基于CEEMDAN-SE-TCN的集群资源预测研究
2023-05-11史爱武张义欣
史爱武,张义欣,韩 超,黄 河
(武汉纺织大学 计算机与人工智能学院,湖北 武汉 430200)
0 引言
集群技术是指将多台计算机通过集群软件相互连接,组成一个单一系统模式进行管理,其目的是为了通过较低的成本获取更高性能,增加系统的可扩展性与可靠性。随着科技飞速发展,人工智能等计算机技术渐渐融入大众生活,随之而来的大规模访问量、海量数据处理等问题给服务器集群的负载均衡能力带来了新的挑战。目前,大多数厂商与平台均定期获取集群中计算机硬件的各项使用情况并计算相应权值,然后根据整个集群的情况对任务进行调度并作出相应的负载均衡策略,但该策略在应对某些访问量、数据量突然增长的时间点时会出现调度不及时的情况,导致集群部分计算机压力过大,资源分配不均,甚至造成服务器宕机,此时将严重影响平台用户体验,对平台造成无法挽回的经济损失。对一个服务器集群而言,及时、灵活地进行负载均衡,对集群负载进行预测,根据预测数据作出相应的预调度策略使集群面对大访问量时存在一定的缓冲阶段,避免集群服务器压力过高。因此,增加集群资源利用率,减少服务器响应时间,提升服务质量具有实际价值,其中最重要的是需要建立一个准确的集群负载预测模型。
目前,已有许多学者对负载预测进行研究,主要预测模型包括传统时间序列模型与机器学习算法。其中,对于传统时间序列模型包含差分整合移动平均自回归模型(Autoregressive Integrated Moving Average Model,ARIMA)[1-2]、指数平滑法(Exponential Smoothing,ES)[3],但该方法无法提取数据的非线性特征,而集群负载数据通常为非线性,因此难以保证预测精度;机器学习算法包含循环神经网络(Recurrent Neural Network,RNN)[4-5]、长短期记忆人工神经网络(Long Short-Term Memory,LSTM)[6-7]等,该算法相较于传统算法预测精度更高。
近年来,研究发现RNN、LSTM 为使用最为广泛的时序预测模型之一,但时间卷积网络(Temporal Convolutional Network,TCN)[8-9]由于自身梯度的稳定性和并行性等优点,在某些场景上的预测效果要优于RNN 与LSTM 模型。进一步研究发现,由于部分时序数据的非线性与非平稳性特点,组合模型相较于单一模型能表现出更优异预测效果。因此,在时序序列预测的相关应用研究中,许多学者从降低时间序列的非平稳性与复杂性角度出发,提出基于经验模态分解(Empirical Mode Decomposition,EMD)[10]和人工智能模型相结合的新模型,例如EMD-SVM[11]、EMDLSTM[12]、EMD-RNN[13]等方法。这些组合模型相较于单一模型的预测更精准,但在经典经验模态分解EMD 中仍存在模态混叠与信号分解不完全的问题,影响模型预测精度。
为此,本文提出基于CEEMDAN-SE-TCN 的集群负载预测模型。该模型首先利用CEEMDAN 模型分解非线性和非平稳的时间序列,然后在TCN 模型基础上加入通道注意力机制(Squeeze And Excitation Network,SENet)[14]模块增强网络的特征提取能力,最后与CEEMDAN 模型相融合达到最佳预测效果。
1 自适应加噪的集合经验模态分解
由于经验模态分解EMD 中存在模态混叠问题,提出改进算法集合经验模态分解(Ensemble Empirical Mode Decomposition,EEMD)[15]和完备集成经验模态分解(Complete Ensemble Empirical Mode Decomposition,CEEMD)[16]算法分别在原信号中加入N对白噪声和N对正、负辅助白噪声减少EMD 分解的模态混叠现象。虽然,这两种模型在一定程度上解决了模态混叠问题,但分解信号后得到的本征模态分量(Intrinsic Mode Function,IMF)会残留一定的白噪声,继而影响后续预测模型的训练时间和准确率。
为了解决该问题,Torres 等[17]提出完全自适应噪声集合经验模态分解(Complete EEMD with Adaptive Noise,CEEMDAN)模型。该模型基于EEMD,在分解的每个阶段添加自适应高斯白噪声,有效解决了模态混叠及白噪声残留问题。具体步骤如下:
步骤1:在原始信号x(t)中加入服从正态分布的白噪声αεi(t),形成新序列yi(t)。
其中,i=1,2,3,…,n为加入白噪声的次数,α为噪声标准差,εi(t)为第i次添加的白噪声信号。
步骤2:使用EMD 模型对yi(t)进行进一步分解,得到第一个模态imf1(t),同时得到第一个余量信号r1(t)。
2 SE通道注意力机制
SENet 是视觉神经网络的一种,该模型对各通道间的关系与相关性更敏感,通过忽视相关性较小或非相关性特征通道,增强模型特征提取能力,提升TCN 网络模型性能。由于模型计算量较小,使用方便,可直接插入TCN 模型中形成SE-TCN。SENet模型主要包括以下4个步骤:
步骤1:Transformation(变换)。将输入特征通道进行传统卷积变换,形成新的特征图UϵRH×W×>C。
步骤2:Sequeeze(挤压)。通过全局池化方法将每个通道的二维特征(H×W)压缩为一个实数,具体计算方法如式(9)所示。
步骤3:Excitation(激励)。通过特征参数,使用两个全连接层为每个特征通道生成一个权重值,如图1所示。
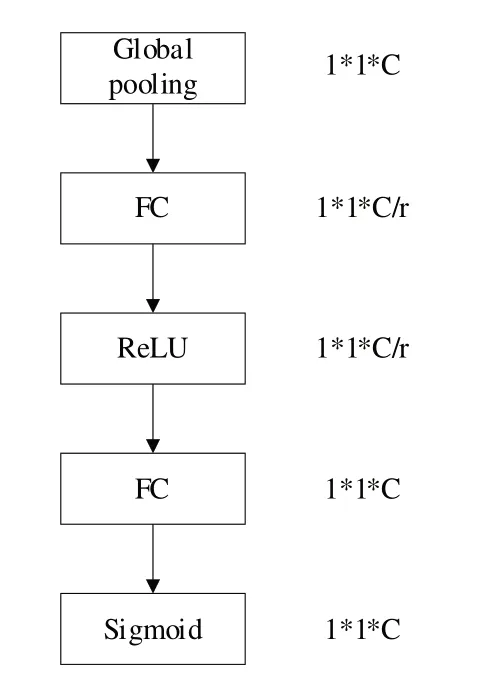
Fig.1 Excitation图1 激励
步骤4:Scale(缩放)。将步骤3 得到的权重逐个乘以对应通道的权重系数,得到最终特征图。
3 时间卷积网络
时间卷积网络是一种可用于处理时序序列预测问题的神经网络,与RNN 相似之处在于可接收任意长度的输入序列作为输入,将其映射为等长的输出序列,但由于TCN 包含了因果卷积与空洞卷积,相较于RNN、TCN 具有更好的并行性,因此内存占用率更低。
3.1 因果卷积
因果卷积是时间卷积网络预测中最为关键的一环,原因在于因果卷积是单向的。相较于普通卷积,在因果卷积中无法知晓未来数据,即t时刻的输出值yt只与t、t时刻前的输入值{xt,xt-1…x0}相关,从而增加了数据的保密性。
3.2 空洞卷积
如果需要知晓更长远的数据信息,就需要增加网络层数,但随着网络模型层数增加,模型可能会出现训练复杂、梯度消失等问题。为了解决该问题,在时间卷积网络中引入空洞卷积,使其与因果卷积结合形成空洞因果卷积,跳过部分输入值让卷积核能应用于大于自身大小的部分,使卷积感受野呈指数级增长,具体结构如图2所示。
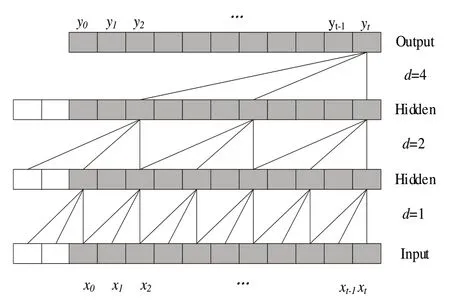
Fig.2 Dilatative causal convolution图2 膨胀因果卷积
图2 中d代表膨胀因子,膨胀因果卷积可通过间隔采样方法在不增加网络层数的同时扩大网络野。同时,在时间卷积网络中还加入了WeightNorm 与Dropout 正则化,以降低模型发生过拟合现象的风险。此外,加入残差连接模块使模型网络以跨层方式传递信息,防止模型发生梯度爆炸与梯度消失问题。
4 CEEMDAN-SE-TCN 负载预测模型
服务器集群的负载数据呈现非线性与高噪声特点,例如在工作日数据变换较为平缓,但在节假日与工作日间存在负载变换迅速的边缘,此时数据变化波动较大,通过单一模型预测困难较大。为此,本文将SENet 嵌入TCN 模型形成SE-TCN 模型(见图3),利用SENet 通道的增强特性提升TCN 模型特征提取能力。该模型相较于单一TCN 与LSTM 模型,能解决在数据快速变化时特征值提取能力不足的问题。

Fig.3 Structure of SE-TCN model图3 SE-TCN模型结构
同时,利用CEEMEDAN 解决数据非线性与高噪声的特点,将带有噪声的非线性原始序列分解为相对平稳、简单的IMF 分量与一个残余分量Res,各IMF 分量相互独立。最后,将相对稳定的信号输入预测模型中进行预测,以提升预测精度。
目前。不少学者将信号分解模型与网络预测模型相结合,大多是将分解后的IMF 分量与Res 分量分别输入人工智能预测模型中得到每个IMF 分量和Res 分量的预测结果,然后将各预测结果进行重组得到最终预测结果。该方法预测结果准确率较高,但训练和预测的时间复杂度较高,无法满足服务器数据预测的时效性要求。为此,本文提出CEEMDAN-SE-TCN 方法(见图4)对数据进行处理,具体步骤如下:
步骤1:归一化处理原始服务器负载数据,将预处理好的数据进行CEEMDAN 分解。
步骤2:从低频信号开始,通过相关系数法将分解好的IMF 分量与原始序列进行比较,求解相关系数,计算公式如式(10)所示。
其中,μ为序列平均值,当μ<0.1 时证明该分量可能为过度分解的分量,与原序列关系性不大。
步骤3:将剩余IMF 分量与Res 分量构建成一个二维矩阵,使用滑动窗口法对数据进行重构,将其转化为一个有监督学习的过程。
步骤4:将重构完成的数据输入SE-TCN 模型中进行训练。
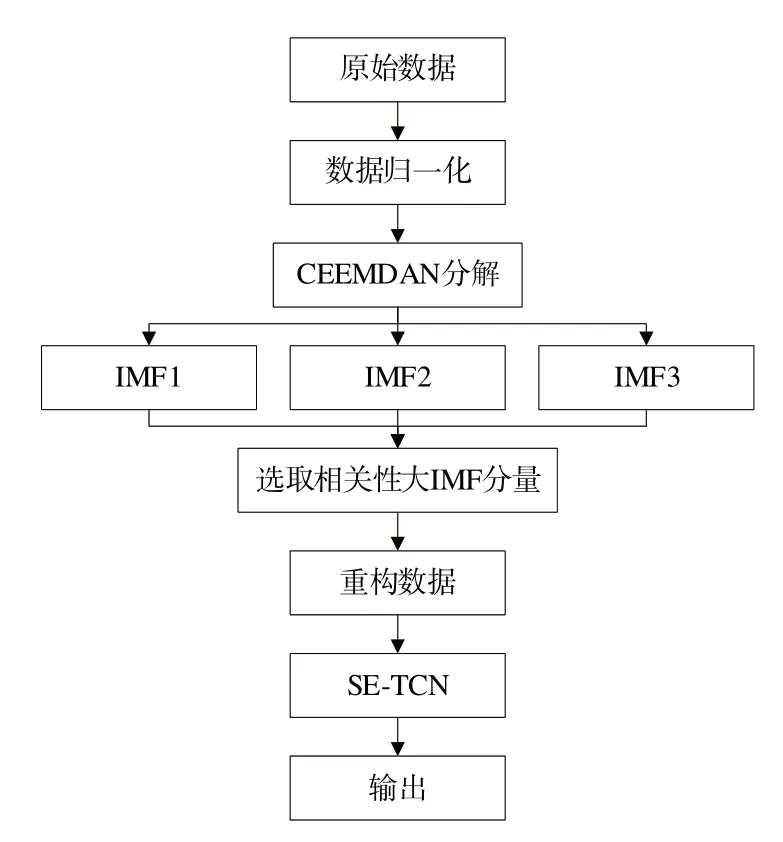
Fig.4 CEEMDAN-SE-TCN prediction process图4 CEEMDAN-SE-TCN 预测流程
5 实验结果与分析
5.1 实验环境与数据集
本文实验环境为:Windows10 操作系统,显卡为RTX 3060,在PyCharm 平台下采用Python 3.7 进行编程操作。实验数据集为谷歌官方的公开的Google Cluster Data,记录了12 500 台机器集群从2011 年5 月开始29 天内每台机器的CPU 使用率、内存占用率、任务调度情况等重要信息。由于CPU 使用情况基本能展现机器的整体使用情况,因此本文采用CPU 利用率作为集群负载预测指标进行预测,将Google Cluster Data 数据集前70%数据作为训练集,剩余30%数据作为测试集,使用插值法对数据进行补充,再对数据进行Min-Max Normalization 归一化处理。
5.2 实验参数与评价指标
本文实验的时间卷积网络初始参数由人工经验选取,通过多次实验反复调整参数得到最优结果,具体参数如表1所示。

Table 1 Parameters of TCN model表1 TCN模型参数表
5.3 实验结果分析
为验证本文所提模型的有效性,将LSTM、TCN、EMDTCN 与CEEMDAN-SE-TCN 模型进行比较分析。同时,使用平均绝对误差(Mean Absolute Error,MAE)、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)、均方根误差(Root Mean Square Error,RMSE)共3 个指标作为预测结果的评判标准,预测结果如图5所示。
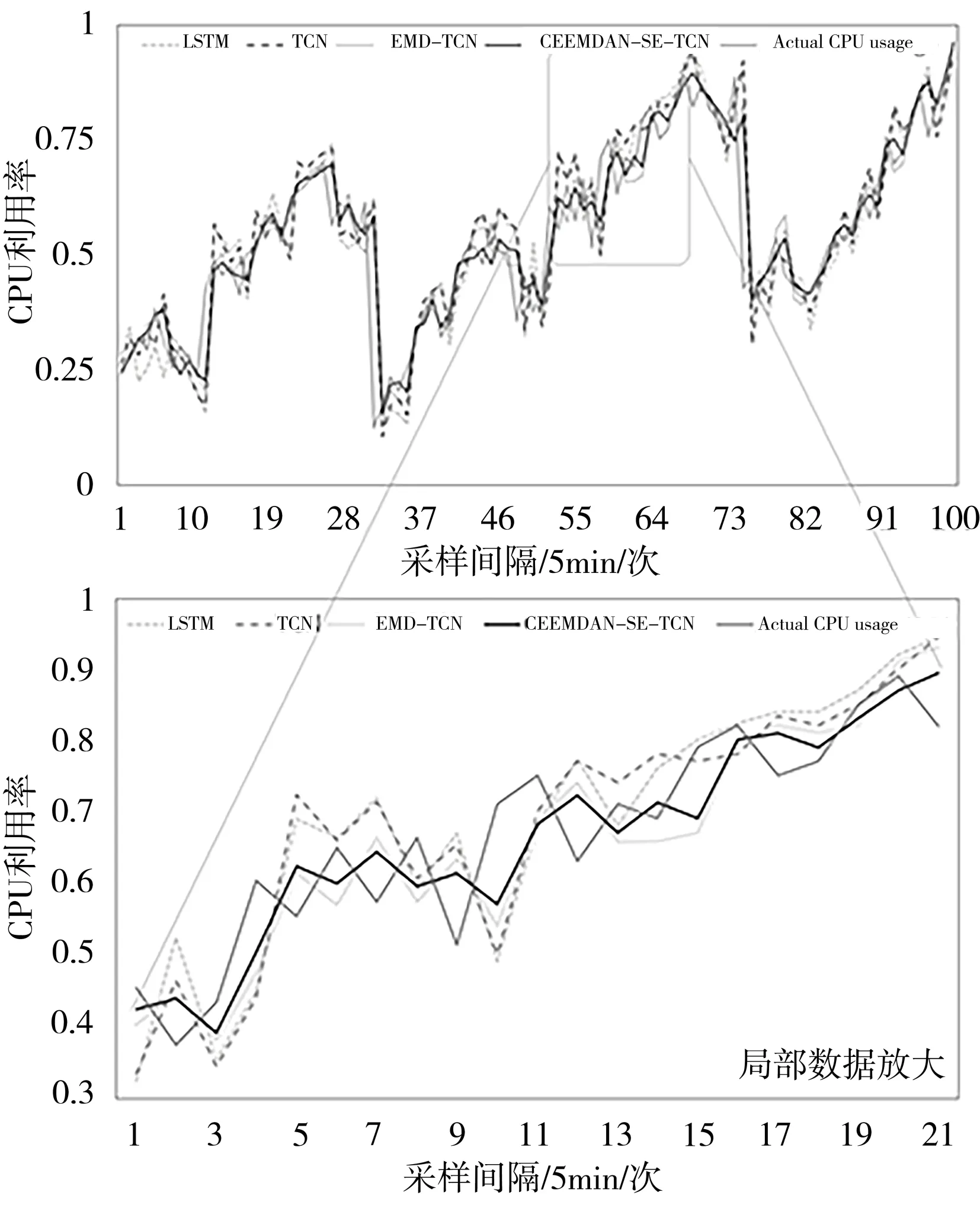
Fig.5 Comparison of prediction models图5 预测模型对比图
由图5 可见,LSTM 与TCN 的预测结果与实际存在一定偏差,且具有一定的延迟性;EMD-TCN 模型、CEEMDAN-SE-TCN 模型的预测结果与原始数据曲线较为贴合,选取数据抖动较为频繁的部分放大比较可清晰地发现EMD-TCN、CEEMDAN-SE-TCN 模型预测结果相较于LSTM、TCN 更理想,但在数据快速变换时CEEMDAN-SETCN 模型的预测值更接近实际值。模型具体评价指标数据如表2所示。

Table 2 Comparison of model prediction results表2 模型预测比较结果
由表2 可见,LSTM、TCN 模型对服务器负载这种非线性波动性较大的数据而言,预测效果相较于组合模型并不理想,可明显看出EMD-TCN、CEEMDAN-SE-TCN 模型的预测结果更好,拟合度更高,且CEEMDAN-SE-TCN 模型预测精准度最高。虽然,本文在原有的分解—预测模型中加入SENet 模块,但SENet 模型自身计算量小,相较原模型增加的参数不足0.01%,因此时间复杂度基本与原模型一致。
为进一步证明模型的有效性,将CEEMDAN-SE-TCN模型应用于Kubernetes 所搭建的Docker 集群中,该集群由一个Master 节点与一个Node 节点构成,集成Promethues 工具监控节点资源指标情况。使用JMeter 压力测试工具模拟用户访问Web 应用,实验结果表明使用本文模型的集群在面对用户模拟请求时,CPU 平均利用率相较于其他模型高出5.545%~12.312%,在面对模拟用户访问请求时节点平均响应时间提升60.3~115.6ms。
综上所述,CEEMDAN-SE-TCN 模型的各项指标数据均在一定程度上优于其他模型,证明了该模型应用于服务器负载预测的有效性。
6 结语
服务器集群的负载控制是保证集群能正常运行的关键,预测集群负载数据应对突发状况,根据预测结果提前对集群机器进行相关操作,可减少服务器集群负荷,节省服务器资源。本文改进原有预测模型,提出更适合服务器负载预测实际情况的CEEMDAN-SE-TCN。实验表明,CEEMDAN-SE-TCN 在各项性能上均优于其他模型。
虽然,CPU 能基本反映负荷情况,但在实际应用过程中还需考虑内存、带宽等影响因素,综合评价服务器负载情况的预测效果,从而得到更客观、全面的预测结果。
