国际三大核酸序列数据库的运行与管理模式及对中国的启示
2023-03-30李欣然
李欣然,刘 云
(1.中国科学院大学中丹学院,北京 100190;2.中国科学院大学公共政策与管理学院,北京 100190)
1990 年,美国启动人类基因组计划,英国、法国、德国、日本、中国等主要国家科学家参与,其直接成果是测定了人类30 亿个碱基对的人类基因组全序列[1],生命科学逐步进入到以数据密集型研究为代表的第四范式,这也推动了生物学研究从实验生物学、分子生物学进入到信息生物学的阶段。预计到2025 年,全球每年将会产出1 ZB 的基因组数据[2]。数据密集型科研范式的深入发展,也推动了基因序列分析的进步[3]。在基因大数据日益成为国家基础性战略资源的背景下,对核酸序列数据的规范化管理以及数据库建设逐渐成为各国关注的重点,对核酸序列数据等人类遗传资源信息的管理也成为中国科学数据中心参与国际科学数据共享的重要课题。本研究旨在调查分析由发达国家主导的国际三大核酸序列数据库的建设情况及运行管理模式,并对中国核酸序列数据库建设进行对比分析,为推动中国核酸序列数据库建设及数据管理与开放共享提供政策建议。
1 国际三大核酸序列库建设总体情况
为对规模庞大的基因组数据进行有效管理与使用,各国纷纷建立了不同规模的核酸序列数据库。但建立核酸序列数据库是一项成本高昂且耗时较久的工程,其重难点就在于数据库架构、中间程序与可视化程序的开发工作,采用不同架构模式或者不同语言建设的数据库之间进行数据交换的难度会更加突出,这使得不同机构数据流动成本居高不下[4]。
1.1 国际三大核酸序列库发展历程
如图1 所示,1980 年,欧洲分子生物学实验室(European Molecular Biology Laboratory,EMBL)创建了世界首个核酸序列数据库(Nucleotide Sequence Data Library),即 EMBL-Bank;1982 年,美国洛斯阿拉莫斯国家实验室创建了GenBank;1986 年,日本国家遗传学研究所(NIG)创建了属于日本的核酸序列库DDBJ (DNA Data Bank of Japan)。由此,形成了分立于不同国家、分属不同机构的三大公共核酸序列数据中心[5]。由于核酸序列数据来源的差异性,且彼时并未有核酸序列数据交换共享渠道建立,致使研究者在获取全面核酸序列数据时存在困难。1988 年,为统一核酸数据格式以方便数据共享,三大核酸序列数据库(以下简称“三大数据中心”)召开了第一届国际合作会议(International Collaborative Meeting,ICM),随后三大数据中心于20 世纪90 年代中期成立了国际机构合作联盟,在联盟框架下,GenBank、EMBL 和 DDBJ 遵循统一政策,各自负责本地核酸序列数据的相关工作,形成了基于机构联盟的共享机制。2005 年,三大数据中心正式将合作命名为“国际核酸序列数据库联 盟”(International Nucleotide Sequence Database Collaboration,INSDC)。

图1 国际三大核酸序列数据库发展历程
1.2 三大数据中心数据资源状况
国际三大核酸序列数据库的主要数据资源情况如表1 所示。
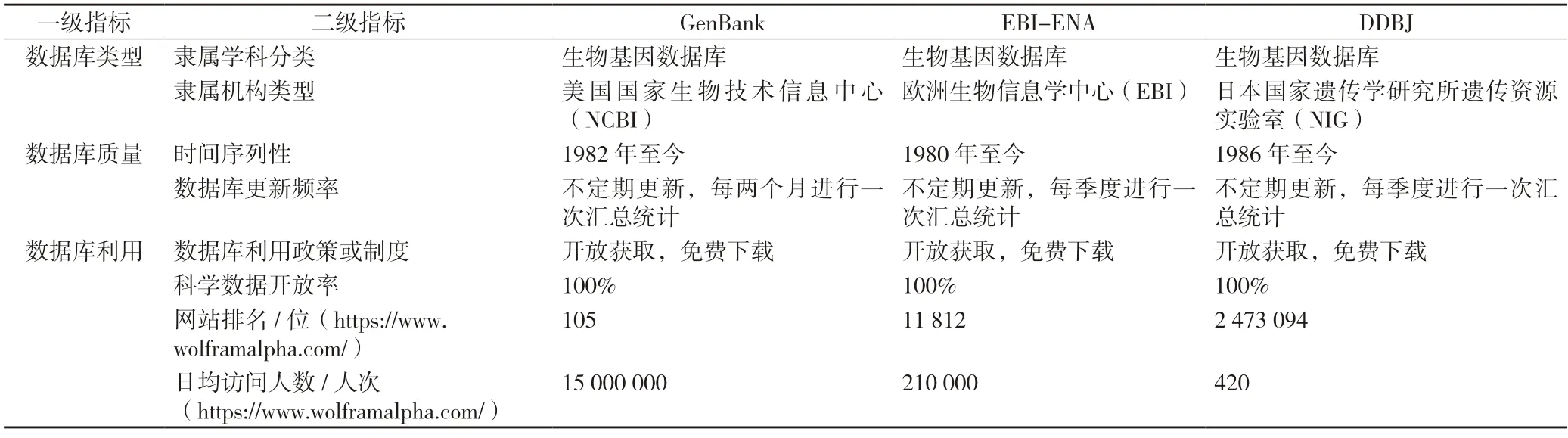
表1 国际三大核酸序列数据库主要数据资源情况
2.1.1 GenBank
美国GenBank 核酸序列数据库受到美国国立卫生研究院(National Institutes of Health,NIH)、美国国家生物技术信息中心以及基金会的支持,其隶属于美国国立卫生研究院,提供核酸数据的上传、使用和下载服务。美国国家生物技术信息中心隶属于美国国立卫生研究院下属国立医学图书馆(The United States National Library of Medicine,NLM),是由NLM 于1988 年建立,主要负责运维GenBank 数据库,提供基于GenBank 的检索和分析服务。1993年GenBank 开始接受直接提交的序列数据,数据主要来源于覆盖全球的实验室和大规模测序项目等[6](见图2)。2013 年,美国国立卫生研究院启动了“大数据向知识转化计划”(Big Data to Knowledge),将从多方面促进生物医学数据的共享与利用[7],因此该计划也在一定程度上推动了GenBank 的发展。

图2 美国GenBank 的组织体系和运行机制
2.1.2 EBI-ENA
1974 年,欧洲14 个国家加上亚洲的以色列共同建立了欧洲分子生物学实验室,该实验室随后建立了欧洲分子生物学实验室核酸序列库(EMBLBank),这也是世界上最早的核酸序列数据库,目的在于促进欧洲国家之间的合作来发展分子生物学基础研究。1992 年,欧洲议会决定在EMBLBank 的基础上建立欧洲生物信息研究所(European Bioinformatics Institute,EMBL-EBI)。1994 年EMBLEBI 于英国休斯顿正式成立,其经费主要来源于欧盟各成员国以及英国维康信托基金会(Wellcome Trust,WT)、美国国立卫生研究院、英国医学研究理事会(Medical Research Council,MRC)。EBI建立了欧洲生物信息研究所核酸档案库(European Nucleotide Archive,ENA),并负责该数据库的运维,其资金来源主要包括了欧洲委员会、英国生物技术和生物科学研究委员会(Biotechnology and Biological Sciences Research Council,BBSRC)和威康信托基金会。2008 至2015 年间,EBI 实施了由WT 资助的“千人基因组计划”(1000-Genome Project),主要目标就是寻找人类群体中出现频率至少为1%的遗传变异[7]。目前,EBI-ENA 为欧洲以及世界各个国家的科研人员提供免费公开的数据查询服务[8]。如图3 所示。

图3 EBI-ENA 的组织体系和运行机制
2.1.3 DDBJ
在欧洲EMBL 与美国GenBank 的邀请之下,1984 年日本成立了DNA 数据库,1987 年DDBJ 正式开始运行,由日本国立遗传学研究所遗传信息中心负责维护[10]。对DDBJ 提供审查和建议有两个机构:日本DNA 数据库咨询委员会(独立于NIG 的外部委员会)以及国际核酸序列数据库联盟INSDC 的咨询委员会IAC。DDBJ 是日本核酸序列数据库,也曾是亚洲唯一核酸序列数据库,其首先是反映日本所产生的DNA 数据,同时与GenBank 和ENA 合作,互通有无、同步更新。其具体发展历程如表2 所示。

表2 DDBJ 组织体系和发展历程
2.2 数据开放共享政策和知识产权保护
2.2.1 数据使用机制
国际核酸序列数据库联盟的数据库INSD 中的数据免费向公众提供,用户可不受限制访问其数据库中的所有数据记录,世界各地的科学家均可访问数据库记录来计划实验或发表任何分析或评论。用户可以检索数据应用于自己的研究,但根据数据共享的FAIR 原则(即可发现findable、可访问accessible、可互操作interoperable 和可重用reusable原则),引用INSDC 数据需标注标识号以保证原始数据提交者得到适当的认可。此外,INSD 不会在记录中附加限制访问数据、限制使用这些记录中的信息或禁止基于这些记录的某些类型的出版物的声明,任何序列数据记录中不会包含任何使用限制或许可要求,任何一方对数据库的再分发或使用都不会有任何限制或许可费用。
2.2.2 数据保密机制
由于部分数据提交者担心核酸序列数据库中一些待出版数据可能会对其成果造成影响,因此数据库会被要求在数据提交后的某一具体时间后再进行数据公开,但INSD 不会无限期持有数据但不出版。因此,对于数据提交者来说,其享有决定数据开放时间的权利,数据的所有权将一直归属于原始数据提供者;若需更新数据,仅允许数据的所有者或是被INSDC 批准的代表有权更新数据。此外,虽然数据库保存的是公共数据,但并非所有数据保密等级一致,数据公开性分为两个级别,即机密材料和公共数据。数据可用性的两个主要级别是数据在发布前保密和在公开发布后保密。
(1)机密资料。数据所有者可以在研究/项目注册期间提出,在所有者管理的发布日期或文献发表之前(以较早者为准)需要保密。在保密阶段,数据不会通过任何方式公开。
(2)公共数据。一个项目在达到指定的发布日期或在此日期之前就被出版物引用时,数据将自动发布成为公共数据。如果必须延长发布日期,数据所有者可以在数据公开之前延长其发布时间。
2.2.3 数据隐私机制
如果要提交人类基因序列数据到核酸序列数据库,研究者需要保证数据中不包含任何泄露个人隐私的信息。核酸序列数据库会假定所有数据提交者在提交数据之前已经明晰了必要的知情同意授权材料,如美国基因数据共享政策(Genomic Data Sharing Policy,GDS)就明确提出了在基因数据等共享过程中要尊重隐私和专利,充分发挥各机构审查委员会的审查作用[11]。
2.3 核酸序列数据库全生命周期科学数据管理模式
2.3.1 数据来源
GenBank 属于一级核酸序列库,它汇集并注释了所有公开的核苷酸序列和蛋白质序列,以及相关文献著作和生物学注释。根据GenBank 官网统计,大概每18 个月,其数据量翻一倍。GenBank 数据来源主要有2 种途径1):第一,测序工作者提交的序列、测序中心(如北京基因组研究所)提交的大量表达序列标签(express sequence tag,EST)、基因组勘测序列(genome survey sequences,GSS)[12],以及其他高通量数据。第二,与其他数据机构协作交换数据。通过与来自各个实验室递交的序列和同国际核酸序列数据库(ENA 和DDBJ)交换数据汇集数据。第三,美国专利商标局(United States Patent and Trademark Office,USPTO)提供的已发表的专利数据。GenBank会从已发表的专利中提取序列[13]。前两种数据都是源于测序工作者直接提交的测序数据,经审核后即可在数据库中公布。
欧洲生物信息研究所核酸档案库收存了欧洲大部分的核苷酸测序信息,包括原始测序数据、序列组装信息和功能注释。其数据来源于基因组测序中心、世界各地的研究人员、欧洲专利局直接提交的数据、大规模基因组测序项目以及与合作伙伴GenBank 和DDBJ 合作交换的数据[6],因此它也是一个较为全面的核酸序列数据库。除此之外,ENA也存储与核酸测序实验流程相关的信息,包括测序材料的分离与制备相关数据、测序仪器产生的数据以及随后的生物信息学分析流程数据等。
日本核酸序列数据库主要收集日本研究者的序列数据并为其赋予唯一标识号,不过DDBJ 也接受来全球研究者的研究数据[8]。2020 年,DDBJ 共接收了6 836 份经过审核认证的核苷酸序列,其中59.3%是由日本研究团队提交的。DDBJ 会定期以平面文件(flat file)发布所有公开的DDBJ/ENA/GenBank 核苷酸序列数据。2021 年6 月数据显示,国际核酸序列数据库联盟中包括2 830 321 188 个序列和15 093 100 107 909 个碱基对,DDBJ 为其贡献了3.39%的序列和2.23%的碱基对[13]。
2.3.2 数据结构
国际核酸序列数据库联盟围绕着数据描述、数据标识和数据分类制定了一系列的规范。1980 年,GenBank、EMBL 和DDBJ 共同设计了数据描述规范——特征表(feature table),方便在不同框架下对核酸序列的特征进行描述。实际应用过程中,三大数据中心在规范框架下制定了不同的格式来进行核酸序列数据的描述。以记录“AF000011”的核酸序列为例,检索结果如图4 所示[6],可以看出GenBank 和DDBJ 的表达形式是一致的,而ENA 则略有不同,但是在特征表的约束下,特征项(feature key)均是一致的,在此规范下能够保证不同数据库之间高效地交换共享(见图4)。
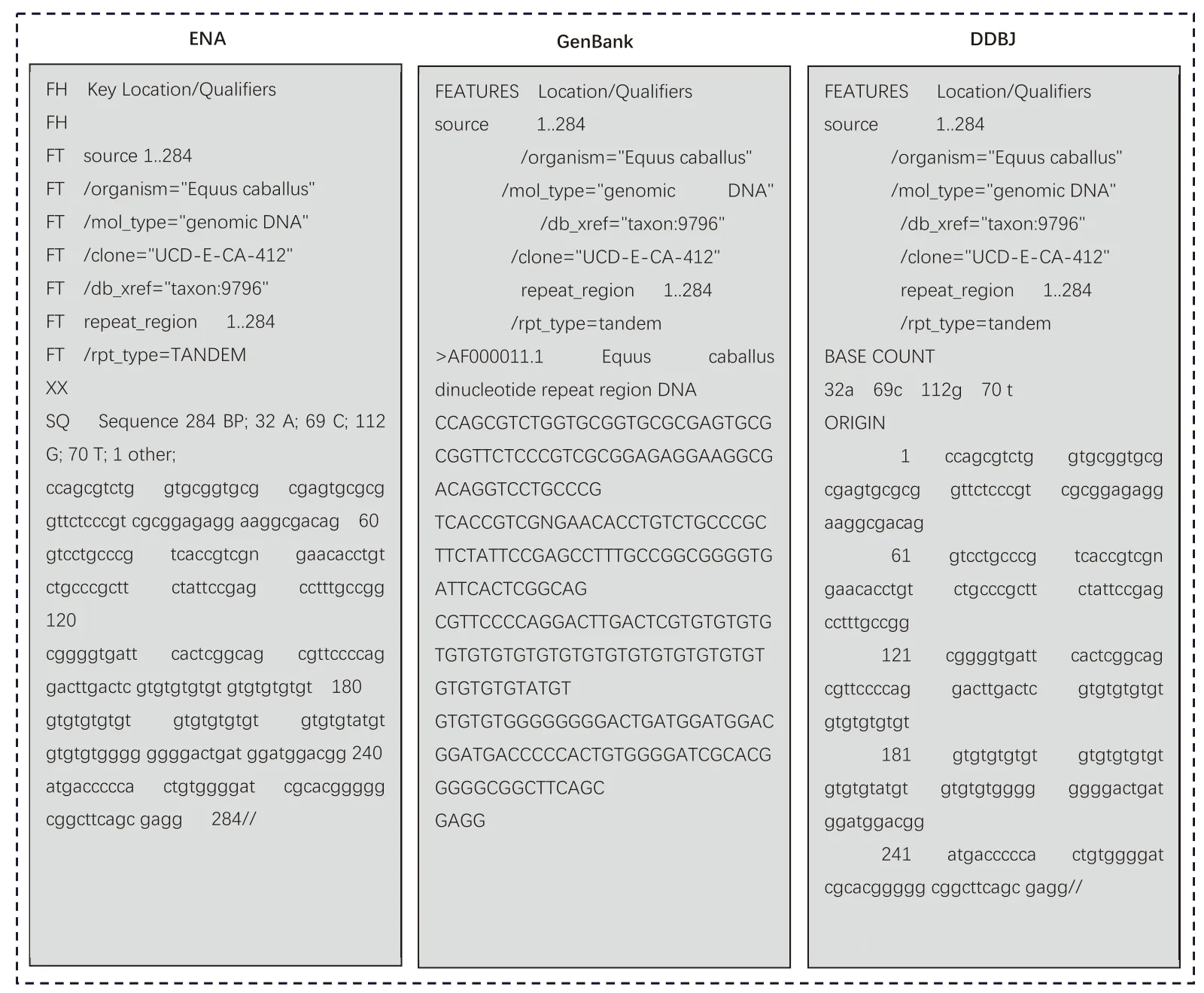
图4 GenBank、EMBL 和DDBJ 数据结构示例
2.3.3 数据处理
三大数据中心采用的数据处理流程基本一致。首先,有数据提交需求的研究人员通过指定的数据提交工具将基因序列上传,然后,审核人员对提交数据进行质量控制与审核,审核通过的数据将被赋予唯一记录号然后被存储,如GenBank 中的GI 标识符(gen info identifier number)就是国际性通用序列标识符,也是数据库在处理数据时为其分配的唯一ID 号[14]。数据开放时间由研究人员自行规定,研究人员需要在提交时就明确数据是立刻开放或者延迟开放,并说明指定时间。当数据库对数据进行公开后,用户即可通过检索系统获取数据。三大数据中心彼此之间建立信任机制,共同采用上述处理流程。以DDBJ 提供的服务为例,如图5 所示,图中:
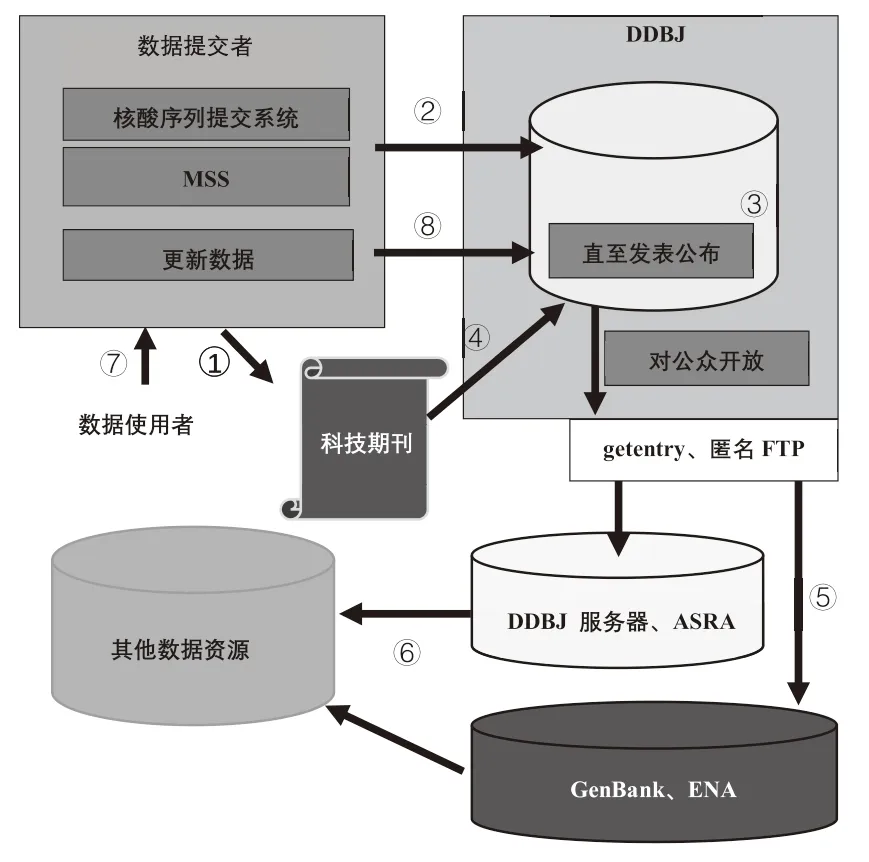
图5 DDBJ 的数据处理流程及数据服务
①向科技期刊提交论文。当作者向期刊投稿时,通常会将序列数据提交到DDBJ(ENA 或GenBank)获取登录号(accession numbers),即使没有论文待发表,也可以向DDBJ 提交序列数据。
②核酸序列提交。DDBJ 通过核酸序列提交系统或者批量上传序列系统(MSS)进行数据提交。在经过审核处理之后,DDBJ 会为每一个序列提供一个登录号。
③直到发表公布。在序列提交之后,数据提交者可以指定数据公布时间;如果提交者希望在论文发表之后再公布,可指定相应日期。
④公开序列数据。DDBJ 根据数据发布规则发布提交数据,当要求保留至论文发表的数据在论文出版之后将被公开。任何人都可以要求DDBJ 公开在已发表论文上登录号所对应的序列数据。
⑤查询序列数据。DDBJ 的数据最初通过getEntry 方式和匿名的文件传输协议(FTP)获取,后来获取方式扩展了ARSA 等网站,同时这些数据还将会与国际核酸序列数据库联盟其他成员共享。
⑥数据引用。许多生物数据库引用了DDBJ/ENA/GenBank 发布的数据。
⑦ 对于发布数据的反馈。如果用户对于发表的数据存疑,可以直接联系序列的提交者或者联系DDBJ 工作人员填写询问表格说明原因。
⑧数据更新。只有序列提交者可以对数据进行更新或者修改;在数据被修改之后,提交者仍可以选择数据公开的时间,但原则上并不能将数据状态恢复为非公开。
为保证数据能保持同步,GenBank、ENA 与DDBJ 每日交换最新数据,用户在任意一个数据库中均能获取最新数据[15]。其交换遵循如图6 所示模式,即机构之间的点对点交换。这种交换方式能够保证数据能够及时得到更新,联盟成员也能保存较为完整数据。具体来看,国际核酸序列数据库联盟体系下各成员的数据交换共享机制的特点可归纳为以下几点:
图6 GenBank、ENA 与 DDBJ 核酸序列数据交换模式
第一,数据共享以国际核酸序列数据库联盟为基础,由联盟委员会决定数据共享发展方向。委员会成员分别来自美、日、欧三方,能够代表各方立场并通过国际合作会议解决数据共享中存在问题,从而保障数据共享机制能够长期平稳运行[16]。
第二,共享机制的形成是由底层需求产生,从而促使上层联盟合作机制形成的过程,数据共享模式的形成从底层实践中抽象而成,因此具有较强可操作性[6]。
第三,任何研究者都可自由和不受限制地访问数据库中的所有数据记录[17],数据共享的保障机制根据需求不断进行调整,机构联盟设置专门委员会进行研讨,灵活应对出现的各种问题与挑战,从而保证合作的稳定性与可持续性。
3 国内外核酸序列数据库对比分析
1999 年中国加入“人类基因组计划”(1990—2003 年),至今已23 年。在这23 年里,中国实施过一些大型基因组学研究项目,但由于国际几大数据中心的领导地位,主流期刊要求论文作者将数据递交到几大数据库的规定,以及国内管理较为分散等原因,中国基因数据流失严重。同时,国内基因组学大数据管理共享机制不健全也带来了“数据孤岛”与“数据主权”的问题[18]。近些年来,国内各类生命健康大数据中心相继建成,具有代表性的有全国公安机关DNA 数据库、深圳国家基因库、上海生物医学大数据中心、国家人口与健康科学数据共享服务平台、北京基因组研究所生命与健康大数据中心(BIG Data Center,BIGD)以及国家基因组科学数据中心(NGDC)等。2018 年,生物数据领域权威期刊《核酸研究》(Nucleic Acids Research)将NGDC 列为与美国NCBI、欧洲EBI 齐名的全球核心数据中心[19]。NGDC 在成立之初就对标INSDC,总体目标是建成有国际影响力的基因组科学数据中心,促进科学数据开放共享,保障科学数据安全可控,支撑国家科技创新和经济社会发展。
3.1 核酸序列数据库多指标对比
作为国内国外生物核酸数据领域领先的数据服务机构,INSDC 与NGDC 在建设运营中既存在共性又各具特色,如表3 所示。

表3 国内外核酸序列数据库多指标对比
3.2 核酸序列数据库对比分析
针对以上指标对比情况,国内外核酸序列数据库存在的主要不同包括:
(1)平台组织架构。这4 个数据库都属于学术性、非盈利性质的数据服务机构,总体上讲,国外的资助机构比较多,资金支持比较雄厚,中国NGDC 的支持来源比较单一,目前主要依靠研究所资助,并在积极寻求资金资助。
(2)建设目标。三大数据中心进行了较为长期的国际合作,其宗旨和数据政策较为统一,均是为了提供并鼓励科学界访问最新和最全面的核酸序列信息,为全球研究者提供更好的服务;中国的核酸序列库除了上述目标之外,还肩负着完善建立中国人群基因组遗传变异图谱、形成中国人群精准医学信息库的重要使命。
(3)数据共享政策。INSDC 成员数据库中的数据全部免费对外开放,实行全部开放免费获取的政策,但是对于数据提交者另有要求的会进行差异性处理,对于有版权要求的数据可根据数据提交者要求时间进行公布,反映出其对于数据安全和作者版权的重视;中国NGDC 的一些数据需要用户进行申请获得审批后才能获取,这反映出NGDC 对于知识产权的重视,但同时这可能也对数据的获取造成一定的阻碍。
(4)数据资源与服务。关于核酸序列数据发布频率,INSDC 成员数据库定期发布最新版本,但频率有所不同;NGDC 暂未形成固定发布周期。在数据空间性方面,三大数据中心具有全球性的特点,涵盖了除本土之外的世界和其他地区;相较而言,NGDC 数据在空间上以则是以中国数据资源为主,兼顾全球。总体而言,三大数据中心空间覆盖范围更广,NGDC 数据库资源建设目前正在逐渐向全球化迈进,未来在国际数据资源整合引进上仍然有发展空间。
(5)国际合作。三大数据中心于20 世纪已经建立了坚实的合作关系,并建立了国际核酸数据库联盟,设置委员会对其国际合作进行专门管理,目前已经形成三足鼎立的态势;与之相比,NGDC 与阿拉伯和泰国的大学建立了国际合作关系,也作为唯一其他国家参与了INSDC 年度会议并做报告,国际影响力在不断增强。近年来,INSDC 与中国科研机构之间的合作交流也逐渐增多。
4 国际三大核酸序列数据库建设对中国的启示
作为国际上有影响力的DNA 序列数据库,GenBank、EBI-ENA、DDBJ 建设和管理过程对中国基因组学领域数据库建设具有很大的参考价值。综合以上对比分析,提出以下发展启示:
(1)从宏微观两层面制定核酸数据管理政策,宏观政策指导建立核酸序列数据管理总体框架,微观政策体现在数据中心的具体管理政策中。要在国家层面逐步完善关于基因组学领域科学数据共享与管理政策。美国于2014 年发布了基因组数据共享政策,旨在促进基因组数据共享,加快数据向知识、产品和流程的转化;中国虽已制订了《科学数据管理办法》等规范性文件,但针对基因组学领域科学数据管理规范仍然存在很大不足。其次,通过数据中心等微观管理主体制定基因组学领域科学数据的管理政策,有助于规范基因组学数据的开放获取服务,促进核酸序列数据的最大化利用[20]。
(2)加强核酸数据共享平台各部门分工和人才队伍建设。三大数据中心拥有跨学科的人才队伍,专业领域涵盖了生命科学、生物信息学、计算机科学、信息和图书馆学等多个方面,这些人员擅长的领域包括元数据和信息管理、软件开发、数据归档、基因组学研究以及跨学科研究等。鉴于此,中国的核酸序列数据中心在建设过程中应保证不同类型人才的专业分工与沟通协调。在人才培养方面,可以根据不同研究方向、领域数据类型的需要,开展跨学科交叉复合型人才的培养,建立起一个分工细致的高效率组织架构。
(3)开展精品数据库的开发与建设,拓展深加工数据资源。三大数据中心中都有一些引用量高、影响力比较大的子库,但通过对NGDC 各子库的考察可见,引用量排名靠前的库较少,如新型冠状病毒库下载量和引用量排在前列,但引用次数仅一百余次。因此,中国的基因组核酸数据中心可参考国外其他生物数据库在精品数据库建设方面的经验,对平台核心的数据产品进行深度挖掘,加强热点领域方向专题数据库建设。
(4)加强问题导向的基因组数据综合集成。中国人口众多、民族多样,各种与基因有关研究问题多而复杂,因此有必要加强以问题为导向的数据平台建设,通过打破学科界限,以高度综合的基因组科学研究对象为基础进行学术思想的整合集成,从而促使其与大型国际/国家科学计划相结合,并进一步促进数据的产生、集成和应用。同时,加强问题导向的数据资源整合集成也是目前中国基因组学领域科学数据资源管理的紧迫需求。
(5)加强数据服务能力建设,形成闭环全生命周期数据管理模式。包括GenBank 在内的核酸序列数据库均拥有多种数据检索、分析工具,且下载格式多样,兼容性较强;除通过网络平台提供数据服务外,三大数据中心还会提供培训服务,以方便研究人员充分利用数据库资源。因此,NGDC 在数据服务建设方面应当加强能力建设,为数据用户提供完善的“一站式”数据服务系统;其次,要充分利用依托部门资源,根据科研用户需求提供持续性的专业科学数据培训服务,同时促进领域内人才培养和交叉学科发展。
(6)从软硬件两方面入手优化数据库性能,同时重视核酸数据安全管理。可利用区块链、云计算、流计算等数据安全管理的特性和使用新的模式,提升大数据传输效率与存储能力。此外,可通过人工智能解决诸如资源调度、索引设计与优化等问题,机器学习等人工智能技术能以科学模型操作海量数据,提高处理效率。同时建立并完善核酸数据安全管理制度,配备齐全的物理设施进行数据存储备份,还可依托云平台建立云备份;对于重要数据采取物理存储隔离,对于特定用户还可采用虚拟专用网络(VPN)机制提供局域网数据服务。
(7)强化国际合作,关注国际数据资源建设。三大数据中心持续整合全球核酸序列数据,INSDC在空间性上具有全球性。NGDC 在发展过程中应进一步加强国际数据资源的交换,引进高质量国际数据资源,同时完善外文版网站建设以吸引国际用户提升自身的国际影响力。除此之外,还可通过颁布政策激励研究人员汇交数据形成良好的数据汇交生态,促进数据提交、储存、使用全流程的可持续发展,同时推进基础设施建设以提高数据储存分析能力。积极寻求国际合作扩大国际影响力,统一数据标准,方便数据交换共享。
5 结论
加强提升中国基因组科学数据中心的建设能力和国际化水平是提高中国包括基因组学在内的生命科学领域研究能力的关键。近年来,中国在各个层面都加强了科学数据中心的布局与建设,出台了一系列的办法规定。对于核酸数据中心发展过程中的规范化管理问题,本研究结合国际三大核酸序列数据库的经验与认识,对其进行剖析,从数据库的总体情况、运行管理机制、全生命周期科学数据管理模式等进行调研与分析,探讨了国际三大核酸序列库的数据处理流程特点及数据跨机构共享的实现过程,并通过4 个数据库的发展沿革、建设目标、建设概况等多维度的对比,总结出中国与国际三大核酸序列数据库不同的方面,进而提出开发建设精品数据库、加强问题导向的基因组数据综合集成等方面的启示建议。
此外,笔者还注意到,根据国际专门提供全站流量数据的Similarweb 网站统计,在访问美国NCBI官网查询数据的所有用户中,中国用户数量排名第6位;访问日本DNA 数据库DDBJ 的所有用户中,中国用户排在第3 位,占比为6.91%;而访问欧洲生物信息分子实验室EBI 网站中的中国研究者排名达到第2 位,约占11.83%。因此,习惯性使用NCBIGenBank、EBI-ENA 等数据库是否已经成为非欧美国家分子生物学研究者头上的达摩克利斯之剑?
另一方面,核酸数据安全也是中国参与国际科学数据共享的重要课题。根据2018 年中国《科学数据管理办法》规定,科学数据中心应当要保障科学数据安全,依法推动科学数据开放共享;同时,科技部下发的《人类遗传资源管理条例实施细则(征求意见稿)》拟规定不得向境外提供本国人类遗传资源,而人类遗传资源必然涉及到人类基因、基因组数据等人类遗传资源信息。因此,如何在保障中国基因数据安全的基础上进一步推进中国核酸序列数据的国际合作与开放共享,是中国相关基因数据中心需要思考和探索的问题。
注释:
1)基于2022 年6 月的数据。
