利用SIMD向量化的数据流软错误检测算法
2023-05-12曹子宁
张 磊,彭 飞,曹子宁,庄 毅
(南京航空航天大学 计算机科学与技术学院,软件新技术与产业化协同创新中心,南京 211106)
1 引 言
宇宙高能粒子辐射引起的计算机硬件的瞬时故障会导致软错误[1],如α粒子和高能中子.这种粒子的撞击持续时间很短,但会造成P-N结翻转,从而引起存储元件的位翻转或中断组合逻辑电路的异常操作,这种现象称为单粒子翻转(Single Event Upset,SEU).这可能会影响应用程序的输出,甚至使计算机系统崩溃.工作在辐射环境中的SRAM单元很容易发生这种错误.目前已有通过电路设计和错误检查码(ECC)等技术来提高其恢复能力.随着处理器尺寸的减小和电源电压的降低,技术的发展为处理器提供了更好的性能和能效,但是这又使得计算机系统更容易受到软错误的影响,对可靠性提出了重大挑战.
目前已有不少针对软错误的硬件和软件检测方法.例如高速缓存,大型SRAM阵列均有较高的软错误率(Soft Error Rate,SER),这已经通过电路技术和使用校验验码来解决.已有的研究表明,SRAM的SER在几代技术中大致保持不变,一般为10-4FIT/bit[2].组合逻辑电路更能抵抗由于错误掩蔽而引起的瞬时故障,即使存在软错误,逻辑电路的输出值也可能不会改变,在结果被锁定之前,电路也可以自己从错误中“恢复”.锁存器和组合逻辑电路的SER范围从10-5~10-3,每个芯片每年大约有0.5次故障[3].尽管未来的处理器可能在所有锁存器上都有奇偶校验,但是这也引起较大的面积和功耗开销,并且额外校验位的引入也会提升错误率,因此这些错误很难检测到,即使在硬件中可以检测到也很难纠正[4].
基于硬件的解决方案在性能方面十分有效,通常开销在5%~10%之间.然而对于目前市场的利润是十分昂贵的,并且也不能做到万无一失.为了克服这些缺点,可以通过软件实现容错(Software Implemented Hardware Fault Tolerance,SIHFT)来替换或加强硬件冗余.这种方法的另一个好处是可以有选择地应用,例如对于一个系统的所有执行计算,中断控制程序和多媒体应用程序是较为重要的.通过使用SIHFT,可以忽略非重要应用程序加固,并仅将其应用于重要应用程序.
软错误会对计算机系统产生不同的影响,例如系统崩溃、超时、SDC(Silent Data Corruption)等,其中SDC问题是可靠性领域一直以来研究的重点之一.当SDC发生时,程序正常执行,但是输出结果不正确.已有方法主要是通过软件方法对发生SDC概率高的指令保护,从而减少整个系统的SDC错误.
软件实现的数据流错误检测方法主要是通过冗余执行来实现错误检测,但这会带来很大的开销问题.在硬件迅速发展的时代,可以在软件层利用多核并行、SIMD数据并行等能力来加速程序地执行效率,这是已有方法所忽略的地方.本文运用SIMD指令将原计算和冗余计算向量化实现并行处理,必须解决如下两个挑战:
1)难以将程序中不同数据类型向量化.通常一个程序中存在一些不同类型的数据,例如整型、浮点型、数组、结构体.如何将这些类型的原始数据和冗余数据向量化,并在访问它们时以一个向量访问操作完成读取数据操作,是一个待解决的问题.
2)难以将标量与向量数据的指令向量化处理.对原数据和冗余数据进行向量化后,对其原始的标量操作需转化为向量操作.因完全冗余带来的巨大开销,通常不会采取完全冗余的策略,如何兼容向量与非向量数据间操作是性能提升的一个关键问题.
针对已有的基于冗余复制的数据流软错误检测算法开销大的问题,本文提出了一种基于SIMD(Single Instruction Multiple Data)向量化的数据流软错误检测算法(Vectorization-Based Soft Error Detection,VBSED),对原数据和冗余数据进行处理向量化处理,生成向量数据;进一步,使用SIMD指令执行向量数据,从而提高加固后程序的性能.目前大多数主流商业处理器CPU都支持SIMD指令.例如Intel x86的SSE/AVX,ARM NEON.本文的主要贡献有:1)定义程序数据在向量环境下的向量格式,设计了标量数据到向量数据的转化规则;2)提出基于SIMD向量化的数据流软错误检测算法,对源程序在中间代码层自动进行向量化处理.在Mibench测试程序上的实验结果表明,本文提出的算法比已有数据流冗余算法有更好的检错能力和更低的性能开销.VBSED算法相较于已有的数据流软错误检测算法具有的下列优点:
1)利用数据并行性的特性,可提高加固后程序的性能;
2)减少了加固后程序代码空间开销;
3)考虑了Cache和内存发生错误,具有检测缓存等部件软错误的优点,这是现有算法一般不具有的能力,提高了检错能力.
本文的其余部分组织如下.第2节介绍了相关研究工作;第3节详细介绍了VBSED算法的设计,包括算法整体框架,数据与指令向量化规则,错误检测代码生成规则;第4节进行了相关对比实验;第5节给出了本文结论.
2 相关工作
目前针对软错误检测的方法主要分为两类:基于硬件的错误检测方法和基于软件的错误检测方法.
基于硬件的错误检测方法大多数是通过修改或扩展硬件模块来达到检测错误目的,而修改硬件模块是一件困难的工作,因此主流的方法是通过添加额外的硬件电路.典型的双模冗余和三模冗余是通过硬件冗余技术,并验证运行结果的一致性来判断故障的发生.Diva等人使用一个不完全的有序检查器[5],到达重排序缓存的指令,包括相关的输入和推测的结果,将按程序顺序被移动到检查器进行检测,但是这个方法的弊端是检查器数量会随着主内核功能单元数量而增多.Nathan等人针对超标量、乱序执行处理器核设计了一种低开销的方法[6],它在每一条指令在解码阶段就预测当前指令所做的操作,随后记录指令执行阶段操作,验证预测和实际运行结果是否一致,从而检测每一条指令发生的错误.
尽管硬件的方法可以带来很好的性能,但是成本和难度却很大.基于软件的错误检测方法实现较为简单且成本低,主要分为控制流检测方法和数据流检测方法两类.CFCSS(Control Flow Checking by Software Signatures)[7]是经典的控制流检测方法,它将程序划分为一系列基本块,把基本块和控制流跳转关系抽象为控制流图,通过在图中各个基本块头添加验证标签来检测控制流错误,该方法具有较高的控制流错误检测率,且开销很低,缺点是无法检测到块内的控制流错误.Vankeirsbilck[8],Zheng[9]等人在CFCSS的基础上进行了改进,在基本块内添加额外的标签和利用多层分段标签来检测块内的控制流错误,从而提高检测率.
EDDI(Error Detection by Duplicated Instructions)是一个典型的数据流错误检测方法[10],它复制程序基本块中所有指令,并在存储指令和分支指令之前插入比较指令,用于比较原指令和复制指令的值.然而这种方法开销巨大.Reis[11],Eduardo[12],Thati[13],Ko[14]等人对EDDI提出了改进的方法,对全冗余复制方法带来的开销问题进行了改进,设计了可选择指令复制和可选择检查指令插入机制.Chen提出利用SIMD指令提升冗余执行效率的思想[15],将原数据复制一份并与原数据打包到向量寄存器,随后用SIMD指令完成对向量寄存器运算,但是该方法只考虑寄存器上的错误,且数据打包操作会带来很大的性能开销.Zhang[16],Yang[17]等人提出了选择性保护方法,允许在用户指定的开销范围内有选择地保护程序中易发生SDC的指令,首先提取程序指令中静态和动态特征,通过建立回归树和随机森林预测模型来预测程序指令的SDC脆弱性,进而利用指令的SDC脆弱性选择重要指令冗余,在保证高检错率的前提下减少冗余开销.
3 基于SIMD向量化的数据流软错误检测算法设计
3.1 基于SIMD向量化的数据流软错误检测算法框架
本文设计的基于SIMD向量化的数据流软错误检测算法框架由源码编译、预处理分析、向量化加固3个阶段组成,框架如图1所示.
提出的基于SIMD向量化的数据流软错误检测算法框架(VBSED)是一个由源码到最终加固代码的自动化处理过程.首先源码经过编译生成中间代码[18,19],然后预处理分析对中间代码中的指令构建数据流依赖图[20],通过拓扑排序对数据流依赖图进行排序,得到指令依赖顺序.向量化加固是本文算法的核心,通过使用SIMD向量化的数据流软错误检测算法对目标程序进行加固,VBSED对预处理后程序进行数据向量化和指令向量化处理[21,22],并在检查点位置比较向量数据中原数据和冗余数据进行错误检测.为了让本文算法具有更高的灵活性和可配置性,用户可以制定重要数据和检查点规则配置,在时间开销与空间开销之间作调整,得到不同粒度的加固结果.
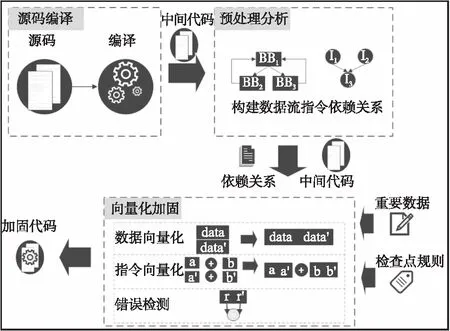
图1 基于SIMD向量化的数据流软错误检测算法框架Fig.1 VBSED algorithm framework
本文的算法基于LLVM[23]开发的编译器工具,实现完全编译自动化,无需人工修改程序.基于SIMD向量化的数据流软错误检测算法流程如图2所示,分为两个阶段:
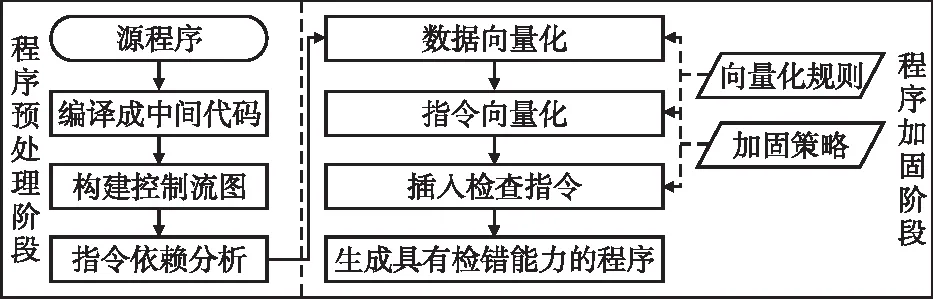
图2 基于SIMD向量化的数据流软错误检测算法流程Fig.2 VBSED algorithm process
1)程序预处理阶段
给定一个目标源程序,首先由Clang编译器将其编译成LLVM中间代码,并构建控制流图和数据流指令依赖关系分析,得到指令依赖顺序,为加固阶段做准备.
2)程序加固阶段
程序加固阶段分为如下4个阶段:
a)数据向量化
此阶段首先根据用户指定的加固策略,对用户指定的重要数据保护,对这些数据应用相应的数据向量化规则.
b)指令向量化
按指令依赖关系顺序依次处理每条指令,对其应用相应的指令向量化规则.
c)添加检查点
根据加固策略中的检查点规则应用相应的检查点规则,生成错误检测代码,将存在于向量中的原数据和冗余数据做比较以实现错误检测功能.
d)生成可执行程序
对完成前3个阶段后的代码编译链接,最后生成具有数据流检错能力的目标程序.
3.2 相关定义
本文中,首先给出以下相关定义:
定义1.数据(Data,D):数据在程序中分为4类,有标量类型,向量类型,数组类型和结构体类型.
1)标量类型数据Db:
2)向量类型数据VD:<(value1,…,valueM),type>,该向量表示包含M个类型为type的元素.
3)数组Darr:{Db1,Db2,…,Dbn},n≥1,表示n个元素Db的集合,且其中Dbi的type都相同.
4)结构体Dst:{Db1,…,Dbi,…,Dbn,Darr1,…,Darrj,…,Darrm},n×m>0,n≥0,m≥0,表示由Db和Darr组成的复合数据,其中Dbi与Darrj的type不作限制.如Dbi的type为int,Darrj的type为float,其中0 定义2.指令(Instruction,I):将指令I分成如下5种类型,并给出对应格式: 1)运算指令Iarith: 2)加载指令Ild: 3)存储指令Ist: 4)跳转指令Ijmp: 5)其他指令Iot: 定义3.数据流指令依赖关系:程序中指令序列I={I1,I2,…,In},若存在Ij操作数odt为指令Ii结果数,则称指令Ij依赖指令Ii,表示为Dep(Ii,Ij). 本文设计的标量数据转换为向量数据的规则如下: 规则1.基本类型数据向量化转换规则VEC_D_B(Db,K),定义见式(1).Db为应用该规则的数据,K为转换后向量的长度,下文表示相同.对于任意Db= VEC_D_B(Db,K): VDb=<(value1,…,valueK),type> (1) 其中valuei=value,1≤i≤K. 规则2.数组向量化转换规则VEC_D_ARR(Darr,K),定义见式(2).Darr为应用该规则的数组.对于任意Darr={Db1,Db2,…,Dbn},有: VEC_D_ARR(Darr,K): VDarr={VDbj|VDbj=VEC_D_B(Dbi,K),Dbi∈Darr} (2) 规则3.结构体向量化转化规则VEC_D_ST(Dst,K),定义见式(3).Dst为应用该规则的结构体.对于任意Dst:{Dbi,…,Dbn,Darrj,…,Darrm},n×m>0,n≥0,m≥0,0≤i≤n,0≤j≤m,有: VEC_D_ST(Dst,K): VDst={VDbi|VEC_D_B(Dbi,K),Dbi∈Dst}∪ (3) 结构体是由基本类型数据和数组组合成的复合类型数据,对其应用向量化规则,需对它的所有基本类型数据Db应用规则1,对所有数组数据应用规则2.例如结构体数据Dst={Db1,Db2,Darr},对Dst应用规则3,需对Db1和Db2和分别应用规则1,对Darr应用规则2,因此对Dst向量化后的向量数据VDst={VDb1,VDb2,VDarr}. 上述定义的3种规则是将原数据和冗余数据用向量表示,例如对于基本类型数据Db= SISD(Single Instruction Single Data)指令中的寄存器是标量类型的,其中数据为基本类型数据Db,将SISD指令向量化需要将指令中的数据也向量化,根据上一节定义的指令类型,本文定义的算术指令、加载指令、存储指令向量化规则如下: 规则4.算术指令向量化规则VEC_I_ARITH(Iarith,K),定义见式(4).Iarith为应用该规则的算术指令.对于任意Iarith: VEC_I_ARITH(Iarith,K): VIarith= (4) 其中vop是op的向量运算,od1,od2,dest是Db数据,vod1,vod2,vdest分别为对应的VDb数据.K表示对此指令中数据向量化的长度.运用该规则,可将运算op向量化为vop,在执行对向量数据vod1和vod2运算,可并行对向量中每一个运算. 规则5.加载指令向量化规则VEC_I_LD(Ild,K),定义见式(5).Ild为应用该规则的加载指令.对于任意Ild: VEC_I_LD(Ild,K): VIld= (5) 其中vload是向量加载操作,从内存地址addr处读取一个向量.val是Db数据,vval为对应向量类型VDb数据.K表示对此指令中数据向量化的长度.运用该规则,可将加载指令load向量化为vload,在执行加载地址addr处向量数据,可并行加载向量数据中每一个元素. 规则6.存储指令向量化规则VEC_I_ST(Ist,K),定义见式(6).Ist为应用该规则的加载指令.对于任意Ist: VEC_I_ST(Ist,K): VIst= (6) 其中vstore向量加载操作,将一个向量存储到内存地址addr处.val是Db数据,vval为对应向量类型VDb数据.K表示对此指令中数据向量化的长度.运用该规则,可将存储指令store向量化为vstore,在执行将向量数据存储到addr处,可并行存储向量数据中每一个元素. 在标量计算、函数返回、函数调用处依然使用标量数据,这些地方需将原向量数据VDb转换成标量数据,下面定义向量数据转换为标量规则. 规则7.向量数据转换为标量数据规则DEVEC_VD_B(VDb,Idx),定义见式(7).VDb为应用该规则的向量数据,Idx是该规则返回向量数中的基本类型数据的索引.对于任意VDb=<{value1,…,valueK},type>,有: DEVEC_VD_B(VDb,Idx):Db= (7) 应用上一小节规则1~规则7后,可实现原数据运算与冗余运算转换为向量运算的并行计算,但是此程序不具有错误检测能力.本节给出VBSED算法中错误检测代码生成规则,用于在一些检查点位置生成错误检测代码,比较向量数据中原数据与冗余数据来检查错误,本文算法可以在四种情况下生成错误检测代码.本文还设计了可配置的检查点生成规则,用户可指定检查点位置,可选择性地在以下四种位置处生成错误检测代码. 1)条件分支:若条件判断数据是一个向量数据,从向量中提取数原数据前,检查向量中数据是否一致. 2)加载操作:当从内存中读取一个向量数据后,检查向量数据是否在内存或Cache中发生错误. 3)存储操作:将一个向量数据存储到内存前,检查向量中数据是否一致. 4)函数调用:在调用另一个函数前检查所有的参数,若函数形参存在向量化数据,则对向量化的形参数据生成错误检查代码. 根据上述4种情况,本文设计了4个检查点规则,如表1所示. 表1 检查点规则Table 1 CheckPoint 本文提出的基于SIMD向量化的数据流软错误检测算法主要思想是针对冗余执行的数据流算法效率低下问题,通过利用硬件SIMD数据并行性提升程序性能,设计了数据和指令化规则,对程序完成向量化处理,最后根据检查点规则在相应位置生成错误检测代码,实现错误检测功能.本文提到的向量化数据为程序中变量,用户可以有选择性的对重要变量进行向量化保护,从而避免因对所有变量数据向量化带来较大的空间开销问题.在对变量数据向量化处理后,程序中存在向量数据和标量数据,指令向量化规则会生成对这些数据操作的指令,以完成对数据正确操作. 该算法的输入是C语言源程序,由编译器将源程序转换生成LLVM中间代码,再根据3.3节中的规则对程序中的变量数据和指令进行向量化,然后在检查点位置生成错误检测代码,最终生成具有错误检测能力高效的加固程序,具体的步骤如下: Step 1.将源程序编译成中间代码; Step 2.根据用户给定的重要数据选择需向量化的数据,即程序中的变量,判断变量数据的类型,应用数据向量化规则1~规则3得到向量化数据; Step 3.将程序按基本块划分,构建基本块控制流图; Step 4.将基本块内的内指令根据指令依赖关系构建指令依赖的有向无环图,对此有向无环图通过拓扑排序生成指令依赖顺序; Step 5.按指令依赖关系依次处理每条指令,使用指令向量化规则得到向量化指令.若该指令为算术指令,指令中操作数均为已向量化数据,对该指令应用规则4.若该指令为加载指令,加载地址处的数据为已向量化数据,对该指令应用规则5.若该指令为存储指令,所存储的数据为向量数据,对该指令应用规则6; Step 6.根据用户指定的检查点规则和3.4小节中错误检测代码生成规则,在条件分支、加载操作、存储操作和函数调用位置处生成错误检测代码. 提出的基于SIMD向量化的数据流软错误检测算法无法完成对程序中所有指令向量化,本文算法针对数据访问指令和常见运算指令作向量化,例如加法、减法、乘法等指令.下面用一个快速排序程序的例子来应用本文提出的基于向量化的数据流软错误检测算法,详细解释原始程序的中间代码在应用本文提出的向量化规则后,生成向量化代码,本文实例中向量化长度K=2,即冗余一份原数据. 图3 应用规则和生成错误检测代码示例Fig.3 Example of rule and error detecion 如图3所示,将程序中数组数据向量化,实例中数组是包含8000个整数标量的一维数组,根据3.4节中规则2,经过转换后生成一个包含8000个长度为2的整数向量的数组.图3中规则1将5个整数标量数据转换为5个长度为2的整数向量.图3中展示了应用规则5的示例,因为变量数据i,j已经被转换为向量数据,所以此处load转换为对应的向量操作.图3中还展示了应用规则4、规则6和生成错误检查代码的示例,规则4和规则6与规则5应用类似,add,store对向量数据的操作需转换为对应向量操作.根据3.4小节规则在存储指令之前生成错误检测代码,将向量中第1个元素(原数据)和第2个元素(冗余数据)比较,实现错误检测功能. 本文构建了故障注入仿真实验平台[24].课题组基于Gem5[25]仿真工具进行了二次开发,该平台具有模拟寄存器、存储器、缓存故障等功能,在此平台上对EDDI与VBSED算法的错误检测率等方面进行对比实验.在PC机上对VBSED算法生成的程序进行时空开销实验评估.使用的实验环境配置如下:CPU为Intel(R)Core(TM)i7-6700HQ,支持SSE3/AVX[26],2.6GHz.内存16G.操作系统Ubuntu16.04,基于LLVM7.1开发了基于SIMD向量化错误检测的程序转换工具.此外本文还基于同版本LLVM复现了EDDI算法,用于在同样环境作为与本文算法比较的对象. 测试程序本文选择MiBench[27]中QSORT、CRC、RAD2DEG、FFT 4个测试程序和深度学习中CONV2D、MatMul两个常见的算子,用这些程序来对比上述两个算法的时空开销和错误检测率. 1)时空开销对比 首先将上述6个测试程序分别经EDDI算法和本文的VBSED算法处理后生成具有错误检测功能的程序,此外生成一个未使用任何加固算法的程序(UnProtected,UP)作为对比基准程序.空间开销对比这些程序在硬盘上所占空间大小,时间开销对比这些程序平均运行时间.EDDI、VBSED、UP 3类程序的时空开销如图4所示.从实验结果中可以看出,现有的 图4 EDDI、VBSED、UP 3类程序时空开销对比Fig.4 Comparison of time and space cost EDDI算法在时间开销方面是UP程序的2.2~5.1倍,这一大部分原因是因为EDDI完全复制指令带来寄存器压力,从而产生大量的访存操作,导致时间开销增加.而本文提出的VBSED主要的时间开销来源于错误检查代码,这是一些比较指令和跳转指令,而跳转指令在x86体系结构中会影响指令流水线执行,不可避免地降低性能.其中QSORT是访存密集型程序,EDDI算法产生寄存器压力的弊端在此程序体现更加明显,从图4中可以看出EDDI算法在QSORT测试程序上时间开销是UP程序的5倍多,而本文算法通过向量化并行计算,有效的减少了时间开销.在空间开销方面,VBSED算法相较少于EDDI算法生成的程序空间大小,这是因为EDDI算法是复制原始程序指令产生冗余执行指令,而本文算法相较于EDDI算法是把原指令和冗余指令向量化成一条指令,减少了大量冗余指令.虽然VBSED会产生少量的向量与标量转换指令,但这些并不会带来显著的空间开销. 2)错误检测率对比 VBSED算法不仅降低了时空开销,还具有较高错误检测率.本文对Gem5仿真工具进行二次开发,实现仿真故障注入平台,具有对寄存器、缓存、内存等故障注入功能,对每一组对比实验进行3000次故障注入.本文将故障注入结果分为5类: a)CORRECT:程序运行结果正确; b)DETECTED:检错算法检测到错误; c)ERROR:操作系统检测到错误; d)SDC:未检测到的错误,程序正常运行结束,但结果输出错误; e)TimeOut:程序运行超时. 图5 寄存器故障注入实验结果Fig.5 Results of register fault injection 图5展示了EDDI算法和VBSED算法转换的程序对寄存器故障注入实验结果对比,包括通用寄存器和向量寄存器.由于EDDI算法无法检测在缓存和主存上发生的错误,这里不对其作实验评估.本文对VBSED算法转换的程序在缓存和主存上进行了故障注入实验,结果如图6所示. 图6 缓存和主存故障注入实验结果Fig.6 Results of cache and memory fault injection EDDI算法和VBSED算法都是在中间代码层次对进行程序转换,处于汇编代码的上层,因此无法细粒度地对所有机器指令进行转换处理.EDDI算法会添加大量冗余指令,这会带来寄存器分配压力问题,导致编译器在寄存器分配阶段引入较多的寄存器溢出代码,EDDI算法无法检测溢出代码地方发生的错误.而VBSED算法将原计算指令和冗余计算指令转换为向量指令,不会带来这样的问题.由图5中可以看出,VBSED算法的检测到的错误比EDDI算法平均高15.8%.VBSED算法的另一个优势是考虑了缓存和主存上错误.缓存存放了主存中一部分数据,是程序运行过程中某一时段用到的数据,对缓存中数据进行故障注入会比对主存故障注入更容易导致程序错误.实验结果中VBSED算法缓存错误检测率平均为98.39%,主存错误检测率平均为98.57%.综合以上实验结果,本文提出的算法对寄存器、缓存和主存上错误具有较高的检错率. 本文提出了一个基于SIMD向量化的数据流软错误检测算法,利用现代处理器SIMD能力来提高软错误检测的性能.本文还设计了数据和指令向量化规则,在中间代码层应用相应的向量化规则生成转换后的代码.最终生成的程序在时间开销方面相较于EDDI算法平均提升了1.8倍,在空间开销方面代码大小平均降低了1.25倍.最后通过仿真故障注入实验模拟寄存器、缓存、主存故障,验证了VBSED算法的有效性和错误检测能力.实验结果表明本文算法针对寄存器软错误检测率比EDDI算法平均提升了15.8%,缓存和主存错误检错率分别为98.39%和98.57%.3.3 数据与指令向量化规则设计
{VDarrj|Darrj=VEC_D_ARR(Darrj,K),Darri∈Dst}3.4 错误检测代码生成规则

3.5 错误检测代码生成规则

4 实验结果与分析
4.1 实验环境配置
4.2 实验结果分析



5 结 论
