新型内存硬件环境中的事务管理系统综述
2023-03-27梁文凯李诗逸王鸿鹏
胡 浩 梁文凯 李诗逸 王鸿鹏,2 夏 文,2
1(哈尔滨工业大学(深圳)计算机科学与技术学院 广东深圳 518055)
2(广东省安全智能新技术重点实验室(哈尔滨工业大学(深圳))广东深圳 518055)
事务作为支撑大型复杂场景的技术基石,以一个有限逻辑执行单元为现代应用技术服务提供强有力的可靠性保障[1].事务是构建数据管理应用的核心,后来这一理念被广泛运用于数据库系统中,为数据操作提供完整性、一致性、并发性和恢复性4 个基本属性[2].传统的事务管理系统以硬盘(机械硬盘(hard disk drive,HDD)和固态硬盘(solid state drive,SSD))为数据存储中心,借助主存(dynamic RAM,DRAM)低延迟和随机访问速度快的特性缓存部分数据操作的关键信息,加速事务语义处理.但是,随着数据存储量的爆炸性增长以及业务种类的扩增,以Oracle[3],SQL Server[4]为代表的传统关系型数据库已经无法满足工业界的需求,低延迟[5]、计算密集型[6]、I/O 密集型[7]等新型应用正在不断涌现.一些学者提出非关系型数据库,如Redis[8],HBase[9],MongoDB[10],Neo4J[11]等适用于联机分析处理(on-line analytic processing,OLAP)[12]的新型数据库.数据库系统中的事务允许多个操作并发执行并保证数据状态的一致性,但是通常数据库中的一个事务包含多个指令.由于传统数据库中的数据存储在磁盘上,因此事务执行周期较长.而软件事务内存(soft transaction memory,STM)[13]旨在简化并行编程模型,替代基于锁的数据同步方案,高效服务上层应用程序,使应用程序得以简化.并且,软件事务内存与数据结构中每个模块的加载和存储相处更为融洽,从而使应用程序维护更简便.软件事务内存与数据库中的事务不同之处在于前者研究的重点是并行编程模型范围内的内存访问效率,并且不保证持久性.
为了提高软件事务内存的性能,先前的工作利用额外的数据结构、内存脚印等机制[14-15]减少磁盘访问,这些机制在事务执行时产生较高的运行时开销.近年来,为了最小化软件事务内存的开销,硬件事务内存(hardware transactional memory,HTM)[16-17]逐渐获得了研究人员的关注.HTM 通过一系列事务相关的指令集在CPU 核心中的专有缓存区域追踪事务的读、写集合,并使用通用的缓存一致性(MESI)协议保持事务的修改状态,利用硬件检测事务冲突并中止相关事务执行.英特尔的事务同步扩展(transaction synchronization extensions,TSX)[18]是一种商业HTM 机制的实现,于2013 年添加至CPU 处理器 中.TSX 分 为2 种实现模型:1)硬件锁 定省略(hardware lock elision,HLE)允许CPU 不对事务操作对象集合的锁进行持久化,从而致使资源在程序模型视角是空闲的,进一步提高性能;2)受限事务内存(restricted transactional memory,RTM)是HLE 的替代实现,它可以为应用开发者提供灵活的软件接口,通过相应的指令集为事务代码指定执行区域,这一实现模型被广泛应用于实际场景中.
HTM 无法提供数据的非易失性,因此仍然要借助持久化设备保证数据的完整性.后摩尔时代意味着传统的磁盘存储设备已经到达了发展瓶颈,无法高速迭代产品.在这种不平衡的现状下,主存(DRAM)和持久化存储介质之间的I/O 带宽和延迟会变得越来越大,难以满足上层应用程序的性能需求.工业界和学术界开始寻求其他新型存储技术的突破,提出了一系列的新型非易失性存储器,如相变存储器(phase change memory,PCM)[19]、电阻式存储器(resistive RAM,ReRAM)[20]、自旋传递扭矩磁性存储器(spin torque transfer magnetic RAM,STT-MRAM)[21]等.英特尔在2019 年发布了首款商用傲腾非易失性内存(optane DC persistent memory,Optane PM)[22],该介质利用一种类似PCM 的技术——3D XPoint,打破了硬盘和内存之间的栅栏屏障,提供高密度、大容量的非易失性存储.Optane PM 可以直接放置在内存总线上,使用DDR-T 协议与内存控制器交互通信,允许程序使用异步命令同时保证数据时序,并且事务可以在非易失性内存控制器中重新排序.
然而,新型硬件的广泛应用使得传统的事务管理系统面临诸多挑战:1)HTM 受限于L1 缓存大小的限制,极易产生事务冲突,如何在解决事务冲突的前提下减少事务处理延迟是一个挑战.2)持久化内存为事务管理系统提供相较于传统持久化存储介质低1~2 个数量级的访问延迟,但是直接替换现有事务管理系统中的持久化存储介质会无法发挥持久化内存的性能特点.3)为了保证数据的一致性,事务管理系统往往通过额外写机制维护数据持久化顺序,这容易成为新型硬件中事务管理系统的性能瓶颈,可能面临新的可扩展性难题.
近年来,新型硬件中的事务管理系统已经成为了研究热点,研究人员聚焦于如何保证事务处理系统的高并发、高可扩展性.本文梳理了近年来基于新型硬件的事务管理系统研究工作.首先,从新型硬件在体系结构中的层次架构、事务并发控制协议、软硬件协同设计、崩溃一致性4 个方面阐述相关概念及问题.接着,对事务管理系统所使用的新型硬件进行分类,从事务性能、并发性、可扩展性等方面论述相关工作,明确基于新型硬件的事务管理系统设计目标.最后,对现有基于新型硬件事务管理系统设计的缺陷和瓶颈进行总结,指出基于新型硬件的事务管理系统的未来研究方向和具有价值性的设计原则.
1 新型硬件中事务管理系统的机遇与挑战
新型硬件在计算机体系结构中的层次架构如图1所示,本文聚焦于新型硬件对现有的事务管理系统的影响,因此仅从硬件本身带来的挑战和性能提升进行分析描述.
HTM 为事务 提供原子性(atomicity)、一致性(consistency)、隔离性(isolation)属性.为了保证数据在共享内存中操作原语的原子性,程序编程模型通常采用锁机制确保原子性.由于该机制在数据争用时会阻塞其他进程处理,并且同步开销较大,HTM以更简单的事务编程模型允许事务推测性执行,从而提高并发性能.
由于目前商用的持久化内存较少,因此本文的新型持久化内存硬件特性以傲腾非易失性内存(Optane PM)为例进行描述,后文若描述非易失性内存对象不是Optane PM,则用持久化内存替代.Optane PM 提供低延迟的数据访问,并且保证在机器发生意外崩溃时保证数据的完整性.傲腾非易失性内存具有3 种模式:Memory 模式、AppDirect 模式和混合内存模式.Memory 模式与DRAM 相同,目的是为上层程序应用提供高速、大容量的易失性存储;AppDirect模式具有与硬盘类似的特性,它可以为上层程序应用提供更低延迟的持久化存储;混合内存模式下,用户可以根据需求对Optane PM 空间进行区域划分,既可以提供大容量内存,又可以提供低延迟的持久化存储.
上述HTM 和Optane PM 的特性为事务管理系统带来了新的机遇,本文针对HTM 和Optane PM 特性对上层应用程序的性能增益进行评估,如表1 所示.
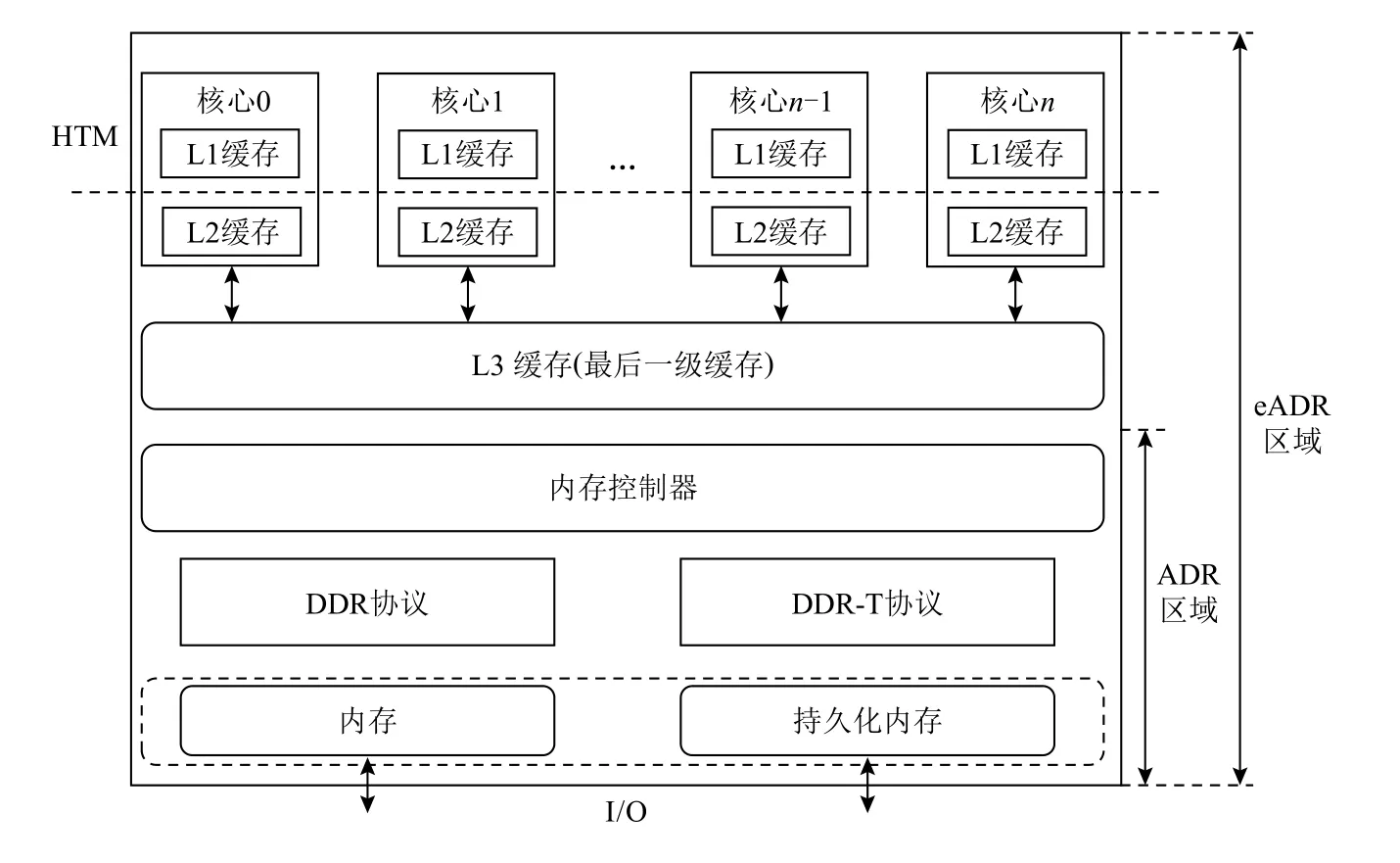
Fig.1 Architecture of the new hardware hierarchy图1 新型硬件层次架构

Table 1 Performance Evaluation of New Hardware表1 新型硬件的性能评估
从表1 中可以观察到,Optane PM 在延迟和吞吐上略差于DRAM,但是它在应用程序的性能增益上远超过传统的硬盘存储.这是由于应用程序无需复杂的I/O 路径,通过load/store 指令直接在Optane PM上读写数据.图2 展示了Optane PM 在存储层次结构中的3 种不同访问路径类型:1)Optane PM 作为主存和二级存储之间的中间层,可以降低数据的访问延迟并提高系统整体吞吐,相较于价格高昂的主存,可以有效降低数据总拥有成本.2)将主存和Optane PM 放置在同一层,使得Optane PM 既可以拥有类似主存高速随机访问的优势,又可以提供非易失性存储.3)将Optane PM 放在二级存储层次,但是此架构下的数据关键路径可以绕过主存,使用相应的指令集直接对Optane PM 上的数据进行访问,仅适用于数据需要实时持久化存储并对延迟有一定容忍度的场景.
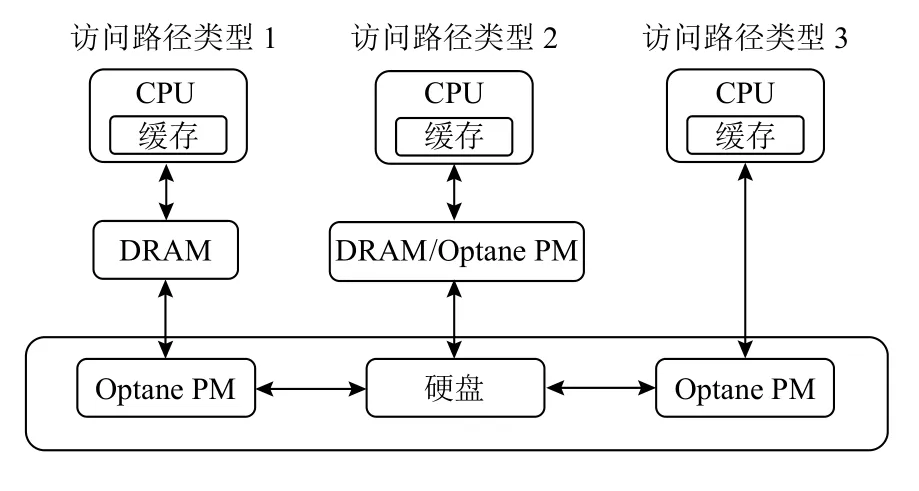
Fig.2 Different memory organization layout architectures图2 不同的内存组织布局架构
研究人员对Optane PM 特性进行深入测试[23-24],发现Optane PM 中的持久域无需额外的电池就可以提供系统崩溃或者意外断电后的数据完整性服务,并且可以保证8 B 的原子写,即只要程序以8 B 的粒度写入Optane PM,无需额外的数据结构即可保证数据一致性.如图1 中的ADR 区域,只要数据进入ADR 区域即可保证数据完整性,该区域已经在目前支持Optane PM 的第2 代英特尔至强可扩展CPU 上得到广泛支持;eADR 区域与ADR 的区别之处在于它的持久域包括整个内存层次架构及CPU 缓存,只要数据进入CPU 缓存中就可以保证数据的完整性,不会因为系统崩溃以及意外断电而导致数据丢失.
如果将Optane PM 直接放置在现有的应用程序上,具有3 点局限性:1)读写不对称,已有的研究[23-24]表明在最理想的测试环境下,Optane PM 的顺序读延迟是DRAM 的2 倍,随机读延迟是DRAM 的3 倍,但是Optane PM 使用专有指令集的写延迟与DRAM 相差不大.2)访问粒度不匹衡,Optane PM 的带宽不能随着访问粒度的增大而线性增长,研究表明小于256 B 的随机访问Optane PM 会引起写放大,导致Optane PM 的使用寿命减少[23-24].3)可扩展性差,Optane PM 的吞吐率无法随着线程数量的增长而线性扩展,在高并发场景下,这将会造成大量的资源浪费,并且产生性能瓶颈.
随着新型硬件商业化应用的兴起,事务管理系统的发展面临新的挑战,主要包括2 个方面:
1)HTM 的区域容量以及并发控制协议增加了事务中止概率
HTM 可以提供硬件级别的事务冲突检测,并减少各个核心之间的锁同步开销.在HTM 中,事务以类似乐观并发控制协议(OCC)的方式执行.然而,互联网正在重塑我们的日常生活,各种新型业务需求正在爆炸性增长,大事务和长事务等类型的事务所读取或写入的缓存行数量会溢出HTM 区域.因为HTM 中的事务在执行时是在CPU 核心的私有核心区域中处理.如果此时事务发生冲突,则有可能中止其他对相同缓存行读取的事务,从而造成资源浪费.此外,事务的冲突检测、冲突解决时机以及一致性保证也会制约事务管理系统的吞吐性能.仅使用单个核心的HTM 可以避免核间数据通信,减少事务冲突中止率,但是这种方案无法高度并行化.因此,如何扩展HTM 区域并选择合适的冲突检测时机,是设计硬件事务内存驱动的事务管理系统的重要挑战.
2)Optane PM 的硬件特性限制了事务系统的性能
Optane PM 的延迟、吞吐特性会限制现有的事务管理系统的性能.相比较于传统事务管理系统中的磁盘访问方式,Optane PM 已经将访问延迟降低至纳秒级别.从理论层面分析得知事务管理系统没有完全发挥Optane PM 的性能极限,主要原因有2 个方面:一方面,Optane PM 可以提供持久化存储,但是它无法保证系统崩溃之后较大数据粒度存储至Optane PM 上的数据一致性.而且,由于Optane PM 的读写不对称以及访问粒度等硬件本身特性的限制,目前现有的机制如日志等会造成大量的带宽浪费并减少Optane PM 的使用寿命.另一方面,当前的事务并发控制协议需要重新设计冲突检测策略以及持久化顺序.Optane PM 无法随着现代多核架构中内核数量的增加而线性扩展事务吞吐性能.并且Optane PM 可以为HTM 提供持久化存储,但是当前的并发控制协议无法充分发挥硬件级别的性能以及Optane PM 访问模式特性也会对HTM 进行制约,直接将二者结合会因为事务执行和存储关键路径上的等待问题而降低事务吞吐性能.
2 新型硬件环境下的事务相关概念
本文将从事务并发机制、软硬协同、事务崩溃恢复机制3 个维度着手进行综述.事务并发机制是保证事务性能的软件基础,软硬协同是设计高性能事务管理系统的重要方向,事务崩溃一致性机制是保证事务管理系统的可用性.
2.1 事务并发控制协议
并发控制协议是事务管理系统的重要组件,其代表允许事务并发执行的最大限度为多少,而隔离级别则控制事务并发执行的性能.事务的隔离级别一般可以分为强、弱2 种级别.事务中强隔离级别为串行化(serializable),它意味着一次仅执行一个事务,一个事务结束之后才处理下一个事务.虽然这种隔离级别无需额外的机制保障数据一致性,但是它会制约事务管理系统的扩展性,这与语义模型的并发性趋势相违背.弱隔离级别可以分为快照隔离(snapshot isolation,SI)和可串行化快照隔离级别(serializable snapshot isolation,SSI).快照隔 离级别 指的是事务在读数据时并没有读取最新的数据项,而是选择某个时间点具有一致性保障的数据快照(副本),目的是减少等待其他并发事务完成的时间.对于此隔离级别下的写事务,事务容易发生“写倾斜”异常.因为快照隔离级别并发执行的2 个事务存在修改同一个数据项的可能性,但是它们无法获取双方事务更新后的数据项状态,从而无法保证数据一致性.可串行化快照隔离追踪并发执行多个事务之间发生的冲突(读-写、写-读和写-写冲突),一旦检测到冲突事务,系统则选择中止其中一个事务达到可串行化执行的目的.
以上的并发控制协议隔离级别的实现机制分为基于锁的协议和基于时间戳的协议.基于锁的并发控制协议的典型代表是数据库中的2 阶段锁(two-phase locking,2PL).2PL 在事务的执行过程中分为2 个阶段:1)增长阶段,这个阶段事务获取相应读写的数据项,并对其上锁,阻塞其他事务对数据项操作.2)缩减阶段,这个阶段释放增长阶段获取的数据锁,并不获取新的锁.基于时间戳的并发控制协议对每个事务赋予唯一的时间戳,通过时间戳的大小避免并发事务之间的冲突,保证事务可串行化执行.
根据事务冲突类型以及并发控制协议的实现机制,并发控制协议可以分为悲观并发控制、客观并发控制和乐观并发控制.2PL 就是典型的悲观并发控制协议,适用于解决读-写和写-写冲突.但是悲观并发控制对事务操作数据单元集合中的每个数据项都需要获取锁,而频繁的锁管理操作会降低事务处理性能.因此,客观并发控制为了减少锁开销,使用基于时间戳的机制.每个事务开始时会获取唯一的时间戳作为事务的开始标志,通过时间戳的逻辑顺序,事务管理系统可以保证事务的读写操作有序执行.乐观并发控制认为事务执行期间不会相互干扰,因此事务可以在执行期间不获取任何锁,直接对事务操作逻辑单元集合中的数据项进行更新.但是在事务提交之前,乐观并发控制会验证读写数据是否存在冲突.如果验证失败,则中止事务并回滚相关数据项;否则说明事务执行期间没有任何冲突,则可以提交事务并持久化更新相关数据项.
HTM 的思想是“尽力而为”,因此当事务在硬件层面没有成功提交时,需要使用软件回退保证事务的执行进度.通常采用全局锁序列化执行未能成功执行的事务.根据冲突检测时机,现有的方案分为2 类:急切检测和惰性检测.急切检测指的是在硬件事务启动后立刻检查全局锁的状态,如果发现已经上锁,则该事务立刻中止;否则,事务则在硬件路径上执行.并且,事务追踪锁的更新状态,一旦发现其他事务获取锁,则中止事务.但是,急切检测机制无法同时执行推测性事务和软件回退路径上的事务,而惰性检测则是在事务提交之前获取锁状态,类似于乐观并发控制算法.HTM 通过黑盒和强原子性操作保证事务的一致性.但是当发生冲突时,非事务性访问的位置都在事务性访问之前进行排序,从惰性检测的角度无法观察到数据不一致的状态,从而导致事务错误提交.
2.2 事务软硬协同设计
随着新型硬件技术的发展,仅使用新型硬件直接替代传统事务管理系统中持久化介质的技术路线并不能发挥硬件本身的最大性能.原因是新型硬件的特性无法透明支持上层程序应用,导致软件栈限制了事务吞吐性能,具体原因为:
研究表明[23-24]Optane PM 内部的访问粒度为256 B,这与CPU 中的缓存行粒度64 B 不匹配,如果不对程序编程模型进行重构,将造成大量的写放大.并且第3 代英特尔可扩展至强CPU 提供了有效的缓存行刷新(CLFLUSH)、优化的缓存行刷新(CLFUSHOPT)、缓存行写回(CLWB)、非临时存储(NT-STORE)和内存屏障(FENCE)原语.CLFLUSH 指令能够将指定内存地址的缓存行从CPU 缓存中淘汰,并向所有CPU核通知.如果该缓存行是脏数据,则在缓存行失效前写回主存中.CLFUSHOPT 指令则是CLFLUSH 的优化版,其支持在访问不同的缓存行时,可以不按照顺序淘汰缓存行.CLWB 作为目前只有第3 代英特尔可扩展至强CPU 支持的指令,它的功能与CLFLUSH 相似,但是在缓存行的数据写回主存之后,该缓存行仍显示为未被修改的状态,即写回数据后不让缓存行失效.NT-STORE 指令可以使数据绕过缓存,直接将数据写入Optane PM.而FENCE 的功能则是保证访存指令按照程序的逻辑顺序执行,即在高并发场景中,多个load/store 指令对Optane PM 上的数据进行并发操作,缓存行刷回可能会并行执行,导致脏缓存行无法保证有序写回,这时则需要FENCE 指令来约束缓存行的写回顺序.但是,Optane PM 相关的指令如CLFLUSH 和FENCE 在保证串行持久化时会产生较大的持久化开销,降低系统性能.
HTM 作为底层硬件级别的冲突解决方案,其可以与Optane PM 结合.但是由于高速缓存行逐出策略具有黑盒属性,Optane PM 的指令集无法对高速缓存行的状态进行有效推测,从而可能出现事务数据持久化顺序无法受到指令集约束的情况.
2.3 崩溃一致性
由于Optane PM 具有异步刷新功能,加载至ADR区域的数据并不会丢失.在系统意外断电或者程序发生崩溃错误后是否可以维护数据一致性,是衡量事务管理系统可靠性的一个重要指标.即使事务管理系统发生故障,系统在恢复后仍然可以访问正确状态的数据.但是在实际程序语义模型中,由于一个事务内部可能需要修改多个数据项,系统崩溃故障可能发生在事务部分数据项已经完成变更状态并持久化之后.而故障恢复模型可以在系统恢复时追踪数据状态,将数据恢复至正确状态.
持久化模型保证事务管理系统的崩溃一致性,但是一致性模型规定的持久化顺序会限制事务管理系统的吞吐性能.按照数据上下文持久化顺序可以将持久化模型分为2 类:严格持久化和宽松持久化.程序语义中的严格持久化与Optane PM 上数据存储顺序一致.如果前面的数据没有存储完成,会阻塞后续的数据存储,这种模型受到了排序约束从而导致性能瓶颈.宽松持久化模型允许数据持久化的顺序与程序语义中上下文中的数据可见性顺序不同,通过设计新的持久化屏障控制数据的可见性和存储排序约束性.
构建在Optane PM 上的事务管理系统在崩溃恢复时对数据的操作原语同样需要原子性操作.目前用作实现崩溃一致性的技术分为2 类:预写日志和影子分页.预写日志要求在数据写入Optane PM 之前将数据的变化记录在日志中,日志先于数据持久化.当前主流的预写机制分为undo 日志和redo 日志.undo 日志在每一个数据持久化之前首先创建一条日志并持久化,使多个独立写原子化地执行.系统崩溃重启后利用undo 日志的内容将未完成的原子单元中的修改回退到一致性状态.redo 日志采用异地更新方案,在日志中记录更新后的数据版本,当事务单元的所有更新结束后首先将日志持久化,之后再将数据写回到原位置.影子分页与预写机制的不同之处在于允许数据异地更新,从而减少预写机制的冗余写入.影子分页也叫做写时复制(CoW),它创建一个新的数据副本,并将原始数据以及后续的更新内容写入到持久存储,然后改变指针来指示新的对象/数据,而旧的对象/数据则可以被丢弃.影子数据对整合数据区域维护2 个(或多个)版本,每次只更新一个版本,保证了在任何时刻至少有一个副本处于一致性状态,系统崩溃后通过观察持久性状态信息来选择具有一致性版本的数据恢复.
本文对上述方案进行了总结,如表2 所示.表2中N为一个事务内修改的单元数,内存屏障数量表示持久化约束指令,flush 表示需要手动将缓存刷回到Optane PM 的次数.

Table 2 Performance Comparison of Write-ahead Logs and Shadow Paging表2 预写日志和影子分页的性能对比
undo 日志中每个单元更新引入2 个顺序限制:日志数据必须在日志头更新之前持久化,以及日志头的持久化必须在更改数据之前.因此需要2 个内存屏障,并且需要对日志、日志头以及数据本身执行3次缓存刷回,除此之外还需要保证每个事务的日志清空要在数据更新完成之后.
redo 日志异地更新数据,日志数据持久化后需要更新日志大小,之后才能原地更新Optane PM 对象,其中每个对象需要1 次缓存刷回,日志区域以及日志大小各需要1 次持久化写入.
CoW 只需要保证事务在更新对象指针之前,每个操作对象的更新已经完成持久化,每次更新需要将对象本身以及对象指针刷回.并且,在以数据块为单位的事务管理系统中,CoW 需要拷贝整个数据块的内容,如果数据块的容量被设置得很大将会导致较高的复制开销.
虽然表1 所述方案的实现方式不同,但是它们有4 条共同原则:1)一定会有一个数据副本;2)一定会有一个持久性状态信息来指示哪一个副本处于一致性状态;3)要求至少一个持久化写的顺序限制;4)只有经历一次与持久性设备之间的往返屏障之后才能保证数据持久化.这4 条共同的性质也是保证崩溃一致性的基本要求.
3 基于新硬件的事务管理系统研究
为了应对新硬件带来的挑战,相关研究学者针对新硬件本身特性和事务属性展开了一系列相关工作.本节仅从单机事务管理系统相关文献出发,并将这些文献划分为硬件事务内存驱动的事务策略研究、面向持久化内存的事务管理系统技术研究和面向新硬件的软硬协同事务技术研究,并在最后对这3 个研究进行总结.研究框架图如图3 所示,从硬件本身、事务并发控制机制和持久化机制3 个维度进行分类分析.
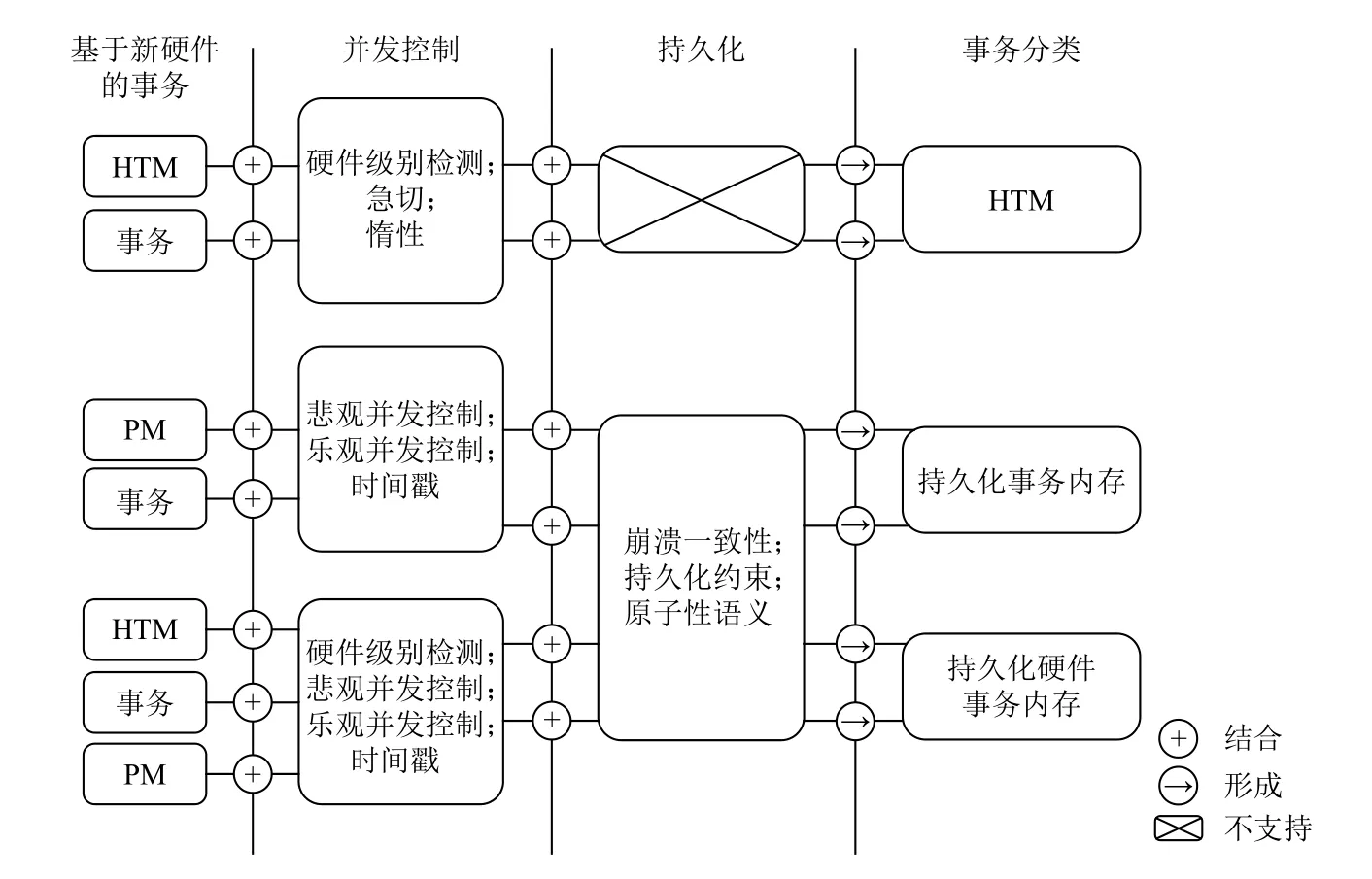
Fig.3 The technical framework of transaction management system based on new hardware图3 基于新硬件的事务管理系统技术框架
3.1 HTM 驱动的事务策略研究
随着多核架构的发展,并行编程已经成为了当前程序语义模型的主流实现方案.为了保证同步访问共享内存中的数据,传统的方法容易导致程序上下文出错,并且基于软件运行时开销较大.HTM 作为一个抽象的硬件级别解决方案,减少额外冲突检测开销,但是HTM 受限于区域容量限制,并且操作系统上下文中的原语操作容易中止事务,限制了HTM 的可扩展性.降低HTM 中的事务中止率,减少HTM 的软件栈路径开销对于HTM 驱动的事务管理系统至关重要.表3 对目前主流的HTM 驱动的事务管理系统进行总结.表3 中的冲突检测代表事务冲突检测时机,其中惰性检测意味着事务冲突检测在提交时才进行检测,急切检测则反之.数据版本含义为数据持久化是否立即发生,惰性代表事务提交后数据进入缓冲区,急切则代表数据被日志所记录.回退路径则代表HTM 不提供进度保证,需要采用其他机制保证软件回退.悲观回退路径代表事务回退时,需要对相关的数据项获取锁,重试则代表事务会丢弃所有执行的更新并重新启动更新.
LogTM-SE[25]发现目前HTM 方法中的数据版本控制以及冲突检测严重依赖L1 缓存.然而,这样做一方面增加了L1 缓存的存储压力,另一方面也不利于访问事务的状态信息.LogTM-SE 利用签名以及日志来存储事务状态信息,将事务执行路径与L1 缓存解耦.签名用来检测事务冲突,在收到缓存一致性请求时,处理器立刻利用签名信息检查读写集合是否冲突.日志则用来保证事务冲突后可正确回退,因此LogTM-SE 发生数据更新时使用日志记录数据的变化,出现事务中止回退时采用悲观机制即获取锁的方式保证数据有序回退.签名以及日志的实现仅需要少量修改现有硬件提供的缓存阵列,实现了事务执行路径与L1 缓存的解耦.在此基础上其允许事务状态信息可以被软件访问,操作系统内核和运行时软件可以利用这些信息来支持事务虚拟化,支持任意大小的事务,并且可以接受内存页切换等操作系统活动.

Table 3 Classification of Transaction Strategy Research Driven by HTM表3 HTM 驱动的事务策略研究分类
EazyHTM[26]发现在事务之间发生冲突时立刻中止会增加级联等待时间.为了解决事务潜在冲突,事务管理系统需要推测事务之间的优先级顺序.但是,由于事务在执行时缺少先验性知识,无法得到最优结果.即使得出正确结论,事务之间也无法保证高度串行化.基于此观察,EazyHTM 将冲突检测和冲突解决任务分离,在事务执行的同时进行冲突检测,但是冲突解决推迟至事务尝试提交时进行,从而实现惰性冲突检测机制.这种机制类似于乐观并发控制协议,但是与之不同的是,EazyHTM 可以避免事务提交时的验证,减少验证等待时间.为了保证在多个CPU核中的数据一致性,EazyHTM 通过对MESI 协议进行微小修改.其使用位图维护事务提交时必须中止的事务列表,并且允许事务通过向其他CPU 核心广播特殊请求,中止每个CPU 核心上正在执行的事务.通过设置2 个额外的标记位扩展私有缓存,分别代表关联缓存行已被读取和缓存行已被修改.EazyHTM允许事务管理系统在事务生命周期内维护一个完整的冲突快照,使用该快照可以进一步地提高事务处理性能.
由于EazyHTM 从事务中止中恢复服务时,无法确定与其他CPU 核心上的事务是否发生冲突,从而引发事务长时间等待处理的结果,降低事务性能.Pi-TM[27]可以加速这一过程,采用温和的悲观机制,在私有缓存中维护一个额外的单位,称为Pi 位.当事务中止时,只有事务执行过程中操作的缓存行才会失效.并且事务可以立即重试,使用私有缓存的数据进行处理,无需额外的通信开销.为了保证数据一致性,事务提交时会强制读取集合中存在冲突的缓存行无效.当系统中事务冲突率较高时,Pi-TM 使用混合检测方法,同时采用惰性冲突检测以及使用之前的Pi机制.这2 种模式都发生在私有缓存中,因此可以安全交互.
HTM 的“请求者获胜”原则在发生事务冲突时,会重复导致相同的事务中止,迫使执行更慢的非推测性路径,并且对长时间运行的事务极为不友好.针对此场景,PleaseTM[28]解耦事务冲突一致性检测路径,仅在一致性请求中添加请求位,同时追踪缓存行状态,透明支持更深层次的一致性协议.PleaseTM 中的事务在接收到请求者消息时,可以根据实际执行过程自由选择是否中止事务.为了保证序列化原子性执行,事务在重新请求缓存行时,需要重新获取事务执行之前的旧数据来验证数据是否发生变化.如果数据不一致,则中止事务.该机制的优势是发生事务冲突时减少一致性协议中的数据传输,并可以与软件事务内存协议协同工作,进一步提高性能.
“尽力而为”的HTM 的一个关键设计约束是避免修改一致性协议,因为在实际场景中,高速缓存行中的数据和状态都是转瞬即逝的,并且对缓存一致性协议进行修改容易引起程序语义模型崩溃.Forgive-TM[29]提出一种惰性冲突检测模型,无需修改现有的缓存一致性协议,并且支持延迟冲突检测.它采用“先行动,后请求”的原则,推测性写入会立即写入特殊缓冲区中,无需获取全局写入权限,仅在事务提交时才获取写入权限.在延迟写入时,处理器仅检查数据的读取权限,只在读取权限不可用时,才会对其他核心广播获取读取权限.当事务对缓存行具有读取权限时,该缓存行则被添加至LazySet,在本地私有缓存中该缓存行状态则为脏数据,并且对于全局是不可见状态.事务对缓存行检索或存储时,不会发生任何改变数据一致性的操作.当该事务提交时,Forgive-TM 分为2 阶段提交:第1 阶段是提交准备阶段,对LazySet 中的所有数据获取全局写入权限,任何推测性访问LazySet 中的数据都将被中止.第2 阶段是提交阶段,该阶段的原则是尽力而为.如果该阶段发生冲突,事务则向对等方发送一条特殊消息,阻止其他事务提交.由于延迟检测与处理冲突会直接影响事务延迟,因此Forgive-TM 限制了LazySet 的大小,并采用打分机制推理缓存行发生事务中止的可能性.通过打分机制可以对一部分缓存行进行惰性写入,从而降低延迟.并且Forgive-TM 在事务到达提交时,发送写权限请求,允许操作重新排序为多核应用程序提供更高的可扩展性.
HTM 需要提供一个回退计划来保证事务在经历HTM 区域空间不足、页错误以及高竞争导致的频繁崩溃等场景时不会永远阻塞下去,常用的手段例如Intel 提供的RTM 中采用积极的单一全局锁机制,所有的事务在开始阶段都需要检查全局锁是否被上锁.如果是表明当前有事务正在执行回退计划,则本事务直接崩溃,否则事务正常执行.然而这种机制严重限制了系统的并发性,当有一个事务执行回退计划时,即使其他事务与回退计划中的事务没有冲突,也不得不等待其结束.CIT[30]对硬件做了少量修改,在缓存一致性协议的请求消息中增加推测位,在响应消息中增加请求位,并在L1 缓存中增加冲突队列,冲突的事务请求将会被放置在冲突队列,并在事务结束或者崩溃后移出队列.CIT 借助冲突队列使系统执行回退计划时允许其他事务并发地执行,只有当冲突真正发生时才会中止事务,从而提高系统的并行性.CIT 通过消除或者避免获取回退锁的方式增加事务之间的并发性,并且所需的指令和硬件更改远少于现有方法,可以显著提高事务性能.
针对数据库中事务内存同步数据开销大的瓶颈,Leis 等人[31]对每个事务的读写集合分配一个时间戳,使用乐观并发控制协议执行事务.由于事务发生冲突后回滚事务恢复数据时,为了保证数据一致性,需要对相应的数据项上锁,产生较大的开销.Leis 等人[31]分析了HTM 原理,发现HTM 可以捕获冲突,并保证较低的回滚成本.当发生事务冲突时,因为HTM 内部有latch,只需要将事务修改的缓存行失效即可.而原本的数据副本依然存在L2/L3 缓存中,后续事务执行可以直接从高速L2/L3 区域中读取.为了避免事务回滚时无限次重试,Leis 等人[31]使用事务开始执行时分配的时间戳计算安全时间窗口,以序列化的语义模型重新执行事务.为了提高HTM 中事务冲突错误识别率并提高事务插入性能,Leis 等人[31]提出一种友好的HTM 存储模型,将内存区域分成多个zone segement,避免集中访问同一内存位置造成的事务高冲突率.实验结果表明该方法与数据库结合可以提高事务并发性能,并且在多核处理器上具有较好的可扩展性.
新加坡国立大学的研究者分析了HTM 应用于OCC 时的性能变化.虽然在一些场景下可以取得较高的事务吞吐率.但是,在处理高争用的工作负载时,性能远低于理想情况.并且在事务中止后重新执行时,需要检索相关数据进行处理.因此,HTCC[32]将数据冷热分离,根据数据争用热度自适应选择悲观并发控制或者乐观的HTM 访问数据.为了降低事务中止后的频繁重试执行,HTCC 维护一个工作集缓存,对事务操作原语进行保存,该机制可以减少频繁的磁盘I/O.为了防止在高争用时工作集缓存区中的数据项出现死锁,HTCC 使用HTM 简化程序语义模型.在事务处理时,HTCC 可以自动跟踪事务的冲突访问,对引发事务验证失败的记录进行原子性来增加其计数器.为了保证事务的序列化提交,HTCC 采用时间戳机制为每个事务分配唯一标识进行排序.为了兼容数据库中的操作原语,HTCC 使用标识位对每个记录进行标识,并结合数据库本身的操作原则进行处理.HTCC 通过降低事务冲突中止率,无需频繁地重试执行,因此可以在多线程场景中展现较高的性能.
澳大利亚国立大学的Cai 等人[33]对HTM 特性进行了更加深入的研究,发现之前关于HTM 的工作仅仅考虑了容量对程序模型的影响,并没有考虑缓存替换策略是决定事务读取有效缓存行的关键因素.Cai 等人[33]对当前主流的英特尔处理器模拟了HTM的事务执行过程,通过观察得出结论:事务管理系统在执行事务之前应该预热相关数据.其目的是为了提高事务成功提交率,减少由于缓存行频繁逐出而造成的事务高中止率,并且Cai 等人[33]事务管理系统应该优先逐出未被事务访问的缓存行.
3.2 面向持久化内存的事务管理系统技术研究
持久化内存可以将数据持久化的延迟降低至纳秒级别,由于持久化内存的特性与现有的传统硬件并不相同,因此需要重新设计更适合新型硬件的事务管理系统,这是系统设计者的当务之急.为了全面理解面向持久化内存的事务管理系统技术,本文从事务自身的宏观角度出发,对其进行总结,如表4 所示.表4 中的持久化方案意味着确保数据持久化和崩溃一致性的机制.并发机制代表事务并发执行时的事务管理机制.隔离级别包括最严格的线性化成为系统的瓶颈,去中心化分配事务唯一标识以及使用逻辑时间戳等方案更符合事务系统高扩展的趋势.写放大遵循TimeStone[34]的计算规则,是持久化内存上实际持久化数据大小和事务请求之间的比率.写放大出现的原因是为了保证事务一致性从而引入了额外写操作.管理粒度是指事务系统操作持久化内存区域的单元大小或者其锁粒度,较小的管理粒度可以提高事务并发性能.(linearizability,LN)、可串行化(serializability,SR)以及快照隔离(snapshot isolation,SI)机制.LN 保证事务内的读写操作完全按照事务的执行顺序执行.SR 相对放松了顺序限制,允许不同事务的读写事务交错进行,但是最终事务从整体上符合某一种线性顺序.而SI 只需保证事务读取的数据是在某一时刻具有一致性状态的内存快照,但是可能会出现写倾斜的问题.事务标识用来区别每一个事务,也可以用来作为恢复阶段日志执行的顺序,中心化分配的ID 通常会

Table 4 Classification of Persistent Memory-Based Transaction Management System表4 面向持久化内存的事务管理系统技术分类
Marathe 等人[46]通过实验对比了基于undo,redo,CoW 机制的事务管理系统在模拟的持久化内存环境上的表现,综合考虑了持久域、工作负载访问模式、缓存一致性等因素.实验结果显示,每项技术在不同的场景中都有自己的优势和缺点.基于预写日志的技术需要写日志以及数据本身,但是额外的写操作会导致较大的开销.为了保证数据一致性,预写日志一定要在更新数据之前完成持久化操作.而undo 日志由于无法事先获取写集合,因此集合中每一个更新都需要保持严格的顺序,对于N个日志项会增加2N个持久化屏障,从而导致性能急剧下降.redo 日志直接在日志中创建新版本数据并直接更新.但是由于新值仅出现在日志中,随后而来的读操作必须查阅日志才可以获得最新值,有可能出现遍历整个日志才可以找到最新值的情况.CoW 机制可以避免这些问题,但是引入了大量的元数据更新,例如对象的指针、内存分配器的元数据,这些元数据的更新主要是由较小的数据结构(小于64 B)组成,而非易失性内存内部的访问粒度为256 B,大量较小的随机元数据更新会导致严重的写放大问题.同时CoW 也会产生较大的缓存局部性开销.
1)基于undo 的日志事务管理系统
Kolli 等人[35]发现由于持久化内存存在较高的写延迟,减少写操作的顺序限制对提高事务系统的性能至关重要.Kolli 等人[35]首先分析了理想情况下,即软件可以识别出所有持久性写之间的顺序依赖时系统能够实现的最小持久化关键路径长度,并以此为基准优化现实的工作负载.文献[35]总结了4 种持久化模型,分别是严格持久化(strict persistency)、阶段持久化(epoch persistency)、链持久化(strand persistency)以及乐观同步(eager sync).严格持久化限制任何2 个持久化操作之间的顺序,保证强一致性,但是由于严格序列化,导致事务无法乱序持久化,降低事务吞吐率.阶段持久化宽松了持久化顺序的限制,要求保证2 个阶段之间的持久化顺序.链持久化将程序的执行划分为链,新的链将会得到之前的事务持久化顺序限制,从而保证每个链都是独立的,链内通过持久化屏障保证顺序.乐观同步利用Intel x86 提供的缓存行刷新指令以及PCOMMIT 指令保证持久化的顺序以及其对外可见的顺序.Kolli 等人[35]在这4 种持久化模型的基础上进一步引入延迟提交事务(DCT)减少了持久化操作之间不必要的顺序限制,提高事务的性能.为了保证一致性,Kolli 等人[35]采用undo 日志记录数据项的变化,并为每个线程维护一个日志来提高可扩展性.Kolli 等人只关注静态事务,即执行前可以知道事务修改的内容,同时利用校验和的方式保证日志的完整性,降低每次写日志所需的内存屏障.由于使用了延迟提交,需要保证事务之间的顺序,他们使用向量时钟来排序事务,在系统崩溃后逆序恢复数据.DCT 在保证事务一致性时需要完成2次数据持久化,即undo 日志项和写入对象数据本身,因此该方法写放大为2.DCT 中静态事务的先验性知识并不适用于通用的场景,无法预先获取现实场景中事务修改的数据集合.
与DCT 不同的是,Kamino-Tx[36]支持动态事务,它主要关注如何减少事务提交关键路径上耗时较长的对象拷贝操作,通过对事务逻辑执行单元中的数据对象维护2 个版本,将数据拷贝操作移出了事务提交的关键路径,缩短了事务的提交延迟.传统的事务一致性机制如预写日志以及CoW 等,它们需要在事务提交之前持久化旧版本的数据.由于持久化内存写延迟较高,Kamino-Tx 选择维护一个后备版本的堆结构,事务在执行过程就地读取或更新主区域数据对象,提交之后将本事务的修改拷贝到后备堆区域中,缩短了提交延迟.这种后备堆区域本质上也是一种undo 日志.然而直接备份整个堆空间将导致持久化内存中的内存开销翻倍,Kamino-Tx 提出只备份频繁访问的数据对象,利用一个并发的哈希表来查找对象是否已经备份.系统支持设定备份空间的大小,当空间超过设定阈值时,将利用LRU 算法替换备份区域的对象并更新查找表.Kamino-Tx 在持久化内存中记录事务修改的内容,将更新数据从主区域拷贝到备份区域或者在系统崩溃后从备份区域恢复.需要注意的是,Kamino-Tx 在持久化内存上备份热点数据可以显著提高具有倾斜特征的工作负载下的事务性能,但是直接在非易失性内存上同时记录事务修改内容会增加持久性写的开销.
为了减少Kamino-Tx 的持久性指令带来的开销,Romulus[37]机制利用高速主存记录修改的内容,在持久化内存中维护数据的双副本,并存储在2 个不同的区域,即主区域和后备区域.由于在某个时间点,Romulus 保证主区域和后备区域中的数据副本状态至少存在一个是一致的.因此,系统崩溃后直接恢复整个数据存储区域.Romulus 将持久化内存空间分为3 个区域:控制头、主区域以及后备区域.控制头存储了系统的元数据信息,其中最重要的是事务状态信息,包括“空闲”“执行”“拷贝”3 种状态.“空闲”即系统内没有事务执行,“执行”表示当前有事务正在执行并且修改了内存状态,“拷贝”状态表示事务执行完成正在备份事务的更新.Romulus 利用这3 种状态判断系统崩溃后如何恢复.后备区域是主区域的一个备份,事务执行过程中直接修改主区域,事务提交之后将更新拷贝到后备区域.为了减少数据拷贝开销,Romulus 在修改主区域的同时在DRAM 中生成redo日志(此日志不需要持久化),记录主区域中被修改的地址以及修改的大小,因此事务执行结束后只需要拷贝redo 日志中记录的数据区间即可.Romulus 避免了重定向读,读取事务仅需要单个指令加载数据,并且将每个事务的内存屏障数目限制为4.因此,Romulus 在读场景下的性能可以和线程数量呈线性关系,并且较少的持久性指令和较低的写放大可以提高事务整体性能.但是由于Romulus 中的主、备区域大小是相同的,因此事务数据存储空间只能使用持久化内存区域一半的空间,显著降低了持久化内存的空间利用率.
ATOM[38]采用缓存行级别的undo 日志来保证持久化内存更新的数据一致性,利用内存控制器(硬件层次)创建日志.日志控制器位于L1 缓存,每个store操作都创建一条日志.由于undo 日志只需要保存事务开始前的数据版本,因此ATOM 利用一个日志位标记缓存行是否已经被记入日志,避免重复的日志持久化操作.undo 日志的性能瓶颈在于强制了日志操作与数据更新之间的顺序,因此,ATOM 在硬件层面将日志与数据发送到同一个内存控制器,更新缓存之前首先在内存控制器对缓存行上锁并写日志.同时缓存控制器可以将数据更新到存储缓冲区,不需要等待日志的持久化完成,等待日志持久化完成之后对缓存行解锁使数据可以写回至持久化内存,保证了日志与数据之间的持久化顺序.在缓存不命中时,内存控制器加载到的数据是undo 日志需要记录的版本,因此内存控制器直接对缓存获取锁,向缓存传递数据时添加日志位,避免了日志控制器向内存控制器的冗余数据传输.ATOM 利用类似数据库中组提交的思想将7 个数据缓存行与一个元数据缓存行作为一个日志单元,减少57%的日志写操作,并通过跟踪日志更新的依赖关系和硬件更新的数据,将日志更新移出数据原子更新的关键路径,提高事务执行效率.ATOM 通过更新缓存行级别的undo 日志以及记录数据对象本身实现事务一致性,在内存控制器对缓存行中的日志进行修改时所使用的锁并未持久化,因此ATOM 的写放大为2.
2)基于redo 的日志事务管理系统
Mnemosyne[39]方法实现了一个简单的持久内存编程接口,并且提供了4 种不同粒度的一致性保障机制:单字更新、追加更新、影子更新以及就地更新,这4 种机制随着通用性的提高逐渐呈现性能下降的趋势.Mnemosyne 中利用高性能的 raw word log(RAWL)日志结合现有的软件事务内存系统TinySTM[47]来支持持久化内存事务.Mnemosyne 支持在代码中用“atomic”关键字注释事务代码段,编译器识别出事务代码后触发底层TinySTM 中提供的事务原语,系统为每个线程维护一个基于RAWL 的日志,事务更新数据时在DRAM 中创建redo 日志记录更新的地址及数据,事务提交后日志刷回到持久化内存上持久化,数据原位置中仍然保留着未更新的数据,当访问数据时首先检查数据是否被更新,若被更新则到对应的日志中读取最新的版本.为了保证系统的可扩展性,Mnemosyne 将地址空间分区,每个区域维护一个单独的锁,当访问持久化内存空间时需要对该区域获取锁,若已经被其他事务持有锁则该事务崩溃.Mnemosyne 的优势是支持同步或异步地将日志中的数据刷回到原位置,不需要等待写回操作,直接提交事务,缩短了事务提交的延迟.但是,Mnemosyne 的直接利用为DRAM 主存设计的TinySTM 提供事务语义,忽略了持久化内存的内部特性,无法充分利用持久化内存的性能优势.
为了进一步提高持久性事务的性能,LOC[40]将持久化内存事务系统中的顺序限制区解耦为事务内的顺序执行和事务间的顺序执行:事务内的顺序执行指事务提交之前必须等待本事务所有更新的数据全部持久化,并且更新提交标记;事务间的顺序执行指不同事务间持久化的顺序一定要与它们提交的顺序一致.这2 个顺序执行原则保证了系统的崩溃一致性.但存在由于事务提交标记以及事务间的顺序执行等待导致事务性能大幅下降的问题.LOC 提出“积极提交”与“推测持久化”2 种策略分别解决此问题.“积极提交”通过特殊的日志组织方式,即采用数据块组来存放日志及其元数据,1 个数据块组包含7 个数据块和1 个元数据块.并利用基于计数的事务提交协议,即统计事务修改的数据块数设置阈值,将日志的完整性检验推迟到了恢复阶段,而不是在提交之前等待日志完整的持久化完成,解决了事务内顺序执行的限制,从而降低了事务提交的延迟.“推测持久化”策略通过设置一个推测窗口(sp-window),允许sp-window 内的事务可以乱序地持久化,但是可以保证事务顺序提交.为了实现“推测持久化”,LOC 利用多版本CPU 缓存(mv-cache)保证多个线程并发执行并且跟踪记录事务的提交顺序.多版本缓存将窗口内多个事务的修改都暂存在缓存之中,保证了不同事务重叠写的可恢复性,并且可以将多个修改合并写回持久化内存.恢复阶段以整个推测窗口为单元执行整体恢复,一个事务成功提交的条件为该事务满足计数提交协议并且同个窗口中之前执行的事务都已经成功提交.LOC 旨在提高事务持久化性能,首次分析了事务之间的依赖关系并分类阐述,针对事务内部与事务之间的依赖关系,减少持久化的顺序开销,在硬件层面以很小的开销完成事务的执行管理并提供了较高的处理效率.但是,LOC 实现中使用WAL 机制,在事务执行时需要利用日志记录修改对象的新版本,并且为每个事务分配1 个日志块记录事务执行状态.在事务执行完成后,LOC 通过更新指针修改数据版本.通常一个指针的大小小于数据对象本身.LOC 为了提高事务崩溃恢复性能,通过静态组织日志空间机制利用1 个元数据块和7 个日志数据块组成日志数据块组进行持久化存储.因此,LOC 的写放大大于2.
Giles 等人[41]提出一种基于软件的写辅助持久性(SoftWrAP)机制,解耦事务生命周期路径,分离事务执行和持久化路径.SoftWrAP 在持久化内存中维护一个redo 日志来保证事务更新的原子性,日志中记录数据更新后的值.该日志仅在崩溃恢复时使用,通过缓存行追加写的方式进行有效更新,并定期删除无效日志.SoftWrAP 使用软件别名机制,允许在后台中重定向持久化内存中被管理的区域数据,从而可以在DRAM 中直接修改,减少缓存行淘汰顺序限制带来的性能瓶颈,并且可以加速主存访问持久化内存的访问效率.SoftWrAP 利用2 个无锁别名表来记录重定向的关系,一个处于活跃状态用来接收新的请求,另一个用来将数据写回持久化内存从而可以释放日志空间,实现了事务执行与持久化的并发执行.由于SoftWrAP 使用双缓存别名表,1 次读操作可能导致3 次重定向,降低读操作的效率.并且其采用的1 对1 页级别映射引入了较大的内存开销,同时SoftWrAP 在保证事务一致性的前提下额外持久化一些元数据,因此该机制的写放大不小于2.虽然Soft-WrAP 声称可以与并发控制解耦,但是为了保证事务正确的隔离性,其仍然需要使用别名表等机制对系统作出较大的修改,无法透明支持事务管理系统.
DudeTM[42]利用“影子内存”(shadow DRAM)来避免redo 和undo 日志存在的问题,DudeTM 提供了一个开箱即用的持久化组件,可以结合任何现有的STM 或HTM 共同构建一个持久内存事务系统.因此,DudeTM 并发机制依赖于事务内存进行实现.DudeTM以内存页为单位将持久化内存上的内容映射到DRAM中,事务执行过程中原地更新或读取DRAM 中的影子页,避免了redo 日志带来的重定位读以及undo 日志频繁地刷回持久化内存操作.事务更新影子页的同时构建redo 日志,记录修改的内存地址和内容,执行完成之后需要将日志持久化到持久化内存.为了提高事务的可扩展性,每个线程维护一个日志.DudeTM在 “再现”阶段利用构建的redo 日志将更新写回,日志的写回顺序必须与事务的执行顺序一致,否则无法保证一致性.为了保证事务的串行化执行,DudeTM利用一个全局递增的事务ID 来为每一个事务分配唯一的标识进行排序,并将日志顺序写回持久化内存.但是由于每个线程都需要频繁的读取并更新全局的事务ID,导致其成为整个系统的扩展瓶颈.并且DudeTM 只使用单一的线程来执行“再现”过程,写密集场景下单线程的数据刷回操作会造成很高的延迟,同时日志回收产生相关的同步成本也会成为阻碍系统可扩展性的关键因素.
Pisces[43]是一个“读友好”的事务系统,通过快照隔离机制降低事务隔离级别从而获得了更高的事务性能.为了利用缓存局部性并减少快照隔离数据的查找开销,Pisces 采用双版本并发控制来实现快照隔离,每个对象只有原始版本以及利用redo 日志构建的新拷贝版本.当事务试图更新一个对象时,它创建一个原始对象的拷贝并直接修改拷贝对象,事务提交时再将新版本数据拷贝至原始对象.读操作根据事务的时间戳来判断读取新/旧版本,并发写操作利用对象锁来避免冲突.但是,事务提交时旧版本的数据仍可能被其他线程正在运行的事务访问,因此不能简单地将新版本数据直接拷贝回原始版本.Pisces利用RCU(read copy update)机制[48]确保写回操作的正确性,即写回之前需要等待所有可能访问旧版本数据的事务(开始时间小于本事务结束时间的所有事务)都结束后才将新版本写回.Pisces 的优点是利用3 阶段提交法避免了Optane PM 持久化开销对读操作的性能影响.首先是持久化阶段将事务的日志持久化到Optane PM;之后是并发提交阶段,在这一阶段保证更新的数据对其他事务可见;最后是写回阶段,在这阶段执行RCU 机制并将新版本数据写回到原始对象.3 阶段提交法使事务的更新不必等待耗时较长的数据持久化操作结束即可对其他事务可见,实现了近乎非阻塞的读操作.并且,Pisces 的快照隔离可以确保事务的无锁读取操作,进一步地提高读场景下的性能.但是,Pisces 采用的双版本并发控制机制和日志回收期间的同步写同样会影响事务的可扩展性.
TimeStone[34]在Pisces 的基础上进一步利用多版本并发控制(MVCC)来提高系统的可扩展性,并且首次提供了多种隔离级别.TimeStone 使用多层日志结构TOC 来保证数据崩溃一致性并最小化写放大问题,MVCC 实现事务系统的高扩展性并以此为基础提供了多种隔离级别.当一个线程上的事务更新数据对象时,首先在当前线程的TLog(位于DRAM)创建数据副本并直接更新,同时在OLog(位于Optane PM)记录执行的操作保证立即持久化,事务成功提交后会利用ordo 机制[49]获取事务的提交时间,并将TLog中的副本添加到对象的版本链中.当事务读取数据时,需要在对象的版本链中查找提交时间早于本事务开始时间并且最新的版本,获得数据的引用,使得事务并行性得以提升.当TLog 或者OLog 空间不足时TimeStone 会执行检查点机制,仅需要将被更新对象的最新版本持久化到CLog(位于Optane PM)上,减少对Optane PM 的直接访问.由于日志中的数据可能正在被引用,TimeStone 采用MV-RLU[50-51]的策略回收日志,等待所有可能引用待回收数据版本的事务结束之后再执行回收操作.TimeStone 利用多层日志架构机制最小化写放大开销,并且支持3 种事务隔离级别:快照隔离、可串行化、序列化,允许用户可以通过其提供的接口在事务执行时指定隔离级别.TimeStone 的实验结果表明,TLog 减少了日志写入,仅有6%的TLog 被写入CLog,因此TOC 机制有效降低了事务的写放大.
3)基于CoW 的日志事务管理系统
Wang 等人[44]通过实验发现持久化内存事务系统的扩展瓶颈在于不同线程事务之间的依赖与冲突,并且基于时间戳的持久化顺序引入了不必要的依赖.因此他们提出了SP3 方法来提高多核场景下事务系统的并发性能.SP3 利用OCC 并发地执行和提交事务.SP3 首先创建一个对象的索引表,将对象映射到一个控制条目,这个控制条目包含了对象的锁、最新版本的指针以及最近一次更新的事务ID 等.在OCC的读阶段,事务使用无锁机制读取数据并添加到读集合(read set),事务的更新暂存到写集合(write set)中.SP3 采用CoW 策略,即修改对象前先拷贝,并直接在拷贝版本上更新,因此写集合只需要记录拷贝对象的新地址.同时SP3 也会生成redo 日志,这一阶段最重要的是需要记录事务之间的依赖关系.事务访问或更新对象前都需要先访问其控制条目,获取该对象最近修改的事务ID 并添加到依赖集合中.SP3 在事务提交阶段引入了预测持久化机制来提高并行性,即在更新持久化之前允许更新对其他线程可见.提交阶段首先执行OCC 并发控制协议验证依赖数据是否已经被更新,通过比较访问依赖集合中对象的控制条目记录的最新地址与读集合中记录的地址判断是否发生冲突.验证完成之后将暂存的写集合映射到控制条目中,即将对象的新地址以及本事务ID 更新到控制条目中,此时事务的更新将对其他线程可见.之后持久化日志以及依赖集合等待其依赖集合中的事务全部执行结束后提交事务,保证崩溃后的可恢复性.在恢复阶段通过每个事务的依赖集合构建有向无环图,并删除未提交事务的日志.有向无环图构建成功后利用拓扑排序决定恢复阶段事务执行的顺序.SP3 目标是提高多核之间的事务可扩展性,无需等待事务中的数据持久化阶段完成即可允许更新后的数据对其他线程可见,减少因事务持久化时间过长而引发的事务冲突中止率.SP3 的逻辑时间戳可以提高系统的扩展性,但是全局的对象索引表依旧会成为系统扩展的瓶颈.SP3 在日志中记录事务操作对象的指针变化,通常小于对象本身,因此该方法写放大小于2.
Wu 等人[45]观察到Optane PM 的特性,即随机写与顺序写之间有较大的性能差距,并基于避免较小的写和尽量顺序写2 项原则设计以CoW 为基础的原型系统.由于CoW 机制的元数据更新导致很多较小的写操作,因此ArchTM 将内存分配元数据、对象CoW 索引元数据放置在了DRAM 中以减少Optane PM 上的元数据写.同时利用注释机制来保证崩溃一致性,即将对象的元数据与对象本身存储在一起.为了尽可能地提高顺序写,ArchTM 中采用了全局单链表内存分配结构对小对象数据项分配空间,充分利用空间局部性.因为连续分配的对象很可能会连续访问或修改,每个线程有自己的私有分配链表,只有私有分配空间耗尽才会从全局链表中获取新的空间.由于对象以64 B 为单元进行分配,这种方式容易导致内存碎片,ArchTM 中使用后台线程以4KB 粒度统计空间利用率,当小于50%时就对数据进行聚合.通过Optane PM 感知架构,ArchTM 避免了小的数据写入,聚合可合并的数据,并将其写入Optane PM,充分利用Optane PM 硬件内部的优势.为了提高事务吞吐率,ArchTM 需要维护额外的元数据,同时为了确保事务崩溃一致性需要将这部分元数据持久化,因此ArchTM 的写放大为1~2.
3.3 面向新硬件的软硬协同事务技术研究
HTM 仅支持事务的ACI 属性,持久化内存可以提供内存映射的持久化数据存储,简单的编程模型可以将2 种新型硬件结合在一起.但是大部分软硬件协同策略为了保证事务的一致性语义,使用额外的机制集中式维护事务执行顺序.事务的集中式处理不仅会影响系统的吞吐率,还会限制事务系统在现代多核架构上的可扩展性.明确软硬协同策略的缺点并提出新型软硬协同的事务协议,对于新型硬件环境下的软硬协同事务管理系统至关重要.表5 对新硬件的软硬协同技术进行了总结分类.硬件是否修改代表该研究对硬件是否进行修改,以及代表该机制移植性是否简便.HTM 区域代表研究中HTM 控制的区域空间.日志机制代表研究采用何种机制加速事务处理以及保证崩溃一致性.持久化代表研究中允许数据持久化是否可以等待,以便于减少频繁的写入.可扩展性则代表该机制是否在多线程模型下随着线程数量的增加吞吐率也随之增加.事务标识意味着研究方法如何区分事务的唯一性以及事务之间的顺序.
由于RTM 受限于L1 缓存的区域大小,数据只能短暂滞留在LLC 缓存行中,并且LogTM-SE[25]在中止事务时会阻塞其他修改同样数据单元的事务并发执行.为了快速实现ACID 编程模型,DHTM[52]使用HTM 与非易失性内存相结合,从而加速事务处理性能.DHTM 采用一种基于HTM 的redo 日志,在内存中维护一个单独的区域,允许写入覆盖缓存中先前的值,提供持久化和原子性保证,并对L1 中的缓存行设置标签位,目的是跟踪读取和写入集合,从而将RTM 从L1 缓存扩展至LLC 中.为了保证隔离性,推测性读取的缓存行必须在事务提交之前交由另外一个处理器修改,并且推测行读取的缓存不得被修改和写入.当正在执行的事务的缓存行从L1 缓存溢出时,事务会中止执行.因此,DHTM 维护一个溢出列表,记录缓存行的状态以及内容地址.为了减少从LLC 到持久化内存的数据移动,并利用日志先于数据落盘的特性,DHTM 在LLC 上创建时间缓冲窗口,使用写合并机制减少数据持久化延迟.DHTM 通过减少持久化开销提高了事务整体性能,但是DHTM在硬件中构建redo 日志为事务提供的崩溃原子性操作,无法扩展到其他高级语言的持久化模型中.并且,合并写机制仍然会将冗余写入这一过程放置在持久化内存的关键路径上,可能会增加后续事务延迟,从而影响事务管理系统的服务质量.

Table 5 Classification of Soft/Hardware Co-design in New Hardware Environment表5 新硬件环境下软硬件协同设计的分类
cc-HTM[53]不需要对硬件作任何修改,它将事务分为执行阶段和持久化阶段:执行阶段利用Intel 处理器提供的HTM 原语并发执行,为了防止缓存替换导致的持久化内存中的数据不一致,写操作会被映射到DRAM 中的 ALIAS TABLE,同时在易失性的缓存中生成日志,事务执行结束后再将日志持久化到持久化内存,避免HTM 事务执行期间访问持久化内存延迟过高导致的事务崩溃.执行阶段结束之前,cc-HTM 用RDTSCP 指令获取“持久化时间戳”,并以此为序将事务放入优先队列,事务进入“等待”状态.专用持久化线程按照顺序从优先队列取出事务并将其更新的数据写回到持久化内存上的原地址,形成一个符合一致性的“检查点”,写回后通知事务结束等待并提交.cc-HTM 还提供一个延迟参数,允许事务在持久化完成之前提交事务,应用可以根据自己的需求权衡更短的延迟与更高的一致性来设置参数区间.cc-HTM 利用递增的全局事务计数器来作为开始与结束的时间戳,并且采用只有一个持久化线程来从优先队列取出事务并将其更新写回到原位置.cc-HTM 允许从事务关键路径中移除延迟较大的内存屏障指令,由上层应用决定持久性时机,但是这种方法会增加上层应用的复杂性.
NV-HTM[54]与DudeTM[42]类似,同样使用“影子页”以及redo 日志的方式解耦事务的执行与持久化.NV-HTM 使用CPU 提供的物理时间戳来作为事务ID 的唯一标识,支撑事务的序列化执行顺序,避免了全局逻辑事务ID 带来的扩展瓶颈.每个线程记录当前正在运行的事务时间戳,事务提交之前需要等待所有线程中更早开始或提交的事务结束以保证一致性.NV-HTM 通过检查点策略来将日志写回释放日志空间.首先对每个线程的日志结尾指针进行一个原子快照,快照之前的日志都是可以回收的区域,使用反向过滤检查点机制反向遍历线程的日志快照,以更新的地址为键、内容为值创建一个键值对,只记录最近的更新并且合并相关的数据项,减少回写次数;遍历完所有的线程后将键值对中的内容写回持久化内存,并刷回缓存;最后利用“检查点日志”(CPLog)原子性更新所有线程日志的起始指针.NVHTM 通过将日志刷新延迟到事务提交之后,消除了事务执行关键路径中的日志刷新延迟.但是,NVHTM 需要事务按照顺序线性提交来保证一致性,这样引入了过多的等待,导致系统性能下降.
Avni 等人[55]发现随着处理器核心数目的增加,基于锁的原子性操作越来越成为系统的瓶颈,利用HTM 可以避免这个问题,但HTM 无法直接访问持久化内存介质使其难以构建HTM 和持久内存的事务系统.Avni 等人提出一种PHTM 方法,对硬件作出修改,同时引入了新的指令透明刷回(TransparentFlush,TF).TF 支持在HTM 执行过程中将数据从缓存刷回到持久化内存并且不会使事务崩溃,也不会使缓存行失效,Avni 等人[55]利用TF 指令结合HTM 与持久化内存构建了PHTM.事务执行过程首先在线程自己的缓存中修改对象并构建undo 日志,此时的修改内容是私有的,外部没有可见性.在事务提交之前,PHTM 首先利用TF 指令持久化本事务的日志,提交之后持久化提交状态标记并将事务的修改写回到持久化内存中的原始位置,写回成功之后即可回收日志空间.PHTM 利用标记来保证每个地址最多允许出现在1 个日志中,这样避免了日志回收过程中多线程日志之间的通信.标记类似于一个写锁,事务写数据地址之前需要等待标记被释放才能继续执行.PHTM 仅对日志中记录的部分事务顺序执行,通过额外的锁机制实现,可以有效防止发生冲突的事务刷新日志,同时保证重放阶段的正确性.但是,PHTM 在事务执行期间一直持有锁直至事务的所有日志都刷新到持久化内存才释放.在此期间,PHTM 可能遭受锁争用,从而引发大量的事务中止.
PHTM 仅允许顺序执行事务,无法支持硬件和软件之间的事务并发执行,这将导致硬件事务内存在回退时会中止软件事务内存的执行,降低事务并发性.PHyTM[56]提出一种基于持久化内存的混合事务机制,提供3 种事务路径.首先是基于软件事务内存(STM)路径,PHyTM 使用类似2PL 的悲观并发控制协议,对相应数据项获取锁阻塞其他事务访问.STM路径通过日志回放机制实现数据持久化操作.其次是Slow HTM 路径,不同于STM 路径的是它无需获取写入地址的锁,而是只需检查写入地址的锁状态.由于HTM 本身的特性,Slow HTM 可以提供原子性操作,因此该路径下的事务无需等待回放日志即可实现数据持久化写入.如果事务在执行阶段和验证阶段发现冲突,则中止该事务.当事务重试次数超过阈值时,则交由STM 路径执行.最后一个是Fast HTM 路径,允许事务在读取数据时使用类似数据多版本的机制,仅保证当前数据在某个状态下的一致性,无需查看锁的状态.为了保证数据一致性,该路径下的每个事务通过验证STM 路径上是否有正在写回阶段的执行事务.如果有,则中止该事务;否则,继续处理.当事务中止次数超过阈值时,事务会交由Slow HTM 执行.Fast HTM 在只读场景中没有额外的同步开销.同时,为了减少锁同步开销,PHyTM 维护一个类似数组结构的共享地址锁存储体,通过散列计算内存中的地址获取唯一的锁存储位置,防止对同一位置的内容重复获取锁.PHyTM 通过自主切换事务执行路径机制有效减少事务并发执行时由于回退引发的事务中止,但是PHyTM 仅关注了软硬件之间的事务并发执行,忽略了可扩展性对事务性能的影响.
NV-PhTM[57]指出在持久化内存系统中提供事务模型,软件与硬件事务内存各有优缺点.软件模式更加灵活且不受限制,但是对于短事务造成很严重的性能下降;硬件模式开销更小,效率更高,但是受到硬件资源的限制,并且提供的是一种“尽力而为”机制,不保证事务的成功提交.因此,NV-PhTM 提出结合硬件与软件的模式,将系统分为3 个阶段,分别对应执行硬件事务内存(HW),软件事务内存(SW)以及串行化模式(GLOCK)这3 种不同的路径,并利用启发式动态选择最合适的执行路径.HTM 利用NVHTM[54]结合CoW 技术将持久化内存区域映射到DRAM 中,软件事务内存基于PSTM[55]结合日志提供事务模型.启发式阶段转换综合考虑系统的事务崩溃率、事务大小以及日志剩余容量等因素.比如事务较小则会切换到HTM 模式,多次资源受限导致事务崩溃将会切换到软件模式,崩溃率过高将会进入到串行化执行等机制.
Crafty[58]通过构造无损undo 日志(nondestructive undo logging)来解决HTM 与持久化之间的矛盾,即在事务提交前将日志持久化,但是在HTM 执行过程中持久化会导致事务崩溃.“无损undo 日志”将事务的完整执行过程分为2 个HTM 事务和一次日志持久化操作:1)第1 阶段Crafty 利用HTM 执行事务,每一次修改数据前需要构建一条undo 日志,在这一阶段的结尾,HTM 事务执行前后的新旧数据都具有可见性,利用暂时还没有持久化的undo 日志逆序将这个HTM 事务所作的更新还原并利用新数据构建redo 日志.2)在上一个HTM 事务结束之后与下一个HTM 事务开始之前将undo 日志持久化.3)事务在这个阶段的开始时利用逻辑时间戳来检查第1 阶段结束后是否有事务成功提交.如果没有,则没有发生冲突,Crafty 利用HTM 与第1 阶段构建的redo 日志更新数据;否则,需要通过验证阶段进一步检查是否真正有冲突产生,验证阶段即重新执行事务逻辑,检查undo 日志中每一个条目地址所在位置的值.如果没有冲突则可以提交事务,否则需要崩溃事务重新执行.Crafty 使用2 个策略保证事务的执行.当事务间竞争激烈导致的系统频繁崩溃且一段时间内没有事务成功提交时,系统将回退到单个全局锁(single global lock,SGL)模式,即事务执行前首先需要验证是否有事务获取了全局锁,如果有则直接中止.这项策略保证了系统至少有一个事务可以正常进行.其次,Crafty允许将事务拆分成多个小的事务执行,防止缓存不足而导致的崩溃,当事务更新的数据达到预设的阈值后将构建undo 与redo 日志.但是,Crafty 可能出现事务重复执行的情形.因为在使用HTM 启动事务时,Crafty 需要使用全局时钟检查该事务是否是首次执行.如果验证失败,则需要重新执行事务.在高并发时全局时钟的更新可能会产生争用,导致事务频繁执行,产生额外开销.
Castro 等人[59]为了更好地发挥HTM 和Optane PM的性能,提出一种可扩展的持久硬件事务 SPHT.SPHT 不需要额外的硬件支持,就可以提供强一致性,即所有成功提交的事务及其依赖事务在系统崩溃后都可以被恢复.为了避免顺序持久化日志带来的扩展性瓶颈,SPHT 允许不同线程的事务能够并发刷回日志.每个线程记录当前正在执行的事务ID 及其持久化标记,当时间戳小于等于当前事务ID 的事务都全部完成持久化操作,当前事务才可以成功提交.全局持久化的“提交标记”记录最新的事务ID,用作恢复阶段找到最新具有一致性的恢复点.多个事务并发提交时,只有具有最大时间戳的事务会更新标记,避免了Optane PM 上冗余的数据写入而引发的高延迟以及线程间的争用.目前的日志回写阶段具有2 个扩展瓶颈:1)必须遍历所有线程的日志才能确定日志的执行顺序;2)必须执行顺序回写日志操作来保证一致性.为了解决这2 个瓶颈,SPHT 将日志按照事务的时间戳顺序用指针链接起来,不再需要遍历日志来构建事务间的顺序关系.同时,SPHT 将Optane PM 内存区域分区,不同的日志写回线程写入不相交的区域,这种空间分片机制使日志回写操作得以并行扩展.
3.4 小 结
新型硬件中的事务管理系统的2 个基本要素为崩溃一致性和事务并发性能.崩溃一致性需要通过额外的日志等机制保证数据一致性[60-61],顺序化和持久化操作可能会对事务并发性能造成影响.同时,事务并发机制为了提高性能,可能会乱序执行并提交事务,这也会对崩溃一致性造成影响,二者的关系相辅相成.目前新型硬件上的事务管理系统使用数据库中广泛使用的技术保证崩溃一致性,通过比较观察得到5 点结论:1)对于更新数据较多的场景,使用redo 日志可以使事务系统达到更高的性能;2)对于读为主的工作负载,使用undo 日志可以获取更好的性能;3)CoW 解决了日志中的2 次写入问题,但是复制开销会产生写放大.4)redo+CoW 混合机制可以灵活应用于事务系统,提高事务系统性能.比如SoftWrAP[41]和DudeTM[42]利用该机制减少写放大和写入次数.并且,软硬结合的事务系统如cc-HTM[53],NV-HTM[54],NV-PhTM[57],SPHT[59]使用该机制获得了更高的性能.5)事务应避免昂贵的持久化内存指令使用,尽可能地使用合并写机制.对于事务并发性能,LOC[40]和SP3[44]等机制的目的是减少硬件顺序化开销.Pisces[43]和TimeStone[34]等机制通过提供不同的隔离级别有效提高不同工作负载下的事务并发性能.ArchTM[45]和SPHT[59]充分利用Optane PM 内部特性,打破了事务管理系统的可扩展性瓶颈.总之,面向新型硬件的事务管理系统可以通过修改事务提交顺序和降低事务持久化开销,在保证数据一致性的前提下减少额外的冗余数据写入,实现高可扩展性的并发控制协议,从整体上提高面向新型硬件中的事务管理系统性能.
4 未来展望
新型硬件具有与传统硬件不同的特性,如HTM支持原子性写入,持久化内存既可以保证类似主存的高速访问,又可以提供二级存储的非易失性.现有的事务管理系统无法有效发挥新型硬件的最大性能,因此需要对传统事务管理系统中的关键路径和技术路线进行重新抽象化,结合现实场景中的业务需求进一步地对新型硬件环境下的事务管理系统进行设计.
1)设计新型硬件环境中多核架构下的并发控制协议.NUMA 架构已经成为当前服务器的主流趋势,未来可能出现数十核乃至上千核的平台架构.跨NUMA 节点的数据访问会造成一定的开销和访问延迟.虽然传统事务管理系统中已经针对NUMA 架构下的数据访问进行了一系列的优化,但是目前新型硬件环境下的并发控制协议并没有对此进行重新设计.NUMA 架构已经成为了制约新型硬件环境下并发控制协议的前置放大器,事务无法具有高扩展性.并且随着业务场景的工作负载日益复杂,不同场景下的应用程序语义与不同并发控制协议之间的结合各有优势.如何感知程序语义、智能化实时调整并发控制协议是未来的研究工作.虽然当前其他新型硬件如ReRAM 技术尚不成熟,没有在工业界大面积推广使用,但这种存算一体化的新型硬件可以打破现有的冯·诺伊曼架构瓶颈,提供高性能、低功耗的硬件服务,减少数据从内存单元移动至计算单元的开销,这为研究者带来更多的机遇与挑战.但是,如何高效利用存算一体化新型硬件的内部特性设计并发控制协议可能是未来的研究路线,如带宽、访问粒度、硬件介质内部数据处理最大并行度等维度对事务管理系统的性能影响.并且,如何保证基于存算一体化事务管理系统的一致性可能会得到更多的关注.
2)设计异构事务管理系统.当前HTM 和非易失性内存结合的工作主要考虑了事务管理系统执行路径如何实现1+1 > 2 的高性能优势,并没有针对硬件本身特性进行优化,也没有在性能和硬件寿命之间进行权衡.非易失性内存的持久域已经扩展到LLC层次,可以有效延展HTM 的区域.各种新兴的异构硬件架构正在对现有的体系结构产生挑战.如CPU和GPU/FPGA 结合为上层应用提供更高效率和低延迟的处理性能.但是,由于异构硬件本身硬件特性的不同,无法在不同的工作负载下发挥最大性能.因此,研究者可以进一步考虑异构硬件下的耦合事务执行路径,抽象化表征属性设计事务模型.并且,服务质量是衡量事务管理系统的一项重要指标,即事务管理系统在保证高并发的同时保障尾延迟被用户所接受.新型硬件环境下的长尾延迟出现的原因主要包括事务并发原语冲突和持久化屏障开销大.异构事务管理系统可以从底层构建与传统事务系统不同的组织布局,消除事务执行冗余路径.异构事务管理系统可以进一步设计相关程序模型,如异构一致性模型,该模型从底层构建原子性存储,从而提供系统可靠性服务.
5 总结
利用新型硬件可以为事务管理系统提供高效的运行效率,但是设备工艺本身的不足同样会成为新的挑战.由于HTM 受限于区域容量限制,无法从根本上减少事务冲突率;并且非易失性内存访问粒度、读写不均衡、持久化屏障开销大等问题制约了事务管理系统性能,导致事务管理系统无法真正发挥高并发、可扩展性强的优势.
本文从新型硬件本身特性、事务层面特性和持久性路径等方面出发,介绍了目前相关研究工作,并且结合实际应用场景需求给出了未来基于新型硬件的事务管理系统的重要研究方向.未来复杂的业务需求对事务管理系统的设计也提出了更高的要求,因此相关研究人员要结合新型硬件特性,立足于未来存算一体化的发展趋势,设计智能感知事务管理系统,保证新型硬件环境下的事务管理系统的可靠性.
作者贡献声明:胡浩负责搜集相关研究工作以及文章整体撰写;梁文凯负责硬件特性分析并协助文章撰写;李诗逸负责讨论论文框架和修改论文;王鸿鹏负责对目前研究热点和未来发展方向的内容进行补充;夏文负责文章框架调整、整体思路的指导,并修改论文.
