行人检测和姿态估计系统帧数优化*
2023-05-12户庆凯万舒畅朱命冬
户庆凯 万舒畅 朱命冬
(河南工学院计算机科学与技术学院 新乡 453000)
1 引言
通过对现有行人检测[1]和姿态估计系统[2]进行了研究,现在的基于机器学习,视觉技术应运而生的行人检测和姿态估计系统在运行在不同配置的计算机上时会有较大的效果差异,不同性能的计算机,可能会出现帧数过剩,精确度不够,或者精确度足够,却帧数过低,那以实现行人检测和姿态估计的实时性。因为系统的默认解决方案不能完美地适配在各种不同的计算机上,所以在一台计算机上进行了多种不同的配置方案,找到一种帧数精确度最高的解决方案。
2 相关工作
对于行人检测与姿态估计[3]的应用,CVPR 2016 Convolutional Pose Machine (CPM) 和CVPR2017 realtime multi-person pose estimation 算法是其基础,两种算法的模型效果很好,并且取得了较好的鲁棒性,当行人被遮挡了一部分后还是能够估计出来。
1)CMP[4](单人姿态估计)的模型采用的大卷积核来获得大的感受野,这对于推断被遮挡的关节是很有效的。
整个算法流程:
(1)首先对图像中出现的所有人进行回归,回归各个人的关节的点;
(2)然后根据center map 来去除掉对其他人的响应;
(3)最后通过重复地对预测出来的heatmap 进行refine 得到最终的结果,在进行refine 的时候,需要引入中间层的loss,从而保证较深的网络仍然可以训练下去,不至于梯度弥散或者爆炸。
2)realtime multi-person pose estimation(多 人姿态估计)[5]算法是基于CMP 构造的,所以计算量较大,需要较好计算性能的显卡进行计算。该网络的结构与CPM 很类似,也是通过CPM 的方式先将所有人的关节点都回归出来,然后再对这些关键节点进行划分,这样就可以把关节分配到每个人。
以下是几种常见的人体姿态识别算法。
2.1 DensePose
2018 年2 月Facebook 开源了人体姿态识别系统DensePose[6]。Facebook公布了这一框架的代码、模型和数据集,同时发布了DensePose-COCO,这是一个为了估计人类姿态的大型真实数据集,其中包括了对5万张COCO图像手动标注的由图像到表面的对应。这对深度学习研究者来说是非常详细的资源,它对姿态估计、身体部位分割等任务提供了良好的数据源。
DensePose 的论文中提出了DensePose-RCNN,这是Mask-RCNN 的一种变体,可以以每秒多帧的速度在每个人体区域内密集地回归特定部位的UV坐标。它是基于一种能将图像像素通过卷积网络映射到密集网格的系统——DenseReg。模型的目标是决定每个像素在表面的位置以及它所在部分相对应的2D参数。
DensePose 借用了Mask-RCNN[7]的架构,同时带有Feature Pyramid Network(FPN)的特征,以及ROI-Align 池化。除此之外,他们在ROI 池化的顶层搭建了一个全卷积网络。
2.2 OpenPose
OpenPose[8]是由卡内基梅隆大学认知计算研究室提出的一种对多人身体、面部和手部形态进行实时估计的框架。
OpenPose 同时提供2D 和3D 的多人关键点检测,同时还有针对估计具体区域参数的校准工具箱。OpenPose可接受的输入格式有很多种,可以是图片、视频、网络摄像头等。同样,它的输出格式也是多种多样,可以是PNG、JPG、AVI,也可以是JSON、XML 和YML。输入和输出的参数同样可以针对不同需要进行调整。
2.3 Human Body Pose Estimation
该模型利用MPII[9]人类姿势数据集进行训练,这是一个内容十分丰富的数据集,专门针对人类姿态估计。目前只有TensorFlow的实现。
这项研究将人类姿态估计的任务应用到真实的图片中,该方法既可以进行动作识别,也能进行估计,与之前先检测人类动作再对此进行推测的技术有所区分。在实施过程中用到了基于CNN 的探测器和整数线性规划法。
2.4 UniPose
基于“瀑布”收缩空间池架构(WASP),Artacho 等提出了一个统一的人体姿态估计框架(UniPose)[10]。UniPose 不需要单独的分支来进行对边界框和关节检测,结合上下文分割和联合定位功能,确定了人体检测的关节点和边界框的位置。在不依赖统计后处理方法的情况下以高精度估计人体姿势。
默认的openpose[11]参数和自己电脑的配置不完全匹配,会导致电脑性能资源的浪费或溢出,导致软件在运算处理行人态势时,无法充分使用电脑性能,无法跑出最大FPS。甚至有时因为参数设置不当和优化不足,会导致FPS 数值非常低。针对openpose 默认的参数进行优化,使程序跑的过程中,将电脑性能发挥到极致,将没必要的处理减到最少,处理精度和震荡率减小到最合理范围,open⁃pose 的默认处理分辨率的精度较高,识别精度很高,但如果GPU 性能不好的话,就会让FPS[12]非常不理想。本文结合这些问题进行分析和调试,寻找最优的参数解决方案。
3 平台设计
本系统平台的硬件部分包括一部手机、一台GPU性能较好PC机,手机进行视频录制和拍照片,把录制好的视频和图片导入到PC 里,PC 端利用OpenPose 系统进行处理,如图1。手机端和电脑端分别下载DroidCam,此软件可以实现通过无线网络,把手机作为PC端摄像头的功能,将电脑和手机连接好,实现实时的摄像画面功能,PC 端利用OpenPose 系统,进行实时摄像画面人体姿态识别,如图2。

图1 视频图片处理流程

图2 摄像实时处理流程
4 系统实现
综合前面的开发环境搭建和算法分析,本章主要任务是设计并实现基于OpenPose[13]的图片、视频和实时摄像头的人体姿态识别系统。深度学习训练数据集模型文件采用预先训练好的COCO[14]模型,通过OpenPose 对图片、视频、实时摄像头、进行姿态识别和图片、关节点信息的输出。
4.1 手机作为摄像头与电脑连接
手机端和电脑端各自下载DroidCam 软件,从而手机可作为电脑的摄像头。
1)下载手机端DroidCam运行如图3。

图3 Android端DroidCam运行
手机屏幕上显示的WIFI IP 为手机的IP 地址,Device IP为端口号。
2)下载电脑端DroidCam运行如图4。

图4 电脑端DroidCam运行结果
电脑端输入手机端的IP 地址和端口号,如图5。

图5 输入界面
将上面手机上的IP 地址和端口号输入电脑端的对应位置,下面的Audio 可以设置是否通过手机录制声音。
4)连接后的效果如图6。
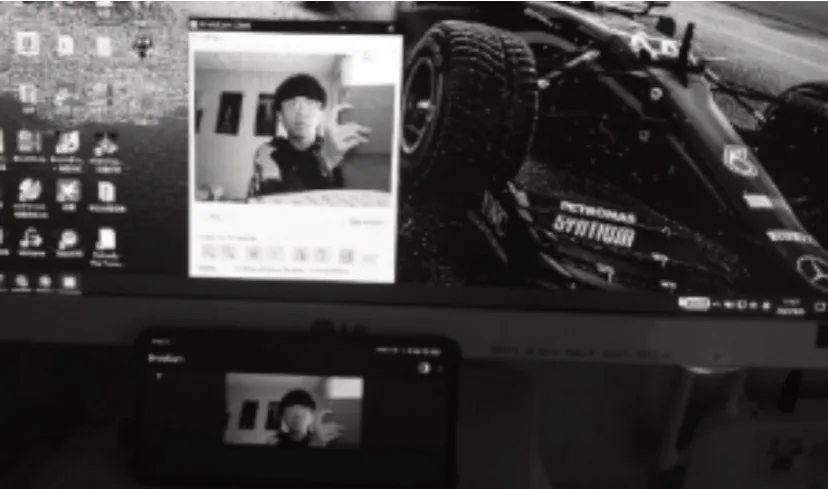
图6 连接效果
点击“Start”后手机与电脑连接,手机摄像头的画面被同步到电脑上,视频延迟很低,清晰度流畅度也不错,电脑端视频也是以摄像头视频流的方式被调用的,方便后面对调用摄像头时,能够调用到这个视频流。
4.2 对图片进行人体姿态识别处理
1)选取一张含有人物的图片,如图7。

图7 人物图
2)输入命令行指令,输入图片地址和想要将处理好的图片输出的地址,如图8。

图8 指令图1
其中”binOpenPoseDemo.exe”为运行OpenPose的命令,--write_images examples3”表示将处理的数据以图片格式输出,输出地址为”examples3”。--image_dir examples2”表示处理的数据为图片,读取地址为”examples2”。
3)输出的人体姿态图像如图9。

图9 人物姿态识别图
4.3 对图片进行人体面部识别和手部识别
1)输入命令行指令如图10。

图10 指令图2
其中“--face”表示启用人脸姿态识别,“--hand”表示启用手部姿态识别,--face_net_reso⁃lution“256×256”表示面部识别的识别分辨率为‘256×256’,--hand_net_resolution“256×256”“表示手部姿态识别的识别分辨率为‘256×256’。
2)运行效果如图11。

图11 人体姿态面部手部识别图
4.4 对视频进行人体姿态识别
1)选取一段人物清晰的视频如图12。

图12 人体视频动图
2)输入命令行指令如图13。

图13 指令图3
视频地址为“examplesmediammexport162703 4-098799.mp4”,“write_images_examplesmedia_out”为设置输出格式为图片,输出地址为“examplesme⁃dia_out”。
3)输出的人体姿态图片如图14。

图14 图片输出图
因为视频通过处理只能输出为逐帧的图片,所以此时该文件夹中输出了两千多张图片,是逐帧处理输出的。
4)逐帧图片合成视频
通过pr 等视频剪辑软件,将导出到“exam⁃plesmedia_out”路径下的2847张进行视频合成。
5)合成后视频效果如图15。

图15 视频合成效果动图
6)视频人体识别流程图如图16。
图16 视频处理流程图
4.5 摄像头实时人体姿态识别
1)手机作为摄像头进行连接
手机端电脑端下载DroidCam 软件,电脑端输入手机端的IP 地址和端口,进行连接,效果如图17所示。

图17 摄像头连接图
2)输入命令行命令,如图18所示。
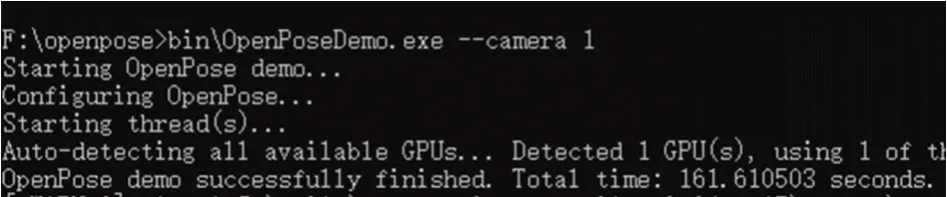
图18 指令图4
3)运行结果为如图19。

图19 实时人体姿态识别动图
5 系统优化
5.1 摄像头调用错误
在启用摄像头实时运行时,会出现摄像头调用错误的情况,调用的不是自己想调用的手机摄像头,而是电脑摄像头,如图20所示。

图20 系统默认调用摄像头
在运行时,需要将摄像头指定为数组中的第二个摄像头,如图21所示。

图21 指令图5
改过摄像头后运行程序如图22。

图22 改后摄像图
将摄像头改为1 后,OpenPose 的运行可以正常显示手机作为摄像头传入的画面。
5.2 运行时内存溢出
独立运行Pose[15]模式时,OpenPose可以正常运行,但将face 和hand 添加进来时,程序就会出现溢出如图23。

图23 内存溢出提示图
第6 行显示“out of memory”表示内存溢出了。经过查询研究发现,OpenPose 在默认情况下,对pose、face、hand 的解析分辨率设置的较高,设置成小一点的分辨率可以解决这个问题。对pose、face、hand重新设置分辨率参数,如图24。

图24 重新设定分辨率图
运行效果如图25所示。

图25 人体脸部手部姿态识别动图
5.3 优化调试
经过几次讨论和尝试,锁定了flags.hpp[17]文档,里面有每个参数详细注释,如图26。

图26 文档注释图
其中主要参数:
Pose:身体骨骼关键点检测模式;
Face:脸部关键点检测模式;
Hand:手部关键点检测模式。
在不同模式下设置不同分辨参数,导致运行帧率不同和人体识别精度不同。通过调整参数,来提高骨骼还原度、面部还原度、手部还原度。通过实验设置不同分辨率参数来找到一套最优参数设置。
发现是电脑GPU 配置太差,无法运行默认状态的pose+hand/face[16],以上报错信息也是内存溢出。
解决方案:
调整网络的分辨率,其调整如表1。

表1 分辨率调整表格
实验结果:
默认情况下如表2所示。

表2 默认情况表
第一次调整如表3所示。

表3 第一次调整表
第二次调整如表4所示。

表4 第二次调整表
第三次调整如表5。

表5 第三次调整表
由以上实验结果,对每个列表的分辨率进行实验,统计每个列表分辨率下运行的帧率,综合考虑流畅性和识别精度两方面,得到了一套比较合理的分辨率方案,如表6所示。

表6 最终方案表
为了使得行人检测和姿态估计系统在精确度、时效性以及帧率之间达到了一个良好的平衡,通过实验,本文总结出一套全新的参数优化策略:为了得到一套比较合理的分辨率方案,可以快速地去设置参数,初始分辨率为256*256,针对net_resolution模型,可以调整pose、pose+face、pose+hand、pose+face+hand 的参数;针对face_net_resolution 模型,只需要去调整post+face 参数或pose+face+hand 参数;针对hand_net_resolution 模型,只需要调整pose+hand或pose+face+hand参数。
6 结语
本论文研究了在各种不同检测需求下和不同硬件环境下,最优的配置参数。实现性能利用最大化。
本文在基于深度学习的行人检测姿态估计系统的基础上主要做了以下工作:
1)对与不能调用其他非系统摄像头的问题进行研究改进。
2)对不同精度需求和不同配置的电脑进行参数优化。
3)总结出一套全新的参数优化策略。
人体姿态识别做为一个研究方向,以后一定会进入我们每个人的生活,可以预测这个技术以后一定会改变我们的生活方式,为人类带来巨大贡献。
