大坝变形监控模型识别的R-OC准则
2023-05-26吴震宇陈建康
张 博,刘 健,吴震宇*,陈建康,尹 川
(1.四川大学 水力学与山区河流开发保护国家重点实验室 水利水电学院,四川 成都 610065;2.雅砻江流域水电开发有限公司,四川 成都 610051)
中国目前已修建水库大坝9.8万余座,带来巨大社会经济效益的同时,其安全风险也不容忽视[1]。变形监测是大坝长期运行安全的重要手段[2-3],常通过分析变形监测数据来诊断坝体结构性态,预测大坝发展趋势。而构建监控模型是分析大坝变形监测数据的常用方法,通常根据监控模型预测的预警界限对大坝变形进行异常预警,因此,构建大坝变形监控模型对于大坝安全管理具有重要意义。
大坝变形监测数据序列一般由两部分组成,即由水库水位和环境温度变化引起的可逆变形和大坝随时间演变的不可逆变形。基于监测资料,应用回归方法进行分析,可将影响大坝变形的因素归结为水压、温度和时效分量[4]。在3种分量中,水压分量一般采用上游相对水深3次幂多项式的形式[5]。温度分量可由多个周期谐波的三角函数[6]、变形测量前多段平均气温的线性组合[7]构成,或对坝体温度计监测数据进行主成分分析,将主成分的线性组合作为温度分量[8]。时效分量一般通过预设不同函数进行模拟,多采用线性函数和对数函数组合[9-11]、线性函数和指数函数组合[12-14]、指数和多项式组合[15-16]等形式构建,也可采用EMD方法分离出大坝变形监测序列时效分量,使非平稳的大坝变形时间序列平稳化,能有效提高预测精度[17-18]。
对于同一个变形测点,通过不同形式的水压、温度和时效分量的组合,可以建立多种大坝变形监控模型,因此,需要从所有待选模型中识别出最优模型。大坝变形监控模型的优劣主要体现为模型泛化能力的高低。模型泛化能力即模型对训练集外样本的预测能力,欠拟合与过度拟合均会导致监控模型的泛化能力不足[19]。欠拟合是指建立的监控模型不能从历史监测数据充分学习和准确描述大坝变形监测量的统计变化规律,具体表现为监控模型对历史监测数据的回归显著性较低,拟合误差较大,常通过复相关系数R、均方根误差RMSE、平均绝对误差MAE、平均绝对百分比误差MAPE等指标进行评判[20-21]。R越大,表明监控模型对历史监测数据的回归显著性越高,RMSE、MAE、MAPE的值越小,表明模型拟合误差越小。而过度拟合表现为模型对监测序列的过度学习,甚至会捕捉到训练集中单个样本的特征拟合抽样误差,从而导致模型泛化能力降低,出现对监测数据异常的误判。AIC、BIC准则被广泛应用于监控模型识别[22-25],均采用似然函数度量模型拟合误差,同时引入模型参数数量的惩罚项。经实际应用检验,AIC准则适用于样本量较小的情况,BIC准则适用于样本量较大的情况。但AIC、BIC准则不能定量比较和评价模型的过度拟合程度,在某些情况下,识别出的最优模型可能存在严重的过度拟合问题。因此,在进行模型选择时,需要能够量化模型过度拟合程度的识别准则。
本文定义了能够量化模型过度拟合程度的指标—过度拟合系数OC,同时采用复相关系数R刻画模型的拟合精度,提出了大坝变形监控模型识别的R-OC准则。将R-OC准则应用于某大坝垂直位移测点的变形监控模型优选,并与AIC和BIC准则进行对比,验证了R-OC准则的有效性。
1 大坝变形监控模型
大坝变形监控模型一般由水压分量、温度分量和时效分量构成,表达式如下:
式中,Y(t) 为 坝体变形监测值在时间t的统计估计值,F1[H(t)]为 坝体变形的水压分量,F2[T(t)]为坝体变形的温度分量,F3[θ(t)]为 坝体变形的时效分量,C为待定常数项。
1.1 水压分量
大坝变形的水压分量与上、下游水位的乘幂相关,对水位进行归一化处理[26],构造形式如下:
式中,aui、adi分别为上、下游水位因子的待定回归系数,Ht、ht分 别为t时 刻的上、下游水位,Hmin、Hmax分别为大坝运行时期最低、最高上游库水位,hmin、hmax分别为大坝运行时期最低、最高下游库水位。
当水位对大坝变形影响存在滞后时,水压分量与观测日前j天的平均水位呈线性关系:
1.2 温度分量
1.2.1 传统温度分量
1)多个周期谐波三角函数
引起坝体位移的温度因素主要是边界温度及坝体混凝土的水化热。对于运行时间较长的大坝,水化热可忽略不计。坝体温度基本呈年周期性变化。因此,可采用多个周期谐波的三角函数作为统计模型的温度分量,具体构造如下:
式(4)~(5)中,bi(i=1,2,3,4)为 待定回归系数,t0为设定的1月1日的初始时间。
2)多段平均气温线性组合
坝体边界温度的变化都是由于气温的季节性变化引起。当外部环境气温监测序列完整时,温度分量可采用多段平均气温的线性组合,函数构造如下:
式中,bi(i=1,2,3,4)为 待定回归系数,Ti代表观测日当天及前5、15、60 d的平均大气气温。
1.2.2 基于主成分分析的温度分量
当坝体埋设的温度计较多且监测数据连续时,可采用坝体温度监测序列的主成分构造大坝变形的温度分量,能有效减少模型的变量和参数,降低模型的过度拟合程度。
假设坝体埋设了p支温度计,每支温度计有n(n>p)个监测数据,表达为矩阵形式:
式中,xi=(x1i,x2i,···,xni)T,i=1,2,···,p。
并计算相关系数矩阵:
为消除量纲不同带来的影响,对数据X进行标准化处理,使变量的平均值为0,方差为1,标准化公式如下:
式中:
计算相关系数矩阵的特征值和对应的特征向量,依次排列大小,相应的单位特征向量如下:
则第i个主成分PCi(i=1,2,···,p)的表达式为:
式中,PCi(i=1,2,···,p)为对筛选出的坝体温度计进行主成分分析后得到的主成分因子。
通过式(14)计算各主成分贡献率,并由大到小累加,根据式(15)计算累积贡献率。
式(14)~(15)中,λi为 特征值,ηj为各主成分贡献率,Mm为主成分累积贡献率。
选取合适的主成分PCi作为因子,进行温度分量的构造,构造形式如下:
式中:bi(i=1,2,3,4)为 待定回归系数;m为所选取的主成分因子个数,一般选取累积贡献率大于85%或95%的主成分个数。
1.3 时效分量
1.3.1 传统时效分量
时效分量反映了大坝的不可逆变形。常采用如下两种形式来表示:
式(17)~(18)中,θ=(t-t0)/100,t0为监测点初始监测日的时间,c1、c2为待定回归系数。
1.3.2 基于经验模态分解的时效分量
通过经验模态分解法(EMD)将大坝变形监测效应量分解并重构为周期变化项和时效趋势项,选择合适的函数形式对时效趋势项进行拟合,构建时效分量模型。该方法能克服传统方法在未知时效分量实际变化规律和趋势情况下预设模型形式的缺点。
EMD的步骤如下:
1)找出x(t)上所有极值点xmax(t)、xmin(t)。
2)通过3次样条差值函数将极值点连接,绘制上、下包络线。上、下包络线的均值m1(t)可以表示为:
3)计算原始数据和m1(t)之 间的差值h1(t):
4)用h1(t)替 换x(t),重复上述3个步骤,直到满足相应的终止条件:①数据序列的零点数m和极值点数n满足不等式|m-n|≤1;②上下包络线的均值m1(t)趋于0。
第1个imf1(t)分量可表示为:
5)计算原始数据和imf1(t)之 间的差值r1(t):
6)将步骤1)中的x(t)替 换为r1(t),重复步骤1)~5),直到rn(t)残差单调或小于预设误差,EMD分解终止。
变形监测数据时间序列EMD分解的数学表达式如下:
式(19)~(23)中,x(t) 为变形监测测点在时间t的监测效应量,imfi(t) 为 通过EMD分解得到的n阶IMF分量,rn(t) 为 监测数据序列x(t)的时效趋势项。
则时效分量F3(θ(t))可表示为:
对于时效分量F3(θ(t)),本文采用如下复合指数函数进行拟合:
式中,a、b、c、d为待定拟合参数,θ=(t-t0)/100,t0为监测点初始监测日的时间。
2 模型识别准则
2.1 信息准则
2.1.1 AIC准则
AIC准则是衡量统计模型拟合优良性的一种标准,由日本统计学家Akaike在1974年提出,公式如下:
式中,k为模型参数个数,L为似然函数。
从待选模型中选择最佳模型时,通常选择AIC值最小的模型。一般而言,当模型复杂度提高时,似然函数L增大,从而AIC值减小;但当k过大时,似然函数增速减缓,导致AIC增大。因此模型过于复杂容易造成过度拟合现象,而 2k可以作为对参数的惩罚。AIC准则的实质就是由候选模型取最大似然后加上一个惩罚项得到的,可以衡量模型参数复杂度与拟合优度之间的平衡关系,并选择模型参数较少但拟合度较好的模型作为最优模型。
2.1.2 BIC准则
BIC准则是Schwartz于1978年根据Bayes理论提出的判别准则,引入了后验概率的思想,其计算公式如下:
式中,k为模型参数个数,n为 样本数量,L为似然函数。
BIC准则与AIC准则的差别主要体现在惩罚项,考虑到样本个数会对模型选择起到一定的影响作用,所以在BIC准则中加入样本量n作为模型惩罚项的一部分;当样本数量过多时,可有效防止模型精度过高造成的模型复杂度过高。最优模型通常为 B IC值最小的模型。
2.2 R-OC准则
过度拟合是导致模型泛化能力降低的主要原因之一,通常表现为模型对历史数据的拟合精度很高,但预测精度明显低于拟合精度。因此,可以通过比较模型预测误差和拟合误差来确定模型的过度拟合程度。本文提出模型过度拟合系数OC,其表达式如下:
式中,RMSE为均方根误差,MAE为平均绝对误差,MAPE为平均绝对百分比误差,下标V和下标F分别代表验证时段和拟合时段。相应的RMSE、MAE及MAPE的值定量反映了监控模型预测误差和拟合误差的大小。
RMSE、MAE和MAPE是常用的误差评价指标[21],但各有优缺点。RMSE能够很好地反映拟合值与监测数据的偏差,但对于远离监测数据均值的异常值很敏感,其表达式如下:
MAE克服了RMSE的缺点,能更好地反映拟合值误差的实际情况,但不能合理反映模型拟合的相对误差,其表达式如下:
MAPE适合评价相对误差,缺点是当实测值为0时,将无法计算,其表达式如下:
当模型过度拟合时,验证时段的模型预测误差将大于拟合时段的拟合误差,即:当OC>1,且OC的值越大,表明模型过度拟合程度越高;反之,当OC<1时,且OC的值越小,表明模型预测精度高于拟合精度,不存在过度拟合,预测精度相对越好;当OC=1时,表示预测精度和拟合精度相同。因此,OC能定量反映监控模型的过度拟合程度。
而进行模型选择时,既要保证模型验证时段数据的预测精度,不能存在过度拟合;也要保证模型拟合时段数据的拟合精度,不能存在欠拟合。因此本文选用复相关系数R定量反映模型拟合时段数据的拟合精度。
复相关系数R反映一个因变量与多个自变量之间的相关程度,其表达式如下:
式中,R2为可决系数,SSR为回归平方和,SST为总偏差平方和,Yi为观测数据,Y为观测数据均值,Yˆi为拟合数据。
回归平方和SSR反映回归方程中全部自变量的“方差贡献”。可决系数R2表示这种贡献在总偏差平方和SST中所占的比重,R2越大,说明自变量对因变量的解释程度越高,引起的变动占总变动的比重越大,模型拟合程度就越高;反之,说明模型对样本观测值的拟合效果越差。因此,复相关系数R越大,监控模型的拟合时段数据的拟合精度就越高。
本文基于反映模型拟合精度的指标R和反映过度拟合程度的指标OC,提出了一种新的大坝变形监控模型识别的R-OC准则。在进行模型选择时,可将指标R和OC绘制为2维散点图,从而可以直观地挑选出拟合精度高、过度拟合程度低的模型。
3 案例分析
3.1 工程概况
国内某水电站工程,属二等大(2)型工程,由左岸重力式挡水坝段、河床式电站厂房坝段、河床4孔泄洪闸坝段、右岸导流明渠内3孔泄洪闸坝段、右岸重力式挡水坝段等建筑物组成。水库正常蓄水位为1 015 m,死水位为1 012 m,坝顶高程1 020 m,最大坝高69.5 m,水库具有日调节性能。
选取10#坝段真空激光准直系统LA14测点垂直位移构建位移监控模型,测点布置情况如图1所示。10#坝段长30 m,顺水流方向长60 m,最大闸坝高60 m,堰顶高程994 m。为监测坝体运行期温度场的变化情况,在10#坝段坝体内共埋设30支温度计,封存停测后纳入运行期统计共计14支,具体仪器布置情况如图2所示。

图1 LA14测点布置及工程鸟瞰图Fig.1 LA14 measurement point layout and engineering aeroview
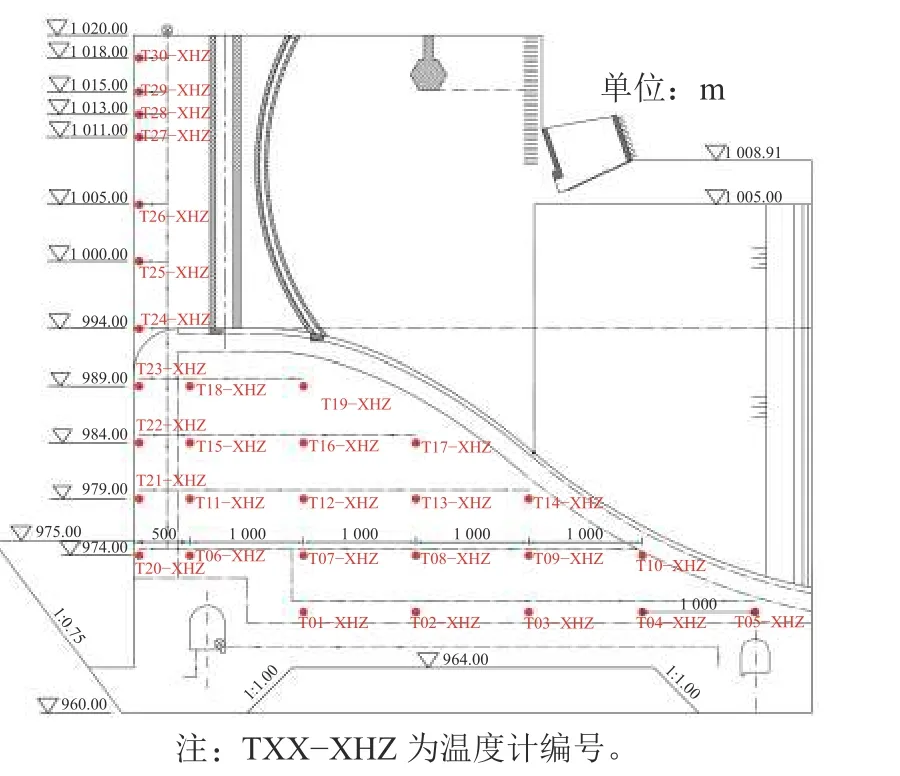
图2 10#坝段温度计布置图Fig.2 10# dam section thermometer layout
3.2 位移监控模型
在建模时段内大坝正常运行,工作性态良好,巡视检查未发现异常的变形迹象。收集LA14测点垂直位移自2017年7月6日至2021年3月30日的完整监测数据,测量频率为1 次/d。剔除异常值后,获得1 238组实测序列,用以构建模型的样本观测值。为检验监控模型的预测效果,将数据序列分成拟合时段和验证时段数据。拟合时段数据用于拟合构建监控模型,通过监控模型对LA14测点位移进行预测得到预测数据,并同验证时段内的LA14测点位移的实测值进行对比分析。其中,拟合时段起止时间为2017年7月6日至2020年12月31日,验证时段起止时间为2021年1月1日至2021年3月30日。LA14测点全过程时间序列曲线如图3所示。
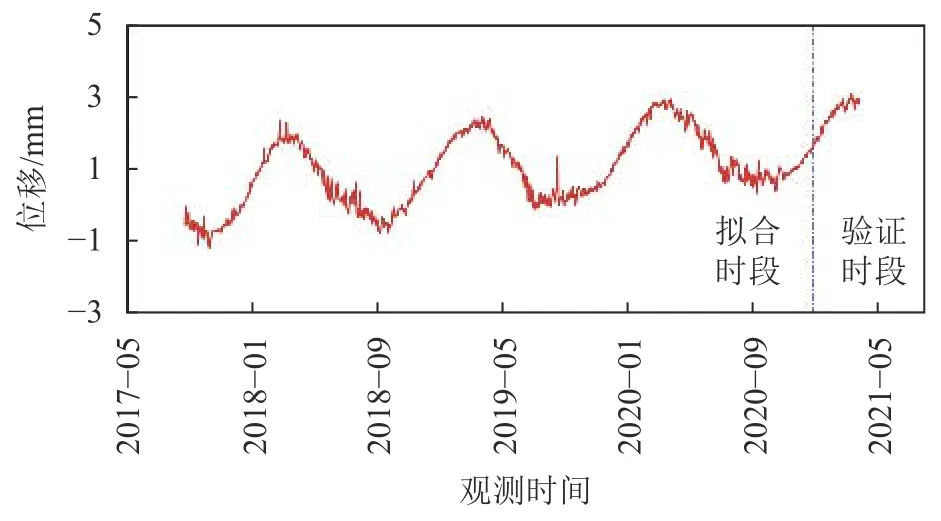
图3 LA14测点全过程时间序列曲线Fig.3 Whole process time series curve of LA14 measuring point
3.2.1 水压分量
水压分量根据第1.1节中的形式进行构建,统一对上下游水位进行归一化处理,且需考虑下游水位的滞后性。
3.2.2 温度分量
1)传统温度分量:由于该水电站运行多年,水化热已释放完毕,坝体内部温度场已趋向稳定,故在回归计算时,水化热可不予考虑;且外部环境气温监测序列完整。因此,温度分量可分别采用第1.2节中的形式进行构建。
2)基于PCA的温度分量:通过数据筛选,选择T01-XHZ、T04-XHZ、T05-XHZ、T10-XHZ、T14-XHZ、T15-XHZ、T16-XHZ、T17-XHZ、T21-XHZ、T23-XHZ、T28-XHZ、T29-XHZ共12支温度计,形成温度主成分PC1、PC2、···、PC12,各主成分贡献率及累积贡献率如图4所示。
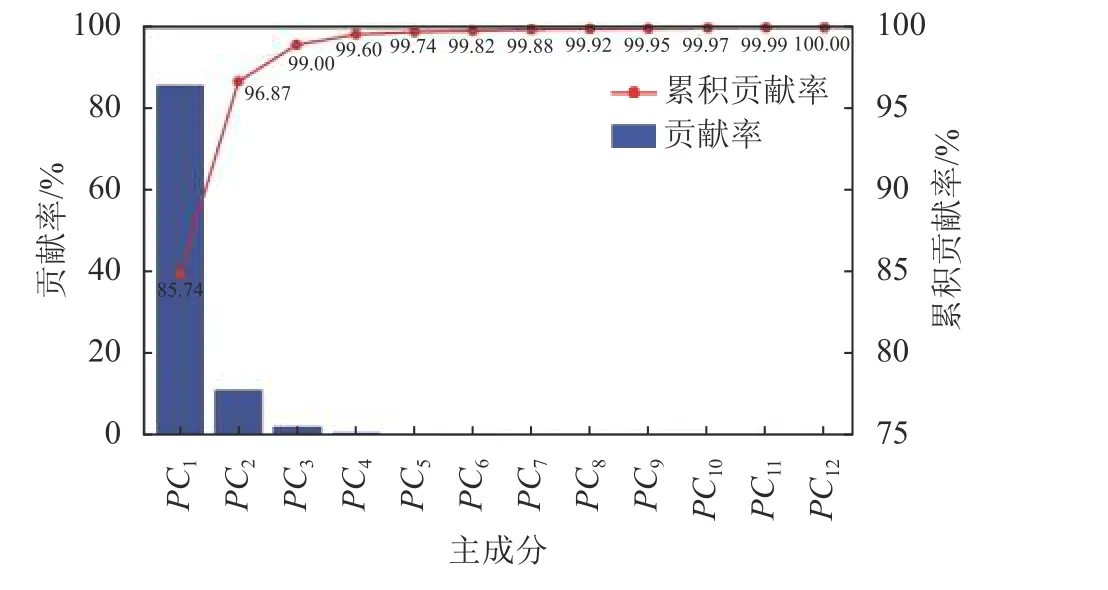
图4 温度监测数据主成分的贡献率及累积贡献率Fig.4 Contribution rates and cumulative contribution rates of principal components in temperature monitoring data
由图4可得,当选取前4支主成分PC1、PC2、PC3、PC4时,累积贡献率达到99.60%,可近似表示上述12支温度计在所选时段的所有包含信息,达到降维处理的目的。因此,将主成分PC1、PC2、PC4作为温度分量因子。
3.2.3 时效分量
1)传统时效分量:时效分量可采用第1.3.1节中的形式进行构建。
2)基于EMD的时效分量:对LA14测点监测数据序列进行EMD分解,根据EMD提取的时效位移时间序列,选择复合指数函数构建时效分量,采用遗传算法确定复合指数函数的系数。LA14测点EMD时效分量及复合函数拟合效果如图5所示。
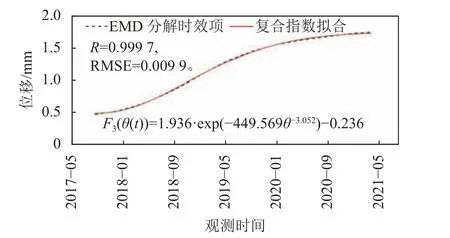
图5 LA14测点EMD分解重构及拟合Fig.5 EMD decomposition reconstruction and fitting of LA14 measuring point
拟合结果显示,复相关系数R>0.99,均方根误差RMSE<0.01,即复合指数函数对分解出的坝顶时效位移拟合效果良好。
3.3 待选监控模型
大坝变形监控模型一般包含水压、温度和时效分量3部分,通过选取上述构建的水压、温度和时效分量不同的函数形式进行组合,并确定是否考虑下游水位滞后,即可构建不同的监控模型,本文总计建立18种大坝变形待选监控模型。各监控模型表达式见表1。
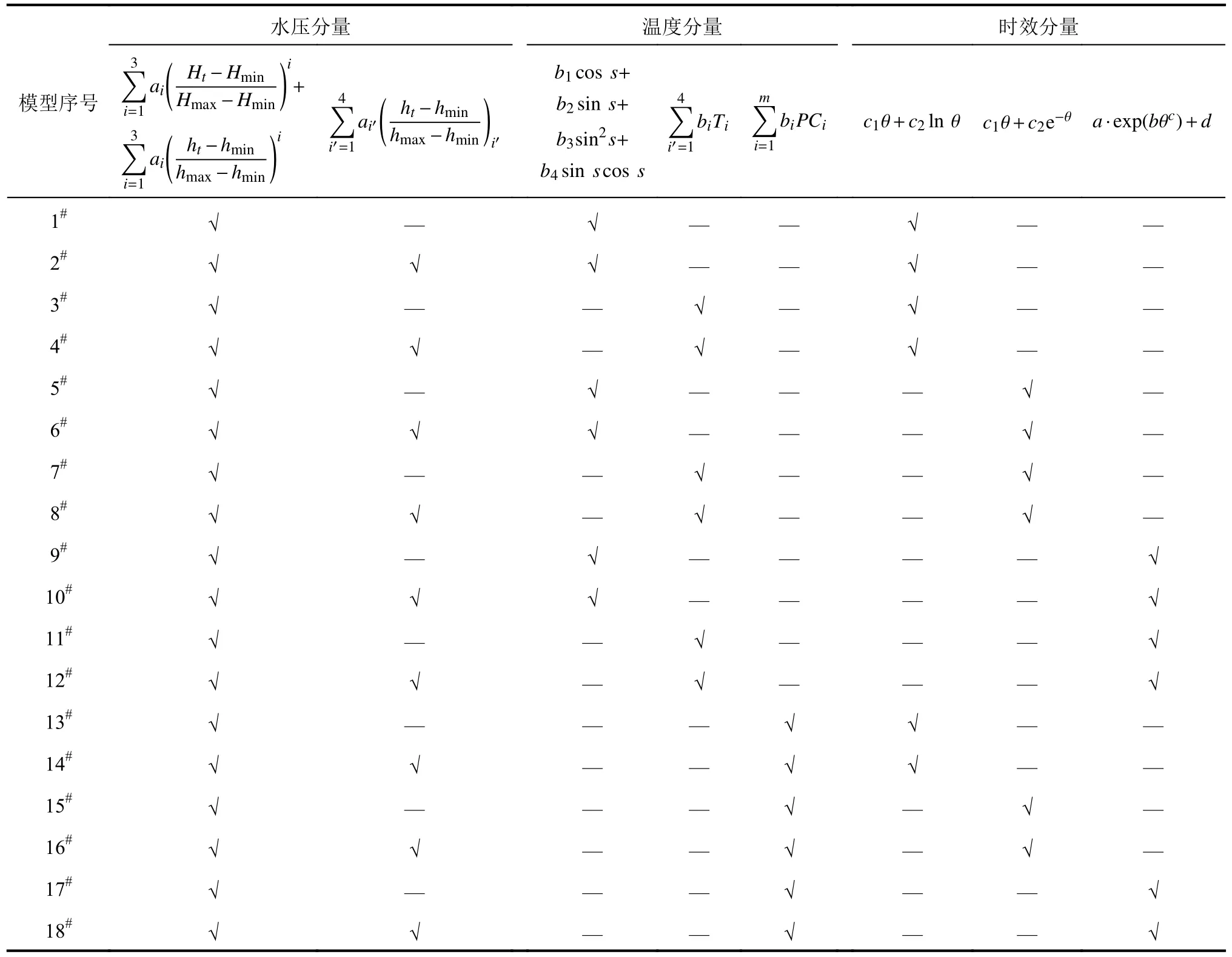
表1 LA14测点垂直位移监控模型汇总Tab.1 Summary of LA14 vertical displacement monitoring model
3.4 模型识别结果及讨论
采用全回归方法对LA14测点进行拟合。在评判预测效果时,使用核密度估计法进行分布拟合,其表达式如下:
式中,fˆh(x)为 残差样本x的 分布概率,K、h分别为核函数、平滑参数,xi为参与统计的数据信息。
根据监控模型对LA14测点位移的估计值和估计误差的概率分布确定异常监测数据的预警界限。其中,预警上限为U CL=E+Δ97.5%,预警下限为LCL=E+Δ2.5%,E为LA14测点位移的模型估计值,Δ2.5%和Δ97.5%分别为模型估计误差的2.5%和97.5%分位值。当新获得的监测数据超出预警界限时,则判断为异常数据,并发出预警。
由于案例分析中的重力坝在验证时段内处于正常运行状态,巡视检查未见任何异常变形迹象,验证时段内的监测数据不应超出预警界限。因此,本文将监控模型的误警率定义为验证时段内被误判为异常数据的数量与该时段监测数据总数比值。
模型评价指标及误警率FAR计算结果见表2。
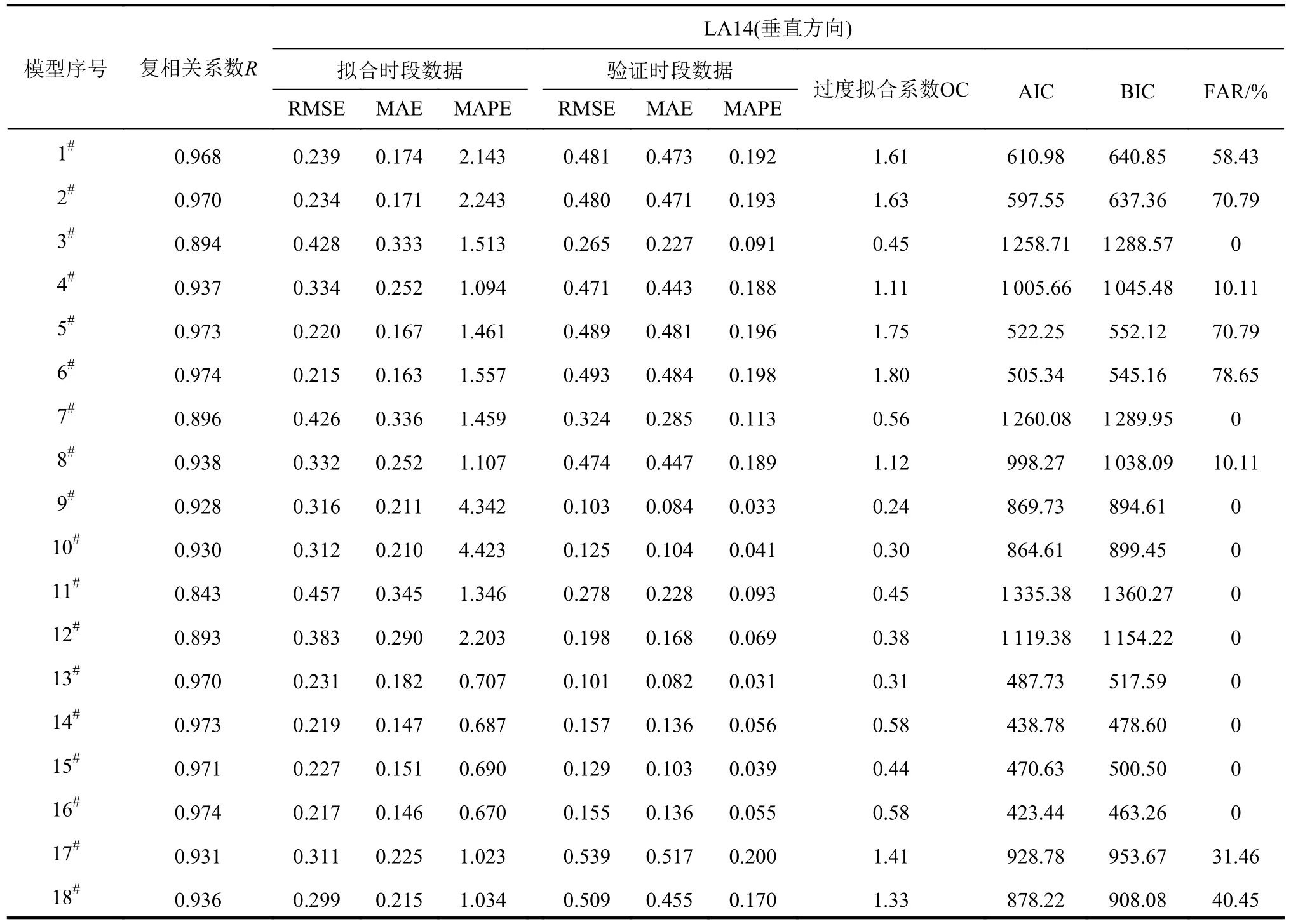
表2 模型评价指标及误警率统计结果Tab.2 Statistical results of model evaluation indenes and false alarm rates
1)将表2中过度拟合系数OC、AIC值、BIC值和误警率FAR分别绘制成散点图,以OC=1.0和OC=1.2的直线将模型分为无过度拟合、低过度拟合、高过度拟合3种类型;以FAR=0和FAR=0.25的直线将模型分为无误警、低误警、高误警3种类型,结果如图6和7所示。
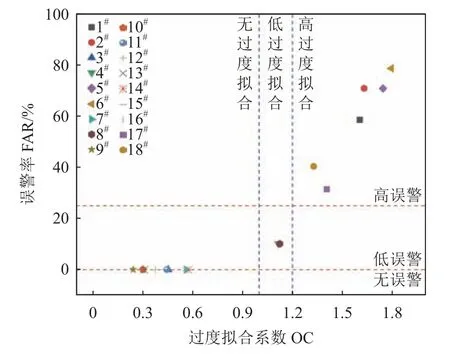
图6 监控模型的过度拟合系数与误警率散点图Fig.6 Scatter plot of over-fitting coefficients and false alarm rates of monitoring model
由图6可知:过度拟合系数OC和误警率FAR的散点图呈较明显的线性关系;当无过度拟合现象时(OC≤0),模型误警率 FAR均为0;当过度拟合程度较低时(1.00<OC≤1.20),模型为低误警(0<FAR≤0.25);当过度拟合系数较高时(OC>1.20),模型为高误警(FAR>0.25)。因此,模型误警率FAR与过度拟合系数OC大致呈正相关关系。
由图7可知,AIC、BIC准则同误警率FAR无明显关系。1#、2#、5#、6#等模型的AIC、BIC值相对较低,但误警率FAR均高于50%,属于高误警类型;3#、7#、11#、12#等模型AIC、BIC值虽相对较高,但误警率FAR均为0,属于无误警类型。因此,AIC、BIC准则不能良好地反映模型误警率FAR,与AIC、BIC值越小,模型效果越好的规则相矛盾。
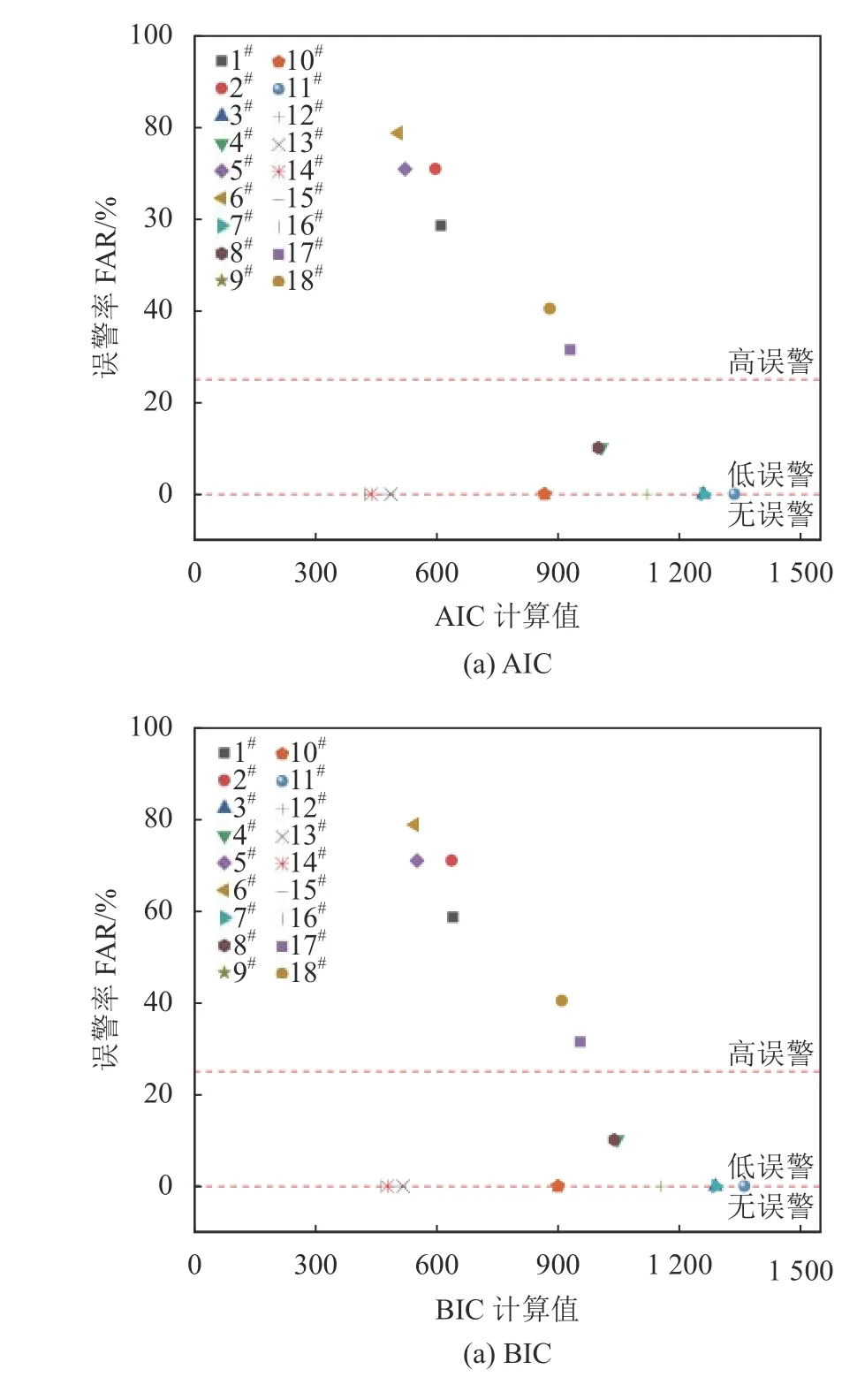
图7 监控模型的AIC和BIC计算值与误警率散点图Fig.7 Scatter plot of AIC and BIC values and false alarm rates of monitoring model
因此,从模型误警率FAR的角度出发,R-OC准则中的过度拟合系数OC比AIC、BIC准则更能反映大坝变形监控预警的真实情况。
2)当采用AIC、BIC准则选取模型时,根据AIC、BIC值最小原则,最优模型为16#模型,其拟合段精度最高为0.974,但验证时段数据的预测效果并非最好,过度拟合系数为0.58。
采用R-OC准则选取模型时,将复相关系数R和过度拟合系数OC绘制成散点图,选出的较优模型用红线圈出,如图8所示。
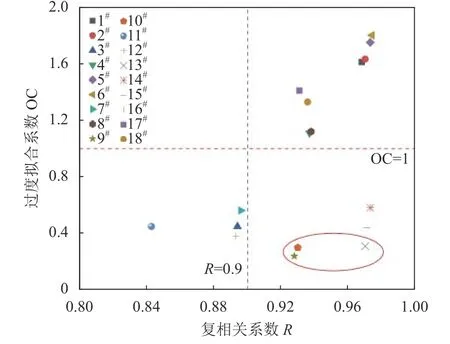
图8 监控模型的R和OC指标的散点图Fig.8 Scatter plot of R and OC indexes of the monitoring model
图8中左上角区域(OC>1.0,R<0.9)中的模型既有欠拟合又存在过度拟合;右上角区域(OC>1.0,R≥0.9)中的模型无欠拟合但存在过度拟合;左下角区域(OC≤1.0,R<0.9)中的模型有欠拟合但无过度拟合;右下角区域(OC≤1.0,R≥0.9)中的模型既无欠拟合又无过度拟合。因此,满足OC≤1.0、R≥0.9的模型为较优模型。当所有模型均不满足此条件时,可以从两个方面进行优化:①改进监控模型的水压、温度和时效分量的函数形式;②采用深度学习算法[27]对历史监测数据进行学习,建立监控模型。在LA14测点较优模型9#、10#、13#、14#、15#、16#模型中,各模型的复相关系数R均在0.9以上,满足模型精度的要求;对比各模型的过度拟合系数OC,并从小到大进行排序,次序为9#、10#、13#、15#、16#、14#,最优模型为9#模型。
3)根据AIC、BIC准则选择模型时,选择最优模型的准确度受模型数量限制。由表2可知:①当只构建前12种模型时,AIC、BIC准则会将5#模型判定为最优模型,虽然其复相关系数R为0.973,拟合精度最高,但其过度拟合系数为1.75,属于高过度拟合类型,误警率FAR高达70.79%,5#模型预警界限如图9所示。但R-OC准则会选择9#模型,其复相关系数R为0.928,拟合精度满足要求,同时过度拟合系数为0.24,无过度拟合现象,误警率FAR为0。9#模型预警界限如图10所示。②当对18种模型进行选择时,根据第2)点分析,AIC、BIC准则将16#模型判定为最优模型;此时,R-OC准则仍会选择9#模型。
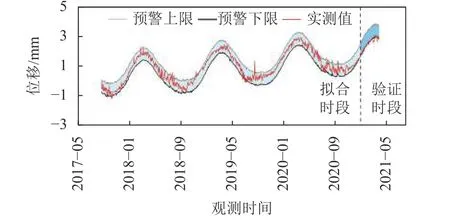
图9 基于AIC、BIC准则识别的最优模型(5#模型)的预警界限Fig.9 Early warning limits of optimal model (5# model)based on AIC and BIC criteria
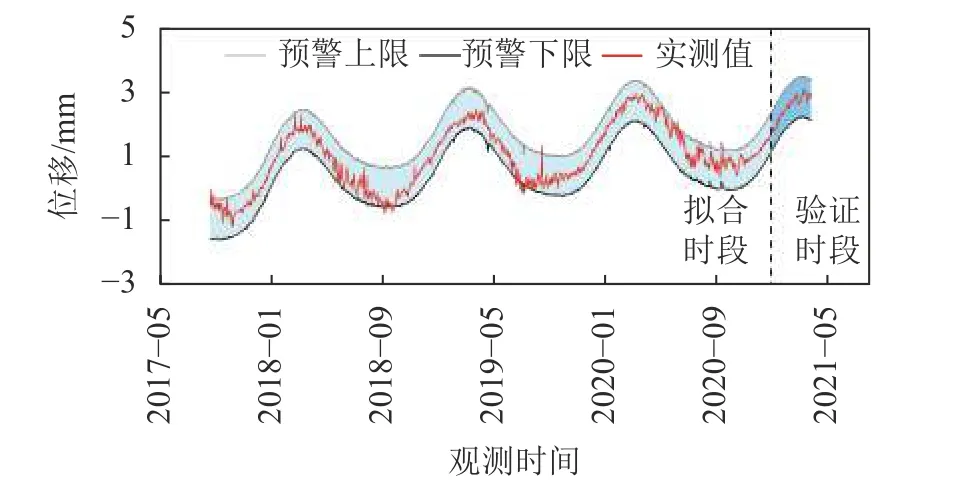
图10 基于R-OC准则识别的最优模型(9#模型)的预警界限Fig.10 Early warning limits of an optimal model (9# model) based on R-OC criterion
因此,对于不同数量的待选模型,R-OC准则均能识别出拟合和预测精度都较高的模型,而AIC和BIC准则识别出的最优模型可能会存在较严重的过度拟合现象。
4 结 论
本文定义了能够量化过度拟合程度的指标,即过度拟合系数OC。同时,为满足既不能欠拟合又不能过度拟合的模型识别原则,结合复相关系数R,提出了大坝变形监控模型识别方法R-OC准则。
案例分析表明,过度拟合系数OC与误警率FAR存在密切关系,当过度拟合系数OC≤1时,监控模型误警率FAR为0;当过度拟合系数OC>1时,监控模型误警率FAR与过度拟合系数OC呈正相关关系。R-OC模型识别准则弥补了传统模型识别方法AIC、BIC准则不能定量比较和评价模型过度拟合程度的缺陷;通过R和OC两个指标,既保证了模型的拟合精度,又限制了模型的过度拟合程度,合理选择最优模型,提高了模型识别的准确度。同时,对于不同数量的待选模型,R-OC准则均能识别出拟合和预测精度都较高的模型。
