基于图像信噪比自适应阈值模型的秦简文字图像二值化算法
2023-05-19汪政阳夏蓉陈明陈炳权
汪政阳,夏蓉,陈明,陈炳权
(吉首大学 通信与电子工程学院,湖南 吉首 416000)
在文本图像的文字识别过程中,二值化算法的优劣,不仅能验证预处理前期步骤中图像增强降噪的效果,也为后续的检测识别打下基础,因此文本图像二值化算法研究已成为当前人工智能研究领域的经典问题之一。秦简文字在保存中难免会遭到人为或非人为的损坏,其图像的质量不容乐观,存在诸如噪声复杂、字迹模糊、简牍残缺等质量不均衡现象,这给秦简文字图像PSNR值和二值化精确率的提升带来诸多挑战,直接影响秦简文字检测识别的准确率与速度。
数字图像二值化算法通常分为全局与局部两大方法,其中全局二值化算法主要包括OTSU算法,局部二值化算法主要包括Bernsen算法和Niblack算法。一般情况下,局部二值化算法的精确率要高于全局二值化算法。OTSU算法[1]采用基于聚类的思想,根据图像总的像素点数在全局范围内实现阈值的最优化计算,使其计算出的二值化阈值可以达到类之间的方差最大化。Bernsen算法[2]在光照欠均衡与噪声点较多的图像上的表现效果优于OTSU算法,其算法步骤是首先设置2个默认参数值,其次计算图中以某一像素点值P为中心,窗口大小设置为k×k的像素参数值,并与预先设置的2个默认参数值进行比较,以数值大小判定选取该像素点处的灰度值。Niblack算法[3]的优势在于能够很好地处理光照不均或噪声点复杂的图像,使得分割出的字符轮廓和细节可以最大程度得以保留,但缺点在于容易产生伪噪声,且伪噪声过度依赖于滑动窗口的大小,过小的窗口便会产生伪噪声。Sauvola算法[4]是在Niblack算法基础上进行的改进,将其像素点邻域内点的均值作为计算标准,辅以局部标准差再对其进行调整,这样便可以处理掉图像背景中的噪声点,但在处理低信噪比图像时其效果不佳。
国内有关秦简文字诸如二值化、文本检测与识别等方面的数字化研究还处于起步阶段。陶珩等[5]提出了针对秦简文字图像的数字化检测技术,利用最稳定极值区域算法和非极大值抑制算法来检测秦简文字,但在秦简文字二值化处理方法上并未做深入研究。参照其他古籍图像与少数民族文字图像的二值化方法,Lu等[6]提出了基于背景估计和笔画宽度估计的二值化算法,首先选用一维的迭代高斯滤波算法估计古籍文档图像背景,然后利用估计出的背景对不同情况的退化古籍文档做相应地补偿处理,最后根据图像的像素点平均值与笔画结果进行二值化处理。熊炜等[7]针对存在墨迹类噪声点的文档图像提出了一种融合背景估计与能量函数的二值化算法,能够有效地处理文档中的噪声点,性能指标均优于OTSU等经典二值化算法。冯炎[8]提出了基于局部对比度和相位保持降噪的古籍图像二值化算法,在对古籍图像的局部对比度进行构建时,采用对局部像素值的最大值与最小值做归一化处理方法;在降噪处理上选用相位信息降噪,得到较好的估计结果;在上述基础上对古籍图像做增强处理后得到二值化结果。Howe[9]提出了一种基于拉普拉斯图像的全局能量函数最优化二值化算法,该方法使用预先训练好的图像去选定目标函数,使其图像二值化结果的精确率较高。但该算法的鲁棒性不理想,特别是对于噪声点严重的低信噪比图像,其二值化仿真结果不理想。
目前大多二值化算法局限于清晰古籍类文字图像,在解决背景复杂且噪声点多的秦简文字图像时还未取得实质性进展。为解决秦简文字图像背景干扰、噪声点多的问题,也为提高二值化结果的精确率,本文提出一种改进型的二值化算法,首先对秦简文字图像做二值化前的预处理,以提高图像质量,其次根据图像信噪比自适应阈值模型将图像采用不同的二值化算法进行二值化,最后依据图像质量评估指标选取最优的二值化图像作为秦简文字二值化图像的输出结果。
1 秦简文字图像二值化预处理
为提升秦简文字二值化效果,特别是其二值化的 PSNR值,本文首先针对秦简图像光照背景欠均衡和噪声点多等问题,提出秦简文字图像二值化预处理流程,通过平衡背景亮度和降噪,达到提升图像质量,为提升秦简文字二值化效果打下前期基础。秦简文字图像处理流程如下:
1)将秦简文本图像转化为灰度图像;
2)获取图像的平均灰度值,判断图像的背景亮度,并通过自适应伽马变换调节图像背景亮度,使其不会过度灰暗或过度曝光;
3)利用非局部均值滤波算法在保留图像边缘细节的同时,达到降低图像噪声的目的。
1.1 图像灰度转换
为提升文本图像质量,通常将多通道的图像变为每个像素点仅由一个灰度值表示的单通道图像。图像灰度转换将能够满足多通道的RGB图像转换为单通道灰度图像,由于大多数二值化算法都是基于灰度图像进行操作,所以要将输入的彩色图像进行灰度化处理。其转换公式[10]为
D=R×0.299+G×0.587+B×0.114,
(1)
式中:D表示转换后的图像像素的灰度值;R、G、B分别表示原图像像素中的红、绿、蓝三基色分量。本文采用经典灰度转换算法,即OpenCV中封装的cvtColor()函数,实现彩色图像的灰度化转换处理。
1.2 自适应伽马变换
在复杂环境下,由于受到光照强度、自然侵蚀、拍摄角度或人为损坏等因素影响,导致原始秦简文字图像会产生各种复杂的背景与噪声点,使后续秦简文字图像二值化的精确率严重下降。因此需对秦简文字图像进行增强处理,提高图像的清晰度,凸显秦简文字轮廓和细节。本文结合自建的秦简文字数据集QBS text dataset中的图像做背景亮度自适应调整处理。
利用伽马变换调整秦简文本图像亮度背景。具体过程:对输入图像每一像素点的灰度值做指数变换,使输出图像中像素点灰度值与输入时的灰度值呈非线性关系,变换公式为
S=crγ,
(2)
式中:r为灰度图像的输入值,通常取值为[0,1];S为经过伽马变换后的灰度输出值;c为灰度调整系数,通常取1;γ为伽马因子,控制整个变换的调整程度。本文采用自适应方法调整γ值大小,以使最终图像的亮度背景处于较为均匀的状态,更适合人眼的观察范围和后续降噪处理,自适应调整γ值为
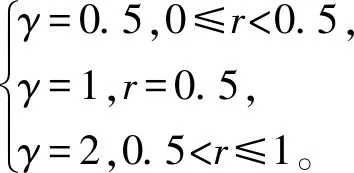
(3)
1.3 非局部均值降噪
非局部均值滤波(nl-means,简称NLM)是目前较为主流的降噪技术之一。采用非局部均值滤波降噪后,不仅能够提升图像的清晰度,而且能够有效地保存文本轮廓和细节。
在非局部均值滤波算法中,采用了均方误差(MSE)作为判定邻域块相似度大小的标准,MSE计算公式为
(4)
式中:m,n表示邻域块的行列数;A(i,j)为A邻域块中的点(i,j)的像素值;B(i,j)为B邻域块中的相同位置点的像素值。
NLM的权重根据邻域块相似度大小计算而来,相似度越大则权重越大,计算公式为
(5)
式中:sum是整个搜索框内所有领域窗口的MSE之和;σ是高斯系数权值,其值越大则最终的降噪效果越好。得到了每个像素块的权重,就可以计算出滤波后新的像素值,其计算公式为
(6)
式中:IP为原像素;Iq为新像素。
本文在对NLM降噪参数设置过程中,将目标像素块的相似半径设置为2×2,像素块的搜索区域半径设置为5×5,高斯函数平滑参数设置为10。经实验仿真结果分析,运用NLM算法对秦简文字进行去噪,可以在降噪声的同时较好地保留秦简文字区域的笔画细节。
为了体现出本文所选用的降噪算法的优势,文中选取了目前经典降噪算法,如中值滤波[11]、高斯滤波[12]、最值滤波[13]等与NLM算法作对比分析。在选取横向对比降噪能力的评估指标上,本文采用基准指标即峰值信噪比(PSNR)。
从自建的秦简文字数据集QBS text dataset中,选取了100幅图像对其采用各个降噪算法进行处理,单独计算每幅图像的PSNR值后再对其整体求平均值,根据计算结果横向比较它们各自降噪能力的高低。降噪性能对比结果见表1。
由表1可知,相较于其他传统降噪算法,采用非局部均值滤波降噪后的秦简文本图像取得了最高的PSNR均值,证明其能够最大限度降低秦简文本图像噪声,为后续的二值化处理提供较有利的条件。
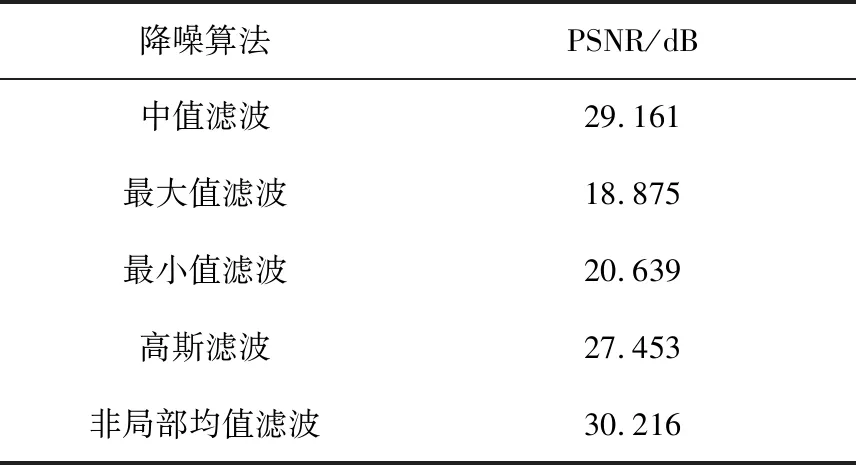
表1 降噪性能对比
2 改进的二值化算法
2.1 算法基本思想
OTSU算法的特性导致其在噪声点过多的低信噪比图像中,会将大量噪声点判定为需要提取的前景文本区域,且不能对多个目标进行分割处理,在目标与背景大小呈现不均衡比例的情况下,其类间方差的计算结果会表现为多峰直方图形态,导致算法二值化效果不好。因此对于存在过多噪声点的秦简文字图像需使用其他二值化算法来进行二值化处理。Bernsen算法在光照欠均衡与噪声点较多的图像上的表现效果优于OTSU算法。但Bernsen算法也存在一些不足,在处理高信噪比文字图像时,不能很好地处理噪声区域,导致文本区域和噪声区域产生大量黏连,最终显示出的二值化效果较差。
两种算法对于秦简文字图像二值化处理的仿真对比如图1所示。图1(a)为经过预处理后的较清晰图像的OTSU算法和Bernsen算法的仿真结果,图1(b)为经过预处理过后仍存在复杂背景与较多噪声点图像的算法仿真结果。由图1可以看出,OTSU算法在处理高质量图像时的表现效果普遍优于Bernsen算法,而在处理低质量图像时Bernsen算法的表现效果则普遍较好。
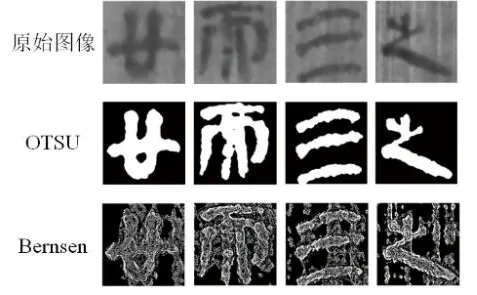
(a)高信噪比图像仿真结果
因此,本文将OTSU算法与Bernsen算法进行结合,依据图像信噪比大小设置自适应阈值进行二值化处理,最后按照评价指标表现性能大小选取最佳二值化图像。
2.2 SNR阈值的确定
在进行秦简文字图像信噪比阈值确定的过程中,判定标准有三项:首先能够将所需文本区域从背景当中提取出来;其次能够保留更多的文字细节特征;最后能够定量分析强度。本文所使用的秦简文字数据集QBS text dataset中的图像数据以数码相机拍摄的方式进行收集,因此采用通用相机的信噪比衡量标准进行阈值选取。信噪比与图像质量关系见表2。

表2 信噪比与图像质量关系
在数据集QBS text dataset中,将30 dB≤SNR<50 dB的图像归为低信噪比图像,将SNR≥50 dB的图像归为高信噪比图像。因此本文根据实验要求,再结合数据集中数据与表2对应关系,将算法自适应阈值设定为50 dB来进行仿真测试。
2.3 算法模型
本文算法将OTSU算法与Bernsen算法结合,通过秦简文字图像信噪比设定自适应阈值进行二值化处理。算法流程步骤如下:
1)将输入的秦简文字图像依据信噪比进行高、低信噪比图像判定,将30 dB≤SNR<50 dB的图像归为低信噪比图像,将SNR≥50 dB的图像归为高信噪比图像;
2)对阈值高于50 dB的高信噪比图像采用OTSU算法进行二值化处理;
3)对阈值位于30 dB≤SNR<50 dB的低信噪比图像,首先采用Bernsen算法进行二值化处理,并计算图像的PSNR值、结构相似性(SSIM)值,再与OTSU算法得到的二值化图像的PSNR值、SSIM值进行对比,选择评价指标更优的二值化图像。
其模型流程如图2所示。
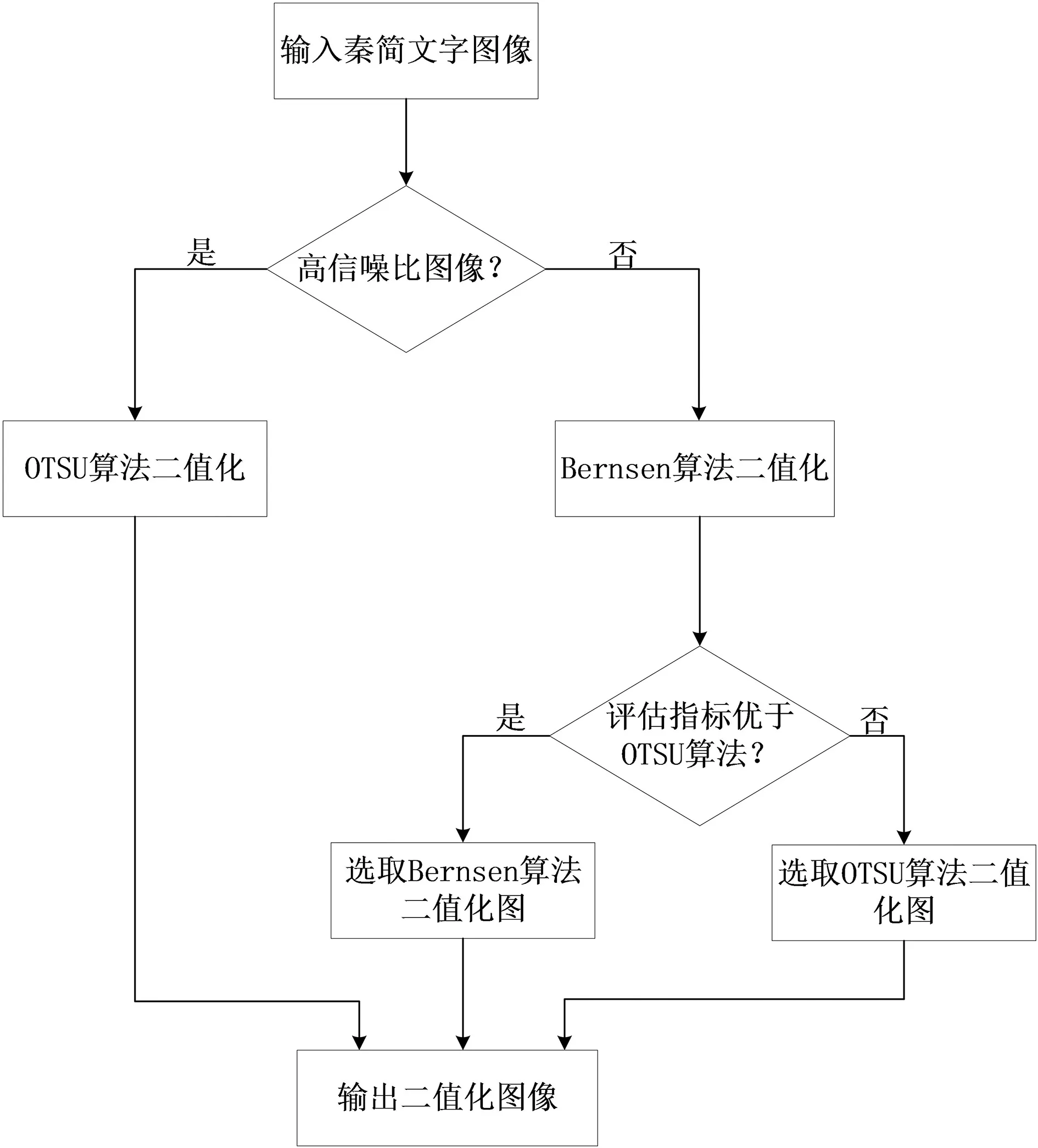
图2 秦简文字图像信噪比自适应阈值模型流程
3 实验仿真与分析
3.1 秦简文字数据集QBS text dataset的构建
由于目前并设有统一的针对秦简单字文字图像的实验测试数据集,因此参考孟一飞[14]对于西夏古文字图像样本库的建立步骤,本文完成了秦简文字图像样本库的制作与建立。秦简图像数据主要来源于湖南省文物考古研究所出版的《里耶秦简壹》《里耶秦简贰》以及武汉大学出版社出版的《秦简牍合集》,具体制作方法如下:
1)截取图片。将书籍中秦简图片进行扫描制作电子扫描件,对扫描图像中的文字区域进行单个截取。
2)按测试要求分类。根据清晰度与测试需求分为模糊样本库、低信噪比样本库与高信噪比样本库。图片分类标准参照SNR参数值设置,SNR<20 dB归为模糊样本,20 dB≤SNR<50 dB归为低信噪比样本,SNR≥50 dB归为高信噪比样本。最终取得模糊样本图18 057幅,低信噪比样本图34 569幅,高信噪比样本图11 434幅。本文根据测试需求,选取低信噪比样本库中部分典型图片进行实验。
3)建立图像-文释对照关系。为迅速准确地检索到图像所对应的出处位置,在图像文件的命名规则上采取了归一化处理,格式统一为:“Unearthed landN_page_Num_Num.jpg”,其中Unearthed landN代表该秦简书籍上所标注的出土地来源,该书籍的页编号用page_Num表示,在该页上所截取的字符编号用Num表示。统一了图像与文释对照关系后,就可以建立每幅文字图像与书籍出处的联系,再按照归一化后的文件命名便可以迅速准确地找到图像来源。
4)划分测试集和验证集。测试集中的低信噪比样本图像共1 200张,验证集中的低信噪比样本图像共计1 000张。
3.2 实验环境与评估指标
本文采用自建的秦简文字数据集QBS text dataset作为文本图像二值化算法的测试和验证数据,其中所有图像像素大小均设置为227×227×3,本次实验中网络模型基于OpenCV和TensorFlow框架建立,并将网络模型加载至GPU上进行,服务器显卡型号为RTX3070。
为对比本文算法与其他算法的优劣性,选取了二值化主流的4种图像评估方法:精确率(Precision)、F值(F-measure)、峰值信噪比(PSNR)和结构相似性(SSIM)。精确率体现的是二值化结果的精确度,即算法计算结果中文本像素个数与全部像素个数的比值,比值与精确度呈正比关系。F值是一种集中体现图像二值化处理结果准确率与召回率的评估指标,在与标准图像对比过程中,可以表达二值化图像与标准图像的误差大小,其值越大,则表示图像之间的误差越小。两者的计算公式分别为:
(7)
(8)
式中:TP、FP和FN分别表示真实的正值、错误的正值和错误的负值;召回率(Recall)是评估属于某类别的查全比例,在二值化中体现为正确召回二值化图像结果类别的比例,具体计算公式为
(9)
峰值信噪比是衡量图像降噪性能的重要评价指标,其值直接反映二值化算法处理图像时的性能高低,其具体计算公式为
(10)
式中:l表示位深度,即图像某像素点可显示或打印的色彩信息值,一般取l=8;amax表示图像像素点颜色的最大数值,在位深度为8时,一般amax= 255。
结构相似性是衡量两幅图像像素间关系与结构信息相关性的经典评估指标,其取值区间为[0,1],值越大说明二值化图像的失真度越小,即与基准图像越相似。其定义式为
(11)
式中:μx,μy分别代表两幅图像x,y的像素平均值;σx,σy分别代表x,y的标准差;σxy代表x,y的协方差;c1和c2为常数。
本文实验选取了文献[1-4,15-19]9个有代表性的二值化算法与本文算法进行比较。其中Niblack算法根据实验需求设置像素阈值与其窗口参数、前景像素值为:k=-0.3,w_size=24,wp_val=255,Sauvola算法中设置修正参数与窗口大小为:k=0.1,kernerl=31。
3.3 实验结果与分析
为体现本文改进后算法优势,并寻找与其他二值化算法之间的差别,从验证集中的不同信噪比样本图像库中选取了10张有代表性的实验图像,图3是本文改进后算法与其他算法的仿真结果展示。

图3 不同二值化算法对比结果
图3(a)的原始图像是较为清晰的高信噪比样本图与背景复杂或噪声点较多的低信噪比样本图。文献[1]和文献[17]算法对于高信噪比的清晰图像二值化处理效果较好,但对于带有复杂背景和较多噪声点的低信噪比图像处理没有达到预期效果;文献[2]和文献[15]算法在处理高信噪比图像时会将大量文本区域错判为污渍区域而覆盖掉;文献[4]和文献[16]算法尽管在一定程度上降低了噪声,但对于文本区域的黏连效果处理不太理想;文献[3]、文献[18]和文献[19]算法由于算法特性导致对噪声点敏感,会将大量的噪声点判定为需要保留的前景文本区域;本文提出的改进后方法在处理有亮度背景不均衡和噪声点干扰的秦简文字图像问题时,相比其他算法有了较好的改善,在一定程度上本文方法取得了相对满意的结果。
本文方法与其他二值化算法在自建的QBS text dataset数据集中1 000个验证数据的各项评估指标平均值对比结果见表3。
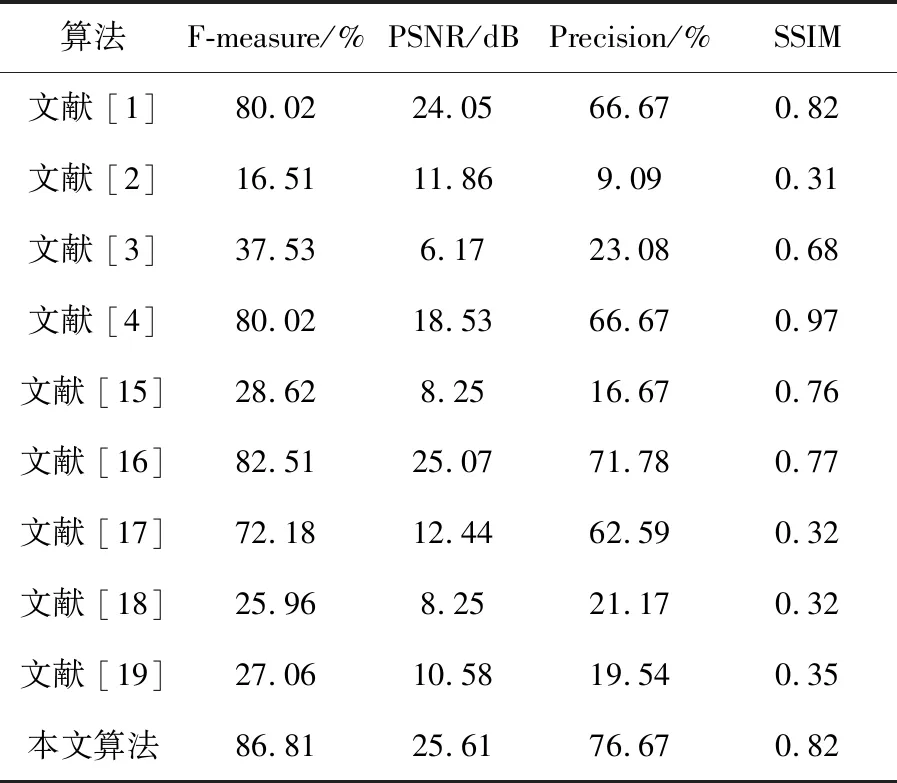
表3 各二值化算法在QBS text dataset的评估指标平均值
由表3可知,在F-measure、PSNR和Precision的评估结果中,本文方法都达到了相对最优值。在相较于各项评估指标次优的文献[16]时,本文方法的F-measure、PSNR和Precision分别提高了5.21%、2.15%和6.81%,但在SSIM值的对比算法数据中还未达到最优,与最优的文献[4]相差0.15,与次优的文献[1]持平。
4 结束语
本文依托于自建的秦简文字数据集QBS text dataset,针对其图像的复杂背景以及多噪声点,提出了一种改进后专用于对秦简文字图像进行二值化处理的算法。首先将图像进行灰度转换、调整亮度和降噪等一系列二值化前的预处理,以最大限度提高图像质量;然后根据图像的信噪比进行自适应阈值处理,将高信噪比图像采用OTSU算法进行二值化处理,将低信噪比图像采用Bernsen算法进行二值化处理;最后根据其二值化后的PSNR与SSIM值的比较,选择效果最优的二值化图像。在测试图像上的仿真结果表明,本文算法所处理的秦简文字图像的精确率达到76.67%,F值达到86.81%,PSNR值为25.61 dB,但仍存在以下不足:QBS text dataset中不同类别的字符类型样本数据不平衡;本方法对于秦简文字模糊样本数据的二值化效果不太理想。这些不足将在后续研究中不断完善。
