基于语料库的法律文化负载词“的”字的韩译研究
2023-05-28张晴晴
张晴晴
(徐州工程学院)
《中央宣传部、司法部关于开展法治宣传教育的第八个五年规划(2021-2025 年)》要求加强法治文化国际传播和国际交流,以讲好中国法治故事为着力点,突出对外宣传中华优秀传统法律文化等内容。高质量的法律翻译是实现这一目标的重要前提之一,但具有鲜明中国特色的法律文化往往在译入语中很难找到与之相对应的表达,特别是承载着中国独特法治文化的法律文化负载词给翻译造成诸多困难。所谓文化负载词(culture-loaded terms)指的是标志某种文化中特有事物的词、词组和习语,这些词汇反映了特定民族在漫长的历史进程中逐渐积累的有别于其他民族的独特的活动方式。[1]译者在翻译文化负载词时,由于理解的角度不同和选择的翻译策略不同,常会将相同的文化负载词翻译为不同的版本,这在翻译中是客观存在的正常现象。[2]由于不同国家和民族之间的文化差异,法律文本中也存在大量的文化负载词,但是准确性和严谨性是法律翻译的重要标准,相同文化负载词翻译的多样性容易造成法律概念混乱,引起译文读者的误解,损害法律翻译的准确性和严谨性。法律文化负载词的译名统一问题也因而成为译者翻译时所面临的重要难题。
中国法律中经常使用一种独特的“的”字,常以“X+的,”“X+的;”“X+的。”等形式出现在句子中,具有复杂的语法和语义功能,由于在韩文中没有与之相对应的固定表达,导致译者在翻译时很容易出现误译或者译文不规范的问题。中韩两国间的协定或条约的中文版和韩文版均是由官方公布的权威法律文本,如果能够总结出“的”字在这些文本中的对应规律,显然对解决法律文本中“的”字翻译问题具有重要启示意义。因此,本文以中韩两国官方公布的10 部中韩协定(中文总字数约为24 万,韩文总字数约为29 万)为语料自建平行语料库,结合语料库的统计分析,探究“的”字的使用特征和韩译规律,以期为中韩法律翻译研究和实践提供参考和指导。
一、研究语料及方法
语料库(corpus)是将真实使用的大量语言信息经过科学地收集、整理而形成的语言资料库。平行语料库(parallel corpus)在语料库的基础上发展而来,是由一种语言原文文本和一种或多种译文文本在段落、句子或词汇层面形成对齐的语言资料库,一般用于原文和译文间的差异比较或等值关系研究。平行语料库有别于可比语料库(comparable corpus),后者所收集的语料一般是属于同一主题但相互间不存有翻译关系的语料,如二语习得者产出的语言与母语者产出的语言。
平行语料库的构建环节主要包括选取语料、清洁语料、对齐文本、文本分词、文本标注、文本储存等,根据建库目的的不同,各个环节也可适当的调整。本文语料库的构建目的是通过语料库检索和统计功能等来考察中韩协定中“的”字的使用特征和韩译规律,为实现这一目的要求所构建的语料库应满足以下原则:语料真实、权威,内容均衡,确保语料库具有代表性;语料对应整齐、无杂质,能够快速检索、定位关键词并进行数据统计;能扩大或更新语料库,为以后的深入研究做准备。为此,本语料库所有语料均选自中国外交部、韩国外交部、韩国法制处等官方网站,包括《中华人民共和国政府和大韩民国政府自由贸易协定(2015.12.20)》《中华人民共和国政府和大韩民国政府领事协定(2015.04.12)》《大韩民国政府和中华人民共和国政府气候变化合作协定(2015.02.28)》《大韩民国政府与中华人民共和国政府关于合作拍摄电影的协议(2015.01.29)》《中华人民共和国政府、日本国政府及大韩民国政府关于促进、便利及保护投资的协定(2014.05.17)》《中华人民共和国政府和大韩民国政府社会保险协定(2013.01.16)》《大韩民国政府和中华人民共和国政府陆海联运汽车货物运输 协 定(2010.11.25)》《 中华人民共和国政府与大韩民国政府海上搜寻救助合作协定(2007.05.16)》《中华人民共和政府和大韩民国政府渔业协定(2001.06.30)》,《中华人民共和国和大韩民国关于刑事司法协助的条约(2000.03.24)》等10 部中韩协定,内容涵盖政治、经济、社会、环境、海洋、司法等多个领域。接下来,借助EditPlus4、中文文本处理器等工具清除语料中的表格、公式、标记、图片、非文字内容等杂质,并使用TMXMALL 在线对齐工具对语料进行了对齐。双语平行语料库的对齐单位有篇章、段落、句子、短语、词等不同的层次。由于大多数自然语言间缺乏一对一的对应关系,所以词级对应极其困难且容易出错,段级对应则因为过于宽泛而难以检索和定位,因此本语料采用的是句级对齐。此外,由于翻译很多时候并不是遵照句子对句子的原则,省译、扩译、摘译等情况经常出现,且法律中部分句子极长,因此除了句号外,部分逗号和分号也被视为句子的边界标准。最终,本语料库共生成2816 条句对,总字数约为53 万。接下来,分别使用WordSmith Tools8.0软件进行单语检索和统计,使用Transmate 软件进行双语平行检索统计,通过量化数据及实例,对“的”字的使用情况和对应的韩文表达进行定量和定性相结合的分析。
二、“的”字的概念与研究现状
“的”字在汉语中是一个虚词,常出现于“X+的+Y”的结构中。这里的“X”可以是名词、动词、形容词、代词等单词,如“木头的椅子(名词+的)”,“知道的多(动词+的)”,“白的纸(形容词+的)”;“X”也可以是词组,如“看电视的人(动宾短语+的)” ;“X”也可以是句子,如“我借给他钱的那个人(句子+的)”。传统的观点认为,“X+的”是修饰中心语的定语成分,“X+的”后面直接是被修饰的中心语,如“[善良的]男人”,“[通往成功的]路”,“[我最爱的]人”等。但是这没法解释“开车的回家了”,“披露将造成侵犯隐私权或合法的商业利益的。”等语言现象。因为“开车的回家了”中,“回家了”是谓语性成分(Verb Phrase,以下简称VP),不能被定语成分来修饰。“披露将造成侵犯隐私权或合法的商业利益的。”中,“的”字后面是句号,缺少中心语。
目前学界关于此类特殊的“的”字主要有“名词说”和“省略说”两大主流观点。名词说以朱德熙为代表。朱德熙认为,可以将“的”字看作是一种名词化的标记,作为谓语性成分的“X”在添加了“的”字后,“X+的”就具有了名词的属性(Noun Phrase,以下简称NP),可以用作主语、宾语等句子成分。[3]但也有很多学者并不认同朱德熙的观点,他们认为此类“X+的”结构仍然是一个定中结构,只是“的”字后面省略了中心语,通过上下文语境或者相关背景知识能够找出被省略的中心语。因此,在“红的好看”中,“红的”可以看作是“红的颜色”省略了中心语“颜色”,“开车的”可以看作是“开车的人”省略了中心语“人”。
无论是名词说,还是省略说,从中都可以看出此类“的”字的显著特征:与一般的定中结构不同,“的”字后面没有中心语,且常跟表示停顿的标点符号;“X+的”具有名词性的属性,可以直接用作主语、宾语、同位语等成分;需要结合具体的语境和背景知识补充一定的内容才能把握“X+的”的准确语义。
中国法律是使用此类特殊“的”字频率最高的文本之一。徐优平等指出,大量使用以“的”字结尾的假设是中国法律最显著的特征之一。[4]余致纯最早对中国法律中的此类“X+的”结构进行了定义,认为其是定中短语在一定条件下省略中心语而构成的名词短语。[5]冯文贺等分析了“X+的”结构的语义功能,认为其具有表示假设和条件的语义功能,一般可直接转换为条件句。[6]此外,不少学者探讨了法律文本中的“X+的”结构的英译方法。郑剑委认为可根据不同情形将其翻译为名词词组、介词词组、定语从句和状语从句[7];蒋长刚等认为可将其翻译为名词、介词、主语从句、条件从句、状语从句等。[8]然而,目前鲜有学者关注法律文本中此类“的”字的韩译情况。
三、中韩协定中“的”字的韩译规律
由 于“ 的” 字 后 面 常会带有表示停顿的标点符号, 所以在语料库中以“的、”“的,”“的;”“的:”“的。”为关键词分别进行了检索。排除掉“目的、”“目的,”“目的;”等不相关信息,最终检索出74个符合要求的结果。为避免遗漏,在语料库中也以“的”为关键词进行了检索,排除掉“的”后面存在定语中心语的情形,检索出7 个符合要求的结果,检索结果如表1 所示。
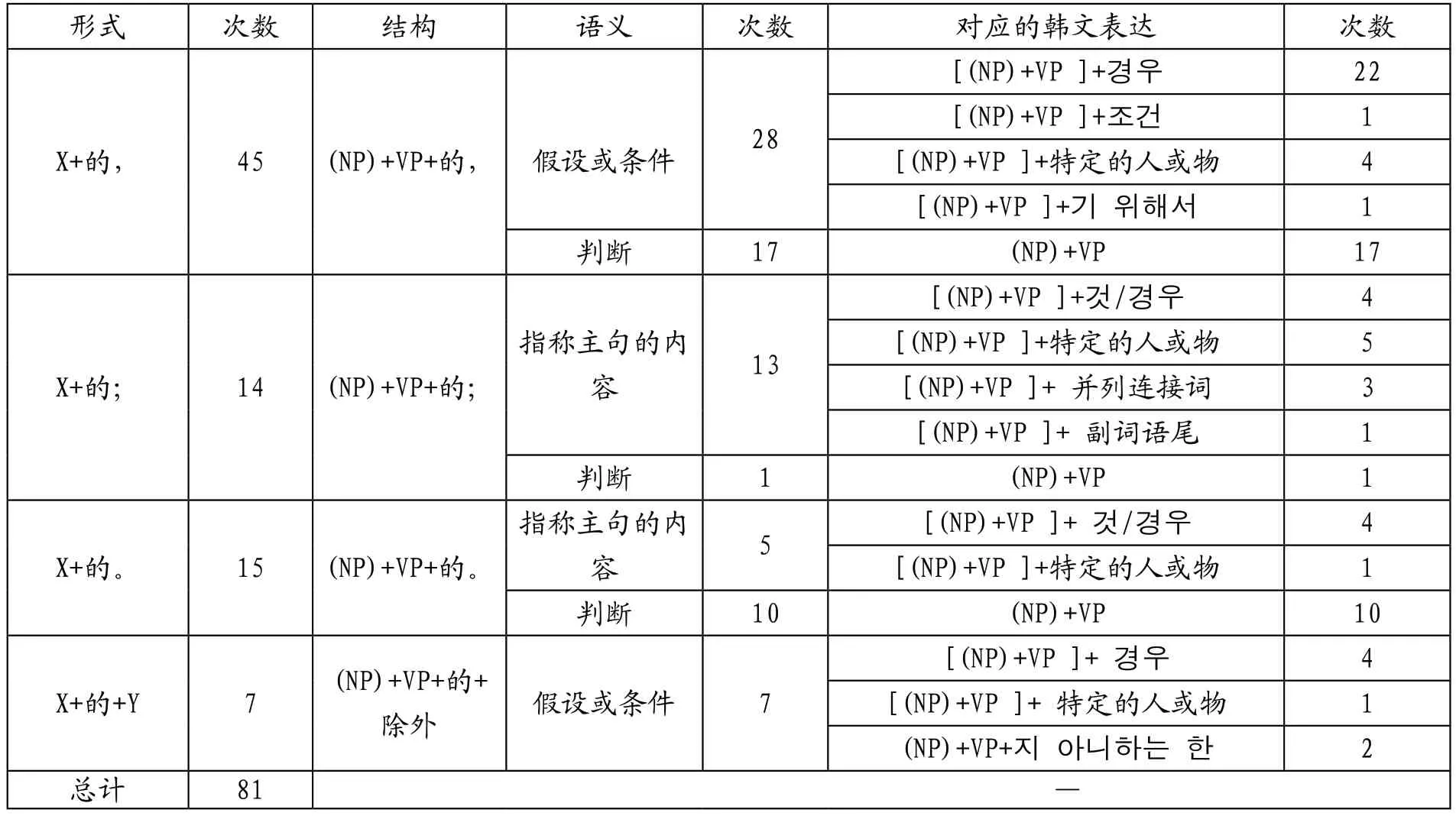
表1 “的”字在语料库中的检索结果
从形式上看,“的”字后面一般存在表示停顿的标点符号,其中“X+的,”(45 次)出现的次数最多,接下来是“X+的。”(15 次),“X+的;”(14 次),“X+的+除外。”(7 次)。从结构上看,“X+的”均由“(NP)+VP +的”构成,其中NP 有时被省略。从语义上看,“X+的”主要分为两类:一类是把表示陈述的结构转化为表示指称人和事物的结构(53 次);另一类是加强肯定和确信的语气(28 次)。从语义上看,“X+的”分为三类:一类是表示假设或条件,用于指明法律条文适用的对象、时间、情形、范围等(28 次);一类是表示判断,用来加强肯定的语气,渲染法律严肃、客观的氛围(17 次);还有一类是用于指称总句中所表达的内容(18 次)。其中,“X+的,”主要用来表示假设和判断,“X+的;”和“X+的。”主要用来表示判断和指称主句中的内容,“X+的+Y”用来表示假设,但是“X+的+Y”在本语料中仅出现2 次。
“X+的”对应的韩文内容可以总结为以下几类。当“的”字结构指称某类情形、行为等不涉及具体的、特定的人或事物时,对应的韩文内容主要为“X+경우/것”。当“X+的”指称具体的、特定的人或事物时,对应的韩文内容主要为“X+具体的、特定的人或事物”。当“的”字结构表示判断时,对应的韩文内容为表示肯定的陈述句。
需要注意的是,在一般文本中,当“X+的”表示假设时,可以对应“X+ 면,……”“X+지 아니하는 한”这样的从句,或者抛弃原文的语言形式,采取意译等翻译策略来实现中韩文间的对等。但是根据检索结果,在中韩协定中,当“X+的”表示假设时,对应的韩文内容几乎都是“X+경우/조건/것”和“X+特定的人或事物”,很少有其他情况出现(仅2 次)。这主要与法律翻译的特殊性有关系。鲍克(Bowker L,2002)指出,法律文本是内部重复率高的文本,经常使用相对固定的表达和句式,在翻译时经常重复利用之前的“翻译记忆”。[9]因为重复利用之前的翻译成果,不仅能提高翻译效率,而且还可以避免或减少因翻译内容的不统一而导致对法律产生错误理解的情况。因此,平行翻译语料的积累对法律翻译实践和研究具有重要的意义。从这个意义上来说,构建并不过扩大、更新拥有优质中韩平行语料的语料库是推进中韩法律翻译实践与研究的重要途径。但是优质的标准是什么,例如“X+的+除外”是翻译为“X+경우를 제외하고”还是翻译为“X +지 아니하는 한”更好,这也是一个值得思考的问题。但是鉴于篇幅有限,对于这一点,将在以后再进行深入的研究。
四、结语
“的”字在中国法律中常以“X+的”的形式出现,具有特殊的语义和语法功能,是极具中国法律文化特色的表达之一。本文通过创建中韩协定平行语料库,结合定量和定性相结合的分析方法,探究了作为法律文化负载词“的”字的使用特征和韩译规律,这不仅有助于解决中韩法律翻译中“的”字的译名统一难题,提升翻译的准确性和规范性,而且对中韩法律翻译研究和实践也具有重要启示意义。本文也存在一定的不足。除中韩协定外,还应搜集更多优质、权威的其他类型的中韩法律平行文本,这样才会得到更加准确的分析结果,并且未来还需结合翻译理论来进一步探究优质译文的标准、翻译策略等。
