基于图卷积网络的产业领域科技服务资源命名实体识别*
2023-05-12赵卓峰
张 硕 赵卓峰 刘 晨
(1.北方工业大学信息学院 北京 100144)(2.大规模流数据集成与分析技术北京市重点实验室 北京 100144)
1 引言
科技服务业是将科技成果转化为生产力的突破口[1]。随着科技的快速发展,产业领域产生了大量的科技服务资源,包含论文、专利、项目、咨询等。这些资源信息隐含着丰富的知识价值,通过信息抽取可以帮助我们分析挖掘科技知识之间的关联关系,掌握当代科技研究的热点,预测科技发展的动态规律。然而,产业领域科技服务资源所涉及的行业众多,大多为半结构化数据和非结构化数据,并且缺乏统一的描述规范。因此,亟需找到可以将非结构化的产业领域科技服务资源信息转化为结构化知识的信息抽取方法,便于之后的数据分析和知识挖掘。
命名实体识别是信息抽取的重要步骤[2]。产业领域科技服务资源实体识别需要抽取出专家人才、专业技术点、科技方法以及领域术语等信息。现有常用的命名实体方法主要是基于深度学习的方法。基于深度学习的方法包括递归神经网络(RNN)[3]、双向长短期记忆网络[4](BiLSTM)以及双向门控循环网络(BiGRU)[5]等。为了避免RNN 带来的梯度消失的问题,能够获取文本数据的上下文特征信息,提高实体识别的准确率,基于BiLSTM模型的方法在生物医学、电子病历、法律、军事等领域得到广泛应用。为了节省时间和内存空间,又提出了采用结构简单的BiGRU 模型。虽然命名实体识别在许多领域得到广泛应用,但针对产业领域科技服务资源命名实体识别的研究较少。
通过分析产业领域中科技服务资源信息,发现实体识别时有以下几个难点:1)产业领域科技服务资源命名实体识别的边界模糊,实体词的长度不一。如“氧化硅”和“氧化硅气凝胶”,“乙烯”、“苯乙烯”、“聚苯乙烯”和“聚苯乙烯螯合树脂”均可作为实体出现。2)产业领域科技服务资源包含大量复杂的专业术语实体,包含了数字和特殊符号表示。如“Sm-Al-Co 系Sm 基三元块体非晶合金”、“Pb-Si-N 三元化合物”和“邻苯二甲酸二丁酯”等等。3)产业领域科技服务资源文本描述语句较长,缺乏特定的表述规则,很难充分获取词语的语义特征以及词语之间的关系特征。如图1 中,从“发明”到“氢化物”存在远距离的VOB 动宾关系,再结合“镧系”、“金属”均与“氢化物”的存在近距离ATT定中修饰关系,可以更好地表征“镧系金属氢化物”这一实体的存在。

图1 依存分析图
因此,为了解决产业领域科技服务资源命名实体识别的问题,提高实体识别的准确率,本文提出了一种融合图卷积网络(GCN)的命名实体识别,记为BERT_pos-BiLSTM-GCN-CRF 模型。由于产业领域科技服务资源存在大量复杂的专业术语,为了解决word2Vec 模型只能表示一种静态语义,不能表示多义的问题,通过BERT 词嵌入模型进行字符编码的表示。可以结合句子上下文信息来获取字符的动态特征,有效解决一词多义的问题。此外,BERT模型还可以通过下一句预测句子之间的上下文关系[6],并通过其内部多头注意力机制设置权重来获取字符间的语义信息。另外,仅通过字符特征很难确定实体边界,因此,还通过添加词性特征对BERT 获得的字符表示向量进行扩展。此外,由于产业领域科技服务资源文本描述没有统一的标准,句子结构复杂,没有充分利用句子中词语之间的依赖关系进行实体识别。而BiLSTM只能获取近距离字符间的特征信息,不能充分获取句子远距离词语间的依赖关系。在BERT-BiLSTM-CRF 模型的基础上引入图卷积网络,借助依存句法分析,挖掘字符及字符间关系的结构信息,将BiLSTM 提取到的特征向量与词语间的依存关系矩阵进行拼接,充分获取文本的全局特征。实验结果表明,本文采取的BERT_pos-BiLSTM-GCN-CRF 模型优于传统的实体识别方法。
2 相关工作
基于深度学习的方法进行实体抽取是近几年研究的热点。文献[7]提出了一种适用于电力文本基于多个特征的字符级实体识别模型,结合了字符、左邻熵和词性来表示电力调度文本的领域特征,利用BiLSTM对字符序列标签进行预测,最后利用CRF对预测的标签进行优化。文献[8]提出一种临床命名实体识别模型(CNER),先将原始数据集的文本序列的字符向量和词向量有机地结合起来,然后将序列分别输入多头自注意模块和BiLSTM神经网络模块的并行结构中,以此获得上下文信息和特征关联权值等多层次信息。文献[9]提出了一种基于BIBC的命名实体识别方法。该方法利用基于整词掩蔽的BERT-WWM 模型进一步提取中文数据中的语义信息,并通过大规模无标注数据补充特征,结合BiLSTM-CRF 模型进行实体识别,实验结果表明该方法能够更准确地抽取出糖尿病病历中的实体信息,获得良好的实体识别结果,能够满足实际应用的要求。此外,由于BiLSTM结构复杂,模型训练时需要消耗大量的时间和内存空间,而双向门控循环网络[8]结构较简单。文献[10]提出利用BiGRU 模型学习上下文特征提取肺癌医案中的实体。
尽管这些方法在其他领域的实体识别任务上取得了较大的进步,但还是无法有效地应用于产业领域科技服务资源中的实体识别任务。由于产业领域科技服务资源文本描述语句较长,很难充分获取词语的语义特征以及词语之间的关系特征,虽然BiLSTM-CRF 方法可以在一定程度上获取到句子的上下文语义特征,但不能获取远距离依赖关系。所以本文引入GCN 层充分获取句子的全局特征。另外,由于产业领域科技服务资源中存在大量复杂的专业术语,仅通过基于字的BERT 模型无法高效关联出词语之间的关系,使得实体边界的识别变得困难。所以添加词性特征作为外部辅助特征,将BERT获取到字符特征、句子特征、位置特征与词性特征进行拼接融合,可以帮助更好地识别实体的边界,提高实体识别的准确率,所以本文采用BERT_pos-BiLSTM-GCN-CRF 模型对产业领域科技服务资源进行实体识别。
3 构建模型
本文采用的方法主要包含4 个模块,分别为BERT 层、BiLSTM 层、GCN 层以及CRF 层。首先采用BERT 层将文本向量化,得到蕴含语义信息的字符表示;然后通过BiLSTM 层和GCN 层联合深度学习提取全句特征信息;最后在CRF 层对GCN 模型的输出特征序列进行解码,根据所有标签概率得分选取一个全局最优序列。该模型结构如图2所示。

图2 模型总体结构图
3.1 BERT层
将文本字符输入,通过BERT 词嵌入模型输出每个字符的向量表示。首先对科技服务资源文本中的每一句话进行处理,在每一句话开头加[CLS]标志,代表一句话的开始,并在该句的末尾加[SEP]标志,代表一句话的结束。例如“[CLS]一种制备氨基乙酸的方法[SEP]”。该模型的最大序列长度seq_length 设为128,采用多退少补的原则,当文本句子字符长度超过128 时,进行截断操作,当文本句子字符长度小于128 时,使用[PAD]进行填补。通过查找词向量文件找到每个字符所对应ID映射编码。然后通过训练获取字符ID 对应的向量,批大小batch_size 设为32,映射为768 维的向量。总的嵌入表示向量是由字符编码、句子编码和位置编码三部分拼接组成[11]。其中,输入的形状为(32,128),输出的形状为(32,128,768)。
将获取的总embedding 作为Transformer 层的输入,Self-Attention 是Transformer 结构的重要组成部分,利用Self-Attention能有效得到蕴含语义信息的序列向量[12]。一共包含12 个layer 层,当前layer层的输入为前一layer 层的输出结果,第一个layer层的输入为embedding 层获取的向量,输入的形状为(4096,768)。每层都包含一个注意力机制,12个layer层共有12个头。总隐层大小为768,每个头64 维特征向量,然后将这12 个头提取的特征向量结果concat 拼接。每个头拥有不同的3 个Q、K、V矩阵,其中Q、K、V分别表示query,key,value,将上一层的输出矩阵与该层的Q、K、V相乘得到新的Q、K、V矩阵。注意力权重分数计算公式如下所示:
该层的输出形状为(32,128,768),然后进行归一化残差连接。为了提升特征表达的能力,加入全连接层将768 维特征向量提升为3072 维,激活函数采用gelu。最后将结果再变回一致的维度768。
另外,由于加入了外部特征词性特征,所以对BERT 层输出的embedding 进行扩展,加入词性嵌入pos_embedding。
3.2 BiLSTM层
该层主要是为了提取文本字符的上下文特征信息,将从BERT 层获取的各个字的embedding 序列作为双向长短期记忆网络的输入。这里采用两层LSTM,第一层LSTM 网络计算前向的隐特征,第二层LSTM 网络计算后向的隐特征,如“我爱你”和“你爱我”是两个不同的语义特征,所以把这两个LSTM 层输出的隐状态序列进行concat 拼接。LSTM 隐藏层的特征维度为128,隐层的层数为1,dropout-rate 为0.5。将LSTM 状态类型以元组类型表示输出,输出状态表示为[ht,ct],包括两部分内容,一部分为细胞状态ct,另一部分隐藏层状态ht,计算公式如下所示。
其中,it表示输入门输出的信息、ft表示遗忘门输出的信息、ot表示输出门输出的信息[13]。ct通过tanh神经单元用于计算数据的输入。
ht,ct的维度为当前LSTM单元的hidden_size,输出的维度大小为128维。由于双向LSTM 获取上下文特征,最后将产生的前向隐特征和后向隐特征拼接联合输入到图卷积网络层,其输出的维度大小为256维。
3.3 GCN层
将BiLSTM 层完整的隐藏层状态送入GCN层。该层的输入由两部分构成:一部分是BiLSTM层输出的特征向量,另一部分是依存关系分析图的邻接矩阵向量。本文采用LTP 工具构建依存分析图。例如产业领域科技服务资源文本中的“本发明涉及新材料领域”其构建的依存分析图如图3 所示。

图3 依存句法树示例
然后将依存分析图转化为邻接矩阵,若词语之间存在依赖关系,则为1,否则为0。由于该模型的输入是以字为单位的,而通过依存关系分析的是词级别的,因此,对原来的词邻接矩阵进行修改,构建出字级别的矩阵向量,如图4所示。

图4 邻接矩阵
图卷积网络中单元数设为128,GCN 层数为2,第一层作为前向图卷积网络层,获取每个字符的出度信息,即该字符依赖哪些字符;第二层作为后向图卷积网络层,获取每个字符的入度信息,即哪些字符依赖于该字符。然后将这两层的最终输出结果进行concat拼接。
首先进行前馈计算,将从BiLSTM 层输出特征矩阵与每个节点的权重矩阵矩阵相乘,然后与一个自身相连的邻接矩阵相乘,通过激活函数σ,得到融合句子中字符间依赖关系的特征矩阵,其输出的形状均为(256,128),两个GCN 进行拼接输出的形状为(512,128)。
其中,L为BiLSTM 层传入的特征向量,Wo为图的出边邻接矩阵,Wi为图的入边邻接矩阵,W→k和W←k为GCN 的前向权重矩阵和后向权重矩阵,I 为自旋单位矩阵,b为偏移矩阵,选ReLu函数为激活函数。
然后将GCN 输出的每个字的128 维特征向量送入条件随机场CRF层中。
3.4 CRF层
CRF 的主要作用是通过训练自动学习最终预测的标签之间约束关系[14]。如:句子以B 或O 开头,B-M标签只能在I-M标签之前等。
CRF 对从GCN 层输出的每个字的所有标签得分进行筛选,对于给定的从BERT 层输出的文本字序列向量X={x1,x2,…,xn},定义矩阵P为输入序列X经BiLSTM 层和GCN 层联合学习后输出的对应标签的分值。本研究中包含18 个标签,分别 为[O、X、[CLS]、[SEP]、B-service、I-service、B-person、I-person、B-organization、I-organization、B-time、I-time、B-domain、I-domain、B-term、I-term、B-tech、I-tech],W为(18,18)维的状态转移矩阵,得到某一个预测序列y={y1,y2,…,yn}与X的联合概率,通过损失函数loss计算真实路径得分与所有路径得分的比值,选取给定序列中的最优联合概率分布,即全局最高的为实体识别的结果,输出的形状为(4096,18),即一次训练32 个样本句子的所有字符对应的序列标签。
4 实验数据与结果分析
4.1 实验数据
本文从国家知识产局、知网、科技资源共享平台、科易网等网站爬取产业领域科技服务资源信息,包括科技专利资源、科技论文资源、科技咨询资源、科技项目资源以及仪器设备资源等。一共获取8954 个科技服务资源的描述文本,通过对产业领域科技服务文本内容进行分析,定义了7 种实体类型:科技服务名称、专家人才、机构组织、发布时间、所属行业、行业术语以及技术点。
采用BIO 的方式对产业领域科技服务信息进行序列标注,利用Brat标注工具对文本进行数据标注,“B”代表实体的起始位置,“I”代表实体的中间部分,“O”代表与实体无关的词[15],“-”代表实体的类型。产业领域科技服务资源信息实体标注标签如表1所示。

表1 实体标签标注
另外,本文在原有标注上加入词性特征,“-”后代表实体的词性,标注示例如表2 所示,将经过序列标注和词性标注的文本数据作为实验数据集进行训练预测。

表2 实体标注示例
4.2 实验环境及参数设置
本文实验环境如表3所示。

表3 实验环境配置
在实验中,参数设置如表4所示。

表4 模型参数设置
4.3 评价指标
本模型采用实体标签的准确率(P)、实体标签的召回率(R)以及实体标签的调和平均数(F1)作为评价指标[16],计算公式如下:
其中,Ec为标注正确的实体数量,Ei为标注错误的实体数量,Ed为未标注出的实体数量。
4.4 实验结果分析
采用交叉验证的方式,将实验数据的训练集与测试集按8∶2 比例进行划分。设置随机种子为1~5,取5 次测试结果的平均值作为最终的评估值。具体实体标签分布如表5所示。

表5 实体个数统计情况
为了验证BERT_pos-BiLSTM-GCN-CRF 模型的性能,本文通过实验与常见的实体识别模型BiL⁃STM-CRF、SelfAtt-BiLSTM-CRF、BERT-BiGRUCRF、BERT-BiLSTM-CRF、BERT-BiLSTM-GCNCRF进行比较。各模型的F1值变化如图5所示,由图可知,基于BERT 模型的算法在初始训练时基本能达到一个较好水平,其中本文的BERTpos-BiL⁃STM-GCN-CRF模型的实体识别的效果最好。
本文模型与其他模型的对比实验结果见表6,实验对比分析结果如下。
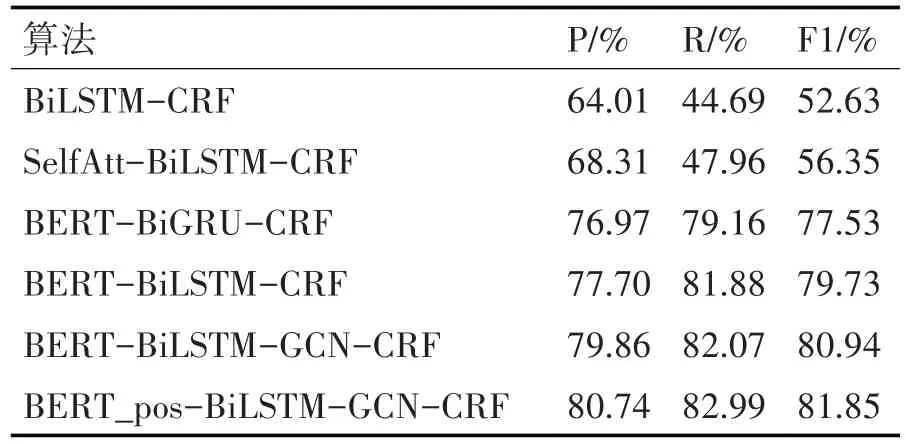
表6 相关模型对比
1)对比BERT-BiGRU-CRF 和BERT-BiLSTMCRF 算法,目的是验证BiLSTM 与BiGRU 两者之间哪个更有益于实体识别,从图6 中可以看出,在本实验中,采用BiLSTM 模型的效果略优于BiGRU 模型,可以获取丰富的上下文特征,帮助提高实体识别的准确率,F1值提高了2.2%。

图6 第1组实验结果
2)对比BiLSTM-CRF 算法和BERT-BiLSTMCRF,目的是验证选取不同的词词嵌入模型对实体识别的效果是否存在影响。其中,BiLSTM-CRF 中使用的是word2Vec词嵌入模型,从图7中的实验结果可知,BERT 词嵌入模型与word2Vec 词嵌入模型相比,F1 值平均提升了27.10%。结果表明,使用BERT 预训练语言模型可以,由于它能充分提取字符间关系的特征,能更好地表达科技服务资源文本中字符隐含的语义信息。

图7 第2组实验结果
3)对比BERT-BiLSTM-CRF和BERT-BilLSTMGCN-CRF 算法,目的是验证加入基于依存分析图的图卷积网络是否有助于提高实体识别的准确性。从图8 中可以发现,在BERT-BiLSTM-CRF 模型基础上融入图卷积网络能更好地提取全局特征,提高了科技服务资源信息实体抽取的准确率,F1值提高了1.21%。
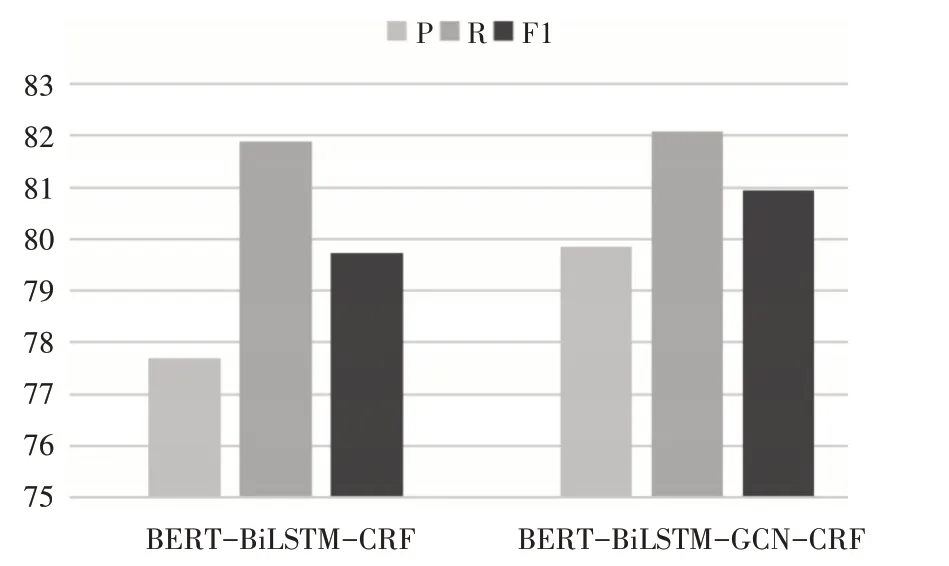
图8 第3组实验结果
4)对 比BERT-BiLSTM-GCN-CRF 和BERT_pos-BiLSTM-GCN-CRF 算法,目的是为了验证添加词性特征后是否可以更有效地识别实体的边界,从图9 中可以看出添加词性特征后使得实体识别的准确率提高,F1值提高了0.91%。

图9 第4组实验结果
为了验证实验结论的正确性,使用该模型在CoNLL2003 语料上进行实验,该语料中包含人名、地名、组织和其他。实验结果如表7所示。
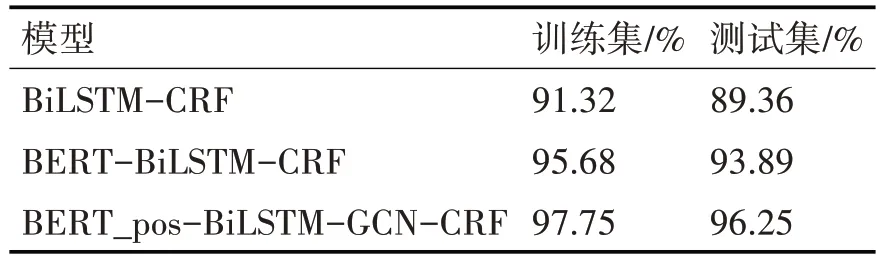
表7 CoNLL2003语料的实验结果
由表7 可以看出,与BiLSTM-CRF 和BERTBiLSTM-CRF 模型相比,本模型在CoNLL2003 语料上的训练集准确率为97.75%,测试集的准确率为96.25%,由此可文中模型可以有效提高实体识别的准确率。
5 结语
本文提出了一种基于图卷积网络的产业领域科技服务实体识别方法。该模型采用BERT 预训练语言模型提取产业领域科技服务资源文本中的上下文语义特征,引入词性特征作为辅助特征,对BERT 获取的语义特征进行扩充,并通过GCN 学习文本句子中词语之间的依存关系,用以获取句子的远距离特征。通过实验发现,该模型优于传统的实体识别方法,能够有效提取产业领域科技服务资源中的实体信息。此外,该模型虽在一定程度上提升了产业领域科技服务资源信息中实体识别的准确性。但为了避免实体抽取模块产生的误差影响整个知识图谱构建的质量,后续将进一步研究实体关系联合抽取的方法,从而完善产业领域科技服务资源信息的提取。
