基于异构关系分布的学术网络相似性搜索
2023-05-11张明西王金华
乔 田,张明西,王金华,周 飞,刘 洲,罗 睿,吴 玉
(1.上海理工大学 出版印刷与艺术设计学院,上海 200093;2.中国电子科技集团公司第三十二研究所,上海 201808;3.江苏国信靖江发电有限公司,江苏 泰州 214513;4.中国人民解放军军事科学院,北京 200023)
0 引言
近年来,基于学术网络的相似性搜索已经在学术搜索、合作关系预测等领域引起广泛关注。学术网络中的相似性搜索旨在从海量的学术数据中发现相似的对象。相似性搜索的关键是有效的相似性度量,在学术网络中,相似性度量侧重于评估同一类型对象间的相似性,例如学术网络中与给定作者相似的作者或与给定论文相似的论文。在数据化时代,学术网络逐渐呈现大规模化和复杂化,增加了相似性度量的难度。如何快速、有效地实现多数据源对象匹配,帮助用户从大规模数据中识别出其感兴趣的内容具有重要的研究意义。
目前,相似性度量方法主要分为两类:基于内容的相似性度量和基于链接的相似性度量。与基于内容的相似性度量相比,基于链接的相似性度量更加符合人类的直观判断。当前已有大量工作利用网络的全局结构信息计算节点间的相似性,例如RWR[1]、P-Rank[2]、SimRank[3]等。这些方法通常采用随机游走算法进行迭代计算,尽管能够得到理想的结果,但是时间和空间复杂度较高。大量工作提出优化技术[4-8]以减少计算开销,但其主要针对同构网络。本文研究了学术网络中的top-k相似性计算,旨在进行相似性计算时考虑节点间的异构关系,并有效降低相似性计算的时间和空间成本。
1 相关工作
相似性度量评估了网络中对象间的相似度,是许多数据挖掘任务的基础。同质网络中的对象间相似度已被广泛研究。SimRank[3]是一种典型的相似度计算算法,基于“相似的节点被相似节点引用”的思想,利用网络上下文结构迭代计算相似度。SimRank 在近期引起了广泛关注,并出现了一系列变种,包括P-Rank[2]、C-Rank[9]、RG-Sim-Rank[10]等。其中,P-Rank 和C-Rank 考虑了不同方向链接关系对相似度的贡献,RG-SimRank 通过构建随机游走图整合任意方向和任意步长的相遇概率。针对SimRank 的效率问题,研究者提出一些优化方法用于快速计算。Top-Sim 从top-k搜索角度优化SimRank,其枚举了所有随机路径,以避免在SimRank 计算时访问整张图,适用于大规模图[4];ProbeSim 算法根据反向游走计算SimRank[11];CrashSim 在ProbeSim 算法基础上计算图中所有顶点与查询顶点的top-k结果集[12]。然而,这些方法针对的是同构信息网络,没有考虑多类型链接关系。
近年来异构网络中的相似性搜索得到了广泛关注。PathSim[13]首次提出元路径的概念,通过特定元路径的对称路径实例度量相同类型对象的相似度。许多学者提出基于元路径的方法,包括HeteSim[14]、AvgSim[15]、RelSim[16]等。HeteSim 通过元路径实例度量相同或不相同类型对象之间的相似度;AvgSim 改进了HeteSim 算法,该算法通过沿着给定元路径和反向元路径的两个随机游走过程评估相似度值;RelSim 基于元路径,根据用户提供的简单关系实例测量异构网络中关系实例之间的相似度。基于用户定义元路径的方法依赖于网络模式,缺乏通用性。Net-Sim[17]和SimCC[18]仅处理x-star 模式的网络,但当网络变得多样化时并不适用。SimFusion 通过统一关系矩阵(URM)表示不同类型的关系,并通过URM 迭代计算对象间的相似度[19]。SimFusion+解决了SimFusion 的发散问题[20]。SimFusion 和SimFusion+只考虑当前路径长度的相遇,不能完全整合多类型关系。HeteRank 提出的通用关系矩阵(General Relationship Matrix,GRM)利用节点间的相遇整合所有关系类型[21]。
针对上述大多数相似度计算方法存在的各种问题,本文提出一种基于链接的相似性度量方法。首先,由于学术异构网络中不同类型对象的数据规模存在差异,节点间的关联路径由多种类型链接关系组成,利用全局异构关系的分布规模统计分析得到关系特征矩阵。然后,基于关系特征矩阵扩展传统的top-k相似性计算方法TopSim,使其适用于大规模异构网络[4]。同时,通过阈值筛选策略[22]加速查询过程,返回最相似的k个节点。
2 基于链接的相似性度量算法
2.1 符号与问题定义
学术网络中对象与关系构成了不同类型的链接,可被视为异构网络。如图1 所示的学术网络包括作者、论文、会议等类型对象,以及引用、发表、被发表等多个类型的链接关系。
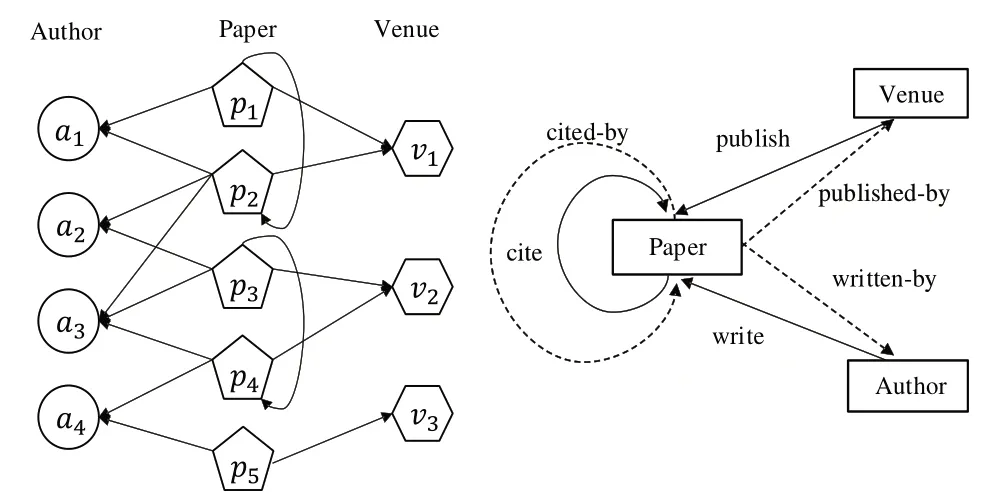
Fig.1 academic network and network model图1 学术网络与网络模式
定义1异构网络:异构网络[13]表示为有向图G=(V,E),网络中每个节点v∈V,Xi类型的节点集合由Vi表示。Eij表示Vi与Vj间关系Rij的链接集合。G具有对象类型映射函数Φ:V→Λ 和关系映射函数Ψ:E→R,其中|Λ|>1 或|R|>1。每个对象Φ(v)∈Λ 属于一个特定对象类型Φ(v) ∈Λ。每个边e∈E属于特定关系Ψ(e)∈R。其中,用来描述异构网络的元结构被称作网络模式,定义为TG=(Λ,R),节点为对象类型Λ,边为R中的关系。
top-k相似性搜索问题定义如下:给定查询对象u和参数k,top-k相似性搜索的任务是找到k个与u最相似的对象,并将对象按照相似性分值由高到低排序后返回给用户。对于返回序列中的v和不在序列中的v′,满足s(u,v)≥s(u,v′),其中s(u,v)是相似性度量函数。
2.2 关系特征矩阵构建
关系的重要性与网络中不同类型对象的规模有关[17]。GRM[21]是统一关系矩阵URM[19]的一种改进形式,优势在于能够利用网络不同类型对象的数据规模,依据异构关系的分布进行统计分析,捕获关系的重要性,避免了在进行URM 中涉及的关系重要性计算时繁琐的人工定义过程。GRM 适用于复杂的异构网络,因此借鉴GRM 的思想构建关系特征矩阵。
关系特征矩阵是根据不同类型对象的分布特征,统计分析获得的。依据GRM 中的定义,关系特征矩阵表示为:
2.3 相似性度量算法
2.3.1 基于链接的相似性度量
SimRank[3]是一种经典的链接相似性量算法,适用于任何具有链接的网络。SimRank 算法将节点u与v之间的相似性值定义为s(u,v),若u=v,则s(u,v)=1;否则:
其中,Rl(uv)表示在目标节点处结束的长度为l的相似路径集合,Sn(u,v)是两个随机游走分别从节点u 和v 开始行走n步后第一次相遇的概率总和。
2.3.2 TopSim算法扩展
针对学术网络对象间关联路径中不同类型的链接关系,引入关系特征矩阵扩展TopSim 算法,扩展后的算法可用于异构网络的相似性计算。在构建关系特征矩阵时使用GRM 预先计算得到异构链接关系权值,每条链接的权值表示从一个节点转移到另一个节点的概率。[Pn]u,t、[]t,v表示分别从u和v出发沿 着路径随机游走n步长到节点t的转移概率,根据公式(1),[P]u,t=ωij[pij]u,t,u∈Vi且t∈Vj。相似矩阵用S 表示,Sl(u,v)表示节点u和v之间的相似性。对于l≠0,可得到:
2.3.3 top-k相似搜索
扩展的TopSim 算法(EntSim)利用查询节点n步内结构的上下文计算节点间的相似度,给定查询节点u,从查询点出发的两个随机游走分别表示为rw1和rw2。Set表示rw2经过的相似路径集合,假设rw1在第i步访问节点u,Seti是rw2在第i步访问的节点集合。对于每个节点v∈Seti,根据公式(8)计算Si(u,v),并将(u,Si(u,v))存储Smapi(u)中,通过Smapi(u)迭代计算相似性值。具体算法步骤如下:


在top-k搜索过程中,给定查询节点u,假设n为最大随机游走步数,D为节点的平均出度,l表示从u到v的步数。该算法仅需存储查询节点在n步内的结构上下文,空间复杂度为。Smapi(u)存储查询节点u的局部邻域,在最坏的情况下,生成Dl个走了相同步数的Smapi(u),其中Smapi(u)的大小为D2(n-l)。在真实数据集中,许多相似路径是可以合并的,其中Smapi(u)的大小为D(n-l),该算法的时间复杂度为O(nDn)。
3 实验结果与分析
3.1 实验数据
实验所用数据为开放学术图谱(OAG)中的微软学术图谱MAG[23]。MAG 是索引1.11 亿篇论文的有向引文图的一个子集。MAG 是包含了论文(736 389 个节点)、作者(1 134 649 个节点)、机构(8 740 个节点)和研究领域(59 965 个节点)以及节点之间有向关系的学术异构网络。实验通过对MAG 原始数据集进行预处理来抽取数据,抽取后的学术异构网络包括31 548 个作者及其机构数据,3 260 个论文及其研究领域数据以及158 183 条关系数据,从中选取1 000 个论文节点与作者节点来验证查询的准确率和效率。
依据现有基准(Ground Truth)选取方法[3,10],实验选取不参与计算的对象类型作为基准。在相似论文查询时,选取与查询论文研究领域相同的论文作为基准,将数据集中属于{论文,研究领域}类型的边去除,以避免影响准确率评估。例如,论文SimRank 所属领域包含SimRank Compution、Similarity Search、Information Retrieval 等,其中Sim-Rank Compution 领域的论文包括PRSim、Simrank*、Sim-Rank++、TopSim 等,实际上这些论文的研究内容是相关的。同样的,在相似作者查询时,将数据集中属于{作者,研究机构}类型的边去除,选取与查询作者相同研究机构下的作者作为基准。
3.2 评估方法
实验对比了TopSim 和EntSim,以观察引入关系特征矩阵扩展和阈值过滤对相似性搜索性能的影响。实验以MAG 数据集中论文和作者对象为例进行搜索,采用平均精度均值(Mean Average Precision,MAP)评估 top-k相似性度量结果的准确性。MAP 的定义为:
其中,n为处于相似性度量结果位置j时的相似对象数量,rel(j)表示位置j上的对象是否相关,不相关时取值为0,相关时取值为1。
3.3 实验结果
3.3.1 MAP值
图2 表示不同排序k对应的MAP 值,其中步长l=5,阈值μ=0,0.01,0.05。通过观察可知,随着k的不断增加,MAP 值呈不断下降趋势。因为查询搜索到的弱相关对象也随着k增加,MAP 值不断下降。由图可知,返回结果中排名较高的对象更相似,应该接近给定的查询,而排名较低的对象应该在相似对象列表的相对后序位置,表明所提出方法返回的查询结果具有合理的排序。
图3 表示不同参数l对应的MAP,其中,阈值μ=0,0.01,0.05。分别以论文和作者进行查询,观察MAP 值随着步长发生的变化。从图中可以看出,当步长大于3时,MAP 值出现下降趋势,造成这种现象的一部分原因是步长的增加产生了噪声链接,进而影响相似性度量效果。步长l在2~3 时的MAP 值是最佳的,当l超过4 时,相似度结果趋于收敛,因而不再变化。实验结果表明,本文所提出方法的MAP 值明显高于TopSim 算法。
图4 表示不同阈值μ对应的MAP,其中参数k=5,10,15。以论文和作者进行查询,观察MAP 随着μ变化而发生的变化。通过观察可知,随着μ的增加,MAP值呈逐渐下降趋势,这是因为相似性度量时忽略了低于μ的相似性值,影响了低值相似性对最终相似性值的贡献。实验结果表明,本文提出的修剪策略在忽略较低相似性的同时,对测试参数范围内查询结果的精确度影响较小。

Fig.2 MAP corresponding to different parametersk图2 不同参数k对应的MAP

Fig.3 MAP corresponding to different parameters l图3 不同参数l对应的MAP
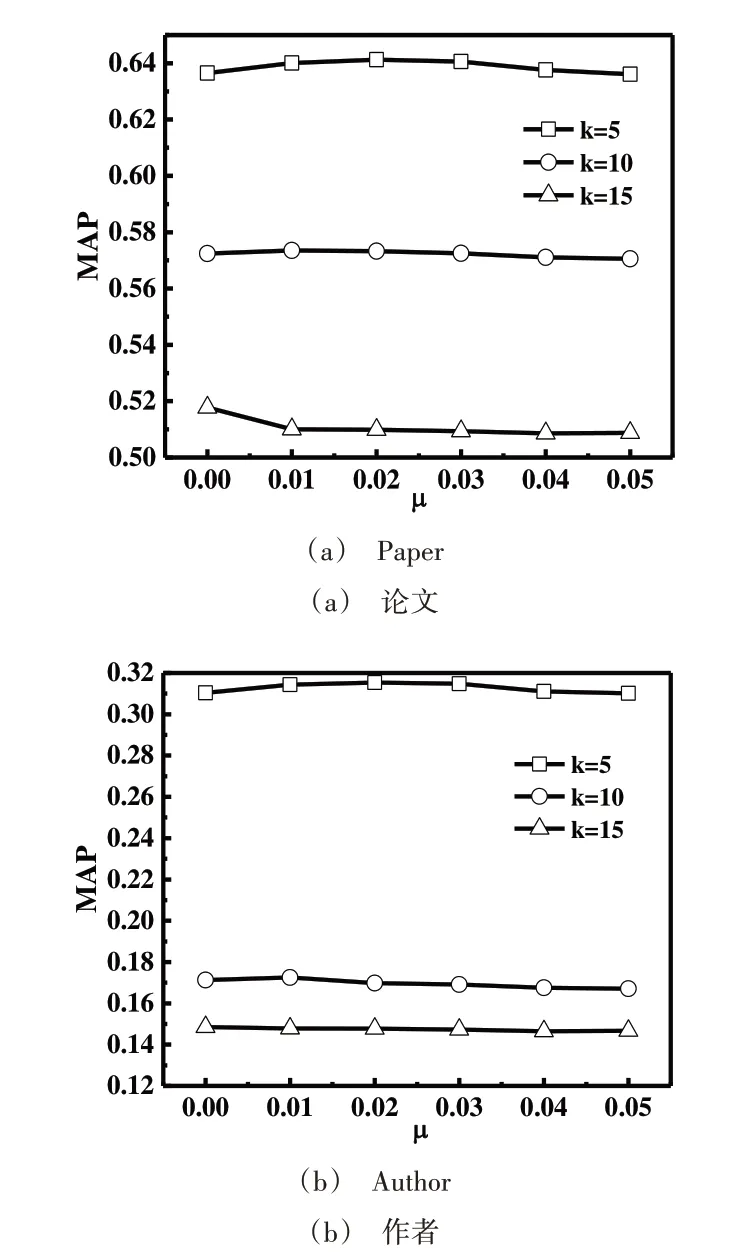
Fig.4 MAP corresponding to different parameters μ图4 不同参数μ对应的MAP
3.3.2 案例研究
以论文和作者对象作为查询内容进行案例研究,观察返回结果中的前5 个对象,以验证EntSim 的查找是否符合人们有关相似性的常规认知。
表1 是对随机选取的论文和作者进行查询后返回的前5 名相关结果。其中,第一篇目标论文“Distilling Word Embeddings:An Encoding Approach”涉及的主题有“word embedding”“neural networks”等。在返回的查询结果中,排序第1 的论文主题包含“word embedding”“linked data”等,排序为2 的论文包含的主题为“Domain-specific word embeddings”“word2vec”等。尽管排序为3 的论文并没有涉及相关主题,但总体而言,论文3 的领域也是偏向于“embedding”的相关方向。第二篇目标论文包含的主题有“knowledge discovery”“classification”等。在查询结果中,前两篇都涉及主题“knowledge discovery”,与所查询的论文主题相关。第1 位目标作者“Yehuda Koren”的研究方向主要是“数据挖掘”“推荐系统”等。在返回的结果中,排序为1 的作者“Chris Volinsky”的研究方向主要涉及“数据挖掘”“推荐系统”等;排序为2 的作者“Shawndra Hill”的研究方向主要涉及“知识发现”“数据挖掘”等;排序为3、4、5 的作者研究涉及不同方向。类似地,第2 位目标作者“Kevin Mc-Guinness”的研究方向主要是“图像处理”“图像分割”等,返回结果中前2 名作者的研究领域都涉及到了“图像处理”方向,与所查询的作者研究领域相关。

Table 1 Top-5 similar papers similar to given paper and author表1 与给定查询论文及作者相关的前5名
案例研究表明,本文提出的方法不仅在MAP 指标上提升了相似搜索效果,而且能够从真实学术异构网络中查找到符合人们常规认知的相似对象。
3.3.3 效率
图5 表示不同阈值μ对应的查询时间,其中k=5,比较在进行相似论文和作者搜索实验时μ在0~0.05 范围内的时间开销。通过观察可知,随着μ的增加,计算时间明显减少。因为在相似性度量时忽略了低于μ的低值相似性,减少了有关低值相似性所涉及的计算操作。实验结果表明,通过对低值相似性进行阈值过滤,能够有效降低相似搜索的在线查询时间开销。
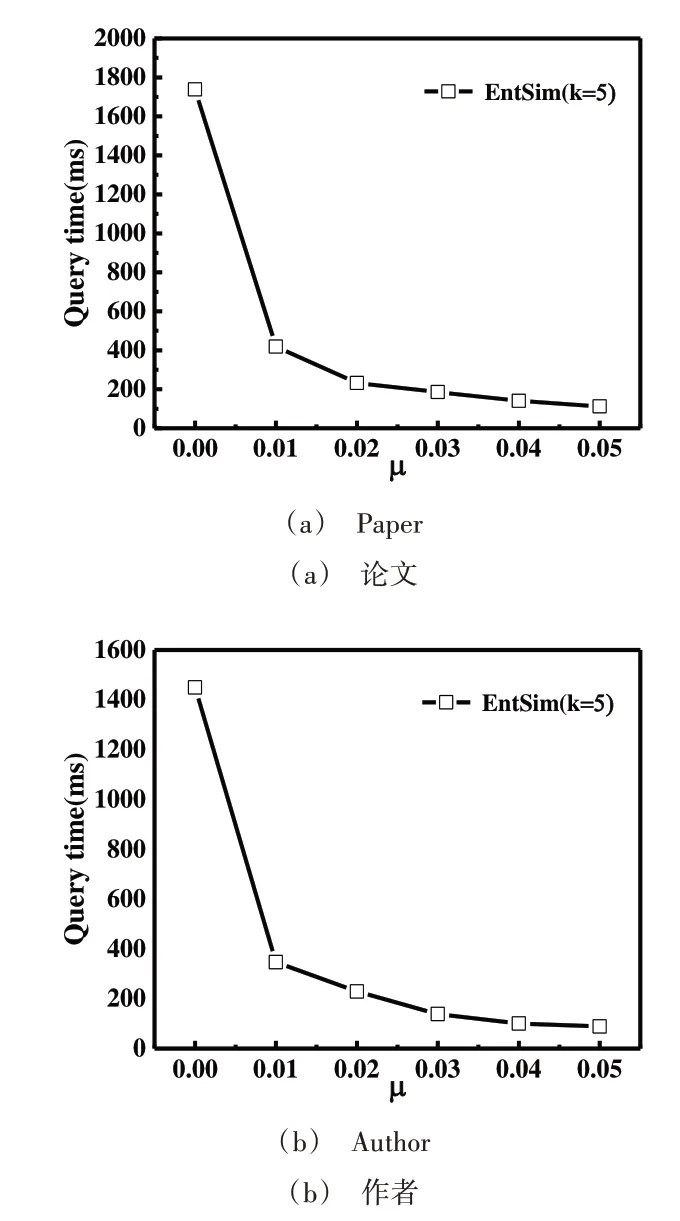
Fig.5 Query time corresponding to different parameters μ图5 不同参数μ对应的查询时间
图6 表示不同步长l对应的查询时间,其中μ=0,0.01,0.05。比较在相似论文和作者搜索实验中参数l在1~6 范围内的时间开销。通过观察可知,随着步长l的增加,查询时间呈快速上升趋势,这是因为路径数量随着步长的增加呈指数级增长,进而影响相似搜索的时间开销。本文所提出的方法通过设置阈值,显著降低了时间开销。事实上,由于相似性度量结果在l为4 时已经收敛,在实际实施过程中可通过限制路径长度的方式进一步降低时间开销。实验结果表明,本文所提出方法的在线查询处理时间成本较低。
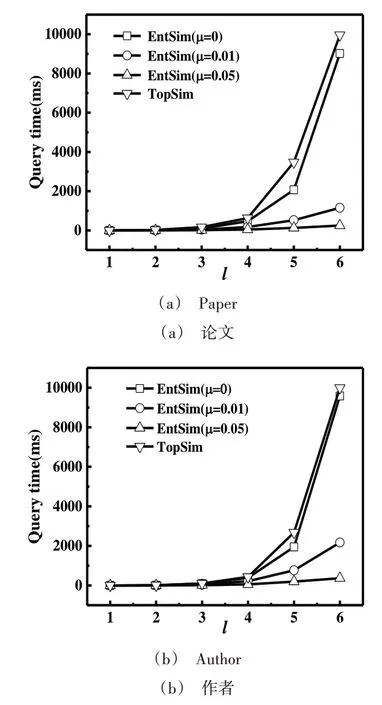
Fig.6 Query time corresponding to different parameters l图6 不同参数l对应的查询时间
4 结语
本文从学术网络复杂化和大规模化的现状出发,提出一种基于异构关系分布特征的相似性搜索方法。与现有方法相比,该方法考虑了网络的异构关系数据分布特征。通过对不同类型的对象数据规模进行统计分析,得到关系特征矩阵。基于关系特征矩阵扩展TopSim 算法实现大规模学术网络上的相似性搜索。同时,为了节省计算开销,设置阈值筛选来减少不必要的计算操作,以实现快速的查询处理。在真实数据上开展大量实验,结果表明,当考虑数据构成及其分布特点时,在保证查询效率的基础上,查询结果的准确率平均提升了7.25%。
