嵌入重评分机制的自然场景文本检测方法
2023-03-29刘艳丽王毅宏程晶晶
刘艳丽,王毅宏,张 恒,程晶晶
(1. 上海电机学院电子信息学院,上海 201306;2. 华东交通大学信息工程学院,江西 南昌 330000)
1 引言
自然场景文本是指存在于任意自然情境下的文本内容,例如广告牌、商品包装、商场指示牌等。近年来,基于深度学习的自然场景文本检测与识别方法快速发展,广泛应用于智能机器人、无人驾驶等领域,并成为当下研究热点。与文档图像中的文本不同,自然场景中的文本检测与识别方法主要存在以下三方面挑战:①自然场景图像背景复杂、存在类文本目标如窗户或栅栏等;②图像本文在字体大小、排列方向、文本稀疏程度等方面有很大的差异性;③自然场景图像中文本上存在光照强度不均衡、拍照角度不统一等干扰因素。
为了应对上述挑战,大量基于深度学习的自然场景文本识别方法被提出。其中,文本检测与文本识别的研究大部分是分开处理的,文本检测阶段通过训练有素的检测器从原始图像中定位文本区域。现有的文本检测方法主要包括以下几种:基于区域建议的方法、基于语义分割的方法、基于区域建议和语义分割的方法。如文献[1]提出一种基于笔画角度变换和宽度特征的自然场景文本检测方法;文献[2]提出了嵌入注意力机制的自然场景文本检测方法。文献[3]中提出通过语义分割检测多方向场景文本。相比于水平或多方向场景的文本检测,针对自然场景中的任意形状文本的检测方法不多。文本识别阶段的主要任务是对定位好的文字区域进行识别,现有的文本识别技术主要包括以下几种:基于朴素卷积神经网络的方法、基与时序特征分类的方法、基于编码器和解码器的方法。如文献[4]中使用卷积神经网络和循环神经网络对图像特征提取,用连接时序分类(connectionist temporal classification,CTC)输出识别的序列;文献[5]中提出通过注意力机制的序列到序列模型来识别场景文本。
虽然基于文本检测加文本识别的方法看似简单有效,但检测性能无法达到最佳,因为检测和识别阶段是高度相关的:检测质量的高低决定了识别的准确率、识别结果可以给检测阶段提供信息反馈,纠正检测误差。针对该问题,端到端的文本识别框架[6-8]被提出。如文献[9,10]等将实例分割应用于文本检测与识别。

图1 场景文本检测与识别
基于实例分割的方法解决了图像文本形式多样的问题,并且可以从不同干扰因素下定位文本。但是检测效果受到自然场景图像背景复杂、各种噪声的影响,极易导致文本检测出现大量假阳性样本和不完整检测等,如图1(c)所示。
在实例分割任务中,文本掩膜的质量分数被量化为文本分类的置信度。然而真实文本掩膜的质量分数为实例掩膜与其对应的地面真值的IoU(Intersection over Union),通常与文本分类分数相关性不强。如图1(d)所示,实例分割得到精确的文本框以及该文本框对应的高分类置信度scls,然而文本分类置信度scls与文本掩膜置信度smask存在一定差异。使用文本分类的置信度来衡量文本掩膜的质量是不恰当的,因为文本分类置信度仅用于区分文本类别,而不知道文本掩膜的实际质量和完整性,从而在一定程度上导致自然场景文本检测出现大量假阳性样本。
为了解决文本检测假阳性问题,本文提出嵌入重评分机制的自然场景文本检测方法。该方法在实例分割网络(Mask R-CNN)的基础上进行改进,实现了对自然场景中多方向、不规则文本的检测。具体来说,本文方法首先参考实例分割中利用预测的掩膜与地面真值之间的像素级别IoU来描述实例分割质量,提出一种学习掩膜交并比网络;其次通过引入重评分机制,将文本语义类别信息与文本掩膜完整性信息相结合,矫正真实文本掩膜质量与文本掩膜置信度之间的偏差,提高文本检测与实例分割的精确性。总之,本文的主要内容如下:
1) 使用实例分割网络检测自然场景中的文本,兼顾自然场景中规则文本与不规则文本的检测,并通过FPN融合深层、浅层CNN语义信息,兼顾小尺度文本与大尺度文本的检测,提升召回率。
2) 设计重评分机制,通过学习预测掩膜的分数,将预测得到的掩膜分数与文本分类分数相结合,重新评估文本掩模的质量,提升实例分割的准确性,保证检测文本的完整,进一步提高召回率。
3) 在三个文本检测与识别模型常用的数据集ICDAR2013、ICDAR2015和Total-Text进行对比试验从而分析、评估本文方法。
2 嵌入重评分机制的文本检测网络
本文方法以Mask R-CNN[11]为基础网络架构,如图2所示。包括:用于提取图像特征的特征金字塔网络FPN[12]、用于生成文本区域建议的区域建议网络RPN[13]、用于边界框回归的Fast R-CNN[13]、用于文本分割和字符分割的Mask Head分支、用于字符掩膜评分的重评分模块。
2.1 CNN特征提取
自然场景中的文本复杂多样,存在不同的尺寸,而不同尺寸的文本对应着不同的特征。低层特征的语义信息较少,但目标位置准确,有利于检测小尺寸的文本框;高层的特征语义信息较为丰富,但是目标位置比较粗略,有利于检测大尺度的文本框。针对该问题,本文在CNN特征提取模块使用了FPN,以ResNet-101为骨干网络,如图3所示。对于在单尺度的图像输入,FPN使用自顶向下的体系结构来融合不同分辨率的特性。图中{C2,C3,C4,C5}分别表示ResNet-101中的conv2_x、conv3_x、conv4_x、conv5_x层,经过FPN处理计算得到特征层集合表示为fi={f2,f3,f4,f5,f6},计算公式如下所示

(1)
其中,Upsample(.)表示步长为2的上采样,MaxPool(.)表示最大值池化计算;由于fi的每一层均会作为RPN的输入并完成回归与分类计算,所以Convi(.)为1×1卷积模板的卷积层,并约束fi的通道数为256。通过深层特征的上采样与浅层特征进行融合,在顾及小尺度目标检测的同时,增强对大尺度目标的感知,一定程度上提升文本检测召回率。
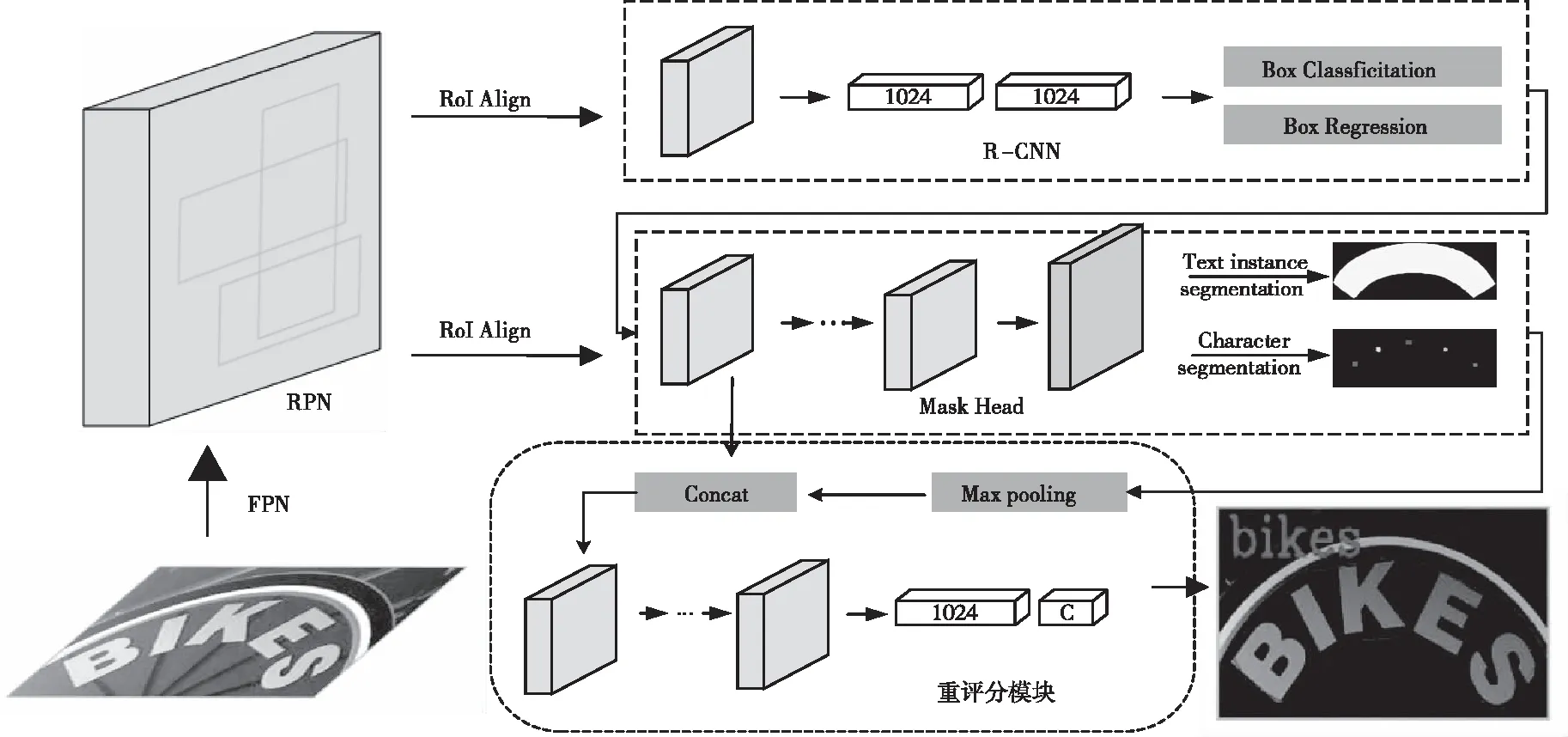
图2 本文方法流程图
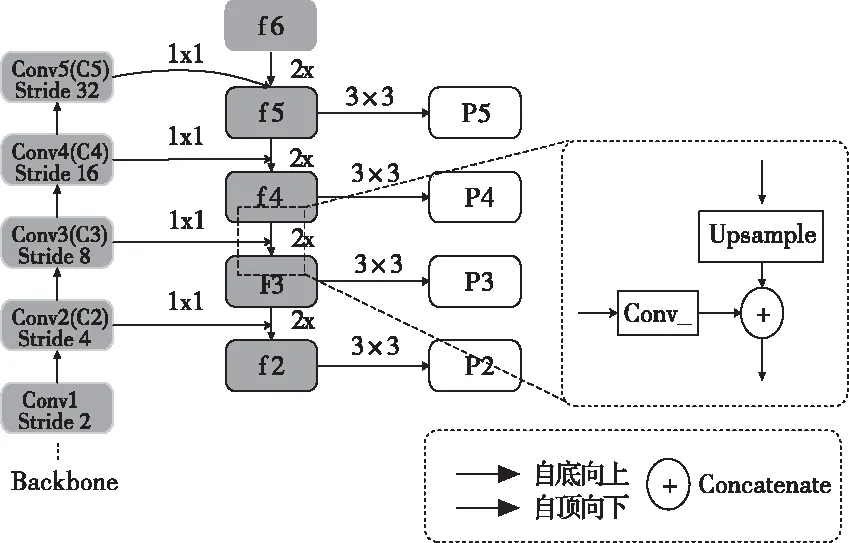
图3 特征金字塔网络
2.2 文本区域建议与边界框回归
候选区域生成网络(Region Proposal Network,RPN)为后续的Fast R-CNN和Mask分支生成文本候选区域(ROIs)起到关键的作用。针对自然场景中的文本大小不一致、方向不统一等问题,RPN网络参考FPN[12],根据锚的大小在不同阶段分配锚。具体来说,在{P2,P3,P4,P5,P6}五个阶段把锚的面积分别设置为{322,642,1282,2562,5122}像素,其次参考文献[13],在不同的阶段把锚的长宽比设置为(0.5,1,2)。同样的,本文方法采用RoI Align[11]对RPN生成的边界框的特征进行统一表示,相比于RoI池化,RoI Align保留了更准确的位置信息,提升了生成掩膜的精度,这对于掩膜分支中的分割任务相当重要。
Fast R-CNN分支的输入由RoI Align根据RPN提出的文本区域建议生成,主要任务包括:边界框分类和边界框回归,其主要目的是为检测到的文本区域提供更加准确的位置信息。Fast R-CNN将文本检测视为分类问题,首先利用已经获得的建议区域对应的深度特征,通过全连接层与Softmax函数计算得到每个区域建议属于什么类别(文本、背景),输出类别概率向量;其次通过回归文本边界框获取文本区域建议的位置偏移量,用于回归更加精确的文本检测框。
3 嵌入重评分模块
3.1 重评分机制
一般情况下,经过RPN生成的得分高的ROIs中存在大量非文本实例即负样本。因而在对文本、非文本分类的同时,过滤更多的非文本区域,有助于提升正样本的准确性,生成更准确的ROIs。本文方法将文本实例特征与其对应的预测掩膜结合起来学习,提出引入重评分机制的自然场景文本检测方法,如图4所示。
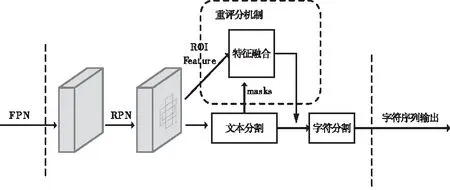
图4 重评分机制
首先,在传统实例分割任务中,虽然输出结果是文本掩膜,但对掩膜打分却是和文本边界框检测共享的,是针对文本区域分类置信度计算出来的分数,该分数和文本分割掩膜的质量未必一致,用来评价文本掩膜的质量可能出现偏差。文本掩膜的质量由文本预测的掩膜与该文本对应的地面真值之间的像素IoU来描述,本文方法设计直接学习文本掩膜IoU的网络,通过将预测的文本掩膜分数与分类分数相乘,重新评估文本掩模置信度,最终文本掩模置信度将同时考虑文本语义类别信息与文本掩膜的完整性信息。
Smask表示文本掩膜置信度,理想的Smask量化为预测的文本掩膜和其对应的地面真实掩膜的交并比。其中每一个文本掩膜只属于一类,且Smask对有地面真值的类别只可能有正值,对于其它的类别的得分为零。本文方法将学习任务分为掩膜分类和MaskIoU回归,所有对象类别表示为:Smask=Scls×Siou。其中Scls专注于掩膜分类,已在MaskHead分支阶段的分类任务中完成,从而专注于掩膜交并比回归的Siou将作为重评分模块的主要任务。
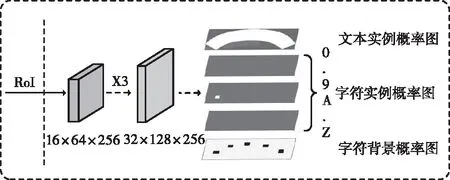
图5 Mask Head结构图
Mask Head分支主要负责三项任务:文本实例分割、字符实例分割和文本序列识别,如图5所示。输入一个大小为16×64的ROI特征,连续经过三个卷积层和一个反卷积层后,输出38份概率图,包括文本实例概率图、字符(包含字符和数字)实例概率图、字符背景概率图。其中,文本概率图用于预测矩形区域中的文本实例区域,不同的字符实例概率图用于预测矩形区域中不同字符区域;字符背景概率图用于预测矩形区域中非文本区域。
为了将预测的字符图解码为字符序列,文本采用像素投票算法首先对背景图进行二值化,其值从0到1,阈值为0.75;然后根据二值化图中的连接区域获得所有字符区域;计算所有字符图每个区域的平均值;平均值可以看作是区域的字符分类概率,它可以看作字符的置信度,平均值最大的字符类将分配给该区域。具体过程如算法1所示。然后,根据英语的书写习惯将所有字符从左到右进行分组。
算法1 像素投票
输入:背景B,字符图C
1)在二值化背景图上生成连通域R
2)S←∅
3) for r in R do
4) score←∅
5) for c in C do
6) mean=Average(c[r])
7) score←scores+mean
8) S←S+Argmax(scores)
9) return S
3.2 掩膜预测
重评分模块的主要任务是将预测的文本掩膜与其对应真实文本掩膜之间IoU进行回归。如图6所示。
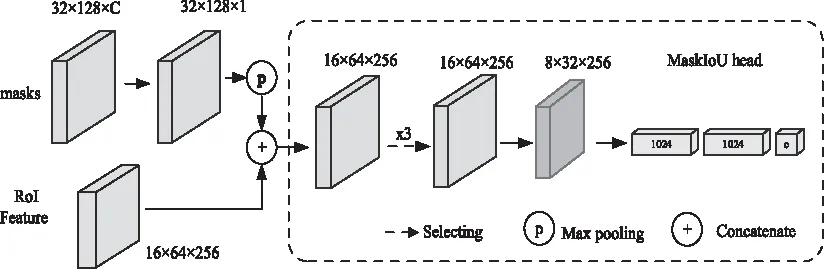
图6 特征融合模块
在重评分模块中,将RoI Align层的特征和预测的掩膜连接起来作为该网络的输入。在连接时,使用卷积核大小为2、步长2的最大池化层使得预测的掩膜与RoI相同的空间尺寸。对于地面真值类,网络中只选择返回MaskIoU,而不是所有的类。重评分网络由4个卷积层和3个全连接层组成。对于4个卷积层,将所有卷积层的核大小设置为3,滤波器个数设置为256。对于3个全连接层,前两个全连接层的输出设置为1024,最后一个全连接层的输出设置为类别的数量。
3.3 文本标签的生成
本文方法在训练阶段输入图像的地面真值由以下部分组成:P={p1,p2…pm}和C={C1=(cc1,cl1),C2=(cc2,cl2),…,Cn=(ccn,cln)},其中pi表示的是文本实例区域,由一个多边形框构成。ccj和clj分别代表了字符像素对应的位置与类别。首先用最小的水平矩形来覆盖多边形,然后遵循Faster R-CNN中的方法为RPN网络和Fast R-CNN网络生成目标。其中地面真值P、C以及RPN提供的建议区域为Mask Head生成两种类型的目标:用于预测矩形区域中文本实例区域的文本概率图和用于预测矩形区域中不同字符区域的字符实例概率图。给定建议区域r,Mask Head参考文献[13]的匹配机制获得最佳水平矩形,相应的文本实例区域和字符区域进一步得到。然后将匹配的多边形和字符框移动并调整大小来对齐建议区域,目标地图的 的计算根据以下公式
Bx=(Bx0-min(rx))×W/(max(rx)-min(rx))
(2)
By=(By0-min(ry))×H/(max(ry)-min(ry))
(3)
其中(Bx,By)和(Bx0,By0)分别表示的是更新后的多边形顶点和原始多边形顶点。(rx,ry)是提议r的顶点。之后,在初始化为零的遮罩上规范化多边形并填充多边形区域值为1。字符实例的生成如下:通过固定字符边界框的中心点并将其边缩短到原始边的四分之一来缩小所有字符边界框,将缩小字符边界框中的像素值设置为其相应的类别索引,将缩小字符边界框之外的像素值设置为0,如果没有字符边框批注,则所有值都设置为-1。
3.4 损失函数
本文方法是多任务的,依据MaskR-CNN中损失函数的设计思路,本文方法加入全局文本实例分割损失和字符分割损失。损失函数如下
L=Lrpn+α1Lcls+α2Lbox+α3Lglobal+α4Lchar
(4)
其中Lrpn、Lcls和Lbox是RPN和FastR-CNN的损失函数,Lglobal和Lchar参考文献[9],表示实例分割损失和字符分割损失。
+(1-yn)×log(1-S(xn))]
(5)
对于Lglobal,N表示全局文本地图的像素总数,yn(yn∈(0,1))代表像素标签,xn表示输出N的像素。
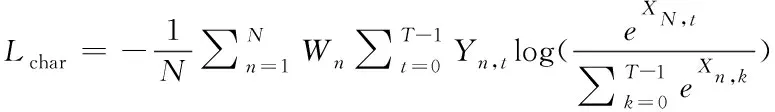
(6)
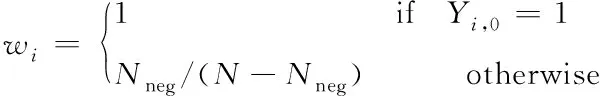
(7)
对于Lchar,T表示类别数,N表示每张地图的像素数,其中输出的地图X可以看作为一个N×T的矩阵。其中Y对应于地面真值X,权重W用于平衡字符类和背景类的损失值,Nneg表示背景像素的数量,其权重可以通过式(7)计算得出。
4 实验与分析
了验证本文方法的性能,该模型在ICDAR2013、ICDAR2015和Total-Text三个数据集上进行实验。其中ICDAR2013和ICDAR2015是主要的线性文本检测与识别数据集,Total-text为弯曲文本检测与识别的重要数据集。
4.1 数据集
1)Synth-Text:该数据集是一个合成的数据集,包括大约80K张图片。在数据集中大部分文本实例都是多方向的。
2)ICDAR2013:该数据集是2013年ICDAR 举行的稳健阅读竞赛(robust reading competition,简称RRC)所提供的公共数据集。数据集的图片包含路标、书籍封面和广告牌等清晰的场景文本(focused scene text)图片,专注于水平文本的检测与识别,如图7所示。
3)ICDAR2015:该数据集是2015年ICDAR在RRC中增加的偶然场景文本(incidental scene text)阅读竞赛提供的公共数据集,数据集是由 Google Glass 在未聚焦的情况下随机拍摄的街头或者商场图片,旨在帮助文本检测和识别模型提高泛化性能,如图8所示。
4)Total-Text:弯曲的文字是一个很容易被忽视的问题,Total-Text是一个针对曲线文本检测的公开数据集,数据集图片中包含商业标识、标志入口等现实生活场景中的弯曲文本。该与ICDAR数据集不同,该数据集有大量面向曲线的文本和多方向的文本,如图9所示。
4.2 实验指标
目前文本检测性能主要包括3个评价指标:召回率(Recall,R)、准确率(Precision,P)和综合评价指标(F-Measure,F),如式(8)(9)(10)。此外,利用表征检测速度的参数即每秒传输帧数(Frames Per Second,FPS)作为效率参考标准。

(8)
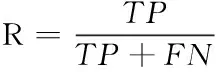
(9)
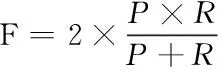
(10)
其中TP、FP和FN分别代表的是命中框的数量、错误框的数量和遗漏框的数量。文本识别的评估方式分为两类:End-to-End 和Word Spotting,其中End-to-End 表示检测并识别图像中的文本,Word Spotting 表示检测并识别词汇表单词(将图像中包含非法字符的文本视为无关文本)。与文本识别类似,端到端的文本识别任务提供3种不同的约束词汇表:
1)Strong(S):每张图像的强语境词汇表(100个单词),包括图像中的所有单词以及从训练或测试集的其余部分选择的干扰词。
2)Weak(W):包括训练和测试集中所有单词的弱语境词汇表。
3)Generic(G):源自Jaderberg等人的数据集,大约 90k 单词的通用词汇表。
4.3 实验细节
文本识别的训练方法大多使用两个不同的模块来训练样本即文本检测与文本识别,或者使用交替训练的方式。本文方法的所有子网络都以端到端的形式训练。整个训练步骤包括两步:在Synth-Text数据集中与训练和在真实单词数据集中调整。
在训练阶中,首先采用小批量迭代法训练,mini-batch设置为8,并且将所有输入图像的短边调整为800像素,同时保持图片方向不变。其中RPN和Fast R-CNN的batch-size设置为256和512,每张图片正负样本比设为1:3。在Mask Head分支中batch-size设置为16。在微调阶段,由于缺乏真实样本,因此采用了数据扩充和多尺度训练技术,具体地说,对于数据增强,将输入的图片随机旋转到某个角度范围,然后加入一些其它增强技巧,如随机修改色调、亮度、对比度等。在多尺度训练中,输入图像的短边随机调整为三个尺度600、800、1000。另外,使用额外的1162张来自文献[14]的用于字符检测的图像作为训练样本,mini-batch保持为8,且在每一个mini-batch中,Synth-Text、ICDAR2013、ICDAR2015、Total-Text和额外图像的不同数据集的采样比例分别设置为4:1:1:1:1。
使用SGD优化本文模型,在预训练阶段,训练模型进行180k次迭代,初始学习率为0.005,在120k次迭代时,学习率衰减到十分之一。在微调阶段,初始学习率设置为0.001,在60k迭代时降低到0.0001,微调过程在80k迭代结束。

图7 ICDAR2013数据集

图8 ICDAR2015数据集
4.4 实验分析
在测试阶段,针对自然场景中的水平文本、多方向文本和不规则文本,本文方法分别在ICDAR2013、ICDAR2015和Total-Text数据集上评估它的性能,用准确率(P)、召回率(R)、综合评价指标(F)和检测时间(帧/秒,FPS)评价该方法的性能,S、W、G分别表示Strong、Weak、Generic三种不同的约束词汇表,最优结果用黑体加粗标注,实验结果如图(10-12)所示。
1)水平文本
针对水平文本,实验中输入图像的短边长度统一设置为1000像素,其次将本文模型与5个检测器进行比较,包括Textboxes[15]、Deep TextSpotter[16]、Li et al.[17]、Mask TextSpotter[9],Text Perceptron[7],对比结果如表1和表2所示。

图9 Total-text数据集
即使只是在单尺度上检测,本文方法在准确率、召回率和综合评价三个指标下均优于之前提出的一些方法[7,9],达到了95.1%,90.9%,92.9%。尤其在召回率方面,超出最先进的检测模型Mask TextSpotter1.4%,在保证检测效果的同时,本文方法的时间损耗同样良好,FPS为2.9。如表2所示,在数据集ICDAR2013的识别测试中,基于End-to-End的评估方式下,本文方法的文本识别性能在Strong、Weak、Generic三种不同的约束词汇表中均优于其它先进的模型,综合指标分别达到了94.8%、92.1%、88.7%。
2)多方向文本
针对多方向文本,实验中输入图像的短边长度统一设置为1600像素,其次将本文方法与5个检测器进行比较,包括TextSpotter[18]、StradVision[19]、Deep TextSpotter[16]、Mask TextSpotter[9]、Text Perceptron[7],对比结果如表1和表3所示。

表1 在数据集ICDAR2013和ICDAR2015上文本检测结果
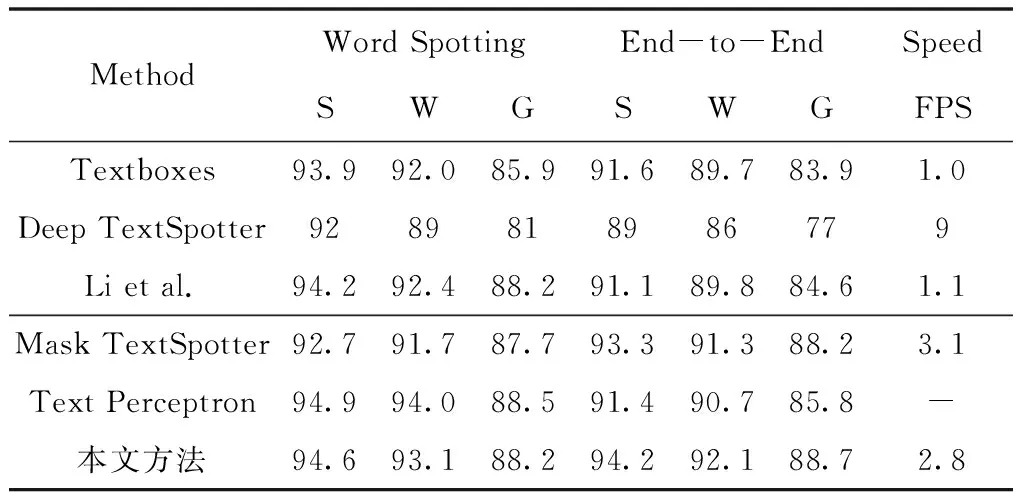
表2 ICDAR2013数据集评估结果
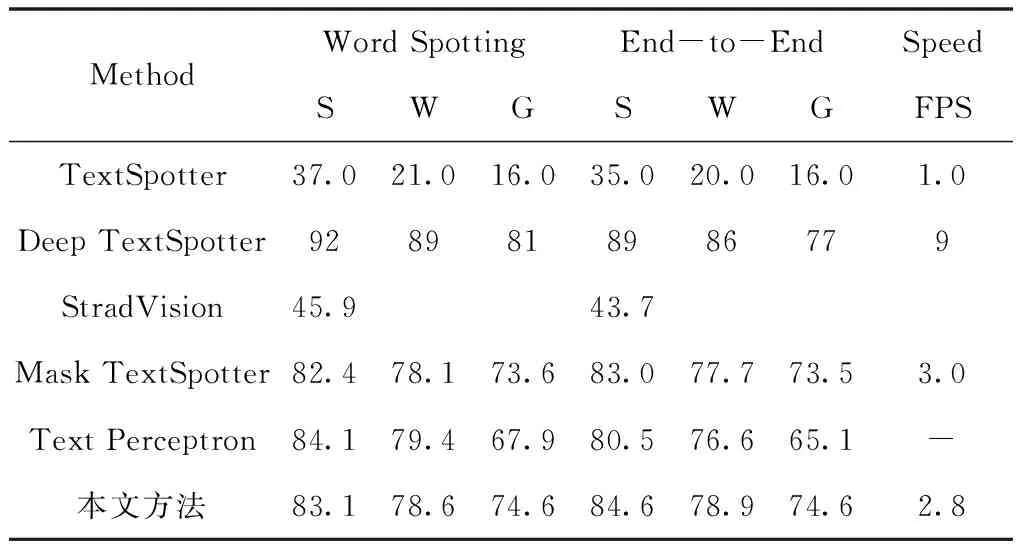
表3 ICDAR2015数据集评估结果
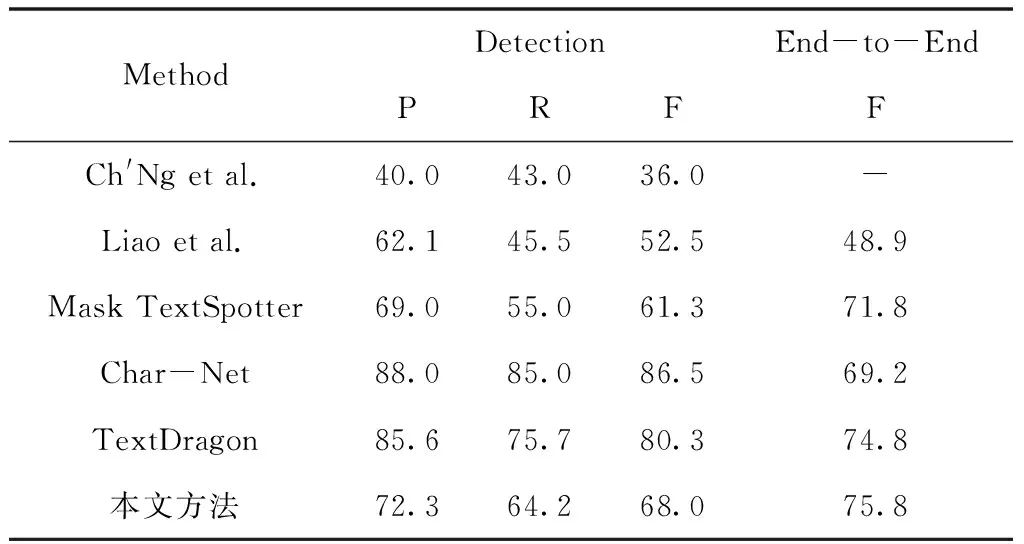
表4 Total-Text数据集上的评估结果

图10 ICDAR 2013数据集上的文本检测与识别可视化结果

图11 ICDAR 2015数据集上的文本检测与识别的可视化结果

图12 Total-Text数据集上文本检测与识别的可视化结果
在召回率方面,本文方法比最先进的Mask TextSpotter的87.3%还有所提升,召回率达到了90.6%。如表3所示,在数据集ICDAR2015的识别测试中,基于End-to-End的评估方式下,指标比之前的网络都要优秀,综合指标达到了84.6%,78.9%和74.6%。
3)不规则文本
针对不规则文本,实验中输入图像的短边长度统一设置为1000像素,然后将本文方法与5个检测器进行比较,包括Ch′Ng et al.[20]、Liao et al.[15]、Mask TextSpotter[9],Char-Net[21],TextDragon[8],对比结果如表4所示。结果表明本文方法在不规则文本的检测与识别上表现更优异,准确率、召回率、平均调和都有显著性提高。虽然本文方法在检测方面的性能次于最先进的文本检测模型Char-Net[21],但是文中网络的综合指标是表现最好的网路之一,基于端到端的评估方式下,相较于Char-Net[21]提高了6.6%,比表现最优的TextDragon[8]高出1%,综合指标达到了75.8%。
4.5 消融实验对比分析
为了说明本文方法设计的每个模块对最终结果是否为正相关,本文将进行消融实验加以验证。本文以Mask R-CNN为基础框架,引入FPN以满足适合各尺度文本检测要求;针对自然场景中文本内容检测不完整、假阳性等问题,提出重评分机制。
消融实验在Total-Text数据集进行,从Mask R-CNN开始逐步融合各个模块并计算出对应的准确率、召回率与F值,实验结果如表5所示。实验过程其它参数均保持一致。
通过表5发现,FPN网路中加入{P6}层,使本文方法召回率和F值分别提高了3.2%和1.6%,但准确率下降了2.3%,经分析由于{P6}层的增加扩大了模型的感受野,使得更多较大的文本得到检测,但{P6}也会相对应地增加干扰区域导致准确率下降;最后完整地使用FPN网络与特征融合网络,通过重新评估文本掩膜的质量使得文本区域减少各种因素的干扰。准确率、召回率和F值分别达到72.3%、64.2%和68.0%。

表5 消融实验结果
检测结果与对比图如图13所示,可以发现本文方法可以完整地检测到文本区域,且未出现漏检;对比其它模型的检测结果,本文检测到的文本区域更加精确、更加贴合实际的文本边界。综上所述,可见文本检测准确度的提高主要来源于更精确的定位输出,即使用FPN结构使得小文本得到一定程度检测,而文本检测召回率的提高主要来源于对字符掩膜的评分,正确的评分带来更加准确的文本检测。

图13 消融实验可视化结果
5 结束语
本文提出了嵌入重评分机制的自然场景文本检测方法,一个用于自然场景文本检测与识别的端到端网络。它在复杂多变的背景下可以高效的检测出文本并分割出字符。与近些提出的文本识别模型相比,本文模型训练简单,识别速率快,且有能力检测与识别自然场景中的不规则文本。在展开的实验中,该模型在水平文本、多方向文本、不规则文本等数据集上都取得了优异的表现,提高了识别准确率的同时还大幅度降低了假阳性,在文本检测和端到端识别方面展现出了高效率与鲁棒性。在未来的工作中,将尝试优化该模型来提高文本检测的速率以实现在现实生活中的应用,其次,针对现阶段该模型只能够处理英文文本,探索中文文本的识别也是一项重要的工作。
