基于改进单步多框目标检测的道路小目标检测算法
2023-03-27吴晨曦应保胜许小伟刘光华程书瑾
吴晨曦,应保胜,许小伟*,刘光华,程书瑾
(1.武汉科技大学汽车与交通工程学院,武汉 430065; 2.智新科技股份有限公司,武汉 430058)
基于深度学习的目标检测算法现已广泛应用于自动驾驶领域。其中,汽车在行驶过程中车速快,为了预留充足的反应时间和制动距离,要求使用的目标检测算法对于远处的小目标也有良好的检测效果,同时具有较快的检测速度。但如果行人、骑行者以及远处的汽车这类小目标的尺度小,在图像上占据的像素很小,所对应的区域所包含的信息较少,在检测过程中易出现误检漏检,因此对于道路上小目标的检测成为自动驾驶领域中的难点。
目前对于小目标的界定方式主要有两种[1]。第一种为绝对尺度,即所占像素小于32×32的目标可视作小目标;第二种为相对尺度,即目标的长宽为原始图像的1/10,可视作小目标。考虑到汽车在行驶过程中遇到的障碍物种类多,且障碍物大小跨度大,因此现综合两种方式界定小目标。
基于深度学习的目标检测算法可分为双阶段(two-stage)和单阶段(one-stage)。区域卷积神经网络(region convolutional neural networks,R-CNN)[2]、快速区域卷积神经网络(faster region convolutional neural networks,Faster R-CNN)[3]、Mask R-CNN[4]等均属于双阶段检测模型。双阶段检测模型耗时多,检测速度慢。YOLO[5-8]系列和单步多框目标检测(single shot multibox detector, SSD)[9]均属于单阶段检测模型,在检测速度上优于双阶段检测模型。YOLO系列从YOLOv3开始加入了特征金字塔结构,增强了对小目标的检测效果。但是SSD目标检测模型中特征层尺度较小,且各特征层之间没有联系,对于小目标检测效果较差。为了提升SSD模型在小目标上的检测效果,学者们进行了大量研究。Fu等[10]在SSD模型的特征提取网络后添加反卷积模块,增加特征层的感受野,再将相同尺度的卷积层融合,提高了小目标检测效果,但是由于特征提取网络过深,导致检测速度过慢,难以应用到车辆上;Zhang等[11]提出的DDSSD模型,在SSD模型的特征提取网络中添加反卷积模块和空洞卷积,增加特征层的感受野,再将相同尺度的卷积层融合,提高了小目标检测效果,但是由于沿用SSD模型的特征融合方式,对于小目标的检测效果并不好;Li等[12]提出FSSD 模型,将SSD模型中的FC7、Conv7_2两个特征层进行双线性插值,使其与Conv4_3尺度相同,再将这个三特征层合并,使用得到的新特征层构造特征融合金字塔,实验结果表明FSSD模型的小目标检测效果优于SSD模型,但是FSSD的特征融合金字塔中各特征层独立,相互没有联系,融合并不彻底;Wang等[13]提出的MFSSD模型在FSDD模型的基础上将Conv7_2替换为Conv5_3进行特征融合,同时使用剪枝压缩模型,但仍然具有FSSD的问题;Jeong等[14]针对SSD模型各特征层相互独立、易出现同一个物体在不同大小的先验框检测出和小目标检测效果差两个问题,提出了一种新特征融合结构,具体操作是同时采用池化和反卷积两种融合方式进行特征融合,充分利用不同尺度特征层的信息,提高了小目标检测效果;Zhang等[15]提出RefineDet模型,该模型结合双阶段和单阶段模型,一方面引入类似双阶段模型中的区域候选网络(region proposal network,RPN)用来生成先验框和除去负样本,另一方面在SSD模型上添加特征金字塔加强对小目标的检测效果;Pourya等[16]将图像金字塔与SSD模型的特征层进行融合,获取更强的语义特征,但产生不同大小的图像会大幅增加计算量,对训练和运行的设备性能要求较高。结合上面的分析,SSD模型在小目标检测上的优化主要集中在特征融合方式的改进。
以上的改进方法均采用特征融合的方式来提高小目标的检测效果,在一定程度上弥补了SSD模型在小目标检测上的不足。但是以上的特征融合方式都将重点放在了不同尺度的特征层之间的融合上。然而由于不同物体的外观复杂程度不同,相同尺度的物体需要的语义信息不一定相同,深层的特征适合表征外观复杂的物体,浅层的特征适合表征外观简单的物体。因此合适的特征融合方式需要兼顾尺度与层级两个方面。
在SSD模型基础上,现提出一种感受野增强和特征融合的小目标检测模型。在主干网络中添加使用膨胀卷积的感受野增强模块,增大卷积层的感受野,以获得更多小尺度目标的信息。同时引入多层级特征融合结构金字塔替换SSD模型的特征融合结构,将不同尺度、不同层级的特征层进行特征融合,形成新的特征金字塔用于预测,从而有效提高小目标的检测效果。最后通过消融实验和性能对比实验,在保证检测速度的情况下,验证改进的目标检测模型降低对道路上小目标的漏检率。
1 感受野增强和特征融合的目标检测模型
1.1 感受野增强与特征融合模型总体结构概述
所提出的感受野增强与特征融合模型的结构如图1所示。其中,感受野增强型的SSD模型指在SSD的主干网络中嵌入感受野增强模块(RFB_s),得到的新主干网络模型,目的是获取更多的小目标信息。而后将主干网络输出的特征层送入多层级特征金字塔(图中蓝色虚线框部分)进行多次特征融合,绿色虚线框内是4次U形特征提取,目的是提取出不同层级的语义信息,橙色虚线框内是4个不同层级的特征金字塔,最后将4个特征金字塔合并为一个具有6个尺度的多层级特征金字塔,每个尺度包含4个层级的语义信息,这样可以充分结合不同尺度,不同层级的特征层,提高小目标的检测效果。由于在SSD模型上添加了多层级特征融合结构和感受野增强模块,网络深度有所增加,时间复杂度会增大;同时4个不同层级的特征金字塔会输出24个不同尺度的特征层,空间复杂度会增加。
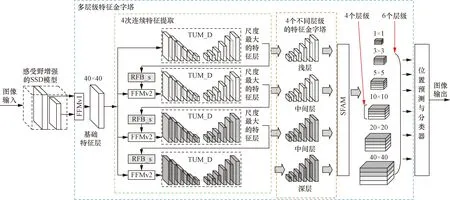
图1 感受野增强与特征融合模型结构图Fig.1 Structure of receptive field enhancement and feature fusion model
1.2 感受野增强的SSD模型
传统SSD 网络结构如图2所示,有6个用于预测的有效特征层,分别为Conv6、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2,其中尺度最大的特征层为Conv4_3层,尺度为38×38。SSD网络从靠后的Con4_3层开始抽取特征并获得预测结果,由于这些特征层尺度较小,因此SSD模型对于小目标的检测效果并不好。
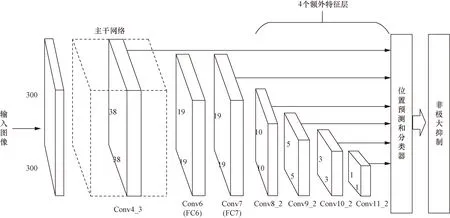
图2 SSD网络结构图Fig.2 Network structure of SSD
感受野是指卷积神经网络每一层输出的特征图上的像素点在输入图片上映射的区域大小,通俗解释是特征图上的一点对应输入图上的区域。较大的感受野可以提高主干网络的特征提取能力。神经学研究发现,在人类视觉皮层中,群体感受野的尺度是其视网膜偏心度的函数,其尺度与视网膜图的偏离度正相关,且不同视网膜图上群体感受野的尺度不一样[17]。Liu等[18]提出了感受野模块(receptive field block,RFB),对这一发现进行模拟,用以加强轻量级卷积神经网络模型学习到的深层特征。
RFB模块结合了膨胀卷积[19]和InceptionNet[20]的并行卷积来扩大特征层的感受野。如图3所示,原始的RFB模块有3条分支,每条分支都有不同大小的卷积核,卷积核的大小分别为1×1、3×3、5×5,且分支的末端都有一个膨胀卷积层,膨胀率rate分别为1、3、5。为了进一步增强特征层的感受野,在原始RFB的基础上再添加一条具有更大视野的分支,并将其命名为RFB_s模块,其结构如图4所示。同时考虑到应用在自动驾驶的目标检测算法应当由较高的检测速度,所以使用串联的小卷积替换大卷积来减少模型的参数量,以提高检测速度。具体操作为:在第3条分支中,使用两个并联的3×3卷积替换原本的5×5卷积;在第4条分支中,使用1×7卷积和7×1卷积替换原本的7×7。4条分支的结果进行会连接并经过一个1×1的卷积,然后与一条残差边作为输入送入激活函数。残差边的作用是使输入的图像信号可以从底层直接传播到高层,缓解过深的网络导致的梯度发散。

图3 感受野模块结构图Fig.3 The architecture of receptive field block

图4 感受野增强模块结构图Fig.4 The architecture of receptive field block
如图5所示,将改进的RFB_s模块嵌入SSD模型,具体步骤如下。
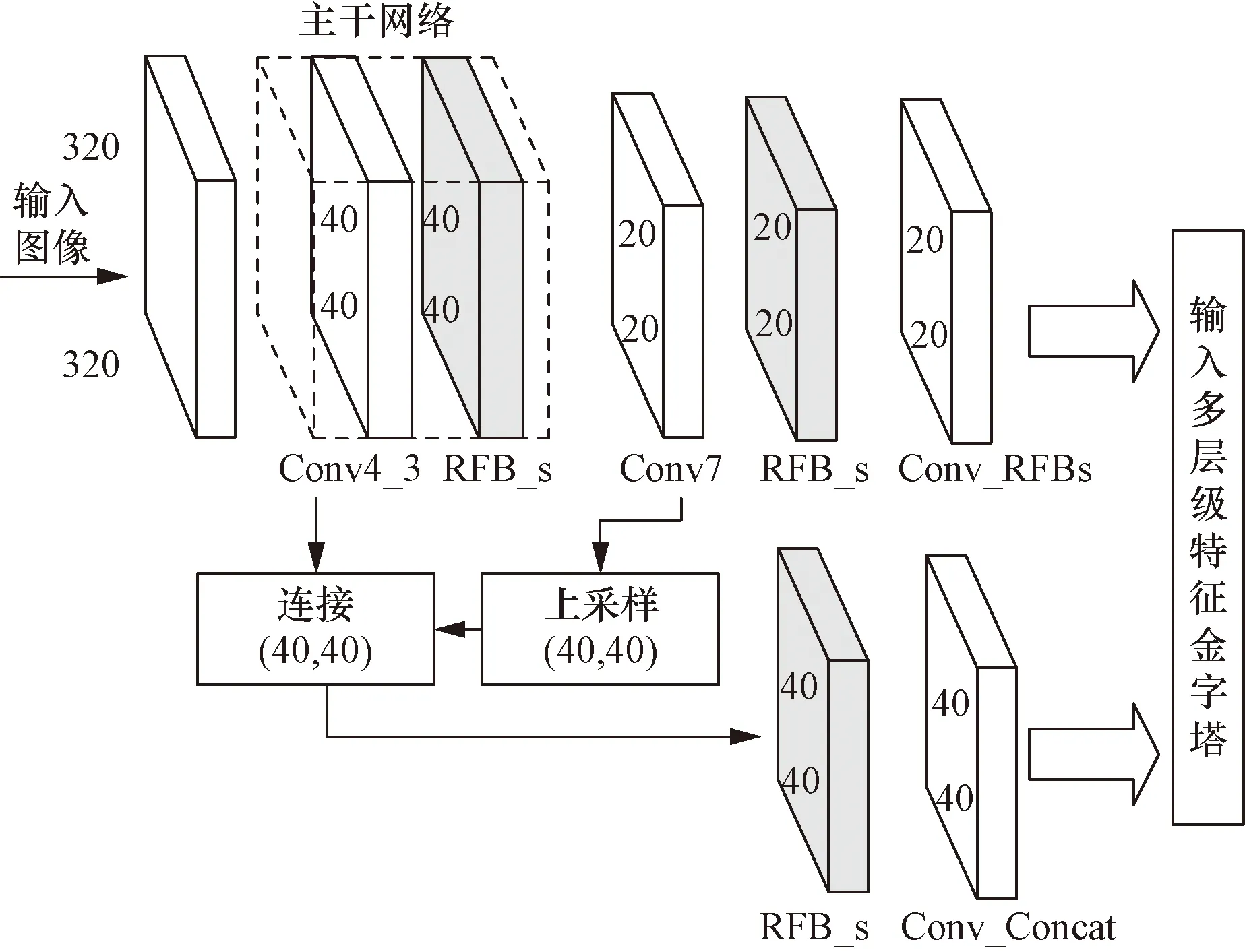
图5 感受野增强的SSD网络模型Fig.5 SSD network model with RFB_s
(1)将FC7层进行一次上采样,使其尺度与Conv4_3保持一致。
(2)在Conv4_3层后嵌入一个RFB_s模块,再将FC7层与其连接,连接后的特征层再经过一个RFB_s模块得到Conv_Concat层。
(3)在FC7层后嵌入一个RFB_s模块得到Conv_RFBs层。
(4)将Conv_Concat层和Conv_RFBs层输入特征融合金字塔。
1.3 多层级特征融合金字塔
在卷积神经网络中,随着卷积加深特征层增多,靠后的特征层拥有的深层语义信息更多,更适合表征外观复杂的物体,靠前的特征层拥有的浅层语义信息更多,更适合表征外观简单的物体[18]。但是具有相似大小的对象的外观可能完全不同,例如在小目标检测中,交通信号灯和远处的行人可能具有相当的尺寸,而人的外观要复杂得多。所以检测信号灯需要浅层特征,检测远处的行人需要深层特征。因此实际检测中不仅要考虑尺度层面还要考虑层级层面。
特征金字塔[21](feature pyramid networks,FPN)是一种优秀的特征融合结构,其结构如图6所示。FPN将特征提取网络中每个阶段最后一层的输出构建金字塔,对金字塔高层的特征层逐层进行上采样,并将尺度相同的特征层横向连接起来,可以看出特征金字塔主要从尺度层面考虑。但特征金字塔结构也存在不足,首先特征金字塔的主干网络是为分类任务设计,对于目标检测任务不一定非常适用,其次特征金字塔的每个特征层主要或仅从主干网络的单层中提取,这意味它主要或仅包含单层信息。

图6 特征金字塔结构图Fig.6 The architecture of feature pyramid network
因此引入多层级特征融合金字塔(multi-level feature pyramid network,MLFPN)。多层级特征融合金字塔由Zhao等[22]提出,该特征融合金字塔与FPN最大的不同在于结构上兼顾尺度与层级两个方面,特征层在输入金字塔前会进行初步融合,并使用多个U形结构进行连续的特征提取,形成不同层级、不同尺度的多个特征金字塔,最后融合成一个多层级多尺度的特征金字塔用于检测。这样能够在FPN的基础上,有效地将浅层特征和深层特征结合起来进行目标检测。
1.3.1 特征融合模块
为了提高不同尺度特征图的融合效果,特征融合模块(feature fusion module,FFM)融合不同尺度的特征图,FFMv1将送入特征金字塔的两个不同尺度的特征图进行初步的融合,得到基础特征层(base feature),因此会有一个上采样的操作,将深度特征缩放到与浅层特征相同的尺度。首先将Conv4_3层和Fc7层的通道数都调整为1 024,然后对Fc7层进行一次上采样,使其与Conv4_3层尺度一致,再使用Concatenate函数将两者融合,融合输出再通过一个RFB_s模块进行感受野增强得到Conv_Concat层;接着使Fc7层通过一个RFB_s模块进行感受野增强得到Conv_RFB层。将Conv_Concat层和Conv_RFBs层作为FFMv1模块的输入,得到基础特征层。
FFMv2将FFMv1输出的基本特征图和上一个TUM模块输出的最大特征图作为输入,产生下一个TUM的融合特征图。FFMv1和FFMv2的结构如图7所示。为了不过多增加计算量,因此输入FFM模块融合的特征层的尺度较小,但这样会导致小目标检测效果下降,因此沿用感受野增强的思想,在FFM模块和TUM模块之间嵌入RFB_s模块,扩大输入FFMv2模块的特征层的感受野,增强对小目标的检测效果。
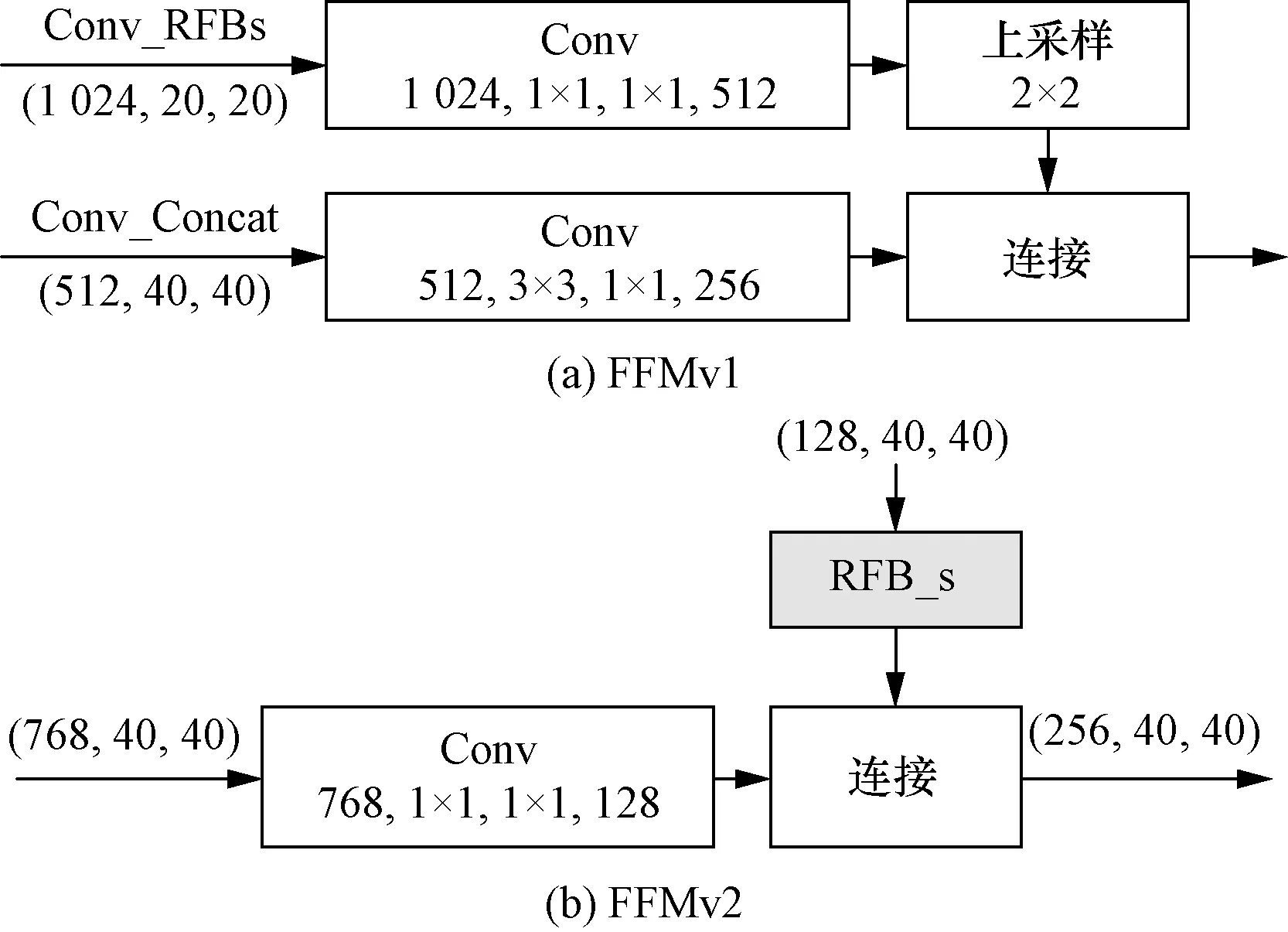
图7 特征融合模块结构图Fig.3 The architecture of feature fusion module
1.3.2 增大感受野的U形模块
减薄的U型模块(thinned U-shape module,TUM))的结构与FPN特征金字塔结构类似,对输入的特征层进行特征提取,即先对特征层用大小为3×3的卷积核下采样,进行连续的特征压缩,再用同样大的卷积核连续上采样,然后将尺度相同的特征层进行融合,得到6个不同尺度的有效特征层。与FPN特征金字塔结构不同的是,TUM模块在上采样步骤之后添加一个1×1的卷积层和按元素求和的操作,可以增强学习能力并保持特征的平滑性。
但是在连续下采样过程中由于图形分辨率的降低会导致信息丢失,因此参照上述RFB模块的思路,使用膨胀卷积代替常规卷积,增大特征层的感受野,让下采样输出的卷积层包含更大范围的信息,且使用膨胀卷积不会增加计算量,将替换后的TUM模块称为TUM_D模块。TUM_D模块结构如图8所示,其中红色虚线框中为替换常规卷积的膨胀卷积。下采样的常规卷积的卷积核大小为3×3,步长为2,替换为膨胀卷积后卷积核大小不变,步长为1,膨胀率为3。
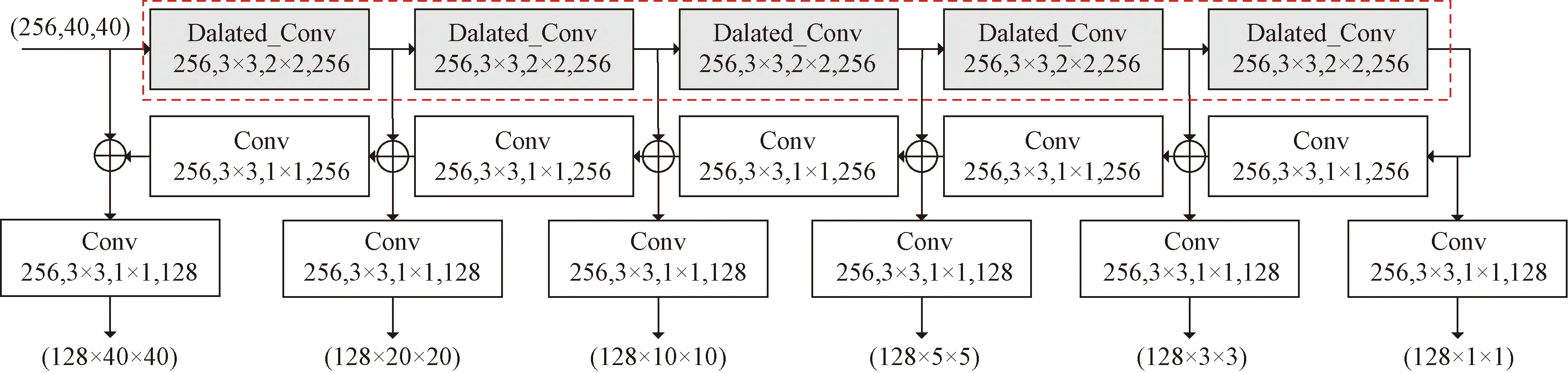
图8 感受野增大的U形模块结构图Fig.8 Structure diagram of U-shaped module with enlarged receptive field
1.3.3 基于尺度的特征聚合模块
基于尺度的特征聚合模块(scale based feature aggregation module,SFAM)负责将TUM模块输出的多尺度特征层构造多层级特征金字塔,构造过程分为两个阶段。第一个阶段是将相同尺度的特征层连接在一起,这样得到的每个尺度的特征都包含多层级信息。第二个阶段引入注意力模块SE[23],通过两个全连接层(Fc1,Fc2)实现注意力机制,进行各通道的注意力机制调整,判断每个通道数应有的权重,将特征集中在最有益的通道。SFAM模块结构如图9所示。
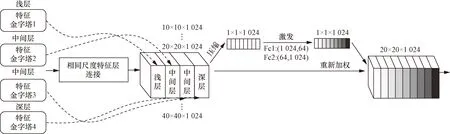
图9 基于尺度的聚合特征模块Fig.9 The architecture of scale-wise feature aggregation module
2 实验准备及结果分析
2.1 实验准备
实验所使用的数据集为KITTI[24]数据集,KITTI数据集为常用的自动驾驶数据集,包含在不同天气、环境和时间下采集的大量真实交通场景,分为8个类别,共计7 481张图片,考虑到KITTI数据集部分类别数量少,且有的类别并不属于所研究的对象,为了便于训练,将Car、Truck、Van合并为Car,将Person_siting、Pedestrian合并为Pedestrian,Cyclist单独作为一类,并忽略掉Tram、Dontcare和Misc。实验主要硬件配置为Inter(R)Core(TM)i5-8300HCPU@2.3GH处理器、GeForce GTX 1050Ti显卡和16 G内存,操作系统为Windows 11。深度学习框架为Tensorflow 1.13.2+Keras 2.1.5。优化方式选择批量梯度下降,每训练整个数据集一次对学习率进行一次调整,调整方式为指数衰减,根据TensorFlow官方文档将衰减指数设置为为0.94,为了平衡训练时间与训练效果,参照文献[9]将初始学习率设置为0.000 1,训练时期设置为300个epoch。
2.2 实验结果与分析
实验分为两个部分。第一部分是验证感受野增强模块(RFB_s)和多级特征金字塔(MLFPN)对目标检测的影响,设计了消融实验。第二部分是将本文模型与Faster R-CNN[3]、SSD[9]及其改进算法DSSD[10]、DDSDD[11]、FSSD[11]、RSSD[13]等主流目标检测网络进行训练和检测效果对比。
使用平均精度(average precision,AP)和平均精度均值(mean average precision,mAP)对模型性能进行评估,AP是以精确度(precision,P)和召回率(recall,R)为坐标轴绘制的P-R曲线下的面积,mAP则是所有类别AP的平均值。精确度和召回率的计算公式如下。
(1)
(2)

(3)
式中:TP(true positives)为被正确分类的正样本数量;FP(false positives)为被错误分类的正样本数量;FN(false negatives)为被错误分类的负样本数量。
首先进行的是消融实验,目的是定量分析感受野增强模块和多级特征金字塔在SSD网络模型对小目标检测效果的影响。取3类检测目标的AP、交并比(intersection over union,IoU)为0.5时的平均精度均值(mAP)和帧率(frames per second,FPS)作为评价指标,消融实验结果如表1所示。
由表1可知,将RFB_s模块嵌入SSD网络模型中,3个检测类别的AP分别提高了1.58%、1.42%、2.54%,平均精度均值(mAP)由67.58%提高到70.12%,帧率降低了2.0 帧/s;在SSD网络模型中加入MLFPN,mAP提高了4.6%,但模型更复杂,故帧率从33.2 帧/s下降到29.3 帧/s;在SSD网络模型中同时加入RFB_s模块和MLFPNN,即本文算法,mAP提高到73.59%,帧率下降了4.4 帧/s。由实验结果可知,相较于原始SSD算法,本文算法在Car、Pedestrian、Cyclis这3个检测类别上的检测精度均有明显提高,同时也兼顾了检测速度。

表1 消融实验结果Table 1 Results of ablation experiments
SSD模型与本文模型检测效果对比如图10所示,图10(a)、图10(c)、图10(e)、图10(g)为SSD模型检测效果,图10(b)、图10(d)、图10(f)、图10(h)为本文模型检测效果。图10(a)和图10(b)为同一数据集的一张图片,本文模型相对SSD模型能够检测出远处的行人和更多的骑行者;图10(c)和图10(d)为同一数据集的一张图片,本文模型相对SSD模型成功检测出远处的行人;图10(e)和图10(f)为同一数据集的一张图片,SSD模型漏检了左边两位远处的行人,而本文模型成功检测;图10(g)和图10(h)为同一数据集的一张图片,本文模型相较于SSD模型检测了远处的多辆汽车,而且对于被汽车遮挡的行人也成功检测到。通过以上分析可知,本文提出的改进SSD模型相较于原始SSD模型,检测出小目标的效果更好。

图10 SSD模型与本文模型检测效果对比图Fig.10 Comparison of the detection of SSD model and the model proposed
第二个实验是将Faster R-CNN、SSD、DDSSD、DSSD、FSSD、RSSD和本文算法进行对比,取三类检测目标的AP值、IoU=0.5时的平均精度均值(mAP)和帧率(FPS)作为评价指标,性能对比实验结果如表2所示。
如表2所示,与二阶段算法Faster R-CNN相比,本文算法在3个检测类别的AP上分别提升了2.92%、3.4%、5.4%,FPS提升了17.8 帧/s,说明本文算法在检测精度与检测速度上均优于二阶段算法;与SSD算法相比,本文算法在3个检测类别的AP上分别提升了4.9%、3.66%、9.46%,证明感受野增强和多层级特征融合可以提升模型对小目标的检测效果,但是由于结构更复杂导致检测速度略有下降;与SSD的改进算法DDSSD、RSSD、FSSD、DSSD相比,本文算法在3个检测类别的AP上均有提升,综合起来mAP分别提升了1.83%,3.03%,1.94%,2.64%,同时检测速度也分别提高了5.0、4.7、0.5、18.5 帧/s,平均提高7.2 帧/s。通过以上分析可知,本文算法通过增强特征层的感受野和采用多层级特征融合结构,相较于其他SSD改进算法,对小目标的检测效果的提升更好,并有更快的检测速度,能够运用于自动驾驶中的实时检测。

表2 性能对比实验结果Table 2 Results of performance comparison experiment
3 结论
针对SSD算法应用在自动驾驶领域时,在小目标检测中易出现漏检错检等问题,提出了改进SSD的小目标检测算法。根据理论分析和实验验证,得出以下结论。
(1)对感受野模块进行优化,通过加入一条更大膨胀率的分支,扩大特征层的感受野,提高了特征层提取道路小目标特征的效果,对比SSD模型,检测精度提高了2.54%。
(2)引入多层级特征金字塔,并在其中加入感受野增强模块,从尺度和层级两个方面利用浅层语言信息和深层语义信息,进一步提高道路小目标检测效果,对比SSD模型,检测精度提高了4.60%。
(3)在自动驾驶公开数据集KITTI上进行消融实验和性能对比试验,实验结果表明所提出的两个改进点对道路上小目标的检测效果有明显提升;与原始SSD算法相比,本文算法的检测精度提高了6.01%;与SSD的其他改进算法相比,本文算法的mAP平均提升2.36%,FPS平均提高7.2 帧/s,达到27.9 帧/s,说明本文算法的检测精度与检测速度均更优。
但是本文模型在检测被遮挡的小目标中依然存在未能有效检测的问题,以及模型的参数量还有进一步优化的空间,后期将从主干网络特征提取和模型剪枝两方面进行分析,适当解决部分相关问题。
