一种基于生成对抗网络的卫星异常检测方法
2023-04-19程月华张香燕
王 泽, 姜 斌, 程月华*, 张香燕, 薛 琪
1. 南京航空航天大学自动化学院, 南京 211100 2. 中国空间技术研究院, 北京 100094
0 引 言
卫星系统组成复杂,受太空恶劣环境影响以及部件磨损老化,卫星在轨运行期间可能会出现各种异常或故障[1].遥测数据是反映卫星工作状态和系统性能的重要参数之一.针对卫星遥测数据开展异常检测研究,能为卫星的动态健康监测和故障排查提供有力的帮助.从而保证卫星的在轨运行安全可靠,延长卫星的使用寿命[2-4].
传统的异常检测方法主要包括:统计[5]、聚类[6]以及一阶分类器[7].基于统计的异常检测是最早的异常检测方法,常用的有主成分分析及其各种改进方法.聚类方法通过对数据进行相对距离度量来将数据划分成不同的簇,每个簇代表一类数据的集合,这样就可以将正常数据和异常区分开.BREUNIG等[8]提出了局部离群值因子(LOF)方法,这是第一个基于松散相关的聚类离群值检测方法,该方法利用了k最近邻实现异常检测.分类的方法主要是使用机器学习算法中的一阶分类器,通过寻找正常数据的分布边界,将正常数据和异常数据进行区分,范围之外的数据将当作异常数据输出,常用的方法有支持向量机(support vector machine, SVM).
随着深度学习在计算机视觉、自然语言处理以及机器翻译等领域的发展,深度学习的成果开始向其他领域扩展,形成许多全新的异常检测方法.目前,常用的异常检测研究可以分为3类:
1)深度聚类(deep clustering)方法[9-10]采用深度学习的聚类方法,一般是用神经网络对输入数据进行编码,认为最后的编码序列可以代表神经网络的很多特征,最后以编码序列的聚类结果作为原始数据的结果.
2)基于预测的方法[11-12]通过学习一个预测模型来拟合给定的时间序列数据,使用该模型来预测未来的值.如果某一数据点的预测输出和原始输入之间的差异超过某一阈值,则该数据点被识别为异常点.文献[13]提出了一种基于统计模型(autoregressive integrated moving average model,ARIMA)的异常检测方法;文献[14]使用(long short-term memory,LSTM)来预测未来时间步的数据,通过预测偏差实现了对数据的异常检测.
3)基于重构模型的方法[15-16]主要采用自编码器,通过编码器和解码器学习正常数据的重构知识,而异常数据无法被有效重构,导致在异常的部分数据差异大,进而实现异常检测.文献[17]提出了一种基于稀疏自编码器的异常检测方案,通过学习一个模型来捕获给定时间序列数据的低维表示,然后创建数据的合成重构.文献[18]提出了一种基于LSTM的自编码器异常检测模型,通过学习正常数据的重构模型来区分异常,可以实现不可预测序列的异常检测.
生成对抗网络(generative adversarial network, GAN)[19]是一种数据生成式神经网络,在图像生成方面取得了目前最好的成绩[20-21],属于重构方法的一种.GAN的主要灵感来源于博弈论中零和博弈的思想,应用到深度学习神经网络上,就是通过生成网络G(generator)和判别网络D(discriminator)不断博弈,从而使生成网络G学习到输入数据的分布.如果将生成对抗网络用于图片生成,那么在模型训练完成后,生成网络G可以从一段随机噪声中生成与训练样本相似的图片.使用GAN进行异常检测是一个新兴的研究领域.文献[22]提出了一种名为AnoGAN的异常检测模型,这是此概念的首次提出.为提高AnoGAN的性能,文献[23]提出一种基于BiGAN的异常检测方法EGBAD,在运行时间上优于AnoGAN.与传统重构算法相比,GAN的数据生成准确度在零和博弈的思想下不断迭代,最后使得生成的序列与输入序列高度相似.对于存在异常的序列,其异常部分无法被有效生成,所以生成序列与原始序列在异常部分差异较大,通过对残差信号进行处理,就可以对异常进行有效的检测.
由于实际卫星遥测数据存在复杂的变化模式以及不规律的数据跳变,聚类模型和预测模型的效果较差.同时,实际卫星遥测数据中异常数据稀少,导致模型在训练时容易过拟合,异常检测效果不佳.针对卫星遥测数据不平衡,缺乏异常标签数据的问题,本文提出了基于生成对抗网络的异常检测方法.利用GAN的数据生成能力,实现了对输入序列的生成重构,并输出原始序列和生成序列的残差信号.结合阈值自适应方法实现对残差信号进行异常检测.通过多个领域的数据集进行实验验证,证明了所提方法的有效性.
1 方法概述
如图1所示,基于生成对抗网络的异常检测方案可以分为数据预处理、模型训练和阈值自适应3部分.因为卫星遥测数据存在大量的野值和噪声,在对网络进行训练前,首先对数据进行预处理,步骤如下:遥测数据去噪、遥测数据归一化.然后按照设计的网络结构建立序列生成模型,使用预处理之后的数据进行模型训练,并用测试集数据得到生成序列和原始序列的残差信号.最后使用阈值自适应方法进行异常检测,并记录检测结果,计算模型评价指标.
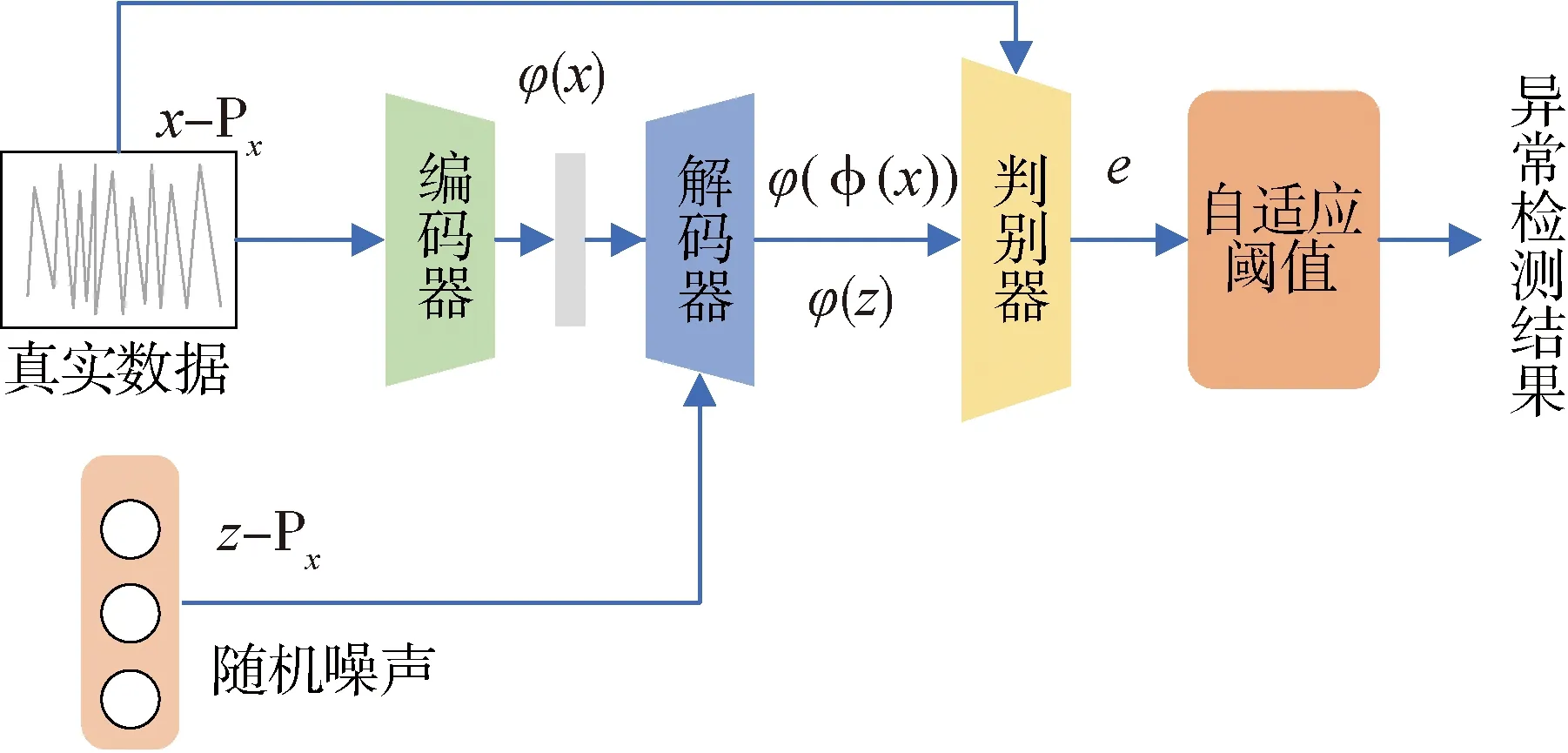
图1 异常检测方案图Fig.1 Diagram of anomaly detection scheme
2 数据预处理
2.1 数据去噪
在轨卫星遥测数据在采集时难免受到噪声的影响,噪声可能会对部分异常信号的特征进行掩盖,导致无法检测出相应的异常,所以需要对遥测数据进行去噪处理.考虑到遥测数据中的噪声多为脉冲噪声,通常只会出现在某一时刻,因此选用中值滤波来去除此种噪声.中值滤波算法的窗口一般根据遥测数据的最小周期来选择,本文选择以一天为一个窗口长度.图2展示了某卫星电源系统的温度参数在进行中值滤波前后的对比情况.
2.2 数据归一化
遥测数据中,同一部件的多个遥测参量具有不同的物理量纲,导致不同参数的数据变化范围差异较大,为了加快模型的收敛速度,对输入数据的不同属性进行归一化操作.常用的归一化方法有3种:最小-最大归一化、零均值归一化和按小数定标归一化.零均值归一化方法适用于样本最值未知或者存在离群点的情况,因为卫星遥测数据中包含异常数据,所以采用对异常数据鲁棒性更高的零均值归一化方法对遥测数据进行归一化.
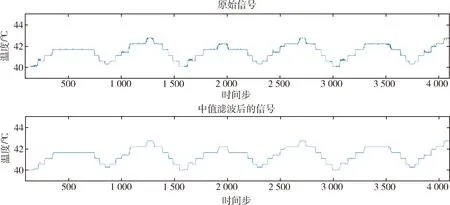
图2 中值滤波前后数据对比图Fig.2 Comparison chart of data before and after median filtering
假设序列A为数据样本,记μA为样本A的均值, 为样本A标准差,零均值归一化的公式可以表示为
(1)
通过式(1),可以将样本A的均值和方差转换为0和1.
3 异常检测算法设计
3.1 生成对抗网络
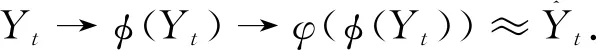
利用对抗训练的学习方法来实现φ和φ的映射关系,实现方案如图1所示,φ和φ共同组成了GAN的生成器部分.在生成器中,φ是作为编码器存在的,主要作用是将输入的时间序列编码,映射得到固定维数的潜在空间表达向量;φ的作用是解码器,负责将潜在空间向量解码重构为与输入序列格式相同的一段序列.判别器D(·)的目的是判断随机噪声和编码器输出的映射效果.根据GAN的设计原理,φ的目标是尽可能使得生成的序列看起来像真实的序列,GAN的损失函数可以表示为
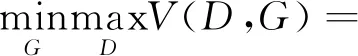
(2)
D(x)=1(x~Pdata(x))
(3)
另外一项是企图欺骗判别器的生成器G(·).该项根据“负类”的对数损失函数而构建,即
z~pz(z)[ln(1-D(z))]
(4)
因为原始GAN在应用上述损失函数时经常遇到梯度消失导致训练不稳定的问题[21],所以在原来的标准损失函数的基础上增添了两项:1) Wasserstein Loss,引入Wasserstein距离,解决了原始损失函数中KL散度与JS散度计算的2个分布不连续,导致梯度消失的问题[24];2) Cycle Consistency Loss,引入循环GAN的损失函数使得编码器φ和解码器φ能对输入序列进行重构[25].
3.2 损失函数设计
针对上述标准损失函数在训练时存在的问题,引入Wasserstein-Loss作为GAN损失函数的一部分.在训练判别器时,引入Wasserstein Distance距离W(·),以取代原来的判别器D,对于生成器G和新的判别器fw,得到如下的函数:
(5)
和
|fw(x1)-fw(x2)|≤K|x1-x2|
(6)
式(6)表示fw是Lipschitz连续函数,且Lipschitz常数为K,即存在常数K≥0使得任意2个元素x1、x2都满足式(6).与原先的KL散度与JS散度相比,Wasserstein距离W(·)更加平滑.所以在更新梯度时,权重就不会剧烈地变化,减小了梯度消失的危险,可以保证训练的稳定进行[26].
训练GAN是为了生成输入序列的近似序列,获得和重构相似的结果.但是采用Wasserstein-Loss只能保证训练过程的稳定,无法使得输入序列Xt期望的输出进行映射.所以,继续引入循环GAN的部分损失函数来辅助进行时间序列的重构.在训练生成器φ和φ时,使用循环一致性损失函数最小化原始样本和重构样本之间的L2范数
(7)
模型的目标是进行异常检测,所以引入L2范数来减小异常数据的影响.联合已经给出的损失函数式(5)~(7),可以得到最后的损失函数形式
(8)
3.3 阈值自适应异常检测方法
上文通过生成对抗网络建立了时间序列的生成模型,得到了输入序列的残差信号.通过对残差信号进行分析,发现在异常点处,残差信号往往和正常序列的残差存在较大区别,通过对残差信号进行平滑操作,可以保留潜在的异常波动.应用单一阈值来检测异常时,如果波动特征Qi大于阈值,则该数据点将被归类为异常.但是,单一的固定阈值太过简单,且需要人工经验进行设置,无法保证得到满意的结果,所以利用SPOT[27]算法来对残差信号进行统计分析处理,并最终实现阈值的选择.
SPOT(streaming peaks over threshold)方法是一种基于极值理论的数据峰值阈值方法.该方法仅依赖于极值的分布而不依赖于原始数据的分布,主要思想是通过广义帕累托分布(generalized pareto distribution, GPD)来近似拟合长尾分布
(9)
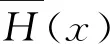
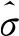
(10)
(11)
式中,μ和S2分布表示所有峰值超出阈值部分的数据点的均值和方差.最终的检测阈值thf的计算公式为
(12)
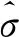
4 实验验证
4.1 实验数据集
为了测试本文提出的异常检测方法的有效性,实验使用了3个数据集:KPI、NASA和某卫星遥测数据,数据统计结果如表1所示.
KPI 数据集由AIOps挑战赛提供,它是一组带有异常标签的KPI曲线,来自腾讯、eBay、阿里巴巴等众多互联网公司的真实数据.大多数KPI序列的时间间隔为1 min,有7个KPI曲线的时间间隔为5 min.同时该数据集中的序列基本都包含一些缺失点或连续的缺失段.
NASA公开了一组卫星遥测数据,用于数据挖掘与健康诊断研究,主要包含2个数据集:火星科学实验室(mars science laboratory, MSL)和土壤水分主动被动(soil moisture active passive, SMAP).
某卫星的遥测数据主要涉及到卫星电源系统的多个遥测参数,数据跨度在10年左右.

表1 数据集信息统计表Tab.1 Statistics table of data set information
4.2 实验设置
(1)序列生成模型网络结构设置
在实验中,每个时间序列平均分为两半,前半部分用于训练无监督模型,后半部分用于评估(即作为测试数据). GAN生成模型的输入为100个时间步的时间序列,潜在空间维数设置为20. 生成器φ使用的是一个单层的具有100个隐层节点的双向LSTM网络层,生成器φ由一个双层的具有64个隐层节点的双向LSTM网络层组成. 2个鉴别器,均使用一维卷积层,用来捕捉可以确定序列异常程度的局部时间特征.设置模型对一个数据集的特定信号进行训练时,进行200次迭代,批大小为64. 在残差信号处理中,主要需要考虑自适应阈值的系数r和窗口大小t、m、n.
(2)评价指标
实验中,用3个数据集将本文所提出的异常检测框架与3种常用算法进行比较,对比方法为ARIMA[15]、Auto-Encoder[18]和LSTM-DT[16].因为数据集中样本类别不均衡,正常样本数比异常样本数多太多.如果只使用准确率作为评价指标,那么更多把未知样本分类为多数样本类的模型会取得较好的评价分数,所以本实验使用指标精准率(precision)、召回率(recall)和F1分数(F1-score)来衡量不同方法的性能,计算公式如式(13)~(15)所示
(13)
(14)
(15)
4.3 实验仿真结果与分析
(1)基于阈值自适应的异常检测
实验中,阈值部分采用阈值自适应方法,在每个窗口内更新阈值,使得阈值能跟随异常分数的变化进行调整,提高检测的准确率.因为在初始化时需要部分数据进行初始阈值计算,所以会造成小部分数据点无法进行检测,但是整体来看影响不大.图3和图4分别为某卫星遥测数据集和NASA数据集的阈值自适应检测结果展示,从图上可以看到,阈值在起点开始,每隔一段数据点就进行一次调整更新,最后趋于一个较稳定的值.阈值的自动调整避免了手工调整的繁琐与时间成本,提高了异常检测的效率.
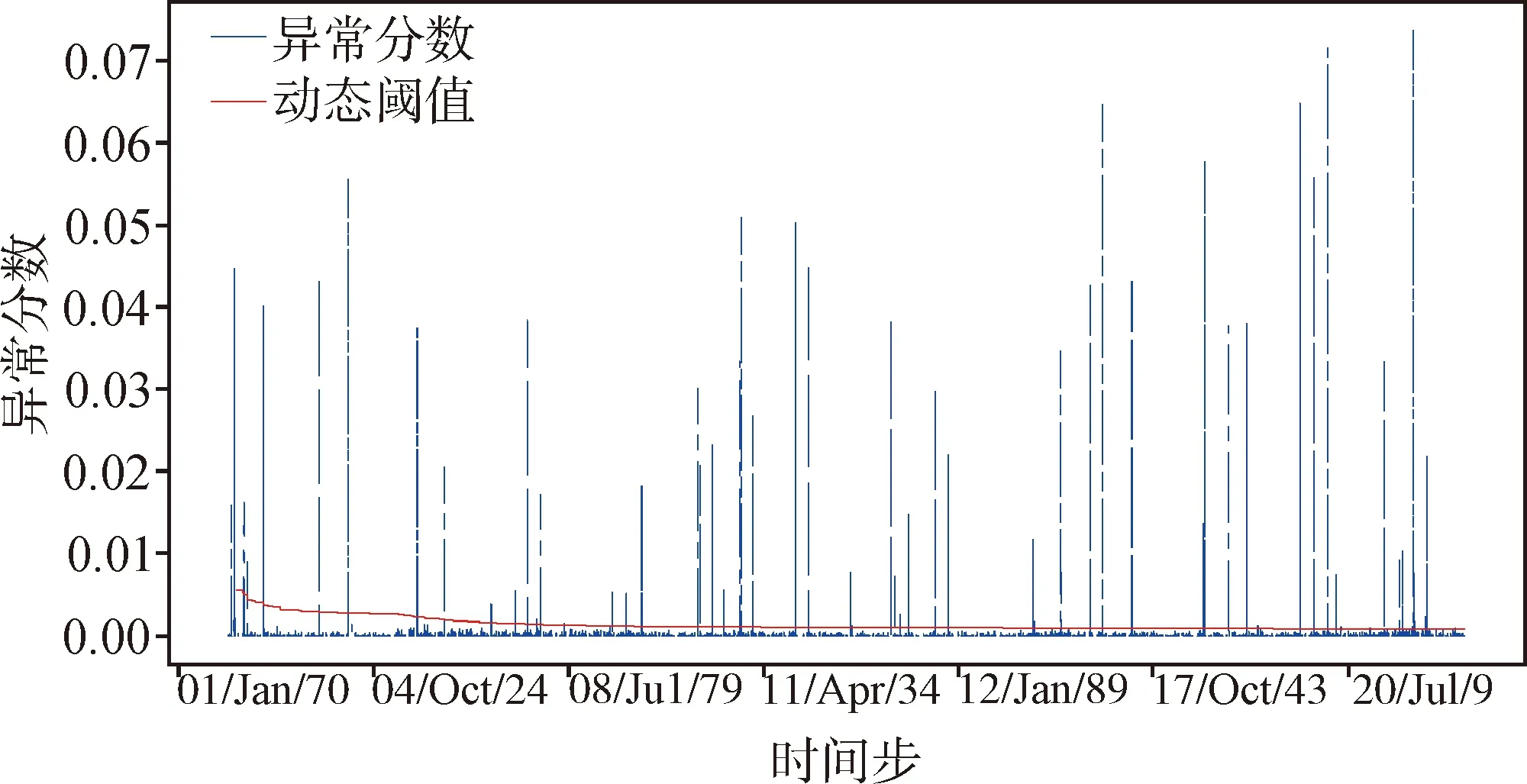
图3 某卫星遥测数据集动态阈值检测结果展示Fig.3 Display of dynamic threshold detection results of satellite telemetry data
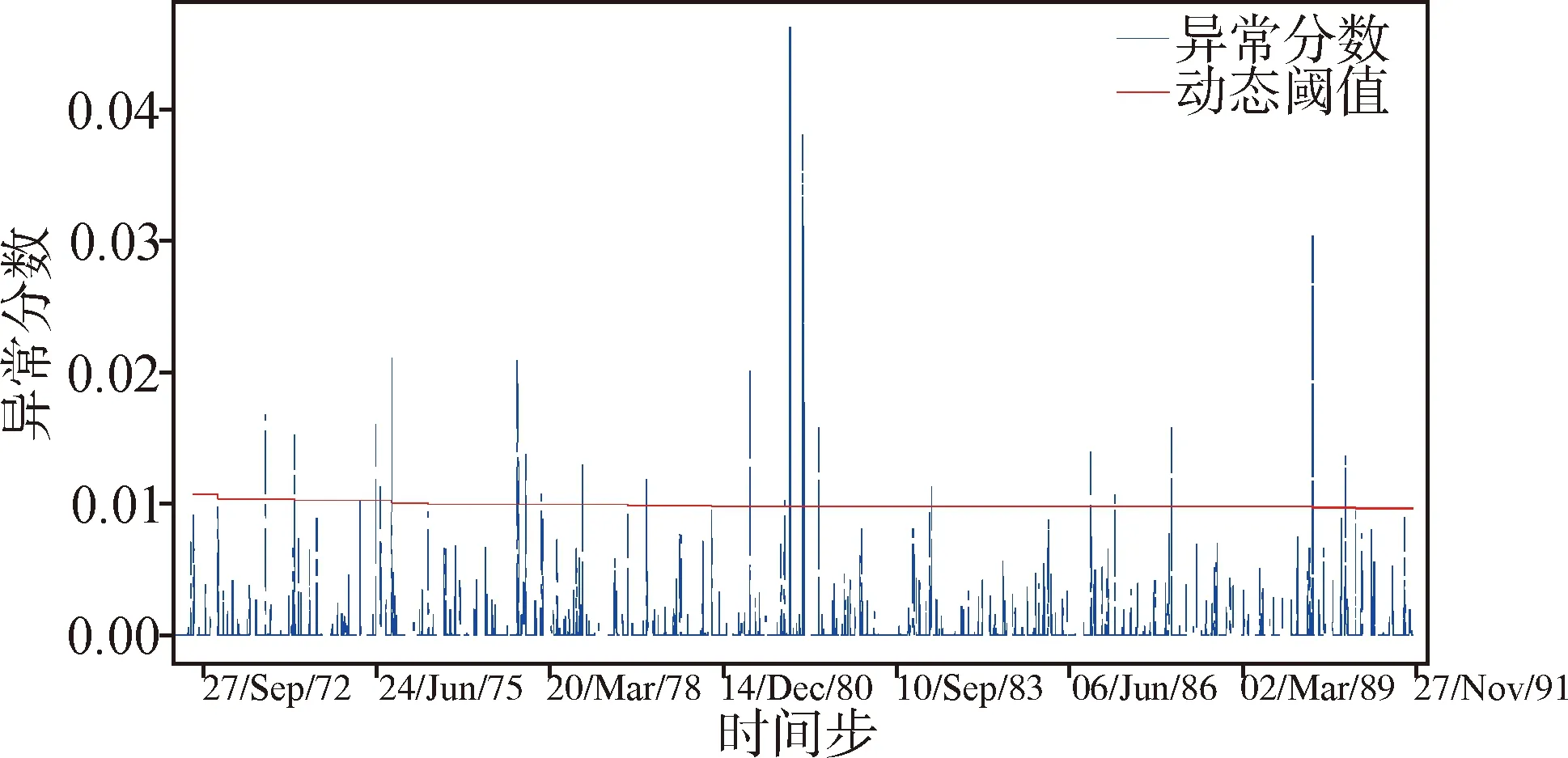
图4 NASA数据集动态阈值检测结果展示Fig.4 Display of dynamic threshold detection results of NASA data set
(2)结果统计与分析
3种算法的检测结果如表2所示.本文所提的方法相较于其它方法有比较明显的提升,在多个数据集中都取得了最好的检测结果. 在KPI数据集中,F1分数较基准算法的最优结果提升8.3%,召回率提高了3.8%,精确率提高了4.4%;在NASA数据集中F1分数较基准算法的最优结果提升5.4%,召回率提高了9.5%,精确率提高了4.0%;在卫星遥测数据集中,F1分数较基准算法的最优结果提升8.8%,召回率提高了16.8%.
本文提出的异常检测方法,在3个数据集上都取得了最好的F1分数,均在71%以上.基于LSTM网络的动态阈值方法结果比基于自编码器重构的检测方法稍好,表明基于LSTM的重构和预测方法对于异常检测都是适合的,再结合动态阈值设置,可以做到不错的检测效果.但是它们的整体检测效果要稍差于本文所提的检测方法,在NASA数据集和卫星遥测数据集中,本方法可以有效提高检测的召回率,这样可以使得数据集中的少量异常样本有效地检测,能解决样本比例不平衡的问题,对提高模型的检测效果有帮助.
从结果分析可以看出,本文所提方法在时间序列的异常检测方面具有较好效果,借助于生成对抗网络的数据分布学习能力,减小了原始数据变化模式复杂带来的影响,阈值自适应方法能提升算法对不同序列的适应能力,增强了算法的普适性.

表2 实验结果统计表Tab.2 Statistical table of experimental results
5 结 论
本文提出一个基于生成对抗网络的异常检测框架,实现了时间序列重构和异常检测.首先对卫星遥测数据进行处理,然后用GAN模型学习正常数据样本的分布,这一过程为无监督学习,所以在训练阶段不需要异常样本;最后通过重构序列残差和阈值自适应来实现异常检测.GAN的数据分布学习能力可以做到比数据映射更好的重构效果.实验结果表明,本文所提方法在3种数据集上都取得了最高的平均F1分数,优于所有对比方法,证明了所提方法在时间序列异常检测上的有效性.
本文所提方法在验证时主要实现了单点异常和周期变化模式异常的数据检测,但是对于恒值变化的序列,其重构误差往往在正常误差的变化范围内,导致这部分异常无法使用阈值进行有效检测.所以,未来将继续研究如何提高模型对恒值异常的检测.
