基于卷积神经网络的火车站语音情感识别方法
2023-03-29彭凯贝孙小明陈皓炜王建荣
彭凯贝,孙小明,陈皓炜,王建荣,3
(1. 中国铁道科学研究院集团有限公司电子计算技术研究所,北京 100081;2. 山西大学数学科学学院,山西太原 030006;3. 天津大学智能与计算学部,天津 300072)
1 引言
语音情感识别在人类与机器的交互中发挥着重要的作用,近年来在智能汽车、在线呼叫以及医疗紧急事故处理等多个领域应用[1]。语音情感识别主要是从人的情感语音中提取出不同情感的相关特征,然后根据提取的特征辨别出不同的情感并进行分类。语音情感识别中常用到的智能算法有:神经网络、支持向量机和贝叶斯网络等[2]。随着人工智能的发展,深度学习在情感识别中的应用越来越广。Kim首次将CNN用于文本情感分类,经过实验得出CNN要优于其它传统的机器学习算法[3]。赵小蕾等人将人工统计的特征与深度学习提取的特征输入到支持向量机中进行识别,该方法得到了较高的识别率[4]。吴俊清等人将CNN和GRU结合对小数据集语音进行情感识别,该方法比传统的情感识别方法更有竞争力[5]。高帆等人使用深度受限玻尔兹曼机融合语音的情感特征,使用长短期记忆网络(LSTM)识别语音情感,在多情感分类方面有着较好的性能[6]。余莉萍等人将LSTM中的输入门和遗忘门改为注意力门来识别儿童语音情感,实验表明该改进算法的儿童语音情感识别识别率高于LSTM[7]。
以上方法仅考虑了语音识别在某些公共数据集中的性能,而忽视了实际应用中数据集随机性强,规律性差的缺点。在火车站等人群密集场所中安全是不可忽视的因素之一,当发生危险时快速可靠的应急处理有利于将损害降至最低,因此本文将情感识别技术应用于火车站中,通过识别乘客的正负面情绪,为危险情况的预警提供一定的帮助。针对此应用场景,本文首先提取语音的MFCC特征,然后把提取的特征送到CNN中,最后输出每个语音的所属类别。仿真结果表明与其它深度学习算法相比本文所提出的方法有着更高的准确率。
2 语音情感识别
深度学习的快速发展推动了语音情感识别技术成熟。深度学习技术可以寻找到变量间复杂的非线性关系[8],在语音情感识别中,将每一条语音赋予一个标签,通过深度学习技术提取每一条语音的特征,使得每一条语音的特征与其标签一一对应,进而得到每一条语音所属的标签,并最终完成语音情感识别的任务。
2.1 语音预处理
本次实验需要将愤怒、恐惧、高兴、中性、悲伤、惊奇六种语音数据分为两类。愤怒、恐惧、悲伤为负面语音情绪数据,中性、高兴、惊奇为正面情绪。因此累计获取了由铁科院采集的分别代表愤怒、恐惧、高兴、中性、悲伤、和惊奇六种情感的4797条语音,这些语音由多名不同性别的人员录制。
对语音数据集的研究发现,该数据集中的大多数语音都有着不同程度的缺陷,例如:有些语音中存在空音,有些语音的音量过大,有些语音的音量过小,此外,每条语音的质量也各有不同。为此首先对数据集中的每一条语音做了预处理。
在预处理过程中,首先仔细去除了每一条语音中的空音,使每一条语音都仅包含有用的特征,而不包含无用的特征,接着统一了每一条语音的音量,使每一条语音的音量都在同一范围内,最后对每一条语音的质量做了提升,使数据集中的每一条语音都只包含高质量的语音特征。这些预处理工作为后续的语音情感识别做了准备,有利于语音的特征提取并且利于模型分类。
该模型属于深度学习中的监督学习类型,因此,将预处理后的每一条语音数据都做了标签标样处理,使得最终的训练数据集标签化,即每一条语音都带有各自的标签,例如第一条语音带有“高兴”的标签。
2.2 语音特征提取
经过梅尔频率倒谱系数特征提取后,数据集中的每条语音都提取了259维的特征。将提取到的特征矩阵中的缺省值做了补充处理,以保持特征矩阵的完整性。接着打乱特征矩阵的顺序,以降低数据间的顺序关联,进而增强模型的训练效果。提取、补充并打乱顺序后的部分特征矩阵如图1所示。
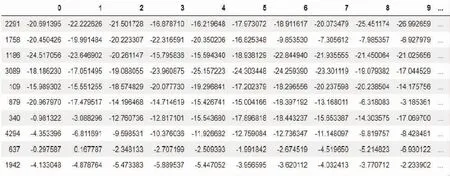
图1 提取并处理后的部分特征矩阵
最后将提取并处理后的特征矩阵按8:1:1划分为拆分成训练数据集,用于模型的训练、检验数据集,主要用于模型的效果检验与测试数据集,用于模型结果测试。
2.3 训练
该任务维分类任务,并且语音特征分布有明确的层级关系,因此,本文采用卷积神经网络对模型进行训练[10]。本文所开发的网络结构如图2所示。
如图2所示,图中的卷积运算代表分级提取语音特征,最大池化运算则是去掉前一层特征中的冗余信息,同时运算简化,Softmax运算的详细描述总结在本文2.4节部分。在每一个卷积层之后都设置了一个激活层,经过试验确定的最佳的激活函数为Relu,且其公式如下

(1)
由于该任务是将愤怒、恐惧、高兴、中性、悲伤、惊奇六种语音数据分为两类。愤怒、恐惧、悲伤为负面语音情绪数据,中性、高兴、惊奇为正面情绪。因此在输出层设置了两个全连接神经元,来将语音信号分为两大类。
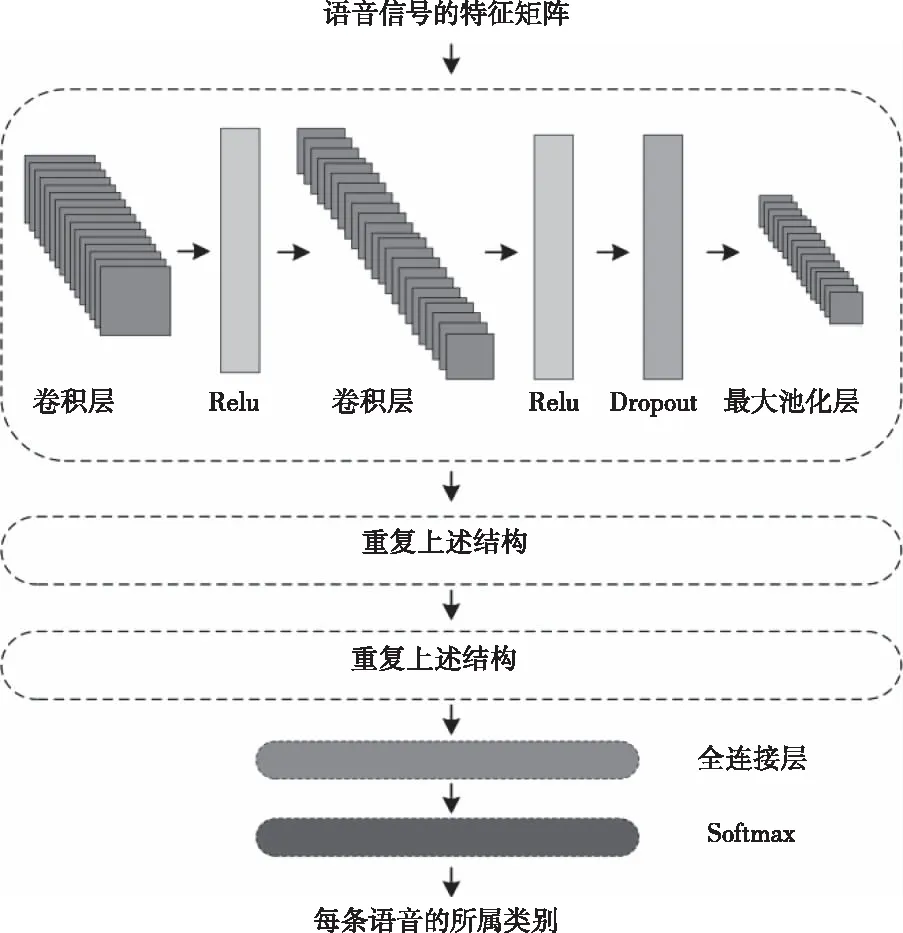
图2 卷积神经网络结构
此外,考虑到网络结构的复杂度,在每一个隐含层之后设置了随机失活(Dropout)来防止网络在训练过程中发生过拟合[11]。
*本文属于2017年度国家社会科学基金艺术学一般项目《李铁夫与中国早期油画研究》阶段性成果,项目编号:2017BF00860。
在添加了Dropout后,每个隐含层的神经元在训练过程中会有一定的概率不更新权重,并且每个神经元不更新权重的概率都相等,这样的设置可以在很大程度上减小网络过拟合的可能性。经过多次试验,在本实验中,每个隐含层后的Dropout概率值设置为0.2。即在每一个隐含层中,所有神经元不更新权重的概率相等,都为20%。
在训练过程中,经过大量试验确定了模型的一些超参数:使用了RMSprop作为网络的优化器,优化器的学习率设置为0.0001,批量大小(batch size)设置为32,迭代次数设置为200,损失函数(loss function)为分类交叉熵 (categoricalcrossentropy)。
2.4 模型优化
为了获取更加精确的模型效果,本实验在模型输出层添加了预警置信度的设置,来增强模型的实用性[12]。即数据集中的每一条语音会输出一个概率值,这一概率值代表每一条语音属于某个标签的概率,概率值越大则该条语音数据属于某标签的可能性越大,反之则可能性越小。这样的设置,在很大程度上保证了每一条语音输出各自类别的准确性。进一步提高了模型的分类精度,并且极大地提升了模型极端情况的预警性能。
在本实验中,输出层的置信度值设置为85%。通过自己录制的120条不同情感类别的语音数据对所提出的预警置信度设置方法进行验证。验证结果表明:预警置信度的设置可以让网络更好地识别每一条语音的特征,并且120条情感录音数据集中,负面情绪的预测准确度可以达到94%,能够完全识别具有极端愤怒情感语音特征,很好地满足了实际需求。可以为火车站等人员聚集场景的危险情况预警提供一定的参考。
本文使用了在深度学习中广泛使用的Softmax分类器来执行预警置信度的设置[13]。Softmax分类器的公式表达如下所示
ai=eai
(2)

(3)
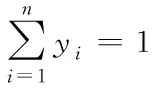
(4)
oi=aiyi
(5)
其中,为每一层中第i个神经元的输出,n为每一层中神经元的个数,yi为每个神经元的权重,oi为Softmax层的输出。
3 仿真结果
3.1 训练集和验证集精度
本实验使用卷积神经网络(CNN),对训练集的语音数据做了训练。图3为CNN模型训练集与验证集的精度。

图3 CNN模型精度
从图3可以看出,随着迭代次数的增加,训练集与验证集的精度都有升高的趋势,尤其是训练集。而验证集的精度在第50次迭代以后逐渐趋于平稳。最终经过200次迭代,训练集的精度达到97%以上,验证集的精度达到80%以上。
作为对比,本实验使用循环神经网络(RNN),多层感知器(MLP)神经网络与所提出的卷积神经网络做比较,来验证本实验所开发模型在车站语音情感识别任务中的准确性。为了保证实验的公平性,所有实验的环境均相同:所用的计算机配置为:Inter(R) Core(TM) i5-9300HF CPU,主要使用的语言为Python,用到了Numpy,Pandas数据处理库,Librosa音频处理库,Keras深度学习框架(Tensorflow为后端),以及Matplotlib绘图库等。
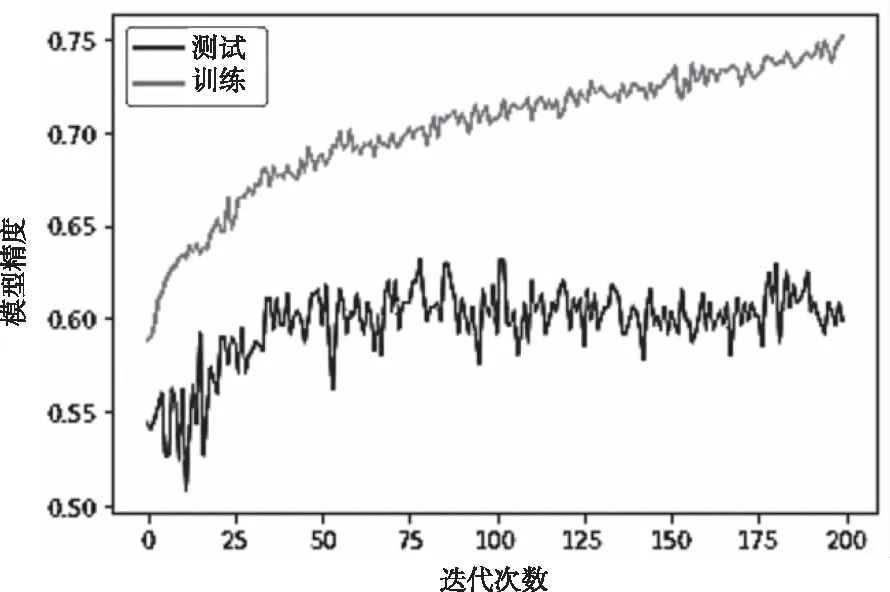
图4 RNN模型精度

图5 MLP模型精度
图4和图5分别展示了其它参数设置相同下,分别使用RNN模型和MLP模型时训练集和验证集的精度。从图3,图4和图5中可以清晰地看出,本文所开发的CNN模型在训练集和验证集中都有着很高的精度。并且在训练集和验证集的精度中都优于RNN和MLP两种常用的模型。这一对比结果进一步体现了本实验所开发的基于卷积神经网络的语音情感识别模型的准确性。
3.2 测试集精度
为了进一步验证所开发模型的泛化性,使用了不同人员录制的累计214条语音信号(144条代表中性、高兴、惊奇等正面情绪的语音,70条代表愤怒、恐惧、悲伤等负面情绪的语音)对模型的泛化性进行测试。这些语音信号同样包含了前文所述的愤怒、恐惧、高兴、中性、悲伤、惊奇六种情感,并且由不同性别的人员录制。
该测试语音数据集同样经过了语音预处理(如2.1节描述)、语音特征提取(如2.2节描述)。为了更好地验证模型的测试精度,将测试集的分类结果与前文所述的RNN模型,MLP模型做了对比。已知正面情绪个数为144,三种算法分类后的正面情绪个数对比结果见表1。
从表1可以看出,在代表正面情绪语音的分类中,累计有144条代表正面情绪的语音,而本实验所提出的CNN模型的分类结果中有133条代表正面情绪的语音,RNN模型的结果有80条,MLP模型的结果有72条。证明了本实验所提出的CNN模型在正面情绪的分类中有着很高的精度,并且高于RNN和MLP这两种常用的模型。
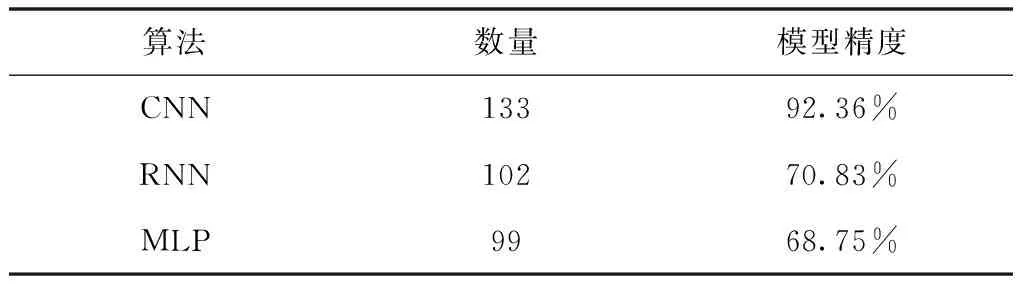
表1 三种模型在正面情绪语音中的分类结果
三种算法分类后的负面情绪个数对比结果见表2。在代表负面情绪语音的分类中,累计有70条代表负面情绪的语音,而本实验所提出的CNN模型的分类结果中有66条代表正面情绪的语音,RNN模型的结果有39条,MLP模型的结果有36条。这也反映了本实验所提出的CNN模型在负面情绪的分类中有着很高的精度,并且高于RNN和MLP这两种常用的模型。

表2 三种模型在负面情绪语音中的分类结果
测试集所有语音的分类中,三种模型的分类结果总结于表3。
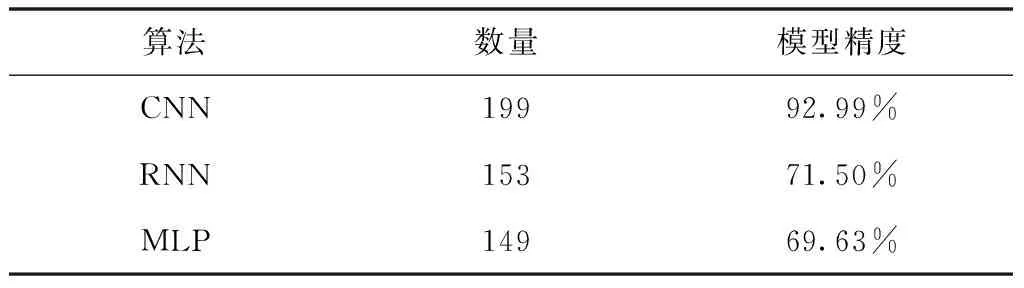
表3 三种模型在所有情绪语音中的分类结果
在表3中可以看出,测试集总计214条语音,本文所提出的CNN模型有199条分类正确的语音,而有15条分类错误的语音。对于RNN模型,分类正确的语音有119条,分类错误的语音有95条。而对于MLP模型,分类正确的语音有108条,分类错误的语音有106条。这一结果再一次反映了本文所提出的基于CNN的语音情感识别模型的准确性。此外,本实验结果在负面情绪语音的分类中有着较高的准确性,有利于火车站及其他人员聚集场所中危险情况的预警。
4 结论
为了减少火车站等人群密集场所中发生危险所造成的危害,本文将语音情感分类识别技术应用于火车站的应急处理中,提出一种CNN情感分类模型,首先提取语音的MFCC特征,然后把提取的特征送到卷积神经网络,最后输出每个语音的类别。此外在输出层加入预警置信度,可以让网络更好地识别每一条语音的特征。仿真结果表明,该模型准确率高于RNN和MLP模型。本文所提出的方法为火车站的危险预警提供一定的参考。
