面向智慧教育的智能阅读行为分析研究
2023-04-06皮曙冯骥
皮曙 冯骥


关键词:智慧教育;机器学习;聚类算法;阅读行为
智慧教育是指在教育领域(教育管理、教育教学和教育科研)全面深入地运用现代信息技术来促进教育改革与发展的过程。其技术特点是数字化、网络化、智能化和多媒体化,基本特征是开放、共享、交互、协作。以教育信息化促进教育现代化,用信息技术改变传统模式,是提高人类自然智能的系统和过程。祝智庭教授认为智慧教育的本质是培养学生的自主学习能力和创新创造能力,推进信息技术与教育教学深度融合以适应创新时代对创新型人才的需求,其精神内核是伦理道德和价值认同,智慧教育强调文化、认知、体验、行为的整合运用[1]。而阅读作为自主学习中重要的一环,在自主学习中有着不可取代的地位。因此,分析阅读中的行为并提取有效信息进行分析,有助于实现对学生的智能分析,以求实现智慧教育中针对不同的学习者制订与之适应的教学计划,最后,智能地为学生定制资源、调整策略,以提升学习效率,提供可行性研究与基础方法探索[2]。但是,目前关于这方面的研究较为稀少。而在目前存在的對于阅读行为的研究中,其更多的是对阅读时人阅读书籍类别等进行研究,关于视线方面的实际研究仍具有极大的意义。
基于以上的问题,文章从两个方面开展阅读行为的分析。其一,文章对阅读时产生的视线轨迹进行分析,并通过轨迹行数的计算为后续的行为分析奠定数据基础。其二,文章研究了阅读时的视线行为,并使用DBSCAN聚类算法对行为进行划分,对用户各个行为及其占比进行了分析。
1 研究现状
针对智能教育的可行性与具体细节,国内多位学者从多个角度开展了研究:郑庆华等从数据,教学和平台三个方向对智慧教育研究进行了总结和归纳[3];杨宗凯等从教育学的视角讨论了信息化智能化对教育学发展的意义[4];孙茂松等从技术的角度对人工智能在教育领域的应用场景和边界进行探讨和展望[5];陈恩红等从试题表征模型,个性化学习资源分配等层次对当前在线智慧教育的技术和未来发展方向进行了详细探讨[6]。而以上的研究更针对教育方面的研究,基本不涉及行为分析。
针对阅读行为的研究,国内也有多位学者进行了研究:吕纪从等主要研究不同书籍与不同人群之间的潜在规则[7];陈美玲则主要研究读者网上阅读行为分析、心理需求解析和制约因素[8];但是以上的研究均未涉及关于阅读视线的研究,当前关于阅读视线的研究仍然较少。
而文章主要针对阅读时的视线位置数据,研究其轨迹及数据表示的用户的阅读行为,并尝试将用户的阅读行为数据用文字进行描述。因此,文章所研究的课题仍具有巨大的研究价值。
2 视线轨迹分析分析
本章节主要对阅读的视线轨迹进行研究,并基于该研究采用机器学习的方式对阅读时每一页的实际阅读行数进行估计,从而对阅读时的实际完成度进行估算。
2.1 数据来源
本算法在重庆师范大学“基于视线追踪的智能阅读器项目”的依托上,对用户在学习过程中所产生的视线数据进行收集,并整理获得真实的阅读视线数据集。选取这个数据集的原因为:基于项目产生的数据集更加接近平时生活中阅读产生的数据,对实际应用更具有参考意义;同时可以以页数为划分标注每一页的实际行数,针对每一页的行数计算,更容易获取有关实际行数的信息,使数据的获取变得更加容易,为进行阅读实际完成度的研究做好铺垫。
2.2 数据特征分析
该数据集分为两组,一组为视线数据,其中该项目1秒钟收集十个视线点,标注有页数,x,y,时间戳,具体数据如图1所示。
另外一组则为行数数据集,标记每一页的实际行数,如图2所示。
通过对视线轨迹数据分析可知,阅读时视线的轨迹具有如下规律:在横向上视线轨迹表现为先向左后向右的往复运动,其中一次往复运动代表阅读一行。而纵向上视线横向右移时基本不变,但视线横向左移动时纵向向下位移较为明显,由于数据采集时垂直方向数据受眨眼等因素从而波动较大,因此主要研究横向数据的变化。其中某一页视线轨迹如图3所示,其中x轴和y轴对应视线的横向(向右为正)和纵向(向下为正),点上的编号对应其时间顺序。
通过分析可以发现,x轴的左移和右移的位移长度并非完全一致,因此设存在某阈值,使得左移位移量大于右位移量乘该阈值时为一行阅读结束。同时这里使用机器学习的方式去求得该阈值的值。
2.3 数据清洗及预处理
数据清洗(Data Cleaning)是指对数据进行重新审查和校验的过程,在本算法中主要表现为在屏幕外的视线的无效值的处理,包括摄像头可捕捉但实际处于屏幕外的视线点和摄像头无法捕捉的视线点,其中第二种表现为同一位置的连续重复出现。获取的真实数据集只有x与y的值及页数,因此基于保证数据的泛用性的目的,需要对数据进行归一化的处理,使数据x,为同一单位。部分清洗后的数据信息如图4所示。
最后,基于数据以页为单位的理由,将数据以页为划分,存入数组中进行训练。
同时,另外准备一组测试集用于测试训练结果,处理方法同训练集。
3 基于聚类分析的阅读行为判定
这一章节主要对阅读时的视线行为进行分类并针对表示不同阅读行为的视线点进行分析统计。
3.1 数据来源
本算法中实验部分的数据主要由以下两部分数据组成:
第一部分为来源于眼动仪的标准数据集。本实验主要引用了含有时间t,坐标x与坐标y,以及视线类型四种参数的数据集,所有数据均来自SensorMotoric Instruments(SMI) 的头戴式眼动仪,目的之一是训练出有效的分类器,使得本项目仅可以依靠t,x,y便可知阅读者的视线状态,为后续个性化学习以及相关分析做铺垫,以及对视线数据进行可视化分析。
第二部分数据集为在重庆师范大学“基于视线追踪的智能阅读器项目”的依托上,对用户在学习过程中所产生的视线数据进行收集,并整理获得的真实的阅读视线数据集。真实数据集用于对上一数据集的成果进行检验,反映在贴近实际生产应用情况下的效果。
3.2 对阅读行为的划分
在对阅读时人的行为进行分析后,发现了阅读有以下几个基本行为:
首先是不专注行为:即在阅读视线处于阅读书本外时即为不专注行为,在“智阅”项目视线上表现为点在屏幕之外,或未检测到视线,而该视线在眼动分析仪上表现为视线在屏幕外或为nan(无法检测到视线点坐标值)。虽然看书时偶尔会有视线划出书本又划入的轨迹,但误差小,可以忽略不计。
第二个为浏览(扫视)行为:当视线从书本划过时为对书本的浏览(扫视)行为,在视线上表现为x值快速变化。同时其变化的速度则与每人的阅读习惯有关,多出现于不重要的章节或对小说等故事类文章进行阅读的状态。
第三个为注视行为:在阅读时会对某一块区域进行反复阅读,包括但不限于回头。该行为在视线上的表示为某一行或某一区域产生一个比较集中的点位,因此可以考虑使用聚类算法来寻找具有该类紧密特征的点集。该类点多出现于用户感兴趣的区域,主要知识点区域即主要难点区域。
此外,阅读中也存在眨眼行为,但在“智阅”项目中没有体现,实际生产中分离该类行为会较为困难,因此会去除该类行为。
最后鉴于不专注行为结果较为明显,这边不再对该类行为进行讨论,主要就浏览和注视进行验证和讨论。
3.3 DBSCAN 聚类算法核心及优势
DBSCAN 聚类算法是基于密度的聚类算法,主要根据数据分布的紧密程度进行聚类。DBSCAN 聚类算法的两个参数邻域样本阈值minPts和距离阈值Eps 的取值是决定聚类效果的关键所在,同时通过这两个参数来刻画数据的紧密程度[9]。相比于其他算法,尤其是K-Means算法,其优势主要体现在以下几点:
K-Means算法,其优势主要体现在以下几点:第一,可以发现任意形状的聚类簇,而有别于K- Means,K-Means一般仅仅使用于凸的样本集聚类的算法。同时它在聚类的同时还可以找出异常点,这点和BIRCH算法类似。
第二,该项目的数据集并不为标准的凸的样本数据集,因此存在噪声点。而噪声点为浏览行为的代表点,因此DBSCAN能更有效找出数据集中的噪声点,从而对噪声点进一步分析。
同时,在对数据经过不断观察分析后,取minPts 为3,Esp为0.024作为分析时DBSCAN算法的参数,此时能最大限度地将注视点通过该方式找到。
4 实验过程与实验分析
4.1 阅读视线轨迹行计算训练
前向计算方式如下:
對每一页的数据进行单独分析,首先由于行数变换只与x的差值有关,因此先针对每一页计算两个相邻点之间的差值,差值为正数时为向右位移,为负数时向左;同时鉴于0-1数值太小,计算阈值时可能会导致阈值移动过大,因此对每一个差值乘1000;之后每一次会统计视线向左位移的绝对值和向右位移绝对值之间的差值,直至达到阈值,对向左位移进行清零,直至视线重新向左,则行数加一,并重复以上步骤直至行结尾,此时因为视线不会向右位移,行数加一。
Loss采用(输出行数-实际行数)的均值作为损失函数,更新时基于loss值正负对阈值移动,移动步长为0.001。准确度并不是按照完全准确来计算,而是基于每组数据的行数偏差计算。训练过程部分数据如图5,其中time为时间,loss为损失,Result为计算结果,acc为在测试集上的准确度。
训练后在测试集上准确率约为97.84%,图6展示训练至各个阶段的测试集准确度,该结果表示训练取得了一定的效果。目前该模型已经可以对大部分情况做初步分析,在实际应用中也取得了一定的效果。
基于上述结果,在实际使用中任取两页,以模型检测阅读的行数除以书本行数计算阅读的完成度百分比,同时收集实际阅读行数检测其准确性,最终测试结果为39.3% 和92.3%,实际结果为39.3% 和100%。该数据证明该模型已取得了较为准确的结果,同时表明该模型有一定的使用价值。比较结果如图7所示。
4.2 阅读视线行为分析
4.2.1 数据清洗及预处理
视线数据的形状如图8所示。
首先需要进行数据清洗,在这里表现为去除无效点。具体做法为:首先去除数据中存在x或y小于0或大于1的数据,该类数据分布在屏幕外。之后去除x,y为NaN的数据,因为该数据为无效数据,推测为视线不在捕获范围时的数据。同时鉴于该实验只研究注视和浏览行为,因而去掉除了event strings为Fixation (注视)和Saccade(扫视、浏览)之外的视线数据,去除前后对比如图9和图10所示。
在阅读行为中,由于翻页的动作会导致维度x,y 的不规则剧烈变化。基于上述问题,这里将数据按照页数的变化进行分组,在聚类时对每一组单独聚类。同时,由于单纯的二维数据特征不够完全,因此对该数据每页中每个点同上一个点的x和y差值计算并一起作为特征输入(每页首部x,y差为0) ,形成一个四个维度的数据。处理之后的数据格式展示如图11和图12所示。
4.2.2 实验过程与结果分析
实验中对每一页的数据进行DBSCAN聚类。注视行为会处于一种x和y相对移动较小,x,y较为接近的状态,具体展示其中一页的聚类结果如图13所示。但鉴于一页中可能存在不同的聚类簇,所以不同于正常的聚类,此处不关心聚类产生了多少簇,更多是对该数据是否为噪声点进行分析。若为噪声点,此处认为该行为是快速浏览的结果,记为浏览行为数据;否则记为注视行为数据。图13展示其中一页的聚类效果,鉴于无法根据四维画出图形,这里用x,y二维画出图形,可以看到属于注视的点较容易形成簇。
经检验,该算法的正确率达到79.03%,基本上可以较为准确预测,各个点的判定结果如图14所示。
由上述结果可知模型更倾向于做出“注视”的判断,实际情况下对于注视的判断基本为正确,因此用于判断注视是十分可靠的。
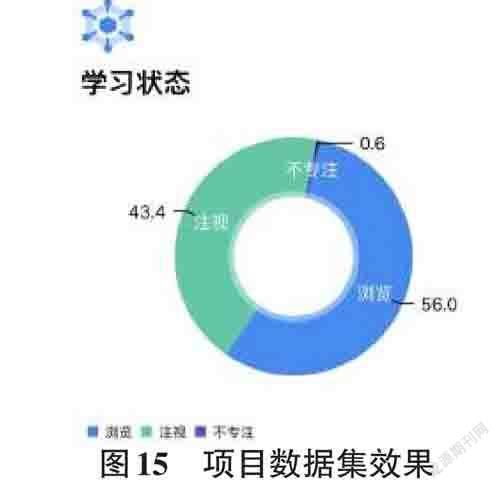
在真实数据集下会对每页数据隔离,相对于该数据可以对每一页有一个划分。但是鉴于y值的不稳定,很难通过四维数据得到有效准确的结果,准确率可能会受到一定的影响。真实数据集下虽然没有实际准确答案,但根据阅读时的状态,基本确定该方法虽然受一定影响但是可行有效的。图15是该算法部署在“基于视线追踪技术的智能阅读器”上后在真实数据集对产生的饼图,其中浏览行为对应“扫视”百分比,注视行为对应“注视”百分比,不专注行为即为屏幕外的点数百分比。
5 结束语
文章基于阅读时产生的视线数据在关于智慧教育的方向上对其做了两方面的研究:一是对阅读时的视线轨迹进行分析,并通过机器学习的方式计算了阅读时实际阅读的行数,准确度相对可以,但该研究主要以扫视(浏览)为主,同时其核心算法有待进一步改进;二是针对阅读时的行为进行分类,使用DBSCAN 聚类算法并对其进行部分处理识别视线行为中注视和浏览的行为,实际算法效果相对准确,但在提高其精确度和针对现实生产作业中的数据仍待深入研究。
这两项研究均对智慧教育的研究有着重大意义。首先视线轨迹和行算法对行数进行分析,而通过对实际行数进行对比,可以得知该用户对每一页或整本书的阅读完成度,可以更好地了解该学生对本书的学习程度。若关系为学生和老师则有助于老师根据所有人的完成进度制订个性化的教育计划。
对视线行为的分析也有着多方面的价值:一方面,可以了解学生的阅读习惯等,有助于根据学生的阅读习惯制订相应的阅读方针和计划,从而更高效地完成学习计划;另一方面,可以对学生当前的学习状态做出相应的评估,基于学生当前的状态给予针对性的教育和指导,从而为个性化教育和智慧教育提供相应的信息,为智慧教育提供辅助手段。