无人车基于激光雷达/视觉的目标体积自动测量方法
2023-04-24郑国庆赖际舟范婉舒
郑国庆,吕 品,赖际舟,方 玮,范婉舒
(南京航空航天大学自动化学院,南京 211106)
0 引言
近年来,无人车在园区巡检、安全检查及交通运输等工业场景得到了广泛应用。激光雷达和视觉传感器被用于无人车的目标识别、路径规划及自主定位等多个领域[1-3]。通过激光雷达与视觉信息融合,可以实现对环境与目标的可靠感知,对于无人车的自主运行具有重要意义。
近年来,基于立体视觉的物体体积测量方法[4-5]得到了国内外学者的关注。文献[6]提出了一种基于双目立体视觉的小型煤堆体积测量方法,通过提取双目视觉采集图像中的SURF特征进行匹配,实现了小型煤堆体积的非接触测量。然而,基于视觉的物体体积测量方法存在受光照影响大、计算时间长等缺陷。而激光扫描仪扫描线束密集,且测距精度高,广泛应用于测绘领域。文献[7]提出了一种基于三维激光扫描技术的粮食储量在线监测方法,可对粮食体积进行有效测量。然而,激光扫描仪数据量较大,大多采用离线方式解算,且主要用于固定场景的静态测量。
激光雷达具有全天候、高精度的优点。目前激光雷达较多用于无人车的实时定位与构图(simultaneo-us localization and mapping,SLAM)。常用的二维激光雷达SLAM算法包括Hector SLAM[8]、Gma-pping[9]和Cartographer[10]等,其中Cartographer采用因子图优化的方法,鲁棒性强,能在大规模复杂场景下实现精确的定位和地图构建,代表了2D SLAM的最高水平。常见的三维激光雷达SLAM算法有LOAM[11]、LeGO-LOAM[12]和SuMa++[13]等,其中LeGO-LOAM在LOAM算法的基础上,使用两步法计算位姿变化,降低了计算负担。同时该算法经过了闭环优化,较LOAM算法稳定性更高,计算负担更低,适合在低性能的嵌入式上使用,在室内和室外场景均得到了广泛应用。通过激光雷达还可以实现对物体轮廓的扫描,从而估计其体积。文献[14]利用激光雷达获取物体的原始点云,使用隐式曲面重建算法构建了三维点云的mesh网络模型,从而求取空间体积。该方法主要用于室内房间测量,且需事先安装定位滑轨获取激光雷达的实时位置,自主性受到一定限制。
针对于此,本文提出了一种基于激光雷达/视觉的物体体积自动测量方法。以无人车为载体,在LeGO-LOAM算法的基础上进行点云畸变补偿,获得了精度更高的无人车位姿与三维点云地图。同时将视觉与激光雷达融合获取目标物的点云轮廓,通过点云切片的方法对目标物点云快速切割并进行体积计算,实现了无人车在行驶情况下对静态目标体积的测量。本文方法可以实现无人车对目标物体的实时、自动测量,对于提升无人车的自主化能力具有积极意义。
1 基于激光雷达/视觉的目标体积自动测量算法架构设计
传统目标体积测量通常假设测量仪器位姿已知或静止,继而将物体轮廓在确定坐标系中拟合,其在无人车自主测量中的使用受到一定限制。针对于此,本文提出了一种面向无人车的激光雷达/视觉目标体积自动测量方法,其架构如图1所示。首先,在LeGO-LOAM算法的基础上对点云进行畸变补偿处理,利用畸变补偿后的点云依次进行特征提取、特征匹配与构图优化等步骤,提升了无人车的构图与定位精度;接着,将视觉与点云信息融合,获得目标的位姿,从而获得目标在点云地图中的绝对位置,并利用地面点剔除得到目标点云;最后,对目标进行聚类和降噪处理,获取目标的点云轮廓,并采用点云切片法实现目标体积的实时解算。

图1 激光雷达/视觉目标物体积测量算法框架Fig.1 Framework of lidar/vision target volume measurement algorithm
2 基于无人车的物体体积自动测量算法
2.1 基于改进LeGO-LOAM的构图定位方法
对物体体积进行动态测量需要无人车自身的实时运动信息以及目标轮廓。LeGO-LOAM是无人车常用的SLAM方法,其在LOAM的基础上增加了回环检测,且更加轻量化。LeGO-LOAM对激光雷达点云进行特征提取和帧帧匹配,在机动情况(如转弯)下点云地图会产生畸变。为了提升定位精度和地图质量,本文利用高频的惯性测量单元(inertial measurement unit, IMU)和里程计信息对点云进行去畸变补偿,继而利用去畸变后的点云进行特征提取,整体流程如图2所示。

图2 改进LeGO-LOAM构图定位流程图Fig.2 Flow chart of improved LeGO-LOAMcomposition and positioning
2.1.1 点云畸变补偿
传统激光雷达去畸变算法仅利用IMU数据,对一帧点云中的每个点进行线性插值,获得其相对于扫描开始时刻的位姿变化。然而,仅靠IMU解算的相对位置误差较大,通过增加车载里程计信息可以有效提高相对位置估计精度。因此,本文利用IMU角速度信息与车载里程计进行航位推算,并对激光雷达点云进行畸变补偿处理。
设pi,i=1,2,…,l为一帧点云中的一点,点云扫描的开始时间为t0,pi到t0的相对时间为ti。扫描到该点前已产生n个IMU数据,其中每个数据相对于t0的间隔时间为tj,j=1,2,…,n。则扫描到该点时获得的相对于t0的角度变化量为

(1)

(2)

(3)
经过去畸变补偿的单帧点云前后对比如图3所示。可以看出,经过畸变补偿后,点云的畸变现象得到明显改善。

图3 点云畸变补偿对比Fig.3 Comparison of point cloud distortion compensation
2.1.2 特征提取
本文采用LeGO-LOAM算法的特征提取方式,将去畸变之后的点云PLi投影至距离图像Da×b中,a表示雷达线束,b表示激光雷达的水平分辨率。距离图像Da×b中的每个像素对应PLi中的每个点pt,其像素值ri表示pt到激光雷达中心的欧式距离。对距离图像进行聚类分割,剔除容易造成误差的干扰点,并得到分割后的点云Lt。对分割后的点云进行特征提取,计算距离图像中一行点云的曲率c
(4)

2.1.3 匹配构图
(5)
(6)

2.2 目标物体自动识别与体积测量
为实现目标物体体积的自动测量,本文在无人车上搭载激光雷达与视觉传感器,算法整体框架如图4所示。首先通过目标检测模块获取目标物体在图像中的位置,并利用视觉成像进行坐标解算,实现对该物体的绝对位置的求解。继而将包含目标物的点云进行地面点剔除,并对目标物进行聚类、降噪及滤波,获得目标物体的点云轮廓。最后利用切片法对目标物的体积进行估计。

图4 基于激光雷达/视觉融合的目标体积测量算法流程Fig.4 Flow chart of target volume measurement algorithm based on lidar/vision fusion
2.2.1 目标定位

(7)
为解算目标三维位置,首先根据目标检测算法获取其在平面图像上的二维位置(x,y,w,h),其中(x,y)表示目标中心坐标,(w,h)表示目标宽与高,其具体流程可参照YOLO(you only look once)算法[16]。设O-u-v为图像坐标系,其固定在成像平面上,O点位于图像左上角,u轴向右与x轴平行,v轴向下与y轴平行。基于检测框信息与对齐深度图,取(x,y)为目标二维平面位置,设其对应于图像坐标系下的坐标(u,v)。代入视觉传感器的内参矩阵K,可得检测目标三维位置为
(8)

(9)
2.2.2 地面点剔除
对目标点云进行聚类时,会误将地面点云当作物体点云,因此在对目标点云聚类之前首先需剔除地面点。本文通过平面拟合算法对地面点进行平面拟合,可实现地面点的有效分割与剔除。
首先在去畸变点云Pdistor中筛选高度最低的部分点作为种子点集合Pseeds,继而基于随机抽样一致(random sample consensus, RANSAC)算法[17]对Pseeds进行平面拟合,可以获得地面平面模型。之后,计算原始点云中的每个点到平面的距离disti,i=1,2,…,l,l为点云个数。当点到平面的距离小于设定的距离阈值Thdist时,被当成新的种子点。之后重复以上操作,直到当前拟合平面的法向量与上一次拟合平面法向量的夹角θ之差小于一定阈值。此时的种子点即为地面点,记为Pground;其余点为非地面点,记为Pno_ground。
2.2.3 目标体积计算
在获得目标点云与目标的全局位姿之后,通过点云拼接、聚类可以获得物体的点云轮廓,此时即可对物体进行体积计算。以目标物位置为中心,进行欧式聚类可得到目标物的表面点云[18]。利用点云的法向量信息,剔除目标点云噪点,可获得目标点云轮廓。切片法是在传统切段法基础上改进的物体体积测量方法,通过对物体点云轮廓切片求取体积,具有测量精度高、测量稳定性强等优点[19]。在切片法中,当切片足够小时,可认为切片的体积等于切片的面积与切片厚度的乘积,逐个将切片体积累加即可获得物体的体积。
如图5所示,本文自上而下将目标的点云切成b段,设目标高为H,则每段的厚度为

图5 激光雷达点云切片法原理示意图Fig.5 Schematic diagram of lidar point cloud slicing method
(10)
此时,对目标体积的计算可转换为每段的面积Si,i=1,2,…,b的计算。每一段是由单个点pj=(xj,yj),j=1,2,…,u构成的多边形Ai,其中u为Ai中的点数。在计算Ai面积时,首先需要将点云按照一定方向排序。在Ai中选择一个点ps,搜索其最近点获得pe,两点相连可以得到多边形的一条边。然后从剩下的点中搜索离ps(pe)最近的点p,并计算其到ps(pe)的距离ds(de)。若ds≤de,则将点p沿着ps方向更新ps,反之将点p沿着pe方向更新pe。依此类推,直到Ai中所有的点被搜索完。此时可以得到按顺序排列的多边形Ai点云。假设Ai中有u个点云p0,p1,…,pu=p0按逆时针排列,则Ai的面积Si为
(11)
继而可以根据每个多边形的面积,求解目标物的体积为
(12)
3 仿真与试验验证
在本文研究中,通过激光雷达和视觉实现对目标体积的自动实时测量。为验证本文提出算法的有效性,首先利用Gazebo仿真软件搭建测量环境,模拟三维目标物体对算法精度进行验证。继而构建了无人车试验系统,在室外对真实物体的体积进行测量。
3.1 基于Gazebo的仿真验证与分析
仿真平台采用Gazebo机器人仿真系统,Gazebo可以设计具体的三维仿真环境,能够对无人系统和传感器进行高保真的物理模拟。仿真平台如图6所示,主要包括:

图6 仿真场景构建Fig.6 Simulation scenario construction
1)Summit_xl小型无人车载体,车体可发布实时位姿真值,可添加误差值对体积测量误差进行分析;
2) OS164线激光雷达,水平线数为2 048,水平视场360°,垂直视角±22.5°,测距误差±1.5 cm,测距范围0~120 m。
在上述环境中,设置了6个待测目标物体。通过本文算法对其体积进行测量,测量结果如表1所示。

表1 仿真环境下的测量结果Tab.1 Measurement results in simulation environment
由图6和表1可以看出,本文提出的方法可以实现对6个目标物体体积的准确测量。其测量误差最大为1.77%,平均相对误差为0.99%。
3.2 试验验证与分析
为了验证本文所提算法的实际性能,在室外搭建了试验场景,如图7所示。由于不规则物体的体积真值较难测量,因此选择定制的长方体和圆柱体

图7 试验器材与试验场景Fig.7 Test equipment and test scenario
道具作为目标物,并将规则物体堆叠模拟不规则物体,长方体与圆柱体尺寸的定制精度可以达到0.001 m。试验中使用松灵SCOUT无人车平台,搭载了Besos GX01微型主机、Intel RealSense D435i相机、OS1-64线激光雷达与FSS-6132 IMU。各传感器性能参数如表2所示。

表2 传感器性能参数Tab.2 Sensor performance parameters
3.2.1 定位试验
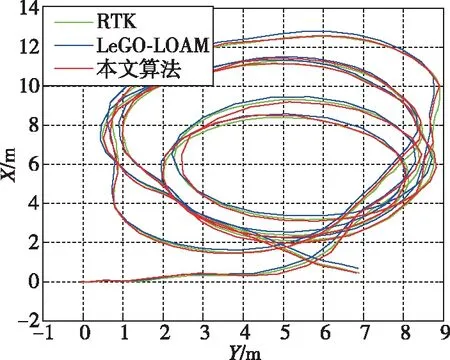
定位试验中,无人车搭载激光雷达、IMU、实时动态定位(real-time kinematic, RTK)在试验场地以1.5 m/s的速度行驶,以RTK的定位结果作为基准,构图结果如图8所示,定位误差对比如图9和表3所示。

表3 试验场景下LegGO-LOAM和本文算法的RMSE和最大定位误差对比Tab.3 Comparison of RMSE and maximum positioning error between LeGO-LOAM and the algorithm in this paper in the test scenario

(a) LeGO-LOAM构建的点云地图

(b) 本文算法构建的点云地图图8 点云地图构建对比Fig.8 Comparison of point cloud map construction
(a) 试验轨迹

(b) 定位误差图9 试验轨迹与定位误差Fig.9 Test track and positioning error
由图8、图9和表3可以看出:
1)LeGO-LOAM算法在构建地图时,地图产生了较为明显的形变。而本文算法可以有效改善地图形变问题,构图精度得到提高。
2)LeGO-LOAM的全程定位均方根误差(root mean square error,RMSE)为0.092 m,本文算法的全程定位RMSE为0.057 m,定位精度提升了38.0%。
同时LeGO-LOAM的最大定位误差为0.314 m,而本文算法的最大定位误差为0.165 m,最大定位误差减少了47.5%。
3.2.2 体积测量试验
设置6个测量目标,定制了2个长方体泡沫与2个圆柱体泡沫,并将规则物体堆叠模拟不规则物体。无人车在测量目标周边3 m内运行,并进行目标体积测量,其场景如图10所示。表4所示为目标体积测量结果。

图10 试验场景与测量过程Fig.10 Test scenario and measurement process

表4 试验测试结果Tab.4 Test results
由图10和表4可以看出,6个目标体积测量最大相对误差为4.08%,平均误差为2.61%,其中组合体的体积测量精度分别为1.33%与2.89%。相对仿真实际试验测量精度有所下降,其主要原因为:当实际试验时,定位精度降低导致物体点云轮廓拟合效果变差,测量误差随之增加。
4 结论
本文面向无人车对目标体积测量的需求,提出了一种基于激光雷达/视觉的无人车目标体积自动测量方法。该方法利用IMU数据与车载里程计信息对原始LeGO-LOAM算法进行改进。基于目标识别定位、地面分割及点云聚类,实现了目标物点云轮廓的自动提取,并设计了激光雷达点云体积切片计算方法。仿真和试验结果表明:
1)基于畸变补偿的改进LeGO-LOAM算法在高速情况下能够明显补偿点云畸变,提升了定位精度与构图效果;
2)基于激光点云切片的目标体积计算方法可以实时测量目标的体积,实现了无人车对目标体积的测量。
