基于神经网络的城市大气雾霾污染短时预测方法研究
2023-04-29刘娜
刘娜

关键词:神经网络;雾霾污染;短时;预测
中图分类号:X823 文献标志码:B
前言
近年来,随着城市化进程的不断加快,大量工业废气和汽车尾气排放到空气中,致使大气雾霾现象越来越严重,给人类的生活带来了巨大的危害。同时由于大气污染导致能见度降低,影响了人们正常的工作和生活。近年来针对城市大气雾霾污染问题开展了大量研究工作,其中以灰色关联度法与AQI-AQI指数关联分析两种方法最为突出。但是通过长期应用实践发现,两种方法在短时预测方法中均存在时间量分析长度与对应雾霾变化特征对应误差偏大问题,因此相关研究人员将研究中心转为短时预测与雾霾特征预测匹配,通过不断研究发现神经网络可以兼顾短时特征与预测量之间的统一,基于此特性,提出一种全新大气雾霾短时预测方法,并对其实现及性能验证进行详细描述。
1方法的具体实现
1.1构建神经网络预测结构
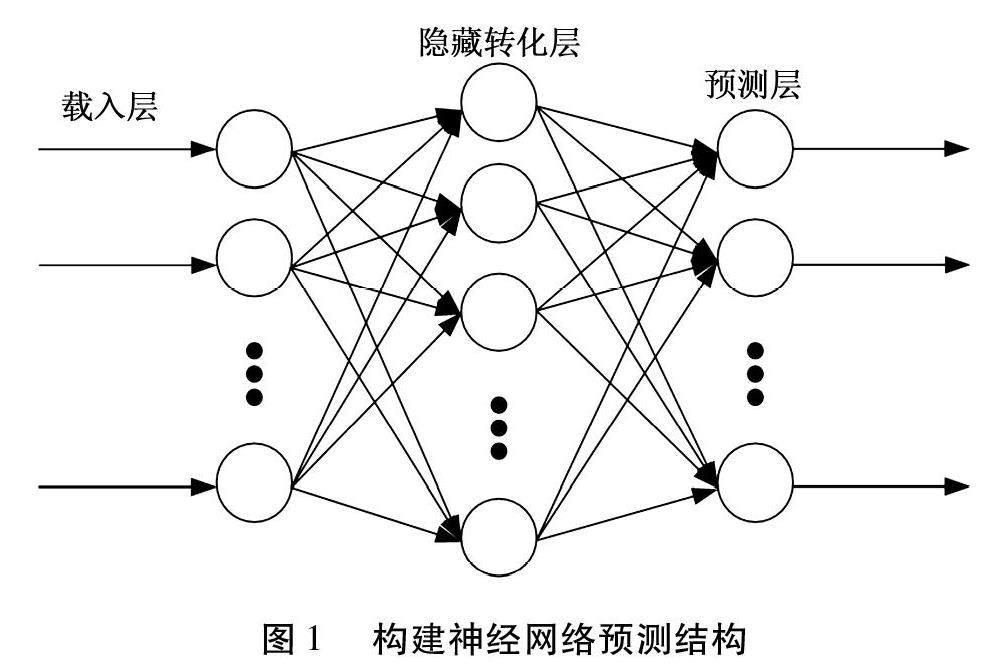
根据对以往中国大气雾霾数据变化特征的分析,结合短时瞬态时间预测参量分析中心分布情况,利用神经网络,构建预测结构。基于神经网络的三层结构,对其大气参量采集器获取的数据信息进行载入层输入,根据不同大气成分参量的分析,获得雾霾构成成分的预处理信息流,根据特征量对应的瞬时时间点对预处理信息流中的雾霾特征进行时间关联,通过神经网络中的隐藏转化层对其加以污染指数评估,获得短时大气雾霾的污染指数。同时,将神经网络分析指标量与实际污染质进行差量计算,获得评估污染指数偏置系数,通过构建神经网络中预测层的加权迭代修正,优化输出大气雾霾特征精度,为后续精准、高效预测打下数据基础。以下为构建神经网络过程中大气雾霾污染量配置计算的详细步骤:
Step 1:构建神经网络载入层,在该层下每一采集节点X上的雾霾采集数据均对应一个Y。构建神经网络中考虑到载入层与预测层神经元总数的统一与平衡问题,对神经网络构建后所得污染特征评估精度的影响,将载入层与预测层内的节点数量定义为已知量,进而可知对应的隐藏转化层数的计算公式为式(1):
式(1)中:H代表隐藏转化层内的节点总数,M,N分别代表载人层内节点总数与预测层内节点总数。最终得到构建的神经网络预测结构见图1。
Step 2:在隐藏转化层构建过程中,需要对输入的采集数据进行函数激活,为了确保隐藏转化层结构下采集量分类准确,采用Sigmod函数作为神经网络载入层的激活函数。隐藏转化节点h的计算公式如式(2):
式(5)中β代表神经网络的学习效率,根据历史经验,设计中将初始量设定为β=0.1-100。
Step 6:对评估预处理所得参量进行测量值比对,如果测量值满足下一环节计算标准,则配置网络预测层将其载入输出,若不满足下一环节计算标准则返回第二步。
考虑到神经网络自身对特征匹配量存在局部限制,因此为了完善构建神经网络结构,设计中参量节点的权值与阈值匹配均采用一次性随机策略,以此突破网络限制。
1.2雾霾污染函数选取
基于灰色关联理论中的灰色关联系数确定方法,对影响大气环境霾浓度的因素进行灰色关联度分析建立城市大气霾的影响因素与大气霾污染等级指标体系。在构建体系下完成神经网络空间内雾霾污染函数选取。基于神经网络内部参量的多目标优化属性,对其雾霾污染函数进行均方根误差MSE优化计算,计算具体步骤如下:
1.3大气雾霾短时预测层计算输出
为了更好地将神经网络应用到对短时雾霾浓度及AQI指数变化之间进行时间序列预测中,根据计算所得雾霾特征参量,对神经网络结构中预测层进行设计,以区分传统神经网络输出层结构特征,设计预测层以短时时间特征为预测量的评估标准,最大化调动该时间段内的所有节点信息,对此累积雾霾污染特征,构成连续性污染特征趋势,获得精准预测结果。
考虑到预测层内的节点数量对短时预测结果的精准度有着重要影响:若设计层中特征节点数量偏少,整体神经网络对应短时时间量的特征信息偏少,无法准确作出预测;若设计层中特征节点数量偏多,网络结构中的神经元过于活跃,容易出现预测结果的过拟合现象,并且增加神经网络预测的复杂度。因此,在设计预测层内部节点数量时,根据完成的载人层与隐藏转化层节点数量的计算公式,生成不同状况下的节点数量与预测结果配置公式。如式(9)~(13)所示:
2应用测试
对提出的预测方法进行性能测试,测试围绕雾霾短时样本展开。分为预测误差测试、随机预测响应测试与压力测试三个测试科目。测试数据采用中国多区域特征混采数据作为测试样本,由仿真测试工具随机组合;参与测试的对比样本分别基于PM2.5质量浓度特征分析的雾霾预测方法与混合算法的雾霾特征预测方法;两种方法在测试过程中的标签分别为:P1方法与P2方法;提出方法的测试标签为Ql方法;在相同样本预测试条件下完成设定项目,通过分析测试指标得出测试结论。
2.1设置测试条件
测试数据采用多区域特征混采数据,根据实际需求,应用采样器、重量测定仪等,随机选择合适的采样点,分别采集北京、泰安、唐山、哈尔滨四地2020年5-11月期间的相关数据作为实验样本。多区域大气雾霾采集监测点位置分布见图2。
图2中每个区域中设有3个监测点,测试样本数据为3个监测点采集数据的均值。
2.2预测误差测试
由仿真测试工具根据采集样本及随机组合的测试条件,对P1方法、P2方法及Q1方法进行大气雾霾预测误差测试,测试全程时长为120s,每种预测方法连续测试3次,测试结果生成的曲线,见图3。
由图3分析可得:(1)预测方法的预测结果存在不稳定因素,3次测试所得误差曲线线型特征差异较大,说明每一次预测Pl预测方法所采用的雾霾预测策略存在标准指数偏置量过大的问题;(2)通过分析图3(b)中的三条曲线波动情况可知,P2预测方法第1次预测结果相对稳定,误差值随时间推移逐步增大,误差值值域范围[0.59,0.78],第2次预测误差值域范围为[0.68,0.78];第3次预测误差值域范围为[0.58,0.92];由此可以看出P2方法误差为动态系数量,对应预测结果与实际雾霾短时变化特征差异较大;(3)由图3(c)中的曲线分布及其相似度可以看出,Q1方法3次所得结果差异最小,曲线走势平稳,无大幅度波动,说明方法在预测量函数控制方面具有优秀的控制能力;同时,3条误差曲线值域分布范围均在[0.2,0.3]之间;由此,综合上述每种方法的测试分析结果,可以得到该项目中最佳预测方法为Q1方法。
2.3随机预测响应测试
为了验证提出方法具备短时预测能力,对其响应速度进行测试,测试样本随机循环下发,样本总数为1000;每40组为一轮测试,计算每种方法响应时间的均值,并对其进行记录,连续记录25组响应均值数据,统计生成表1,对比分析表1数据,得出测试结论。(见表1)
根据表1显示的数据来看,P1预测方法在高强度响应压力测试下的表现较差,主要体现在均值数据之间的差值较大与数值变化无规律性;与其相同,P2预测方法同样存在相同问题,测试结果超出现阶段经验值[1.0~2.0]范围;相比之下,P1预测方法的测试表现更加出色,25轮测试全部数值均为最佳数值,且数据稳定,具有神经网络特有的线性规律,因此在实际应用过程中更加容易适应短时预测场景。综上所述,该项目测试中Q1方法以各项指标最优的成绩通过测试。
2.4压力测试
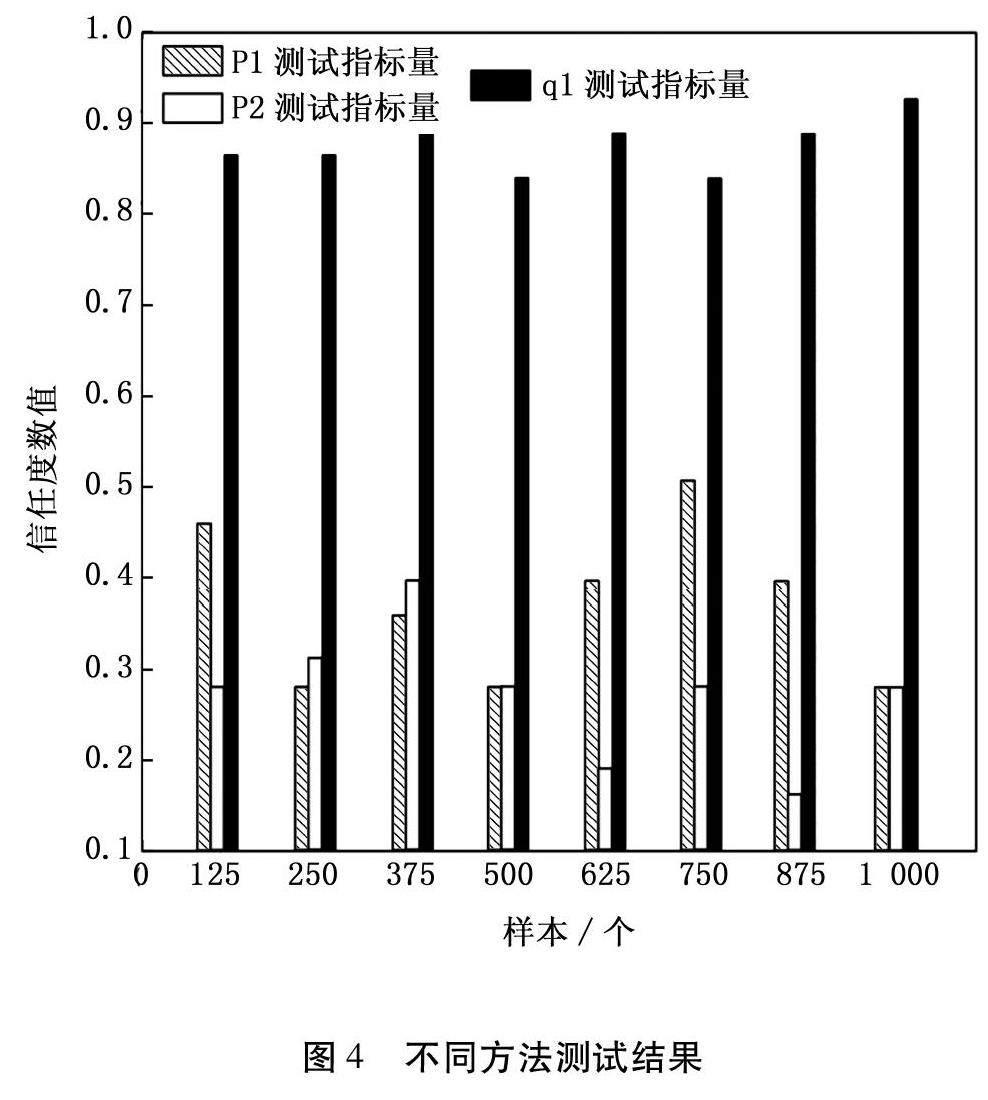
对提出方法进行整体性能的压力测试,测试指标采用信任度作为判定标准,即信任度数值越接近1.0,对应方法的可信度越高,对应方法的适应性与稳定性越好。为了避免不同数据样本带来的测试数据割裂问题,该项目样本数据采用2.3数据作为样本,为了方便对比统计阈值设定为125,具体测试结果见图4。
由图4数据分析可知,在1000样本下最大信任值为0.53,最小值为0.28,根据判定规则定义的指标量1.0,经过对比后可以发现最大值0.53最接近指标量1.0,但数值出现次数仅为1次,因此该信任结果不具有客观性,不予采纳;经过统计P1方法的最终信任值为0.35,对比判定其可信度偏低。基于此分析思路及方法,P2方法的信任值为0.25,Q1方法的信任值为0.87;到此可以直观的发现,Q1方法的信任度最高,相对应的方法性能最优,P1方法性能次之、P2最差。
3结束语
城市大气雾霾污染不仅会影响人体健康,还会对生态环境产生负面影响。通过研究城市大气雾霾污染的短时预测方法,可以提高城市环境管理的科学化和精准化水平,促进城市可持续发展。基于雾霾构成成分的预处理信息流,构建神经网络,在载入层中构建激活函数,分析短时大气雾霾的污染指数,对比实际污染特征系数差量,分析大气雾霾神经网络特征确定雾霾污染函数预测信息及其相关配置函数,对大气雾霾短时预测策略及其参量配置进行了深入优化,进行大气雾霾短时预测层计算输出,取得了较好的预测效果。城市大气雾霾污染的短时预测需要依托于先进的环保监测技术和数据分析方法,提供科学、准确的决策支持机制,这将推动环保技术创新和发展,提高环保技术的应用水平和效果。
