基于机器学习的SAE 患者30 天死亡风险预测模型
2023-04-19肖晓霞龚后武郑立瑞谭建聪
刘 彬, 肖晓霞,2, 龚后武, 周 展, 郑立瑞, 谭建聪
(1 湖南中医药大学 信息科学与工程学院, 长沙 410208; 2 湖南中医药大学 中医学国内一流建设学科, 长沙 410208;3 东华医为科技有限公司, 北京 100089)
0 引 言
脓毒症是由感染引起的全身炎症反应综合征,全球发病率较高,每年患脓毒症的人数约为3 100万,住院病死率约为17%[1]。 脓毒症相关性脑病(SAE)是指在患脓毒症过程中发生的脑功能障碍,是一种比较严重的脓毒症并发症,也是造成脓毒症患者死亡的独立危险因素[2]。 并与人体行为、记忆、认知功能的长期损害密切相关,给患者的家庭和社会带来沉重的经济负担。 仍需指出的是,SAE 患者的死亡率往往高于只患脓毒症的患者。 格拉斯哥昏迷评分法(Glasgow Coma Scale,GCS) 是一种用来评估病人昏迷程度的方法,满分为15 分[3],表示意识清楚;12~14 分表示轻度意识障碍;9 ~11 分表示中度意识障碍;8 分以下为昏迷。 Eidelman 等学者[4]的研究表明脑病与医院死亡率的增加成正相关性,当格拉斯哥昏迷评分(GCS) 为15 分时,死亡率为16%,而当GCS分数为3 到8 分时,死亡率为63%。 Sonneville 等学者[5]的研究也得出了类似的结论,研究显示当GCS分数为15 时,患者30 天生存率为67%;当GCS分数为3~8 分时,30 天生存率下降到32%。 即使发生轻度意识障碍(GCS分数为12~14)也是影响30 天死亡的一个独立危险因素。综上表明,SAE 对于脓毒症患者短期死亡率的增加是有影响的,而这将进一步影响患者的健康,同时加重医疗资源的消耗。
基于上述问题,识别出短期死亡率较高的SAE患者,有利于及时进行医疗干预,对于改善这类患者的预后也具有重要的意义。 因此本研究的主要目的是通过大型的临床数据库MIMIC 去提取相应的SAE 患者数据,然后通过rfe 算法[6]对相应特征进行筛选,选出影响SAE 患者30 天死亡率的重要特征,最后基于这些特征构建机器学习模型,用于改善SAE 患者的预后。
1 算法原理
1.1 RFE 特征筛选
特征递归消除(Recursive Feature Elimination,RFE)是一种用来衡量特征变量重要性的方法,通过重复构建模型,逐步迭代选出最重要的特征变量,能够寻找出最优的特征子集,剔除不重要的特征变量。具体运算步骤如下:
(1)设定需要进行选择的特征数。
(2)选择一个基模型来进行多轮训练, 每次训练将J(k)=(wk)2作为每个特征的排序准则,并且每次迭代去除排序最后需要移除的特征数量。
(3)基于新的特征集进行下一轮训练,直至特征个数为特征设定值。
本文选择的基模型为XGBoost 模型,对总计17个特征进行筛选。
1.2 逻辑回归
逻辑回归[7]是一种广义的线性回归模型,属于机器学习中的监督算法,主要是用来解决二分类问题。 该算法首先通过输入数据拟合出一条直线z =wTx +b,显然这样的函数图像是一条斜线,难以达到最终想要的结果(0 或1),于是要将z通过一个函数映射成0~1 之间的数,这个函数就是sigmoid函数,式子如下:
然后,通过极大似然估计推导出损失函数:
最后,通过梯度下降法求解出式(2)中的参数,从而解决了二分类问题。
1.3 GBDT
GBDT(Gradient Boosting Decision Tree)是一种基于决策树的集成算法。 算法采用将基函数线性组合的方法[8],在训练过程中使得残差不断地减小,最终实现数据回归或者分类。 GBDT 算法的训练过程具体如图1 所示。
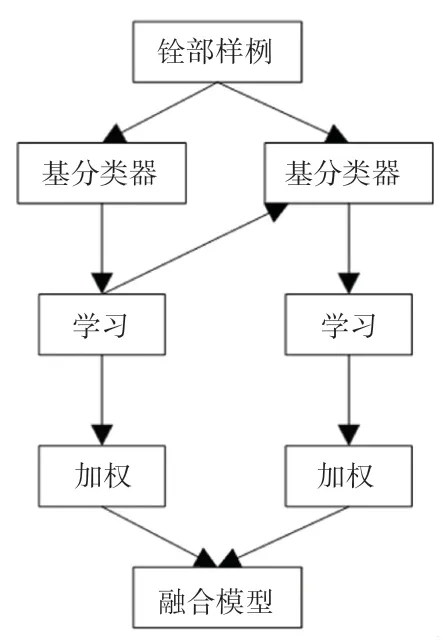
图1 GBDT 算法训练过程Fig. 1 GBDT algorithm training process
GBDT 通过多轮迭代,产生多个弱分类器,每个分类器在上一轮分类器的梯度(如果损失函数是平方损失函数,则梯度就是残差值)基础上进行训练。弱分类器一般会选择CART TREE(分类回归树),这种树具有结构简单、高偏差、低方差的特点,因此十分适合用于GBDT 算法的训练中。
1.4 XGBoost
XGBoost 算法[9]是在GBDT 算法的基础上发展而来的,主要改进有:算法不仅可以使用CART 分类回归树,还能使用线性基础模型;在目标函数中加入了正则化项,用来防止模型出现过拟合;借鉴了随机森林的原理,支持列抽样,不仅能降低过拟合,还能够减少模型的计算量;考虑到了训练数据为稀疏值的情况,能为缺失值指定分支的默认方向,从而提高算法效率。
2 数据与方法
2.1 数据来源
MIMIC[10](Medical Information Mart for ICU)是一个大型的、免费提供的数据库,其中包括来自美国马萨诸塞州波士顿贝斯以色列女执事医疗中心重症监护病房住院病人的高质量健康相关数据,数据包括生命体征、药物、化验数据、护理人员的观察和记录、输液、手术、诊断代码、成像报告、住院时间、生存数据。 MIMIC 数据库到现在已经发布4 个版本。MIMIC-II 中包含2001 ~2008 年的数据,MIMIC-Ⅲ包含2001 ~2012 年的数据,MIMIC-IV 包含2008 ~2019 年的数据。 本文将基于MIMIC-IV 数据库抽取相应的SAE 患者数据。
2.2 数据抽取
SAE 被定义为脓毒症患者中GCS分数小于15的患者。 研究使用的主要软件为Navicat Premium(15.0.12 版本), 按 照 关 键 字[11]“ s - epsis”、“severe sepsis”、“septic shoc-k”从数据库中搜索被诊断为“脓毒症”、“严重脓毒症”、“脓毒症休克”患者的原始数据。 根据以往研究,确定好纳排标准后进一步筛选患者。 患者筛选的详细过程如图2 所示。
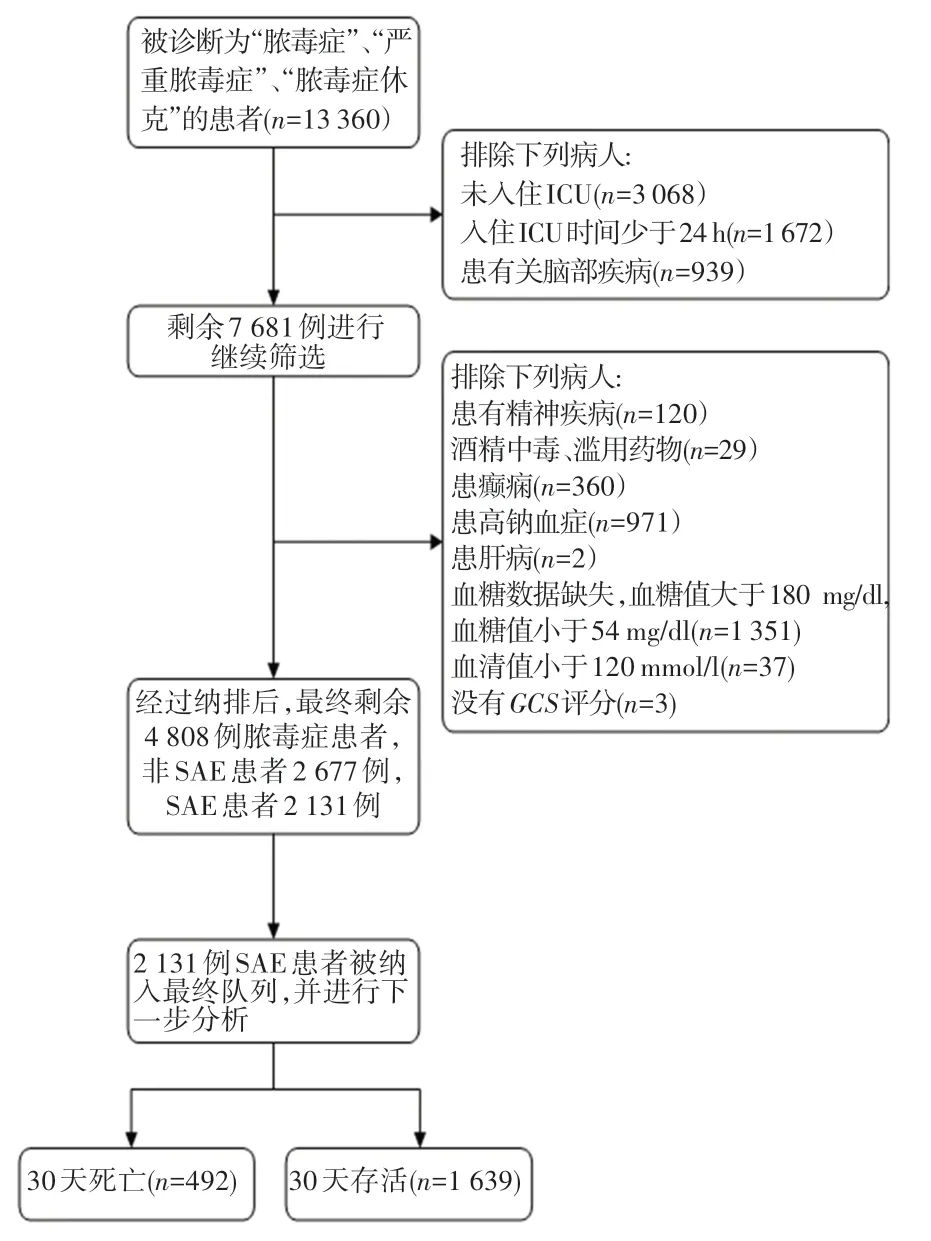
图2 患者筛选图Fig. 2 Patient screening
确定最终的SAE 患者后,根据此前的研究文献,从MIMIC 数据库中提取患者首次入院时对应的年龄(anchor_age)、性别(gender)、住院天数(day)、葡萄糖(glucose)、钠(sodium)、GCS 分数(gcs)、血小板( platelet)、 肌 酐 ( creatinine )、 血 红 蛋 白(hemoglobin)、钾(potassium)、血尿素氮(BUN)、白细胞(WBC)、乳酸盐(lactate)、血浆凝血酶原时间(PT)、心率(heart_rate)、血氧饱和度(spo2)、呼吸速率(respiratory_rate)、30 天是否死亡(morality)。 数据总计17 个特征属性,再加一个类别标签属性,其中类别标签表明患者是否在患病30 天内死亡。
2.3 数据预处理
提取了数据后,对数据的缺失情况进行统计,结果见表1。
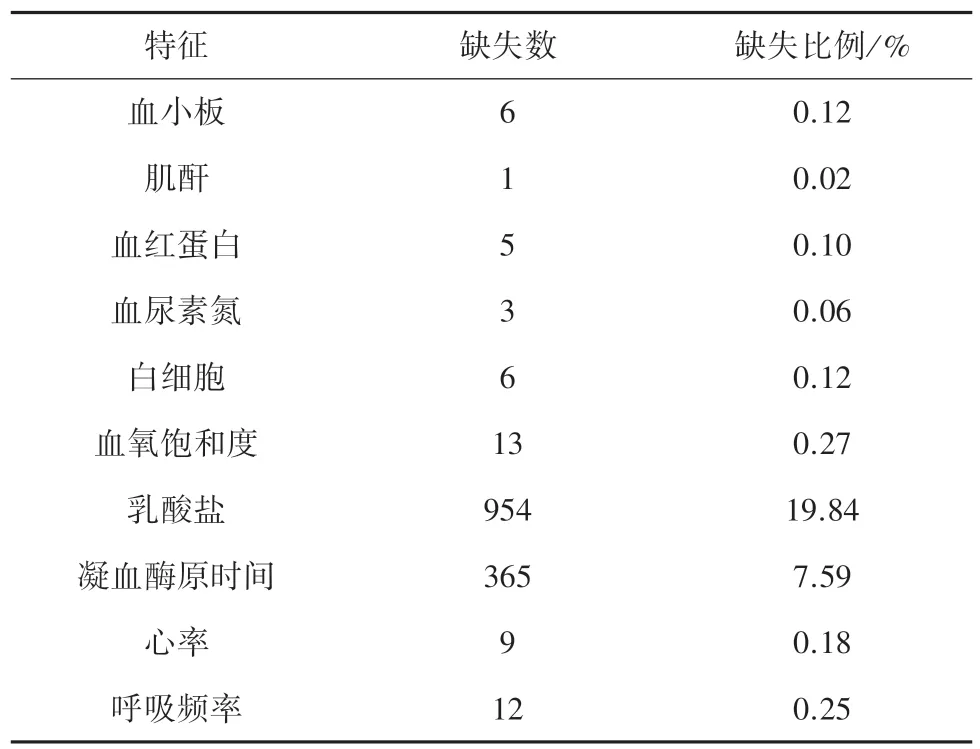
表1 数据缺失情况表Tab. 1 Data missing table
从表1 的结果中可以看出10 个特征存在数据缺失的问题,缺失最多的特征是乳酸盐,缺失比例为19.84%,缺失最少的是肌酐,仅缺失一例。 根据文献[8]中对缺失数据的处理方法来看,缺失特征比例均小于20%,予以保留,并统一采用平均值对其进行填补,在此基础上将对数据进行具体分析。
3 结果
3.1 纳入病例的基本信息
总计纳入4 808 例脓毒症患者,其中2 131 例为SAE 患者。 SAE 患者年龄为19 ~91 岁之间,中位年龄数为68 岁。 男性为1 127 例,女性为1 004 例。30 天内死亡病例为492 例,存活病例为1 639 例,数据分布较为均衡。
3.2 筛选得到的特征变量
根据RFE 特征筛选,每一轮筛选移去特征系数(wk)2最小的特征,直到特征个数为设定值。 结果显示,当特征数设定为13 时,3 个模型中GBDT 的AUC值最高,其在测试集上AUC为0.783。 此时选出的13 个特征分别为:年龄、住院天数、钠、GCS 分数、血小板、肌酐、钾、血尿素氮、乳酸盐、血浆凝血酶原时间、血氧饱和度、心率、呼吸速率。
3.3 实验结果
将SAE 数据集按照7:3 的比例随机划分为训练集和测试集进行训练。 本文采用的评价指标为准确率、P值、R值、F1值、AUC值。 具体的实验结果见表2、表3。
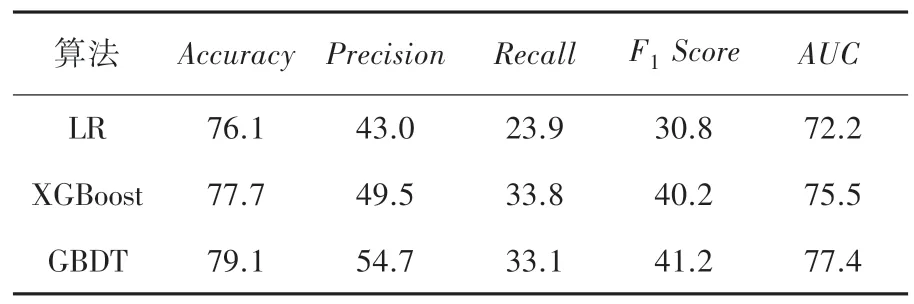
表2 未进行特征筛选结果Tab. 2 No feature filtering results
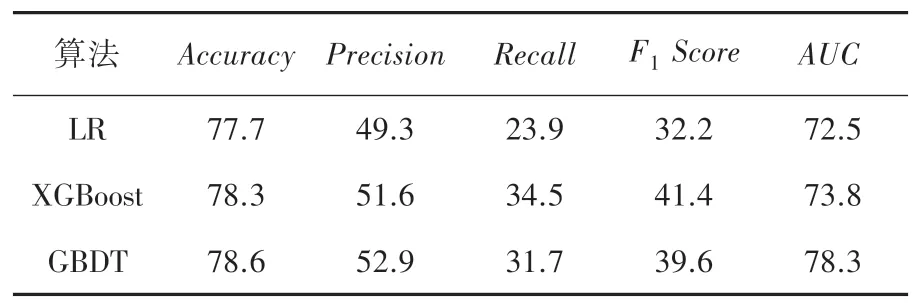
表3 特征筛选后结果Tab. 3 Results after feature screening
从表2 和表3 中可以看出,数据集经过特征筛选后,3 个模型的某些指标得到了提高。 逻辑回归模型的准确率提高了1.6%、精度提高了6.3%、F1值提高了1.4%、AUC值提高了0.3%;XGboost 模型的准确率提高了0.6%、精度提高了2.1%、召回率提高了0.7%、F1值提高了1.2%;GBDT 模型的AUC值提高了0.9%。
为了更直观地比较3 个不同算法的性能,绘制的ROC曲线如图3 所示。
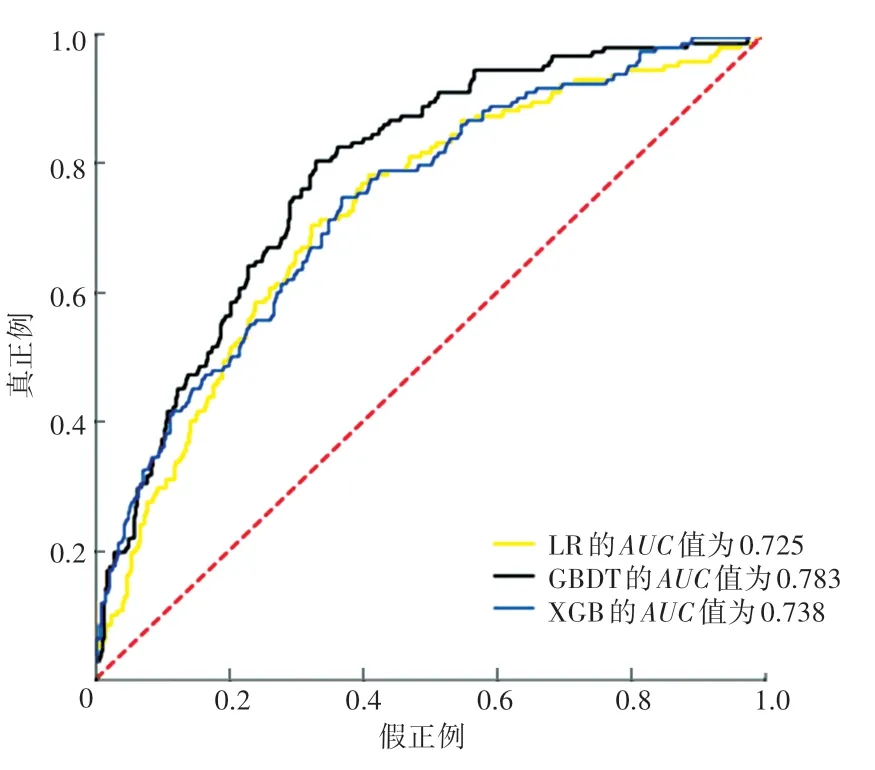
图3 3 种分类算法的ROC 曲线Fig. 3 ROC curves of three classification algorithms
从图3 中可以看出,在3 个算法中GBDT 算法的AUC值最大、为0.783,说明GBDT 算法性能最优,更适合用于SAE 患者30 天死亡预测。
4 分析与讨论
在这项基于MIMIC-IV 数据库的研究中,从MIMIC 数据库中抽取出对应的SAE 患者数据,然后使用了RFE 特征选择,筛选出了与SAE 患者30 天死亡率相关的危险因素,最后基于这些特征建立了3 个机器学习模型去对SAE 患者30 天死亡进行预测。 其中,GBDT 算法对于SAE 患者30 天死亡预测效果最佳,其精度为52.9%,准确率为78.6%、AUC值为78.3%,3 个指标均为不同算法中最高的。 与其它研究方法进行对比,文献[3]提出的列线图模型在训练集上的AUC值为0.763,在验证集上的AUC值为0.753,均比本文提出的GBDT 算法的AUC值略低。 说明本文提出的模型性能更优、泛化能力也更强。 目前,对于SAE 的治疗是具有挑战性的,有许多关于脓毒症的指南列出了各种治疗脓毒症的建议,但却很少有治疗SAE 的建议。 有关SAE 患者死亡预测的研究也较为匮乏,本研究很好地弥补了这方面的空白。 从应用价值来看,本文提出的GBDT 预测模型能够辅助临床医生去评估SAE 患者的预后,从而制定出相应的治疗措施,降低患者死亡率。 一旦研究出针对SAE 的具体治疗方法,该模型的应用价值就会更高。 未来可以开发一款能嵌入电子医疗系统的软件,该软件能够在不增加临床医生工作时间和负担的情况下,辅助临床医生及时治疗SAE。
5 结束语
本文基于MIMIC 数据库,提取相应的脓毒症患者数据,并通过GCS分数进一步筛选出SAE 患者的数据。 然后经过RFE 特征筛选,筛选出13 个重要的特征。 使用逻辑回归、XGBoost、GBDT 三种算法基于筛选后的特征进行建模,实验结果表明,GBDT算法更适合用于SAE 患者30 天死亡预测,其AUC值为78.3%,高于其他2 种算法,也比其他文献中的方法略好。 对于SAE 患者的预后具有一定的参考价值。
本次研究也存在局限性,即只对该数据库进行了内部验证,在今后的研究中还需要根据其它的数据进行外部验证,以进一步检验模型的鲁棒性和性能。
