[6]是一种使用更普遍的推荐算法,它基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户信息进行预测推荐,使用的主要方法有聚类[7]、分类[8]、回归[9]、矩阵分解[10]、神经网络[11]等。
在推荐系统中,一般情况下用户无法对每一个项目评分,而每一個项目也不能被所有的用户点击,只有部分用户和部分数据之间有评分数据,其他部分评分空白。因此,由用户对项目的评分构成的评分矩阵一般是一个高维稀疏矩阵。由于基于矩阵分解的协同过滤在处理此类矩阵的预测和填补方面具有较高的准确性和可扩展性[10],它是目前基于模型的协同过滤广泛采用的一种方法。矩阵分解,直观上来说就是把原来的大矩阵,近似分解成两个包含潜在变量的小矩阵,其中一个代表用户的潜在特征,另一个代表项目的潜在特征。矩阵的元素表示用户或项目对各潜在因子的符合程度,这两个小矩阵被称为潜在因子特征矩阵。另一方面,为了使学习到的特征矩阵更准确地代表实际意义,并使获得的模型更具有可解释性,通常需要对特征矩阵进行非负性约束。在模型的学习中,单元素非负乘法更新规则[12]( SIF-NMU)和交替方向法[13](ADM)是目前最常用的训练原则,它可以避免调节学习率,同时还保证了潜在因子的非负性。
传统的基于矩阵分解的协同过滤模型通过把高维矩阵映射为两个低维潜在因子矩阵,使得模型具有较高的预测精度。但是,影响评分数据的很大一部分因素和用户对物品的喜好无关,而只取决于用户或物品本身的特性。例如,对于乐观的用户来说,它的评分等级普遍偏高,而对批判性用户来说,他的评分等级普遍偏低。通常改进的基于矩阵分解的协同过滤,通过在模型中加入偏置项[14-15]来体现这些独立于用户或物品的因素,使预测精度较传统的矩阵分解有很大提升。然而这些模型并没有考虑同一个用户或项目在不同情景下的评分差异性,不能充分体现用户和项目的潜在因子矩阵客观上具有多样性的特点。通常用户或项目所在的场景不同或用户的情绪变化都会影响潜在因子特征矩阵的状态。例如,某用户在某天心情较好时可能会给某部电影的打分偏高,反之心情不好的时候可能打分偏低;同一部电影在南方上映的评分可能会比较高,而在北方上映的评分会相对偏低。这些影响用户和项目评分的信息隐藏在评分矩阵中,忽略这些重要的隐藏信息会造成模型的预测精度下降。
为了解决这一问题,本文考虑了用户和项目的潜在因子矩阵多样性这一重要的隐含特征,提出了一种基于潜在因子多样性的非负矩阵分解的协同过滤模型( non-negative matrix-factorization-diversity-based, NMFD),刻画了用户和项目的情景差异性,并且在训练模型参数时集成了单元素非负乘法更新规则和交替方向法训练原则,保证了矩阵元素的非负性,使得模型具有更强的解释性。同已有的模型相比较,该模型在减少计算和存储成本的同时,推荐的精度也有明显提升。
1 模型与学习方法
1.1 非负矩阵分解模型(NMF)
协同过滤的推荐算法通常将用户关于项目的评分矩阵作为基本的数据输入源。用M表示用户组成的集合,Ⅳ代表项目组成的集合,用户对项目的评分构成的评分矩阵,记为RIMlxINI。其中:H表示集合中所有元素的个数;RIMlxINI中的元素记为rm它表示第m个用户对第n个项目的评分(偏好)。通常,某一个用户不能点击所有的项目,某个项目也不能被所有的用户点击,所以,评分矩阵RIMlxIN嗵常是高维稀疏(HiDS)的。
在经典的基于矩阵分解的协同过滤模型中[10],给定的评分矩阵R被分解为两个秩为s的矩阵pIMlxs,QINlxs。一般情况下,令s《min {IMI,INI),则R ≈ pQT。这里的P和Q被称为用户和项目的潜在因子矩阵,代表用户和项目隐藏在评分数据中的特征。基于潜在因子矩阵分解协同过滤模型的基本方法是寻找最优的P和Q,使得R中有评分的位置(实际值)与pQT得到的相应评分位置(预测值)之间的误差最小,目标函数为式中:Loss表示损失函数;||.||表示矩阵的F范数。
由于现实世界的评分不会出现负值,在式(l)中加入非负性约束,可以使所涉及的参数P和Q在训练过程中保证非负性。在形式上可以得到
为了防止模型在训练过程中发生过拟合,在目标函数中加入Tikhonov正则化,可以提高模型的性能[16],结合式(2)可以得到最终优化的目标函数为
1.3 NMFD模型的求解
首先使用加性梯度下降法(AGD),对式(5)各个变量进行更新。
值得注意的是,如果A,B,C,D的初始值是非负的,那么经过SLF-NMU更新之后它们的值也为非负。
由于P和Q都进行了分解,则模型的解空间扩大,最优解容易陷入鞍点或者局部最优,从而导致模型收敛的速度变得缓慢。根据文献[13],将交替方向法加入训练过程中可以提高模型的收敛率。训练规则为,首先将原始问题分解成几个子问题,然后按顺序解决每一个子问题。其中,每一个子问题的解依赖于上一个子问题的解,即
2 算法设计与分析
基于以上讨论,本文设计了NMFD算法,如算法1所示。值得注意的是,算法1依赖4个过程,分别为Update_A,Update_B,Update_C,Update_D。由于训练过程非常相似,本文只给出了Update_A的训练细节,如算法2所示。从算法1可知,基于ADM训练规则,A,B,C,D按顺序进行了更新,后一次的更新依赖于前一次的结果。
算法1 NMFD模型
设置潜在因子维数s,最大迭代次数T,收敛阈值δ,n=1。具体计算步骤如下:
Step 1输入原始评分矩阵R以及已知的元素
接下来考虑NMFD算法的复杂度,可以知道,在高维稀疏矩阵中,通常有IAI》max {IMI,INI)。因此,通过忽略低阶项和常数可以得到Update_A的计算复杂度为
而NMFD算法依赖4个过程,所以最终得到NMFD的计算复杂度为
由于n和s都是正常数,因此在高维稀疏矩阵中,NMFD模型算法的复杂度与观察到的元素个数呈线性关系,所以在现实中容易实施。
3 实验设计与结果分析
3.1 評估指标及对比模型
由于本文关注的是模型预测生成数据的准确性,故采用平均绝对误差( MAE)和均方根误差( RMSE)来作为评价指标。具体表达式如下:式中,P表示验证集,并且YciA=o。
从以上两个评价标准表达式可以得知,MAE和RMSE数值越小代表模型的预测精度越高。
实验对比模型为:Ml(带有正则化的NMFD)和M2(不带正则化的NMFD)分别表示本文提出的带有正则化项和不带正则化项的NMFD模型,M3(带有正则化的DF NMF)和M4(不带正则化的DF NMF)分别表示基于二分解(DF)的带正则化和不带正则化的NMF模型[10]。
3.2 实验数据集
为了验证本文模型的有效性,针对以下4个数据集进行实验:
a.DI(MovieLens)。该数据集是电影MovieLens采用的0.5~5的评分等级,包含610个用户对9724部电影的评价,创建时间从1995年1月至2015年3月,其密度为1.70%[17]。
b.D2(Filmtrust)。这是2011年从FilmTrust网站获取的不完整数据集,其中包含1 508名用户和2071部电影,评分等级为0.5~4,评分矩阵密度为1.14%[18]。
c.D3( Learning-from-sets-2019);该数据集是2016年2月至4月从MovieLens网站收集得到的,包含854个用户对6473部电影的评分,评分等级为0.5~5,其评分矩阵密度为0.53%[19]。
d.D4( Eachmovie)。该数据集是1997年DECSystems Research Center运行EachMovie推荐系统18个月,在此期间记录的72916个用户对1 628部电影的评分,评分等级为1~6。它的评分矩阵密度为9.89%c20]。
为了易于比较,在实验之前本文将数据集Dl-D4映射到[0,5]。为了消除偏差和主观因素,本文采用20%~80%的测试集一训练集划分,并使用5折交叉验证。为了说明NMFD模型的有效性,训练过程重复50次。
3.3对比分析
由于正则化系数对于模型性能影响较大[21],所以在对比实验进行之前,需要对上述模型中的参数利用交叉验证方法进行敏感度实验。在实验时发现λ1,λ2取不同值时,实验的精度影响不明显。所以为了简化实验,在Ml和M3中令Ai=λ2=λ,即仅对单一的参数进行训练。
表1给出了模型Ml,M3在Dl-D4上λ的最优值。表2和图1给出了Ml-M4在Dl-D4上训练的RMSE结果和收敛曲线。表3和图2给出了Ml-M4在Dl-D4上训练的MAE结果和收敛曲线。从表2和图1可得如下结论:
a.Ml在Dl-D4上整体表现较好,但是在不同的数据集之间存在着差异,Ml在Dl-D4上最终收敛的RMSE分别为0.2680,0.3561,0.0717,0.9141。整体而言,Ml在Dl-D4上的表现最好,这是因为Ml中拥有更多的自由变量,使得模型最终的解空间扩大,从而导致精度提升。
b.在加入Tikhonov正则化项之后,模型对未知数据的预测精度比不带正则化的模型有明显的提升。比如:在Dl上.Ml最终收敛的RMSE为0.2680,而M2最终收敛的RMSE为0.3405;在D2上,Ml最终收敛的RMSE为0.3561,而M2在Dl上最终收敛的RMSE为0.4170;在D3上,Ml最终收敛的RMSE为0.0717,而M2最终收敛的RMSE为0.1719;在D4上,Ml最终收敛的RMSE为0.914 1,而M2最终收敛的RMSE为0.9410。相同的结论可以从图2和表3可以得到。
由于潜在因子维数s对算法的存储和计算效率具有比较大的影响,所以接下来将s从5增加到100来训练模型,训练过程中的收敛曲线由图3给出。从图3易看出,Ml的RMSE在4个数据集中都是最小的。但是由前面算法复杂度式( 10)可知,s越大,算法的复杂度就越高,训练时间随之变长,并且随着s的增加,模型的精度不再有所提升,如图3(c)所示。所以本文选取s=20来平衡预测精度和计算效率。
表4记录了模型Ml-M4在数据集Dl-D4上关于RMSE的收敛时间。从表2、表3和表4可以看出,Ml和M2虽然增加了一定的计算负担,但是预测精度相比M3和M4有了大幅提高,更加适合在线实时进行和对计算精度要求比较高的实验。
4 结论
本文从矩阵的二分解出发,通过考虑用户和项目潜在因子矩阵的多样性,提出了NMFD模型。针对现实工业界评分数据的非负性特点,引入了AGD和SLF-NMU算法来保证训练过程中用户和项目潜在因子的非负性。由于训练的参数较多,为了防止模型在迭代过程中陷入局部最优,又将ADM原则加入到算法中,提高了模型的收敛性。最后在4个真实的数据集上做了对比实验。实验结果表明,本文提出的带有Tikhonov正则化项的NMFD在适当牺牲一些时间的情况下,预测缺失数据精度比经典的矩阵二分解模型有显著提升。未来可以将NMFD模型与带偏置的NMF结合,对该模型进行进一步的拓展研究。
参考文献:
[1]姚静天,王永利,侍秋艳,等,基于联合物品搭配度的推荐算法框架[J]上海理工大学学报,2017,39(1): 45-53.
[2]王国霞,刘贺平.个性化推荐系统综述[J]计算机]工程与应用,2012,48(7): 66-76.
[3]姚曜,赵洪利,杨海涛,等.协同过滤技术研究综述[J].装备指挥技术学院学报,2011,22(5): 81-88.
[4]王成,朱志刚,张玉侠,等,基于用户的协同过滤算法的推荐效率和个性化改进[J].小型微型计算机系统,2016,37(3): 428-432.
[5]傅鹤岗,王竹伟.对基于项目的协同过滤推荐系统的改进[J]重庆理工大学学报(自然科学),2010,24(9): 69-74.
[6]王硕,基于模型的协同过滤推荐算法研究[D].北京:北京邮电大学,2019.
[7]卢志茂,冯进玫,范冬梅,等,面向大数据处理的划分聚类新方法[J].系统工程与电子技术,2014, 36(5):1010-1015.
[8]邹斌,董雪梅,付丽华,等,基于算法稳定的分类机器学习泛化能力的研究[J]模式识别与人工智能,2004,17(4): 430-433.
[9]李振波,杨晋琪,岳峻,基于协同回归模型的矩阵分解推荐[J]图学学报,2019, 40(6): 983-990.
[10]王鹏,基于矩阵分解的推荐系统算法研究[D].北京:北京交通大学、2015.
[11] YI B L SHEN X X,LIU H,et al.Deep matrixfactorization with implicit feedback embedding forrecommendation system[J]. IEEE Transactions onIndustrial Informatics. 2019, 15(8): 4591-4601.
[12] LUO X,ZHOU M C,XIA Y N,et al.An efficient non-negative
matrix-factorization-based
approach
tocollaborative filtering for recommender systems[J]. IEEETransactions on Industrial Informatics, 2014, 10(2):1273-1284.
[13] LUO X,ZHOU M C,LI S,et al.A nonnegative latentfactor model for large-scale sparse matrices inrecommender systems via altemating direction method[J].IEEE Transactions on Neural Networks and LearningSystems, 2016, 27(3): 579-592.
[14]王建芳,劉冉东,刘永利,一种带偏置的非负矩阵分解推荐算法[J]小型微型计算机系统,2018, 39(1): 69-73.
[15]毕华玲,周微、卢福强,引入偏置的矩阵分解推荐算法研究[J]计算机应用研究,2018, 35(10): 2928-2931.
[16]张航,叶东毅,一种基于多正则化参数的矩阵分解推荐算法[J].计算机工程与应用,2017, 53(3): 74-79.
[17] HARPER F M, KONSTAN J A The MovieLens datasets:history and context[J]. ACM Transactions on InteractiveIntelligent Systems, 2016, 5(4): 1068-1074.
[18] GUO G B,ZHANG J,YORKE-SMITH N.A novelbayesian
similarity
measurefor
recommendersystems[C]//Proceedings of the Twenty-Third InternationalJoint Conference on Artificial Intelligence. Beijing: AAAIPress. 2013: 2619-2625.
[19] SHARMA M, HARPER F M, KARYPIS G.Learning fromsets of items in recommender systems[J]. ACMTransactions on Interactive Intelligent Systems, 2019, 9(4):1-26.
[20] MCJONES P. EachMovie collaborative filtering dataset[J]. Dec Systems Research Center. 1997, 24(9): 57-68.
[21] LUO X,ZHOU M C,XIAO Y N,et al.Generating highlyaccurate predictions for missing QoS data via aggregatingnonnegative latent factor models[J]. IEEE Transactions onNeural Networks and Learning Systems, 2016, 27(3):524-537,
(编辑:丁红艺)
