基于混合注意力机制的软件缺陷预测方法
2023-04-03刁旭炀周俊峰
刁旭炀,吴 凯,陈 都,周俊峰,高 璞
(上海机电工程研究所,上海 201109)
0 引言
软件稳定性是衡量软件质量的重要标准,成千上万行复杂代码往往存在会导致软件失效的风险。为了帮助开发和测试人员更加高效地定位潜在缺陷,软件缺陷预测技术正广泛运用在软件的代码审查阶段,是软件工程[1]研究领域中的重要研究方向之一。
软件缺陷预测技术[2-3]利用软件代码库中的历史项目进行缺陷度量元的设计与提取,并将基于静态度量元的特征放入缺陷预测分类器中进行模型训练,最终得到的缺陷预测模型能够有效识别存在缺陷的代码模块。软件开发与测试人员可根据预测结果对相关模块进行复核校验,从而节省了查找定位缺陷的时间,提升了软件质量维护与保证的效率。软件缺陷预测主要分为同项目软件缺陷预测[4]与跨项目软件缺陷预测[5-6]两个研究方向。此外,依据提取的程序特征颗粒度,可将软件缺陷预测技术分为基于文件级、函数级、变更级的缺陷预测。
传统的缺陷预测方法通常是基于人工设计的静态度量元特征来构建软件缺陷预测模型。相关研究人员已经设计出了相关有辨别度的特征可以有效区分有缺陷和无缺陷的程序模块,主要包括基于运算符和操作数的Halstead[7]特征、基于依赖的McCabe[8]特征、基于面向对象程序语言的CK[9]特征以及基于多态、耦合的MOOD[10]特征。
然而,由于静态度量元特征值是基于专家经验设计的统计值,存在有缺陷代码模块和无缺陷代码模块出现相同值导致无法区分的情况。ASTs[11]是一种基于源代码的特征树表示方式,蕴含着丰富的程序上下文信息。通过运用深度学习技术挖掘基于ASTs的语法语义特征,可以得到比静态度量元更具代表性的缺陷特征,从而构建出性能更好的缺陷预测模型。
为了充分运用程序上下文中潜在的语法语义信息,论文提出了一种基于混合注意力机制的软件缺陷预测方法。首先,使用词嵌入方法将特征序列表示为可被学习的多维向量,然后使用基于正余弦函数进行位置编码,接着运用多头注意力机制自学习每个位置在上下文中的语法语义信息,最后使用全局注意力机制提取整个程序模块的关键特征,从而构建出更加具有鉴别力的缺陷预测模型。论文选取了7个Apache开源项目作为数据集,与5种典型的基于静态度量元和程序语法语义学习的方法进行比较,实验结果表明论文提出的DP-MHA方法在F1上平均提升了17.86%。
1 相关工作
在基于静态度量元的方法中,Chen[12]等人使用多目标决策优化算法对软件缺陷预测特征进行筛选;Huda[13]等人采用包裹和过滤式特征选择方法识别重要的缺陷特征;Okutan[14]等人使用贝叶斯网络来分配静态度量元与缺陷倾向性之间的影响概率;此外,Xu[15]等人提出了一种基于图的半监督缺陷预测方法来解决有标签数据不足和噪声问题。在基于程序语法语义学习的方法中,Wang[16]等人使用深度置信网络生产隐式的语法语义特征进行缺陷预测;Dam[17]等人建立了一种基于深度学习树的缺陷预测模型来尽可能多地保留ASTs的初始结构特征信息;Li[18]等人建立了嵌入静态度量元的卷积神经网络缺陷预测模型;此外,Phan[19]等人基于图神经网络从控制流图中挖掘软件的语法语义特征信息用来构建缺陷预测模型。
但是由于存在长期记忆依赖问题,基于RNN和CNN生产的语法语义信息可能存在信息的丢失。为了充分挖掘特征序列中每一位置的上下文信息,DP-MHA采用多头注意力机制进行上下文自学习编码,然后将生产的隐式语法语义特征放入全局注意力机制网络中提取关键特征信息,用于缺陷预测模型的训练与预测。
2 DP-MHA总体架构
本节对基于混合注意力机制的软件缺陷预测方法DP-MHA的总体架构进行了详细阐述,详见图1。
首先,DP-MHA将项目中的每个程序文件提取为ASTs树结构,然后从中选取关键节点并运用深度遍历方法获得序列向量,接着通过字典映射和词嵌入技术扩展为可学习的多维向量,其次运用正余弦函数进行位置编码,将编码后的向量放入多头注意力机制层,进一步挖掘每个位置的上下文语义,最后运用全局注意力机制提取程序文件中关键的语法语义特征,放入预测输出模型进行训练与预测。
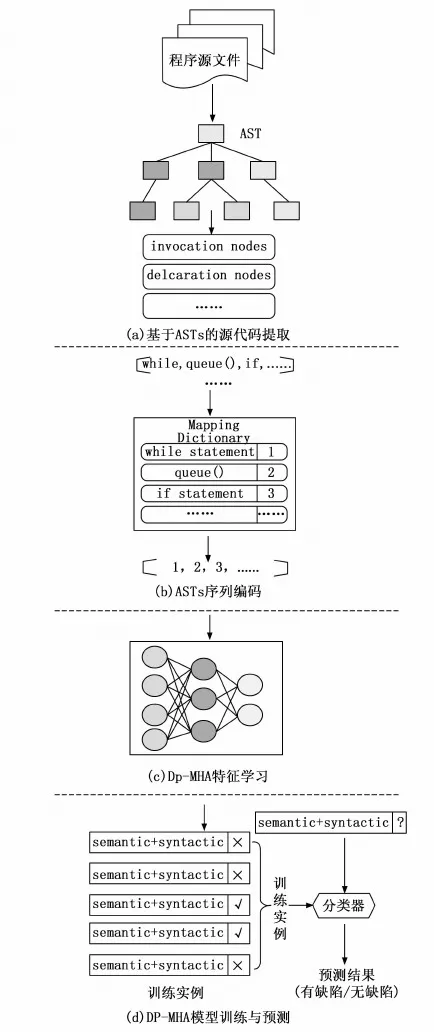
图1 DP-MHA总体架构
2.1 基于ASTs的源代码提取
为了将程序文件中的源代码用向量形式进行表征,需要选择合适颗粒度,如字符、单词或ASTs等形式对源程序进行特征提取。ASTs是源代码语法结构的一种抽象表示,它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的上下文语义信息。基于ASTs的表示形式能映射出源程序中的语法结构和语义信息,具有多维度的特征信息可供缺陷预测模型进行学习,因此论文采用该形式对源代码程序进行抽象表征。
根据先前的研究,论文只提取3种类型节点作为ASTs树特征值。第一类为方法和类实例的创建节点,此类提取方法名称和类名称;第二类为声明节点,包括方法、类型、枚举等声明,此类提取它们的具体值;第三类为控制流节点,包括分支、循环、异常抛出等控制流节点用它们的类型值记录。所有被选择的AST节点值如图2所示。
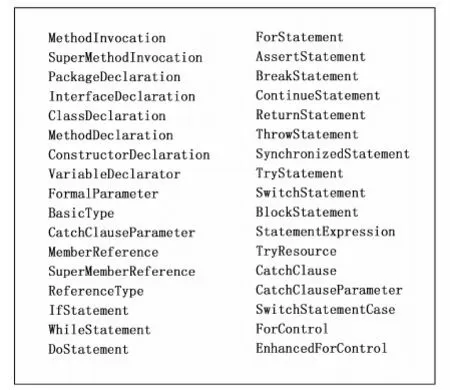
图2 选取的AST节点类型
在本次实验中,论文采用基于Python的开源数据分析包javalang对Java源代码进行分析提取为AST抽象语法树,然后采用深度遍历的方法将提取的节点值转化为一个序列向量,详细描述见算法1。
算法1:将源程序文件提取为ASTs字符向量
输入:
F:源程序文件{f1,f2,…,fn}
R:选取的节点类型{r1,r2,…,rn}
输出:
S:字符向量{s1,s2,…,sn}
1. For i = 1→n do
2. 构建源程序fi的AST抽象语法树ASTi;
3. For node in DFT(ASTi) then
4. If node in R then
5. Add node into ;
6. End
7. End
8. Addsiinto S;
9. End
10.Return S;
2.2 ASTs序列编码和类不平衡处理
ASTs序列向量存储着大量程序模块的语法语义信息,两段代码模块可能具有相同的静态度量元特征值,但它们的ASTs结构存在差异,这使得基于ASTs序列可学习生成更具有辨别力的特征。为了让提取的ASTs序列向量具备可学习性,采用字典映射技术将序列中的节点映射为一个整型数字,假设节点的数量为m,每个节点用一个整型数字表示,那么映射范围就是从1到m。算法2为ASTs序列编码的详细描述,首先统计每个节点出现的频率,并按照频率从高到底排序,然后将ASTs字符向量映射成数字向量,接着需要将长短不一的数字向量统一为固定长度,少于固定长度的向量通过填充0来补齐长度,超出固定长度的向量将频率低的节点依次剔除直至长度与固定值一致,最终为了使得映射的数字向量具备可学习性,构建可被训练的高维词字典,采用词嵌入技术将每一个数字节点转化为一个多维向量。
算法2:ASTs序列编码
输入:
S:ASTs字符向量{s1,s2,…,sn}
M:字符向量的长度
StrFreq:字符频率字典
StrtoInt:字符转整型字典
StrFreqList:字符频率列表
输出:
V:编码后的整型向量{v1,v2,…,vn}
1. 初始化V、StrFreq、StrtoInt和StrFreqList
2. For i = 1→n do
3. For j=1→len(si) do
4. if sijnot in StrFreq.keys then
5. StrFreq[sij]=0;
6. End
7. StrFreq[sij]+=1;
8. End
9. End
10. For key in StrFre.keys then
11. StrFreqList.add((key, StrFreq[key]));
12. SortbyStrFreq(StrFreqList) ;//按频率降序排列
13. For i=1→len(SortbyStrFreq) do
14. Str= SortbyStrFreq[i][0];
15. StrtoInt[Str]=i;
16. End
17. For i = 1→n do
18. For j=1→len() do
19.vij=StrtoInt[sij];//将字符映射为整型,频率高的字符靠前
20. End
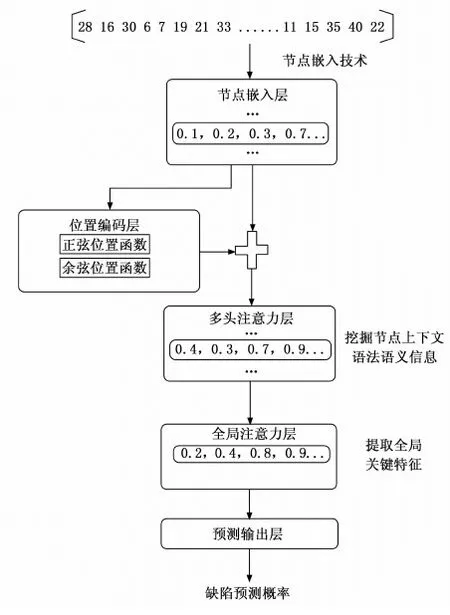
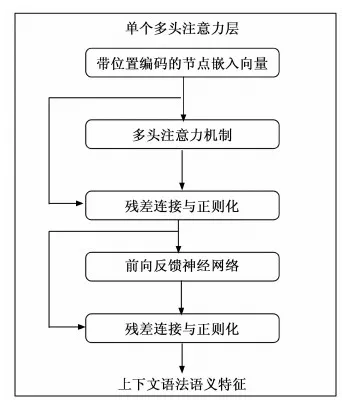
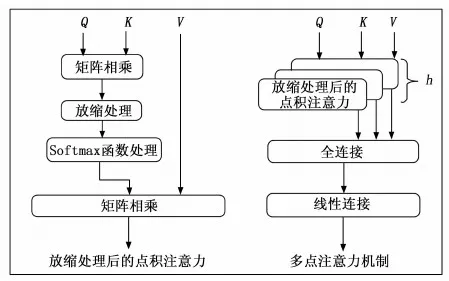
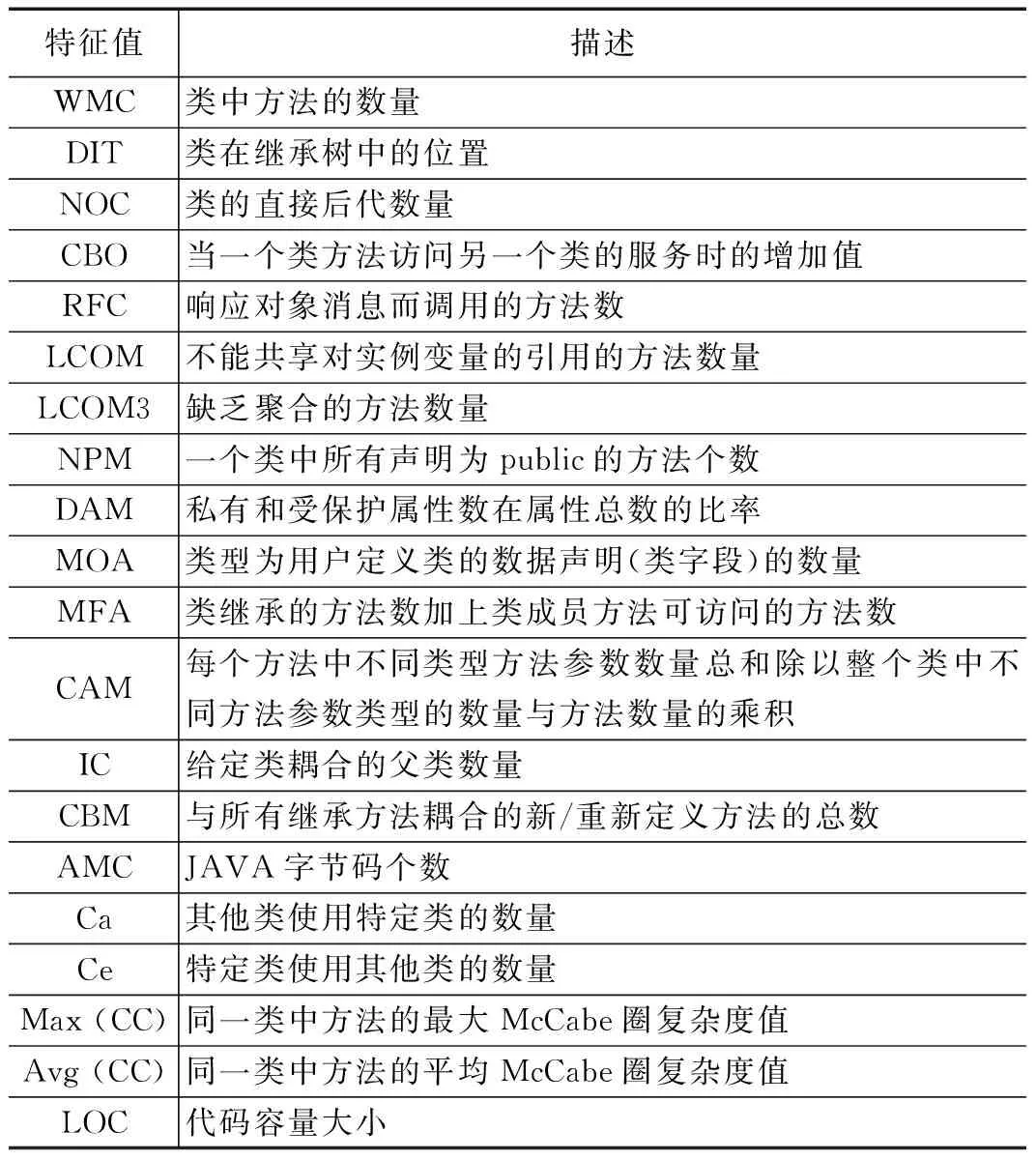
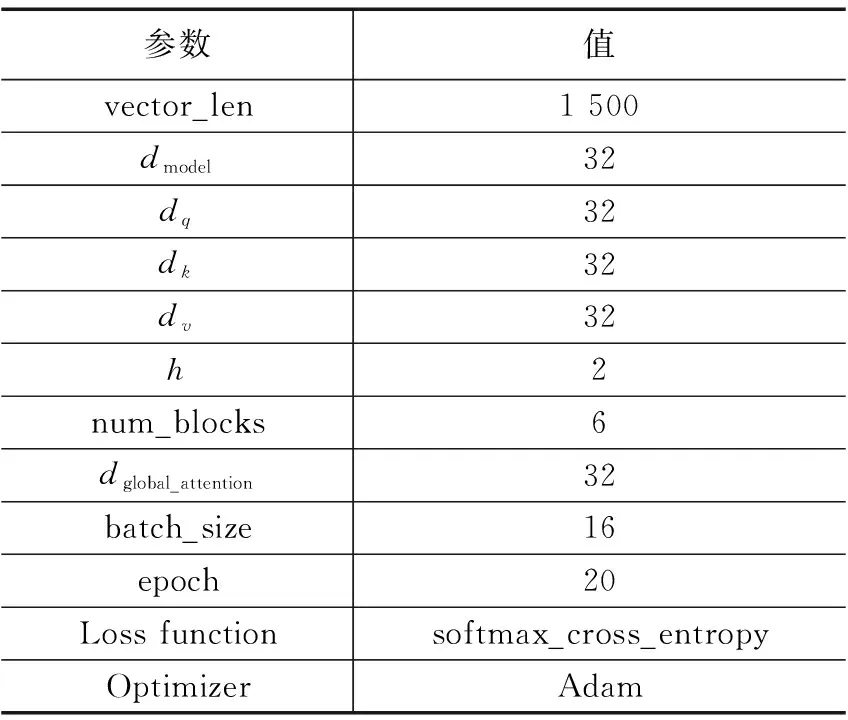
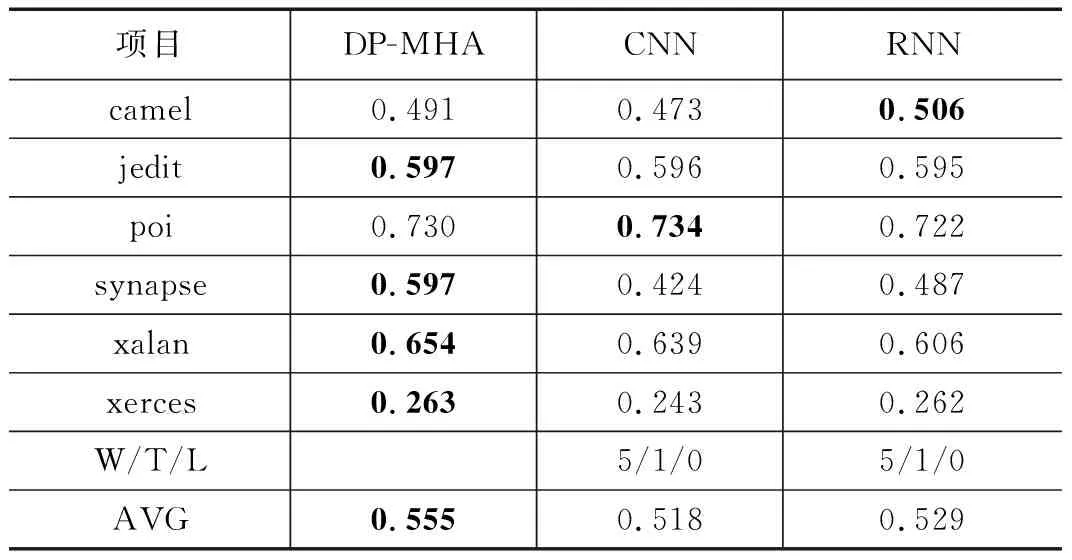
21. If len(vi) 22. Add M-len(vi) 0 s intovi; 23. End 24. Else if len(vi) >Mthen 25. For k=1→len(vi)-m do 26. z=vi.index(max(vi));//找到频率最低的字符所对应的序号 27. Delviz//删除该字符 28. End 29. End 30. Addviinto V; 31. End 32. Return V; 软件仓库中的缺陷数据通常是类不平衡的,其中有缺陷的程序文件往往只占据很小的一部分。直接采用原始数据集训练的到模型存在偏向于大多数(无缺陷)类的偏差。为了解决该问题,通常采用过采样或欠采样技术对数据集进行平衡处理。过采样通过复制少数类的实例来实现类间平衡,而欠采样则是将多数类中的实例进行剔除。考虑到欠采样或导致数据信息的丢失,从而导致欠拟合的情况,因此论文采用过采样技术将少数(有缺陷)类的实例进行复制,从而构造出两类平衡的数据集。 DP-MHA神经网络架构如图3所示,主要包含节点嵌入层、位置编码层、多头注意力层、全局注意力层和预测输出层。 图3 DP-MHA神经网络架构 2.3.1 节点嵌入层 一维数字符号无法充分描述一个AST节点的上下文信息,论文采用词嵌入技术将每一个一维数字向量映射为一个高维向量,详细公式见式(1)所示。 F:M→Rn (1) 其中:M代表一个一维AST节点向量,Rn代表一个n维实数向量空间,F代表一个参数化函数,能将M中的每个数字符号映射为一个n维向量。映射得到n维向量紧接着被放入位置编码层学习节点的位置信息。 运用词嵌入技术不仅可以将节点的语法语义表示形式限制在有限维度的空间内,节省网络训练的成本,避开维数灾难,而且节点之间的语法语义特征相似度也可以通过余弦距离公式来进行度量,极大地提升了网络学习语法语义特征的效率。 2.3.2 位置编码层 在DP-MHA模型中没有涉及到循环和卷积的神经网络,为了充分利用AST向量的序列特性,DP-MHA将节点嵌入层输出的向量放入位置编码层进行相对位置关系的学习,位置编码后的向量维度与节点嵌入后的向量维度相同,以便两者相加得到最终包含相对位置关系的高维节点向量,作为多头注意力层的输入。 根据先前的研究,论文采用基于正弦和余弦函数进行位置编码,其计算公式如式(2)、式(3)所示: PE(pos,2i)=sin(pos/10 0002i/dmodel) (2) PE(pos,2i+1)=cos(pos/10 0002i/dmodel) (3) 其中:pos代表第pos个向量,i代表第pos个向量中的第i个维度,dmodel为节点嵌入的维度。即每个偶数位置的位置编码对应正弦函数,每个奇数位置的位置编码对应余弦函数,函数波长为2π到10 000*2π的几何级数。对于任意固定偏移量k,PEpos+k能用PEpos的线性函数所表示,因此采用正余弦函数能较好的表示节点之间的相对位置关系。 2.3.3 多头注意力层 多头注意力层由6(num_blocks)个相同的神经网络层组成。每层由一个多头注意力机制和位置转化前向反馈网络组成,每个子层计算得到的输出与原始输入进行残差连接与正则化处理,其公式表达如式(4)所示: LayerNormalization(x+SubLayerFun(x)) (4) 其中:SubLayerFun为多头注意力机制和位置转换前向反馈网络两个子层的函数,将SubLayerFun(x)与原始输入x相加得到残差连接并进行正则化处理,所有子层的输入输出向量维度与初始节点嵌入的维度相同。 多头注意力机制由h个基于点积的注意力函数组成,首先将节点嵌入的维度缩小dmodel/h倍,使得神经网络的计算代价与带有整个节点维度的单个头注意力机制的计算代价相同,然后并行应用h个注意力函数,得到的输出进行全连接得到最终的上下文语法语义特征,具体机制架构详见图4所示。 图4 单个多头注意力层 每个点积注意力函数的输入为矩阵Q,K,V组成,计算公式如式(5)所示: (5) 图5 多头注意力机制的函数架构 在运用多头注意力机制后,DP-MHA采用一个全连接的前向反馈神经网络进行位置转换,该网络层由两个线性函数和一个ReLU激活函数组成,其计算公式如式(6)所示: FFN(x)=max(0,xW1+b1)W2+b2 (6) 2.3.4 全局注意力层 从多头注意力层中可以得到一个序列所有位置节点的上下文语法语义信息,这些位置节点对整个序列的语法语义贡献是不同的。为了提取其中关键的语法语义特征,DP-MHA采用了全局注意力函数,每个节点都会分配相应权重,进行加权和即可得到关键特征,其具体计算公式如式(7)~(9)所示: uit=tanh(Wnhit+bn) (7) (8) si=∑tαithit (9) 其中,全局注意力机制首先将节点hit放入一个多层感知器(MLP)来生成uit作为节点的隐式特征表示,然后设定一个全局上下文向量un,作为在每一个序列中搜寻关键节点信息的高阶表示向量,接着计算uit与un的点积相似度并通过softmax函数进行归一化处理。最终计算所有节点的加权和作为学习得到的全局关键语法语义特征向量si。 2.3.5 预测输出层 预测输出层由一层带有sigmoid激活函数的多层感知器组成,损失函数采用基于softmax的交叉信息熵,具体计算公式如式(10)、式(11)所示: Yi=sigmoid(siWo+bo) (10) (11) 本文选取了6个公开Java项目作为实验数据集,所有数据集均可在Github Apache 项目集中获得。每个项目选取两个版本,其中前置版本作为模型的训练集,后置版本作为衡量模型的测试集。在软件缺陷预测研究数据集中,静态度量元数据是一种公认的特征集,针对Java面向对象程序语言的特点,Jureczko[20]等专家已进行相关研究并提取出了20个典型的静态度量元,其中包含了软件规模、代码复杂度以及与面向对象程序语言特性相关的特征。详细见表1所示。此外,程序的语法语义特征则由深度学习模型自动学习生成。 表1 选取的20个静态度量元特征值 表2列举出了实验中项目数据集的相关信息,主要包括了项目名称、版本号、程序模块数量(以代码文件为单位)以及总体缺陷率。 表2 Java项目数据集信息 3.2.1 实验环境 本次实验的硬件配置为一台带有Intel i7酷睿处理器、8G内存和GTX1060显卡的台式机,操作系统为Windows10,使用到的开发语言为Python及其相关机器学习与深度学习模块Scikit-learn和Tensorflow,开发工具为pycharm。 DP-MHA网络架构的输入向量长度(vector_len)为1 500,节点嵌入维度(dmodel)为32;多头注意力机制query、key与value向量的维度为32,h为2,num_blocks为6;全局注意力层的输出维度dglobal_attention为32,其余参数详见表3。 表3 DP-MHA网络参数配置信息 3.2.2 评价指标 本文从F1值角度对DP-MHA方法的软件缺陷预测性能进行衡量。通常情况下,当查全率(R)上升的同时,会降低查准率(P),F1值综合了查准率(P)和查全率(R),对预测框架的综合性能进行了考量,越高代表着缺陷预测模型的稳定性越好,F1值的范围为[0,1],其计算公式如下: (12) (13) (14) 其中:c为无缺陷程序文件,d为有缺陷程序文件。Nd→d表示预测和真实值都为有缺陷的数量;Nd→d+Nc→d为所有预测结果为有缺陷的数量;Nd→d+Nd→c为所有真实值为有缺陷的数量。 在实证研究阶段,论文选取了5个经典方法与DP-MHA方法进行比较,分别为基于静态度量元的RF,基于无监督学习方法的RBM+RF和DBN+RF以及基于深度学习的CNN和RNN,详见表4所示。 表4 选取的5个经典缺陷预测方法 方法名称说明RF基于20个静态度量元的随机森林方法RBM+RF基于RBM提取程序语法语义特征的RF方法DBN+RF基于DBN提取程序语法语义特征的RF方法 CNN基于textCNN提取程序语法语义特征的方法RNN基于Bi-LSTM提取程序语法语义特征的方法 如表5所示,DP-MHA方法相较于其他5种方法在F1值上平均提升了17.86%。由此可见,基于混合注意力机制学习得到的上下文语法语义特征提升了缺陷预测模型的稳定性和准确度。 表5 DP-MHA相较于5种经典方法的F1值提升比率 为了说明DP-MHA方法相较于基于静态度量元方法的优越性,本文选取了基于20个静态度量元特征的RF方法进行对比分析。表6列出了DP-MHA与基于静态度量元特征方法RF之间的F1对比结果。相较于基于静态度量元的RF方法,DP-MHA在F1的W/T/L上全部占优,在F1的平均值上提升了16.6%。综合上述比较结果,可判得DP-MHA方法的软件缺陷预测模型稳定性能要优于基于静态度量元特征的缺陷预测方法。 表6 DP-MHA与基于静态度量元方法之间的F1值比较 为了说明DP-MHA方法相较于基于无监督学习方法的优越性,本文选取了具有典型代表的两种无监督学习方法RBM和DBN来提取程序的语法语义特征,然后将两者学习到的特征分别放入RF分类器训练得到最终的缺陷预测模型。表7列出了DP-MHA与基于无监督学习方法RBM+RF和DBN+RF之间的F1值对比结果。DP-MHA比RBM+RF在F1值的W/T/L上赢了6次;相较于DBN+RF,也全部占优。此外从F1值的平均值来看,DP-MHA相较于RBM+RF和DBN+RF方法分别提升了34.3%、26.4%。综合以上比较结果,可判得在缺陷预测模型稳定性方面,DP-MHA都要比基于无监督学习方法提取程序语法语义特征的方法来得更优。 表7 DP-MHA与基于无监督学习方法之间的F1值比较 为了说明DP-MHA方法相较于基于其他深度学习方法的优越性,本文选取了具有典型代表的两种深度学习方法CNN和RNN来提取程序的语法语义特征并自动训练与预测。CNN采用1维卷积核提取隐藏特征,RNN采用Bi-LSTM的双向循环神经网络学习隐式语法语义特征。 表8列出了DP-MHA与基于深度学习方法CNN和RNN之间的F1值对比结果。DP-MHA比CNN和RNN在F1值的W/T/L上分别都赢了5次。此外从F1值的平均值来看,DP-MHA相较于CNN和RNN方法分别提升了7.1%、4.9%。综合以上比较结果,可判得在缺陷预测模型稳定性方面,DP-MHA都要比基于CNN和RNN的深度学习方法提取程序语法语义特征的方法来得更优。 表8 DP-MHA与基于深度学习方法之间的F1值比较 本文针对同项目软件缺陷预测问题,提出了一种基于混合注意力机制的软件缺陷预测方法DP-MHA,运用节点嵌入与位置编码技术提取AST特征信息,放入多头注意力层中学习节点的上下文语法语义信息,然后使用全局注意力机制提取关键特征,放入预测输出层中进行训练与预测,该方法学习得到的程序语法语义特征有效提升了软件缺陷预测模型的性能。该方法仍有一些工作值得后续开展研究,具体而言为:(1)考虑跨项目软件缺陷预测的应用场景,并验证该方法是否能提升预测性能;(2)在实际工程项目[21-22]数据集中进一步验证该缺陷预测方法的效果与性能。2.3 DP-MHA神经网络构建
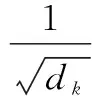
3 实验设计
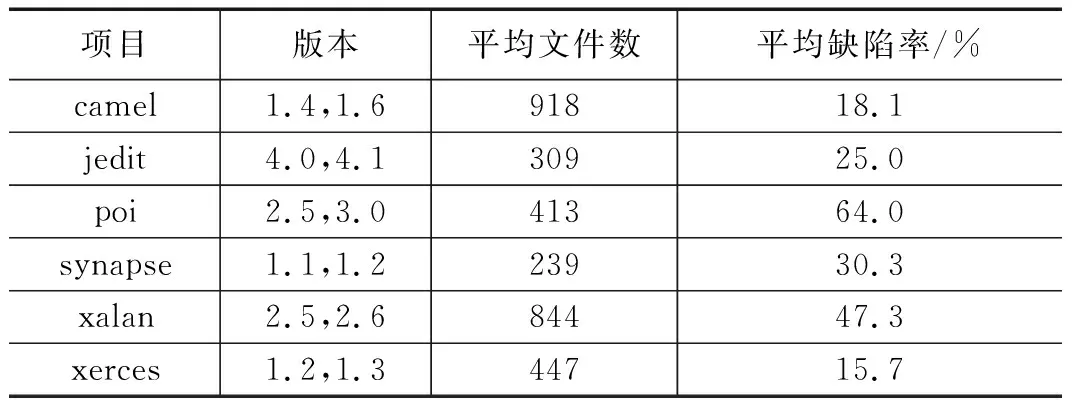
3.1 实验数据集
3.2 实验环境与评价指标
4 结果的分析和讨论
4.1 选取的经典缺陷预测方法


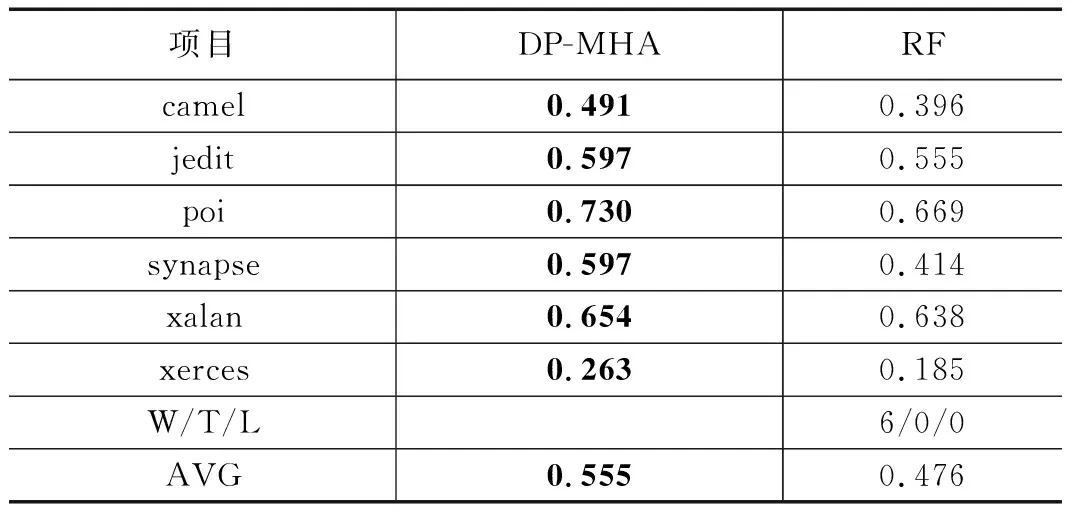
4.2 与基于静态度量元方法的性能比较
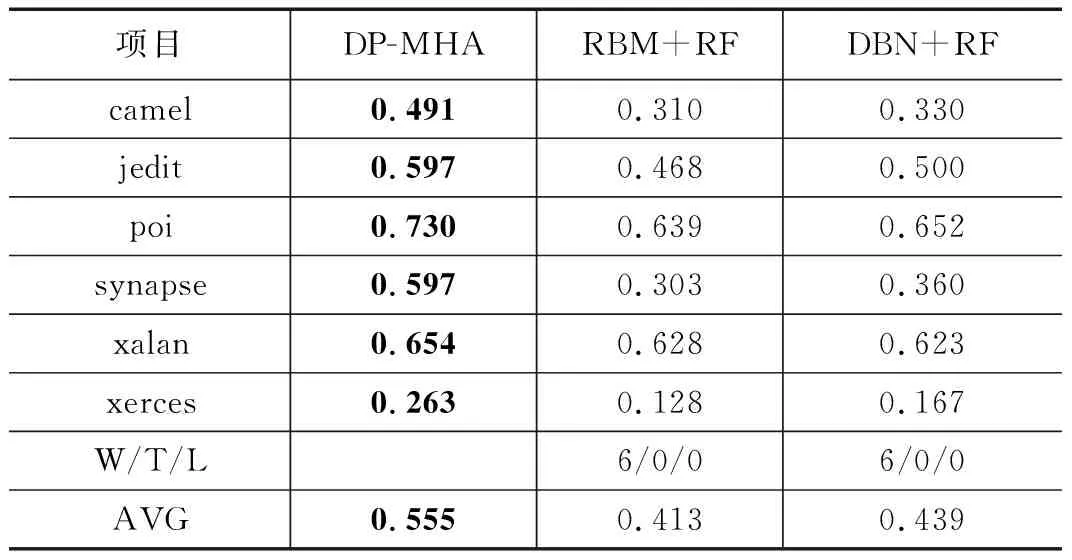
4.3 与基于无监督学习方法的性能比较
4.4 与基于深度学习方法的性能比较
5 结束语
