多尺度上采样方法的轻量级图像超分辨率重建
2023-05-11曾胜强
蔡 靖,曾胜强
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引言
图像超分辨率重建是指将低分辨率图像重建为与之对应的高分辨率图像重建,在机器视觉和图像处理领域是非常重要的课题。超分辨率重建在医学成像[1]、视频监控和安全[2]等领域具有广泛的应用场景,除了能提高图像感知质量外,还有助于改善其他机器视觉任务[3]。然而,图像超分辨率任务是一个不适定问题,因为重建过程中会存在多张高分辨率图像对应一张低分辨率图像。因此,研究重建性能高、适应性强的超分辨率算法至关重要。
Harris[4]于1964 年提出超分辨率重建任务,目前主要的重建方法包括插值法、重构法和基于学习的方法。其中,传统的插值法包括近邻插值、双线性、双三次线性插值等方法是最早提出的超分辨率重建方法,此类方法利用临近像素值人为计算出某一位置的像素,虽然易于解释和实现,但由于仅基于图像自身的信息提高分辨率,实验结果存在明显的边缘效应,细节恢复效果较差;重构法可分为频域法[5]、空域法[6],此类方法需要预先配准图像,操作复杂、效率较低、计算量大且难以保证重建精度,处理复杂退化模型的能力有限;基于学习的方法主要包括基于样例学习、基于深度学习,基于样例学习的方法包括基于图像自相似性[7]、基于邻域嵌入[8]和基于稀疏表示的方法[9]。
本文研究方法属于基于深度学习的超分辨率算法。Dong 等[10]提出一个3 层卷积神经网络——超分辨率图像卷积网络(Convolutional Network for Image Super-Resolution,SRCNN),自此将深度学习引入图像超分辨率领域,但相较于深层网络拟合能力较弱,无法高效学习低分辨率图像到高分辨率图像的映射。为此,Dong 等[11]提出快速超分辨率图像卷积网络(Faster Super-Resolution Convolution Neural Network,FSRCNN)进一步提升重建效果。近年来,研究人员在拓展网络深度、宽度的基础上,极大提升了所提超分辨率算法的网络性能。Kim 等[12]提出深度卷积神经网络超深超分辨卷积神经网络(Very Deep Super-Resolution Convolution Neural Network,VDSR),将网络层数加深到至20 层,引入残差学习思想既有效解决了随着网络加深带来的梯度消失问题,又提升了模型拟合能力。受到递归学习启发,Kim 等[13]在VDSR 基础上提出深度递归卷积网络(Deeply-Recursive Convolutional Network,DRCN),取得了更优的重建效果。
深层网络虽然能提升网络性能,但会带来梯度消失问题。针对该问题,He 等[14]提出深度残差网络(Deep Residual Network,ResNet),通过融合浅层、深层信息有效解决了梯度方面的问题。Huang 等[15]提出密集连接网络(Densely Connected Convolutional Network,DenseNet)高度融合不同卷积层的特征。Tong 等[16]将DenseNet 融入超分辨率任务中提出SRDenseNet,取得了较好的效果。
上述网络模型在各通道对图像特征映射中均作出了相同处理,但在人类视觉环境中,图像在不同区域、通道中的重要性各不相同,注意力机制起源于人眼系统能筛选重要信息而忽略其他次要信息这一生物特性。Hu 等[17]考虑到不同通道间的交互作用,设计注意力机制SENet(Squeeze-and-Excitation Network),首次提出通道注意力机制,通过全局平均池化将每个输入通道压缩到一个通道描述符中,利用Sigmoid 函数产生每个通道的重要系数。Zhang 等[18]结合通道注意力机制与超分辨率提出残差通道注意 力网络(Residual Channel-attention Network,RCAN),显著提升了模型性能。Woo 等[19]提出注意力机制网络CBAM(Convolutional Block Attention Module),在通道注意力的基础上增加空间注意力机制。Zhao 等[20]首次提出像素注意力机制,相较于通道注意力与空间注意力,像素注意力机制能对所有像素分别分配权重,采用一个1×1的卷积核减少了网络参数引用。
近年来,多种深度神经网络[21]被引入以改善重建结果。然而,大量的参数和昂贵的计算成本限制了深度神经网络在实际中的应用,通常使用递归或参数共享策略来减少实验参数[22],但在减少参数的同时增加了网络深度或宽度,导致计算复杂度大幅增加。为此,部分研究者设计轻量且高效的网络结构,避免使用递归模型。例如,Hui等[23]提出一种信息蒸馏网络(Information Distillation Network,IDN),该网络明确地将提取的特征分为两部分,一部分保留,另一部分进一步处理,以获得良好的性能,但在各通道处理图像的特征映射方法相同,存在改进空间。
本文提出一种轻量级的网络,以更好地平衡模型性能与适用性,主要贡献为:①提出双分支特征提取模块。多尺度提取图像特征信息,结合注意力机制、残差和密集连接加强特征提取;②提出多尺度上采样重构模块。该模块相较于传统上采样方法能够具有更丰富的纹理细节,并且目前鲜有将注意力机制引入重构阶段的研究;③提出轻量级的图像超分辨率网络。实验证明,所提算法不仅保持了较低的参数量,还具有更高的重建效率与视觉效果。
1 像素注意力
通道注意力的目标是生成一维(C×1×1)注意力特征向量,空间注意力是生成二维(1×H×W)注意力特征图,而像素注意力(Pixel Attention,PA)可生成一个三维(C×H×W)注意力特征。其中,C 为通道数,H、W 为特征图的高和宽。如图1所示(彩图扫OSID 码可见,下同)。
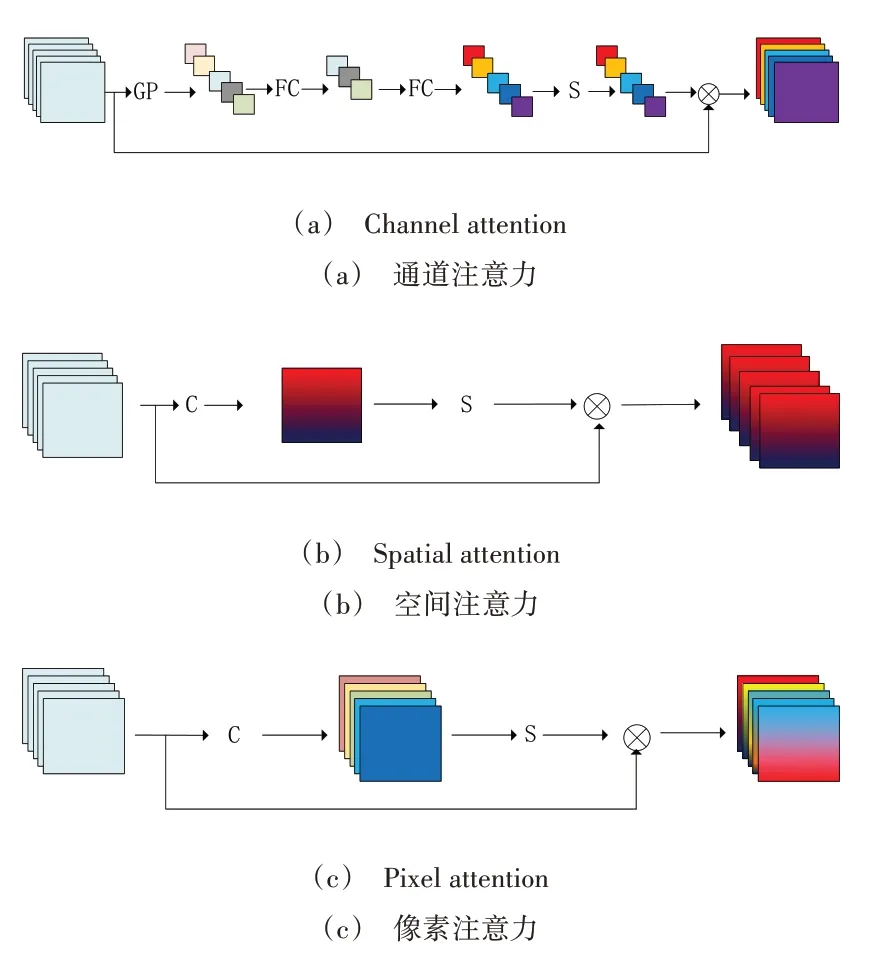
Fig.1 Comparison of attention mechanism图1 注意力机制比较
其中,GP 为Global Pooling,FC 为Fully Connected,C 为Convolution,S 为Sigmoid,像素注意力只使用1×1 的卷积核和Sigmoid 函数得到注意力权重,再与输入特征相乘,在引入少量参数的前提下,分别计算每个像素的权重。
将输入特征图定义为xm-1,输出特征图定义为xm,PA可表示为:
式中,fPA为1×1卷积加Sigmoid 运算。
2 网络结构
本文提出残差与像素注意力相结合的双分支卷积网络(Two-branch with Residual and Pixel-attention Convolutional Network,TRPCN),该网络主要由密集残差特征提取模块(Feature Extract with Residual and Dense Block,FERDB)与像素注意力上采样模块(Upsampling with Pixel-attention Block,UPAB)构成。
如图2 所示,输入的低分辨率图像首先由一个特征提取层FE(Feature Extraction)提取浅层特征;然后通过核心特征提取模块FERDB,该模块包括16 个双通道注意力残差块(Two-branch with Residual and Pixel-attention Block,TRPB),一层卷积核大小为1 的特征聚合层和两个3×3 的卷积层;最后由像素注意力机制和上采样层组成的上采样模块UPAB 进行处理输出高分辨率图像。
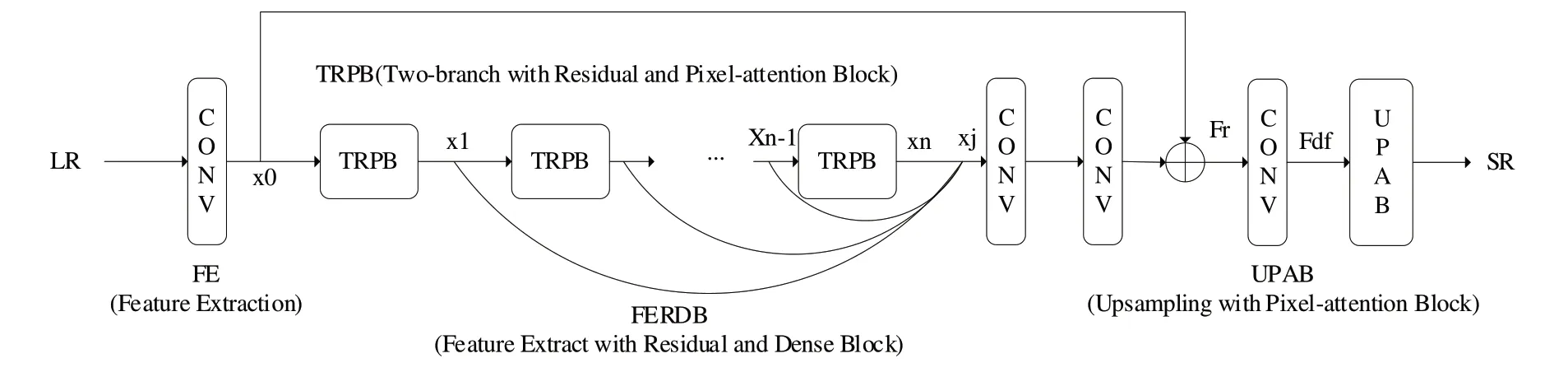
Fig.2 Network structure图2 网络结构
2.1 FE层
FE 层用来初步提取特征,为了降低模型参数量,仅由一个大小为3的卷积核组成。
式中,fconv3为3×3 卷积运算,ILR为输入的低分辨率图像特征。
2.2 FERDB模块
2.2.1 TRPB模块
FERDB 的内部核心特征提取模块为前段的16 个TRPB 块,如图3(a)所示。首先将特征分别经过两个1×1的卷积层输入特征提取分支,每个分支特征维度减半以降低参数;然后合并提取出的特征,由1×1 卷积层增加各通道特征的交互性,输出通道还原为输入特征通道数;最终通过跳跃连接将其与浅层特征进行融合,输出特征xn。
式中,x′n特征通道为像素注意力残差分支,由像素注意力与浅层残差块(Shallow Residual Block,SRB)组成,x"n特征通道为浅层残差分支。
SRB 的非线性变换如式(4)所示,组成结构如图3(b)所示。
式中,激活函数采用LReLU,fconv3表示卷积核大小为3的卷积运算。
2.2.2 FERDB整体模块
如图4 所示,TRBP 模块连接后段的特征聚合层组成FERDB 模块。特征聚合层通过聚合浅层特征与核心TRBP模块提取的特征,通过非线性变换输出深度特征Fdf。

Fig.3 TRPB and SRB structure 图3 TRPB和SRB结构

Fig.4 FERDB structure图4 FERDB结构
式中,Fr为将浅层特征与密集特征进行残差聚合的深度特征。
2.3 UPAB上采样模块
如图5 所示,输入特征分别由一条单上采样分支与一条基于PA 的上采样分支进行提取,融合后输出最终图像。本文所提方法相较于目前使用的单通道上采样而言,能提取特征的深度与空间信息,像素注意力分支使输出图像纹理信息更丰富,单上采样分支也保留了图像的边缘信息。
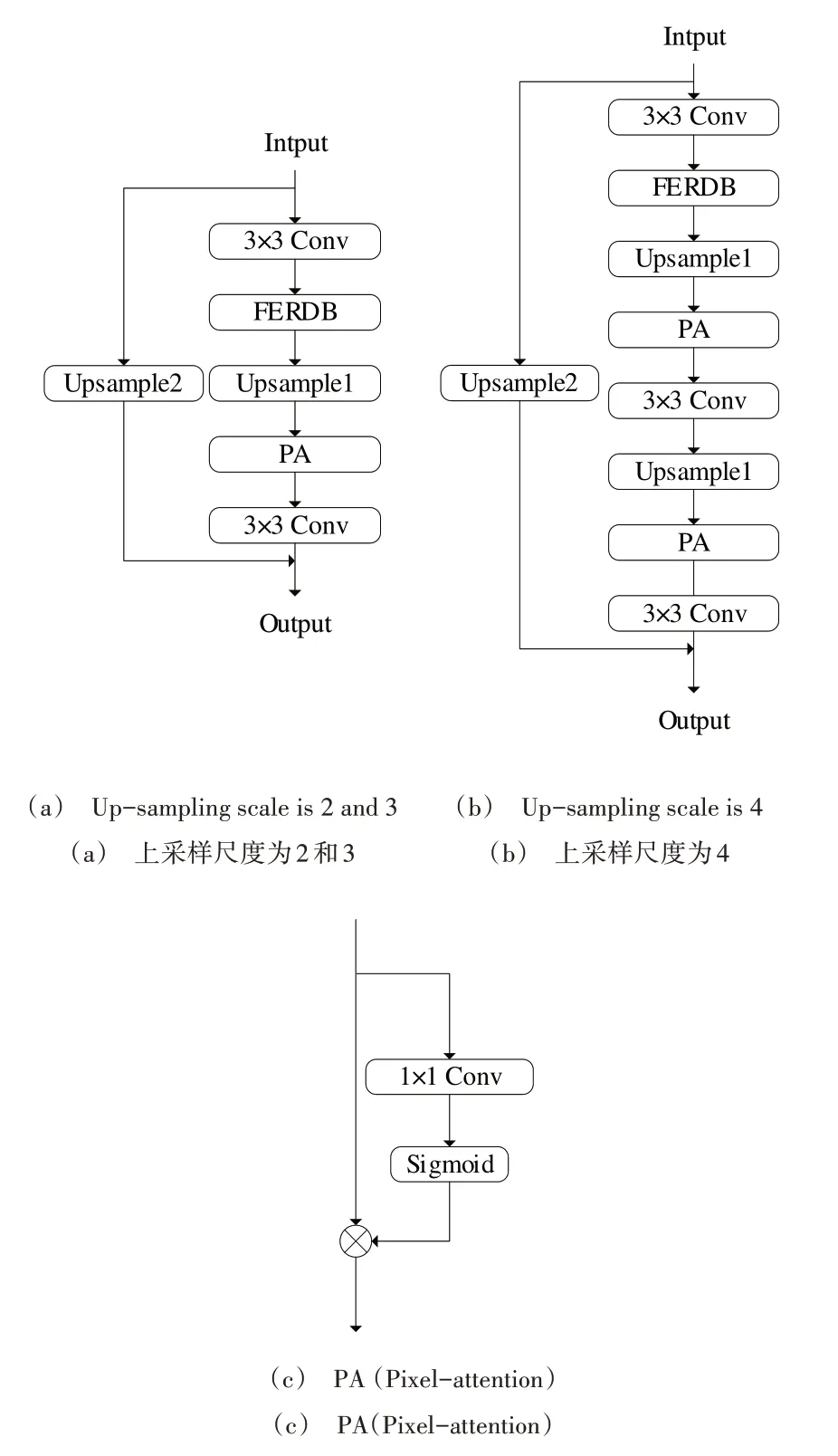
Fig.5 Structure of upsampling module图5 上采样模块结构
当上采样尺度为2 或3 时,仅进行图5(a)所示一次上采样;当上采样尺度为4 时,进行图5(b)所示两次尺度为2 的上采样。其中,Upsample1 为亚像素卷积上采样;为降低参数量,Upsample2 采用邻域插值上采样。
3 实验结果与分析
3.1 数据集和评价指标
本文将DIV2K 作为训练数据集,DIV2K 由1 000 张2K分辨率图片构成,以8∶2 的比例划分训练集与验证集。为提高训练速度和样本数量,将每副图像进行交叉划分,每隔一段像素截取一张480×480 的小图像,最终得到超过三千张可供训练和验证的小图像。训练时再随机水平翻转和90°旋转图像进行数据增强。
测试阶 段,采 用Set5[24]、Set14[25]、B100[26]、Urban100[27]作为测试集。评价指标采用峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性(Structure Similarity Index,SSIM),均在Y 通道进行测试。
(1)峰值信噪比。其是信号的最大功率和噪声功率之比。
式中,MSE 为重建图像和高清图像间的均方误差,H、W表示图像尺寸。一般PSNR 指标越高重建效果越好。
(2)SSIM。其是衡量两幅图像相似度的指标,取值范围为[0,1],SSIM 值越大表示图像失真程度越小,图像质量越高,给定两张图像x、y,SSIM 计算公式如式(10)所示。
3.2 训练细节与损失函数
3.2.1 训练细节
实验硬件平台为Intel(R)Core(TM)i7-9800X CPU,NVIDIA RTX2080,操作系统为Linux,采用CUDA11.5 加速训练。训练时,Batchsize=32,优化器选用Adam,初始学习率设为10-3,迭代周期为250K 次,最低学习率为10-7,总迭代1 000K 次。
3.2.2 损失函数
算法采用L1 损失,通过损失函数计算重建图像与高分辨率图像间的像素误差。
式中,h、w、c分别表示高、宽、特征通道数,I^为重建图像,I为高分辨率图像。
3.3 实验结果
实验在4 个公开数据集上分别测试比较了放大两倍、3 倍和4 倍的重建性能,如表1 所示。由此可见,本文所提模型参数量最多不到370K,但性能优于大多数最先进方法。具体而言,CARN 与本文模型具有相似的性能,但参数接近1 592K,大约为本文模型的4 倍;IMDN 为AIM2019 超分挑战赛排名第一的算法,仍具有715K 的参数量。除了比较PSNR、SSIM 指标外,本文还对以上部分算法进行了视觉效果比较,如图6-图10所示。
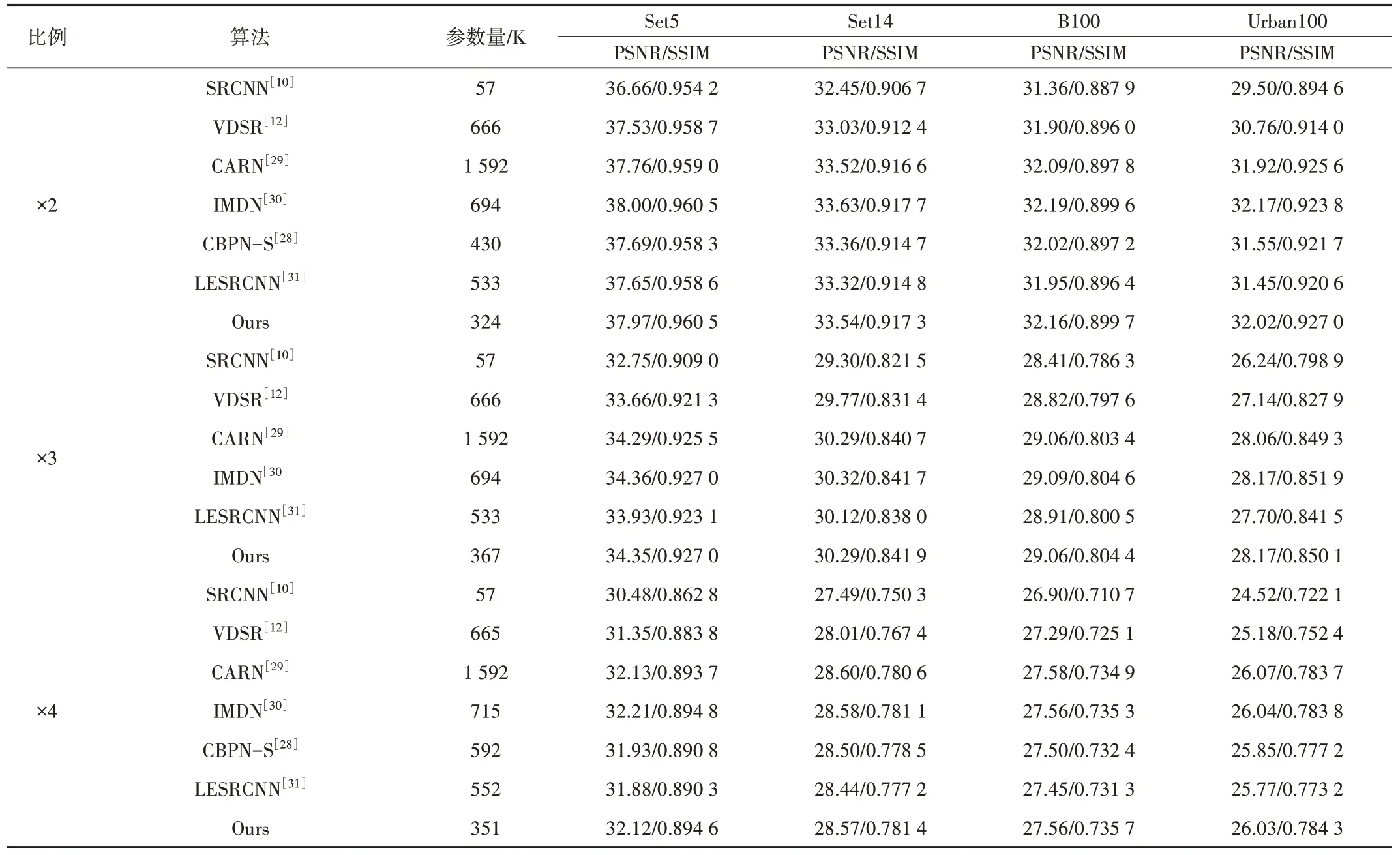
Table 1 PSNR and SSIM index comparison表1 PSNR和SSIM指标对比
图6 从左至右分别为Set5、Set14、B100、Urban100 中选取的高分辨率图像,分别截取图中一部分作为HR 图片,然后通过Bicubic 算法进行4 倍下采样后才作为测试图片。图7-图10 从左至右分别为截取的原始HR 图片、SRCNN、VDSR、CBPN-S、LESRCNN、IMDN、CARN 和本文所提算法处理后的图片。由此可见,本文所提算法重建的图像更好地还原了纹理,相较于其他算法避免了细节处的平滑处理,与原图更接近。综上,TRPCN算法在性能和模型复杂度方面取得了更好的权衡。

Fig.6 Original images of Set5,Set14,B100 and Urban100 dataset图6 Set5、Set14、B100、Urban100原图
3.4 复杂度分析
本文通过参数量、计算量这两个指标分析所提算法的轻量性。在重建尺度为4 时,分别比较DSR、DRCN、CBPN-S、LESRCNN 这4 个网络,如表2 所示。由此可见,本文算法在参数量、计算量上均为最优。

Fig.7 Comparison of reconstruction effect at scale 4 from Set5图7 Set5重建尺度为4的效果比较
3.5 消融实验
为验证上采样方法的有效性,本文对图5 中其他上采样组合进行比较试验,实验均在Set5 验证集上进行4 倍上采样验证,结果如表3所示。
方案1:关闭Upsample2 通道,Upsample1 采用亚像素卷积上采样。
方 案2:Upsample1、Upsample2 均采用 邻域插值上采样。
方案3:Upsample1、Upsample2 均采用亚像素卷积上采样。

Fig.8 Comparison of reconstruction effect at scale 4 from Set14图8 Set14重建尺度为4的效果比较

Fig.9 Comparison of reconstruction effect at scale 4 from B100图9 B100重建尺度为4的效果比较

Fig.10 Comparison of reconstruction effect at scale 4 from Urban100图10 Urban100重建尺度为4的效果比较

Table 2 Model complexity comparison表2 模型复杂度比较
方案4:Upsample2 采用邻域插值上采样,Upsample1 采用亚像素卷积上采样。

Table 3 Ablation experiment表3 消融实验
由表3 可见,相较于方案2、3、4,方案1 只使用了单一的亚像素卷积上采样,虽然参数量较少,但PSNR 不高。虽然同样融入了PA,但方案3 的亚像素卷积上采样相较于方案2 的插值上采样拥有更高的评价指标,可见深度学习方法使输出特征加入了更多非线性变换,最终输出图像的信息更丰富。方案4 同时采用亚像素卷积和插值上采样,并在亚像素卷积分支融入PA,不仅使输出特征加入了更多非线性变换,还丰富了输出图像的纹理细节,进一步加强了输出图像的结构特征,使输出图像具有更好的视觉效果。
4 结语
本文提出一种轻量级的卷积神经网络实现图像超分辨率重建任务,不同于堆砌神经网络深度或宽度来提升算法性能,通过合理利用卷积与注意力机制,设计多通道特征提取块,在降低参数量的同时,保证了模型的重建效果。
此外,多尺度的上采样重构模块加强了生成图像的纹理细节,使其更接近于真实图像。实验表明,本文所提模型能实现与最先进的超分辨率网络相当的性能。
