一种wandering B+tree 问题解决方法
2023-03-27杨勇鹏蒋德钧
杨勇鹏 蒋德钧
(中国科学院计算技术研究所 北京 100190)
(中国科学院大学 北京 100049)
随着大数据时代的到来和发展,数据量呈现爆炸式增长.根据IDC(International Data Corporation)的预测,全球数据领域将从2018 年的33ZB 增长到2025 年的175ZB[1].为了满足数据存储的需求,数据存储系统的规模和存储介质的容量都在不断地增长.各大存储设备厂商纷纷推出大容量存储设备来满足大量数据存储的需求.例如,西部数据已经推出单盘容量达18TB 的机械硬盘(hard disk drive,HDD)[2],和单盘容量达20TB 的瓦记录磁盘(shingled write disk,SWD)[3].存储厂商Nimbus Data 推出单盘最大容量高达100TB 的固态硬盘(solid state disk,SSD)[4].
对于HDD,文献[5]提到,Unix 文件系统只能利用5%~10%的磁盘写带宽,其他时间都消耗在磁盘寻道上.Sprite LFS[5](log-structured file system)采用日志结构(log-structured)技术,该系统假设:文件都缓存在内存中,容量逐渐增大的内存可以很有效地满足读请求的处理需求.基于该假设,Sprite LFS 着重优化写性能.Sprite LFS 的物理地址分配方式为写时分配,文件系统的元数据和数据的更新方式均为异地写(out-of-place write).Sprite LFS 将所有的写请求转换为顺序写后,几乎可以消除所有的磁盘寻道开销.基于Sprite LFS,NILFS[6]在Linux 系统上实现了日志结构文件系统.
对于SSD,文献[7-8]的研究表明:频繁地随机写请求处理,会导致严重的内部碎片,影响SSD 的持续性能表现.SFS[9]研究发现:SSD 的随机写带宽和顺序写带宽的差异超过10 倍;随机写会增加单位写请求的闪存块平均擦除次数,从而减少SSD 的使用寿命.为解决上述问题,SFS 以NILFS 为基础针对闪存介质特性,实现新的文件系统,提升系统吞吐率,降低闪存块平均擦除次数,减少SSD 元数据管理开销,从而提升SSD 寿命.
近年来,业界又先后推出了JFFS[10],F2FS[11-14]等日志结构文件系统.除了文件系统外,日志结构技术还被应用于块存储系统,例如BW-RAID[15]存储系统的ASD 子系统[16-17],ASD 系统向上提供标准块设备接口,将上层写请求转换为本地磁盘RAID 的顺序写,以提升BW-RAID 系统的吞吐率.本文把这类系统统称为日志结构存储系统.
虽然日志结构存储系统可以将所有的写请求转换为顺序写,但是因为日志结构存储系统要求数据和元数据的修改都采用异地更新的方式,它面临元数据异地更新带来的连锁更新问题.树状结构通常被用于保存元数据,例如B+tree,RB-tree(red-black tree),而一旦树状结构的某个结点执行了异地更新,就会触发递归更新树状结构,这一问题通常被称作wandering tree 问 题[18].因 为B+tree 被广泛 应用于 存储系统中,所以本文主要关注wandering B+tree 问题.
针对wandering tree 问题,现有日志结构存储系统均提出了各自的解决方法:例如,NILFS2[19]使用B+tree 管理所有元数据,引入特殊的内部文件DAT(data address translation file)管理所有B+tree 树结点;DAT 文件的每个数据块为B+tree 的树结点,在文件内的偏移作为B+tree 树结点的逻辑索引(用于索引在内存中的树结点).但是,DAT 文件的地址映射关系仍然使用B+tree 维护,以此保存逻辑索引和物理地址的映射(元数据块和数据块在物理设备上的地址),因此当DAT 文件更新时,DAT 文件的映射管理仍然面临wandering B+tree 的问题.
F2FS 采用多级间接索引管理文件映射,同样面临元数据结构递归更新问题.为了缓解这一问题带来的性能影响,F2FS 使用物理设备上固定的NAT(node address table)[11]区域存放元数据块逻辑索引和物理地址的映射关系.1 个设备上共有2 个交替使用的NAT 区域,目的是为了确保每次下刷NAT 块均为原子操作.此外,对于采用日志结构技术的块存储系统ASD 而言,它采用2 层RB-tree 管理地址映射,通过固定区域存放地址映射的反向映射来解决wandering RB-tree 问题.
综上,上述系统均使用额外的数据结构和物理设备空间管理树结点逻辑索引和物理地址的映射,以此解决元数据管理的wandering tree 问题.但引入额外的数据结构和物理设备空间,会增加系统设计的复杂度、降低写物理设备的连续度.
采用日志结构设计的文件系统和块设备系统在业界均有广泛的应用,然而针对大容量块存储系统,若采用高扇出、树操作效率高的B+tree 管理块设备逻辑地址和物理地址的映射关系,则需要解决wandering B+tree 问题,现有的块设备解决方法及日志结构文件系统的解决方法均需要引入额外的数据结构和物理设备空间.为解决wandering B+tree 问题,本文提出IBT(internal node based translation)B+tree.本文的主要贡献有3 个方面:
1)提出IBT B+tree 树结构.中间结点记录孩子结点的逻辑索引和物理地址,避免引入额外数据结构和物理设备空间.
2)提 出IBT B+tree 下刷算 法.引入每 层dirty 链表按层次管理所有dirty 树结点,自底向上按层次下刷IBT B+tree,避免递归更新树结构.
3)设计实现Monty-Dev 块存储系统,评价IBT B+tree 在写放大和下刷效率方面的优化效果.
1 相关工作
对于树状数据结构,父亲结点需要记录孩子结点的地址信息.对于需要持久化到物理设备的树结构,则需要通过在中间结点中记录的孩子结点信息,确定孩子结点的物理地址.本文将树结点在内存中的唯一标识称作树结点逻辑索引,将树结点在物理设备上的地址称作树结点物理地址.Linux 内核中的ext4,dm-btree 等模块的树状数据结构,通过中间结点记录孩子结点的物理地址访问孩子结点,因此树结点逻辑索引和物理地址相同.其中,dm-btree 使用RBtree 组织缓存在内存中的树结点,访问孩子结点时首先检查孩子结点是否在RB-tree 中,如果在则直接访问树结点,否则需要从物理设备加载.
日志结构存储系统要求树结点的更新方式为异地写,且为写时分配物理地址.如果树结点逻辑索引和物理地址相同,则在树结点下刷时需要递归更新祖先结点中记录的孩子结点物理地址,因此存在wandering tree 问题.本节分别介绍NILFS2,F2FS,ASD系统针对wandering tree 问题的解决方法.
1.1 NILFS2
NILFS2 使用B+tree 管理文件映射和inode.对于wandering B+tree 问题,NILFS2 的解决方法是:普通文件映射及管理inode 的B+tree 树结点,由一个文件名为DAT 的特殊文件管理;所有管理用户文件映射的B+tree 树结点是DAT 文件的一个数据块;DAT文件的地址映射也由B+tree 管理,该B+tree 的树结点逻辑索引与物理地址相同.

Fig.1 The case of NILFS2 user file and DAT file mapping [19]图1 NILFS2 的用户文件和DAT 文件映射案例[19]
图1 介绍NILFS2 的解决方法.图1(a)为管理普通用户文件映射的B+tree 示意图,树结点逻辑索引为vblocknr,即树结点在DAT 文件中的偏移;图1(b)为管理DAT 文件映射的B+tree 示意图,树结点逻辑索引和物理地址为blocknr.
若要读取用户文件逻辑地址为0 的块,则需要查找图1(a)所示的B+tree,访问结点Rf确定下一个要访问的孩子结点vblocknr=1;若DAT 文件的第1 号块不在内存,则通过图1(b)中所示的B+tree 查找映射,自上至下访问结点Ad,确定DAT 文件第1 号块的物理地址为4,即为结点Af的物理地址;通过查找结点Af,可确定用户文件第0 号逻辑块的物理地址为0.
图1(a)中树结点修改下刷只需要修改DAT 文件,无需递归更新图1(a);而图1(b)中树结点修改下刷时,仍然需要递归更新.
综上,NILFS2 可以解决除管理DAT 文件映射的B+tree 之外所有元数据面临的wandering B+tree 问题.因此,NILFS2 的方法可以部分解决wandering B+tree问题,但仍然存在递归更新B+tree 树结点的问题.
1.2 F2FS
F2FS 将底层设备划分为多个segment,segment是F2FS 管理的最小单元.除物理设备头部固定空间占用外,剩余每个segment 用来存放数据或者元数据,F2FS 的元数据主要包括2 类:inode 块和间接索引块.F2FS 通过inode 块存放文件信息,使用多级间接索引管理文件的地址映射.多级间接索引有着索引管理简单的优点,但是不抗稀疏,不能支持Extent.由于使用了多级间接索引,F2FS 也存在wandering tree 问题.
F2FS 的解决方法是:引入NAT 的设计,将文件系统元数据块的逻辑索引和物理地址分离;使用固定的NAT 区域存放NAT ID 和物理地址的映射关系,避免修改一个元数据块就需要递归更新上级元数据块中记录的下级元数据块物理地址;F2FS 在格式化时,按照设备大小计算出管理既定物理设备空间所需的NAT 块个数上限,NAT 区域中块数量为上限的2 倍,2 个空间存放NAT 块的不同版本,交替使用.
NAT 块管理示意图如图2 所示,图中有4 个segment,每个segment 包括512 个块,每个块大小均为4KB;每个块包括455 个NAT entry,即455 个NAT ID 到物理地址的转换;由于使用固定物理空间存放NAT,因此可通过每个NAT entry 相对于NAT 区域起始地址的差值计算得到NAT ID;每2 个连续的segment存放512 个有效NAT 块,NAT 块更新时写不同的segment,由version bitmap 标识某一个NAT 块的最新版本在哪个segment 中.因此,通过2 个segment 和bitmap 的设计,可确保NAT 块每次更新均为异地写.
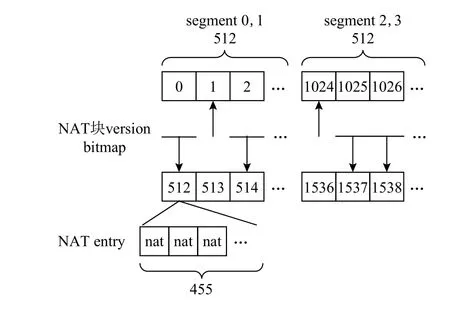
Fig.2 NAT block and version bitmap[11]图2 NAT 块和version bitmap[11]
随着设备的增大,文件系统的元数据量也在增大,因此NAT 区域就需要管理更多的NAT 块.但NAT 的随机修改会导致严重的写放大,为解决该问题,引入了journal 的设计,将最近对NAT 的修改记录在CP 区域中,journal 无可用空间时再更新NAT 并下刷.
综上,F2FS 采用NAT 和journal 的设计解决了wandering tree 问题.但NAT 设计无法利用负载的空间局部性,随着NAT 空间的增大,写放大问题会更严重,且物理设备的访问模式不是顺序写.
1.3 ASD
ASD 系统提供Linux 标准块设备语义,以虚拟块设备(virtual device,VD)的形式提供存储服务.ASD系统在物理设备之上创建一个日志结构存储池,存储池之上有多个逻辑地址空间,每个逻辑地址空间对应一个虚拟块设备VD,每个VD 向上提供存储服务.对于块设备,最重要的元数据信息是逻辑地址和物理地址的映射关系.
ASD 的元数据管理结构如图3 所示.ASD 系统使用Extent 管理一段逻辑地址连续且物理地址连续的映射关系.定长逻辑空间内的多个Extent 组成一个Subtree,多个Subtree 组成一个Group,多个Group组成整个逻辑地址空间.Group 信息常驻内存,Subtree和Extent 信息在内存中的缓存可在内存压力大的时候释放.由于Group 信息与设备容量相关,因此随着设备容量的增大,内存占用也会增大;另外,由于采用Extent 的方式管理,一个Extent 作为一个单独的内存分配单元,大量分配Extent 后回收、释放可能存在内部碎片问题,释放了多个Extent 但是内存占用却没有减少,且内存占用上限越大内部碎片越严重.

Fig.3 ASD system metadata structure [16-17]图3 ASD 系统元数据结构[16-17]
上述Extent,Subtree,Group 结构均采用RB-tree进行组织,每个Group 在内存中索引多个Extent.对于Group 信息的下刷,需要先调整树结构,使得一个Group 索引到的Extent 信息可以记录到物理设备上一个定长的数据块中,Group 的下刷方式为异地写.因此,ASD 也存在wandering tree 的问题,ASD 的解决方法是:
1)Group 信息写到物理设备上之后,将多个Group 的逻辑索引和物理地址的映射以异地写的方式更新到数据区域;
2)将Group 信息的物理地址及其归属信息写入物理设备头部固定的反向表区域;
3)系统重启时通过扫描固定区域重构RB-tree.
综上,ASD 采用2 级逻辑索引和物理地址的映射解决wandering RB-tree 问题.该方法的优点是固定位置写较少,但管理复杂度过高.
2 wandering B+tree 问题分析和结构设计
本节首先分析wandering B+tree 问题,提出该问题的解决方法:IBT B+tree.分别通过B+tree 树结点布局、链表设计和树操作设计,以及第3 节提出的IBT B+tree 下刷算法论述wandering B+tree 的解决方法.
2.1 wandering B+tree 问题分析
首先,通过图4 介绍wandering B+tree 问题,并明确解决问题的难点.图4 展示了1 棵树结点逻辑索引与物理地址相同的3 阶B+tree 树结点更新过程.图4 左图下刷结点A时,需要为结点A分配新的物理地址生成结点A1;图4 中间的图,生成结点A1后,分配结点D1使其指向结点A1;图4 右图分配结点R1同理.因此,非树根结点分配物理地址需要递归更新父亲结点至树根结点,严重影响B+tree 下刷效率.
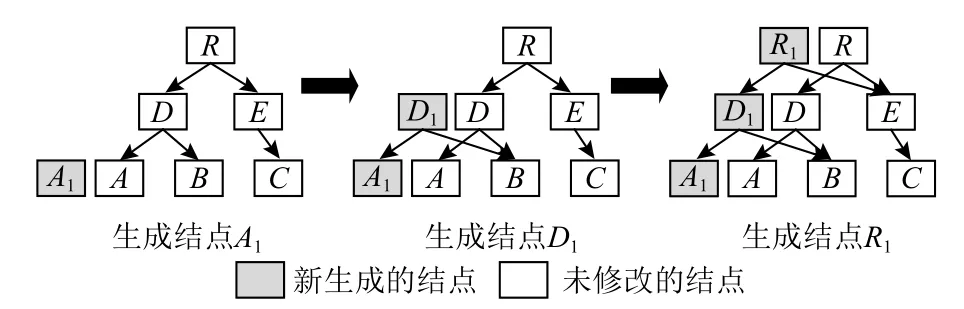
Fig.4 Example of wandering B+tree problem图4 wandering B+tree 问题案例
综上,要解决wandering B+tree,需要满足日志结构系统设计需求:树结点写时分配物理地址,且更新方式为异地写;同时,避免B+tree 树结点下刷时递归更新非叶子结点.
如第1 节所述,针对wandering tree 问题,NILFS2,F2FS,ASD 解决方法的共同点是:树结点逻辑索引和物理地址不同,即树结点的逻辑索引和物理地址分离,额外的数据结构和物理设备空间维护树结点逻辑索引和物理地址的映射关系.
因此,解决wandering B+tree 问题的难点是:
1)支持树结点逻辑索引和物理地址分离,且不引入新的数据结构和物理设备空间,降低复杂度;
2)避免B+tree 下刷时递归更新树结构.
针对这2 个难点,2.2 节提出第1 个难点的解决方法,2.3 节和2.4 节支撑第3 节提出的IBT B+tree 下刷算法解决第2 个难点.
2.2 IBT B+tree 树结点布局
IBT B+tree 的中间结点和叶子结点结构图如图5所示,图5 中各字段的含义如表1 所示.接下来,分别介绍表1 中各字段的用途.
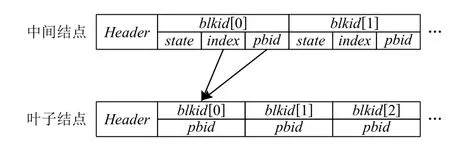
Fig.5 The internal node and leaf node of IBT B+tree图5 IBT B+tree 中间结点和叶子结点

Table 1 The Meaning of the Fields in Fig.5表1 图5 各字段的含义
1)state字段为孩子结点的状态,dirty 代表孩子结点需要持久化到物理设备,clean 代表孩子结点已经持久化且可以在内存紧张时回收.因此,state仅描述内存中的树结点内容是否与设备上的一致.
2)如图5 所示,中间结点记录孩子结点的逻辑索引index,随着树高的增长,所有非树根结点的index和pbid都会存放在其父亲结点中,只有树根结点的index和pbid不存放在树结构中.因此,需要额外的数据结构和物理设备空间存放树根信息,记作Superblock,包括index,pbid,height(见2.4 节).由于所有树结点的更新方式均为异地写,因此树根结点需要记录在物理设备的固定位置上,B+tree 初始化时才能找到树根.
3)中间结点记录孩子结点的index和pbid,在内存中的B+tree 树结点,以index为关键字,使用红黑树进行组织.各类B+tree 操作执行过程中,如果树结点不在红黑树中,则需要通过pbid从底层设备读取树结点.
2.3 IBT B+tree 链表设计
2.2 节提出树结点逻辑索引和物理地址分离的方法,通过树结点逻辑索引管理内存中的树结点,通过物理地址加载不在内存中的树结点,从而支持写时分配物理地址.因此,需要在此基础上解决2.1 节提出的第2 个难点:设计非递归更新的IBT B+tree 下刷算法.主要思路是:按照层次管理B+tree dirty 树结点,使得IBT B+tree 能够按照层次进行下刷.本节主要论述按照层次管理dirty 树结点的方法,IBT B+tree下刷算法在第3 节论述.
扩展并修改B+tree 链表维护方法.传统B+tree只维护叶子结点链表,用来管理所有叶子结点,按照关键字升序或降序排列.本文修改并扩展树结点链表:B+tree 的每一层均有一个dirty 链表;引入全局clean 链表.2 类链表设计主要有2 个特点:
1)B+tree 各层dirty 链表管理相应层中状态为dirty 的树结点,dirty 树结点按照LRU 的方式管理,而非按照关键字排序;
2)clean 链表管理所有状态为clean 的树结点,clean 链表也采用LRU 的方式管理,目的是为了在内存紧张时释放不经常访问的树结点.
链表的使用,特别是dirty 链表,将在2.4 节介绍.第3 节将介绍如何通过dirty 链表更新树结点物理地址.
2.4 IBT B+tree 基本操作设计
B+tree 在插入、查找、删除操作中对key-value的管理,与采用shadow-clone 设计的B+tree[20-21]没有差异.为使用lock-coupling 细粒度加锁协议支持B+tree 并发操作[22],B+tree 采用预先rebalance、分裂的方式调整树结构,避免B+tree 树操作执行过程中对孩子结点的修改导致父亲结点rebalance、分裂.
对于wandering B+tree 问题的解决方法,2.2 节已经给出支持树结点逻辑索引和物理地址分离的树结构设计.本节主要从支撑写时分配物理地址、更新物理地址的角度进行论述.支撑上述特性的主要解决方法是dirty 和clean 链表设计.本节从B+tree 树操作的角度介绍2 类链表的管理.由于clean 链表用来管理clean 树结点、支撑内存回收,只需要维护树结点的LRU 逻辑即可.因此,本节主要介绍dirty 链表的管理.
dirty 链表的变化主要源自插入操作和删除操作.下面分别通过案例介绍这2 个操作中dirty 链表的管理.本节所有的案例均围绕图4 所示的3 阶B+tree进行介绍,B+tree 树结点的key-value 按照key(逻辑地址)升序排序.
2.4.1 插入操作
图6 为将〈10,11〉映射插入1 棵3 阶B+tree 的主要步骤.下面分步介绍插入操作:
1)初始状态如图6(a)所示,所有树结点状态均为clean.
2)图6(b)将结点R标记为dirty,并将结点R插入list[0];由于结点R的key-value 数量达到上限,因此需要分裂结点R,分配D和E这2 个结点.将结点R的key-value 平均分配给结点D和E.将结点D和E中记录的最小key 与结点D和E的逻辑索引分别作为key 和value 插入到结点R中.此时不需要为结点D和E分配物理地址.树高加1,相应地调整链表.
3)图6(c)和图6(d),逐层向下访问到结点A,将〈10,11〉插入到结点A中.
如图6(b)所示,新创建的链表为B+tree 的第2 层.因为除树根结点外,B+tree 其他任何层都可能存在兄弟结点,为降低B+tree 树操作复杂度,仅允许树根结点分裂出孩子结点.综上,新插入的dirty 链表只发生在第2 层,这一特性适用于任何高度大于1的B+tree.
图6 所示的每个阶段操作过程中,都将所有需要访问的树结点状态标识为dirty,同时除树根结点外,将所有dirty 树结点在其父亲结点中的状态标识为dirty.
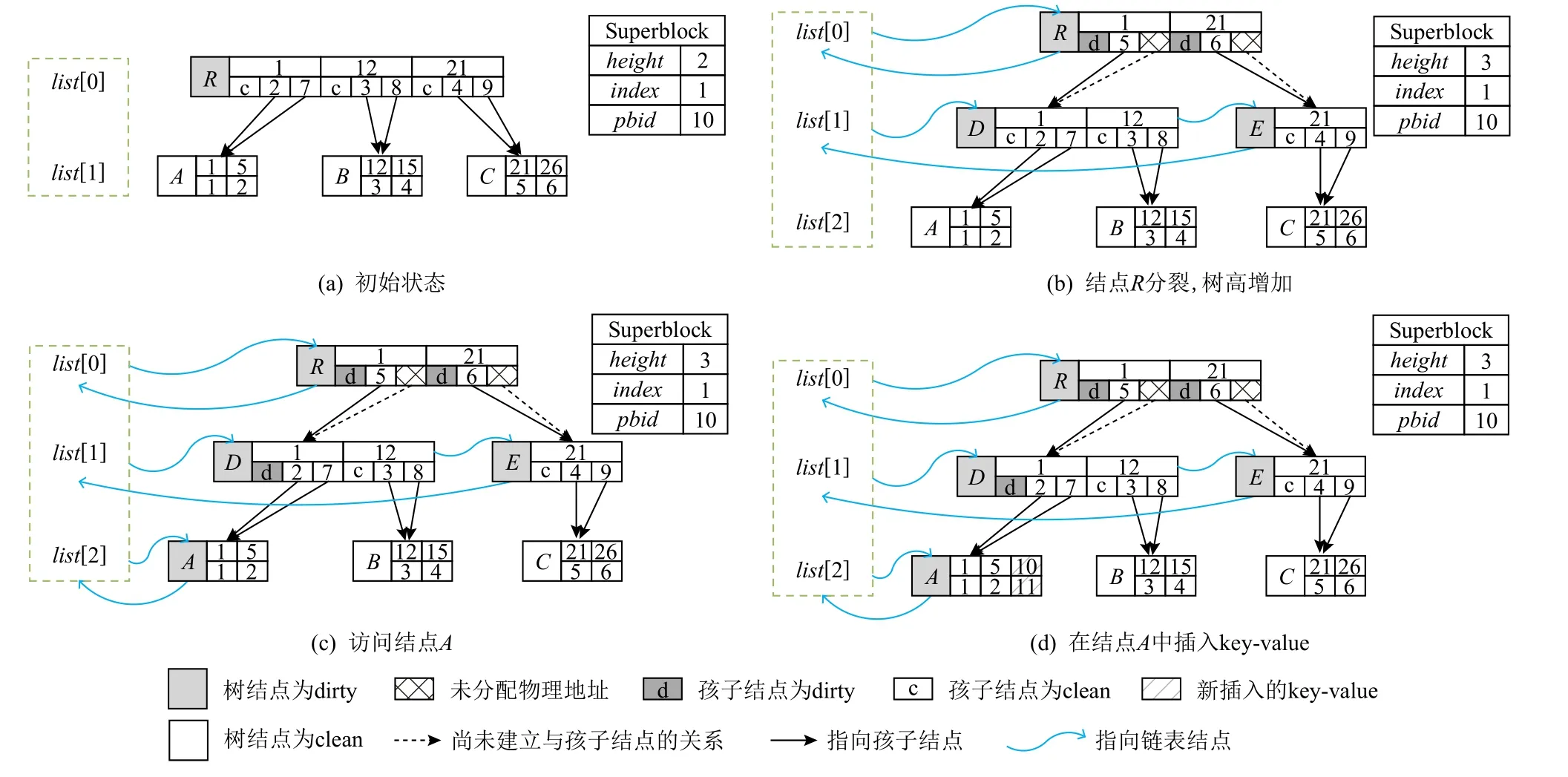
Fig.6 Insert operation(insert〈10,11〉)图6 插入操作(插入〈10,11〉)
由于dirty 链表的引入,2 个并发的插入操作①和②,①先执行,②后执行;如果插入②导致树高加1,①获得的树高信息不正确,则树结点可能插入错误的链表.因此,B+tree 无法支持插入和插入的并发.由于clean 链表对树高不敏感,B+tree 仍可支持插入和查找操作并发执行.
2.4.2 删除操作
以图7(a)所示的3 阶B+tree 为例,介绍删除〈10,11〉映射:
1)访问树根结点R,将结点R标记为dirty,并加入到dirty 链表list[0]中.
2)图7(b),结点R只有1 个孩子.因此,将结点D中记录的key-value 拷贝到结点R中,删除结点D和相应的链表.同时,结点R继承结点D的类型,图7(b)中D为中间结点,也存在结点R只有1 个孩子且为叶子结点的情况.因此,结点R也可能成唯一的叶子结点.
3)图7(c)和图7(d),逐级向下访问到结点A,将〈10,11〉从结点A中删除.
如图7(b)所示,被删除的dirty 链表为B+tree 的第2 层.与插入操作同理,dirty 链表删除操作仅删除第2 层链表,这一特性适用于任何高度大于1 的B+tree.
删除操作可能引起树高的修改,因此删除操作与删除操作、删除与插入操作均不能并发执行.

Fig.7 Remove operation(remove 〈10,11〉)图7 删除操作(删除〈10,11〉)
3 IBT B+tree 下刷
本节针对2.1 节提到的第2 个难点,提出非递归更新的IBT B+tree 下刷算法,从而解决wandering B+tree 问题.通过第2 节中IBT B+tree 的相关介绍可知,IBT B+tree 除树根结点外有如下特性:所有状态为dirty 的树结点的父亲结点状态均为dirty;dirty 结点的状态对父亲结点不透明.利用上述2 个特性,下面分别通过下刷算法和具体案例介绍IBT B+tree 的下刷.
B+tree 下刷存在2 种情况:下刷所有树结点,包括B+tree 创建完成并插入多次关键字之后的状态和B+tree 非首次下刷且所有树结点状态均为dirty;部分下刷,包括部分B+tree 树结点为dirty 的情况和经过多次删除后B+tree 为空.
多次插入、删除操作后,dirty 树结点的内存占用或下刷时间间隔达到一定阈值,需要将B+tree 所有状态为dirty 的树结点下刷到物理设备.
为避免递归更新B+tree 树结构,IBT B+tree 下刷采用2 阶段提交的方式.
第1 阶段,自dirty 链表的倒数第2 层向上下刷所有的dirty 链表:
1)根据该dirty 链表上所有树结点,下刷该树结点所有状态为dirty 的孩子;
2)为孩子结点分配物理地址并下刷,将孩子结点的物理地址记录到父结点中,并更新父结点中记录的状态.
第2 阶段,将Superblock 写到固定的物理设备空间.
B+tree 下刷算法如算法1 所示:
算法1.IBT B+tree 下刷算法.
图8 展示了B+tree 下刷的重要阶段.接下来,以图6(d)所示的3 阶B+tree 为例,结合算法1 和图8介绍B+tree 的下刷.
1)对于图6(d)的B+tree,调用算法1 中的函数flush_btree下刷整棵B+tree.flush_btree调用flush_dirty_lists自list[1]开始至树根链表,下刷所有dirty 链表.
2)如图8(a)所示,对于list[1]的结点D,调用函数flush_dirty_nodes,结点D只有一个状态为dirty 的孩子结点A.因此,如图8(b)所示,为结点A分配物理地址并记录在结点D中,同时将结点D中记录的结点A状态标更新为clean.同样的方式处理list[1]上所有树结点.
3)图8(c)下刷list[0],为结点D和E分配物理地址并下刷.至此,函数flush_dirty_lists执行完成.
4)图8(d)为树根结点R分配物理地址15,写树根结点R并更新Superblock,完成第1 阶段提交.
5)下刷Superblock 完成第2 阶段提交.
4 IBT B+tree 评价系统设计实现
本文以日志结构块设备系统为背景,在第2 节和第3 节提出了IBT B+tree,解决了wandering B+tree问题.但是,仅有IBT B+tree 只可进行树操作测试,难以测试在不同负载下的表现.
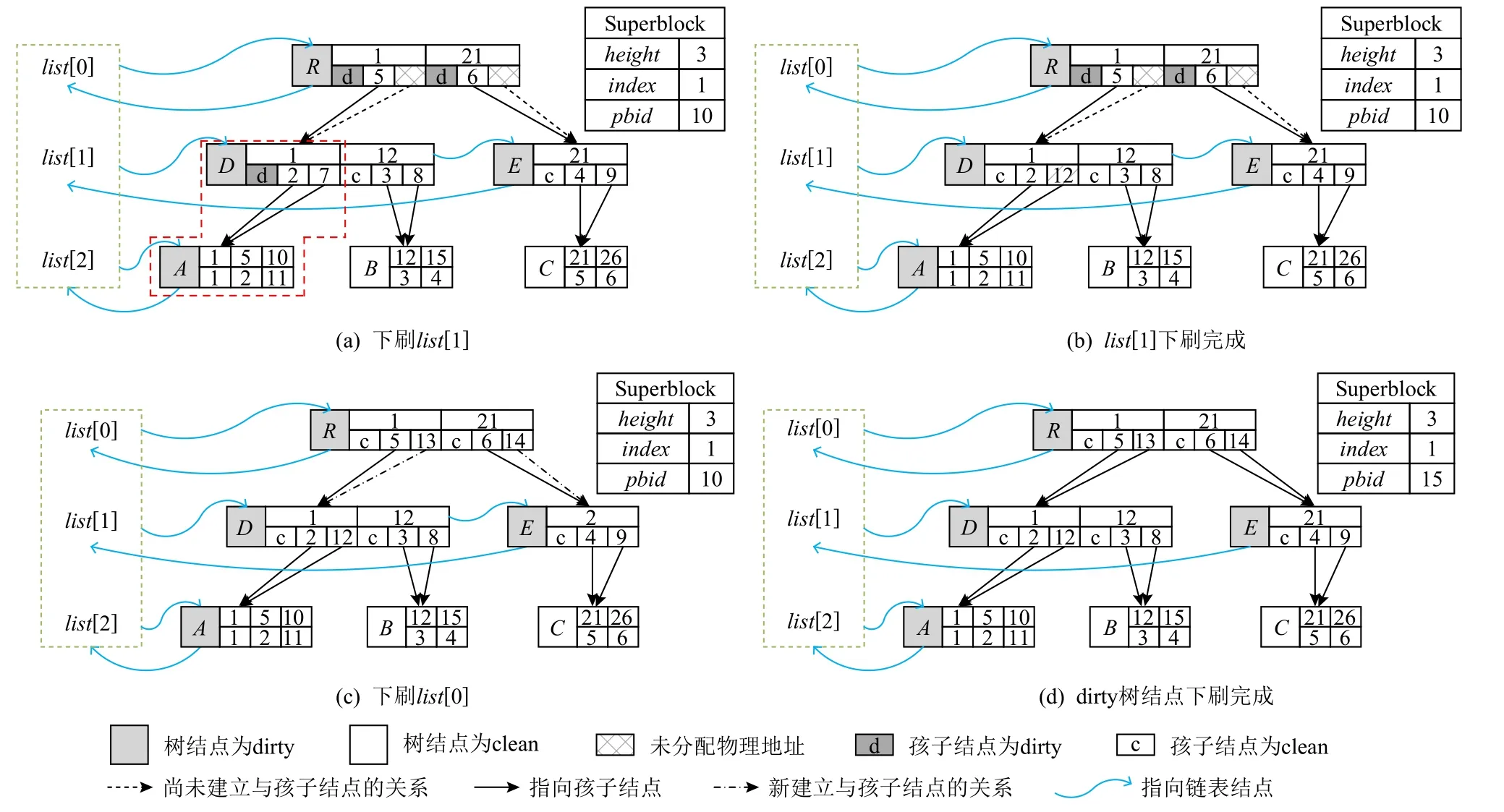
Fig.8 Flush dirty node of IBT B+tree图8 下刷IBT B+tree 的dirty 结点
为全面评价IBT B+tree 在Fio 和Filebench 场景下的写放大和下刷效率表现,需要设计实现能够覆盖IBT B+tree 支持的各类树操作和下刷,且避免I/O上下文干扰的日志结构块存储系统Monty-Dev.
为对比评价第3 节所提出解决方法的效果,拟将IBT B+tree 与采用NAT 方案设计的B+tree(后文称作NAT B+tree)进行对比.其中,NAT 方案设计参考Linux 内核5.14 版本[19]F2FS 的实现.由于NAT 块通过F2FS 内部inode 以文件映射的方式管理,因此这部分不能完全复用,转而使用radix-tree 管理所有缓存的NAT 块,基本与F2FS 的实现方式等价;其余部分均参考F2FS.另外,对于NAT 块的version bitmap需要为每个树结点预留1 b,计算方法与f2fs-tools[23]中格式化操作的计算方法不同.
本文以Linux 系统为平台,设计实现Linux 内核标准块设备Monty-Dev 系统.下面分别介绍评价系统Monty-Dev 的总体设计、元数据管理和系统layout.
4.1 Monty-Dev 系统整体架构
该设计暂不考虑宕机恢复和下刷数据块的反向映射信息,B+tree 树结点和NAT 块均缓存在内存中,本文聚焦写放大和固定物理设备空间非顺序写开销的评价.为评价删除操作的影响,Monty-Dev 系统支持Linux 内核中通用块层的Discard I/O 语义.
Monty-Dev 系统总体架构如图9 所示.使用横向的虚线标识系统的分层,下面逐层介绍.“用户接口”用来管理Monty-Dev 系统,比如创建、删除设备和修改系统配置等.其他系统可通过“标准块设备接口”,直接向Monty-Dev 提交读写I/O 请求.ext4/xfs 等文件系统实例,可向通用块层提交读写I/O、Discard I/O 请求,Discard I/O 用来支持文件系统的trim 操作.

Fig.9 Architecture of Monty-Dev system图9 Monty-Dev 系统整体架构
Monty-Dev 核心模块实现了通用块层的部分接口,处理上层发往通用块层的请求.基于Monty-Dev系统可执行Fio 测试,将Monty-Dev 设备格式化为特定文件系统可支持Filebench 测试.
因此,通过Monty-Dev 系统测试Fio 和Filebench负载,可覆盖B+tree 的查找、插入、删除操作及其并发,以及元数据下刷.
4.2 元数据管理模块
Monty-Dev 的元数据管理模块结构图如图10 所示,后文称作Meta tree.
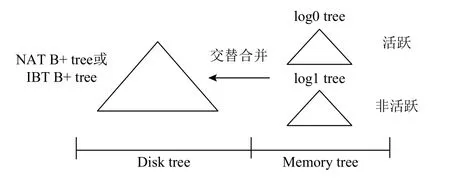
Fig.10 Structure diagram of Meta tree图10 Meta tree 结构图
Meta tree 管理块设备逻辑地址和物理地址的映射关系,支持系列元数据操作,如查询、插入、更新、UNMAP.Meta tree 包括2 部分,为方便描述分别称作Disk tree 和Memory tree,其 中Disk tree 为NAT B+tree 或IBT B+tree,本文评测中树结点大小和数据块大小均为4KB.
仅通过IBT B+tree 或者NAT B+tree 管理元数据,元数据下刷会阻塞I/O 回调时对元数据的修改,影响数据和元数据写并发,无法评价元数据下刷对用户I/O 的影响.因此,本文引入Memory tree,包括log0 tree和log1 tree,统称为log tree.log tree 采用文献[24]提出的基于lock-coupling 扩展协议的B+tree,2 棵树常驻内存,仅记录映射关系修改的log,用来聚合log(映射关系的修改,包括插入、更新、UNMAP).2 棵树交替使用,活跃log tree 处理元数据修改,非活跃log tree 进行合并.Disk tree 需要下刷到物理设备,存储所有映射关系.
log tree 功能需求有:
1)将上层写I/O 对元数据的修改以log 的方式记录下来,记录的内容为逻辑块号和对映射关系的修改操作.
2)log tree 的内存占用达到一定阈值或其他条件触发下刷,如设备关闭、下刷超时.Meta tree 下刷时需要遍历log tree 中所有log 将映射关系的修改按照log 类型在Disk tree 上执行相应的树操作.合并结束后,删除log tree.
3)查询操作时,先查询log tree 再查询Disk tree,因为最新的映射关系修改都记录在log tree 中.
综上,log tree 需要提供如下功能:插入、更新、遍历.这些需求文献[24]提出的B+tree 都可以满足,且有着映射关系插入、查找可并发的优点.
通过Meta tree 管理元数据,解决B+tree 下刷时不能更新映射关系的问题,从而避免元数据下刷阻塞用户I/O 请求,影响系统整体性能表现,同时也避免了I/O 上下文对元数据下刷的干扰.
4.3 Monty-Dev 系统layout
使用IBT B+tree 管理逻辑地址和物理地址的映射关系,则需要预留空间满足第3 节中所述的2 阶段提交下刷B+tree 的需求,以及存储块设备系统的必要信息.
使用NAT B+tree,则需要NAT 区域和Checkpoint区域:NAT 区域与F2FS 中NAT 区域的功能相同;Checkpoint 区域记录NAT 块的version bitmap.
5 测评与分析
本节基于第4 节提出的分别采用NAT B+tree 和IBT B+tree 管理元数据的2 个版本Monty-Dev 系统(为方便描述,后文分别称作NAT 版本和IBT 版本)进行评测.本节主要通过Fio[25]和Filebench[26]进行测试,以评价在不同负载下,NAT 版本和IBT 版本在元数据写放大和下刷效率方面的差异.
5.1 测试环境
第5 节的相关测试均在表2 所示的测试环境上进行.5.2 节和5.3 节的测试均分别在SSD 和HDD 上进行测试,以验证IBT B+tree 在2 种介质上的优化效果.

Table 2 The Hardware Configuration of Testing Server表2 测试服务器硬件配置
测试的软件环境如表3 所示.由于NAT 版本和IBT 版本的元数据构成存在差异:NAT 版本的元数据包括NAT 块和B+tree 树结点,而IBT 版本仅包括B+tree 树结点.因此,NAT 版本和IBT 版本在相同测试用例下,元数据的下刷量可能存在差异.此外,NAT版本存在固定物理设备空间随机写的问题,而IBT版本不存在.因此,元数据下刷效率也可能存在差异.

Table 3 The Software Configuration of Testing Server表3 测试服务器软件配置
5.2 Fio 测试
2 个版本的Monty-Dev 系统,采用精简配置设计,读测试和读写混合测试均存在空读的问题,且B+tree 树结点均缓存在内存中,IBT B+tree 和NAT B+tree 的查询效率没有差异,因此仅测试Fio 随机写.
Fio 测试的参数如表4 所示,以表4 中参数连续测试2 次,分别测试首次写和覆盖写的吞吐率表现,测试3 次取平均值.由于Fio 随机写测试发送的I/O 请求为伪随机请求序列,因此在参数不变的情况下每次Fio 测试的I/O 序列均相同.第2 轮测试即为覆盖写,覆盖写测试对于IBT B+tree 和NAT B+tree 而言均为插入更新操作.因此,该测试用例可先后评价NAT版本和IBT 版本在插入和插入更新场景下的差异.

Table 4 Fio Configuration Parameters表4 Fio 配置参数
Meta tree 合并下刷频率受2 个因素制约:log tree内存占用上限;B+tree 的dirty 树结点内存占用上限.其中,log tree 内存占用上限越小,下刷频率越高;dirty树结点内存占用上限影响一轮元数据下刷量,上限越小,一轮元数据下刷量越小,下刷越频繁.因此,本文分别测试log tree 内存占用上限为10 MB,20 MB,30 MB 的情况下,dirty 树结点内存占用上限为65 MB,85 MB,105 MB 时,NAT 版本和IBT 版本首次写和覆盖写的吞吐率表现和元数据下刷的写放大.下面分别在SSD 和HDD 上进行测试分析.
由于NAT 版本和IBT 版本的有效元数据量相同,因此本节通过元数据下刷量评价元数据下刷写放大.
5.2.1 基于SSD 的Fio 测试
Fio 测试中,首次写和覆盖写的吞吐率、元数据下刷量对比如图11 所示.观察分析图11,可得出4 个结论:
1)对于元数据下刷量,IBT 版本在大多数情况下均优于NAT 版本,但差异很小;
2)log tree 内存占用上限越大,元数据下刷量越小;
3)NAT 版本和IBT 版本,在覆盖写测试中log tree 内存占用上限越大,吞吐率越大;
4)log tree 大小相同时,dirty 树结点内存占用上限对元数据下刷量影响很小.
对于第4 个结论,若在Meta tree 合并过程中,dirty 树结点内存占用超过上限,需要下刷后再合并剩余映射.由于log tree 将映射关系按照逻辑地址排序,下刷后再合并剩余映射时,不会修改已下刷叶子结点,但可能会修改部分已下刷的中间结点.而中间结点总量较少,因此dirty 树结点的内存占用上限对元数据下刷量影响很小.


Fig.11 Comparison of throughput and the total amount of flushed metadata based on SSD图11 基于SSD 的吞吐率、元数据下刷量对比
由于NAT 版本和IBT 版本B+tree 插入更新复杂度基本相同,因此只需要考虑Meta tree 合并下刷时的差异.由于吞吐率表现基本相同,因此NAT 版本和IBT 版本的元数据下刷效率对性能的影响基本相同.为此,本节主要通过分析元数据下刷量评价NAT版本和IBT 版本的元数据写放大.表5 统计了图11(a)中,dirty 树结点内存占用上限为85 MB 时,2 轮测试期间的元数据下刷量.

Table 5 Total Amount of 2 Versions Flushed Metadata Under Fio Test Based on SSD表5 基于SSD 的Fio 测试中2 个版本元数据下刷总量GB
从表5 可以看出,IBT 版本的元数据下刷量略低于NAT 版本,但NAT B+tree 下刷时存在非顺序写.NAT 版本的元数据包括NAT 块和B+tree 树结点,NAT 块下刷的物理设备访问模式为固定物理设备空间的非顺序写,而数据写为顺序写,NAT 块和数据可并发写.2 轮测试中NAT 块下刷情况如表6 所示.
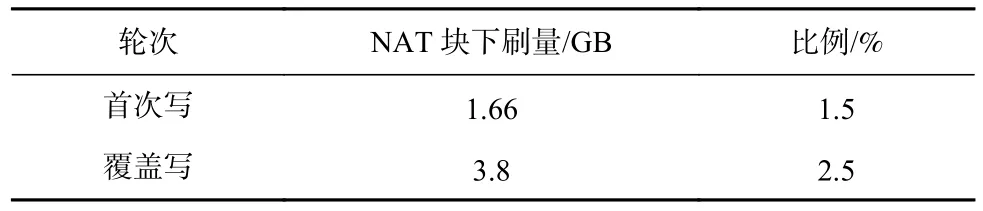
Table 6 Statistics of Flushed NAT Block Under Fio Test Based on SSD表6 基于SSD 的Fio 测试中NAT 块下刷统计
覆盖写测试中NAT 块的写入量和比例都有所增加.主要原因是B+tree 树结点总量增多,导致NAT块总数增多,随机修改NAT 块的范围增大.但由于NAT 块写相对于顺序写的比例较小,对用户数据写性能影响较小,所以NAT 版本和IBT 版本的吞吐率差异很小.然而,随机写会导致闪存块碎片增多,降低闪存性能和寿命,这在短期测试中不能体现出来.
NAT B+tree 下刷需要下刷叶子结点和NAT 块,IBT B+tree 对于状态为dirty 的叶子结点,其查询路径上所有的祖先结点一定为dirty,而IBT 版本的元数据下刷量小于NAT 版本.因此,IBT 版本虽然理论上存在一定的写放大,但由于NAT 块的写开销,IBT版本实际表现与NAT 版本相当或优于NAT 版本.
5.2.2 基于HDD 的Fio 测试
Fio 测试经过首次写和覆盖写2 轮测试后,吞吐率、元数据下刷量对比如图12 所示.观察分析图12,可得出5 个结论:
1)对于元数据下刷量,IBT 版本在大多数情况下均优于NAT 版本;
2)对于吞吐率,相对于NAT 版本,IBT 版本首次写提升4.7%~13.8%,覆盖写提升10.7%~20.3%,内存占用越少提升越大;
3)IBT 版本吞吐率表现几乎不受dirty 树结点内存占用上限影响,而NAT 版本受影响较大,特别是图12(b);
4)log tree 内存占用上限越大,吞吐率越大;
5)log tree 内存占用上限相同,大多数情况下,dirty 树结点内存占用上限越大,元数据下刷量越小.
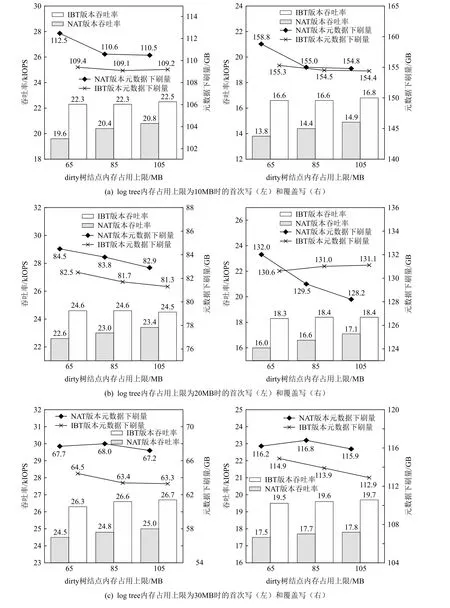
Fig.12 Comparison of throughput and the total amount of flushed metadata based on HDD图12 基于HDD 的吞吐率、元数据下刷量对比
以图12(a)dirty 树结点内存占用上限为85MB 为例,分析元数据下刷与吞吐率的关系.相对于NAT 版本,IBT 版本2 轮测试吞吐率提升分别为9.3%和15.3%.相较于5.2.1 节中基于SSD 的测试,提升比例更高.同5.2.1 节,需要关注Meta tree 合并下刷对性能造成的影响.2 轮测试期间元数据下刷量如表7 所示.
IBT 版本比NAT 版本元数据下刷量略小,但由于NAT 块下刷不是顺序写,且HDD 的吞吐率受I/O连续度的影响较SSD 更大,少量的非顺序写也会造成磁头的抖动,因此导致吞吐率提升比例更大.表8中展示了2 轮测试中NAT 块下刷情况.

Table 7 Total Amount of 2 Versions Flushed Metadata Under Fio Test Based on HDD表7 基于HDD 的Fio 测试中2 个版本元数据下刷总量GB

Table 8 Statistics of Flushed NAT Block Under Fio Test Based on HDD表8 基于HDD 的Fio 测试中NAT 块下刷统计
如表8 所示,覆盖写测试中NAT 块的写入量和比例都增加了,从而导致固定位置非顺序写请求增多.IBT B+tree 叶子结点需要下刷,其父亲结点必须下刷,对于局部性比较好的树操作,多个被修改的叶子结点可能有相同的祖先结点.而NAT 块的设计不确保1 个块涵盖的多个树结点在一轮元数据下刷时同时下刷,所以局部性较好的树操作不一定能减少NAT 块的下刷量.
综上,IBT B+tree 的设计能够更好地利用空间局部性降低元数据的下刷量,避免随机访问提升元数据的下刷效率.NAT 版本,B+tree 树结点总量越多,更新NAT 块越多,写放大越严重,增加HDD 寻道时间从而降低系统吞吐率.因此,IBT 版本在元数据写放大和下刷效率方面的表现均优于NAT 版本.
5.3 Filebench 测试
为避免空读,测试查询、插入、更新、删除操作的综合性能,使用Filebench 进行测试,该组测试主要选取varmail,fileserver 这2 个负载.为充分测试对比IBT B+tree 和NAT B+tree 的综合性能,同时适配当前服务器环境,对Filebench 中标准wml 脚本的测试时间、线程数、文件大小、文件数量均作了修改.这些负载均首先分配一个文件集合,2 类负载的行为如下:
1)varmail,模拟邮件服务器的I/O 负载,该负载多线程执行相同任务.顺序执行删除、创建—追加—同步、读—追加—同步、读操作.
2)fileserver,模拟文件服务器上的I/O 负载,该负载多线程执行相同任务.顺序创建、写整个文件、追加写、读整个文件、删除文件、查看文件状态.
测试方法为:分别基于HDD 和SSD 创建4TB 的Monty-Dev 设备,格式化为ext4 文件系统,使用discard选项挂载文件系统以测试B+tree 的删除操作,每类负载执行1 h,每个测试执行3 次,结果取平均值.
5.3.1 基于SSD 的Filebench 测试
Filebench 测试结果,IBT 版本和NAT 版本基 本相同,差异较小.主要原因有:文件系统并不会将写请求直接转发至底层设备,设备利用率低;文件系统下发的写请求基本为顺序写,2 个版本差异较小.因此,本节及5.3.2 节主要通过元数据下刷量评价IBT版本和NAT 版本.由于Filebench 测试按照指定时长进行测试,不同测试中Monty-Dev 设备收到的I/O 请求数量存在差异,因此,本节及5.3.2 节使用元数据下刷比例指标评价元数据的写放大情况:
通过式(1)的计算方法,计算结果如图13 所示.

Fig.13 Comparison of Filebench test based on SSD图13 基于SSD 的Filebench 测试对比
相对于NAT 版本,IBT 版本在varmail 负载和fileserver 负载测试中,元数据下刷比例分别减少0.67%和0.69%.经统计,若元数据写比例仅统计树结点下刷量,则2 类负载测试中IBT 版本均大于NAT版本,该现象符合IBT 版本和NAT 版本设计的差异.因此,导致NAT 版本元数据下刷比例高的主要原因是NAT 块下刷的开销大.接下来,具体分析NAT 版本元数据下刷量的组成.
如表9 所示,NAT 块下刷量占元数据下刷比例较表6 所示的更高.较Fio 负载,Filebench 负载支持discard I/O 请求,系列删除操作完成后,一些树结点需要被释放,释放树结点需要将NAT 块中的记录更新为无效映射.经统计,varmail 和fileserver 负载测试中discard I/O 占写I/O 请求的比例分别为81.5%和76%.因此,删除操作会严重影响NAT 版本的NAT块下刷量,从而影响元数据下刷比例,导致NAT 版本写放大更加严重.
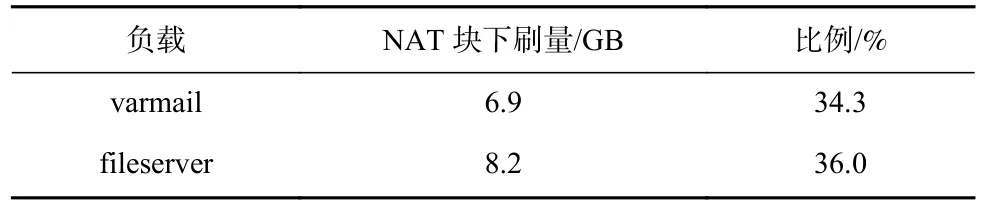
Table 9 Statistics of Flushed NAT Block for Different Loads Under Filebench Test Based on SSD表9 基于SSD 的Filebench 测试不同负载NAT 块下刷统计
5.3.2 基于HDD 的Filebench 测试
评价方法与SSD 上测试相同,元数据下刷比例对比结果如图14 所示.
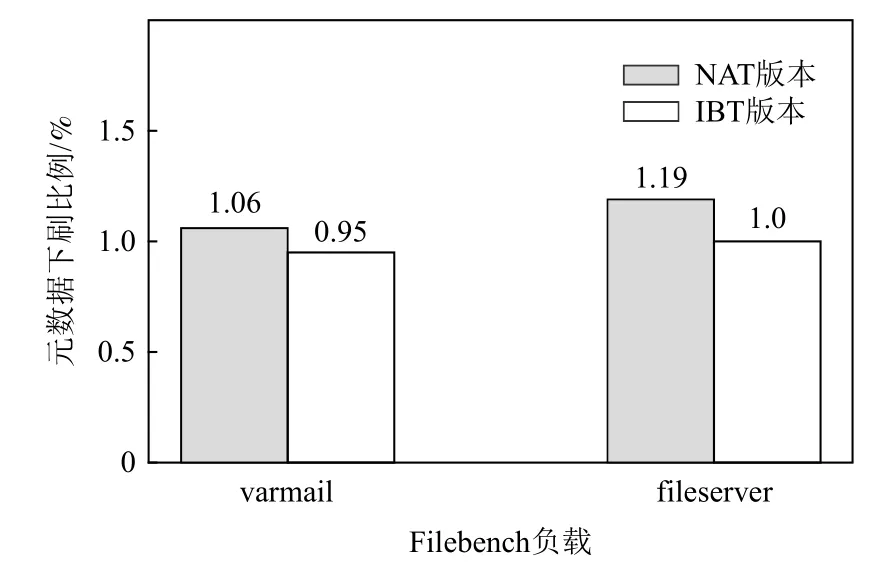
Fig.14 Comparison of Filebench test based on HDD图14 基于HDD 的Filebench 测试对比
相对于NAT 版本,IBT 版本在varmail 负载和fileserver 负载测试中,元数据下刷比例分别减少0.11%和0.19%.HDD 上IBT 版本降低比例较SSD 上测试低的主要原因是:Filebench 测试预先写入的数据量相同,HDD 上测试varmail 负载和fileserver 负载分别比SSD 上测试执行的操作数少约92%和86%.根据5.3.1 节分析,删除操作是造成元数据下刷量差异的主要原因.经统计,varmail 和fileserver 负载测试中discard I/O 占写I/O 请求的比例分别为26%和32.2%,均低于SSD 上的测试结果.造成discard I/O 比例低的主要原因是:discard I/O 操作元数据处理开销较大,HDD 上处理较SSD 慢,在测试结束后,ext4 文件系统仍然在发送discard I/O.因此,造成HDD 上测试IBT 版本元数据下刷比例降低的主要因素也是删除操作,造成降低比例较SSD 测试低的原因是删除操作比例较低.
NAT 块下刷量相对于元数据下刷量的比例如表10所示.discard I/O 占比的差异与NAT 块占比为正相关.综上,在元数据写放大方面,相对于NAT 版本,IBT版本在删除操作中的表现也更优.
综上,进行了Fio 测试和Filebench 测试,IBT 版本相对于NAT 版本:在HDD 上的吞吐率和元数据下刷写放大方面,较SSD 上的优化效果更显著;在处理大规模随机更新和删除操作时,开销更小.
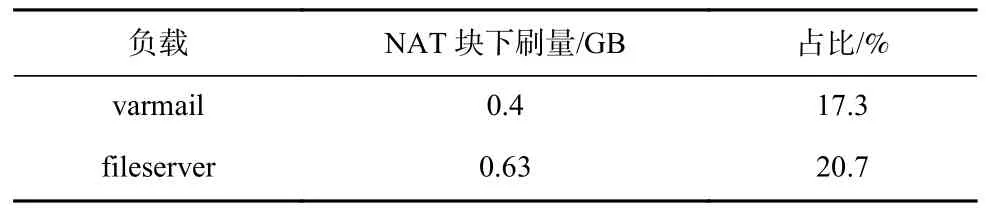
Table 10 Statistics of Flushed NAT Block for Different Loads Under Filebench Test Based on HDD表10 基于HDD 的Filebench 测试不同负载NAT 块下刷统计
6 总结
本文主要研究了使用B+tree 管理日志结构块存储系统的地址映射面临的wandering B+tree 问题.B+tree 具有扇出大、综合效率高的优点,被广泛应用于各类存储系统中.对于日志结构块存储系统,使用B+tree 管理逻辑地址和物理地址的映射需要解决:支持树结点下刷方式为异地写,并避免递归更新B+tree树结构.本文从树结构和树操作设计的角度出发,提出了IBT B+tree,将树结点物理地址嵌入树结构的设计,引入dirty 链表设计,定义IBT B+tree 插入、删除操作,并提出了非递归更新算法,既解决了wandering B+tree 问题,又不引入额外的数据结构和固定物理设备空间.设计实现块设备存储系统Monty-Dev,将IBT B+tree 与NAT B+tree 进行对比,实验结果表明在不同的负载下IBT B+tree 的写放大表现与NAT B+tree 相当或更优,下刷效率更高.IBT B+tree 可应用于日志结构块设备系统,如ASD 系统;也可应用于日志结构文件系统管理文件的地址映射,如NILFS2 文件系统.
作者贡献声明:杨勇鹏负责论文撰写、部分实验方案设计、实验执行和论文修订;蒋德钧负责部分实验方案设计和论文修订.
