去主元相关性DKPCA故障检测与诊断方法
2023-04-21韩宏宇
张 成,韩宏宇,李 元
(1.沈阳化工大学 理学院,辽宁 沈阳 110142;2.沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110142;3.沈阳化工大学 信息工程学院,辽宁 沈阳 110142)
0 引 言
随着现代工业对产品质量和生产安全要求的逐步提高,基于数据驱动的多元统计过程监控(Multivariate Statistical Process Monitoring,MSPM)得到了广泛的应用[1-2]。
针对多变量监控问题,传统的主元分析(Principal Component Analysis,PCA)监控方法可以很好地用于稳态线性过程,或者用于监控非线性过程的局部操作区域(近似线性)[3-4]。但是将PCA方法应用于非线性或动态过程可能导致低效和不可靠的过程监控,主要原因是线性静态的PCA方法不适合描述过程变量中的非线性或动态特征。为了有效地监控非线性过程,基于核主元分析(Kernel PCA,KPCA)的多元统计过程监控方法被应用于工业过程[5]。然而,KPCA并没有考虑变量的时间相关性,即数据具有动态性时,KPCA的监控性能就受到制约。为了描述数据的动态特征,Ku等提出了一种动态主元分析(Dynamic Principal Component Analysis,DPCA)方法[6],即将PCA应用于一个时间滞后的数据矩阵[7-8],从而将样本之间的相关性转化为变量之间的相关性。DPCA监控方法也只适用于线性过程,如果将DPCA方法应用于动态非线性过程监控,那么该方法的监控性能就受到制约。为了解决动态非线性过程的监控问题,Choi等提出了一种基于动态核主元分析(Dynamic KPCA,DKPCA)[9]的过程监控方法。DKPCA的主要思想是在执行KPCA之前对数据矩阵进行了时滞扩展。虽然DKPCA能提取数据的非线性特征和动态特征,检测结果也优于KPCA和DPCA的结果,但是通过大量的实验证明,统计量T2上仍含有显著的自相关性[10],这说明通过时滞扩展并没有彻底解决数据含有动态性的问题。
针对上述问题,该文提出一种基于去主元相关性的DKPCA动态非线性过程故障检测与诊断方法(Dynamic Kernel Principal Component Analysis basedon Removing Principal Component Correlation,DKPCA-RPCC),其基本思想如下:首先,将低维数据引入时滞参数构成增广矩阵,再通过KPCA方法计算增广矩阵的主成分,称为真实得分;其次,假设当前时刻样本缺失,利用前移时刻样本估计当前值,构成新的增广矩阵,再按照相同的方法计算新矩阵的主成分,称为预估得分;然后,使用真实得分与预估得分之间的差异来构建统计量进行故障检测;最后,利用基于变量贡献图的方法进行故障诊断。该方法在DKPCA的基础上去除主元之间的相关性,能够最大限度地降低样本之间动态性的影响。
1 动态核主元分析
动态核主元分析[9]的核心思想是在应用KPCA之前对数据矩阵进行时滞扩展。该方法不仅可以描述变量之间的非线性特征,而且由于加入了额外的时移变量,所以也能描述变量之间的自相关性和滞后交叉相关性。此外,通过选择适当时移数l,使得变量之间的非线性和动态关系都出现在方差较小的主元所对应的噪声子空间中[11]。
(1)
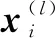

(2)
Cp=λp
(3)
通过φ映射之后,原始数据在高维空间的维数较大,无法直接计算特征值和特征向量,因此引入径向基核函数,通过核技巧间接计算高维空间数据集的特征值和特征向量,从而简化计算。
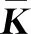
(4)

(5)
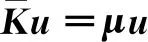
(6)
在高维空间中,样本协方差矩阵的特征向量和特征值与核矩阵的特征向量和特征值之间存在以下关系,如式(7)所示。为了简化计算,将协方差矩阵的特征向量单位化,得到单位向量p,如式(8)所示。高维空间中数据集的得分ti可通过式(9)计算得到,其中P为协方差的特征向量矩阵,U为核矩阵的特征向量矩阵。
(7)

(8)
(9)
DKPCA的监控指标[9]如式(10)所示:
T2=tΛ-1tT
(10)
其中,Λ是由特征值λ组成的对角矩阵。
2 基于去主元相关性的DKPCA故障检测和诊断方法
DKPCA方法通过时滞扩展并没有完全解决数据具有动态性的问题,这导致统计量仍含有较强的自相关性[10]。为了解决这一问题,将DKPCA与缺失值处理技术[11]相结合并利用主成分的差异构建统计量。
具体方法如下:在DKPCA中,建立一个包含当前与过去测量值的矩阵Y。对于每个新的观测向量yi可以计算得分。假设当前的观测向量缺失,可以使用缺失值处理技术,从过去的数据中估计出当前时刻的测量值并计算得分,这本质上是对得分和观察值进行了一步预测。因此,得分之间的差异几乎是连续非相关的[8],这意味着可以使用得分差异更好地对样本进行监控。所选择的缺失值处理技术为条件均值替换法[12],该方法对缺失数据的测量矢量进行重新排列,不失一般性。
(11)
式中,Y#表示缺失的测量值,Y*表示已知的测量值。
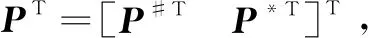
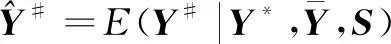
(12)
假设增广矩阵已知。为了计算缺失向量的观测值,只需要EM算法的期望步骤,把P代入到S的表达式,可以得到式(13)。使用式(13)可以计算缺失观测值的条件期望,如式(14)所示。

(13)
(14)
最终可以得到一个新的矩阵,如式(15)所示。
(15)
M=K1U
(16)
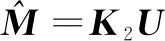
(17)


(18)
(1)离线建模。
第一步:对训练数据集X进行标准化。
第二步:根据时移l生成增广矩阵Yx,然后通过KPCA计算真实得分Mx。
第四步:根据式(18)计算统计量W,使用核密度估计方法[15]确定控制限WUCL。
(2)在线检测。
第一步:对测试样本应用训练数据的均值和方差进行标准化。
第二步:根据时移l生成增广向量Yfi,使用训练数据的核矩阵进行中心化,求出测试数据的真实得分Mfi。

第四步:根据式(18)计算测试样本的Wi,若Wi>WUCL,则判定Yfi为故障样本,否则Yfi为正常样本。
(3)故障诊断。
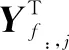

(19)
3 仿真实验
3.1 数值例子
使用一个非线性动态数值例子[9]测试文中方法的有效性,具体模型如式(20)所示。

(20)
其中,u(t)、y(t)、z(t)分别是输入变量、输出变量以及状态变量,o(t)是服从均匀分布U~(0,0.5)的随机噪声,w(t)是服从均匀分布U~(0,5)的白噪声,系统A、B、C、D、w(t)、o(t)分别为:





其中,非线性映射函数f(u(t))如式(21)所示:
(21)
由以上模型随机生成1 000个正常数据作为训练样本,然后,在变量w1加上一个幅值为-4.5的阶跃变化作为故障数据。再由该模型生成100组测试数据集,每组测试数据前500个为正常样本,后500个为故障样本。输出变量u(t)、y(t)被用于过程监控。采用DPCA、KPCA、DKPCA以及文中方法对此动态非线性过程例子进行仿真实验,并对上述的四种方法的结果进行分析。
采用DPCA对该数值例子进行故障检测时,按照95%的累计方差贡献率选取主元,因此主元数设置为5。按照平行分析法[17],时滞参数的选取与特征值有关,特征值为0或接近于0时表示变量之间线性无关,因而时滞参数l的值等于特征值为0或者接近于0的个数[6]。DPCA提取的主元之间含有较强的相关性,特别是前两个主元之间的相关性最大,这将导致计算的统计量T2也含有较强的自相关性,严重影响故障的检测结果。
采用KPCA对此数值例子进行故障检测时,通过经验法[18]确定核宽参数的范围以及选取最优核宽参数。低维空间的数据集通过非线性函数映射,使得数据在高维空间线性可分,此时故障样本与正常样本之间的差异最大,检测结果达到最优。采用DKPCA对此数值例子进行故障检测时,核宽参数σ和时滞参数l采用经典的网格搜索和交叉验证[19]方式进行选取,该方法选取不同的参数时,训练数据的准确率如图1所示。

图1 校验数据的准确率
采用文中方法进行故障检测时,核宽参数与时滞参数的选取均与DKPCA保持一致。图2给出了上述四种方法对于100组测试数据的检测结果,由图2可以看出,文中方法的检测结果明显高于其他三种方法且平均检测效率最高。图3表示四种方法统计值自相关性的对比。由图3可以看出,DPCA、KPCA和DKPCA方法的统计值都含有较强的一步自相关性,而文中方法的统计量的自相关性明显降低,因此能够提高故障检测率。图4给出了文中方法对第一组数据的故障检测结果,由图4可知,故障样本与正常样本几乎完全分离,证明了文中方法的有效性。使用公式(19)对测试数据进行故障诊断,测试数据集10个变量对样本的贡献程度,如图5所示,从图5可以看出第4、9变量的贡献度较大,所以故障发生与这两个变量的相关性最大。

图2 四种方法故障检测结果

图3 统计量的自相关性

图4 DKPCA-RPCC故障检测结果
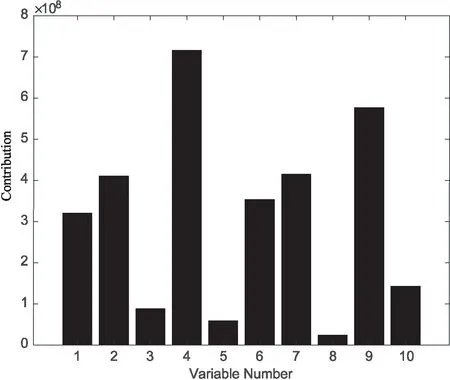
图5 样本变量的累计贡献
3.2 Tennessee Eastman
本节的仿真数据由最新的TE仿真器生成[20],其基本结构如图6所示。数据集在TE仿真器中通过0.01小时采样间隔并持续运行10小时获得。正常状态下采集1 000个样本作为训练集;同时,过程故障在3小时后引入并持续到过程结束。TE过程共包含41个测量变量和12个控制变量,仿真器运行过程中有三个变量恒定不变,所以选取剩余的50个变量进行过程监控。
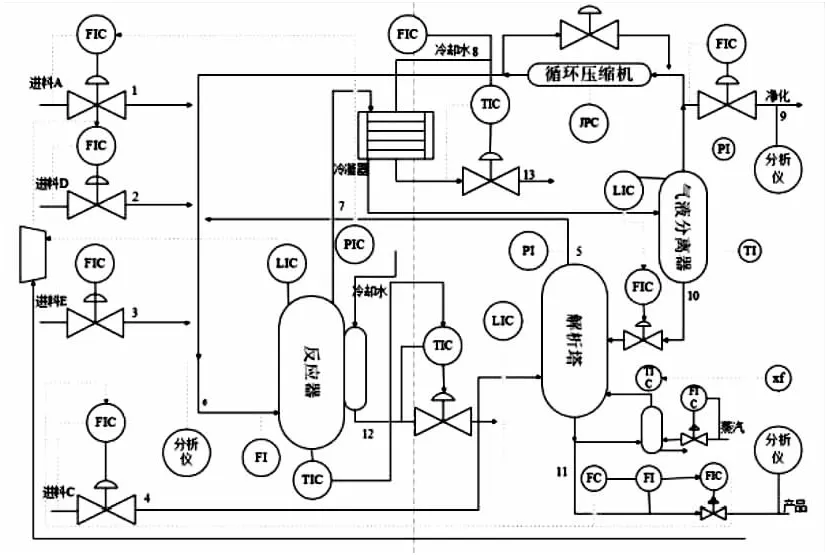
图6 TE过程
仿真使用的计算机环境为Intel(R)Core(TM) i7-7700HQCPU@ 2.80 GHz处理器的64位操作系统,且所有实验结果均在MATLAB中实现。
利用文中方法对TE数据进行仿真验证,并与KPCA、DPCA、DKPCA进行对比分析。四种方法均按照95%的累计贡献率选取主元,此外DPCA的时滞参数选取为1,DKPCA和文中方法的核宽参数和时滞参数均通过网格搜索和交叉验证的方式选取。表1给出了上述各种方法的检测结果,由于第六组数据缺失,因此不做测试。以第27组测试数据为例进行故障检测,图7分别给出DKPCA-RPCC、KPCA、DPCA和DKPCA对于故障27的检测结果。对比四种方法的检测结果可以看出,文中方法的检测率最高。为了进一步确定故障产生的原因,使用式(19)对第27组数据进行故障诊断,图8给出了故障27的诊断结果。从图中可以看出,第9个和第49个变量的贡献度最大,即故障27是由变量9和49引起的。变量9和49分别代表反应堆温度和反应堆冷却水流量,图9给出了反应堆温度和反应堆冷却水流量的变化趋势,由图可以看出与计算的结果恰好相互印证,与实际相符。

图7 故障27的检测结果

图8 故障27的贡献图
图10表示四种方法统计量的自相关性,明显可以看出,DKPCA-RPCC方法构建的统计量具有较低水平的自相关性。根据故障检测率以及构建统计量的自相关性检验所提出方法的性能。统计量的自相关性越低,说明主成分之间含有的动态性越低,故障检测性能更好。

图10 四种方法统计量的自相关
4 结束语
提出了一种基于去主元相关性的DKPCA动态非线性过程故障检测与诊断方法。该方法相对传统的DKPCA方法有两点改进,一是通过缺失值处理技术预测与原始矩阵保留相同特征的矩阵,二是通过真实得分与预估得分作差消除相同特征并在差异空间构造新的统计量。该方法进一步降低了动态性的影响,使得统计量的自相关性显著降低。另外,给出了基于变量累计贡献率的故障诊断方法。通过数值例子和TE过程验证该方法在故障检测与诊断中具有更好效果,对于动态非线性监控过程具有一定的指导意义。
由于该方法在计算过程中多次使用核函数,因而出现检测过程运行时间长,占用内存空间大的问题,接下来将考虑如何优化算法的问题,提高算法的运行效率。
