基于代价敏感的AdaBoost 双层分类社会救助预测模型*
2023-05-12贺远珍樊重俊熊红林
贺远珍 樊重俊 熊红林
(1.上海理工大学管理学院 上海 200093)(2.上海交通大学安泰经济与管理学院 上海 200240)
1 引言
随着“互联网+”的普及,信息化应用到社会生活与政府机构的各方面,尤其是国家各部门相关工作。在《社会救助暂行办法》和《关于改革完善社会救助制度的意见》中,国务院明确表示救助业务要本着公平公正的原则,促进社会和谐和人民共同富裕,科技化精准救助是其中必不可少的部分。目前,国内外民政部门的社会救助管理系统的设计和实现都趋向成熟。但精准识别被救助人员任务上仍存在缺陷,比如救助范围较宽且标准不清晰,因此在决定被救助人员和救助金额时往往存在不确定性。当前各个基层单位是救助业务的主要管理者和实践者,被救助人员及金额大多由基层工作人员凭借经验来判定,这容易造成评判标准的随意性和不统一。因此,在信息化这样一个大背景下,如何实现精准救助是一个亟待解决的问题。
社会救助对象的类型判定需要多方了解家庭的困难情况,需要考虑家庭各个特征并按照政策进行分类,在这个过程中业务员的判断是确定救助类型的主要依据。但现实生活中各家庭在各指标上存在参差,并且业务员受自身的家庭环境、教育环境影响和对政策的理解不同等因素导致判定结果具有主观性,这会增加判定工作的难度。对此,在机器学习的步步发展下,各种能解决该问题的机器学习模型也相继被提出。目前,针对被救助对象困难等级判定的预测方法主要有层次分析法[1],随机森林[2]等,这些模型的应用都已经取得了很好的效果。还有一些其他贫困等级的判定,文献[3]利用所有相关专家的汇总信息,描述为概率语言术语集,将贫困家庭进行排名和聚类。文献[4]通过SOFM 网络对河北省贫困县进行等级划分。文献[5]构建了基于REAHCOR 新型特征选择算法与GBDT 分类算法结合的模型,并把该模型应用到贫困分级评价系统中。
一般来说,社会救助常见类型有低保、低收入、重残无业、特困、支出型救助、临时救助等。在实际的研究过程中,因为样本数据分布极度不均衡,传统分类器会在多数类样本中表现效果更佳,甚至忽略少数类样本对于整体问题的影响。这就使得社会救助困难类别的预测成为不平衡数据多分类问题。传统的分类方法通常基于各类样本的数据分布大致相当,各类样本错分的代价也大致相同的假设,往往不能达到理想的分类效果。常见的不平衡数据问题包括入侵检测[6]、医疗诊断[7]、信用风险评价[8]等。目前,解决数据的不平衡性的方法有很多,主要分为3 类:第1 类是采样法,包括欠采样[9]、过采样[10]和混合采样[11];第2类是代价敏感学习[12~13],通过为少数类赋予相对高的错分代价和为多数类赋予相对低的错分代价来提高少数类的分类性能;第3类是集成学习[14]。
基于此,本文提出一种新的用于解决不平衡多分类问题的模型,该模型结合了代价敏感学习和集成学习两种方式尝试构建代价敏感的AdaBoost 双层分类算法来对社会救助类型的进行分类分析和研究,探讨更有效的精准社会救助技术手段与应对策略。实验结果表明,与多个模型比较,本文所提出模型在社会救助的精准识别有更高的预测精度和更强的稳定性,能为社会救助事业的精准识别提供更好的辅助决策参考。
2 问题描述
由于社会救助本身就是一个复杂的事务,且各个省市政策不同评判标准也具有很大差异,仅依靠人力对被救助对象进行分类是十分耗时和繁杂的。因此,应用数据能很好地为社会救助事业提供客观化、高效化的结果。众所周知,社会救助中被救助人员大多属于低保、低收入等类型,积累的数据集具有很高的不平衡性且分类标签多。因此,本文针对上海市社会救助政策寻求构建一种新的基于不平衡性多分类问题的模型,以获得救助过程中的客观且精细的决策,它也为各省的社会救助信息化事业提供一个参考。
3 研究方法与模型构建
3.1 AdaBoost分类模型
AdaBoost是一种经典的集成算法之一,是通过有限次迭代生成多个泛化能力较差的弱分类器,并在最后通过弱分类器的权重组合生成一个具有良好分类效果的强分类器,从而提高整个分类器的精确度。具体的算法思想[15]如下:
令训练集S={(x1,y1),(x2,y2),…,(xm,ym)},其中xi为第n个样本的n维特征向量,yi为样本标签,令迭代次数为T。
1)初始化训练样本权重
给定各训练样本一个初始权重值,在第一轮迭代中各样本的权值平均分布,即:
其中,ω1i表示第一轮迭代中第t=1,2,…,T个样本权重;初始化各样本的权重为t=1,2,…,T,t=1,2,…,T为总样本数。
2)对t=1,2,…,T重复以下操作得到T个弱分类器:
(1)按照样本权值向Dt训练数据,根据htk(x)=σ(S,Dt),k=1,2,…,j的各个特征参量独立生成一个分类器htk(x):
其中,S为训练样本集;σ(∙)为基学习算法。
(2)根据式(3)分别计算j个分类器的加权误差率ωti,取ωti最小的分类器为最终弱分类器,记为ωti,误差率为ωti:
其中,ωti为第t轮迭代中第i个样本的权重值。
(3)计算ht(x)的系数(即在最终集成得到的强学习器中所占权重值):
(4)更新训练样本的权重向量D,以降低正确分类的样本权重值,提高错分的样本权重值,引入的Zt是规范化因子,使Dt+1的所有元素和为1。
3)经过T轮迭代,通过弱学习器加权线性组合构建最终的强分类器G(x)为
3.2 Softmax回归模型
根据文献[16]对多项逻辑回归模型的定义,项逻辑回归模型是逻辑回归的推广,可用于多类分类。假设离散型随机变量Y 的取值集合是{1,2,…,K},那么Softmax回归模型:
其中,xRN+1,wkRN+1。
Softmax 回归模型是一个判别式模型,具有多种模型正则化的方法,在实际运用中可避免多重共线性的问题。与决策树、支持向量机相比,Softmax回归模型可以得到一个可解释的概率架构,并且能轻松通过新数据的加入对模型进行实时更新。由于Softmax 回归模型具有在分类时计算量小,计算速度快,储存空间占用低等优点,因此广泛应用于数据量大,特征空间小的工业问题上。
3.3 CA-SF模型构建
根据救助数据具备类别数量呈现极端趋势的特点,设计一个“多转二”机制将数据集由多分类问题转化为二分类问题,即将样本数量相当的作为一类,几个多数类合成总体多数类,几个少数类合成总体少数类。将总体分为两类,但这个二分类问题具有极度不平衡性。
本文引入有代价敏感机制的AdaBoost模型(又称Adacost 模型)来对这个极度不平衡的二分类问题进行分类。Adacost 模型的实现方法是在Ada⁃Boost 机制里的调整系数中增加一个代价因子bi,所以新的权重更新公式如下:
综上,可以得到总体多数类和少数类的二分类结果。然后在二分类结果的基础上,将问题进一步转化为两个数量相当的均衡多分类问题,再利用能有效规避多重有线性的Softmax回归模型对它们分别进行分类。从而构成针对不平衡数据集的多分类问题的CA-SF模型结构如图1所示。
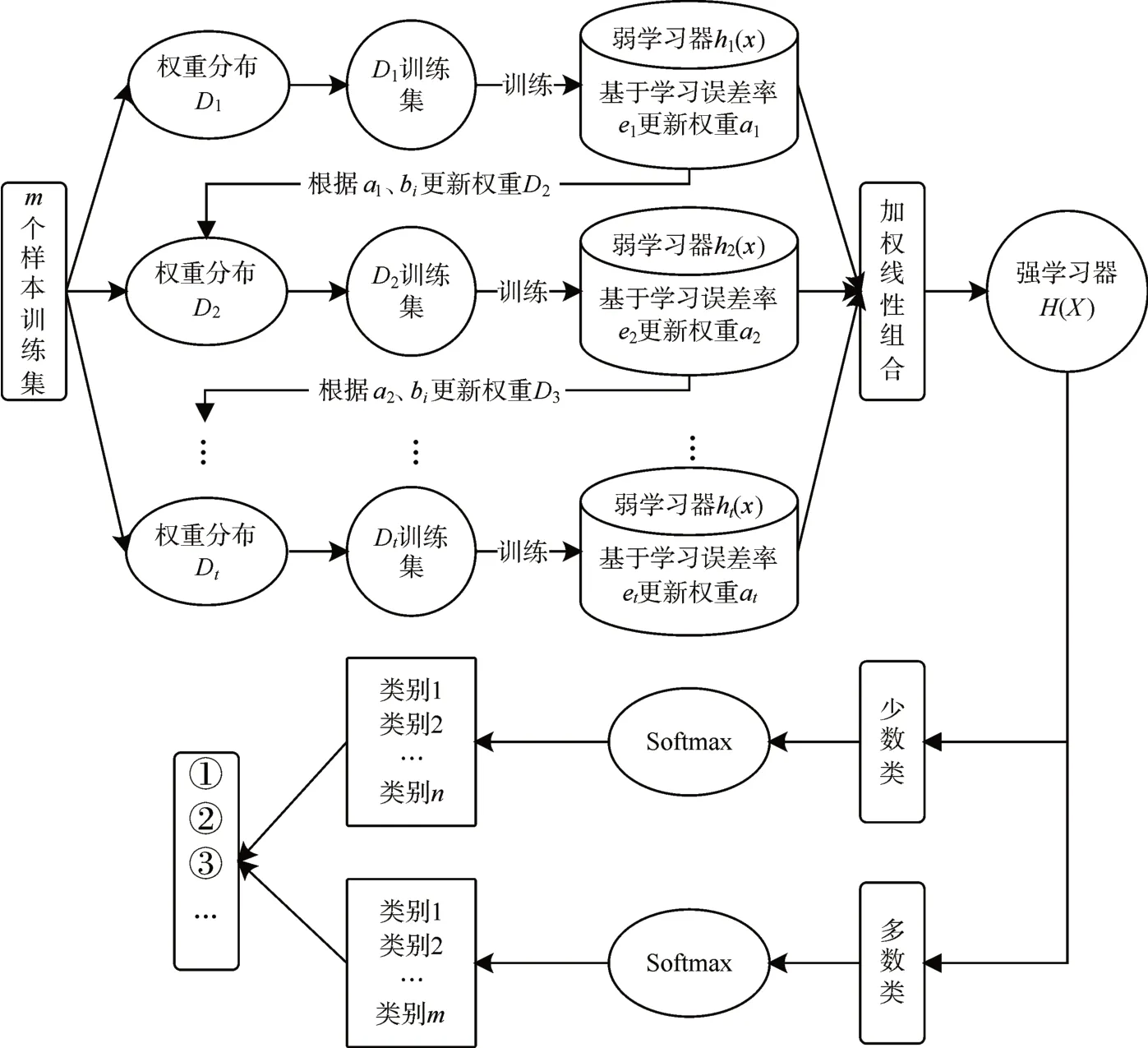
图1 CA-SF模型结构图
CA-SF模型的建模步骤如下:
Step1 对不符合救助条件的样本删除,将反映家庭个体的样本特征维度通过比例法转化为家庭总体特征。
Step2 对经过Step1 的数据进行标准化处理,消除量纲影响。再给样本集基于类别数量均衡原则增加一个二类标签列,并将其按照7∶3 的比例分为训练集和测试集。
Step3 通过式(1)~(4)、式(6)~(7)和式(10)对Step2得到的二类数据集的训练集进行二分类训练,得到强学习分类器H(x),获得测试集的二分类的预测结果y*。
Step4 根据Step2 得到的二类标签为准将训练集中分为两个子样本训练集。再根据Step3得到预测值将测试集分为两个子样本集,分别是少数类和多数类测试集。对两个子训练集分别用Softmax回归进行分类,并在子测试集中进行测试,得到总测试集预测值y′。
4 实证分析
4.1 数据预处理
为验证本文提出的模型有效性,本文对此开展了实证分析。本研究得到了上海市民政局信息研究中心的支持,研究数据社会救助相关人员家庭情况数据来自于上海市2020 年救助人员数据库。根据上海市民政局相关政策将不符合条件的救助对象删除,余下的数据作为研究对象。由于数据集中的文化特征反映的是家庭每个成员的个人特征,而不是家庭总体特征,因此将文化特征分为文盲、义务教育和高水平教育三个级别按照比例法进行计算分类,得到新的家庭文化特征,其他特征均为原始数据,数据集中被救助家庭的相关变量描述如表1 所示,分别从家庭的经济情况、年龄分布、文化水平、劳动能力四个方面对数据进行了描述。

表1 被救助家庭的相关变量描述
根据上海市社会救助类别等级分类政策,将社会救助类别划分为五个类别,多数类别包括低保、低收入和重残无业,少数类类别包括支出型贫困和特困,对各类别进行编码得到:1)重残无业,2)支出型,3)特困,4)低收入,5)低保,部分数据如表2 所示。该数据集共包括162299 例样本,考虑13 个特征维度,按照7∶3 的比例对样本集进行划分为训练集和测试集两部分,样本分布的情况如表3 所示。用各类别间的数量差来表示该样本集的不平衡度。可以看到在五个类别中,支出型救助类型占比最少,不足百分之一;低保救助类型占比最多,超过百分之五十;其他三种类型分布仍然不均衡。两个类别之间的不平衡度最高可达1∶70,最低低至1∶1.66。
表2 社会救助数据集类别编码后的部分数据展示

表3 数据集中被救助家庭类型分布情况
4.2 标准化
由于在样本中经济特征的数值与其他特征的数值差异较大,为避免差异过大影响算法的迭代过程,因此对数据进行标准化处理。对每一列特征属性计算均值、最大值和最小值,然后通过式(11)对所有样本属性值进行归一化处理。
5 对比实验与结果
5.1 分类效果及评价指标
在不平衡的社会救助数据中仅仅使用准确率作为评价标准是不合理的,因为少数类数量占比极少,若这些少数类全部预测为多数类,准确率依旧可以保持在一个相当高的水平。因此,本文采用各类别分别的查准率(precision)、查全率(recall)、F1值对分类能力进行衡量,相应的计算公式如下。
为验证CA-SF 算法的有效性与优越性,本文将与其他常见的经典多分类模型进行对比实验,包括支持向量机(SVM)、人工神经网络(ANN)、随即森林(RF)、多项逻辑回归(SF)、具有样本权重机制的梯度提升随机树(LightGBM)。其中SVM 采用的核函数为RBF 核,LightGBM 模型中的样本权重矩阵为w=[1,1.3,1.2,1.1,1]。
5.2 结果分析与讨论
通过多次试验,CA-SF在第一层的不平衡二分类问题中最佳代价矩阵如表4 所示。通过实验得到以上六种模型的查准率、查全率和F1值的最终结果,其对比情况如表5 所示。为了更加直观地比较和分析各个模型的分类效果,并将其绘制成折线图,具体如图2~4所示。

表4 Adaboost二分类模型代价矩阵
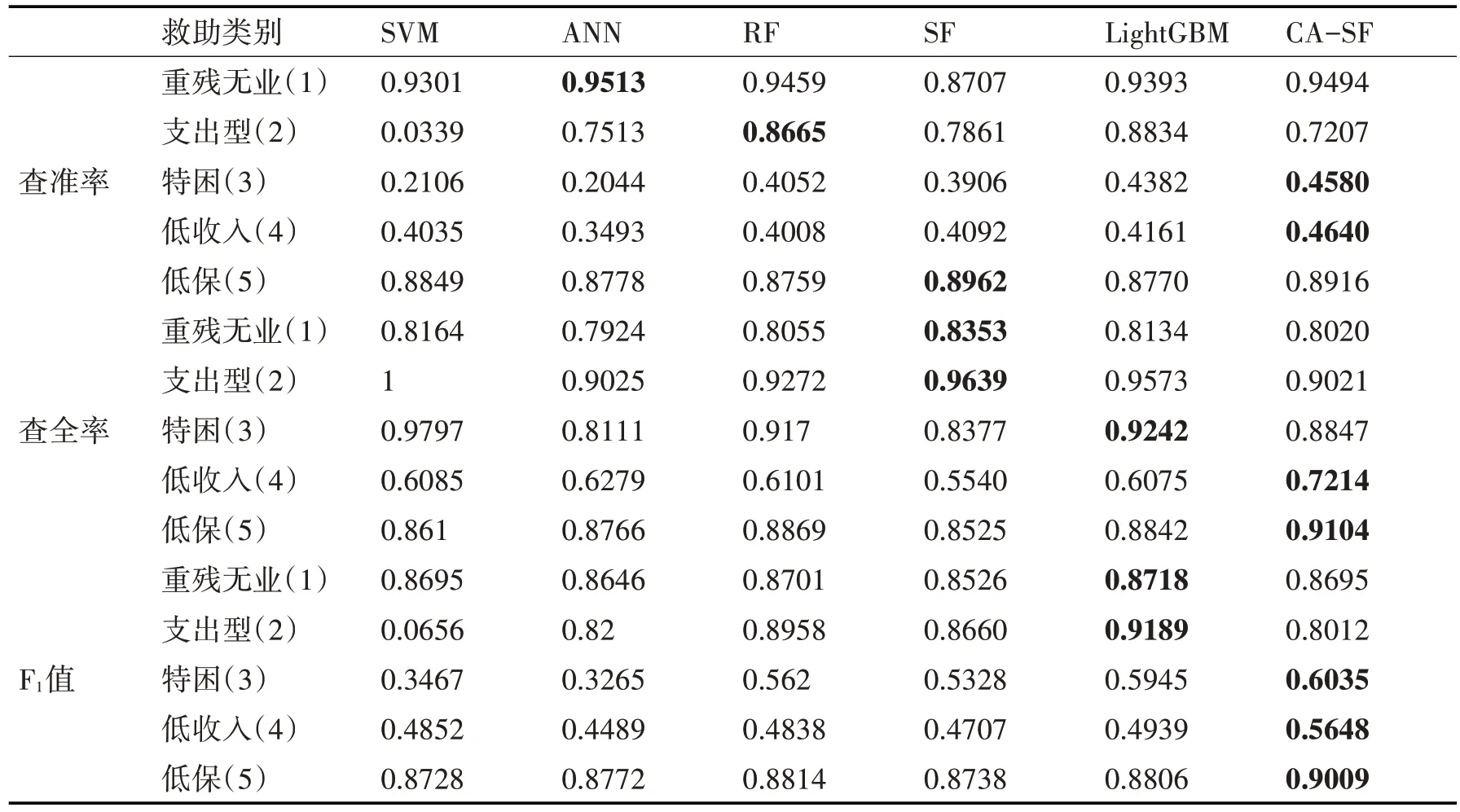
表5 各算法的查准率、查全率、F1值对比情况
从各类别的F1值上来看,CA-SF与四个经典多分类模型比较有三个最大值,其余两个也与最大值差异较小,这说明本文模型相比于传统分类模型在不平衡数据集上的分类效果更好,有着更强的稳定性。同时,无论是常规模型还是本文所提出的模型在类型1、2、5 中表现相较于3、4 更好,说明在训练过程中1、2、5 的特征表现更加突出,而3、4 的特征表现不太突出,数据集可能存在高类重叠率。在其中表现最不好的模型是SVM,在第二个类别中有着最高召回率,但是却拥有最低精确率,这样的结果对于最终的分类来说缺乏说服力。
图2~图4 反映出CA-SF 模型的最大值数量在查准率、查全率和F 值均高于其他算法,因此在社会救助精准识别问题上CA-SF 模型是表现最优异的,它可以有效地减少不平衡性对分类的影响。此外,进一步计算出SVM、ANN、RF、SF、LightGBM 和CA-SF 各模型的总体准确率值,分别为0.8280、0.8299、0.8385、0.8255、0.8391、0.8617,以及F1值的方 差,分 别 为0.0968、0.0540、0.0317、0.0320、0.0301、0.0206。由此也可说明,在不平衡的多分类问题中,本文所提出模型具有更好的有效性和稳定性。
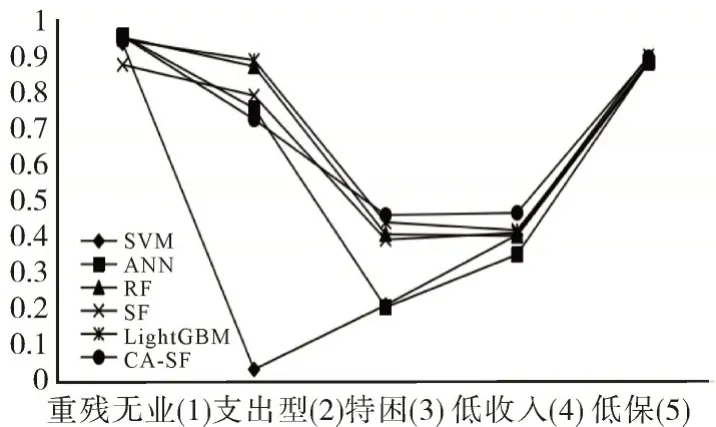
图2 各算法查准率对比图

图3 各算法查全率对比图
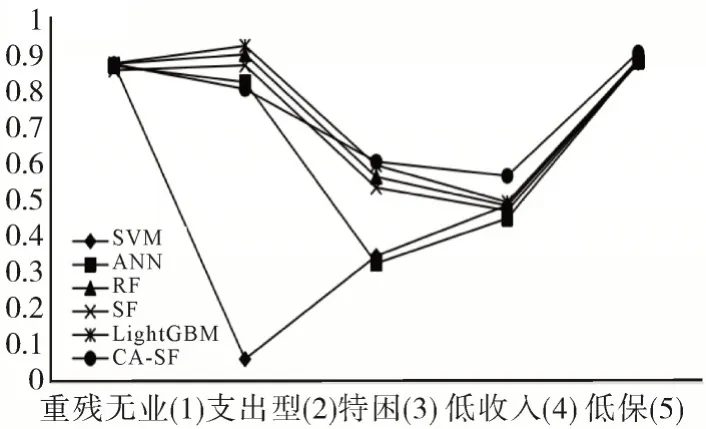
图4 各算法F1值对比图
CA-SF 模型在第一层分类中将不平衡部分单独进行处理,充分抓住了问题的根节点,尽可能减少不平衡性对多分类效果带来的干扰,使最终分类更具有效性,并第二层中的Softmax 回归对数量均衡的多分类问题有着很好的分类能力。将CA-SF模型与带有样本权重机制的LightGBM 模型的F1比较显示CA-SF 模型也具有更明显的优势,据此可以推测将不平衡性的问题放在二分类中解决比直接对多分类问题进行“一刀切”式解决更加有效。
在社会救助精准识别业务数据集上,当救助对象的类型划分为比较少见的特困类型和支出型困难类型或者划分为比较多见的低保、低收入、重残无业类时,Softmax 回归对数据集进行分类,可以使得整体多分类达到很好的效果,会降低数量不均衡导致的训练器偏好性影响。由此可见,CA-SF模型可以更好地去处理救助对象的精准识别问题,为社会救助的困难识别提供一个可行的方案,推进了社会救助的信息化建设,同时推动了民政事业在数字经济中的发展。
6 结语
针对救助业务数据集的各类别的极度不平衡性,根据CA-SF 模型来对这个数据集进行分类分析,并以上海市社会救助数据为实证进行验证,结果表明该方法效果明显。由于数据的隐私性,本研究内容中的家庭救助指标选择和分类标签仅针对上海市政策指向,但方法模型普遍适用于不平衡多分类问题的研究。本研究成果对于民政局准确判断被救助人员的救助类型有着重要的参考意义。该模型能在训练过程中有效利用错误率和代价因子来区分少数类和多数类,保证了样本的最佳可分离性。模型的立足点在于样本数据的多个特征均被运用于优化分类任务结果,对救助类别进行分类分析。通过实验表明该算法对不平衡多分类问题的处理有着明显的效果。
社会救助类型的预测准确率存在提升空间。一方面本文对救助类别的研究中只考虑了家庭经济中的现金流和货币资产的影响,实际上影响困难判定的经济因素是多种多样的,如家庭拥有的固定资产和医疗保险支出等综合因素;另一方面,本文是从数据的不平衡性出发,实际上不平衡数据通常具有类重叠性,这个特点对预测精度具有一定的影响。后续笔者另行撰文将进一步研究增加这些因素以及优化算法降低类重叠率的预测分析。
