Transformer与多尺度注意力的自监督单目图像深度估计
2023-04-19梁水波刘紫燕孙昊堃
梁水波,刘紫燕,孙昊堃,袁 浩,梁 静
(贵州大学 大数据与信息工程学院,贵阳 550025) E-mail:leizy@sina.com
1 引 言
单目图像深度估计是计算机视觉领域的重要课题,其旨在特定视角下从图像中产生像素级别的深度图.这种深度信息有助于更好地理解3D场景,并且还促进了许多计算机视觉任务,例如增强现实、机器人导航、自动驾驶、即时定位与地图构建等.通常,深度信息主要由商业深度传感器获得,如各种激光雷达或者深度相机.除了高成本和操作技能要求外,其还面临着低分辨率和感知距离短的缺点,这限制了其广泛的应用.由于RGB图像的广泛可用性,越来越多的学者对从单目图像中估计深度产生浓厚的兴趣.
传统方法依赖于场景的多个视图之间的差异来恢复3D场景几何,其中至少需要两个图像.由于深度学习技术的快速发展,单目深度估计取得了很大的进步.在准确性和速度方面超越了传统基于机器学习的方法.深度学习方法的深度估计可以分为监督学习和自监督学习两大类.
对于监督学习的深度估计任务,Eigen等人[1]首次将卷积神经网络用来解决从单目图像中预测深度问题.其设计了一个由粗到细的网络预测单目深度并使用了距离传感器测量的真实深度值作为监督信号.文献[2]中,提出了一种能够处理深度估计、表面法线估计和物体标签预测的多任务模型.在文献[3]中,重点关注深度估计在障碍物检测中的应用而不是从单个图像预测深度,提出了全卷积神经网络框架通过单目图像和相应的光流来估计精确的深度图.文献[4]提出了局部平面指导层,有效编码阶段的特征与最终输出深度图联系起来.然而,虽然这些监督的方法具有高质量的深度估计结果,但是针对不同的场景,在现实世界场景中获得深度真实值是非常具有挑战性的.
对于自监督学习的深度估计,Garg等人[5]使用双目图像对网络进行训练,不使用深度信息进行监督,而是使用左图像和从右图像变形的合成左图像之间的颜色不一致作为监视信号.Godard等人[6]提出了左右一致性损失用于正则化.文献[7]将上述的方法用于双目视频.虽然基于双目的方法不需要真实深度,但是精确校正双目图像也不是一件容易的事.文献[8]用自监督学习的方法从单目视频序列中估计深度信息,其将深度估计和自运动估计统一到一个框架中,只使用单目视频序列作为输入,不使用真实深度或者立体图像对进行监督,监督信号来自视图合成.然而,由于移动物体违反了几何图像重建中的潜在静态场景假设,因此出现了性能限制.且由于缺乏适当的约束,网络预测不同样本的深度具有尺度不一致的问题.为了解决移动物体的问题,文献[9,10]中分别加入额外的光流网络和运动分割网络,虽然在精度上有一定的提升,但需要巨额的计算成本且仍具有尺度不一致的问题.文献[11] 在文献[8]的基础上,提出了几何一致性损失来约束视频前后帧上估计出深度的一致性,然后利用这个几何一致性来检测运动物体和遮挡区域,在计算重投影误差时移除这些病态区域,可以提升算法性能.而且用这种训练方式得到的深度估计结果具有在长视频上的尺度一致性,可以用来做SLAM或VO等任务.
Transformer[12]和自注意力模型在机器翻译与自然语言处理领域起着开拓性的作用.最近两年,越来越多的学者将Transformer运用到计算机视觉领域,提供了新的解决思路且取得了不错的效果.Transformer模型及其变体已成功的用于图像识别、语义分割、目标检测、图像超分辨率、视频理解等任务.DPT[13]将Transformer应用在监督方法的深度估计上,取得了很好的效果.为了获得对象边缘更加细化的深度图,对象边缘主要由语义信息和空间信息确定.语义信息通过约束像素类别来获得清晰的边界,而空间信息使用几何约束来描述对象的轮廓.基于此,本文提出一种基于Transformer的多尺度注意力融合的网络结构,对图像在多个尺度上的特征信息充分利用.通过注意力模块更好地整合语义信息和空间信息,在网络提取深层的语义信息的同时融合浅层语义信息,使得最后预测的深度图具有很好的深度连续性以及实现深度估计精度的提高.
2 单目深度估计模型
2.1 自监督学习深度估计算法原理
自监督学习的方法是通过单目图像序列训练的,并且在相邻帧之间的投影上构建了几何约束:网络以连续的单目图像作为输入,通过视图合成作为网络的监督信号.给定一源图像Is视图合成任务是生成合成目标图像It,通过公式(1)将源图像像素Is(ps)投影到目标视图It(pt)上:
ps~KTt→sDt(pt)K-1pt
(1)
K是相机的内参数矩阵,Tt→s为从目标帧到源帧的相机运动矩阵,Dt(pt)表示目标帧中每个像素对应的深度映射.训练目标是通过优化真实目标图像和合成唯一的光度重建损失来确保场景几何的一致性.
(2)
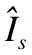
2.2 基于Transformer的多尺度特征提取编码器
本文的深度估计网络如图1所示,采用Transformer作为编码器的基本框架,利用Transformer的提取全局信息以及局部信息的优势.参考文献[14] 中spatial-reduction attention (SRA)模块以灵活调整各阶段的特征尺寸,不仅使网络在多个尺度上提取特征,还能增加网络的全局信息以及局部信息.提取的特征图包含4种不同的分辨率,分别为输入图像的1/4、1/8、1/16、1/32.
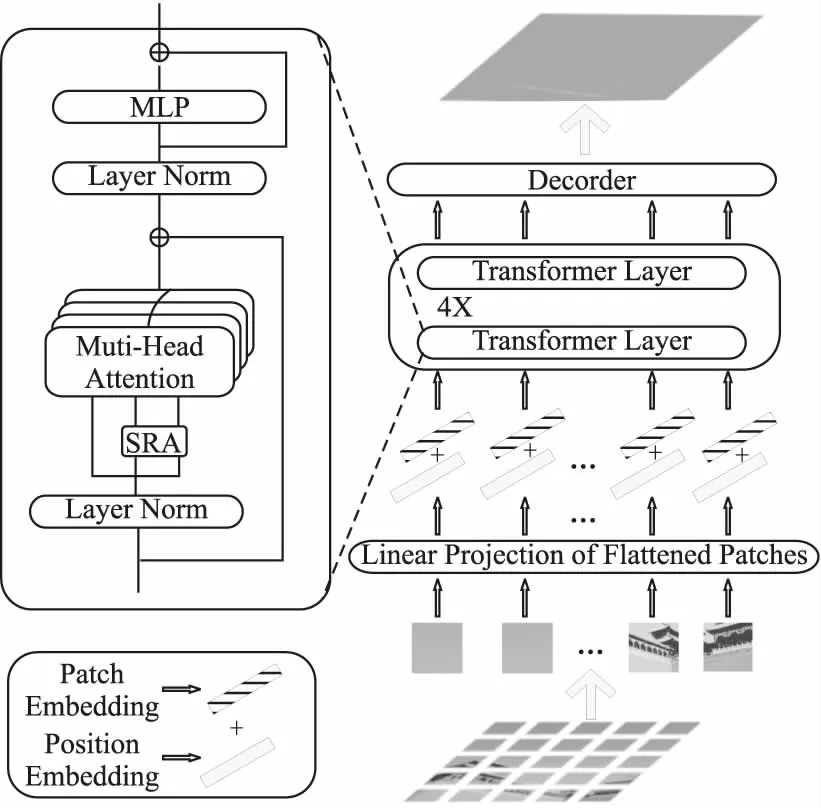
图1 网络结构示意图Fig.1 Schematic diagram of network structure
给定尺寸为H×W×3的输入图像x∈H×W×3,为了将二维图像变成一维序列,首先将其划分为N个图像块,其中N=H×W/P2,P为每个图像块的大小,本文设置每个图像块的大小典型值为4×4×3.其次将展开的图像块送入线性投影层(linear projection)得到尺寸为HW/42×C1的嵌入块.然后将嵌入块(Patch Embedding)与位置嵌入(Position Embedding)信息执行相加后的信息E送入Transformer Layer.
Transformer Layer主要包含层归一化(Layer Norm)、多头注意力(MHSA)以及多层感知机(MLP).在Stage l中,经过Layer Norm之后,对于输入为El-1∈L×C将会与3个线性投影层参数WQ、WK、WV∈C×d分别计算query、key、value.query=Zl-1WQ、key=Zl-1WK、value=Zl-1WV.C是隐藏层的通道大小,d是query、key、value的维度.自注意力层(Self-Attention)则可以由公式(3)表示:
(3)
多头自注意力则是m个自注意力层操作拼接起来然后投影得到,公式如式(4)所示:
MHSA(Zl-1)=[SA1(Zl-1);SA2(Zl-1);…;SAm(Zl-1)]WO
(4)
其中WO∈md×C.最后,通过Layer Norm和MLP以及残差连接得到输出:
Zl=MHSA(Zl-1+MLP(MHSA(Zl-1))∈L×C
(5)
图1中所示,每一个Transformer层都有两个层归一化,为了简单体现,本文并未在公式推导中体现.本文中有4个Transformer层,将会得到各层的不同分辨率的输出E1、E2、E3、E4.
2.3 基于残差通道注意力融合的解码器
对于密集预测任务,为了解决卷积神经网络的受卷积核大小的限制,网络无法很好的获得全局信息的问题.很多学者通过叠加多个卷积层的方式虽然可以获取图像的全局信息,但是在信息由浅层向深层逐渐传递时,由于采样操作,会导致信息的遗失.如果一味的堆叠网络也会导致网络太深训练无法收敛等问题.本文受文献[15] 中判别特征网络(DFN)的启发,将残差细化模块(Refinement Residual Block,RRB)和注意力模块(Attention Module)运用到解码过程中,提出了基于残差细化与通道注意力多尺度融合的解码器.将编码器Transformer层中的不同分辨率的特征图E1、E2、E3、E4进行残差细化模块和通道注意力模块后,经过上采样后进行特征融合,最后,分别在不同的分辨率下进行深度预测.解码器结构如图2所示.
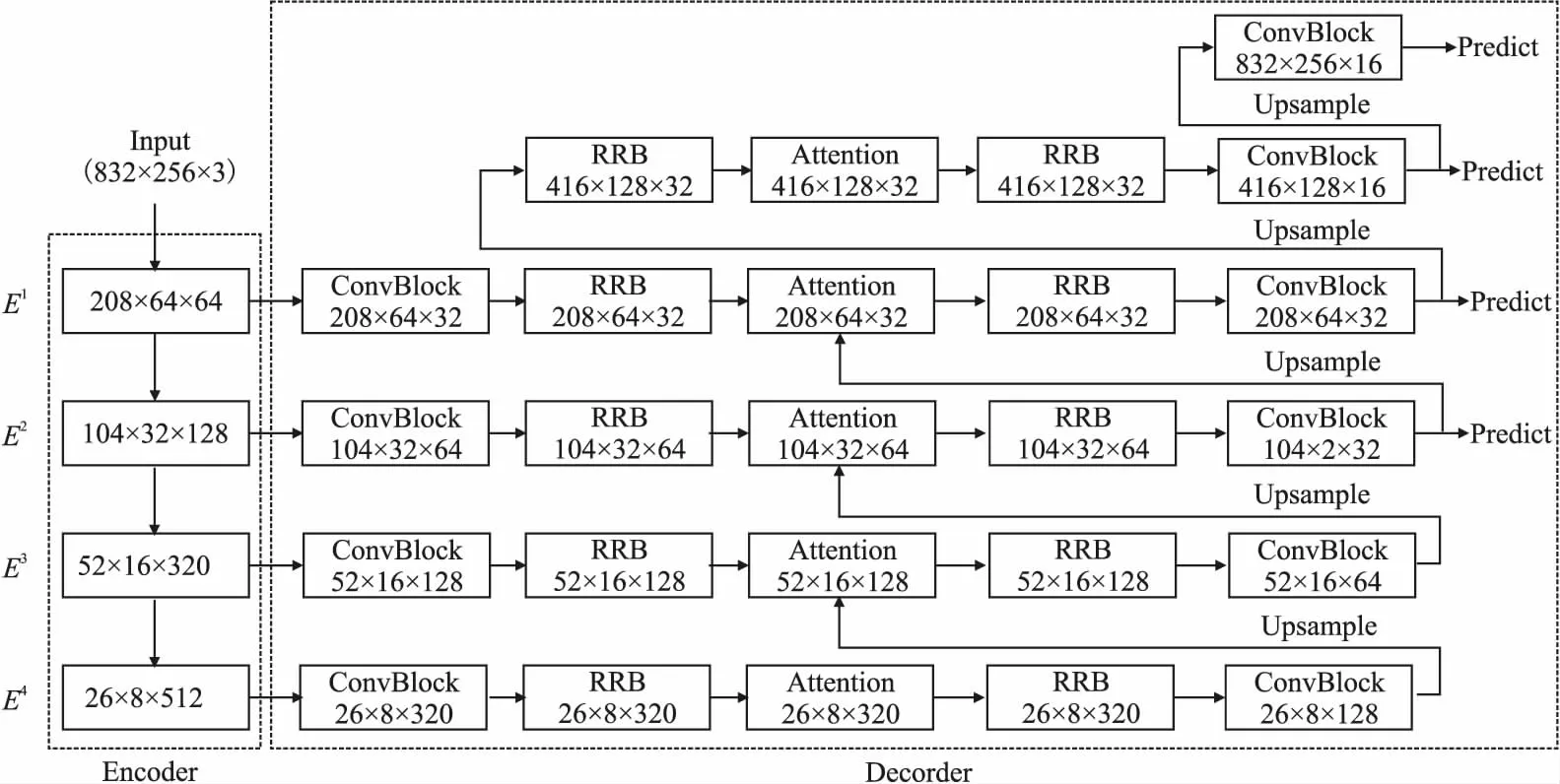
图2 残差通道注意力融合的解码器网络结构Fig.2 Decoder network structure of fusion on residual and channel attention
对于输入大小为832×256大小的RGB图片,图片经过Transformer编码器后得到4个不同尺度的特征图E1、E2、E3、E4.对于特征图E4∈26×8×512,依次进行ConvBlock、RRB、Attention、ConvBlock模块后,通过图中的Upsample双线性插值进行上采样后与E3经过ConvBlock、RRB、Attention的特征进行融合,融合后的特征再进行RRB和CovBlock模块后进行上采样.同理,对E2、E1执行相同的操作,最后,在尺度为104×32×32、208×64×32、416×128×16、832×256×16的特征图上进行预测,即图中的Predict,最终输出为通道数为1的深度图.
对于ConvBlock,其结构由一个为3×3卷积和一个激活层组成.主要起减少特征图通道的作用,也增加了局部上下文信息.

图3 Refinement Residual Block (RRB)模块Fig.3 Refinement Residual Block (RRB) module
对于残差细化模块RRB,其结构如图3所示.模块的第一部分是一个1×1卷积层,将输入的通道固定到具体值,主要起着跨通道的信息整合作用.两个步长为1的3×3卷积、批归一化(Batch Norm)和激活层(ReLU)组成的残差结构不仅可以对特征图进行像素级的细化,还能增强每个阶段的识别能力.
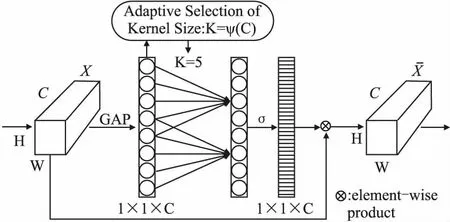
图4 注意力模块Fig.4 Attention module

由于单纯的堆叠注意力模块会导致对特征的反复加权操作,使得网络不能很好的特征表达,从而使网络的性能下降.因此本文在注意力模块后加入残差细化模块,不仅能解决因网络层数的加深而导致的难以优化和收敛问题,还能进一步提炼细化.
本文的位姿估计网络采用和文献[8]相同的网络,以ResNet18[18]作为网络的编码部分,与之不同的是,本文未采用文献[8]的掩膜预测部分,输入为相邻的图像对即6通道图像,输出为6自由度的相机姿态.因此,位姿编码器在第一层具有6×64×3×3的卷积权重,而不是默认3×64×3×3的ResNet权重.网络训练时,加载在ImageNet预训练的ResNet18模型作为编码部分.
2.4 损失函数
本文采用了文献[11] 中提出的损失函数,由光度损失、平滑度损失以及几何一致性损失3个方面组成.
给定相邻两张图片Ia与Ib,使用预测的深度图Da和相对相机位姿Pab,利用可微双线性插值将Ib转化为Ia′,形成光度损失函数见式(6):
(6)
其中,V表示从图像Ia中成功投影到图像L1的有效点数.选择L1范数是因为其对数据中的异常值具有很好的鲁棒性.上述损失由于在真实环境下的光照变化使其不是固定不变的,所以添加额外的相似度损失SSIM[19],其对像素亮度进行标准化来更好的处理复杂的光照变化.修正的光度损失函数如式(7)所示:
(7)
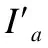
由于光度损失在低纹理区或重复特征区域的效果不佳,因此结合平滑度先验条件对估计的深度图进行调整,平滑度损失定义如式(8)所示:
(8)
对于几何一致性损失,首先计算出深度不一致图Ddiff,其中Ddiff的表达式如式(9)所示:
(9)

(10)
LGC通过最小化连续图像对之间预测的深度值之间的几何距离以及促进他们的尺度一致性.
将上述的3个损失函数加权结合在一起组成最终的损失函数L,如式(11)所示:
(11)

3 实验结果与分析
3.1 实验设置
为了验证本文算法的有效性,采用Eigen[1]分割的KITTI raw dataset[20]进行模型训练和测试,在文献[8]去除静态帧的基础上.本文将数据集的输入大小调整为832×256.在训练过程中,对输入的彩色图片进行随机翻转、随机裁剪两种方式进行增广.
本文在NVIDIA GeForce RTX 3060 GPU上对算法网络进行训练,深度学习框架为PyTorch框架,PyTorch版本为1.8,CUDA版本为11.1.使用Adam(自适应估计)优化器进行优化,学习率为0.0001,设置优化器的超参数β1=0.9,β1=0.999.网络训练165个epoch,步长为4.对于编码器部分,则由ImageNet数据集提供的模型进行初始化,而网络中其它层都是随机初始化的.
为了评估和比较各种深度估计网络的性能,在文献[1]中提出了一种常见的评估方法,其中包含5个评估指标:均方根误差(RMSE)、均方根对数误差(RMSE log)、绝对相对误差(Abs Rel)、平方相对误差(Sq Rel)和不同阈值下的准确率(δ).这些指标的表达式为:
(12)
(13)
(14)
(15)
(16)
3.2 网络消融分析
本文算法主要设置解码器端的通道注意力模块与残差细化模块两个消融因素.为了验证本文算法的有效性,采用以下的方式进行消融实验分析:1)编码器采用Transformer结构,解码器部分仅由ConvBlock模块、以及上采样两个部分组成,称为T-A;2)编码器采用Transformer结构,解码器部分由通道注意力模块、ConvBlock模块、以及上采样3个部分组成,称为T-B;3)编码器采用Transformer结构,解码器部分由残差细化模块、ConvBlock模块以及上采样3个部分组成,称为T-C;4)解码部分器含有通道注意力模块、残差细化模块、ConvBlock模块以及上采样4个部分组成,即本文的算法网络结构(Ours).因为3种网络都具有ConvBlock模块和上采样操作,所以本文就不在表格上呈现这两个模块.
表1所示为设置的3种网络消融实验的结果.从表1中可以看出,本T-B与T-A相比,在绝对相对误差(Abs Rel)上差别不大,但是在其它数据上,T-B网络提升了很多.这得益于通道注意力模块,在不需要大量增加网络的参数条件下,通过对各通道的特征权重配比,对特征图进行自适应的校准,从而提高模型识别的准确性.T-C网络比T-A、T-B网络相比的误差小、准确度高,主要是在编码部分残差细化模块保留了主要的特征,不仅防止了过拟合,还使模型的鲁棒性进一步增强.
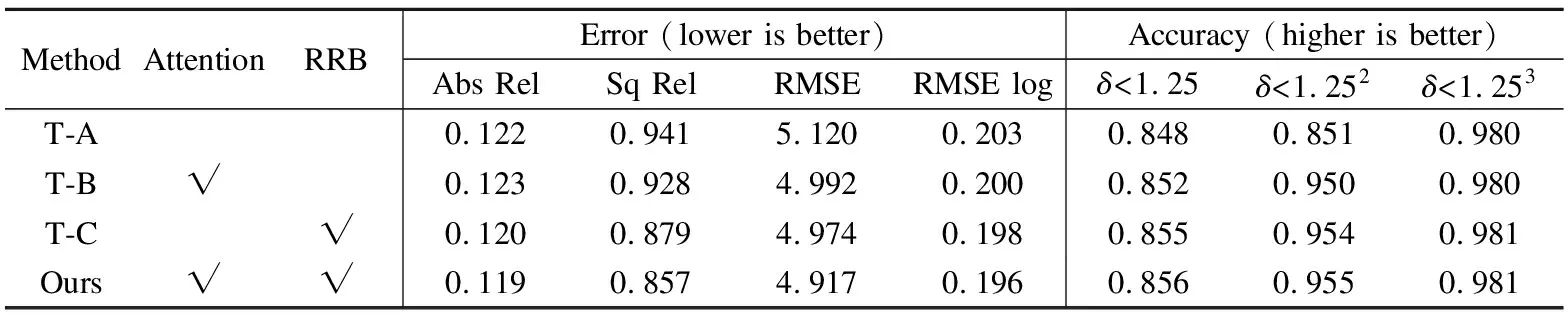
表1 网络消融分析Table 1 Ablation analysis of networks
本文的算法网络(Ours)与T-A、T-B以及T-C网络相比,误差更小,准确率更高.这是因为网络汲取了T-A、T-B两个网络的优点.残差细化模块和通道注意力的联合使用,通过对上下级特征的融合,提高了网络对上下文信息的利用,弥补了单一层级特征信息表达能力不足的问题.

图5 消融实验结果对比Fig.5 Comparison of results of ablation experiment
图5为消融实验的结果对比图.从图5可以看出,本文算法生成的深度图可以对图像的深度信息较好呈现,生成的深度图与其它消融网络相比,具有更好的物体轮廓以及深度连续,这主要得益于通道注意力模块和残差细化模块的联合使用.
3.3 对比实验分析
表2为本文与23种不同的深度估计算法的对比结果.从表中可以看出,本文算法的均方根误差(RMSE)、均方根对数误差(RMSE log)、绝对相对误差(Abs Rel)、平方相对误差(Sq Rel)以及不同阈值下的准确率(δ)在自监督学习方法中都取得了很不错的效果.与Bian[11]相比,本文在均方根误差、均方根对数误差以及绝对相对误差较于Bian[11]分别减少3.2%、21.3%、9.6%,在阈值为δ<1.25、δ<1.252、δ<1.253的准确度分别提升3.1%、1.5%、1%.Bian[11]采用ResNet256作为深度估计与位姿估计的基础网络,模型较大.而本文将多尺度的Transformer结构作为编码器,其模型大小等同于ResNet18网络结构大小,两者相比,本文的网络模型更加的轻量.除此之外,本文解码器中残差细化模块与通道注意力的设计,提升了网络对上下文信息更好利用的同时,也使得在多个尺度上估计的深度的物体轮廓更加清晰和连续.与结果最好的Monodepth2[22]相比,其基于外观损失函数使得网络具有不错的表现.而本文主要在网络模型设计上具有不错的优势,所以两者取得的结果接近.虽然精度还达不到基于监督的方法的效果,但正因如此,自监督学习的深度估计还有更多的发展空间.表中D代表监督方法,即用深度图进行监督,D*代表用深度图辅助监督,S代表用双目自监督,M单目自监督.

图6 不同深度估计算法的结果比较Fig.6 Comparison of results of different depth estimation algorithms
图6所示为本文算法与Zhou[8]、Bian[11]、Monodepth2[22]算法的生成深度图像质量的主观效果对比.其中,图6(a)为原始的RGB图像,图6(b)为Zhou[8]算法的深度图,其深度图中的物体轮廓非常的不明显,但其作为首个用自监督方法的单目深度估计算法,很有对比的意义.图6(c)为Bian[11]所提出算法深度图效果,与Zhou[8]算法相比,其物体轮廓更加清晰,对原图像中的车以及行人都能很好的显示,但其物体边缘细节较为模糊.图6(d)与Bian[11]算法相比,在物体轮廓上相差不大,但是Monodepth2[22]算法能更好的捕捉原图像中距离较远的物体.本文的算法与Monodepth2[22]算法相比,具有更加清晰的物体轮廓信息,且边缘更加锐利,可以从图6(e)中右图的行人可以看出.本文通过多尺度Transformer结构的编码器,从多个尺度提取图像信息.残差通道注意力融合的解码器,更好的物体上下文信息对深度图进行更新,最终生成的深度图像物体轮廓更加清晰、边缘更加锐利.因此,本文算法在深度图的主观视觉效果上优于其他自监督的算法.

表2 不同深度估计算法的结果比较Table 2 Comparison of the results of different depth estimation algorithms
4 结 语
本文提出了一种基于Transformer多尺度注意力的自监督学习单目图像深度估计框架.首次将视觉Transformer应用到自监督学习的单目深度估计任务上,通过消融实验证明了本文残差细化通道注意力融合编码器的有效性.整个框架是端到端进行训练的,并且与自监督学习的方法对比也取得了不错的效果.本文的工作主要是在设计深度估计网络上,并没有对位姿估计网络进行很多工作,下一步工作考虑将视频中的时间性运用起来,设计更加鲁棒、更加轻量的无监督位姿估计网络.
