机器学习下半结构化文本信息抽取仿真
2023-03-29朱小龙
朱小龙,邱 林
(1. 荆楚理工学院计算机工程学院,湖北 荆门 448000;2. 湖北省荆门产业技术研究院智能信息技术研究所,湖北 荆门 448000;3. 长江大学计算机科学学院,湖北 荆州 434023)
1 引言
为了准确、高效地在海量信息中抽取特定的信息,需要一种自动化程度较高的计算机辅助工具。信息抽取系统的主要工作是在信息源中获取所需的信息,并向用户展示抽取的信息,将抽取的信息存储在数据库或电子表格中,方便后续工作的使用和分析[1,2]。目前针对半结构化文本的信息抽取算法较多,在各个领域中都得到了广泛的应用,但目前的信息抽取算法都存在一些问题。
赖娟[3]等人在规则约束的基础上构建深度学习网络模型,首先在模型的学习模块中输入数据,在多个维度上结合多头注意力机制和Bi-GRU网络生成单词对应的预测向量,利用规则库中存在的逻辑规则约束模型的深度学习,以此实现文本信息抽取,该算法没有对文本信息实行降维处理,对高维文本信息抽取的复杂度较高,导致算法存在信息抽取精度低、召回率低的问题。孙新[4]等人在CNN和LSTM自编码器的基础上建立短语向量模型,用于表示复杂短语的语义,针对候选短语,采用短语向量计算其对应的主体权重,对计算结果排序,完成文本信息的抽取,该算法的抽取结果与用户所需的信息之间存在差异,存在信息抽取准确率低的问题。陈珂[5]等人通过BERT预训练语言模型提取文本信息的特征,通过依存句法根据信息特征选取最短依存路径,在分类模型中输入最短依存路径完成文本信息的抽取,该方法抽取文本信息所用的时间较长,存在信息抽取效率低的问题。
为了解决上述方法中存在的问题,提出基于机器学习的半结构化文本信息抽取算法。
2 半结构化文本信息预处理
2.1 降维处理
基于机器学习的半结构化文本信息抽取算法通过自编码网络完成文本信息的降维处理,用低维信息代替高维信息,降低后续半结构化文本信息抽取的复杂度。用T={t1,…,tn}表示高维数据集,该数据集中共存在n个半结构化文本信息,将高维数据集T输入自编码网络中,获取对应的低维嵌套结构M。
自编码网络结构由两个部分构成,第一部分为编码网络,第二部分为解码网络[6]。编码网络的主要目的是在维数固定的低维嵌套结构中映射高维原始半结构化文本信息;可用编码网络的逆过程描述解码网络,其主要作用是还原低维嵌套结构中存在的半结构化文本信息,将其转化为高维数据。自编码网络的核心是码字层,存在于解码网络和编码网络之间的交叉部分,具有嵌套结构的高维半结构化文本数据集的本质规律可通过码字层得以描述,获取本质维数[7]。
采用自编码网络对半结构化文本信息处理的具体过程为:对编码网络和解码网络的权值实行初始化处理,遵循误差最小化原则训练自编码网络,半结构化文本信息依次经过解码和编码网络,在链式法则的基础上计算梯度值,根据计算结果调整自编码网络的权值。
所提算法在限制玻尔兹曼机连续形式CRBM的基础上完成连续数的建模,通过CRBM训练获得对应的权值,即编码网络和解码网络在自编码网络中的初始权值。在全局调整阶段中,利用反向传播算法完成权值的调整,实现半结构化文本信息的最佳重构。
设dj代表的是隐单元j在可视单元状态集{di}中的输出,可通过下式计算得到
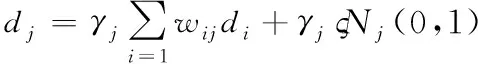
(1)
式中,wij代表的是CRBM的权值;函数γj的表达式为:

(2)
式中,ϑL、ϑH均描述的是渐近线中存在的点;参数sj对sigmoid曲线的斜率具有调整作用,属于噪声控制变量,当参数sj的值变大时,可以将无噪声的确定性状态平滑过渡到二进制随机状态。
高斯随机变量Nj(0,1)与常数ς构成噪声输入分量nj=ςNj(0,1),通过下式计算分量nj的概率分布:

(3)
为了降低半结构化文本信息降维的计算量,将最小化对比散度训练准则引入CRBM中,更新参数sj和权值wij:
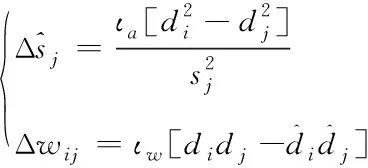
(4)

2.2 聚类处理
基于机器学习的半结构化文本信息抽取算法通过计算文本信息的单词间相似度和文本间相似度完成信息的聚类处理。
2.2.1 单词间相似度
考虑半结构化文本信息之间存在的关系类型,结合信息量和节点连接距离,通过下式计算父概念节点p和子概念节点c之间的连接权值wt(c,p)
×Y(c,p)[IC(c)-IC(p)]
(5)
IC(c)=log-1P(c)
(6)
式中,P(c)代表的是在语料库中出现概念c的概率。
用D(w1,w2)表示两个单词之间存在的语义距离,其计算公式如下
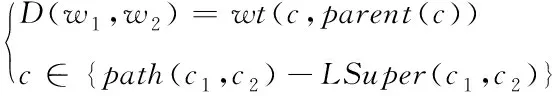
(7)
式中,c1=sen(w1)、c2=sen(w2),path(c1,c2)描述的是节点在c1、c2最短路径中构成的集合;parent(c)代表的是概念c对应的父概念;LSuper(c1,c2)代表的是上位概念。
各条边在最短路径中的权值和即为语义距离D(c1,c2)
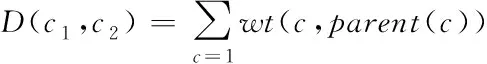
(8)
结合上述公式计算概念之间存在的距离D(c1,c2)
D(c1,c2)=IC(c1)+IC(c2)-2ICLSuper(c1,c2)
(9)
两个含义间语义距离的最小值即为单词间的语义距离D(w1,w2)
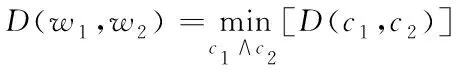
(10)
2.2.2 文本间的相似度
考虑每个概念在联合概念中的元素,用D(d1,d2)表示两个半结构化文本信息之间存在的语义距离[8,9],其计算公式如下
D(d1,d2)=D(C1∧…∧Ck,U1∧…∧Um)
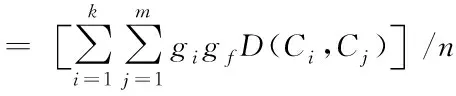
(11)
式中,Ci、Ui描述的是半结构化文本d1、d2的概念列表中存在的单词;gi代表的是半结构化文本d1中概念Ci出现的总数;k、m代表的是半结构化文本概念列表中存在的元组数;n描述的是概念语义在半结构化文本中存在的数量,可通过下式计算得到
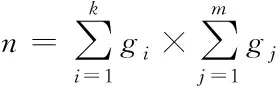
(12)
半结构化文本的语义相似度Sim(d1,d2)的计算公式如下
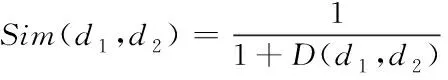
(13)
根据单词相似度和文本相似度完成半结构化文本信息的聚类处理。
3 半结构化文本信息抽取
通过上述过程完成半结构化文本信息的预处理,在不同类别的文本信息中基于机器学习的半结构化文本信息抽取算法通过隐马尔可夫模型[10,11]完成信息抽取,具体步骤如下
3.1 隐马尔可夫模型构建
采用隐马尔可夫模型实现半结构化文本信息抽取,首先学习训练文本,构建隐马尔可夫模型,通过EM算法[12,13]计算初始时刻各状态的概率ϖi
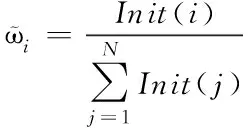
(14)
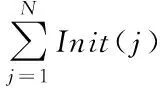
设aij代表的是状态为si的模型变为状态sj的概率,其计算公式如下
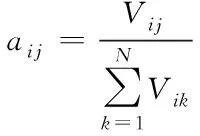
(15)
式中,Vij描述的是状态si变为状态sj的次数,根据上式计算结果构建状态转移概率矩阵A。
设bj(k)代表的是在状态sj下模型释放观察值bk的概率,其计算公式如下

(16)
式中,Rj(k)代表的是状态sj释放观察值bk的数量。根据上式计算结果构建观察值概率分布矩阵B。
通过数据平滑解决数据稀疏问题

(17)
式中,E代表的是词汇表的大小。
3.2 信息抽取的实现
采用隐马尔可夫模型[14,15]抽取半结构化文本信息的过程如下:
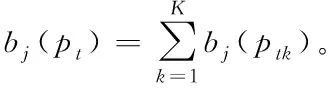
2)在半结构化文本序列P={p1,p2,…,pK}和给定模型λ=(A,B,ϖ)的条件下,通过半结构化文本中释放概率最大的最优状态序列,完成文本信息抽取:
①设εt(i)代表的是模型在路径中达到si状态并释放半结构化文本序列P={p1,p2,…,pK}对应的最大概率,对εt(i)实行初始化处理:εt(i)=ϖibi(pt);
②归纳模型达到si状态时经过的最大概率的路径ζt(j)
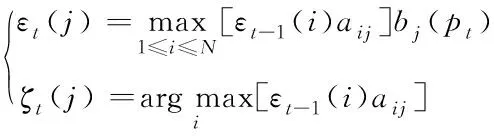
(18)
根据上述分析可知,将机器学习中的隐马尔可夫模型应用在不同的文本信息类别中,实现半结构化文本信息的抽取。
4 实验与分析
为了验证基于机器学习的半结构化文本信息抽取算法的整体有效性,需要对其做如下测试。
在加州大学欧文分校UCI的机器学习数据库中选取500篇论文,采用基于机器学习的半结构化文本信息抽取算法、文献[3]算法和文献[4]算法实行半结构化文本信息抽取测试。
按照文本结构将500篇论文划分为3个数据集,分别为数据集1、数据集2和数据集3,采用所提算法、文献[3]算法和文献[4]算法在上述数据集中抽取设定的信息数量,测试不同方法的信息抽取精度,测试结果如表1所示。
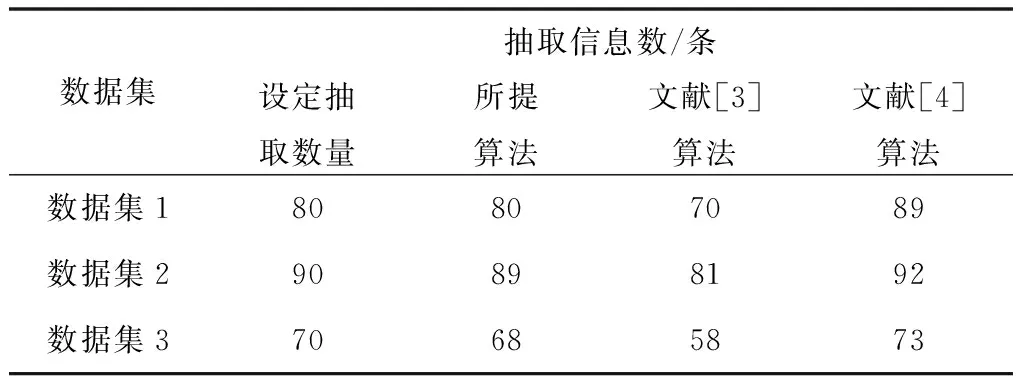
表1 信息抽取精度
由表1中的数据可知,设定在数据集1中抽取80条信息,在数据集2中抽取90条信息,在数据集3中抽取70条信息。分析测试结果可知,采用所提算法在3个数据集中抽取的信息数与设定的抽取数量基本相符,文献[3]算法的抽取数量总是低于设定的抽取数量,文献[4]算法与文献[3]算法相反,该算法抽取的数量总是高于设定的抽取数量。通过上述测试可知,所提算法可精准地抽取所需的信息数量。
将召回率Recall和准确率Precision作为测试指标,测试上述方法的抽取性能:

(19)
式中,X代表的是正确抽取半结构化文本信息的次数;Z代表的是半结构化文本信息没有被抽取到的次数;Y代表的是错误抽取半结构化文本信息的次数。
所提算法、文献[3]算法和文献[4]算法的召回率、准确率测试结果如图1所示。

图1 不同算法的召回率与准确率对比结果
由图1中的数据可知,所提算法的召回率均高于80%,准确率均高于90%,而文献[3]算法和文献[4]算法的召回率测试结果还是准确率测试结果均低于所提算法,验证了所提算法具有良好的抽取性能,因为所提算法在抽取半结构化文本信息之前对信息实行了降维处理,将高维原始数据转变为低维数据,降低了信息抽取的复杂度,进而提高了所提算法的信息抽取性能。
采用所提算法、文献[3]算法和文献[4]算法抽取半结构化文本信息,对比不同方法的抽取时间,测试结果如表2所示。

表2 不同方法的抽取时间
分析表2中的数据可知,所提算法、文献[3]算法和文献[4]算法的信息抽取时间随着信息数量的增加不断增加,在相同信息数量下,所提算法的抽取时间明显低于其 它两种算法的抽取时间,且所提算法的抽取时间增加幅度较低,验证了所提算法具有较高的信息抽取效率。
5 结束语
在信息爆炸背景下,人们开始研究信息抽取技术,以便在海量的信息中抽取用户所需的信息。目前信息抽取算法存在抽取精度低、召回率低、准确率低和抽取效率低的问题,提出基于机器学习的半结构化文本信息抽取算法,该算法通过信息降维处理,降低了算法的复杂性,进而提高了算法的整体性能,减少了抽取信息所用的时间。
