基于XGBoost模型的营养成分分析高血压预测方案
2023-04-07蒋淮李时杰王峻峰
蒋淮䶮,谭 浪,李时杰,刘 昱,王峻峰
(1.天津大学 微电子学院,天津 300072; 2.北京智芯微电子科技有限公司,北京 102200; 3.云南省第一人民医院,昆明 650031)
高血压是一种严重威胁人类健康的慢性病,根据美国高血压控制委员会制定的标准[1],反复测量的收缩压超过14 mmHg或舒张压超过90 mmHg可认定为高血压。英国权威杂志《柳叶刀》(The Lancet)2017年的研究显示[2],1975年全球高血压患病人数为6×109,到2015为止增加至11×109,患病人数几乎翻了一倍;在世界范围内每年有750×104人死于高血压或由其引发的并发症。 中国“十二五”高血压抽样调查结果显示,2017年中国有2.45×109的成年人为高血压患者,占成年人比例的23.2%;有1.25×109人不知道自己是否患有高血压,此人数超过患者人数的一半;此外1.5×109的患者未使用药物进行治疗,只有约3 700×104的高血压患者得到了控制;而处在高血压的边缘人数也达到了4.35×109[3]。目前高血压在中国呈现低知晓率、低治疗率、低控制率的形势。
影响血压状况的因素有很多,如性别、年龄、吸烟、肥胖以及不健康的饮食等,有诸多研究在这方面进行探索[4-6],结果显示不良的饮食是高血压形成与发展的重要影响因素。日常生活中饮食与人密切相关,合理的饮食可以促进身心健康和预防疾病,而饮食可以理解为营养成分摄入,因此不同种类和数量的营养成分摄入会影响疾病的发生以及人们的健康状况。研究也证实了饮食营养与血压值存在一定关系,如高血压患者的血压与膳食中钠摄入成正相关[7];高血压患者血浆中的总包和脂肪酸含量较正常人更高,脂肪与血压成正相关[8];服用维生素A、C、E能降低高血压患者的血压尤其是收缩压[9]。
高血压早期因无明显症状而不易被发现,很难引起重视,若能及早发现问题,通过合理饮食及相关医疗措施,可有效控制并避免后期引起并发症。饮食在高血压的发生及发展中都起到很大作用,所以建立一种通过分析营养成分来预测高血压的模型十分必要。近年来,有学者在高血压的风险因素分析以及预测方面进行了研究,但通过饮食营养来预测高血压的研究较少,方法体系还不成熟。如Dong 等[10]通过改进的反向传播神经网络算法研究了高血压的影响因素,包括遗传因素,生活方式因素,肥胖和合理饮食。Sinkuo chai等[11]基于数据挖掘技术建立了高血压并发症的预测模型。张伟等[12]提出了一种改进的C4.5决策树算法,通过使用住院患者的医疗相关数据来预测高血压,最终获得了81.58%的准确率。Nimmala等[13]通过基于AAA的J48分类器使用年龄、愤怒和焦虑程度来预测高血压,获得了84.30%的准确率。以上研究成果对高血压的发生机制进行了深入探讨,但研究数据主要为影响高血压的一般特征,且使用的分析预测模型较为单一,对比性不强。
因此,以营养成分为主要特征,以年龄、身形体态等一般特征为辅助特征,结合机器学习、统计学习等相关技术提出了一个高血压预测的五阶段方案,并搭建了基于XGBoost的分析营养成分预测高血压模型,结果显示所提出的预测模型具有较高准确率、精确率、召回率与F1分数。此外还针对高血压预测中不同营养特征的影响因子完成风险分析,分析结果可以帮助医生以及患者提早发现问题,采取措施或进行治疗,降低医疗成本并提高患者生存率。
1 基本原理及方法
通过对问题进行分析和解构,笔者要实现高血压预测需要经过以下步骤:1)需要将人的饮食数据转换为所需要的营养成分数据,并筛选出有利于模型预测的一般特征;2)处理得到的营养成分和一般特征数据会伴随着缺失等问题,需要对数据进行清理;3)分类模型可分为二元分类和多元分类模型,通过分析人的每天营养成分摄入以及相关特征来预测高血压为二元分类任务,需要搭建相应的二元分类模型来实现预测。据研究提出了一个5阶段方案,具体流程如图1所示。

图1 预测高血压五阶段方案流程图Fig. 1 Flow chart of five stage scheme for predicting hypertension
1.1 实验数据来源
本次实验的数据来自于中国营养与健康调查(CHNS, china health and nutrition survey),该项目由中美合作,从20世纪80年代起对中国多个地区居民的饮食结构和营养状况等变化进行追踪研究,至今共进行了10次调查,其所有研究调查数据面向公众开放,详细信息请参见[14]。CHNS调查时间跨度较大,因此实验只选择从2006年开始的最近3次调查的数据进行分析。CHNS数据并未直接提供研究所需的营养成分数据,而是记录了调查期间每个人食用的食物名称及重量,以及相应的身高、体重、臀围、头围等基本信息和每个人的血压值。因此对调查数据做出以下处理:
CHNS所提供的食物数据包含食物消耗量和相应的食物代码,中国疾病预防控制中心营养与食品安全研究所发布的中国食物成分表包含了每种食物的食物代码,以及每100g食物所含有的26种营养成分的数量[15],研究使用MySQL搭建数据库建立2个字段之间的关系,将CHNS食物数据转换为对应的26种营养成分数据。
CHNS同时提供了被调查者的血压值检测数据,据统计约有60%的人进行了连续3次测量,30%进行了2次测量,10%左右的人只有一次测量结果或者没有记录数据。高血压诊断需要进行多次反复测量,因此只选择了包含3次的测量结果数据。之后对高压与低压分别取平均值,若高压≥140 mmHg或者低压≥90 mmHg,则视为高血压,标记为01作为正样本;否则为非高血压,标记为10作为负样本。
1.2 特征选择
通过前面处理办法,将饮食数据转换为所需的营养成分数据,并首先选择了这26种营养数据作为预测模型的主要特征。考虑到不同年龄段人们的饮食习惯和结构不同,如年轻人由于工作和其他原因更倾向于食用高碳水化合物和高能量的食物,总体摄入量相对较高。老年人则倾向于食用低碳水化合物、高纤维的食物。此外,不同身形的人的饮食摄入也有差异[16]。因此,希望将年龄和身形体态作为预测模型的辅助特征,从而使预测结果更加合理准确。CHNS数据库中给出了每个调查者的身高和体重,通过身高和体重可以计算出每个人的身体质量指数(BMI, body mass index)来表示个人的身形。
为了更好地验证上述想法,需要使用特征选择方法从全部特征中剔除不相关或者冗余的特征来减少特征个数,从而提高模型精确度及减少运行时间,使构建出来的模型更好。本实验为二分类问题,故采用单变量特征选择方法验证年龄与BMI值是否可作为本分类实验的特征。单变量特征选择方法有4种,选择了适合二元分类任务的SelectKBest方法,SelectKBest中的score_func参数选择f_classif,它会计算单变量与训练目标之间的方差分析F值(Anova F-value),F值越大,说明特征影响分类结果越大。选择了CHNS数据库中提供的基本信息,包括参与者的性别、出生年份、上臂围、三头肌皮褶、臀围、腰围以及要验证的年龄和BMI作为变量特征进行验证。最终将输出结果由高到低排序,如表2所示。
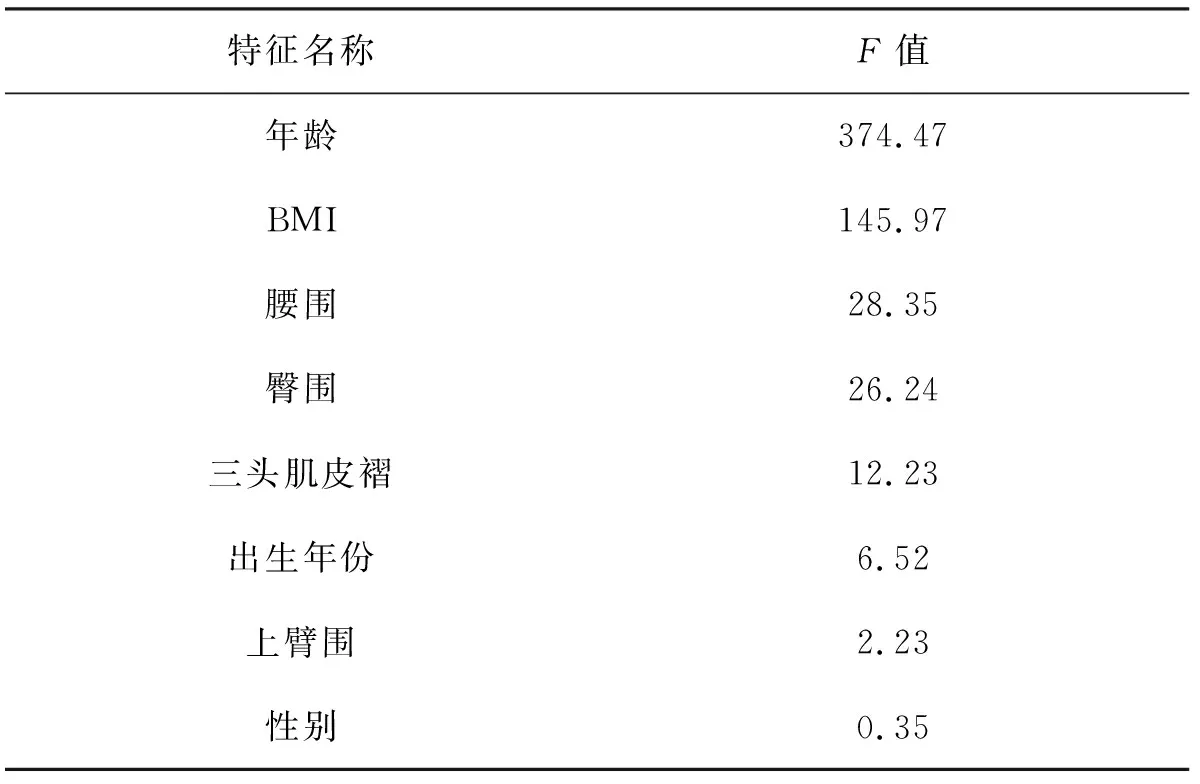
表2 SelectKBest特征选择结果
从表中可知,年龄与BMI的F值分别为374.47、145.97,明显高于其他特征的F值,说明年龄与BMI可以作为预测高血压分类模型的特征,而性别、臀围等基本信息的F值过低,则直接剔除。最终,预测高血压分类模型选择26种营养成分数据以及年龄与BMI共计28维,作为输入特征。
1.3 数据清理与标准化
在机器学习领域中获得的原始数据通常伴有缺失值,即数据集中某些特征属性的值不完全。为了保证数据完整性,利于模型准确预测,需要判断缺失值的类型并完成填充。机器学习中常用的处理缺失值的方法有人工填写、特殊值填写、均值填充、中位数填充、多重插补等。由于营养数据特征是通过饮食记录转换而来,因此若饮食记录有缺失,数据本身的性质无法使用上述方法进行填充,所以这一部分缺失数据直接删除。年龄和BMI 2个特征本身缺失值比例小于5%,这一部分缺失值对整体模型预测影响不大,故使用中位数填充进行替换。
研究显示,18岁及以下未成年人的血压会随着年龄、身高的增长以及体重的增加在标准范围内升高[17],若非家族遗传,很少患有高血压,所以这一部分数据不具有代表性,为了更好地评估模型准确性,删除了18岁及以下未成年人的数据。通过整个数据清理过程,最终得到了包含28个特征的1 582个数据样本,包括826个患高血压的正样本与756个未患病的负样本,比例接近1∶ 1。
由于输入特征主要是每日营养成分摄入量,种类繁多且单位不同,同时某些营养特征的总体方差过大,可能会导致一些机器学习算法的主目标函数阻止参数估计其学习其他特征,造成很难收敛或不能收敛的状况。数据标准化是将数据按比例缩放,使之落入一个小的特定区间,可以将其转化为无量纲的纯数值来去除数据的单位限制,便于不同单位或量级的指标能够进行比较和加权。因此对数据集进行了标准化处理,使每个特征值的平均值为0,方差为1,相当于转化成为标准正态分布即高斯分布。标准化的公式如下
其中:xi指的是数据集中特定维度的所有数据;min(x)是数据集中同一维度的最小数据;max(x)是数据集中同一维度的最大数据;x′表示标准化数据的值。
1.4 模型搭建
XGBoost(extreme gradient boosting)又称极端梯度提升,由Chen等于2014年开发和推出[18],并且在近年来的Kaggle比赛中取得非常突出的表现。XGBoost是基于梯度提升决策树(GBDT)的改进算法,通过boosting思想将个体学习器组合在一起,产生依赖关系,同时可以有效构建提升树且并行运行。XGBoost算法因其运算快速、高效准确、泛化能力强等优点广泛应用于分类与回归领域。其核心概念是通过添加树,拟合最后预测的残差来学习新功能,然后获得样本得分,通过将每棵树的分数相加,可以得出样本的最终预测分数。对于具有m个特征的n个标记样本,使用K个加法函数预测分数的公式如下
F={f(x)=wq(x)(q:Rm→T,w∈RT)},
(3)
其中:F是回归树的空间;f(x)是其中一个回归树;wq(x)表示每个T叶树的独立结构分数。XGBoost的目标函数被定义为

其中:l代表了模型的损失函数;Ω是正则化项;T表示叶节点的数量;w是叶节点的分数;γ与λ代表了防止过度拟合的控制系数。当生成第n棵树时,预测分数公式可以写成

为了加速优化,使用泰勒二阶展开式
通过添加样本的损失函数,重新组合样本,最后利用顶点公式求出最优的w以及目标函数公式L如下
Gi=∑i∈Ijgi,
(11)
Hi=∑i∈Ijhi。
(12)
XGBoost在寻找最佳分割点时结合了传统的贪心算法以及近似算法,根据百分位法列举几个可能成为分割点的候选项,然后根据式(9)、(10)计算出最佳分割点。XGBoost使用多种方法来避免过度拟合,例如引入正则化、行采样以及特征采样,同时还增加了对稀疏数据的处理。此外XGBoost还具有其他的优势,例如能进行并行处理,使速度有了很大提升;具有高度的灵活性,可自定义优化目标与评价标准;内置交叉验证,允许在每一轮boosting迭代中使用交叉验证。综合以上XGBoost在分类算法中的优势,选择了XGBoost作为通过分析营养成分预测高血压的模型。
通过分类算法搭建模型并最终实现高血压预测,需要通过定义算法函数、调用函数搭建网络模型、训练与验证模型、期间调整参数及最后测试与评估模型等步骤。
基于XGBoost的高血压预测模型的设计流程图如图2所示,具体流程如下:首先定义算法函数,调用XGBoost函数搭建网络模型;随后设定初始参数并输入训练集,进行模型训练,每训练一次调整一次权值,直到训练误差最小或达到要求的最高训练次数1 000次;训练后存储当前网络文件,输入验证集,对比评估指标来确定需要人工手动调整的参数是否最优,如此循环直到所有参数全部最优;随后进入测试阶段,对模型评估获得相应指标,完成通过分析营养成分预测高血压的分类实验。
互联网企业关于员工的培训主要包括新员工培训和优秀外出学习培训。虽然新员工入职后有相应地提升员工技能的培训环节,但后续的培训形式主要为员工定期参加外部培训公司的课程活动。企业虽有设置内部培训但并没有形成系统的员工培训体系,使得公司外部与内部培训未能很好结合。这从一定程度上来说,这既增加了企业的培训运营成本,又无法有效地达成企业所制定的发展目标。

图2 XGBoost建模流程图Fig. 2 XGBoost modeling flow chart
1.5 分类与评估
目前的研究中很少有通过分析营养成分来预测患高血压风险的模型,提出了通过分析营养成分来预测高血压的5阶段方案,搭建了基于XGBoost的高血压预测模型,同时与多种常见机器学习分类算法进行对比来验证模型的有效性。算法包括随机森林(RFs, random forest)、支持向量机(SVM, support vector machine)以及人工神经网络(ANN, artificial neural network)。RFs主要利用的是集成学习中的bagging算法,将多棵树集成到一同分类,树与树之间关系为并行,互不影响[19]。SVM作为一种机器学习的有监督分类方法是建立在统计学习理论的VC维理论和结构风险最小原理的基础上,根据有限的样本信息在模型的复杂性和学习能力之间寻求最佳平衡[20],它在解决小样本、非线性以及高维模式识别中表现出诸多优势。ANN是一个局部最优解的分类和预测算法,由大量神经元相互连接而成, 每个神经元节点都是一些动态的权重参数,ANN的学习过程是对大量样本进行归纳学习,然后内部进行自适应,过程中各个神经元节点调整相应权重,使神经网络处于稳定的范围且权重收敛[21]。这些对比算法的建模过程从形式上与XGBoost有相同部分,不同点在于SVM中有4种核函数,本实验中的特征个数远小于样本个数,故选择了径向基核函数;RFs衡量分裂质量的性能函数选择为entropy,即为信息增益的熵;ANN需要确定隐藏层以及各个层神经元个数,由于输入特征为28个,经过实验最终选择28-56-56-2的神经元结构,其中包括1个输入层、1个输出层和2个隐藏层。
在完成分类模型构建之后,需要对模型的效果进行评估,在二分类问题中评价模型最简单也最常用的是准确率(Accuracy),但若数据集正负样本不均衡,准确率并不能很好地评估模型的有效性,因此引入精准率(Precision)、召回率(Recall)以及F1分数(F1_score)[22],具体公式如下

其中:TP为真正类,即实际是正类且预测也为正类的个数;FP为假正类,即实际是负类但预测为正类的个数;TN为真负类,即实际是负类且预测也为负类的个数;FN为假负类,即实际是正类但预测为负类的个数。
除了以上指标,还使用ROC(receiveroperatingcharacteristic)曲线,是反应特异性与灵敏度这2个连续变量的综合指标,它以平面曲线图的形式来全面且客观地对模型以及系统进行分析和评估[23]。ROC曲线以真正类率(TPR,truepositiverate)为y轴,以假正类率(FPR,falsepositiverate)为x轴,x、y两轴取值范围均为0~1。当FPR值保持不变时,TPR值越大,曲线越接近(0,1)点,表明模型越好越稳定。ROC曲线下面积即AUC(areaunderroccurve)值,用来直观地反应ROC曲线图的情况,AUC值越接近1则代表ROC曲线越接近(0,1)点,说明模型的分类性能越好。
以上为提出的高血压预测的五阶段方案,通过数据转换得到了所需要的营养成分数据;通过特征选择确定了以26种营养成分为主要特征,年龄与BMI为辅助特征的28维特征;通过数据清理与标准化去除了数据冗余,提高了模型运算速度和准确度;在模型搭建中选择了运算速度快、准确率高、泛化能力强的XGBoost模型;最终通过与其他分类模型一同比较评估来验证提出的方法与模型的有效性。
2 实验结果及分析
2.1 XGBoost与其他分类算法结果对比
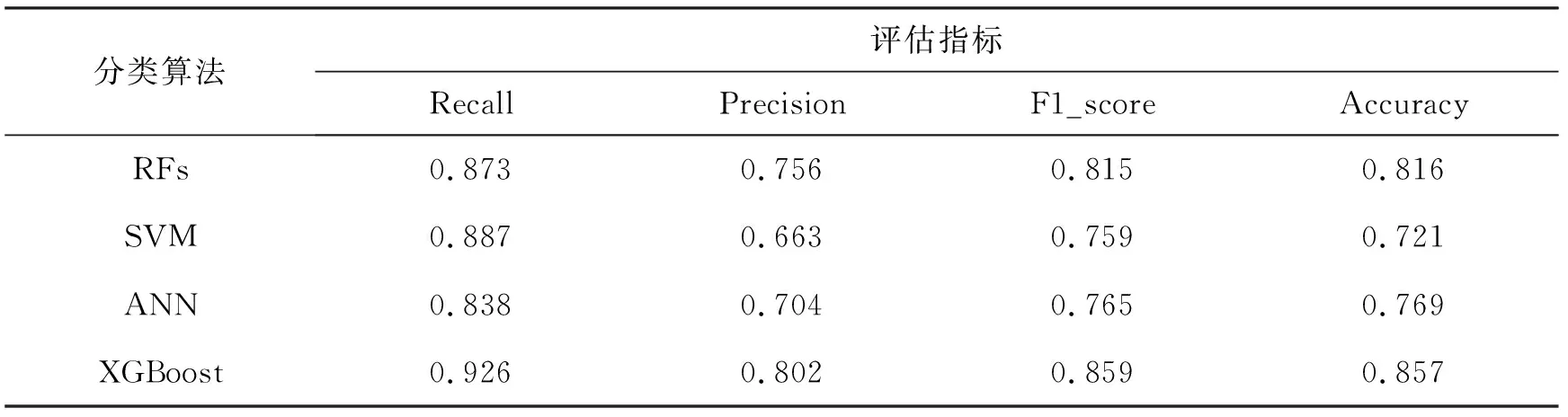
表3 4种分类算法结果对比
从表中可以看出,包括XGBoost在内的4种分类算法的测试准确率与F1分数均超过0.72,其中准确率最低为0.721,最高为0.857;F1分数最低为0.759,最高为0.859。由SVM和ANN这2个分类算法得到的准确率与F1分数均低于0.80,说明这2种算法解决本分类问题的能力较差;RFs与XGBoost的准确率与F1分数均超过0.80,性能较好。其中与RFs相比,XGBoost获得了0.857的最高的准确率与0.859的最高的F1分数,同时召回率为0.926,精确率为0.804也为最高。因此,综合以上指标可以得出,XGBoost为通过分析营养成分预测高血压的最佳模型。
由于实验测试所用试数据集正负样本并不是完全的1∶ 1,为了更好地比较这4个分类算法的性能,画出了测试过程中4个分类算法的ROC曲线图,并将其组合到了一张图中,具体如图3所示。其中不同的颜色代表不同分类算法的ROC曲线,蓝色点划线为XGBoost,绿色点划线为RFs,紫色点划线为SVM,红色点划线为ANN。从图中可以看出XGBoost的ROC曲线更接近(0,1)点,分类效果最好,而ANN的ROC曲线离(0,1)点最远,分类效果最差。此外还可以通过对比ROC曲线下面积即AUC值,来更加直观地看出算法分类的效果,具体如表4所示。
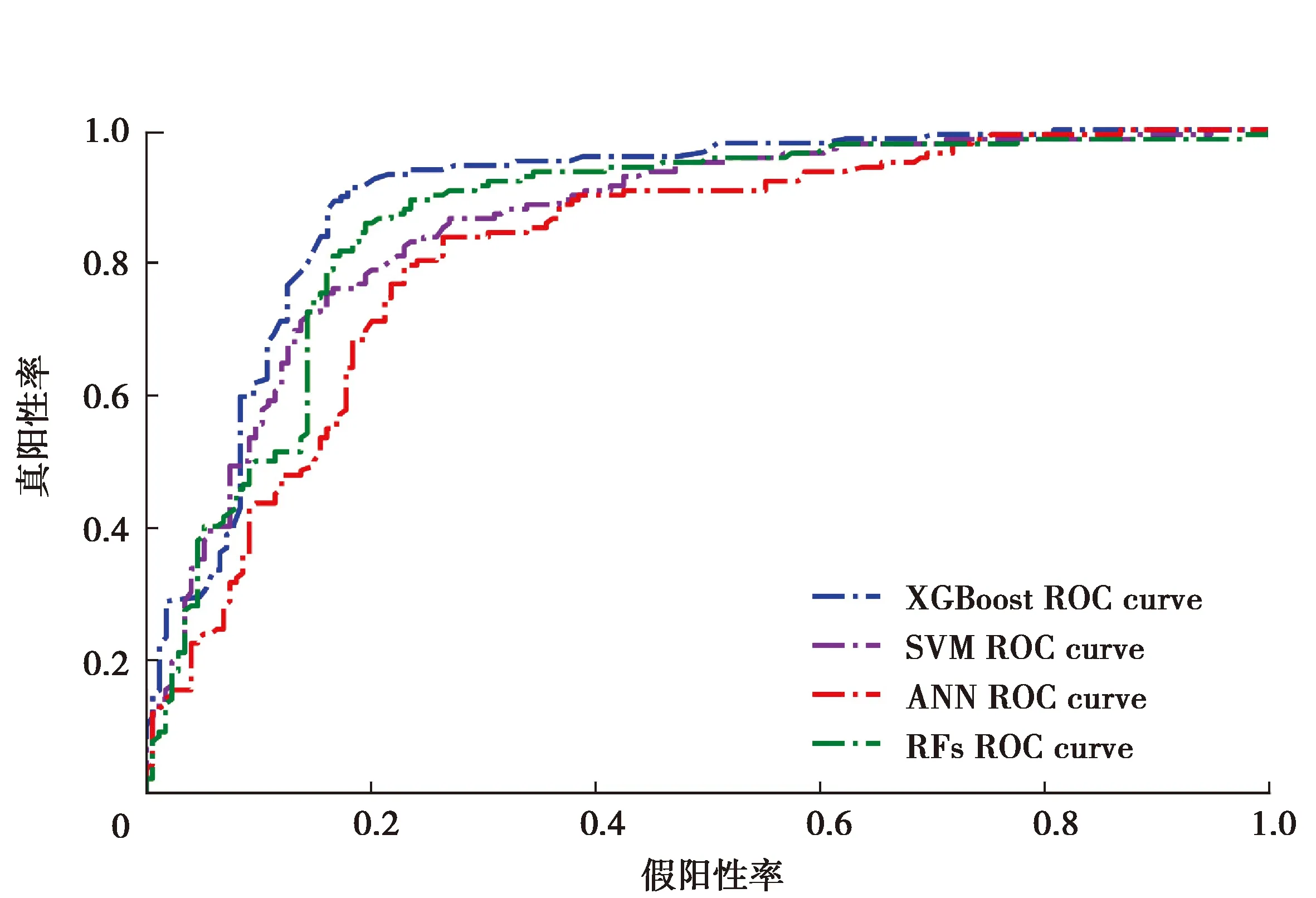
图3 4种分类算法的ROC曲线图Fig. 3 ROC curve of four classification algorithms

表4 4种分类算法AUC值
从表中得知XGBoost的AUC值最高且超过了0.9,而其他各个算法的AUC值均未超过0.9。通过观察这4种分类算法的ROC曲线与AUC值得出的结论与表3中评估指标得出的结论相同。搭建的基于XGBoost的通过分析营养成分预测高血压的模型,拥有较高的准确率、精确率、召回率与F1分数,分类效果好,稳定性强。
由于XGBoost中参数较多,借助网络搜索(GridSearchCV)方法来优化XGBoost中需要手动调整的参数。最终XGBoost模型达到最佳效果时的最佳参数如表5所示。

表5 XGBoost的最佳参数
表中共展示了XGBoost的7种可变参数,每个参数都有不同的含义,其中learning_rate为算法的学习率,控制每次迭代更新权重的步长,默认值为0.3,选取的最佳参数为0.01;n_estimators为总的迭代次数即基础学习器的个数,通常以树的形式存在,默认值为10,选择的最佳参数为1000;max_depth代表树的最大深度,默认值为6,典型值为3~10,值越大越容易过拟合,选取的最佳参数为3;min_child_weight是最小叶子权重,默认值为1,典型值为2~10,值越小越容易过拟合,选取的最佳参数为5;gamma为惩罚项系数,是指定节点分裂所需的最小损失函数下降值,默认值为0,选取的最佳参数为0.3;subsample表示用于训练模型的子样本占整个样本集合的比例,默认值为1,取值范围为0~1,选择适当比例可防止过拟合,选择的最佳参数为0.75;colsample_bytree代表用于训练模型的特征占全部特征的比例,默认值为1,取值范围为0~1,本文选择的最佳参数为0.85。
2.2 特征分析
通过算法进行分类最重要的部分是用于进行预测的特征,某些特征在预测中 起到非常重要的作用,因此为了进一步探索营养成分与高血压之间的关系,以及验证模型的有效性与稳定性,引用了特征重要性分析。在前面的实验中XGBoost模型验证为营养成分预测高血压的最佳模型,而XGBoost可以根据结构分数的增益作为某个特征的分割点,特征的重要性得分可以用特征在所有树中被调用出现次数的总和表示。在调参最优的XGBoost中,根据特征重要性排序,最终获得了影响高血压分类的前12个特征,具体如表6所示。

表6 影响高血压分类的前12个特征
表中特征重要性得分从高到低排序,可以看出影响高血压分类的前2个因素是年龄和BMI值,它们的特征重要性得分分别为301和225,不同年龄和不同身形的人的饮食结构不同,也就是说年龄和BMI值影响着其他营养成分特征,且随着年龄增长和体重增加,高血压的患病率会逐渐上升,所以年龄与BMI值处于前2个位置是合理的。排名在3~12的营养成分特征分别是:脂肪(Fat)、维生素C(VC)、铁(Fe)、钠(Na)、镁(Mg)、碳水化合物(CHO)、维生素E(VE)、钙(Ca)、维生素B2(VB2)、胆固醇(CHOL)。
文献[7-8]中指出膳食中钠的摄入与脂肪的摄入与人的血压成正相关,文献[9]中指出服用维生素C对降低高血压患者的血压值具有一定的作用,而钠、脂肪与维生素C在高血压预测模型中的营养成分特征重要性得分中也排在前5位。文献[24]指出对抑制高血压有积极影响的营养成分有镁、钙、钾和膳食纤维,对抑制高血压有消极影响的营养成分有钠和碳水化合物,其中镁、钙、钠以及碳水化合物这4种,也位于XGBoost模型获得的影响高血压分类的营养成分的前10位。
3 结 论
对高血压的预测问题展开了深入研究,在现有的几种以医疗相关指标与一般信息为主要特征的高血压预测方法的基础上,针对膳食营养与血压值之间的联系,提出了一种通过分析营养成分预测高血压的五阶段方案,搭建了基于XGBoost的高血压预测模型,通过分析个人日常摄入的营养成分信息以及年龄与BMI来预测其是否患高血压。从实验结果来看提出的方法获得了85.7%的准确率以及0.859的F1分数,相比其他分类算法均为最高,验证了提出的高血压预测五阶段方案的可行性;通过特征重要性分析,获得了影响高血压的前10个营养成分,对比各类文献可知,钠、脂肪、维生素C、镁、钙以及碳水化合物对高血压的影响与现有医学结论相同,从而验证了模型的有效性。
