基于特征融合的异源图像匹配算法
2023-04-29冷雪飞李一能
郝 祥, 冷雪飞, 李一能
(1. 南京航空航天大学航天学院, 南京 211106;2. 南京航空航天大学导航研究中心, 南京 211106)
0 引言
导航系统是现代飞行器不可或缺的组成部分,它能为飞行器控制和任务规划提供必要的数据参数。 目前, 较为成熟的导航方式有惯性导航、 卫星导航、 视觉导航等。 视觉导航作为一种自主导航技术, 具有全天候独立工作、 低成本、 高精度的优势, 被广泛应用于飞行器导航中[1]。 然而, 特殊导航场景下图像获取困难成为推进其进一步工程化的技术难点。 随着成像技术的发展, 飞行器通过搭载多种传感器, 能在复杂环境下保证图像的稳定获取; 同时, 不同成像设备获得的异源图像具有更丰富的信息, 能提升飞行器视觉导航系统的适应性和导航精度。 如何从异源图像中获得更多有效信息、 摒弃冗余信息、 构建共性特征,成为异源图像匹配的热点问题。
异源图像成像手段各异, 图像特征各不相同,难以直接采用传统图像匹配算法实现异源图像匹配[2]。 基于深度学习的匹配算法, 能通过神经网络的学习能力完成图像匹配, 一定程度上克服了匹配特征差异大的问题。 例如基于CycleGAN-SIFT 的可见光和红外图像匹配[3]、 基于Yolov3 神经网络的快速图像精匹配算法[4]、 SFcNet[5]、 RF-Net[6]等,该类方法相比于传统的匹配方法能在异源图像上构建较多共性特征或者直接通过网络学习能力输出图像匹配结果, 但仍旧存在特征表述不全面、匹配精度差、 泛化能力差的缺点。
针对异源图像特征差异大、 匹配效果难以达到飞行器视觉导航领域精度和实时性要求的问题,本文提出了一种基于特征融合的异源图像匹配算法, 将特征融合后的图像应用于图像匹配领域,均衡融合了多方面特征, 大大提升了匹配精度。特征提取阶段, 采用Resnet-34 网络改进编码网络,在保证提取深度的基础上减少了网络参数复杂度;特征恢复阶段, 采用稠密连接改进解码网络, 提高了中间层特征的利用率; 特征融合阶段, 通过添加注意力机制的融合策略, 优化了异源图像信息占比; 特征匹配阶段, 采用改进的尺度不变特征转换(Scale Invariant Feature Transform, SIFT) 算法, 提升了异源图像匹配的精度。 实验结果表明,本文算法相较于常见方法在特征融合评价指标上具有优越性, 在图像匹配结果中能获得更多的匹配点、 更高的匹配精度。
1 基于深度学习的异源图像特征融合网络
应用于飞行器视觉导航领域的传感器图像多为可见光图像、 红外图像和合成孔径雷达(Synthetic Aperture Radar, SAR)图像, 图像特征主要是区域强度、 边缘细节特征。 本文提出的基于深度学习的异源图像特征融合网络, 其结构如图1 所示,主体结构由基于残差网络的编码网络、 基于注意力机制的融合策略、 基于稠密连接的解码网络构成。
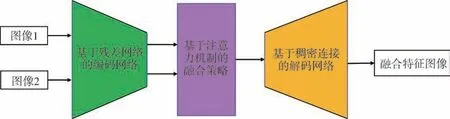
图1 网络结构示意图Fig.1 Schematic diagram of network structure
首先通过将源图像输入基于残差网络的编码网络, 获取对应的图像特征; 然后通过基于注意力机制的融合策略优化融合占比, 得到融合特征;最终通过基于稠密连接的解码网络, 完成图像的重构, 得到包含融合特征的图像。
1.1 基于残差网络和稠密连接的编码-解码网络
由于异源图像成像原理不同, 在同一事物的描述上可以通过不同类型的特征实现。 本文通过采用残差网络结构和稠密连接构建编码-解码网络,实现多层次特征的提取和融合, 极大程度上保留了利于图像匹配的有效特征, 减小了图像特征差异的不利影响。
训练过程为: 将编码网络和解码网络直接进行连接; 损失函数作为网络训练的约束条件, 计算输入为源图像和重构图像。 在此基础上, 获得具有图像特征提取和特征恢复能力的编码-解码网络。 特征提取功能由基于残差网络的编码网络实现, 特征恢复功能由基于稠密连接的解码网络实现, 编码-解码网络结构如图2 所示。
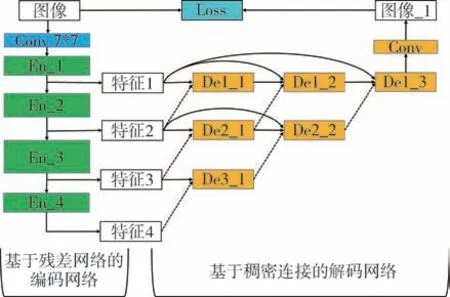
图2 编码-解码网络结构示意图Fig.2 Schematic diagram of encoding-decoding network structure
在特征提取阶段, 本文算法采用Resnet 网络[7]完成特征提取。 Resnet 网络通过添加短连接结构,能保证前后层级特征深度一致时不再进行重复计算, 在网络构成上避免了梯度消失、 减小了参数量。 因此, 解决了飞行器导航系统实时性和图像特征提取深度不能兼顾的问题。 此外, 异源图像特征差异大, 因此需要同时兼顾图像的浅层特征和深层特征。 通过Resnet 网络的残差块分布, 将网络主体分为步长为3、 4、 6、 3 的四个残差层,将中间层特征作为恢复关键信息使用, 极大程度上保留了异源图像的多层级信息。
在特征恢复阶段, 解码网络采用稠密连接的方式, 将多层级特征按照逐级递减的方式应用于图像恢复、 优化特征融合比例。 此外, 采用稠密连接分步恢复的方式, 将中间特征和更浅层次特征进行融合, 保证了特征融合过程中深度差别不大、 消除了语义差异。
1.2 基于组合系数的损失函数
异源图像特征描述不同, 难以直接用某种损失函数进行统一度量。 为了增强算法的泛化能力,本文采用了一种基于组合系数的损失函数兼顾图像的强度变化和结构变化, 函数数值越小, 两张图像相似度越高, 其表达式满足
式(1)中, 组合系数α能够调整Loss中Loss1和Loss2的比重, 均衡约束图像的强度变化和结构变化。Loss1通过计算原图像和编码-解码网络输出图像的均方误差(MSE)来表征图像相似性, 能反映图像的像素灰度变化和整体的强度分布。Loss1函数数值越小, 相似度越高, 其函数表达式如下
式(2)中,Iin为训练源图像,Iout为编码-解码网络输出图像,MSE(·)为均方误差计算函数。
式(1)中的Loss2主要从亮度、 对比度和结构上判断图像的相似程度, 能获得图像的结构和边缘特征的相似度, 对噪声有较强的抗干扰能力。Loss2函数数值越小, 相似度越高, 其函数表达式如下
式(3)中,msssim(·)为多尺度结构相似性计算函数, 其计算公式如下
式(4)中,M表示不同尺度;μp、μg为图像的均值;σp、σg为图像的标准差;σpg为两张图像之间的协方差;βm、γm为相应两项之间的重要性;c1、c2为非零常数, 防止分母为0。
基于组合系数的损失函数能兼顾图像的强度变化和边缘纹理变化, 但是组合系数需要通过实验测得对应的组合系数数值。 本文选取α=10、α=100 和α=1000 进行实验验证, 通过融合特征的评价指标进行评测(评价指标的具体含义在本文第4 节中表明), 实验结果如表1 所示。

表1 α 取不同数值时的特征融合结果Table 1 Feature fusion results when taking different values of α
由表1 可知, 在α=100 时取得最优结果, 因此后续实验参数按照α=100 设置。
1.3 基于注意力机制的融合策略
针对异源图像的特征在融合时权重占比存在差异的问题, 本文提出了一种基于注意力机制的融合策略。 首先通过通道注意力机制和空间注意力机制优化融合策略, 进而优化融合特征中的信息占比, 提高融合特征质量。 整体融合策略示意图如图3 所示。
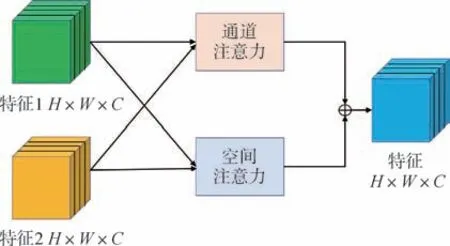
图3 基于注意力机制的融合策略示意图Fig.3 Schematic diagram of fusion strategy based on attention mechanism
将编码-解码网络获得的图像特征表示为H×W×C维度来说明空间注意力机制和通道注意力机制的工作原理。
空间注意力机制能够反映图像特征在H×W维度权重的不同, 能够在特征融合时使得强度更加突出的像素位置获得更高的权重, 其流程示意如图4 所示。
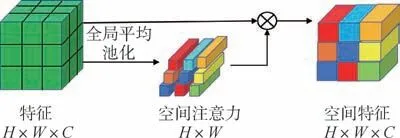
图4 空间注意力机制示意图Fig.4 Schematic diagram of spatial attention mechanism
首先, 通过全局平均池化的方式处理特征,获得H×W维度的特征权重图; 然后, 将权重图和特征相乘, 得到权重分配后的H×W×C维度图像特征; 最后, 将两张源图像的特征进行组合, 得到H×W×C维度组合特征fspatial, 组合方式如下
式(5) 中,Sw1为输入图像1 的空间注意力权重,Sw2为输入图像2 的空间注意力权重,feature1为输入图像1 的图像特征,feature2为输入图像2的图像特征。
通道注意力机制能够反映图像特征在C维度上的不同, 能够将多层特征中信息量更加丰富的层级赋予更高的权重, 通道注意力机制示意如图5所示。

图5 通道注意力机制示意图Fig.5 Schematic diagram of channel attention mechanism
首先, 通过平均池化的方式将特征在通道维度上进行信息统计, 得到信息量S, 其计算公式为
根据信息量数据获得C维度的权重向量; 然后, 将权重向量和特征通道相乘, 获取权重分配后的H×W×C维度图像特征; 最后, 将两张源图像的特征进行组合, 获得H×W×C维度组合特征fchannel, 组合方式如下
式(7) 中,Cw1为输入图像1 的通道注意力权重,Cw2为输入图像2 的通道注意力权重。
最后, 通过两种注意力机制处理编码网络得到的异源图像特征, 获取权重增强的图像特征,经组合获得最终融合特征ffus, 组合方式如下
式(8)中,fspatial为经过空间注意力模块增强的图像特征,fchannel为经过通道注意力模块增强的图像特征。
2 基于特征融合的异源图像匹配算法
在上述基于深度学习的异源图像特征融合网络的基础上, 本文研究了改进SIFT 算法实现最终阶段的匹配任务。 SIFT 算法在生成特征点方面,即使数量不多的目标物体也能生成数量较为可观的特征点。 但是由于生成特征点数量巨大, 匹配准确率需要进行一定程度的优化, 才能满足导航系统的要求。
本文基于改进SIFT 算法的图像匹配实现流程分为以下三部分:
1)特征检测: 首先将实测融合图像和机载参考图像通过高斯金字塔和高斯差分金字塔实现尺度空间的构建; 然后通过空间极值点检测寻找连续空间下不发生变化的点作为关键点; 之后通过高斯差分金字塔进行空间拟合, 得到极值点的精确位置和尺度, 同时去除在边缘位置的极值点, 提高关键点的稳定性。
2)特征描述: 针对上述特征点计算一定采集区域内的像素梯度和方向分布特征, 通过梯度直方图表示特征点方向信息。 其中, 直方图峰值表示关键点的主方向, 峰值大于主方向80%的方向作为辅方向。 之后, 确定图像区域为特定半径的圆形区域, 包含4 ×4 个子区域。 最后将关键点主方向作为所在区域方向, 对每个子区域进行8 个方向的直方图统计, 获得128 维描述向量, 完成特征描述子构建。
3)特征匹配: 获得两张图像的描述子之后, 在参考图像中取得关键点描述子, 然后遍历实测融合图像中的关键点描述子, 找到对应欧氏距离最近的一对关键点。 此时若最近距离与次近距离的比值小于预设阈值, 则判定为匹配点。 最后, 利用随机抽样一致性(Random Sample Consensus,RANSAC)算法进行匹配后错误特征点的剔除, 以提升匹配精度。 剔除过程中, 虽然损失了部分正确匹配结果, 但是对绝大部分正确匹配点没有影响, 能有效提升匹配的正确率。
3 基于特征融合的异源图像匹配总流程
本文的实际应用场景为飞行器导航, 携带传感器为多种异源图像相机, 主要算法流程如图6所示。
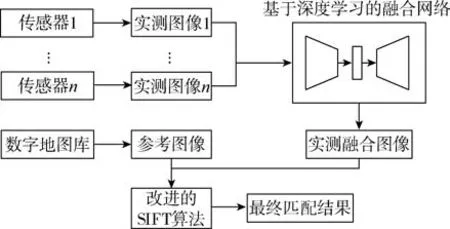
图6 算法流程图Fig.6 Flowchart of algorithm
如图6 所示, 飞行任务中, 首先通过飞行器携带的不同传感器获得实测异源图像; 然后将实测异源图像输入到本文提出的基于深度学习的异源图像特征融合网络中, 在训练好的编码-解码网络结构和注意力增强的融合策略下得到实测融合图像; 最后将实测融合图像和机载数字地图库中的参考图像通过改进的SIFT 算法进行匹配, 得到最终的匹配结果。
4 实验结果和分析
4.1 实验设置
本次实验的网络结构模型基于Pytorch 搭建和训练, 模型训练硬件环境为RTX3060Ti。
为了验证本文算法在真实航空应用场景中的效果, 选取来自携带多光谱相机的无人机采集的RIT-18 数据集[8]制作实验测试集, 该数据集包含可见光波段图像、 近红外波段图像。 特征融合实验测试集包含60 对图像尺寸为512 ×512 的红外/可见光图像, 异源图像匹配实验测试集包含60 对图像尺寸为512 ×512 和75 对图像尺寸为256 ×256的红外/可见光图像。
4.2 特征融合实验
为验证本文基于深度学习的异源图像特征融合网络的有效性, 本文选取了5 种特征融合算法进行比较分析。 其中, 包括3 种传统特征融合算法: 基于交叉双边滤波(CBF) 的融合算法[9]、 基于梯度转移融合(GTF) 的融合算法[10]、 基于曲波变换(CVT) 的融合算法[11], 2 种基于深度学习的特征融合算法: ZCA-Resnet[12]、 DeepFuse[13]。 对应的实验参数按照开源代码的参考文献进行设置, 融合的客观评价指标结果在matlab2019a 中计算得到。
(1)主观评价分析
图7 为不同特征融合算法对可见光/红外图像进行融合后的结果, 图7(a)和图7(b)分别为可见光图像和红外图像, 图7(c) ~图7(g)为各种对比融合算法的融合特征图像, 图7(h)为本文算法获得的融合特征图像。

图7 特征融合实验测试集的实验结果Fig.7 Experiment results of the fusion-test dataset
通过观察融合结果可知, 基于CBF 的融合图像中含有大量的噪声, 覆盖了一些关键特征点,在细节提取上也不够明显; 基于GTF 的融合图像整体展现较为模糊, 在边缘细节上基本没有保留,但是大面积噪声较少; 基于CVT 的融合图像在特征拼接上有明显的像素块边缘, 边缘对比度低,同时仍旧有少量明显噪声; 基于ZCA-Resnet 的融合图像基本没有噪声, 但是整体上特征不够突出,边缘细节保留较少; 基于DeepFuse 的融合图像边缘特征和视觉效果都较好, 但是在对应的弱对比区域强度信息保留不够完整、 对比度低; 本文算法的融合图像对图像的边缘纹理区域保留完整、对比度高, 在地面不同区域上区分明显, 能保留更多的强度信息。 在融合结果对比上, 本文算法取得了最优结果, 视觉效果自然、 图像对比度高、边缘结构细节更加突出。
(2)客观评价分析
为了在客观的角度上验证融合特征的质量,本文选取了信息熵(Entropy, EN)、 标准差(Standard Deviation, SD)、 互信息(Mutual Information,MI)、 结构相似性(Structural Similarity, SSIM)和图像视觉保真度(Visual Information Fidelity, VIF)作为评价指标。 其中, EN 表征了图像中包含信息的数量, 数值越大表示包含信息量越大; SD 反映了图像的分布和对比度, 数值越大对比度越高; MI 反映了从原图中获得信息的数量, 数值越大表示包含更多来自输入图像的信息; SSIM 从亮度和对比度的角度反映了图像结构上的相似程度, 数值越大相似度性越高; VIF 的数值和主观视觉评价有高度的相似性, 数值越大表示图像质量越好、 图像特征更加自然。
表2 展示了在特征融合实验测试集上60 对可见光/红外图像上特征融合结果客观评价指标的平均值对比。

表2 在融合实验测试集上的客观评价指标Table 2 Objective evaluation indicators on the fusion-test dataset
由表2 可知, 本文的融合特征在EN、 SD、 MI和VIF 上取得了最优值。 EN、 SD 和MI 上取得最优值, 表示融合特征中强度特征保留较好; VIF 上取得最优值, 表示生成的融合图像更加自然, 也符合图像的主观评价标准。 此外, SSIM 上取值与最优值差异不大, 表示本文算法的特征融合结果在对比度和结构相似性上有较好的效果。
综合评价, 本文提出的基于深度学习的异源图像特征融合网络在主观评价指标和客观评价指标上取得了较为均衡和优秀的结果。 同时, 针对不同种类的异源图像数据集都有较好的表现, 也说明了本文融合网络有较强的泛化能力。
4.3 消融实验
为验证本文特征提取模块中残差网络结构和注意力模块的优越性, 设置了以下消融实验。 其中, 去除残差模块时采用基础卷积模块完成特征提取, 在其他实验参数选择上与本文算法保持一致。 最后选取特征融合实验测试集进行了实验验证, 客观参数评价指标平均值如表3 所示。 表3中, “√” 表示该实验包含对应模块, 否则表示不包含该模块。

表3 消融实验在融合实验测试集上的客观评价指标Table 3 Objective evaluation indicators of ablation experiments on the fusion-test datasets
由表3 可知, 在去除注意力模块的情况下, 表示信息熵值的评价指标SD、 MI 有较大下降, 表明该模块在强度信息的保留上有较好效果。 在去除残差网络结构的情况下, 表示信息熵的评价指标EN、 SD、 MI 有较大下降, 表明去除残差网络结构模块后在源图像信息保留上有较大损失; 表示结构细节和图像整体效果的评价指标SSIM 和VIF 取得最优值, 表明残差网络结构模块在保留图像结构细节特征和较为深层的图像特征上有较好效果。
综合评价, 剔除任何一个关键组件都会导致融合特征质量下降, 只有在同时包含残差网络结构和注意力模块时, 融合特征取得最优评价指标,表明了关键组件的有效性。
4.4 异源图像匹配实验
为了验证本文算法在实际应用场景中的有效性, 将飞行器搭载异源相机拍摄的基准图像与实时可见光图像、 实时红外图像、 实时融合特征图像构建对比实验, 选取来自RIT-18 数据集中60 对图像尺寸为512 ×512 和75 对图像尺寸为256 ×256的红外/可见光图像作为实验测试集。
实验分别在无干扰情况和旋转情况下进行,评价指标为正确匹配特征点数量、 匹配正确率、匹配时间。 匹配正确率计算公式为P=C/T,P为匹配正确率,C为正确匹配点对数,T为总匹配点对数。 匹配正确率能反映目标图像和基准图像进行匹配时得到的关键点位置的对应关系, 正确率越高, 最终导航坐标的解算精度越高。 融合特征的匹配实验中, 匹配时间包含了实时异源图像的在线特征融合时间。
无干扰情况下, 基准可见光图像与目标图像的匹配结果如图8 所示。

图8 无干扰情况下的匹配实验结果Fig.8 Results of matching experiment without interference
由图8(a)可知, 由于两张图像亮度差异较大,在像素梯度变化上不明显, 难以形成大量有效的匹配点; 由图8(b)可知, 由于两张图像成像手段不同, 特征差异较大, 难以直接形成有效匹配; 由图8(c)可知, 由于融合特征包含可见光图像和红外图像的优势特征, 特征区域获得了有效增强, 因此具有数量较多的匹配点, 且匹配点分布较为均匀。
在导航场景应用中, 基准图像和目标图像经常存在角度差异的情况, 因此所提算法应有一定的抗旋转能力。 为了验证所提算法的抗旋转能力,将基准图像旋转15°进行匹配实验, 匹配结果如图9 所示。

图9 旋转情况下的匹配实验结果Fig.9 Results of matching experiment under rotating condition
由图9 可知, 由于待匹配图像间的角度畸变,容易出现大量的误匹配点。 图9(a) 中, 获得的匹配点基本都是错误匹配点, 无法实现有效匹配;图9(b)中, 匹配点数量较多, 但只存在少量正确匹配点, 匹配精度过低; 图9(c) 中, 总体特征点数量较多, 基本都是正确匹配点, 且在图像上分布较为均匀, 对不同的图像区域都能进行较好的匹配。
以正确匹配点数量、 匹配正确率、 匹配时间作为评价指标, 实验测试集在无干扰情况下的匹配实验数据如表4 所示, 在旋转情况下的匹配实验数据如表5 所示。
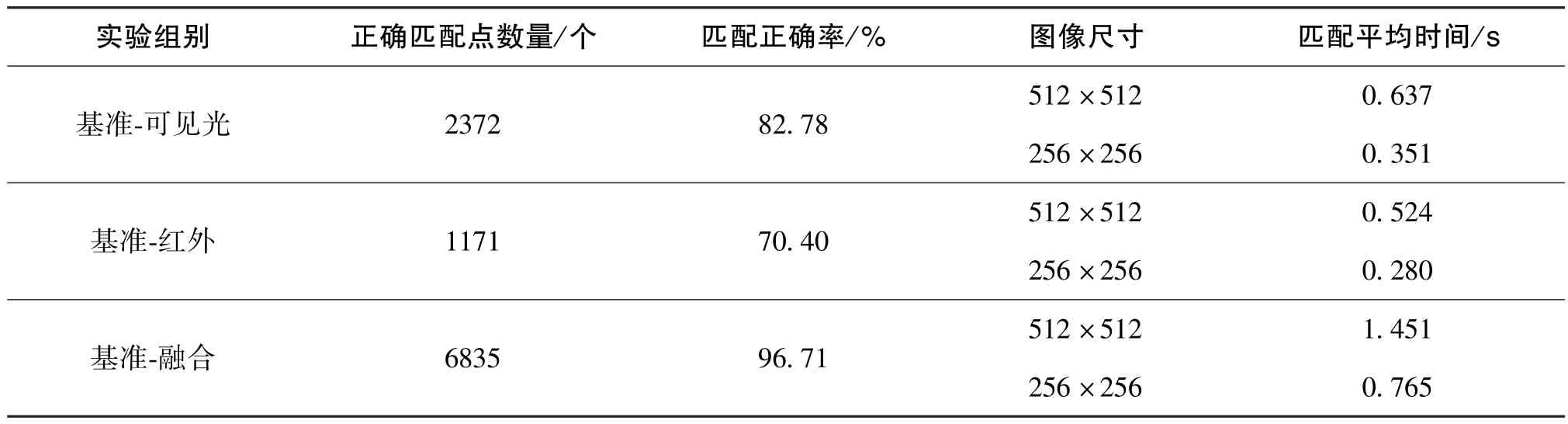
表4 无干扰情况下的匹配实验数据Table 4 Data of matching experiment without interference
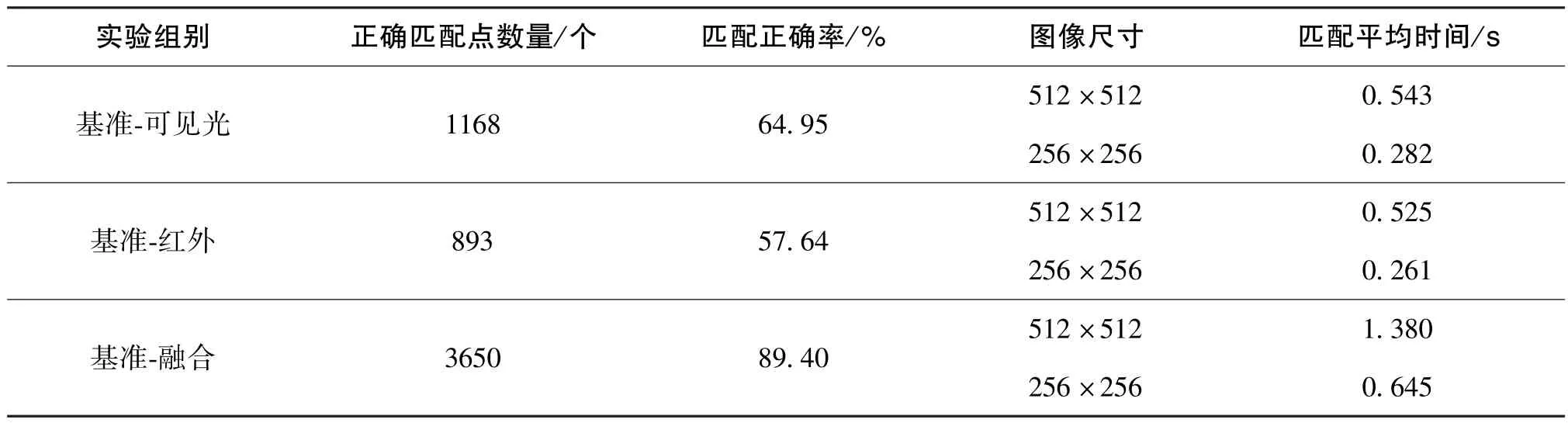
表5 旋转情况下的匹配实验数据Table 5 Data of matching experiment under rotating condition
由表4 可知, 无干扰情况下相较于直接进行异源图像匹配, 本文算法有以下优势:
1)正确匹配点数量为6835 个, 相较于可见光图像提升了188.15%, 相较于红外图像提升了483.69%。
2)匹配正确率为96.71%, 相较于可见光图像提升了16.83%, 相较于红外图像提升了37.37%。
3)匹配时间上, 本文算法受图像尺寸影响较大, 在512 ×512 的实验数据上能保持在1.451 s,在256 ×256 的实验数据上能保持在0.765 s。 匹配时间基于目前的实验设备进行计算, 在获得硬件提升和并行算法应用的情况下, 能满足导航系统的实时性要求。
由表5 可知, 旋转情况下相较于直接进行异源图像匹配, 本文算法有以下优势:
1)正确匹配点数量为3650 个, 相较于可见光图像提升了212.50%, 相较于红外图像提升了308.73%。
2)匹配正确率为89.40%, 相较于可见光图像提升了37.64%, 相较于红外图像提升了55.10%。另外, 匹配正确率相较于无干扰情况实验下降较少, 也表明本文算法在匹配任务上具有更好的鲁棒性。
3)匹配时间上, 在512 ×512 的实验数据上能保持在1.380 s, 在256 ×256 的实验数据上能保持在0.645 s, 与无干扰情况相差不大。 匹配时间基于目前的实验设备进行计算, 在获得硬件提升和并行算法应用的情况下, 能满足导航系统的实时性要求。
综合评价, 本文算法在异源图像匹配上具有数量更多的特征点; 匹配正确率无干扰情况下为96.71%, 旋转情况下为89.40%; 匹配时间在合适图像尺寸时能满足导航系统的实时性要求; 相较于传统匹配算法, 本文算法精度更高、 鲁棒性更强。
5 结论
本文提出了一种基于特征融合的异源图像匹配算法, 该算法通过基于深度学习的异源图像特征融合网络获得融合特征, 之后通过改进的SIFT算法完成异源图像匹配。 首先, 通过对编码-解码网络的训练, 得到能够完成特征提取和特征恢复的网络模型; 在编码结构中采用了残差网络, 增强了网络的深度学习能力, 能够获得更深层次的特征; 在解码过程中采用稠密连接的方式将中间层特征用于图像恢复, 保留了更多的浅层特征。然后, 采用基于组合系数的损失函数, 实现了同时保留图像强度信息和结构信息; 此外, 引入包含注意力机制的融合策略来优化信息占比。 之后,采用改进的SIFT 算法实现了基准图像和融合特征图像的匹配。 最后, 在公开数据集上对本文算法的融合特征和异源图像匹配效果进行了实验验证。实验结果表明, 本文算法在多种异源图像数据集的特征融合上具有优越性, 在可见光/红外异源图像匹配上具有特征数量多、 匹配精度高、 鲁棒性强的优点。
