面向税收条例的知识图谱构建方法
2023-05-11邹安琪陈艳平
邹安琪,陈艳平
(贵州大学 计算机科学与技术学院,贵州 贵阳 550025)
0 引言
随着人工智能、云计算和大数据等新兴技术不断发展,税务作为国家经济的重要组成部分,面临着税务改革和现代化建设等时代任务,因此,智慧税务应运而生。在实际税收征管中,首先需要专家对国家颁布的条例进行解读并制定规则,然后再由计算机工作人员将规则编写成代码进行税收计算。该模式依赖人工,无法实现智慧税务中的“智慧”,税务领域迫切需要一种能够自动抽取并表示税收条例所蕴含规则和知识的方法。由于知识图谱结合了高效的深度学习方法,是决策支持、语义搜索、智能问答等智能服务的基础技术[1],因而能够为上述问题提供优秀的解决方案:通过知识图谱构建可以自动表征和抽取税收条例中的规则及知识,并使用知识图谱“解读”税收条例。
本文结合自然语言处理技术,研究面向税收条例的税法知识表示模型和税法知识抽取方法,构建面向税收条例的税法知识图谱。根据征收条例内在知识结构特征和逻辑关系,对税收条例所蕴含的知识进行建模。同时,对税务条例知识抽取数据集进行标注,设计实现针对税务知识要素的抽取算法,提出针对税法知识图谱的自动构建框架。
1 相关工作
知识图谱始于20 世纪50 年代,可分为3 个发展阶段[2]:第一阶段(1955-1977 年)是知识图谱起源阶段,引文网络分析方法被用于研究现代科学发展脉络;第二阶段(1977-2012 年)是知识图谱发展阶段,语义网得到快速发展,“知识本体”的研究开始成为计算机科学重要领域;第三阶段(2012 年至今)是知识图谱发展的繁荣阶段,2012年谷歌提出Google Knowledge Graph[3],知识图谱正式得名。知识图谱一经提出便引起学术界和工业界广泛关注,并成功应用于医疗、金融、公安、教育、社交网络、电商等领域,可将其分为通用领域知识图谱和垂直领域知识图谱。
在通用领域,国外对于知识图谱的研究早于国内,最具代表性的大规模通用领域知识图谱包括YAGO[4]、DBpedia[5]、Wikidata[6]、Probase[7]、ConceptNet[8]等。国内工业界和学术界也对通用领域知识图谱展开了一系列研究,工业界如百度“知心”、搜狗“知立方”,学术界如THUOCL、大词林、zhishi.me、CN-Probase 等。
在垂直领域,学术界也掀起了知识图谱相关技术研究高潮,胡芳槐[9]以互联网上各类结构化、半结构化数据为基础,提出基于多种数据源的知识图谱构建方法,构建包含数千万事实知识的中文知识图谱。李文鹏等[10]针对4种不同类型的软件资源,基于软件知识实体提取原则,提出软件知识图谱构建方法,包括软件知识实体抽取、关系关联和知识查询,并基于此实现了面向开源软件项目的软件知识图谱构建工具,提高了软件复用性,有助于软件开发人员对软件知识进行检索与应用。杨玉基等[11]对领域知识图谱构建进行系统研究,提出领域知识图谱快速构建方法,并使用该方法以中国基础教育的九门学科为原始数据构建了包含67 万个实体及1 412 万条事实的中文学科知识图谱。张元博[12]构建了一种半监督的知识挖掘方法,依据挖掘的医疗信息构建医疗领域知识图谱,针对医疗数据中结构化知识缺失问题,提出使用Bootstrapping 算法和条件随机场对元数据进行抽取。王剑辉等[13]通过分析知网收录的国内空中交通管理资料,利用知识图谱对空中交通管理知识进行可视化。Arenas 等[14]运用DBpedia 数据集中IT 领域数据资源间的关系,使用建立关联图的方法构建知识图谱,实现了IT 资源实体语义查询。Karidi 等[15]基于知识图谱和图计算提出在Twitter 中关注主题推荐算法,实现了知识图谱在社交网络中的应用研究。洪文兴等[16]基于中文预训练语言模型,对知识图谱构建过程中的信息抽取算法进行研究,其中包括命名实体识别和关系抽取,并以此实现了司法案件案情知识图谱自动构建。
目前,知识图谱在司法、生物医疗、金融风控和电子商务等特定领域有着广泛应用,但在涉税领域方面鲜有研究。税务领域作为国家经济重要组成部分,税务智能化建设与每个人息息相关,构建基于智慧税务的知识图谱迫在眉睫。
2 税收条例知识建模
在构建税收条例知识图谱前,需对构建图谱的原始数据进行分析,得到知识图谱建模数据形态,并说明知识图谱要素的知识类型,定义知识图谱结构模型。
2.1 税收条例知识子图
对税收条例进行人工分析并与税务领域专家进行讨论,发现税收条例文本词汇专业性强、可读性差,具有语言表达规范、语义明确、知识较为结构化、逻辑性强等特点。
传统知识图谱只对涉及到的实体类型和关系类型进行预定义,这种建模方式无法完全将税收条例中蕴含的语义内涵和知识结构表示出来,但税收条例存在明显语义结构,为此提出税收条例知识子图建模具体涉税措施,通常将一个税收条例转化为一个子图,如图1所示。
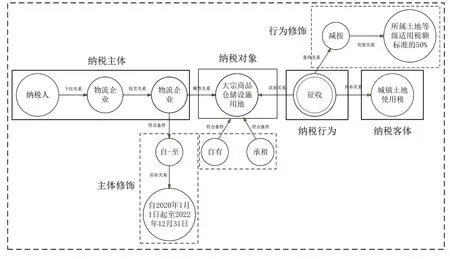
Fig.1 Tax regulations knowledge subgraph图1 税收条例知识子图
2.2 税收条例知识要素
税收条例知识子图是以纳税人为根节点、具体涉税措施为终结点的有向无环图。其内部结构鲜明,包含9 种知识要素和5种要素关系,知识要素如表1所示。
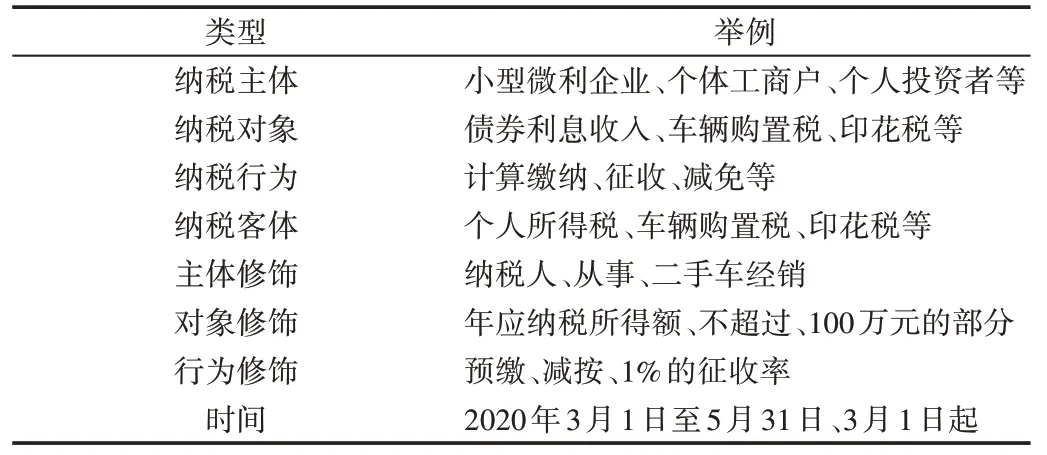
Table 1 Types of knowledge elements of tax regulations表1 税收条例知识要素类型
税收条例知识子图包含纳税主体、纳税对象、纳税行为、纳税客体、主体修饰、行为修饰、对象修饰及时间。其中,修饰要素通常是对主体、对象、行为进行修饰限定,例如表1 中的“二手车经销”与“从事”结合起来对纳税主体“纳税人”进行修饰。修饰要素用于对纳税主体、纳税对象及纳税行为进行限定,对条例逻辑和知识结构更好地进行刻画。时间用于对条例有效日期作出描述。除知识要素外,根据知识表示方法定义的6种关系如表2所示。

Table 2 Six relationships defined according to the knowledge representation method表2 根据知识表示方法定义的6种关系
2.3 税收条例知识图谱及操作
税收条例知识图谱以纳税人源节点为中心节点,由税收条例知识子图构成知识图谱。该知识图谱并非子图的简单拼接,向图谱中添加子图时,需判断待添加税法分面树和已有税法分面树间的语义关系。为此,定义基于知识图谱的操作如下:
(1)查询子图。查询符合条件的知识子图,判断其是否存在。查询操作是其他操作的基础,是分面树进行添加、更新、删除等操作的前提条件。
(2)添加子图。添加某一子图,添加前应先判断该分面树是否已存在,添加后,知识图谱中会新增一个子图。
(3)更新子图。若添加子图前发现该子图已存在,则更新分面树。更新操作可能存在合并、拆分子图的情况。
(4)删除子图。对知识图谱中符合条件的知识子图执行删除操作,查询当前知识图谱,若存在同待删知识子图语义相同的子图,则执行删除操作。
3 基于BERT的税收条例要素抽取
税收条例知识要素抽取采用命名实体识别方法,对句子中每个字预测一个分类标签,从而判断该字在要素中的语义角色。在B-I-O 编码中,B(Beginning)表示该字对应一个要素的开始,I(Inside)表示要素的后续,O(Outside)表示不属于该要素。为保证建模标签间的语义依赖关系,现有要素识别方法主要采用序列标注模型输出一条最大化标注路径,从而建立句子中知识要素间的语义依赖信息。
传统基于Word2vec 的序列标注模型无法表征上下文关系,一个词只包含一个词向量。本文在BiLSTM-CRF 模型基础上,引入基于BERT 的预训练语言模型,构建BERT-BiLSTM-CRF 税收条例要素抽取模型,结构如图2所示。
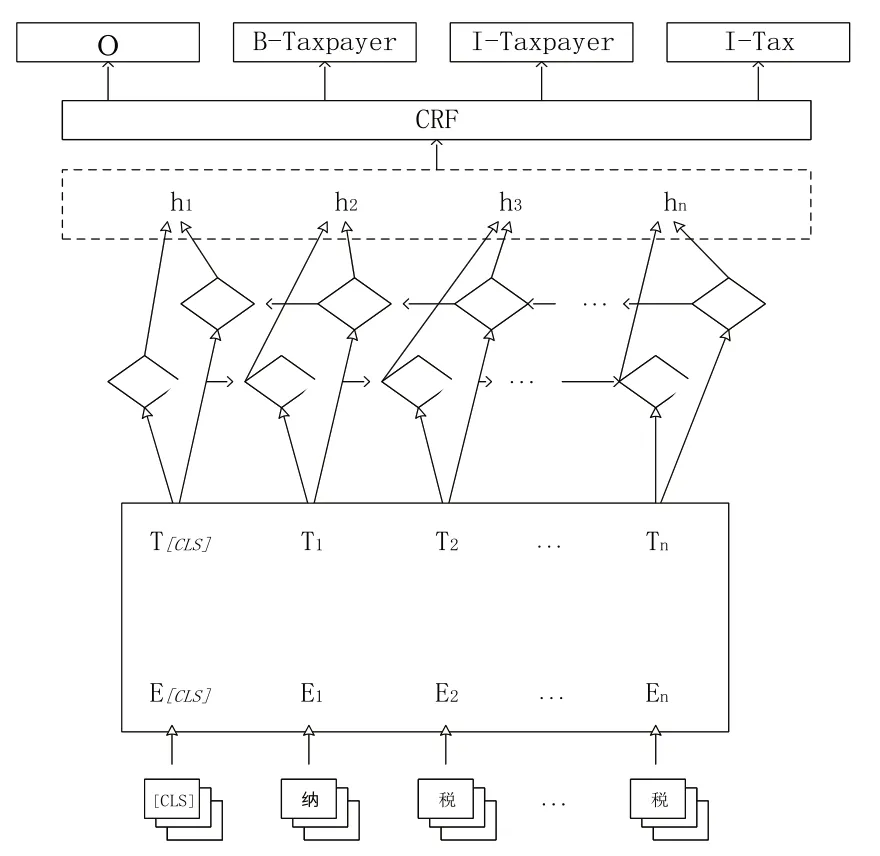
Fig.2 Element extraction model of tax regulations based on BERT图2 基于BERT的税收条例要素抽取模型
模型整体可划分为三大网络层:第一层是嵌入层,利用BERT 预训练语言模型对句子进行嵌入生成融合上下文语义信息的字符向量表示;第二层是BiLSTM 层,对BERT输出的字符向量表示进行编码及解码,有效获取字符序列的长距离依赖;第三层是CRF 层,对上层输出解码,学习标签间约束关系并输出最大化标注序列。
3.1 嵌入层
BERT 模型在嵌入层对输入的条例依次进行词嵌入、段落嵌入和位置信息嵌入[17]。词嵌入对输入的文本进行分词处理,将每一个token 转换为固定维度的向量表示;段落嵌入是用[CLS]和[SEP]特殊符号分割句子中的token,并以0/1 下标做区分进行嵌入。由于BERT 可以处理长度为512 的句子,故以0-512 区分每个字的位置,以此学习每个位置的向量表示,得到包含输入序列顺序特征的位置嵌入。3 种嵌入表示叠加输入后,BERT 采用Transformer 对输出向量进行特征提取。给定条例1 的文本输入为{w1,w2,w3,...,wn},经过BERT 嵌入层得到带有上下文语义信息的向量表示为{x1,x2,x3,...,xn},其中n代表句子长度。
3.2 BiLSTM 层
BiLSTM 指双向长短记忆神经网络,在解决长距离序列依赖方面较为优秀,并解决了LSTM 只能获取单向语义信息的问题,LSTM 单元通过门控机制以控制信息取舍。
每个LSTM 单元中包含输入门it、输出门ot和遗忘门ft,BERT 嵌入得到字符分布式表示为x={x1,x2,x3,...,xn},t 时刻的输入包括xt与ht-1,ct和ct-1表示记忆单元,ct-1通过遗忘门摒弃部分历史信息,结合输入门新加入的信息得到ct,利用输出门计算得到当前时刻ht,其计算过程如式(1)。
3.3 CRF层
CRF 作为解码层,用于学习标签间的约束关系,解决标签不合理问题。BiLSTM 的输出将句子表示映射到与句子字符对应的标签概率矩阵P,其中Pij表示句中第i个字符对应标签是j的概率,而CRF 主要是学习标签间的转移矩阵A,其中Ai,j表示i标签后接j标签的概率。
对于经过BiSLTM 特征抽取后得到的隐状态输出H(h1,h2,...,hn),其对应标签序列为Y(y1,y2,...,yn),得分函数可定义为式(3)。
其中,S表示全部句子集合,Hs表示句子s经过BERT和BiLSTM 的隐状态输出,Ys表示句子s对应的预测标签序列。
4 实验及结果分析
4.1 数据集
为构建税务征收条例知识图谱,本文选用国家税务总局和各地税务局官网政策库自1984 年以来发布的各项税务征收条例作为数据集。采用BIO 格式对税收条例知识建模方法提及的要素进行标注,最终得到Tax 数据集。以8∶1∶1 的比例对数据集进行划分得到训练集、验证集和测试集。税收条例知识要素类型和数据统计信息如表3所示。
为证明本文模型的可扩展性,除在本文标注的Tax 数据集上开展实验外,还选取了两个中文基准数据集MSRA和Weibo[18]进行实验,数据集统计信息如表4所示。
4.2 实验设置与评价指标
本实验基于Tensorflow 深度学习框架,在Linux 系统下的Nvidia Tesla P40 平台上进行模型训练。主要参数包括:最大句子长度为300,batch_size 为64,学习率为0.000 5,优化器采用Adam[18],drop_out 为0.5;为缓解梯度消失和爆炸的影响,LSTM 隐含单元设为128,层数为2;经过预训练模型对比实验后,选取更加适用于本文抽取任务的RoBER-Ta-wwm-ext[19]模型,该模型包含了包含12 个Transformer,预训练词向量维度为768。本文采用P 值、R 值和F1值作为评价指标,F1值使用微平均计算,具体计算公式如式(6)。
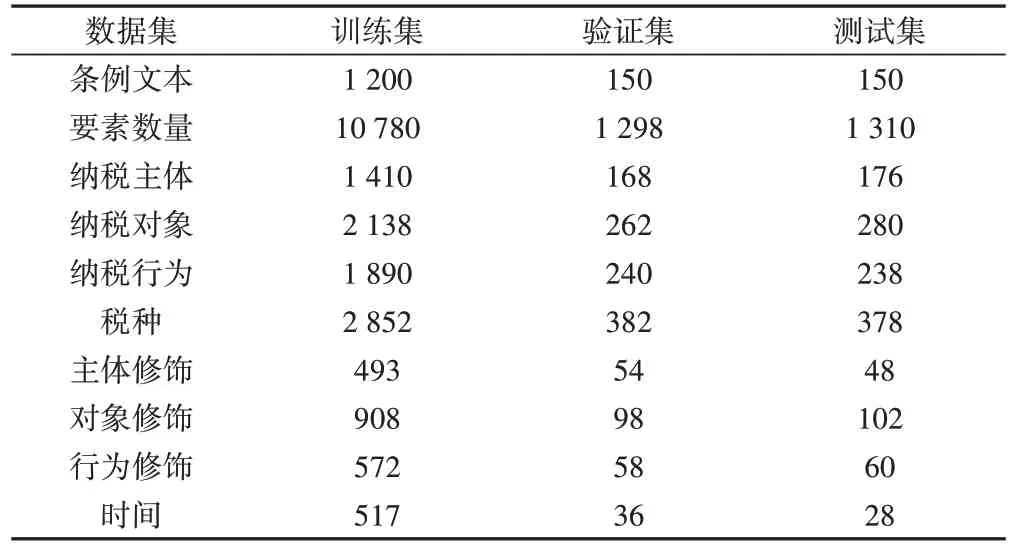
Table 3 Statistics of element number of Tax dataset表3 Tax数据集要素数量统计
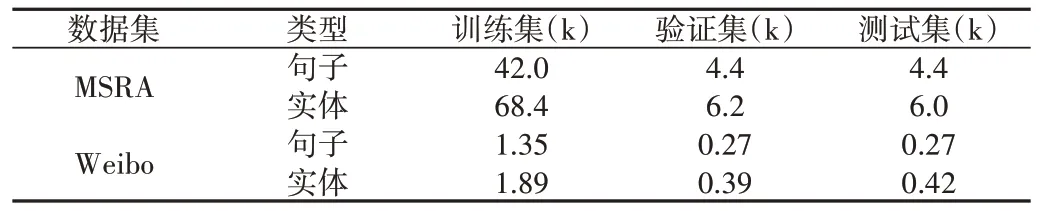
Table 4 Statistical of universal datasets表4 通用数据集统计
其中,TP 表示预测要素是正确识别的个数;FP 表示预测要素是错误识别的个数;FN 表示标准标注要素被错误识别的个数。
4.3 实验结果与分析
为证明本模型性能,采用BiLSTM-CRF、BERT-CRF 这两种模型作为对比模型。具体实验性能如表5所示。
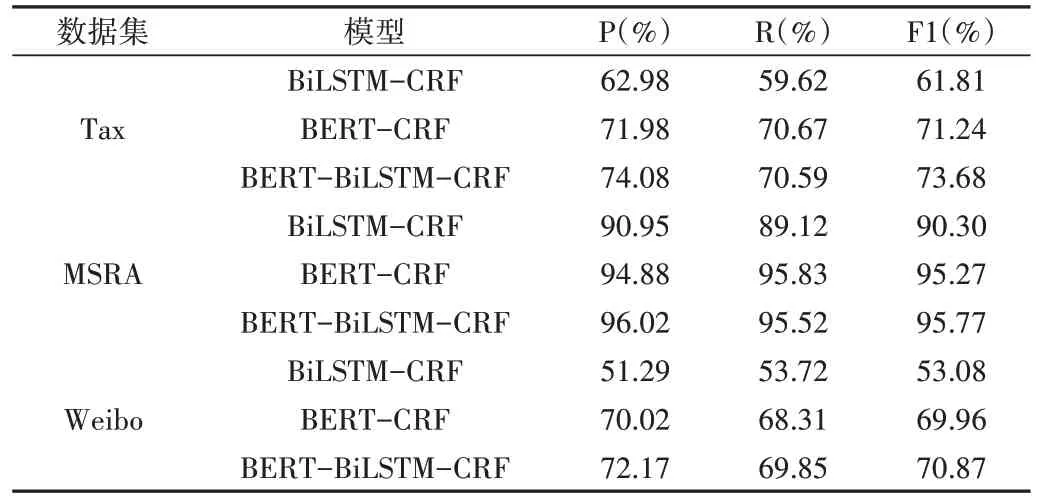
Table 5 Knowledge element extraction model performance表5 知识要素抽取模型性能
将本文模型与序列标注经典基线模型BiLSTM+CRF进行对比,3 个指标均大幅提升,准确率提升10.03%,召回率提升11.47%,F1 值提升11.15%。说明在税务领域,BERT 预训练模型词向量较于传统Word2vec 模型训练的静态词向量在表达字的语义信息和有效提取上下文特征方面表现更佳,证实了本文模型在税务领域要素抽取任务上可行。
将BERT+BiLSTM+CRF 模型与BERT+CRF 模型进行对比,两个模型间的区别在于BiLSTM 层,从结果上看召回率降低了,但准确率提高2.1%,F1 值提高2.44%,证明BiLSTM 在获取句子的长距离语义依赖方面具有一定优势。
在通用数据集MRSA 上实体类型少,识别较为容易,3个模型F1值均达到90%以上,BERT-BiLSTM-CRF 模型相较于BiLSTM-CRF 模型各项指标均提高5%以上,但与BERT-CRF 模型相比,性能提升不大。在更具挑战性的数据集Weibo 中,本文模型各项指标较基线模型BiLSTM 提升17%以上,在BERT-CRF 模型上的提升比MSRA 数据集更大,表明本文方法具有一定扩展性。
为验证各种中文预训练语言模型性能,在本文模型结构下选取BERT-base[17]、BERT-wwm[19]、Roformer[20]、Ro-BERTa-wwm-ext[19]等BERT 模型进行对比实验,实验性能如表6所示。
BERT 系列模型明显优于Roformer,表明BERT 系列模型更适用于本文抽取任务。BERT-wwm 作为BERT 升级版,引入了全词MASK,实验表明,模型在准确率(P)和召回率(R)上略优于BERT-base,F1指标性能几乎接近。
由于RoBERTa-wwm-ext 训练数据量大和特殊设计的MASK 方式,各项指标均明显优于其他对比预训练模型。
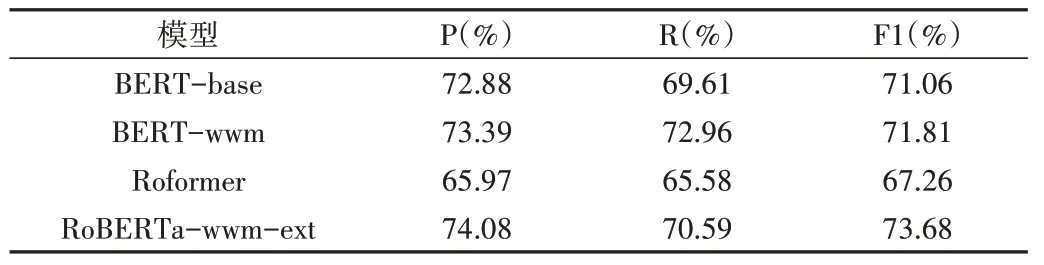
Table 6 Pre-training model extraction performance表6 预训练模型抽取性能
5 税收条例知识图谱自动构建
本文基于上述税收要素抽取模型,实现了面向税收条例的知识图谱自动构建,构建流程如下:
(1)知识要素抽取。给定一条税务条文,采用基于BERT 的税收条例要素抽取模型对税务征收条例进行要素识别,得到知识要素数据列表List1。
(2)结构组合。由于税法分面树的各部分组成词较为固定,将要素按<纳税主体-主体修饰>、<纳税主体-纳税对象>、<纳税对象-对象修饰>、<税种-纳税对象>、<纳税行为-行为修饰><纳税行为-税种>进行组合得到数据列表List2。
对List2中的各类二元组组合,利用表2 中的预定义关系类型进行关系拼接,形成最后的关系数据列表List3。此列表包含:要素1 及其要素类别、要素2 及其要素类别,从而得到三元组,对三元组进行拼接得到税收条例知识子图。
(3)税收条例知识图谱构建。利用子图中的纳税人源节点进行融合得到知识图谱。子图融合之前进行定义的查询子图操作,利用文本匹配方法在条例库中进行匹配,若有冲突则执行子图更新操作,更新知识图谱中的知识子图;若无冲突则进行添加子图操作。通过上述操作融合知识子图得到知识图谱。
(4)可视化展示。将获取的知识图谱以数据形式进行结构化存储,利用Echarts 结合Vue.js 开发的知识图谱可视化工具,以导向图形式对税收条例知识进行可视化展示,如图3所示。
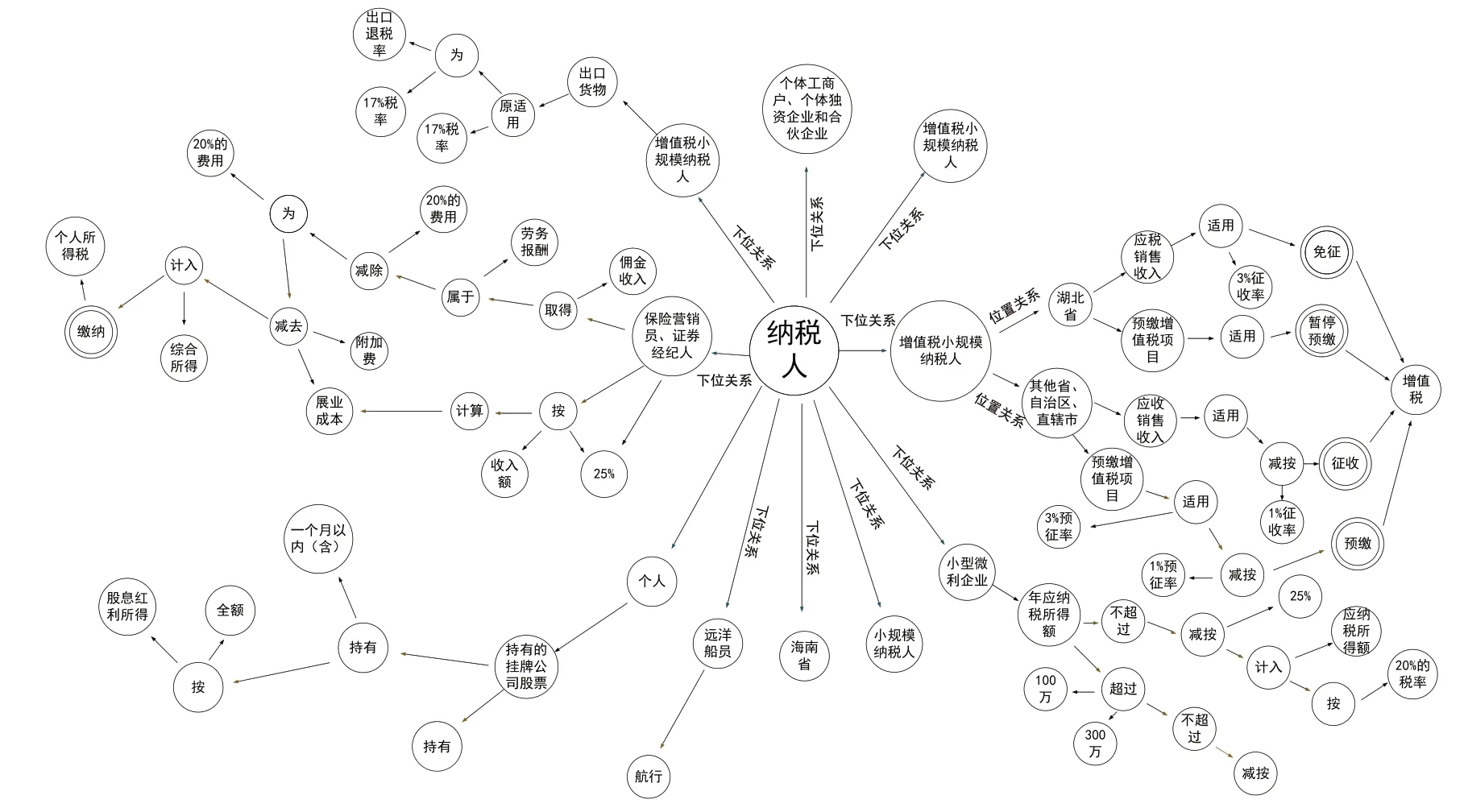
Fig.3 Visual display of tax regulations knowledge graph图3 税收条例知识图谱可视化展示
6 结语
本文面向税务征收条例数据研究知识图谱构建方法,针对知识图谱构建需求,提出面向税收条例的知识建模方法,准确且适当地表示了税收条例中蕴含的知识。同时,针对税收条例的数据特点,设计基于BERT 的税收条例知识要素抽取模型,在本文标注的Tax 数据集上展现出其优秀性能,并通过对比实验选取适合本文任务的中文预训练语言模型。在通用数据集上进行实验也展现了较好性能,证明该模型适用于税务知识抽取任务,且在通用领域具有一定扩展性。最后,基于知识要素抽取模型,提出了知识图谱自动构建流程,实现了面向税收条例知识图谱的构建。
为构建质量更高的知识图谱,后续研究将收集更多税收条例数据进行人工标注,增加数据量以提升知识要素抽取性能。知识建模中要素分类粒度较粗,并不能完全涵盖所有领域知识概念,后续将继续补充相关领域知识,完善知识建模方法。
