基于随机森林方法的柴油机涡轮增压器故障诊断
2023-05-05贾哲宇温华兵朱军超赵震宇
贾哲宇,温华兵,朱军超,赵震宇
(江苏科技大学 能源与动力学院,江苏 镇江 212003)
0 引 言
船舶的安全航行离不开柴油机等动力系统机器的稳定工作。而涡轮增压器作为柴油机中长期在高热、高速环境中运行的机械系统,工作环境恶劣、持续动力工作时间长,发生故障的可能性较大。一旦发生严重故障,会影响到整个柴油机动力装置的正常运行,造成重大事故,导致浪费大量人力财力,甚至危及人员安全。为了确保涡轮增压器正常工作,对增压器的故障诊断方法进行研究很有必要。
神经网络在涡轮增压器模块的故障诊断近年来逐步受到关注。姚荣荣[1]提出了基于BP-GA 的故障诊断方法;魏伟达[2]提出了基于多变量灰色预测模型,引入神经网络和遗传算法优化预测模型,基于RBF 神经网络进行故障诊断;Yi Wei[3]提出了基于单类支持向量机(OSVM)、亲和传播(AP)和高斯混合模型(GMM)的无监督机器学习算法OAGFD 进行故障诊断;孔祥鑫[4]提出了振动分析法对增压器蜗壳转动失效进行诊断。实际应用中,由于柴油机涡轮增压器的样本数据较大且类别较多,很多故障识别方法分类时存在各自的局限性。随机森林(random forest, RF)秉承了Bagging 方法的思想,适合处理高维度大数据,方便进行并行训练,能够有效提高故障分类准确率[5]。张鹏[6]研究了基于深度森林的无线传感器网络故障分类方法;尹际雄[7]研究了基于随机森林的齿轮箱故障诊断方法;张利宏[8]研究了基于会议制随机森林的电机滚动轴承故障诊断方法。
随机森林方法已经应用到多个领域且有较好的效果。因此,本文将随机森林模型应用到涡轮增压器故障诊断,对柴油机涡轮增压器的几种常见故障进行分析,并验证该方法应用在涡轮增压器故障诊断的有效性。
1 随机森林
融合Breimans 的“Bootstrap aggregating”思想与Ho 的“random subspace”,由Leo Breiman 与Adele Cutler 创造出的随机森林方法,是一种具有多个决策树的集成学习方法。由于使用随机的方式生成决策树,也称为随机决策树。随机森林之中的决策树与决策树没有相关性。
随机森林的工作原理是生成一些各自独立学习和预测的分类器,最后将这些结果结合起来进行预测,这比单个分类器或模型预测的结果更好。随机森林的基本元素是决策树,每棵树都作为一个分类模型,生成的最终结果就是各个树分类结果的投票总数。
图1 为随机森林算法的基本流程。随机森林的表现由随机抽样与特征选择2 个阶段起关键作用。确保每棵树彼此独立,随机森林不会简单进入局部过度严格,并且能稳定噪声干扰。

图1 随机森林算法基本流程Fig.1 Basic flow of random forest algorithm
随机森林可以分析复杂交互的经典特征,具有非常强大的能力,可以稳定噪声数据,并具有更快的学习速度。该变量可用作为高阶原始数据选项的工具。近年来,被广泛应用于不同的分类、预测等问题中。
取CART 方法并使用Gini系数最小的原则对各节点分散,故障分类流程为:
步骤1假设随机森林是由一系列的C1(x),C2(x),…,Ck(x)的决策树所构成的,则该随机森林的边缘函数可以表示为
其中:I(·)为示性函数,X为输入特征向量,Y为分类正确向量;j为分类错误向量;avk(·)为对其取平均值,avk(I(Ck(X)=Y))是模型正确分类数,(I(Ck(X)=j))是模型错误分类最大值。
步骤2边缘函数表明正确的分类结果优于错误的最大分类结果。分类的结果随边缘函数的增大而更优。
利用bagging 方法从原始样本集里随机选择N个步骤,并选择数据作为训练样本集。
然后,建立样本训练的决策树,在节点中随机选取d参数,并利用基尼系数选择最优树决策点参数。基尼系数表示为
其中,样本集S中每个类别的概率表示为Pi。若将样本集S分为2 个子集S1和S2,则Gini系数为
步骤3按照顺序重复步骤1、步骤2 创造多个决策树对测试集x分类,结果从众多决策树里的投票多少决定,其中确定类别的公式为
其中:majority表示投票数量最多;Ci(x)表示第i棵决策树;Ntree为决策树的总数[9]。
2 柴油机模型仿真
因为现实环境中利用实验得到涡轮增压器的故障数据非常困难,所以选择AVL Boost 软件模拟涡轮增压器的各类故障。柴油机主要参数如表1 所示。
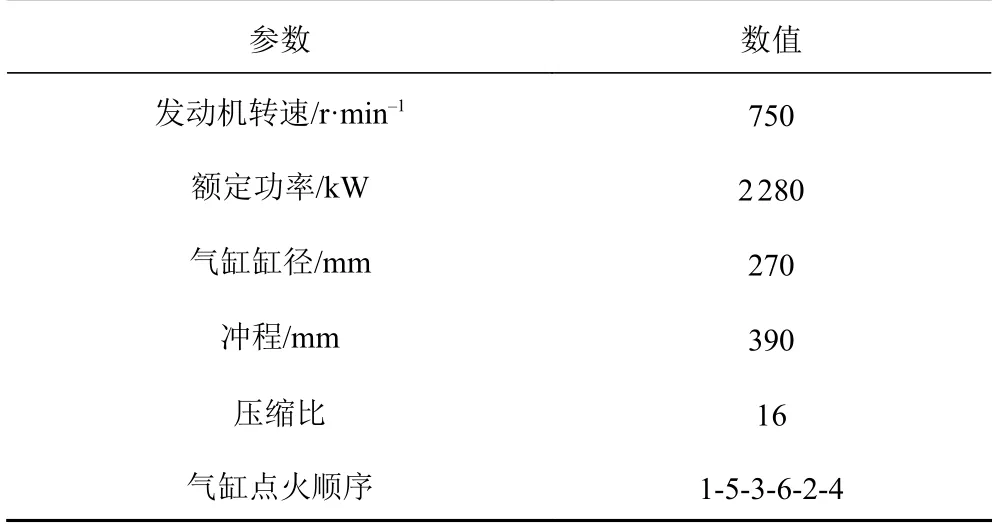
表1 柴油机主要参数Tab.1 Main parameters of diesel engine
基于AVL Boost 平台创建柴油机仿真模型,模型如图2 所示。

图2 柴油机仿真模型Fig.2 Diesel engine simulation model
利用构建的柴油机性能仿真数值模型,模拟计算柴油机额定工况下运行的主要性能参数。设置仿真模型的参数,如表2 所示。

表2 仿真模型主要参数Tab.2 Main parameters of simulation model
通过对比额定功率、燃油消耗率及最高爆发压力等参数修正模型,使模型满足精度要求,对比结果如表3 所示。

表3 额定工况下实际值与模拟值的对比Tab.3 Comparison between actual value and simulated value under rated working condition
额定工况下,建立的柴油机整机模型模拟计算的额定功率、燃油消耗率及最高爆发压力与实际数据偏差均在1%以内,故认为此模型能够达到模拟计算精度要求。据此进行模拟实验获取关联的数据。
分别设置温度降低(F1)、压气机故障(压气机效率降低)(F2)、中冷器气侧堵塞(中冷器压降过高)(F3)、中冷器水侧堵塞(中冷器效率降低)(F4)、曲轴箱窜气(F5)、涡轮喷嘴环脏堵(F6)、排气管脏堵(F7)、喷油延迟(F8)、涡轮前排气管堵塞(F9)、进气道漏气(F10)以及排气道漏气(F11)这11 种故障状况。筛选压气机出口温度(S1)、气缸排气温度(S2)、涡轮后排气温度(S3)、涡轮前排气压力(S4)、涡轮增压器转速(S5)以及增压压力(S6)这6 种热力学参数作为故障诊断的特征参数。根据故障仿真实验,获得规模为1 007×6 的柴油机涡轮增压器故障数据集。建立柴油机涡轮增压器的故障树如图3 所示。
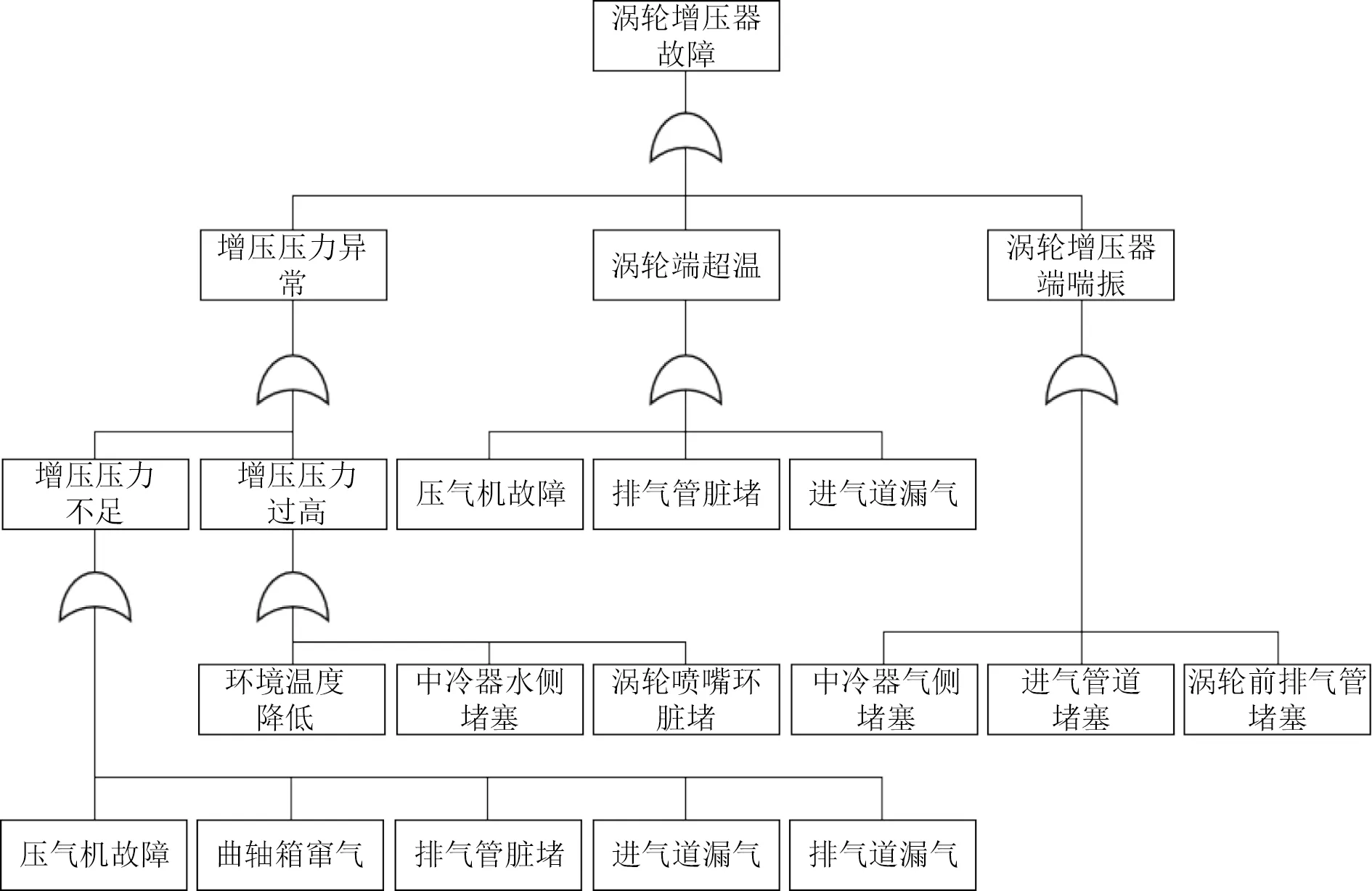
图3 涡轮增压器故障树Fig.3 Turbocharger fault tree
3 基于随机森林的涡轮增压器故障诊断
数值实验的流程如图4 所示。将故障原始数据按比例分为711×6 的训练集和规模为296×15 的测试集,用测试集数据检测该模型的功能。
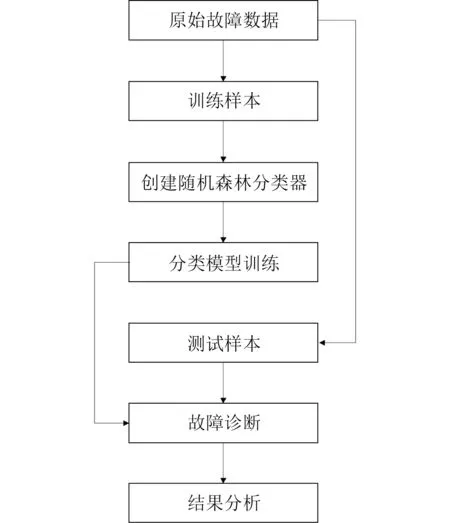
图4 故障诊断流程Fig.4 Fault diagnosis process
3.1 故障诊断结果及分析
仿真获得的数据样本集包括105 组环境温度降低、86 组压气机故障、97 组中冷器气侧堵塞、99 组中冷器水侧堵塞、93 组曲轴箱窜气、93 组涡轮喷嘴环脏堵、90 组排气管脏堵、93 组喷油延迟、83 组涡轮前排气管堵塞、84 组进气道漏气、84 组排气道漏气,总共1 007 组。
使用随机森林函数创建一个分类器。在构建随机森林分类器时,利用随机森林函数的功能对测试数据进行模拟。根据随机森林分类的结果分析,诊断准确率如表4 所示。

表4 随机森林方法故障诊断准确率表Tab.4 Table of fault diagnosis accuracy of random forest method
3.2 与决策树方法对比
为了验证随机森林方法能够有效提高故障诊断率,将整理后的数据集提供给决策树方法进行故障诊断。表5 为决策树算法的诊断准确率,图5 所示为两种分类算法各故障诊断率的对比。可以发现,决策树误诊断51 个,综合准确率为82.77%。远低于随机森林的95.24%诊断率。因为决策树方法是单个分类器,但随机森林方法利用bootstrap 重抽样方法将各种单一分类器组合,其中的训练数据选择各不一样,选择组合分类器的方法把各种分类器的处理结果结合,获得一个森林的处理结果。因此,与决策树方法相比,随机森林能够更准确识别柴油机涡轮增压器故障。

表5 决策树方法故障诊断准确率表Tab.5 Table of fault diagnosis accuracy of decision tree method
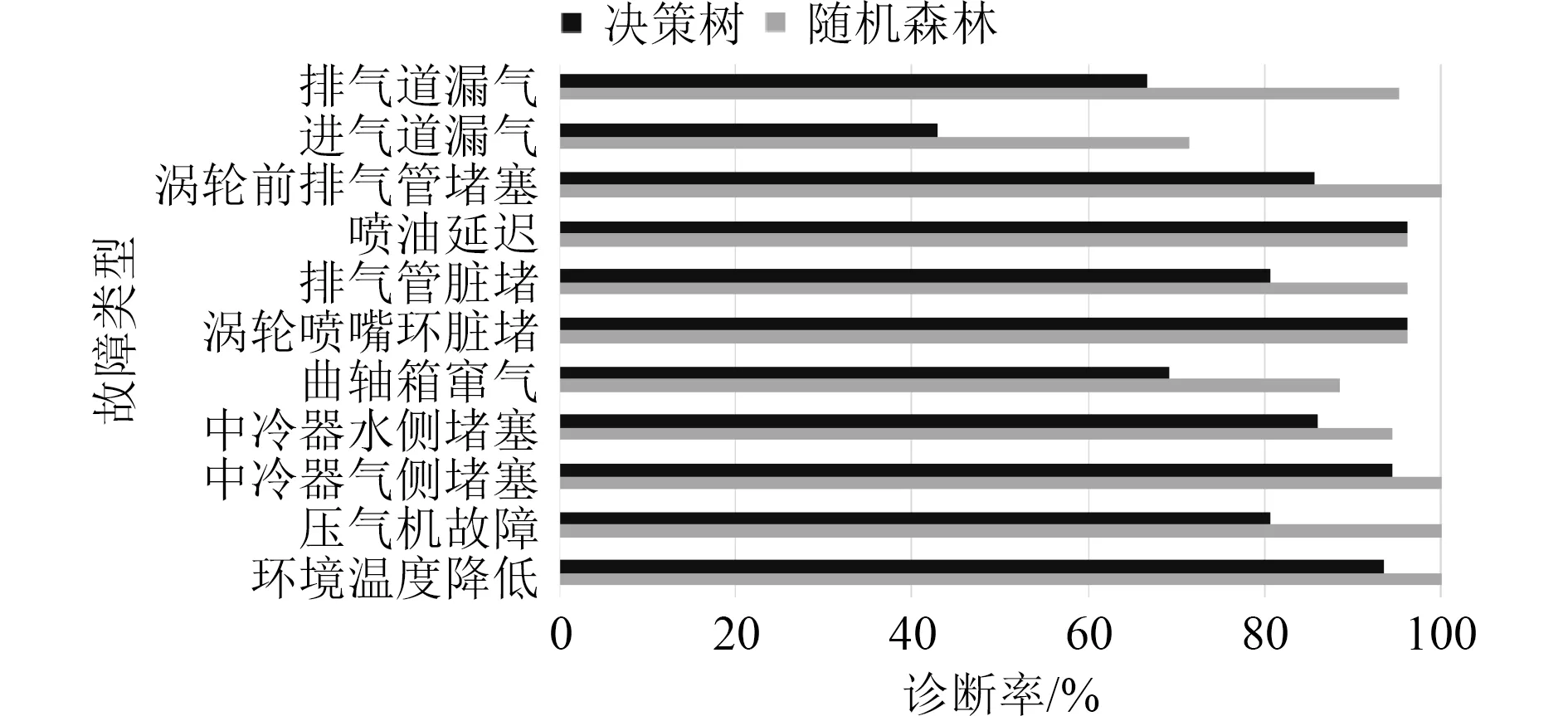
图5 随机森林方法与决策树方法诊断率对比图Fig.5 Comparison of diagnosis rate between random forest method and decision tree method
3.3 决策树棵数对诊断率的影响
结合随机森林的原理,决策树数量大小和集中特征数量有可能影响随机森林的效果,因此,首先保持集中特征数量值m(m=,M为总特征数量)不变为2,对随机森林中决策树的棵数选择多种值,从0~300 每5 个取一次,使用随机森林方法对故障样本进行故障诊断,随机森林决策树棵数对分类的作用如图6所示。

图6 随机森林决策树棵数对分类的作用图Fig.6 Effect diagram of random forest decision tree number on classification
可知,决策树过少对故障诊断的影响较大,但取值超过50 后,随机森林的诊断正确率并无明显变化,基本在95.5%小幅波动。
3.4 集中特征数量对诊断率的影响
首先保持随机森林中决策树的棵数不变为100,对集中特征数量值m进行多次取值,从1~6 每1 个取一次,使用随机森林方法对故障样本进行故障诊断,随机森林集中特征数量对分类的作用如图7所示。
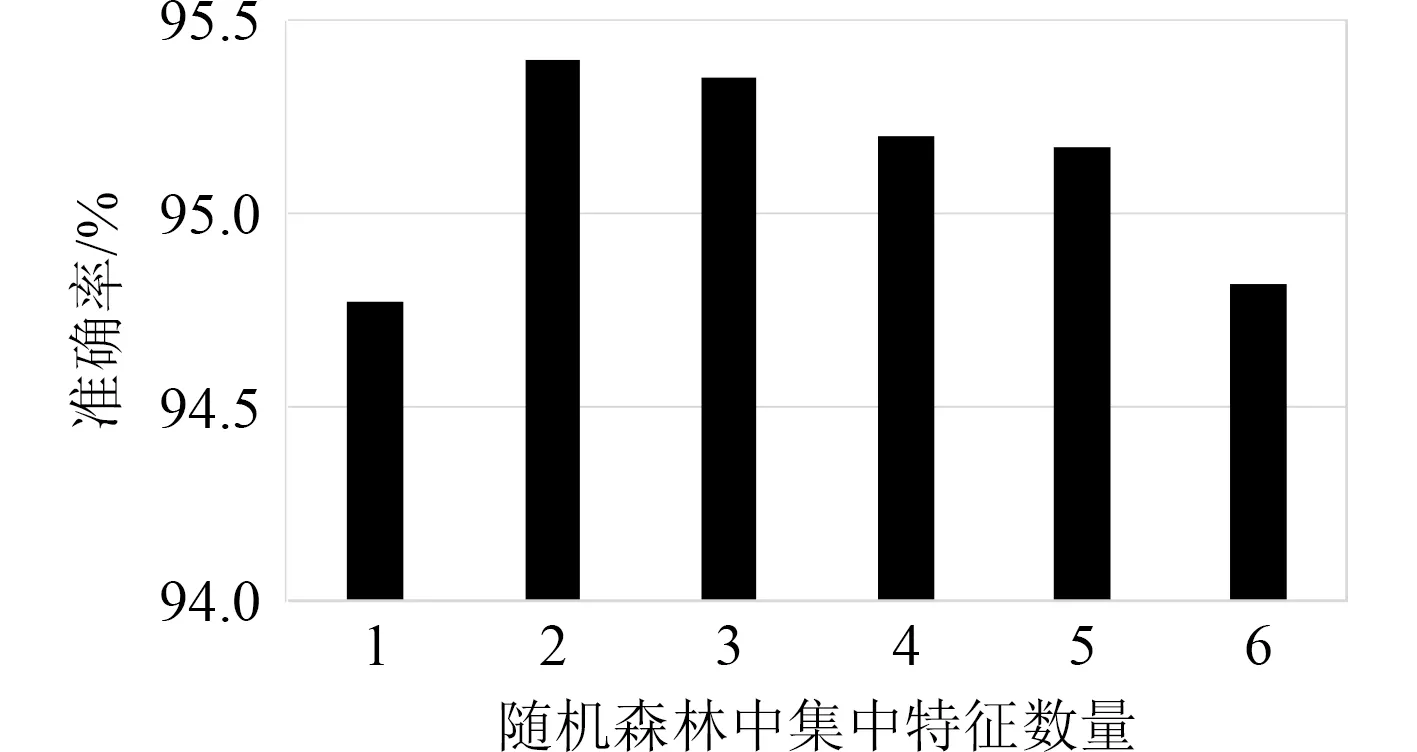
图7 随机森林集中特征数量对分类的作用图Fig.7 Effect diagram of feature number in random forest concentration on classification
可知,集中特征数量取值为2 时,随机森林的准确率最高,因此设置随机森林的集中特征数量为2。
综合2 种参数的影响规律,将随机森林的决策树棵树设置为150 棵,集中特征数量设置为2,得到柴油机涡轮增压器故障96.28%的诊断率。
4 结 语
本文提出基于随机森林的故障诊断方法对柴油机涡轮增压器进行分析。基于AVL Boost 构建仿真模型,选择该模型获得的柴油机各种工况状态中的数据,当做训练样本进行故障诊断,结果表明:
1)相比于决策树分类器这种单一分类器,随机森林方法准确率明显更高,证明其能够更准确识别柴油机涡轮增压器的故障,对提高柴油机涡轮增压器故障诊断的准确率有一定意义。
2)随机森林对柴油机涡轮增压器故障诊断的精度较高,在仿真模型的数据集上将随机森林的决策树数量设置高于50 棵,集中特征数量为2 时,能够达到更高的准确度。
