编码后奖赏影响基于议程的学习:奖赏预期和结果的作用*
2023-04-10姜英杰马潇潇姜元涛任吉梅龙翼婷
姜英杰 马潇潇 姜元涛 任吉梅 龙翼婷
编码后奖赏影响基于议程的学习:奖赏预期和结果的作用*
姜英杰 马潇潇 姜元涛 任吉梅 龙翼婷
(东北师范大学心理学院, 长春 130024)
基于ABR模型考察奖赏预期和奖赏结果对不同难度词对记忆与元记忆的影响。结果发现:(1)限时学习条件下, 奖赏结果促进不同难度词对记忆成绩和学习判断, 奖赏预期仅提高简单词对的记忆成绩。(2)自定步调学习条件下, 定时学习判断时奖赏结果仅影响学习判断; 奖赏预期促进高难度词对的学习时间分配, 从而提高记忆成绩和学习判断。(3)在自定步调学习时, 奖赏预期超越难度成为影响学习时间分配的因素。以上结果表明, 个体会综合奖赏预期、奖赏结果和难度构建学习议程, 足够大的奖赏预期会超越难度成为议程构建的主导因素。但奖赏预期和奖赏结果对记忆成绩、学习时间分配和学习判断的影响受学习条件调节。
奖赏预期, 学习判断, 学习时间分配, 元记忆, 记忆
1 引言
元记忆是对记忆过程进行监测和控制的元认知成分(Flavell, 1979; Flavell & Wellman, 1977), 包括元记忆监测和控制(Nelson, 1990)。元记忆监测(metamemory monitoring)是个体根据记忆材料特征、学习条件与目标、自身记忆特点等对记忆过程和状态的主观评价或判断, 元记忆监测会影响自我调节学习中认知资源的分配。学习判断(judgements of learning, JOLs)是一种前瞻性元记忆监测指标, 是个体在学习之后对于已学习项目在未来测试中成功回忆可能性的预测(Dunlosky & Nelson, 1992)。元记忆控制(metamemory control)是在元记忆监测基础上进行的对记忆过程的调节和控制(Nelson, 1990), 自定步调学习时的学习时间分配(study time allocation)是元记忆控制的核心成分。
有研究表明, JOLs和学习时间分配受项目难度影响(Koriat & Ackerman, 2010; Price et al., 2010)。但另有研究却发现项目难度对JOLs和学习时间分配的影响存在不一致的结果:当实验指导语为记住一个项目得1分, 要求尽量得更多分时, 被试会优先学习容易项目并给其更高JOLs (Koriat & Nussinson, 2009)。但当困难项目价值更高时, 个体就会优先学习困难项目并分配更多学习时间, JOLs也以价值为导向(Koriat & A ckerman, 2010; Price et al., 2010)。为解决上述争议, Ariel等人(2009)引入奖赏结构(reward structure), 包括项目价值和项目测试可能性, 考察其对不同难度项目学习时间分配的影响。发现不论加工容易还是困难项目, 个体会依据项目测试可能性进行项目选择, 优先学习测试可能性较高(90%)的项目; 将测试可能性换成项目价值, 结果相同, 即个体依据项目价值做项目选择。
上述研究表明, 当项目同时具有难度和奖赏结构上的不同特征时, 学习者并非先考虑项目难度, 而是优先依据项目的奖赏结构进行JOLs和项目选择, 即奖赏结构对JOLs和学习时间分配的影响超过了项目难度。据此, 有研究提出了基于议程的调节模型(Agenda-Based Regulation Model, ABR)来解释学习者综合考虑项目难度和价值后建立的议程对学习时间分配的影响(Ariel et al., 2009; Yu et al., 2020)。该模型认为, 个体会综合任务要求等学习条件, 构建学习议程, 并在此基础上不断调整自己的学习行为。在这一过程中, 足够高的项目价值能够取代难度对JOLs和学习时间分配产生主导性影响。
但是, ABR模型仅将项目价值和测试可能性作为奖赏结构, 未对奖赏加工的不同时段进行区分。依据发生在奖赏期待和奖赏获得两个不同时段, 奖赏加工分为欲求阶段(appetitive phase)和执行阶段(consummatory phase), 对应于这两个时段的奖赏结构分别是奖赏预期(reward expectation)和奖赏结果(reward outcome)两种成分(Mason et al., 2017)。奖赏预期是被试对成功记忆项目能获得收益的猜测, 奖赏结果是被试成功记忆该项目后获得的分值或奖赏。先前研究对项目价值或测试可能性的呈现均在项目呈现前, 被试在项目编码前已知成功记住该项目能获得的奖赏, 无需猜测可能获得的收益, 不产生奖赏预期。因此, ABR模型只考虑了奖赏结果对学习时间分配的影响, 而忽略了奖赏预期的作用。如果在项目呈现前仅用指导语告知成功记住该项目会获得奖励, 具体分值在编码后呈现, 被试就会对项目产生奖赏预期, 能够考察奖赏预期对JOLs和学习时间分配的影响。
Soderstrom和McCabe (2011)引入价值呈现顺序这一变量, 控制价值在项目前或后呈现, 考察因价值呈现顺序带来的奖赏预期、奖赏结果和词对相关程度(即难度)对JOLs的影响。结果发现, 在固定步调学习中, JOLs仅受奖赏结果的影响, 而与价值呈现顺序无关; 而在自定步调学习中, 价值呈现顺序虽仍不影响JOLs, 但呈现顺序和奖赏结果对学习时间分配的影响存在交互作用——仅当价值呈现在编码前时, 奖赏结果才能够影响学习时间分配和回忆成绩, 而当价值在编码后呈现时, 奖赏结果的效应消失。但这一结果可能是因其变量和条件设置局限导致:实验中的每个项目都匹配了价值, 导致不论价值呈现在编码前、后, 被试都会对分值结果产生预期, 存在奖赏结果和奖赏预期的混淆, 且考察奖赏预期作用时缺少无预期作为基线比较。因此该研究实际上无法对奖赏预期是否影响JOLs和学习时间分配, 以及奖赏预期高低怎样影响JOLs和学习时间分配等问题做出解释。
综上, 已有研究缺乏对奖赏预期影响JOLs和学习时间分配的有效考察, ABR模型尚需通过奖赏预期成分进行验证。因此, 本研究将奖赏预期成分补充进ABR模型中, 验证在基于难度与价值的学习议程构建中, 足够高的奖赏预期是否能够取代难度对JOLs和学习时间分配产生主导性影响。共3个实验:实验1在 Soderstrom和McCabe (2011)的实验基础上加入控制组, 旨在通过将奖赏后置呈现考察奖赏预期对限时学习时JOLs和回忆正确率的影响; 实验2取消学习时限被试自主控制学习时间, 旨在考察后置条件下奖赏对学习时间分配的影响。实验3在实验2的基础上, 通过操纵价值梯度来控制奖赏预期, 旨在考察后置条件下奖赏预期梯度大小对自定步调学习的影响。
2 实验1:编码后奖赏与项目难度对限时学习的影响
实验1通过2 (难度:简单、困难) × 2 (奖赏预期:有、无)和2 (难度:简单、困难) × 2 (奖赏结果:高、低)实验设计, 将价值后置探究奖赏预期、奖赏结果和难度对被试JOLs和回忆正确率的影响。奖赏组以价值高低作为控制奖赏结果的方法。而非奖赏组不设任何分值作为基线。由于价值呈现在项目后, 价值不能作为记忆的有效线索, 因此假设奖赏结果对被试回忆正确率无显著影响, 而对JOLs影响显著。
2.1 实验方法
2.1.1 被试
依据前人研究中的平均效应量= 0.6来确定被试量(Peng & Tullis, 2021)。(1 − β) = 0.95, 使用G* Power 3进行效能分析, 发现α = 0.05时推荐的最小被试量为8人。实验2被试量的计算同上。
东北师范大学60名在校大学生参与了本次实验, 根据被试报名顺序随机分配为奖赏组(29人)和非奖赏组(31人), 记忆材料平均通过率为0.3~0.55 (Yu et al., 2020), 5名被试的数据因记忆正确率低于10%而剔除。有效被试55名(男24人, 女31人, 平均年龄20.35岁,= 2.34)。被试视力正常或矫正视力正常, 无脑损伤或精神病史, 之前未参加过类似实验。所有被试自愿参加本实验, 在实验开始前签署知情同意书, 实验结束后获得相应报酬。
2.1.2 实验材料
以线索回忆通过率为指标确定词对难度, 选取高(通过率: 0.03~0.13)、低(通过率: 0.63~0.87)难度词对各30对用于正式实验, 另外选取7个中等难度词对用于练习, 共计67个中性词对构成本实验材料(Yu et al., 2020), 例如“电报(线索词)—茶叶(目标词)”。词频控制在0.00076~0.00997, 笔画数范围在7~30画, 音节数范围在4~6个。
为避免首因和近因效应, 正式实验中最初2个和最后2个词对作为填充刺激不计入数据分析(Soderstrom & McCabe, 2011), 有效词对共计56个, 简单和困难词对各半。在奖赏组, 每个词对都匹配了0~6中一个分值。因此, 各价值条件下分别有8个trial。
2.1.3 实验仪器
实验程序使用E-Prime 2.0软件编写。实验设备采用配有21英吋CRT彩色纯平显示器的联想多媒体计算机, 分辨率为1024×768, 刷新率为75 Hz。使用SPSS 26.0软件进行数据处理与分析。
2.1.4 实验程序
实验分为学习阶段和测试阶段。学习阶段具体流程见图1。首先, 屏幕上呈现一个注视点0.5 s, 提醒被试集中注意; 之后, 屏幕上呈现一组双字词对, 被试需要在4s内对其进行记忆; 然后, 奖赏组被试的屏幕上会呈现0~6不等的分值1 s, 如果测试阶段能够成功回忆该词对, 会获得与其分值匹配的额外被试费。控制组被试屏幕上呈现一个等时的空屏; 最后, 被试需要对之后能否正确回忆做0~100的信心判断, 并用数字键盘输入。共计60个词对, 学习30个词对后休息, 待被试状态恢复后完成剩余30个词对的学习。学习阶段结束后进行“自2000开始的连续减3”干扰任务3分钟, 之后进入测试阶段:所有线索词呈现在Excel表中, 不限时回忆与之对应的目标词并输入。无法回忆的项目跳过并继续作答。
2.2 结果
实验1中各价值项目及控制组的回忆正确率和JOLs值见表1。
2.2.1 无奖赏和0价值对回忆正确率影响

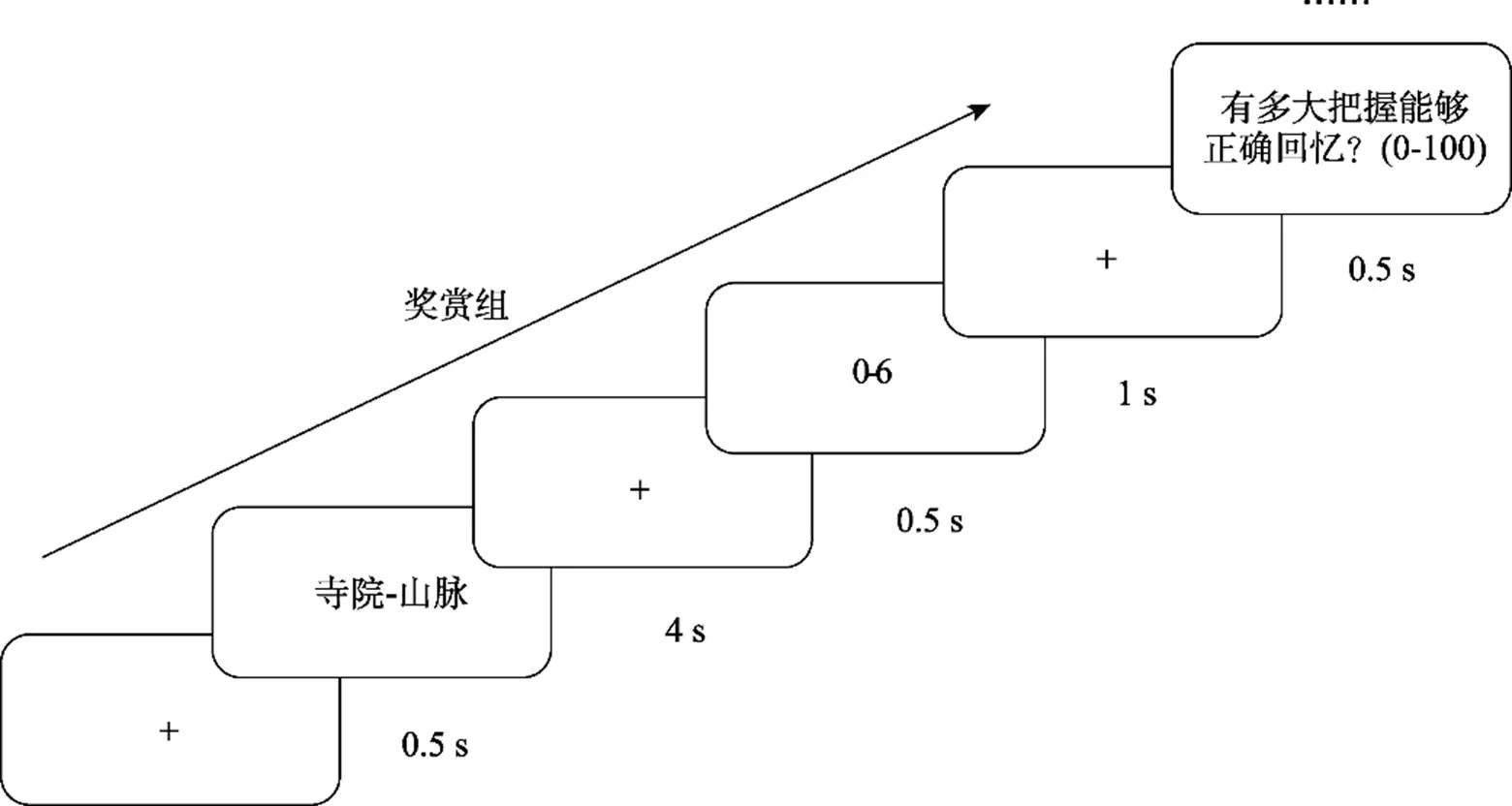
图1 实验1奖赏组学习阶段流程图
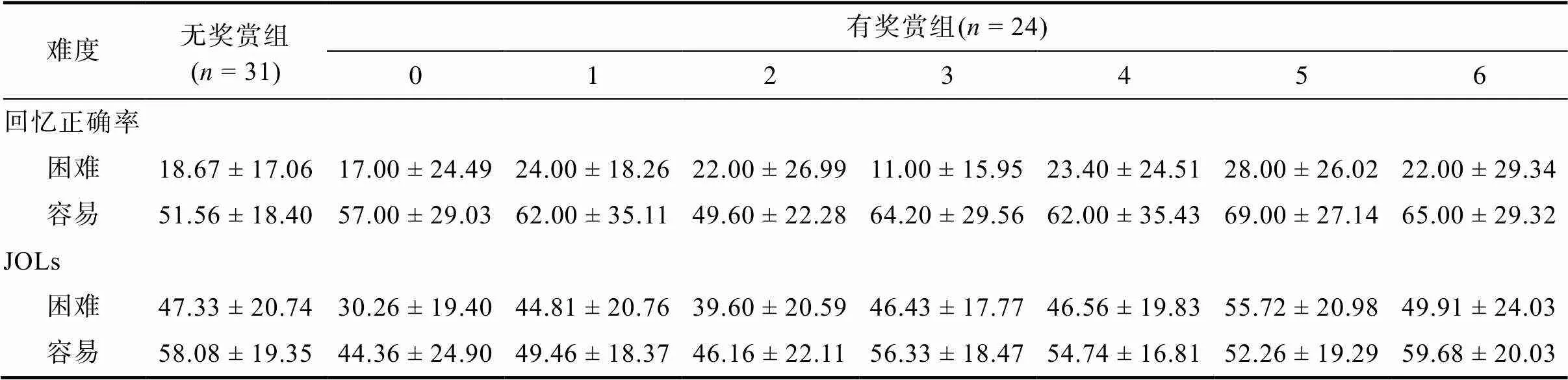
表1 有奖赏组与无奖赏组的回忆正确率和学习判断的平均数和标准差(M ± SD)
2.2.2 无奖赏和0价值对JOLs影响
与有奖赏结果中的1~6价值相比, 0价值词对无法为被试带来任何收益, 被试认识到对0价值词对的记忆会造成认知资源的浪费。因此在得到0价值结果后, 在进行JOLs时就不会再对该词对进行复述等继续加工, 但无奖赏词对在做JOLs时被试会做复述。JOLs结果也验证了上述推测, 被试对无奖赏词比对0价值词对的JOLs更高。但是, 这种对0价值词对在JOLs时的不复述, 本该导致0价值词对的记忆成绩低于无奖赏条件的词对, 可实际上二者并无显著差异。这可能是因为与无奖赏条件相比, 0价值词对的编码受到了奖赏预期的额外促进, 奖赏预期的促进作用与0价值奖赏结果的削弱作用相抵消, 才导致了0价值与无奖赏条件下词对的回忆正确率无显著差异。
2.2.3 奖赏预期与难度对JOLs的影响
2.2.4 奖赏预期与难度对回忆正确率的影响

2.2.5 奖赏结果与难度对JOLs的影响


图2 不同组别和难度的JOLs回忆和正确率
注:*< 0.05, **< 0.01, ***< 0.001, 下同,误差线为标准差
2.2.6 奖赏结果与难度对回忆正确率的影响
2.3 讨论
实验1改进先前实验范式(Soderstrom & McCabe, 2011), 考察后置价值与难度对限时学习的影响。发现记忆困难词对时, 奖赏和非奖赏组回忆成绩差异不显著。而记忆简单词对时差异显著, 表明奖赏组产生的奖赏预期促进了被试简单词对记忆, 验证了本研究奖赏预期能促进编码的假设。而在记忆困难词对时, 奖赏与非奖赏组间记忆成绩和JOLs都无显著差异, 可能是因词对过难, 被试无法在有限时间内(4 s内)根据奖赏预期分配认知资源完成有效学习。先前研究发现学习时间是影响被试JOLs和学习成绩的因素。因此, 实验2中的编码阶段改用不限时的自定步调学习, 进一步探究奖赏预期和难度对回忆正确率以及元记忆监测和控制的影响。
另外, 奖赏结果对学习成绩有显著影响, 高价值比低价值和0价值词对回忆正确率更高。可能因被试在不限时JOLs阶段对高价值词对进行多次复述提取, 而对0价值和低价值项目较少复述提取。为排除JOLs阶段的记忆巩固效应, 实验2改为固定时长的JOLs。
3 实验2:编码后奖赏与项目难度对自定步调学习的影响
将学习时间限制取消, 进行自定步调学习, 探究奖赏预期、奖赏结果和难度对学习时间分配、JOLs以及回忆正确率的影响; 并将JOLs改为固定时长, 防止JOLs阶段进行记忆巩固。根据实验1结果, 实验2采用自定步调学习时间和固定时长JOLs, 由于价值呈现在编码后, 假设奖赏结果只能影响被试的学习判断, 对回忆正确率无显著影响, 而奖赏预期影响学习时间分配, 从而影响记忆成绩。
3.1 实验方法
3.1.1 被试
东北师范大学60人参与本实验, 根据被试报名顺序随机分配为奖赏组(30人)和非奖赏组(30人), 6名被试因记忆正确率低于10%剔除, 2名被试因参与类似实验经历导致练习效应被剔除, 故有效被试52名(男生25人, 女生27人, 平均年龄20.35岁,= 2.34)。被试要求同实验1。

图3 不同价值和难度的JOLs和回忆正确率
3.1.2 实验材料
同实验1。
3.1.3 实验仪器
同实验1。
3.1.4 实验程序
与实验1基本一致, 改2处:(1)取消学习时限, 被试认为记住后, 按“空格”键进入下一屏学习。(2)学习判断时间控制在2 s (见图4)。
3.2 结果分析
实验2中各价值项目及控制组的学习时间见表2, 回忆正确率和JOLs值见表3。
3.2.1 无奖赏和0价值对回忆正确率影响

3.2.2 无奖赏和0价值对JOLs影响

图4 实验2奖赏组学习阶段流程图

表2 有奖赏组与无奖赏组学习时间的平均数及标准差(M ± SD)

表3 有奖赏组与无奖赏组的回忆正确率和学习判断值的平均数及标准差(M ± SD)
3.2.3 奖赏预期与难度对学习时间分配的影响
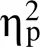
3.2.4 奖赏结果与难度对学习时间分配的影响
3.2.5 奖赏预期与难度对JOLs的影响


图5 不同组别、不同价值和难度的学习时间

图6 不同组别和难度的JOLs和回忆正确率
3.2.6 奖赏预期与难度对回忆正确率的影响

3.2.7 奖赏结果与难度对JOLs的影响
3.2.8 奖赏结果与难度对回忆正确率的影响
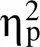
3.3 讨论
与实验1结果类似, 词对难度对回忆成绩、学习判断和学习时间分配均有影响, 困难词对被分配更多学习时间, 而简单词对回忆成绩和JOLs却高于困难项目。再次证明, 难度是个体进行学习判断的重要内部线索, 也是影响学习时间分配的重要因素。
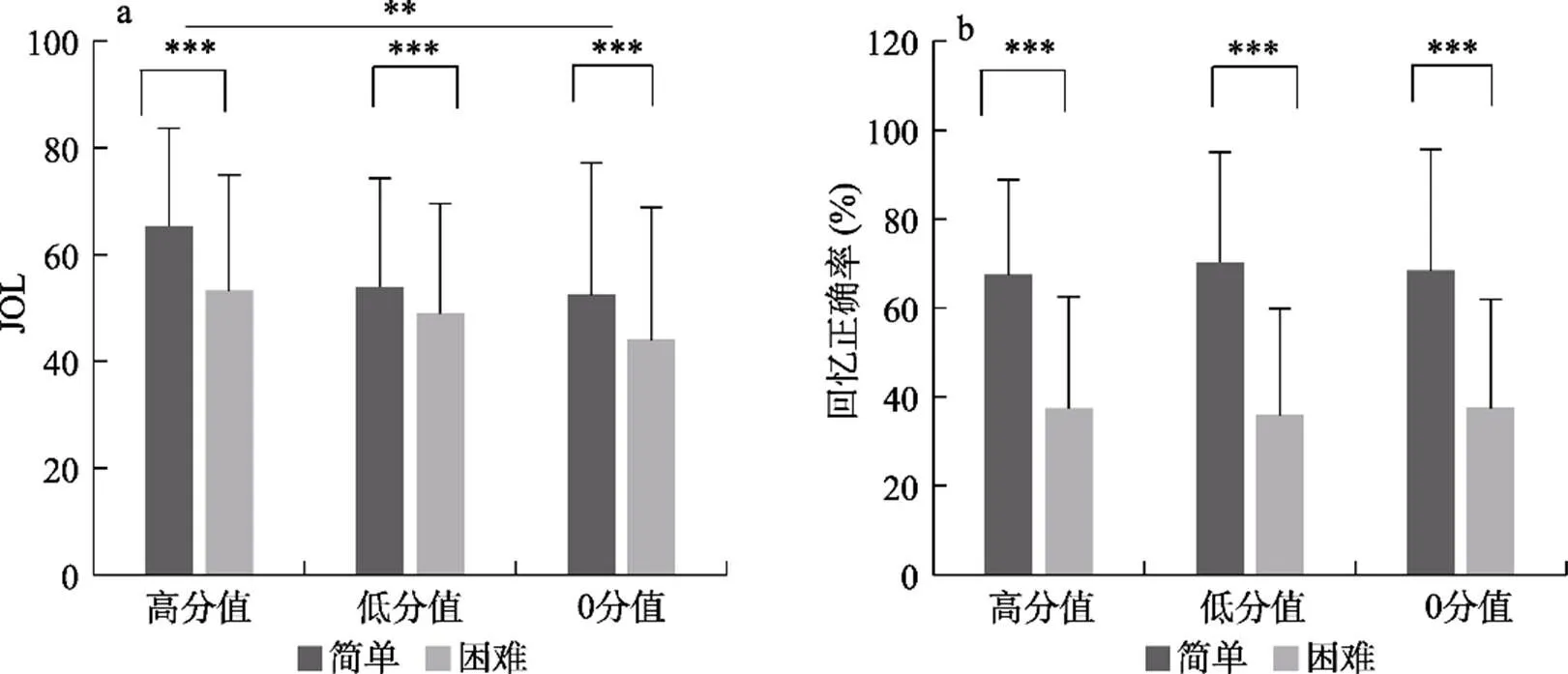
图7 不同价值和难度的JOLs和回忆正确率
价值呈现于词对充分编码后, 被试在编码阶段无法得知价值(奖赏结果)的高低, 因此奖赏结果仅对JOLs产生影响, 而无法对学习时间产生影响, 表现为高价值词对的JOLs显著高于低价值词对, 而高低价值词对的学习时间没有差异。并且, JOLs阶段时间固定, 被试无法根据奖赏结果在此阶段进行复述巩固, 因此, 高低价值词对回忆正确率无显著差异。验证实验2的假设: 实验1中奖赏结果对记忆成绩的影响是因被试在JOLs阶段进行了记忆巩固, 实验2将JOLs改为定时, 被试无法在此阶段对高价值项目进行充分复述, 奖赏结果仅影响被试的元记忆监测, 不影响记忆成绩, 与先前研究结果一致(Dunlosky & Connor, 1997; Mazzoni & Cornoldi, 1993; Soderstrom & McCabe, 2011)。
通过奖赏与非奖赏组比较, 可以得到奖赏预期对JOLs、学习时间以及回忆成绩的影响。结果发现, 自定步调学习条件下, 记忆困难词对时, 奖赏组被试JOLs和学习时间高于非奖赏组; 而记忆简单词对时, 奖赏与非奖赏组学习时间分配的差异相比于困难词对时变小, JOLs差异不显著。表明在元记忆监测过程中, 难度高时个体会根据奖赏预期进行学习判断和学习时间分配; 而难度降低时, 奖赏预期不再成为学习判断和学习时间分配的重要依据。即随着难度的降低, 奖赏预期对学习时间分配的影响在变小。但是, 这并未体现在回忆成绩上, 高低难度词对的回忆正确率都表现出奖赏预期的促进作用。综上, 奖赏预期对元记忆监测和控制的作用会受到难度的影响, 而这种影响并未体现在回忆成绩上。
在自定步调学习时, 有奖赏预期但无奖赏结果的0价值回忆正确率显著高于无奖赏组, 表明在学习时间充足时, 奖赏预期促进被试的记忆成绩。通过比较学习时间可以发现, 有奖赏预期组被试在编码阶段对词对进行充分编码以获得更高的成绩, 因此与实验1相比, 被试对0价值词对的回忆正确率和JOL都显著提高。
奖赏结果对JOLs有显著影响, 高、低价值都和0价值有显著差异。但高、低价值间无显著差异, 表明奖赏结果对元记忆监测的作用可能会受到奖赏结果梯度影响, 梯度足够大时才有明显作用。并且当奖赏预期和难度同时存在时, 二者哪个会成为影响学习的主要依据需进一步探究。因此, 实验3中进一步操控奖赏预期, 考察奖赏预期大小对自定步调学习的影响。
4 实验3:不同梯度奖赏预期与项目难度对自定步调学习的影响
进一步操控奖赏预期大小, 考察其对自定步调学习学习时间分配、JOLs和回忆正确率的影响。如果奖赏预期的大小影响回忆正确率(Yu et al., 2020), 那么大梯度奖赏预期比小梯度奖赏预期对学习不同难度词对时的学习时间分配有更大促进作用。
4.1 实验方法
4.1.1 被试
依据前人研究中的平均效应量= 0.6来确定被试量(Undorf & Bröder, 2020; Undorf et al., 2018)。通过Gpower 3计算得出, 1 − β = 0.95,= 0.05时推荐的最小被试量为8人。东北师范大学18名在校大学生参加本实验, 因记忆成绩过低筛除3名被试, 故有效被试15名(男生4人, 女生11人, 平均年龄22.00岁,= 2.17岁)。被试要求同实验1。
4.1.2 实验材料
因实验3价值数目由7变为6, 故从实验1中选取48个词对作为实验3的材料, 每个价值包括8个词对, 困难与简单词对各24个。
4.1.3 实验仪器
同实验1。
4.1.4 实验程序
与实验2基本一致, 但实验3取消控制组改为被试内设计(见图8)。被试学习两个block, 一个block项目价值为1、3、6 (低奖赏预期), 另一个block项目价值为1、6、12 (高奖赏预期)。每一个block开始前, 告知被试接下来一组词的分值。呈现顺序被试间平衡。
4.2 结果
实验3中各价值项目的学习时间见表4, 回忆正确率和JOLs值见表5。
4.2.1 奖赏预期与难度对学习时间分配的影响
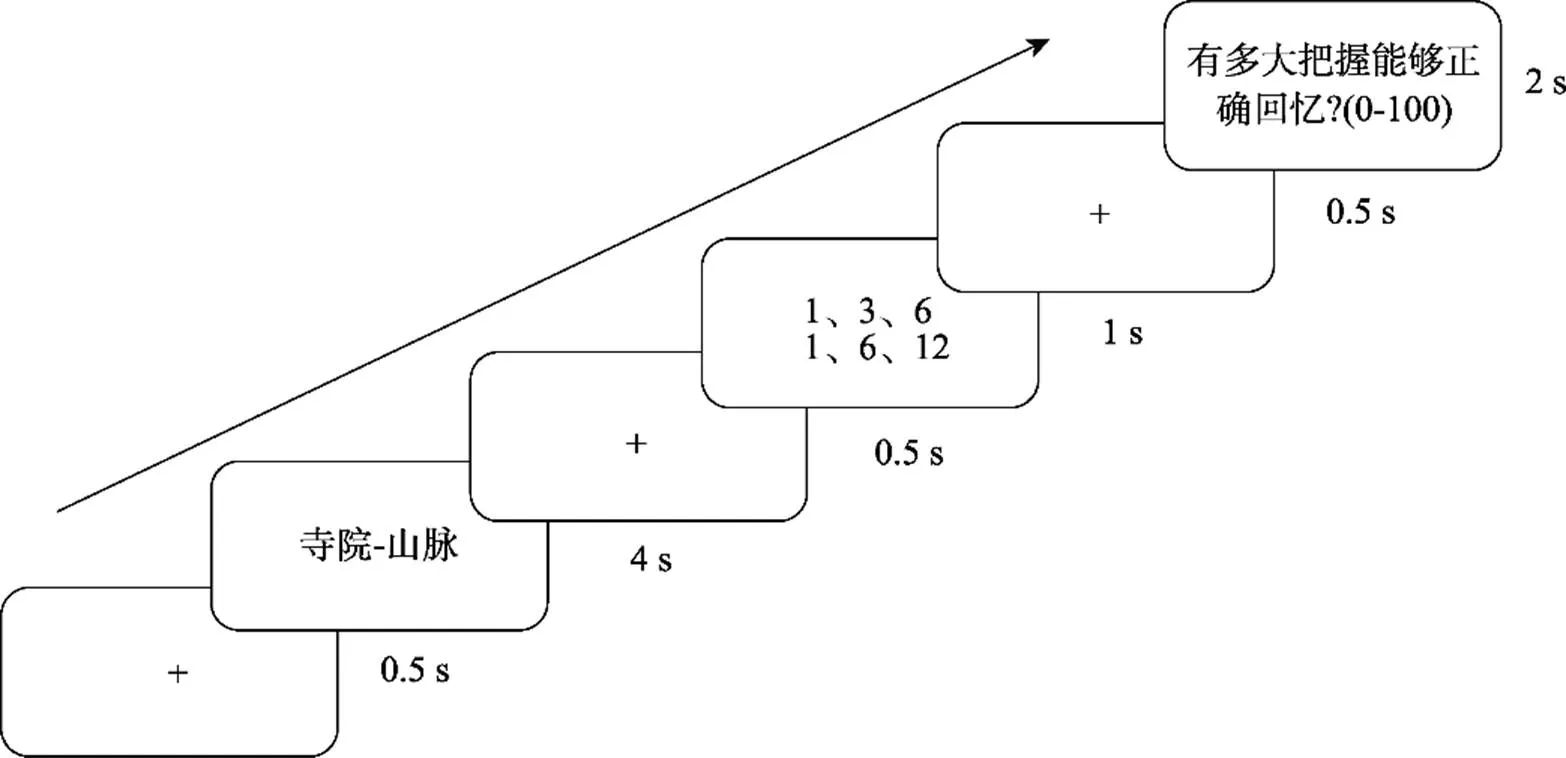
图8 实验3学习阶段流程图

表4 各价值项目的学习时间的平均数及标准差(M ± SD, n = 15)

表5 各价值项目的回忆正确率和学习判断值的平均数及标准差(M ± SD, n = 15)
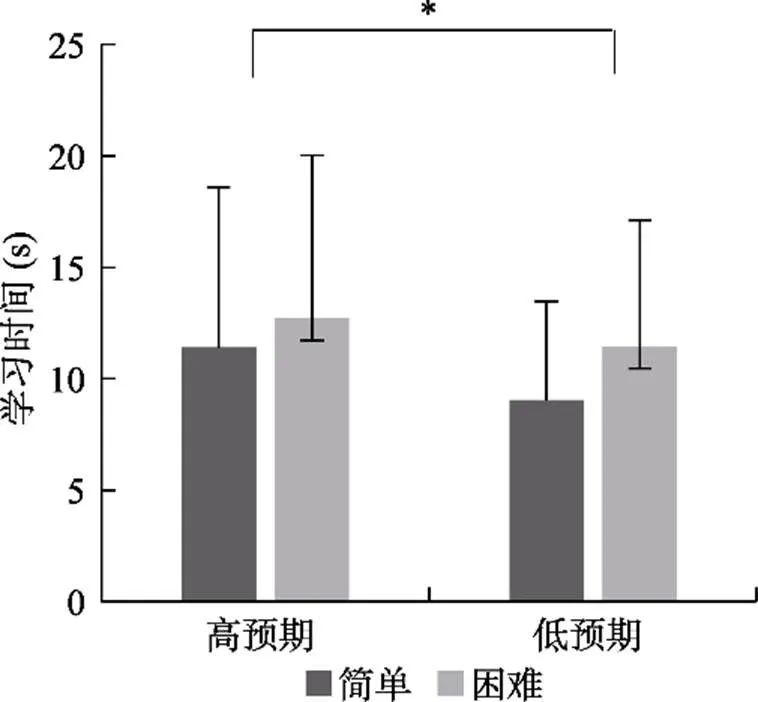
图9 不同奖赏预期和难度对学习时间分配的影响
4.2.2 奖赏预期与难度对JOLs的影响

4.2.3 奖赏预期与难度对回忆正确率的影响

图10 不同奖赏预期和难度的JOLs和回忆正确率
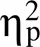

图11 不同奖赏预期价值1和难度的回忆正确率
4.3 讨论
结果表明, 难度作为个体元记忆监测的重要内部线索, 依然对个体学习判断产生影响, 简单词对JOLs高于困难词对; 同时难度对回忆成绩的影响也是稳定存在的, 简单词对回忆成绩高于困难词对。然而在学习时间分配上, 难度的主效应消失, 这与实验2结果并不一致。可能是由于在实验3中, 价值梯度增大, 被试可以更清楚地觉察到奖赏预期的重要性, 从而使奖赏预期取代难度成为影响学习时间分配的主要依据(Ariel et al., 2009; Yu et al., 2020)。
奖赏预期对JOLs、学习时间分配及回忆成绩均产生影响。表现为高预期项目JOLs、学习时间和回忆成绩均高于低预期项目。结合实验1和实验2的结果, 在后置条件下, 奖赏结果和奖赏预期对个体记忆和元记忆的影响存在分离。具体来说, 奖赏结果仅促进了个体在编码完成后的记忆巩固, 而奖赏预期的有无和奖赏预期的高低对个体编码和元记忆监控均产生影响。
5 总讨论
本研究考察了奖赏结果、奖赏预期和项目难度对学习时间分配、JOLs和回忆正确率的影响, 把奖赏预期的作用补充进ABR模型。
5.1 奖赏结果、奖赏预期和项目难度对元记忆监测和控制的影响
本研究结果表明, 奖赏结果、奖赏预期和项目难度会对个体元记忆监测产生影响。实验1通过改进Soderstrom和McCabe (2011)的实验程序, 发现个体会依据奖赏结果、奖赏预期和难度线索进行学习时间分配和JOLs。在记忆表现上, 奖赏预期和难度的交互作用显著, 限时学习时奖赏预期可以促进个体对简单词对的记忆成绩。而个体的JOLs呈现出价值导向, 高价值项目JOLs高于低价值项目, 这表明了奖赏结果能够促进个体的元记忆监测过程。
由于本研究奖赏结果呈现于控制过程后, 故而奖赏结果无法影响个体元记忆控制过程。实验2与实验3中由于限制了JOLs的时间, 奖赏结果对记忆成绩的影响消失, 但仍对JOLs产生影响。实验2和实验3中关于奖赏预期和项目难度对学习时间分配的相关结果表明, 奖赏预期和项目难度都会对元记忆控制产生影响, 通过自定步调学习时间, 被试有足够的时间进行编码, 奖赏预期的作用突显出来。并且通过纵向分析实验2和3的结果可以看出, 随价值梯度加大, 奖赏预期能取代难度成为元记忆控制的主导线索。
为突出奖赏结果和奖赏预期各自对元记忆监测和控制的影响, 本研究分别以奖赏结果和奖赏预期两种视角对奖赏组和无奖赏组进行了比较。但是, 这种比较方式却忽视了奖赏组和无奖赏组之间奖赏结果和奖赏预期共同影响带来的差异。因此本文将有奖赏预期但无奖赏结果的0价值, 与无奖赏预期且无奖赏结果的无奖赏组进行比较, 结果发现二者仅在元记忆层面有显著差异。这一结果可能是由于奖赏预期的促进作用与无结果的抑制作用相抵消, 使被试的回忆正确率与无奖赏相同。为进一步分析奖赏预期的作用, 在实验3中将高奖赏预期组价值1与低奖赏预期组价值1进行比较, 二者均作为价值的起始点且奖赏结果相同。结果表明在奖赏结果相同的情况下, 高奖赏预期组回忆正确率高于低奖赏预期组, 表明了奖赏预期的作用。未来研究可以改进实验范式以及数据分析方法, 在控制奖赏结果和奖赏预期共同影响的基础上, 独立地分析奖赏结果和奖赏预期对个体元记忆监测和控制的影响。
5.2 对基于议程模型的支持和补充
先前研究表明, 基于议程模型中价值对学习时间的影响具有时间依赖性(Soderstrom & McCabe, 2011), 具体来说, 当价值呈现在项目前或与项目同时呈现时, 价值会对自定步调学习产生影响。然而价值呈现方式不同会产生不同的奖赏结构成分, 先于或同时与项目呈现的价值, 其本质为奖赏结果; 价值在项目后呈现, 此时会引发奖赏预期。将两者统称为“价值”并不能清晰说明奖赏结构中不同成分对自主学习的影响(Mason et al., 2017)。因此, 先前研究中对价值呈现时间不同所形成的“奖赏预期”和“奖赏结果”的界定并不明晰。
本研究区分了奖赏预期和奖赏结果对自主学习的影响, 补充和完善了基于议程的自主学习模型。首先, 在价值后置的条件下, 自主学习会受到奖赏预期的影响, 并且通过操纵价值梯度增大使得奖赏预期变大, 奖赏预期可以取代难度成为元记忆监控的决定性线索, 在支持议程模型原有假设的基础上进一步扩展了奖赏预期对自我调节学习的影响。其次, 奖赏预期与奖赏结果对自主学习的影响机制不同。具体来说, 当价值呈现在编码前时, 个体不存在奖赏预期, 此时个体根据已知的奖赏结果建立议程, 并以此为基础开展学习活动; 当价值呈现在编码后时, 主要是奖赏预期对自主学习产生影响, 个体根据奖赏预期建立议程, 在此基础上对自主学习进行调整。
5.3 对教育教学实践的启示
个体如何高效利用有限的认知资源来提高记忆成绩是元记忆研究要解决的关键问题。学习过程中记忆材料的难度并不相同(Laursen & Fiacconi, 2021), 为提高学习效率, 学习者需要综合考虑材料价值、难度和可用学习时间等因素进行合理的认知资源分配。本研究通过设置后置奖赏的方式考察了奖赏预期和奖赏结果对个体记忆以及元记忆过程的影响, 其研究发现有如下教育启示:第一, 在教学中可以恰当设置奖赏来促进个体自主学习效果。如, 学习前预告成功记忆会获取一定的奖赏, 但不明确具体奖赏数额而在学习后呈现具体数额, 比在学习前明确告知具体数额或者分值, 对学习者的学习时间分配会有更好的促进作用; 第二, 对较难材料的学习, 在学习前给予奖赏预期会促进学习时间分配进而促进记忆效果提升, 但要注意给学生自主分配学习时间和调节学习进程的机会, 而不是由教师来控制学习时间和进程。因为如果学习时间过短会影响个体对于奖赏预期的权衡, 减弱奖赏预期对学习时间分配和学习效果的提升作用; 第三, 相比于容易项目, 困难项目学习可获得的奖赏预期更大时, 奖赏预期的作用在学习时间分配中取代难度成为主要影响因素。所以在教学中, 可以通过设置不同的奖赏预期梯度来引导个体对于更困难材料分配更多学习时间, 从而提高记忆成绩。
6 结论
本研究通过3个实验考察奖赏预期和奖赏结果对学习时间分配、回忆正确率和JOLs的影响,结论如下:
(1)个体会综合奖赏预期、奖赏结果和难度构建学习议程, 足够大的奖赏预期会超越难度成为议程构建的主导因素。
(2)奖赏预期和奖赏结果对记忆成绩、学习时间分配和学习判断的影响受学习条件调节。
Ariel, R., Dunlosky, J., & Bailey, H. (2009). Agenda-based regulation of study-time allocation: When agendas override item-based monitoring.(3), 432−447.
Castel, A. D., Farb, N. A., & Craik, F. I. (2007). Memory for general and specific value information in younger and older adults: Measuring the limits of strategic control.(4), 689−700.
Dunlosky, J., & Connor, L. T. (1997). Age differences in the allocation of study time account for age differences in memory performance.(5), 691−700.
Dunlosky, J., & Nelson, T. O. (1992). Importance of the kind of cue for judgments of learning (JOL) and the delayed-JOL effect.(4), 374−380.
Flavell, J. H. (1979). Metacognition and cognitive monitoring: A new area of cognitive-developmental inquiry.(10), 906−911.
Flavell, J. H., & Wellman, H. M. (1977). Metamemory. In R. Kail & J. Hagen (Eds.),(pp. 3–33). Hillsdale, NJ: Erlbaum.
Koriat, A., & Ackerman, R. (2010). Metacognition and mindreading judgments of learning for self and other during self-paced study.(1), 251−264.
Koriat, A., & Nussinson, R. (2009). Attributing study effort to data-driven and goal-driven effects: Implications for metacognitive judgments.(5), 1338−1343.
Laursen, S. J., & Fiacconi, C. M. (2021). Examining the effect of list composition on monitoring and control processes in metamemory.,(3), 498−517.
Mason, A., Farrell, S., Howard-Jones, P., & Ludwig, C. J. H. (2017). The role of reward and reward uncertainty in episodic memory., 62−77.
Mazzoni, G., & Cornoldi, C. (1993). Strategies in study time allocation: Why is study time sometimes not effective?(1), 47−60.
Nelson, T. O. (1990). Metamemory: A theoretical framework and new findings.,(8), 125−173.
Peng, Y., & Tullis, J. G. (2021). Dividing attention impairs metacognitive control more than monitoring.,(6), 2064−2074.
Price, J., Hertzog, C., & Dunlosky, J. (2010). Self-regulated learning in younger and older adults: Does aging affect metacognitive control?(3), 329−359.
Soderstrom, N. C., & McCabe, D. P. (2011). The interplay between value and relatedness as bases for metacognitive monitoring and control: Evidence for agenda-based monitoring.(5), 1236−1242.
Undorf, M., & Bröder, A. (2020). Cue integration in metamemory judgements is strategic.(4), 629−642.
Undorf, M., Söllner, A., & Bröder, A. (2018). Simultaneous utilization of multiple cues in judgments of learning.(4), 507−519.
Yu, Y., Jiang, Y., & Li, F. (2020). The effect of value on judgment of learning in tradeoff learning condition: The mediating role of study time.(3), 435−454.
The effect of after-encoding rewards on agenda-based learning:The role of reward expectation and reward outcome
JIANG Yingjie, MA Xiaoxiao, JIANG Yuantao, REN Jimei, LONG Yiting
(School of Psychology, Northeast Normal University, Changchun 130024, China)
Metamemory monitoring is a process in which individuals subjectively evaluate or judge the memory process and state, and the common indicator is judgments of learning (JOLs). Metamemory control is the regulation and control of memory processes carried out on the basis of metamemory monitoring, and the study time allocation during self-paced learning is a central component of metamemory control. According to Agenda-Based Regulation Model (ABR), individuals in the learning process will comprehensively analyze various factors such as task objectives, task constraints to construct the learning agenda, which is used to prioritize the study items and the amount of time needed to study. However, the main concern of the previous studies is the value presented as a reward outcome (reward obtained after successfully memory), leading to a lack of valid examination of whether reward expectation (prediction of reward outcome) affects the agenda construction and memory performance. Therefore, the aim of this study was to supplement the reward expectation into the ABR model by verifying whether a sufficiently high reward expectation can replace difficulty with exerting a dominant influence on JOLs and time allocation in an agenda construction.
Experiment 1 added a control group on the basis of Soderstrom and McCabe's (2011) to examine the effect of reward expectation and difficulty on JOLs and memory rates under a time limited learning condition by presenting the reward posteriorly. Experiment 2, which abolished the limited time learning to self-paced learning, was designed to examine the effect of reward expectation and difficulty on the study time allocation. To go a step further, Experiment 3 controlled reward expectation in the test by manipulating the value gradient, and was designed to examine the effect of the size of the gradient of reward expectation.
The current study found that: (1) under the limited time learning condition in Experiment 1, reward outcomes facilitated the memory performance and JOLs of both easy and hard word pairs, and reward expectation only improved the memory performance of easy word pairs without significant effects on JOLs. (2) in self-paced learning in Experiment 2, reward outcome only affected the JOLs rather than memory performance, but reward expectation promoted both JOLs and study time allocation thus improving the memory performance, what’s more, JOLs and study time allocation of hard word pairs in condition with reward expectation are higher than with no reward. (3) in self-paced learning in Experiment 3, the influence of difficulty on study time not significant any more, reward expectation beyond difficulty becomes the main factor affecting the study time allocation.
The above results proved that reward expectation is a contributing factor in ABR model. Individuals synthesize reward expectation, reward outcome and difficulty while constructing a learning agenda, and reward expectation overrides difficulty as the dominant factor in agenda construction when it is sufficiently large. However, the effects of reward expectation and reward outcome on memory performance, study time allocation, and JOLs were modulated by the learning conditions.
reward expectation, judgments of learning, study time allocation, metamemory, memory
2021-05-25
* 吉林省自然科学基金面上项目(20230101149JC)和国家自然科学基金面上项目(32271095)资助。
姜英杰, E-mail: jiangyj993@nenu.edu.cn
B842
