基于卷积神经网络的双极化气象雷达冰雹检测方法
2023-04-07桑晨禹郭生权
李 海 桑晨禹 郭生权 田 众
(中国民航大学天津市智能信号与图像处理重点实验室 天津 300300)
0 引言
冰雹灾害性天气虽然出现的范围小、时间短,但是具有极强的破坏力,且常常伴随强降雨、狂风等天气过程,严重阻碍农业、电力通讯等方面的发展。精准的冰雹检测对于灾害性冰雹天气预报预警以及人工作业防雹指挥具有重要意义。冰雹产生于强对流天气,可通过雷达探测强对流系统而进行冰雹的识别[1]。与常规多普勒天气雷达相比,双极化气象雷达能够发射水平和垂直方向的电磁波,不仅能得到反射率因子、谱宽和速度,还能反演得到反映水凝物降水粒子形状、尺寸、密度等物理特性的多种极化参数[2-3],在降水估计、水凝物识别和灾害监测等方面具有明显优势,是冰雹检测领域的研究热点。
1986年双极化气象雷达极化参数首次被应用于冰雹探测领域,Aydin等提出结合反射率因子和差分反射率因子的冰雹识别算法[4]。这种基于统计结果的判决虽然方法简单,但是该算法的前提条件是假设极化参数是互斥的。目前,双极化气象雷达冰雹检测的研究主要有两大类方法,分别为模糊逻辑判别技术和机器学习类算法。Straka应用模糊逻辑成功实现降水粒子分类[5],Ryzhkov验证了该算法能够有效识别冰雹[6]。后续相关学者的研究主要集中于不同波段雷达验证应用[7-8]和隶属度函数参数的优化改进[9-11]。模糊逻辑算法能够有效解决数据交叉、不精确等问题。但是该算法隶属度函数参数的确定和相关权重的选择过度依赖专家经验值,主观性较大。现已应用到天气检测领域的机器学习相关算法主要有支持向量机[12]、贝叶斯[13]、聚类[14]和神经网络[15]等。支持向量机算法在同等样本数量下计算量大、耗时长。贝叶斯神经网络应用回归和分类方案进行冰雹检测,但是易出现过拟合现象。聚类算法减少了获取标签的成本,不易受到数据污染,但是该方法计算成本高且聚类误差对识别结果影响较大。王金虎等将神经网络算法与水凝物分类相结合,但对冰雹等大颗粒固体粒子识别结果较差[15]。神经网络能够依据数据搭建输入输出关系、自适应调节模型参数,然而机器学习性能的上限取决于数据和数据特征[16]。人为选定的特征往往在不同数据、不同模型下不能通用。
本文提出了一种基于卷积神经网络(Convolutional Neural Network,CNN)的冰雹检测方法,该方法通过前向传播搭建模型设置网络结构,再通过后向传播训练网络调节模型参数,最终得到冰雹检测模型。该方法能够提取极化参数数据的显著特征,同时无需进行模型参数假设就可以有效进行冰雹检测。
1 基于卷积神经网络的冰雹检测模型
1.1 数据预处理
本文选取双极化气象雷达回波数据计算得到的四种极化参数作为冰雹检测的属性依据,具体为反射率因子Zh、差分反射率因子ZDR、互相关系数ρHV、以及差分相移率KDP。这些极化参数以数值的形式单独存放在每个雷达回波分辨单元内,而单个数值无法进行卷积计算。因此,在构建卷积神经网络模型之前需要对分辨单元内的极化参数进行扩充。目的是将极化参数数值转化成数据矩阵的形式。首先将每个分辨单元沿距离向和方位向分割成n×n个小分辨单元,每个小分辨单元为一个插值点,然后采用最近邻插值方法[17],利用相邻分辨单元极化信息的值来推断出插值点的数值。n取值为大于3的正整数,取值越大越有利于特征提取但同时产生的冗余也越多。本文取n=5,图1为分辨单元内一个极化参数插值处理示意图。将本文选取的四个极化参量分别进行插值处理后,再通过堆叠操作得到四通道的数据矩阵。此数据矩阵与对应的标签信息相结合构成冰雹检测数据集。
1.2 模型搭建
双极化气象雷达的极化参数经过数据预处理后每个分辨单元数据格式为4×5×5,本文以此三维数组作为输入,构建一个输出为冰雹和其他(非冰雹降水粒子统称)的二分类网络。CNN是一种“特征提取器+分类器”的串联结构,其基础模型包括卷积层、池化层、全连接层三个部分。卷积和池化对极化参数的特征进行提取,全连接神经网络依据特征进行分类。参考CNN的基本架构,本文所提的冰雹检测模型由一个输入层、两个卷积层、两个池化层、三个全连接层和一个输出层组成。模型结构如图2所示,各层参数设置如表1所示。

图2 基于CNN的冰雹检测模型构建

表1 模型参数设置
卷积层通过卷积运算的方式对数据进行特征提取。初始化的卷积核以固定的步长在极化参数上滑动来遍历每个数据。每滑动一次,就要计算卷积核和极化参数重合区域的乘积并求和,再加上偏置。为了防止数据边缘信息丢失,在卷积层1中对极化数据使用全零填充以保证输入数据大小和输出数据大小一致。卷积核会在一次次的迭代中被更新,无限接近符合当前数据分布的特征向量集,最后利用训练好的卷积核提取每个雷达分辨单元的极化参数数据特征。以卷积层1中一个通道的输入为例,在全零填充后输入矩阵变为7×7,经卷积运算后,输出大小为5×5的特征矩阵,示意图如图3所示。

图3 极化参数卷积示意图
经卷积提取后的特征矩阵送入池化层。池化层的作用是对卷积之后的特征矩阵进行降维处理。该层考虑特征不变性,在空间范围内做维度约减,使模型得到更广泛的特征。
Xl=pool(Xl-1)
(1)
l表示层数取值为3和5,对应模型中的最大值池化层和均值池化层;Xl和Xl-1分别为池化层和卷积层的输出;pool(·)表示池化函数。在冰雹检测算法中采用最大池化和平均池化对极化数据的特征进行聚合统计,既关注重要的局部特征,又关注全局特征。池化过程通过设定池化窗口的大小和步长遍历特征矩阵,每滑动一次就计算池化窗口对应的特征矩阵相应区域内的最大值或均值。以图3的输出为例,两种池化标准的计算结果如图4所示。

图4 极化参数池化(最大、平均)过程示意图
全连接层选用3层神经网络,同时加入Relu激活函数和Dropout策略。最后使用Softmax函数作为输出层函数,得到预测结果,其数学定义为
(2)

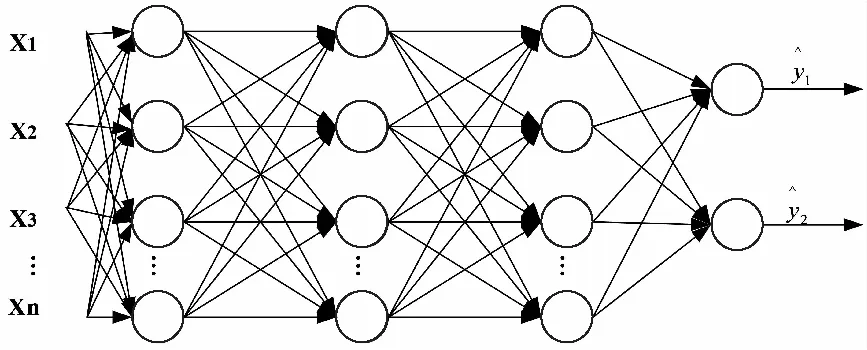
图5 原始全连接神经网络

图6 Dropout后网络结构
1.3 模型参数训练
模型训练任务的最终目标是让预测值和真实标签尽可能的接近。在形式上表现为通过调整模型参数最小化损失函数。而模型参数调整依据梯度下降算法。在后向传播过程中,通过导数链式法则计算损失函数J对各参数的梯度,并根据梯度和学习率更新网络中的权重和偏置。为了避免模型在训练过程中陷入最优解以及减小学习率设置对参数收敛的影响,引入了指数衰减学习率和滑动平均。
下面以权重的更新过程为例进行详细阐述,模型权重参数的更新公式为

(3)

J(w,b)=Jdata(w,b)+JR(w,b)
(4)

(5)
正则化项是在最小化损失函数J时增加一个约束,能够降低原始损失函数在离线训练时的误差以及减小衡量指标下参数w的规模,有效避免冰雹检测模型的过拟合。
JR(w,b)=αΩ(w)
(6)
其中α表示正则化的强度;Ω(w)表示正则化函数,不同的正则化方式对冰雹检测模型的影响也不同,L2正则化通过加入αw来约束参数的变化,这主要是对参数线性的放缩;L1方案正则化对应梯度添加了和符号函数sign(wi)同号的一个常数,能够通过较大的α来稀疏冰雹检测模型参数。因此,在冰雹检测模型离线训练过程中使用L1范数正则化。即公式(4)对应损失函数公式(7),其中‖w‖1作为权重绝对值之和为
(7)
确定损失函数后,对于不同层的梯度计算步骤如下:
1)首先定义节点灵敏度误差δ,表示损失函数J对第l层神经元输入的变化率为式(8)所示。
(8)
当第l层为卷积层时:
δl=up(δl+1)wl+1*f′(ul)
(9)
其中up(·)表示上采样。
当第l层为池化层时:
δl=δl+1rot180(wl+1)*f′(ul)
(10)
其中,rot180(·)表示矩阵顺时针旋转180°。
当第l层为全连接层时:
δl=(wl)Tδl+1f′(ul)
(11)
2)依据得到的各层灵敏度误差计算权重和偏置的梯度。
∇w=δlxl-1
∇b=δl
(12)
模型参数更新公式(3)中η表示学习率。学习率过大过小都会影响参数收敛。为了使模型中参数学习率能够自适应调整,加入了指数衰减学习率。η的计算公式为
η=η0·βK
(13)
其中η0表示初始学习率;β表示学习率的衰减率;K表示当前训练次数与学习率更新频率的比值。在冰雹检测模型中,学习率更新频率定义为训练样本总数和批量样本数的比值。在参数更新的过程中加入滑动平均用于记录一段时间内模型中的权重和偏置,防止模型过拟合。在冰雹检测模型离线训练的过程中,滑动平均值能够体现参数的变化。可以保存每一次训练后的模型,实现断点训练,在测试时只需要加载最新的模型即可,确保模型在训练时更加灵活。
本文选取美国国家海洋和大气管理局(National Atmospheric Administration,NOAA)数据库中提供的KTLX双极化气象雷达偏振参量信息进行实验。在2019年4月至2020年3月期间获取的回波数据中选取15万个作为训练样本。该样本数据包含多个典型的天气情况并涉及不同的季节,具有较强的代表性。采用Python语言和Tensorflow架构进行编程,实现上述模型搭建和参数调整。在训练过程中,采用初始学习率为0.001,学习率衰减率为0.99,滑动平均衰减率为0.99,Droupout调整策略保留率为0.5。在输入样本的过程中引入了小批次样本降低复杂度。随着训练次数的增加损失误差不断下降,当损失误差达到收敛状态时,保存模型及权重参数。模型训练过程中准确率和损失误差的变化曲线如图7所示。

图7 准确率和损失误差变化曲线
2 算法流程与步骤
基于卷积神经网络的双极化气象雷达冰雹检测方法流程如图8所示。

图8 基于卷积神经网络的双极化气象雷达冰雹检测方法流程图
基于卷积神经网络的双极化气象雷达冰雹检测方法步骤如下所示。
1)步骤1:对获取的双极化气象雷达极化数据进行处理,使其符合卷积神经网络的输入同时提高数据分辨率;
2)步骤2:搭建卷积神经网络结构,设定模型中的超参数;
3)步骤3:对模型进行迭代训练,更新模型参数;
4)步骤4:使用冰雹检测模型来进行测试;
5)步骤5:输出模型分类结果。
3 实验及结果分析
本文分别使用仿真数据和实测数据,对训练好的卷积神经网络冰雹检测模型进行验证。下面分别展示两份数据的实验结果。
3.1 仿真数据
通过仿真得到的雷达回波数据反演计算出的极化参数称为仿真数据。仿真过程用到的雷达参数如表2所示。

表2 极化雷达仿真参数


图9 KTLX雷达强降雨过程可视化结果(2020/4/22 05:06)

图10 仿真数据可视化结果(2020/4/22 05:06)
利用卷积神经网络对仿真数据进行检测,冰雹检测的结果如图11所示。结合图10(a)可以看出反射率较大的地方分为了冰雹,与实际情况相符合。

图11 仿真数据冰雹检测结果(卷积神经模型)
对于二分类问题,实际标签与预测标签两个维度交织构成的混淆矩阵包含四种情况,分别为:实际冰雹预测冰雹;实际冰雹预测其他;实际其他预测其他;实际其他预测冰雹。通过对混淆矩阵的分析我们可以得到精确率、召回率和F1指标。用精确率表示冰雹检测结果的好坏,用召回率表示冰雹检测结果的完整性,F1指标表示两者的综合。使用卷积神经网络得到冰雹检测结果的混淆矩阵(仿真数据)如表3所示,从表3中可以计算得到冰雹仿真数据的精确率为70%,召回率为80%,F1为75%。

表3 卷积神经网络检测结果混淆矩阵(仿真数据)
3.2 实测数据
本文实测数据选取NOAA数据库中的KTLX雷达在2019年6月19日14时55分的极化参数来进行测试,该数据的可视化结果如图12所示。
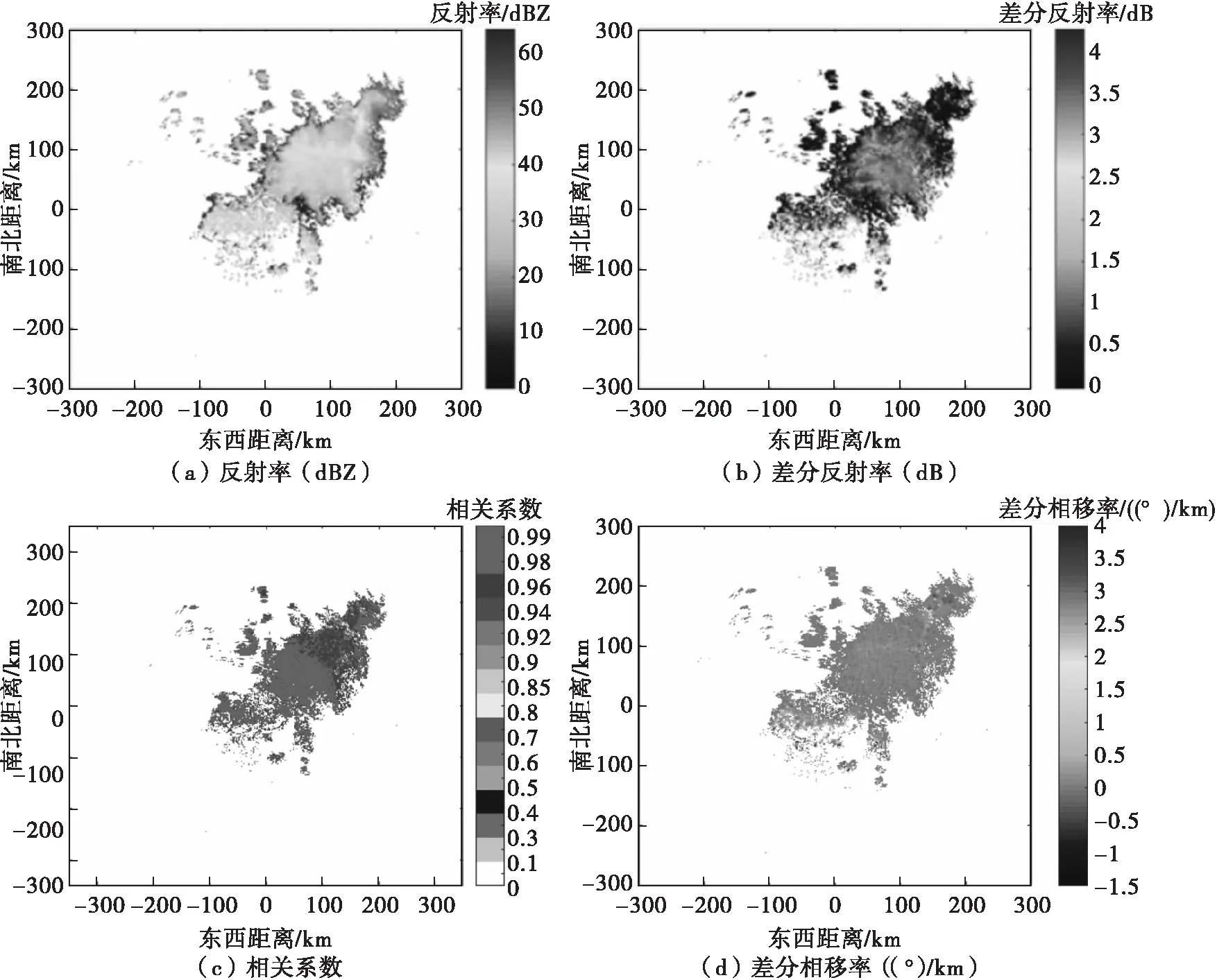
图12 KTLX雷达获取的极化参数(2019/6/19 14:55)
为了进一步说明本文所提方法的有效性,分别利用全连接神经网络和卷积神经网络模型进行测试,全连接神经网络的结构以及初始设置和卷积神经网络中的全连接神经网络一样。如图13所示为使用全连接神经网络和卷积神经网络的冰雹检测结果以及NOAA给出的冰雹检测结果。

图13 冰雹检测结果
与全连接神经网络冰雹检测结果相比,卷积神经网络冰雹检测结果更加接近于NOAA提供的真实分类结果。通过计算两种方法的混淆矩阵对检测结果进一步量化,如表4和表5所示为全连接神经网络和卷积神经网络检测结果计算得到的混淆矩阵。

表4 冰雹检测结果混淆矩阵(全连接神经网络)

表5 冰雹检测结果混淆矩阵(卷积神经网络)
依据混淆矩阵计算得出全连接神经网络冰雹检测模型的精确率为68%,召回率为52%,F1为60%。卷积神经网络冰雹检测模型的精确率为73.59%,召回率为83%,F1为78%。从结果来看,基于卷积神经网络的冰雹检测模型的准确率和完整性均高于全连接神经网络,有效降低了冰雹识别的虚警概率。
4 结束语
本文提出了一种基于卷积神经网络的双极化气象雷达冰雹检测算法。通过对获取的极化参数进行处理,得到符合卷积神经网络输入的数据,然后搭建卷积神经网络模型,接着在模型训练的过程中加入指数衰减学习率、正则化等措施来优化网络,从而实现冰雹检测。通过对比卷积神经网络和全连接神经网络的测试结果,得出了经过特征提取和权值共享后卷积神经网络的检测能力优于全连接神经网络的结论,表明了卷积神经网络能够改善冰雹检测模型的性能。通过对仿真数据和实测数据进行实验表明,该方法能够实现较为准确的冰雹检测,且具有很好的研究潜质和模型泛化性。为防止数据失真,数据插值规模较小,神经网络深度较浅,后续可以通过研究高维数据处理与深度神经网络相结合的方式,提高冰雹检测准确率。
