基于长短期记忆的稀疏数据过滤推荐算法
2023-03-29佘学兵刘承启
佘学兵,熊 蕾,黄 丽,刘承启
(1. 江西科技学院信息工程学院,江西 南昌 330098;2. 南昌大学网络中心,江西 南昌 330031)
1 引言
过滤推荐算法是为了帮助受众群体精准地获得所需信息,但在实际应用过程中,常存在由于用户对于某个项目的浏览信息过少导致推荐效率下降、匹配度降低的问题[1],所以如何通过稀疏数据进行过滤推荐是目前亟需解决的问题之一[2]。
朱元[3]等人首先建立异构信息网络后构造用户属性权重矩阵,然后在此基础上采用模糊贴近度算法对元路径属性权重进行估计,并找到其最近的邻居,最后通过Top-N分析法进行过滤推荐。田保军[4]等人通过CFMTS将获取到的全局和局部信息值加入过滤推荐算法中,将CFMTS与PMF相结合建立推荐模型,采用梯度下降法计算用户和项目特征向量从而完成过滤推荐。贾俊杰[5]等人将数据按照信任度进行划分得到用户间显式信任值,结合用户评分可信度、隐式和显式信任值获取专家信任因子完成稀疏数据的过滤推荐。以上方法没有综合考虑用户的整体评分特征和不同项目的单独评分对于数据补全产生的影响,存在MAE值和RMSE值大、F1值小的问题。
为了解决上述方法中存在的问题,提出基于长短期记忆的稀疏数据过滤推荐算法。
2 云模型数据填充
2.1 云模型
用期望Ex、熵En和超熵He对云数据特征进行整体表征,称其为云的特征向量[6],用C(Ex,En,He)表示,设样本方差用S2表示,样本均值用X表示,得到Ex、En和He的计算公式如下
(1)
2.2 相似性度量

为了综合考虑用户的整体评分特征和不同项目的单独评分,避免结果有效性不佳的问题,基于长短期记忆的稀疏数据过滤推荐算法采用相关因子对相似性进行计算,设两个不同用户i和j对于同一项目进行评分的总数用xi,j表示,权衡系数用λ表示,不同用户对同一项目进行评分的数目越多,对应的λ越大,得到相关因子Φ(xi,j)=1-1/2λxi,j,由相关因子公式可以看出,随着xi,j的增大,Φ(xi,j)的值也随之增大,得到的最终填充项数据也越准确。若Φ(xi,j)大于由用户根据数据集决定的指定值,则对用户相似度进行计算。
2.3 云模型数据填充算法
云模型通过用户评分寻找相似用户并补全缺失项目评分,具体计算步骤如下:
1)采用逆向云算法结合用户评分项对目标用户特征向量进行计算。
2)寻找需要补全的评分数据缺失项,计算目标用户与其他用户之间的Φ(xi,j),若满足条件,则对用户相似性进行计算。
3)结合计算得到的相似性数据建立用户相似列表,获取该用户最近的K个邻居。
4)根据获取到的K个邻居评分情况,通过加权平均算法和Φ(xi,j)进行考虑,对用户的缺失的评分项进行计算。
将用户评分项和余弦距离相结合获取用户相似度和相关因子[9],通过用户i最近的K个邻居对其没有评分的项目I1进行评分补全,补全方法依据相似性原则和加权平均算法,设用户i的邻居u对于项目I1的评分用ru,1表示,i的K个邻居用Ngb(i)表示,i的总评分均值用Si表示,u的总评分均值用Su表示,i与u的相似度用sim(i,u)表示,i与u的相关因子用Φ(xi,u)表示,得到补全用户评分项Si1的计算公式如下所示[10]
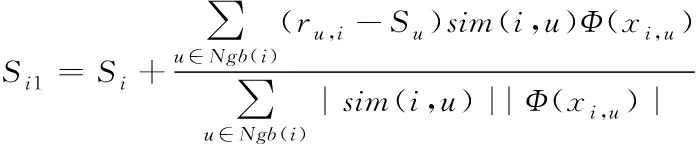
(2)
通过式(2),将稀疏数据中缺失部分进行补全。
3 基于长短期记忆的稀疏数据过滤推荐算法
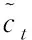
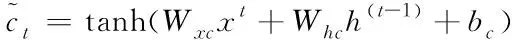
(3)
设t时刻输入门的状态值用i(t)表示,x(t)、h(t-1)和t-1时刻记忆单元候选值c(t-1)对i(t)产生影响,对应的权值用Wxi、Whi和Wci表示,得到i(t)计算方式如下
i(t)=σ(Wxixt+Whih(t-1)+Wcic(t-1)+bi)
(4)
设t时刻遗忘门状态值用f(t)表示,对应的权值用Wxf、Whf和Wcf表示,遗忘门的作用是避免历史信息对记忆单元产生影响[12],f(t)计算方式如下
f(t)=σ(Wxfxt+Whfh(t-1)+Wcfc(t-1)+bf)
(5)
设t时刻记忆单元的状态值用c(t)表示,⊗是点积计算,得到c(t)的计算方式如下
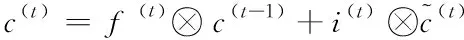
(6)
设用来调控t时刻记忆单元状态的输出状态值用o(t)表示,对应的权值用Wxo、Who和Wco表示,σ是sigmoid函数,得到o(t)的计算方式如下
o(t)=σ(Wxox(t-1)+Whoh(t-1)+Wcoc(t-1)+bo)
(7)
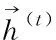
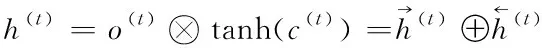
(8)
LSTM的结构分为以下几层:
1)输入层
通过对应项目的描述文档获取所需数据,添加到输入层中。
2)Embedding层
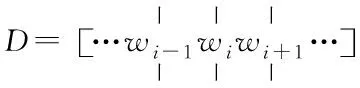
3)LSTM层
LSTM层的作用是获取上下文的特征,将序列D输入至LSTM层中,设ci表示上下文特征的分量,W表示LSTM层的网络权重,ci受到W和wi的共同影响,网络偏置用b表示,得到ci和上下文的特征C的计算方式如下

(9)
4)线性层
利用线性层优异的非线性映射能力对LSTM输出的非线性特征组合处理,即在向量空间中采用简易权重对非线性组合特征进行学习[14]。设线性层权重用Wl表示,偏置用bl表示,得到线性层的输出lo=tanh(Wl*C+bl)。
5)Dropout层
Dropout层在对网络进行训练时通过预先设定的概率值达到控制神经元输出的作用,促使每次网络训练使用的数据特征只为全部数据特征中的一部分,在线性层后接入Dropout层可以避免过度拟合的问题[15]。
设概率值为1-p的二值向量用mask表示,以线性层的输出lo作为Dropout层的输入,得到Dropout层输出y如下所示
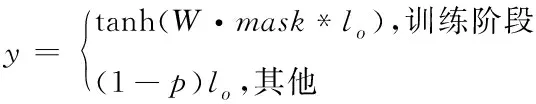
(10)
6)输出层
以项目隐形特征向量S作为输出层结果,设输出层权重用Wo表示,输出层偏置用bo表示,得到输出层结果S=tanh(Wo*lo+bo)。
以项目行文档为输入,设全部权重用W′表示,行文档子项用xj表示,得到文档隐向量Sj=LSTM(W′,Xj)
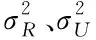
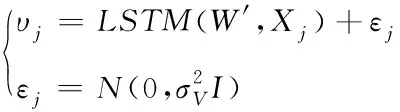
(11)

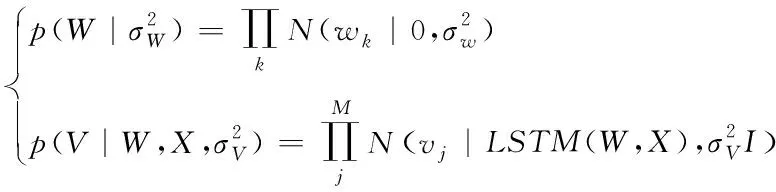
(12)
通过MAP对用户和项目的隐式特征向量进行求解,LSTM网络权值和偏置如下
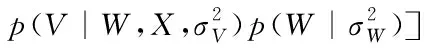
(13)
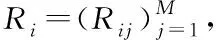
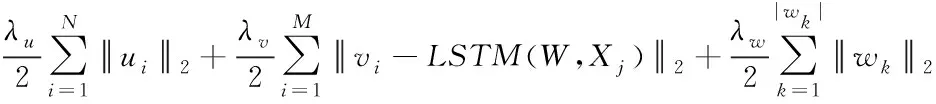
(14)
定义W、V(或U)为常数,简单优化函数Γ即可看作二次函数,通过Γ可求解V(或U)的最优解ui和vi
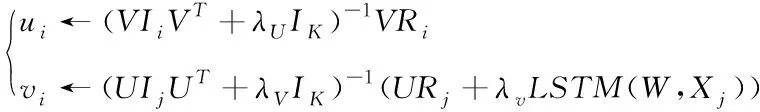
(15)
但由于W受到网络结构的影响,无法通过U和V的方式求解,因此引入L2正规化方差函数求解Γ,得到W的方差ε(W)并用BP算法求解,计算方式如下
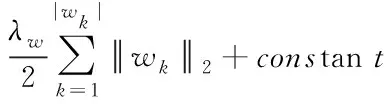
(16)
因为W、V、U交替更新,所以在收敛前进行重复优化,直至得到最优W、V、U,得到稀疏数据过滤推荐算法模型rij
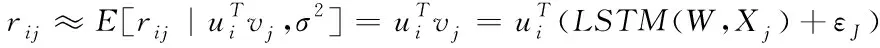
(17)
通过模型rij,完成基于长短期记忆的稀疏数据过滤推荐。
4 实验与结果
为了验证基于长短期记忆的稀疏数据过滤推荐算法的有效性,需要对该算法进行测试。
4.1 MAE
将平均绝对误差(MAE)作为测试指标对所提方法、文献[3]方法和文献[4]方法进行检验,MAE值越小,则对应的过滤推荐算法推荐效果越好。MAE测试结果如图1所示。
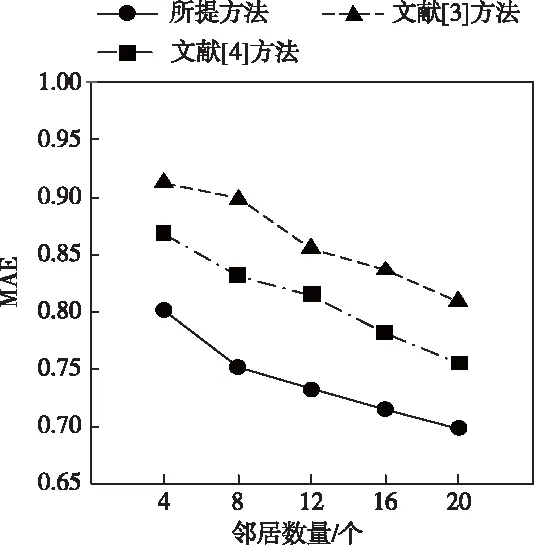
图1 MAE测试结果
根据图1分析可知,在邻居数量不同的情况下,所提方法的推荐效果明显优于文献[3]方法和文献[4]方法,因为所提方法结合用户的整体评分特征和对不同项目的单独评分进行了综合考虑,引入相关因子对相似性进行计算,避免结果有效性不佳的问题,使所提方法对稀疏数据的过滤推荐效果更好。
4.2 RMSE
采用均方根误差(RMSE)对所提方法、文献[3]方法和文献[4]方法进行检验,RMSE值越小,则对应的过滤推荐算法的推荐精确度越高。得到RMSE测试结果如图2所示.
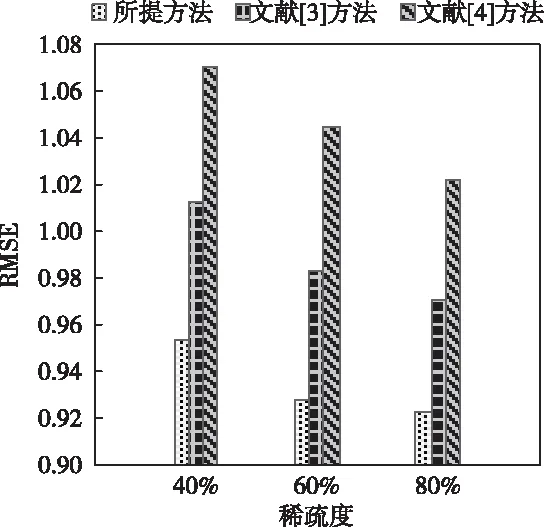
图2 RMSE测试结果
由图2可以看出,采用所提方法、文献[3]方法和文献[4]方法对稀疏数据进行过滤推荐时,所提方法的RMSE均小于文献[3]方法和文献[4]方法,在稀疏度为40%时,所提方法、文献[3]方法和文献[4]方法的RMSE值都比较高,但所提方法仍然远低于文献[3]方法和文献[4]方法,说明所提方法的过滤推荐精确度越高。
4.3 F1值
将Recall和Precision的调和值F1作为指标对所提方法、文献[3]方法和文献[4]方法进行检验,设总用户集中用户i的推荐项目集合用R(i)表示,用户i在测试集中真实参与的项目集合用T(i)表示,Recall、Precision和F1值计算方式如下
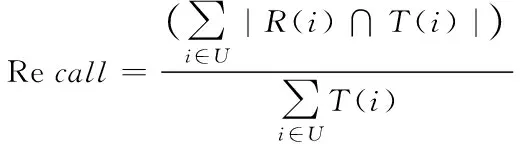
(18)
(19)

(20)
采用训练比率为变量对所提方法、文献[3]方法和文献[4]方法进行测试,测试结果如图3所示。

图3 F1测试结果
根据图3可以看出,采用所提方法、文献[3]方法和文献[4]方法对稀疏数据进行过滤推荐时,随着训练比率的升高,所提方法、文献[3]方法和文献[4]方法的F1值均有降低,但所提方法的F1值始终高于文献[3]方法和文献[4]方法,F1值可用来均衡表示Recall和Precision的变化情况,F1值越大,过滤推荐越准确,即对应方法在实际中的应用更为有效。
5 结束语
随着互联网信息技术的飞速发展,多样化的信息充斥在人们的周围,信息逐渐由匮乏走向冗余,用户在享受海量信息带来的便利同时也受到信息过载的困扰。目前稀疏数据过滤推荐算法存在MAE值和RMSE值大、F1值小问题,因此提出基于长短期记忆的稀疏数据过滤推荐算法,通过云模型计算相似度将稀疏数据进行补全,对补全后数据构造长短期记忆网络,生成稀疏数据过滤推荐算法模型,从而完成对稀疏数据的过滤推荐。实验表明所提方法MAE值和RMSE值更小、F1值更大,为未来对长短期记忆有效应用并进行稀疏数据的准确过滤推荐奠定基础。
