基于改进DenseNet的驾驶行为识别
2023-03-29周晓华武文博
周晓华,武文博
(广西科技大学电气与信息工程学院,广西柳州545616)
1 引言
世界卫生组织发布的《2018年道路安全全球状况报告》显示,每年约有135万人死于道路交通事故,道路交通伤害成为5~29岁儿童和年轻人的主要死因,而驾车时使用手机比专心驾驶发生碰撞的风险高出约4倍[1]。文献显示,80%的撞击事故和65%的追尾事故是分心驾驶所导致的[2]。文献[3]的调查报告中显示,频繁使用电话和进行其它次要任务会严重影响驾驶安全。巴西的一项自然主义驾驶研究证明了使用电话时的车速较低,司机受到电话干扰[4]。有效解决司机分心驾驶问题的一种方案是对司机驾驶行为进行实时监测,正确识别驾驶行为就是本文的研究重点。搭建一个可以实时识别驾驶行为的模型,通过检测司机的分心行为,对其做出警告或做出干预,可以大大减少交通事故的发生。此外,驾驶行为识别还可以用于分析司机驾驶意图,为全自动驾驶功能的实现做出铺垫。
早期的学者们使用传感器来检测驾驶员的分心驾驶行为[5-7],这种检测方法虽然足够准确,但传感器等设备对驾驶员造成的干扰本身已经影响了安全驾驶,所以这种依赖传感器的检测方法没有得到发展。随着图像处理领域的技术突破,学者们将目光转向机器学习和深度学习领域。文献[8]使用Hough算法,监测驾驶员头部姿态和车辆的偏航率,进而建立起二者的模糊隶属度关系,由此来判断司机当前驾驶状态。文献[9]提出了一种基于Faster-RCNN的驾驶行为监测模型,通过识别驾驶员手中是否存在手机来确定是否在安全驾驶状态。文献[10]使用图卷积网络,对驾驶员的姿态图进行特征提取,同时融合关键物体对驾驶员分心行为进行识别,在StateFarm公开的驾驶行为数据集上取得了90%的准确率。文献[11]对VGG-16网络进行了改进,提出的模型可以识别出驾驶员为什么发生分心,取得了较高的识别精度。文献[12]设计了一种级联网络模型,以VGG网络为核心对特征进行提取,通过迁移学习重新训练分类器,达到了93.3%的识别准确率。
目前,驾驶行为识别领域的研究虽然已经取得了一定的成果,但驾驶行为种类繁多而诸多研究主要关注在司机打电话、发短信等与手机有关的行为上,针对其它如喝水等行为的识别还没有较好的结果。为解决此问题,本文在DenseNet的基础上进行改进,使用StateFarm公开的驾驶行为数据集进行训练,并取得了理想的识别效果。
2 原理介绍
2.1 DenseNet
随着卷积神经网络(Convolutional Neural Networks,CNN)研究的进展,计算机视觉(Computer Vision,CV)领域也取得了新的突破,CNN的性能较于传统的机器学习算法具有较大的优势。2012年ImageNet大赛冠军得主提出的AlexNet[13]模型将CNN模型推向了新的高度,作者使用了5个卷积层和3个池化层搭建的CNN模型标志着深度神经网络时代的开始。CNN领域的另一重大突破是ResNet[14]模型的出现,作者提出的“短路连结”使得训练中的梯度易于反向传播,进而可以训练出更深的网络。在这一思路的基础上,文献[15]提出了DenseNet模型。与ResNet模型不同的是,DenseNet模型的后层是与所有前层连结的。DenseNet模型巧妙地将特征在通道上连接以实现特征复用,从而大大减少了需要计算的参数量和计算成本。DenseNet模型网络结构如图1所示,主要由卷积层、dense block、transition layer、池化层和全连接层构成,通过使用不同个数的dense block和transition layer进行级联,就可以组成不同层数的DenseNet。

图1 DenseNet整体结构图

图2 denseblock结构图
其中,dense block是DenseNet的核心模块,其结构如图2所示。
xl=Hl([x0,x1,…,xl-1])
(1)
式中,Hl(·)代表非线性转化操作,它由BN(Batch Normalization)层、ReLU函数和3×3的卷积操作构成。虽然denseblock的设计可以将特征更为完整的传递到每一层,但在通道维度上大量使用拼接操作会使特征图的通道数大量增加,严重拖慢模型运行效率,Hl(·)操作就是通过特征降维的方式将维度数量降低以减轻网络的负担。
在图1中,denseblock与Transitionlayer相连的目的是把复用的特征图大小降低,以此来进一步提升模型的性能。Transitionlayer中有一个大小为1的卷积核和一个平均池化层,并且定义参数θ,表示将denseblock输出的特征图数量减少至原始值的θ倍,通常将其取值为0.5。本文以DenseNet-169作为baseline模型,其配置信息如表1所示。

表1 baseline模型配置信息表
2.2 通道注意力
文献[16]的作者将关注点放在不同通道的特征关系上进行了研究,文中构建了一个新的模块单元——SE(Squzee & Excitation)block,通过建立不同通道之间的关系,自发地校准通道维度上的特征响应。其结构如图3所示。
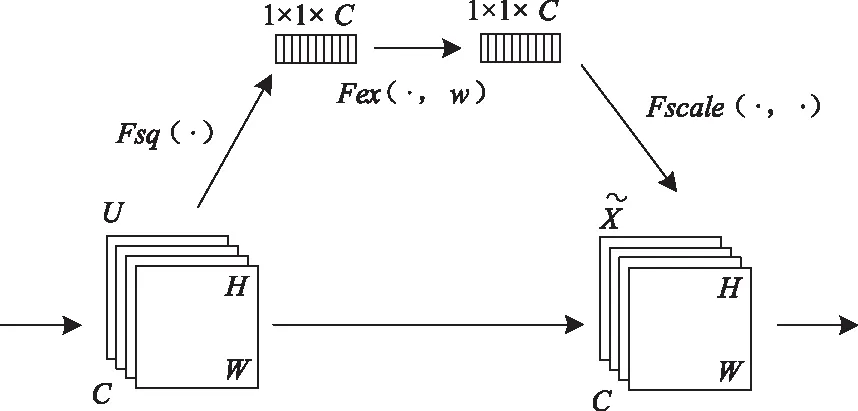
图3 SE模块结构图
图3中,给SE block一个通道数为C的输入U,然后通过三个操作来对其特征进行重标定。首先,在空间维度上对特征进行压缩,将其变成一个实数,这个实数在某种程度上有着全局感受野,它代表了一个通道上特征响应的全局分布。此操作可由式(2)表示,z表示U压缩至空间维数的统计量,z∈RC,U∈RH×W×C。

(2)
然后,对压缩所得的C个实数进行激励操作,这个操作与CNN网络中的门机制类似,通过训练w参数来学习每个特征通道之间的相关性,为每个特征通道生成相应的权重。此操作可由式(3)表示,s为经过sigmoid激活后的激励参数。
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(3)

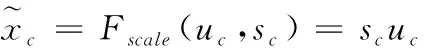
(4)
3 基于改进DenseNet的驾驶行为识别
3.1 数据集及预处理
本文所使用的数据来自StateFarm公司公开的驾驶行为数据集[17],该数据集中包含了来自不同肤色不同性别驾驶员的10个类别的驾驶行为。数据集中每个类别约有2000个样本,共计23500张图片,尺寸均为640×480。将其80%划分为训练集,另外20%平分为验证集和测试集。为方便模型处理,使用编号c0-c9将10种驾驶行为标记,其类别描述如表2所示。

表2 类别描述
为扩充数据集和防止出现过拟合现象,使用图像增强技术对样本进行处理。将样本随机地进行水平翻转、旋转15°、亮度增强、对比度增强、缩放等操作来扩展数据集。部分处理后的图像如图4所示。

图4 一张样本增强后的部分扩增图像
3.2 驾驶行为识别模型改进
为提升模型对于细微差异的识别能力,引入通道注意力机制对其进行改进。使用1.2小节所提到的SE block可以使驾驶行为识别模型能够关注到不同通道之间特征的关系。文献[16]在对ResNet的改进过程中尝试了4种不同的改进方式,分别为:将SE block添加在残差块之后、残差块之前,与残差块并行放置和放置在残差网络最后。实验结果显示并行放置时模型的top-1错误率最低,而放置在残差块之前时模型的top-5错误率最低。据此,本文将设计三种改进方案进行实验对比。将SE模块放置在dense block循环尾部,记为SE-standard模型;将SE模块放置在dense block循环起始,记为SE-PRE模型;将SE模型放置dense block与transition layer之间,记为SE-POST模型。改进前后的方案如图5所示。
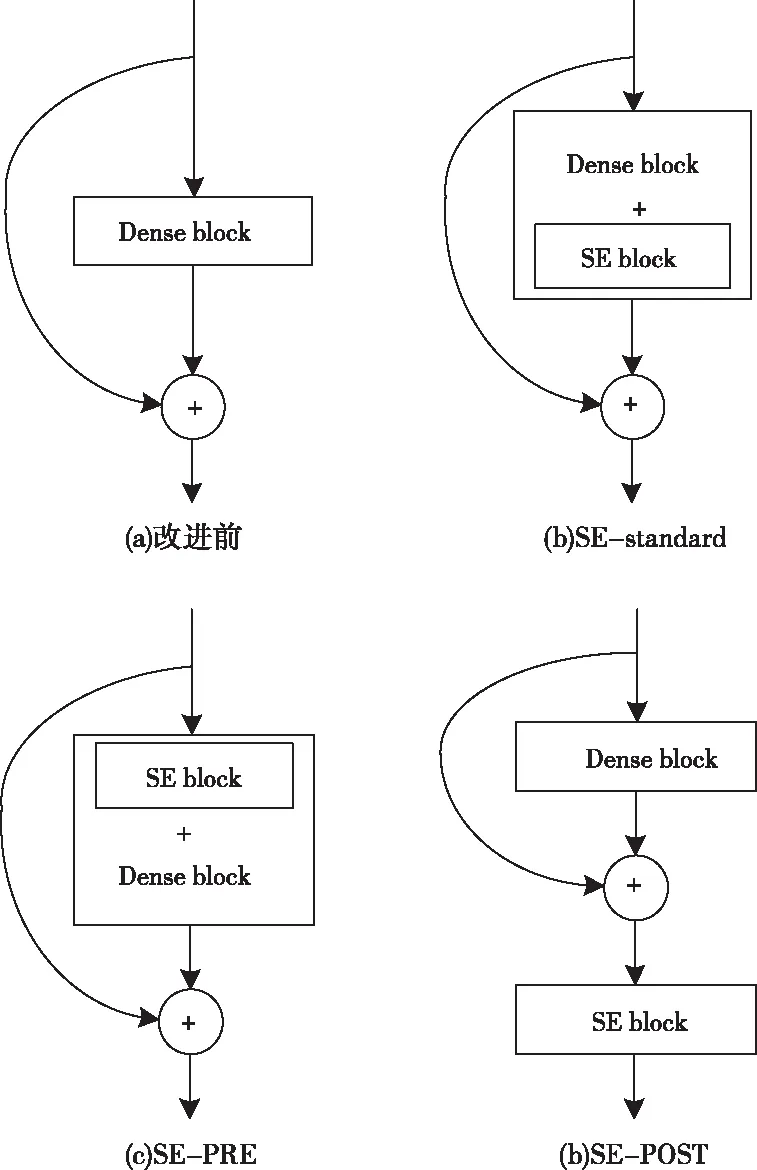
图5 改进方案图
图6 改进驾驶行为识别模型结构
以SE-standard模型为例,改进后的驾驶行为识别模型结构如图6所示,首先将样本输入至模型,然后进行图像数据的预处理操作,将处理后的图像数据送入模型特征提取环节,该环节的核心就是加入SE block后的denseblock,得到该样本的特征后经过分类器计算分类概率,最后输出识别的样本种类。
4 实验与分析
4.1 实验环境
1)实验硬件配置:Intel Core Xeon E5-2670v2 CPU
2.5GHz,16.0GB运行内存,NVIDIA GeForce GTX Titan XP显卡;
2)软件配置:64位Windows10操作系统,Python3.6编译环境,Pytorch1.2深度学习框架。
4.2 实验设置
本文baseline模型为DenseNet-169,输入维度为224×224,故需要将原始样本数据进行大小调整操作。为保证训练结果可复现,在实验时将随机种子设置值为666。为达到快速收敛的目的,本文模型优化器使用Adam优化器,初始学习率为0.02,每10代进行一次衰减,衰减指数为0.5。考虑到DenseNet模型对显存消耗较大的弊端,训练时批处理样本数量为64。
4.3 改进模型性能验证分析
为了证明改进后的驾驶行为识别模型整体性能优于baseline模型,将其与改进后的模型进行对比,实验分别从模型体积、识别速度、单分类正确率和整体正确率四个方面进行分析。
1)模型体积
模型体积表现了该模型占用硬件资源的多少,模型参数越多、结构越复杂则模型体积越大。模型改进前后的体积对比结果如表3所示,通过对比保存的模型文件大小发现,改进前后的模型体积变化不大,体积增大最高不超过3%,对于硬件性能的影响微乎其微。
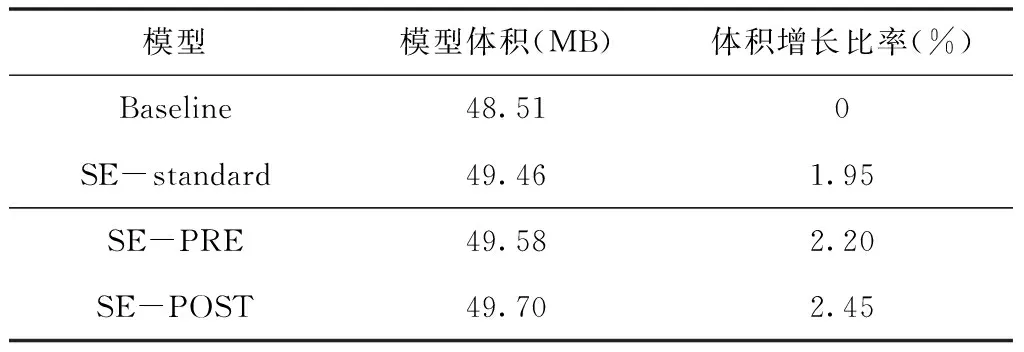
表3 模型改进前后模型体积对比
2)识别速度
对于一个驾驶行为识别模型,其识别速度是一项重要的性能指标,模型的应用场景要求其具有实时识别的能力。本文采用的测试数据集共1782张图片,通过记录测试总用时来获得单张图片识别用时。识别速度测试结果如表4所示,改进前后单张识别速度变化在1毫秒以内,因此模型的改进对模型识别速度产生的影响很小。

表4 模型识别速度
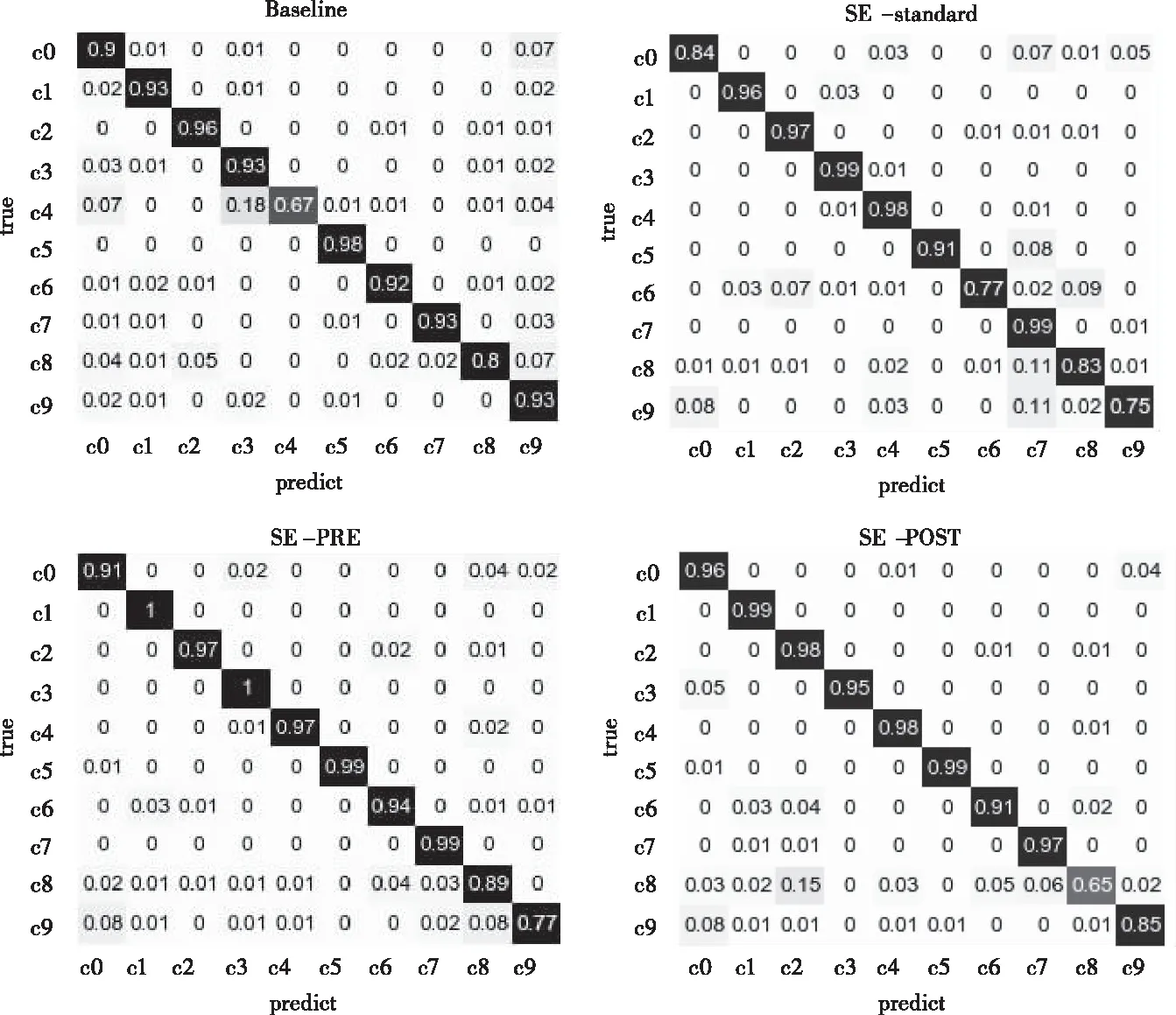
图7 驾驶行为识别混淆矩阵
3)单分类正确率
为了评价模型对于单个行为类别的识别能力,将前文提到的四个模型训练后,载入测试样本数据并将结果绘制在混淆矩阵中观察其单分类能力。观察发现模型在改进前对于c4类行为识别能力较弱;SE-standard模型虽然单分类能力有所提升,但提升效果有限,c6和c9类别的正确率低于80%;SE-PRE模型的单分类能力改善较为明显,c1、c3与c5类正确率接近100%;SE-POST模型的单分类能力依然有缺陷,c8类识别正确率低于70%。
4)行为识别准确率
根据图7中的驾驶行为识别混淆矩阵可按下式计算获得模型行为识别的整体准确率,结果如表5所示。
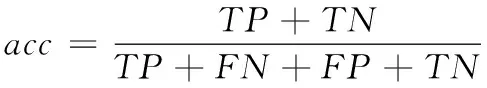
(5)
式中:TP表示预测正确且分类正确数量;TN表示预测错误但分类正确数量;FP表示预测正确但分类错误数量;FN表示预测错误且分类错误数量。

表5 模型识别准确率
从表中可以看出,SE-PRE模型的准确率最高,其它两个改进模型准确率相对原模型均有所提高,证明改进措施有效且效果显著。将模型总体准确率结合模型体积、识别速度和单分类准确率的结果可以得出:本文对于驾驶行为识别模型的改进在不影响模型响应速度和体积的情况下,有效提高了单分类准确率和整体识别准确率,与同类研究相比,以极低的成本提升了模型性能。
5 结语
本文在DenseNet模型的基础上,引入通道注意力机制对其进行改进,相比原有的驾驶行为识别模型,在保证模型识别速度的前提下有效提升了识别的准确率,能够解决原有模型对于单分类准确率不足的问题;高效且准确的识别驾驶行为并对分心驾驶行为做出预警,可以降低发生交通事故的风险,保障人民的生命财产安全。在今后的研究中,可以考虑使用新的注意力机制来进一步改善的行为识别性能,此外还可以从模型体积入手,使用更为轻量化的网络以便于识别模型的部署与落地。
