基于刀片服务器的软件化雷达信号处理方法
2023-04-07陈颖哲
杨 刚 陈颖哲 王 岩
(西安电子工程研究所 西安 710100)
0 引言
传统的雷达往往是针对特定应用场景设计,采用专用的硬件平台和软件架构,开发周期长,成本高,软硬件耦合性强,维护和升级既困难又昂贵[1]。随着雷达探测技术、电子对抗技术的发展,现代战场的电磁环境越来越复杂,目标探测的难度越来越大。为适应复杂的电磁环境,阵列雷达的通道数越来越多,信号带宽越来越大,以及先进的抗干扰算法和目标识别算法的引入,都增加了信号处理的复杂度。而且现在的雷达都具备多种探测任务的需求,集多种功能于一体,要求雷达可以灵活配置资源,扩展功能。
传统的雷达大多采用“FPGA+DSP”处理架构。FPGA集成了大量可编程的数字逻辑构件和RAM块,具有强大的定点运算能力和输入输出带宽[2],一般用于完成雷达信号处理中的AD采样,数字下变频,数字波束形成,脉冲压缩等功能。DSP浮点运算能力强,能够满足算法和逻辑比较复杂的场景,当前雷达信号处理系统中应用最广的DSP是TI的TMS320C6678,其浮点处理能力可以达到128GFLOPS(1GHz主频时),一般完成雷达信号处理中的动目标检测,横虚警检测,点迹凝聚,测角,杂波图等功能。“FPGA+DSP”架构在过去许多年里一直在雷达信号处理领域占据着主流位置,然而,该架构固有的特性,导致程序的可重用性低,硬件调试困难,开发周期长,难以满足当前瞬息万变的现代化信息战的要求。
针对传统雷达的不足,软件化雷达[3-4]的概念被提出,不同于传统雷达的“以硬件技术为中心,面向专用功能”特点,软件化雷达是“以软件技术为中心,面向实际需求”的开发模式。软件化雷达通过层次化的开放式体系架构,可以实现硬件资源的灵活扩展。通过中间件技术,可以将应用程序与硬件资源完全解耦,从而实现可移植、可重构的软件化雷达系统[5]。
1 硬件平台选择
FPGA虽然处理能力强大,但是开发调试周期长,软件和硬件耦合性强,可移植性差,所以较少应用于软件化雷达检测信号处理中。
单片DSP处理能力较弱,所以一般在一块板卡内同时包含2片、4片、8片TMS320C6678,每片C6678包含8个C66x核。为了充分发挥DSP的性能,大多应用中需要手动划分每片DSP,甚至每个C66x核的功能。所以DSP程序开发和调试同样比较复杂,不太适用于软件化雷达信号处理。
受功耗墙的限制,单核CPU无法继续通过提高主频来提升计算性能,CPU也转为了利用更多的核心来提升计算性能[4]。CPU芯片相对于DSP的主频更高,内存更大,浮点运算能力更强,而且运行的Linux操作系统比DSP上运行的轻量级操作系统性能更强,所以广泛应用于软件化雷达信号处理中。
本文方法实践中,计算刀片使用的处理器是志强D-2183IT,主频2.2GHz,最大支持16核/32线程,三级缓存为22MB,采用AVX2.0指令集,板载支持4通道64GB、2400MHz Register DDR4 ECC内存,可检测多位内存错误,查找和纠正单位错误,以保证系统持续正常运行,单精度浮点处理能力为1.1TFLOPS。
MKL是英特尔设计的一个函数库,涵盖了图像处理、自动控制、科学计算、统计数学和信号处理等领域的基本函数,比如快速傅里叶变换,矩阵操作等。MKL内的函数进行了高度的优化,而且是线程安全的,很适合雷达信号处理应用。利用VISPL标准[7]和MKL可以实现高效的算法中间件。
通信中间件采用“发布-订阅”模型,遵循DDS(Data Distribution Service)接口协议,提供了统一的接口进行数据和消息的传递,支持TCP、UDP和共享内存等传输协议。
目前CPU支持的并行编程模型包括Pthread、 OpenMP、 MPI和OpenCL等[6]。Pthread是线程的POSIX标准,定义了创建和操作线程的一整套API,能够在多种操作系统上运行,具有很好的可移植性,且所有线程都可以访问全局的共享内存,可以部分的减少线程之间数据通信的代价,当然多线程之间访问共享内存时需要考虑线程安全问题。本文采用Pthread来设计雷达信号处理程序。
2 信号处理算法
雷达信号处理最显著的特点是各功能模块的流水性,前后模块间数据的迭代性和相关性较弱[8],所以不失一般性,这里只讨论动目标检测和横虚警处理。
2.1 动目标检测(MTD, Moving Target Detection)
在实际工作中,雷达不仅会收到目标回波信号,也可能收到地物、云雨、海浪、以及人为释放的箔条等产生的杂波信号。一般来说,雷达接收到的杂波功率比实际运动目标信号的功率高很多,这对运动目标的检测产生了严重的影响。因此,在横虚警检测之前,必须对杂波进行抑制,尽可能降低杂波对检测的影响。
MTD是一种利用多普勒滤波器组来抑制各种杂波,以提高雷达在杂波背景下检测运动目标能力的技术[9]。MTD多普勒滤波器组的实现方法主要有FFT滤波器组法和有限脉冲响应(FIR)滤波器组法。FFT方法的优点是计算效率高,但是对杂波抑制能力较弱。FIR方法计算量大,但是在零频附近抑制杂波更加灵活,其频率响应可以在零频附近产生满足要求带宽的零陷[10]。16点FIR和FFT多普勒滤波器组如图1所示。

图1 MTD多普勒滤波器组
由于MKL中矩阵乘法效率很高,所以在CPU上实现MTD时一般采用FIR滤波器组。
2.2 横虚警处理(CFAR, Constant False Alarm Rate)
在实际工作中,干扰电平通常是变化的,横虚警检测的目的就是在实际干扰环境下保持信号检测时的虚警率恒定。常用的方法有单元平均CFAR (CA CFAR),平均选大横虚警(GO CFAR),平均选小横虚警 (SO CFAR),审核式横虚警,有序统计横虚警(OS CFAR)等。这些横虚警算法的主要区别在于多目标环境和杂波边缘的表现不同[11]。
3 软件架构设计
整个处理流程采用流水线的方式实现并行计算,除输入输出模块外,各模块接收上一级模块输出的参数和数据,完成计算后,将参数和数据发给下一级模块。这里模块之间传输的参数和数据组合,是通过使用传址的方式进行传递,以减少数据传输的时间。输入模块接收外部模块的输入,输出模块将最终处理结果上报给外部模块。
志强D-2183IT共有16个核,为了各模块处理时间的稳定,对各模块分配了固定的核进行处理,首先对这些核进行隔离,然后将各处理模块线程绑定到对应核上。软件化雷达模块示例见图2所示。
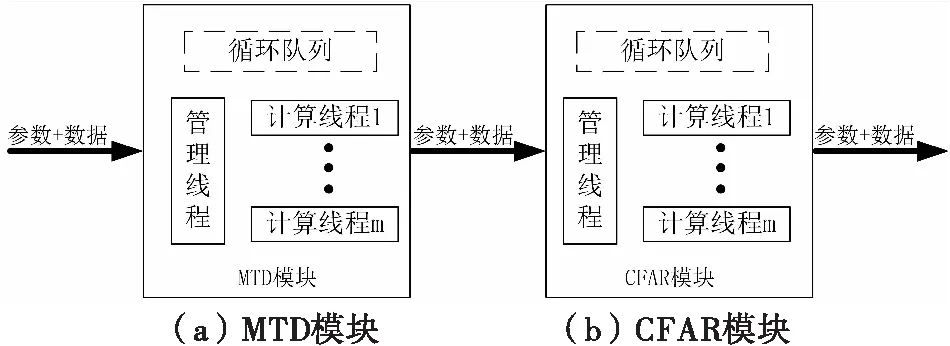
图2 软件化雷达模块示例
每个模块内有一个循环队列,用于存储参数+数据组合的地址,队列越大对模块处理时间抖动的容忍度越大,但队列太大对内存的需求越大,需要根据模块实际的处理时间抖动进行合理设置。
模块内的线程分为两种,管理线程和计算线程。
每个模块的管理线程只有一个,用于判断循环队列的状态,管理计算线程。当计算线程空闲时,管理线程判断循环队列是否为空,如果不为空,就取出最先收到的“参数+数据”组合,根据工作参数,划分好每个计算线程的计算任务,给计算线程发送信号量,启动计算线程开始计算,然后等待计算线程计算完成后发送的信号量。最后将该模块生成的“参数+数据”组合发给下一个模块。管理线程处理流程如图3(a)所示。
每个模块有多个计算线程,计算线程用于完成管理线程分配的计算任务。计算线程空闲时,等待管理线程发送的信号量,收到信号量后开始执行计算任务,计算完成后,给管理线程发送标志着计算完成的信号量,然后继续等待管理线程发送的信号量。管理线程主要是判断循环队列和计算线程的状态,以及完成任务分配,计算量不大,所以无需单独划分一个核,可以和计算线程绑定到同一个核,计算线程数量的选取需根据模块的计算量,以及系统可划分给该模块的核数确定。计算线程处理流程如图3(b)所示。
举例来说,假设当前MTD模块和CFAR模块需要处理的是一个波束,16个多普勒通道,1024个距离单元,MTD模块和CFAR模块分别分配3个核,分别有3个计算线程。

图3 管理线程和计算线程处理流程
MTD模块中管理线程检测到计算线程空闲,且循环队列中有未处理的“参数+数据”时,给三个计算线程分配计算任务,其中:计算线程1完成距离单元1~342的MTD处理;计算线程2完成距离单元343~683的MTD处理;计算线程3完成距离单元684~1024的MTD处理。
同理,CFAR模块中管理线程检测到计算线程空闲,且循环队列中有未处理的“参数+数据”时,给三个计算线程分配计算任务,其中:计算线程1完成多普勒通道1~6的CFAR处理;计算线程2完成多普勒通道7~11的CFAR处理;计算线程3完成多普勒通道12~16的CFAR处理。
4 结束语
雷达信号处理系统计算量大,实时性要求高,传统雷达信号处理系统软硬件耦合性强,不利于升级和扩展,导致研发周期长,成本高。本文介绍了一种基于CPU刀片服务器的软件化雷达信号处理实现方法,使用循环队列实现了对数据和参数的存储和传递,应用管理线程自动划分每个计算线程的计算任务,并管理计算线程的执行状态。通过MTD模块和CFAR模块具体介绍了循环队列,管理线程和计算线程的使用方法。本文介绍的实现方法,可以满足常规软件化雷达信号处理应用场景。
