Policy Iteration for Optimal Control of Discrete-Time Time-Varying Nonlinear Systems
2023-03-27GuangyuZhuXiaoluLiRanranSunYiyuanYangandPengZhang
Guangyu Zhu, Xiaolu Li, Ranran Sun, Yiyuan Yang, and Peng Zhang
Abstract—Aimed at infinite horizon optimal control problems of discrete time-varying nonlinear systems, in this paper, a new iterative adaptive dynamic programming algorithm, which is the discrete-time time-varying policy iteration (DTTV) algorithm, is developed.The iterative control law is designed to update the iterative value function which approximates the index function of optimal performance.The admissibility of the iterative control law is analyzed.The results show that the iterative value function is non-increasingly convergent to the Bellman-equation optimal solution.To implement the algorithm, neural networks are employed and a new implementation structure is established,which avoids solving the generalized Bellman equation in each iteration.Finally, the optimal control laws for torsional pendulum and inverted pendulum systems are obtained by using the DTTV policy iteration algorithm, where the mass and pendulum bar length are permitted to be time-varying parameters.The effectiveness of the developed method is illustrated by numerical results and comparisons.
I.INTRODUCTION
OPTIMAL control has been well developed for control of dynamical systems with a time-invariant model in control system society [1]–[13].As is known to all, the optimal solution for a control system can be obtained by solving the Bellman equation.Generally speaking, it is very difficult to obtain the analytical solution of the Bellman equation, especially for nonlinear systems.In order to obtain the approximate control solutions, several methods have been proposed,where adaptive dynamic programming (ADP), proposed by Werbos [14], [15], has gained much attention from researchers, as this method permits solving optimal control problems forward-in-time.To solve the Bellman equation, iterative method is the main tool in ADP and has been increasingly emphasized [16]–[26].
Policy iteration is one of the main iteration algorithms in ADP [27]–[29].In 1996, Bertsekas and Tsitsiklis [30] proposed a policy iteration algorithm for nolinear systems.In 2002, for continuous-time affine systems with a quadratic utility function, Murrayet al.[31] first put forward the convergence of the policy iteration.In 2005, for continuous-time nonlinear systems with constraints of control, a bound-constraint policy iteration algorithm was proposed [32].In [33],for polynomial nonlinear systems, the policy iteration ofH∞optimal control was investigated via sum of squares programming.In [34], in order to obtain optimal output tracking control, the policy iteration by a multi-step policy evaluation was proposed.To obtain the optimal control law according to system data for an unknown system model, Yanet al.[35] proposed aQ-learning algorithm based on policy iteration, where the error of theQfunction was considered.For a class of discrete-time system with multiple delays, a data-based ADP algorithm was proposed in [36].For affine nonlinear systems,off-policy iteration-based ADP algorithms were widely used for data-based optimal control [37]–[39].In [40]–[42], the optimal cooperative control for multi-agent systems was obtained by using policy iteration.From the previous literature, most policy iteration ADP algorithms were focused on the optimal control of time-invariant nonlinear systems[31]–[46].However, it should be noted that the existing policy iteration methods are aimed at optimal control problems for time-invariant systems, where both of the performance index functions and optimal control laws are functions of the system states.As far as authors know, there are no policy iteration methods for discrete-time time-varying (DTTV) systems in existing research results, which is the starting point of this paper.
In numerous industrial applications, however, the systems’dynamics may change over time.In the case of time-varying systems, optimal performance index functions and optimal control law are related to not only the state but also the time index, which makes traditional time-invariant policy iteration algorithms unavailable for systems with time-varying dynamics.Establishing a new iteration method to cope with the timevarying properties of time-varying systems is the main theoretical difficulty and challenge of this paper.Aimed at discrete-time infinite horizon optimal control problems of timevarying nonlinear systems, a novel iteration algorithm for DTTV policy iteration algorithm is developed in this paper.The main contributions can be given as follows:
1) A novel DTTV policy iteration algorithm is presented in this paper.It is the first time that an ADP method is developed for DTTV systems.
2) The properties of the presented algorithm, including monotonicity, convergence and optimality, are analyzed in detail.
3) Simulation results show that the presented method can obtain the optimal control law and optimal performance index function, which verifies the correctness of the DTTV policy iteration method.
First, for the DTTV policy iteration algorithm, the iteration rules for the iterative value function and iterative control law are designed.Next, it will be shown that any of the iterative time-varying control laws is an admissible control law.Then,the fact that the value functions are monotonically nonincreasing and converge to the optimal performance index function will be proven.We establish new neural network structures to approximate the time-varying iterative control laws and value functions, and the developed DTTV algorithm is implemented, where the difficulty in solving the generalized time-varying Bellman equation can be avoided.Finally,in order to solve the optimal control for the torsional pendulum and inverted pendulum systems, the present DTTV algorithm are implemented, where the mass and length of the systems are permitted to be time-varying parameters.In this situation, the effectiveness of the developed algorithm is verified by the numerical results.
II.PROBLEM FORMULATIONS

Therefore, we express the Bellman equation (4) as
III.DISCRETE-TIME TIME-VARYING POLICY ITERATION
For the DTTV policy iteration algorithm, the derivations will be discussed in this section.We will study the admissibility of the iterative control law, and then analyse the convergence of the iterative value functions to prove that the functions will converge to the optimum.
A.Derivations of the DTTV Policy Iteration Algorithm


Algorithm 1 DTTV Policy Iteration Algorithm Require:Choose an admissible control law randomly.Choose a computation precision σ.Ensure:i=0 V0(xk,k)v0(xk,k)1: Let the iteration index.Construct which satisfies the time-varying Bellman equation (7).i=i+1 2: Let.Perform policy improvementvi(xk,k)= argminuk{U(xk,uk,k)+Vi−1(xk+1,k+1)}.(10)3: Perform policy evaluationVi(xk,k)=U(xk,vi(xk,k),k)+Vi(xk+1,k+1).(11)4: If , goto Step 2.vi(xk,k)Vi(xk,k)Vi−1(xk,k)−Vi(xk,k)>σ 5: return ,.
Remark 1:It is worth pointing out the difference between the traditional time-invariant policy iteration algorithms in[46] with the developed algorithm (7)–(9).First, for traditional time-invariant policy iteration algorithm in [46], the iterative control law and iterative value function are both time-invariant functions, which only depended on the statexk.Meanwhile, the iterative control law and iterative value function are both time-varying functions for the time-varying policy iteration algorithm, which means the iterative control lawvi(xk,k) and iterative value functionVi(xk,k) are different for differentk.Second, for the algorithm in [46], obtaining the iterative control lawvi(xk), the iterative value function can be derived by the following equation:
In the time-varying policy iteration algorithm, for anyi=0,1,..., in (9), the iterative value functionsVi(xk+1,k+1)andVi(xk,k) are different functions.It implies that we cannot obtain the iterative value functionVi(xk,k) by directly solving(7) and (9).Furthermore, for the time-varying policy iteration algorithm, the analysis method for the time-invariant algorithm in [46] cannot be directly used.Hence, new analysis and implementation methods for the time-varying policy iteration algorithm is developed in this paper.On the other hand, if the system and the utility function are both time-invariant, then the DTTV policy iteration algorithm is reduced to the traditional policy iteration algorithm in [46].Hence, we say that the traditional policy iteration algorithm is a special case for the developed DTTV policy iteration algorithm and the DTTV policy iteration algorithm possesses more application potential.
Remark 2:With the development of computational capacity,there is a growing number of needs for the control of complex systems.For complex systems, the system models are always nonlinear and time-varying, which bring great challenges for control and optimization.Furthermore, traditional policy iteration methods can only tackle optimization problems for systems with time-invariant iterative control law and the iterative value function.Establishing a new policy iteration method to obtain the optimal iterative control law and optimal iterative value function of DTTV systems is also a challenge.
B.Property Analysis
For time-invariant nonlinear systems, although the policy iteration algorithm properties were analyzed in [46], it cannot directly be applied to time-varying nonlinear systems.For the DTTV policy iteration algorithm, the properties will be analyzed in this subsection.The optimality and convergence of the iterative value function will be developed, while the admissibility of the iterative control law is discussed.First,some lemmas are necessary for discussions.
Lemma 1:Letvi(xk,k) andVi(xk,k) be obtained by (7)–(9)fori=0,1,...Ifvi(xk,k),i=0,1,..., is an admissible control law for system (1), there exists an iterative value functionVi(xk,k)that satisfies (7) and (9).
Proof:For admissible control lawvi(xk,k) , wheni=0,1,...,we get



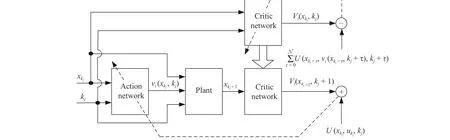
Fig.1.The structure diagram of the algorithm.

After combining (33) and (38), the conclusion (28) can be drawn.■
IV.IMPLEMENTATION OF THE DTTV POLICY ITERATION

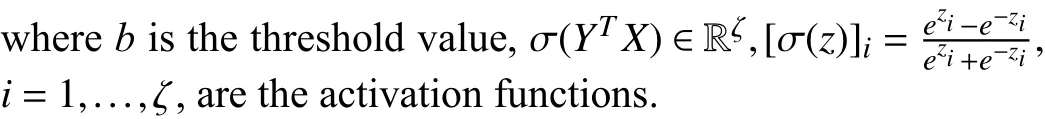
A.The Critic Network
The iterative value functionVi(xk,k),i=0,1,..., is approximate to by using critic network.It should be noted that, for the approximation of time-varying policy iteration algorithm, the neural network approximation for the time-invariant policy iteration algorithm [46] is invalid.First, the iterative value function in [46] is a time-invariant function which is only a function ofxk, i.e.,Vi(xk), for the traditional time-invariant policy iteration algorithm.The iterative value function for the DTTV algorithm is the function for not onlyxkbut alsok, i.e.,Vi(xk,k).For the time-varying policy iteration algorithm, the neural network approximation in the traditional time-invariant policy iteration algorithm is unsuitable to be employed.Second, for time-invariant policy iteration algorithms of systems, the iterative value functionVi(xk) can be obtained by solving (12) which is generally easy to solve, in the case of an iterative control lawvi(xk) being given.However,Vi(xk,k)cannot be obtained by directly solving (7) and (9) with the time-varying policy iteration algorithm, in the case of an iterative control lawvi(xk,k) being given.Thus, in this subsection,the neural network approximation must be improved.
Fori=0,1,..., the iterative control lawvi(xk,k) is proven to be admissible, and the iterative value functionVi(xk,k) converges to zero ask→∞.Thus, for anyi=0,1,..., the iterative value functionVi(xk,k) for 0 ≤k<∞ can be approximated by the functionVi(xk,k) for 0 ≤k≤Tf, whereTfis a large positive integer and for allk>Tf, we regardVi(xk,k)=0.Let M be a positive integer.Letkj,j=0,1,...,M, be time instants, which satisfy 0 ≤kj≤Tf.


B.The Action Network


V.NUMERICAL EXAMPLES
In this section, the effectiveness of the developed algorithm is illustrated by two pendulum systems, which are the torsional pendulum and inverted pendulum systems, respectively.

Example 1:First, for a torsional pendulum system [47] with modifications, where the mass of the pendulum is time-varying, the performance of the developed algorithm is considered.Give the pendulum dynamics as follows:algorithm, neural networks are used.Three-layer BP neural networks are adopted for the action network and the critic network, with the structures of 3–8–1 and 3–8–1, respectively.The neural network training errors are less than 1 0−4by training the action network and the critic network for 2000 steps step under the learning rate 0.01, in each iteration.LetTf=10 s andN=200.Implementing the algorithm for 20 iterations, the convergence ofVi(xk,k) atx0is shown in Fig.2.In Fig.3, the control and states trajectories are shown.It indicates that the iterative value function is convergent to the optimum and non-increasing.The iterative control law is admissible for each iteration.
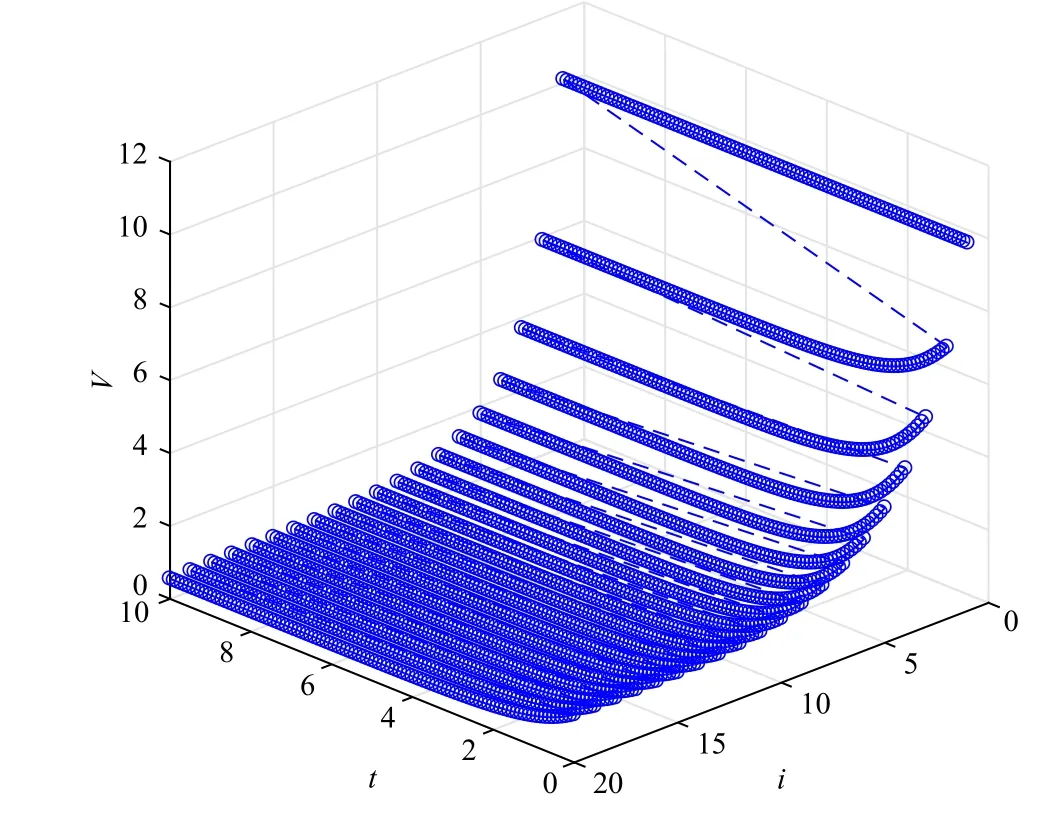
Fig.2.Convergence plots of the iterative value functions.
In order to show the effectiveness of the developed method,the numerical optimal open-loop solution of the continuoustime time-varying optimal control problem is obtained by direct collocation methods [48].In detail, the continuous-time time-varying optimal control problem is first discretized and formulated as a nonlinear programming using the publicly available Open Optimal Control Library [49].Then the resulting nonlinear programming problem is solved by the interior point optimizer [50].In Fig.4, the optimal open-loop control and states trajectories are shown.From Figs.3 and 4, it is shown that the trajectories obtained by direct collocation methods are almost the same as the ones by the developed method.Thus, the optimality of the developed algorithm is verified.However, the optimal control obtained by direct collocation methods is an open-loop control law and is applicable to a single initial state, while the optimal control obtain by the developed method is a closed-loop optimal control law and is applicable to all initial states.
Example 2:The discretized inverted pendulum system [51]with modifications is considered in the second example.The dynamic of the time-varying pendulum system is expressed as

Fig.3.Trajectories of states and controls.(a) x1; (b) x2; (c) u.
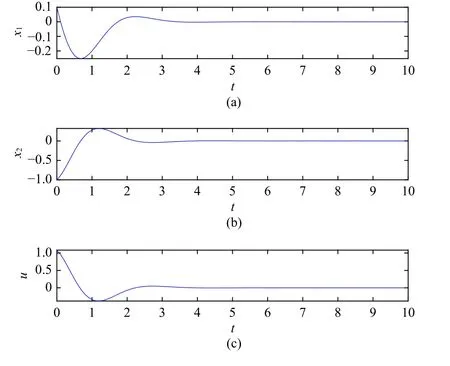
Fig.4.Trajectories of optimal states and controls.(a) x1; (b) x2; (c) u.
With the sampling interval ∆t=0.1 s, the performance index function and the system function are discretized, that leads to
wheremkand ℓkdenote the time-varying mass and length of the pendulum bar, respectively.Letg=9.8m/s2be the gravitational acceleration, and let κ=0.2 be the frictional factor.The same utility function as the one in Example 1 is chosen.To implement the algorithm, neural networks are used.Threelayer BP neural networks are adopted for the action network and the critic network with the structures of 3–8–1 and 3–8–1,respectively.

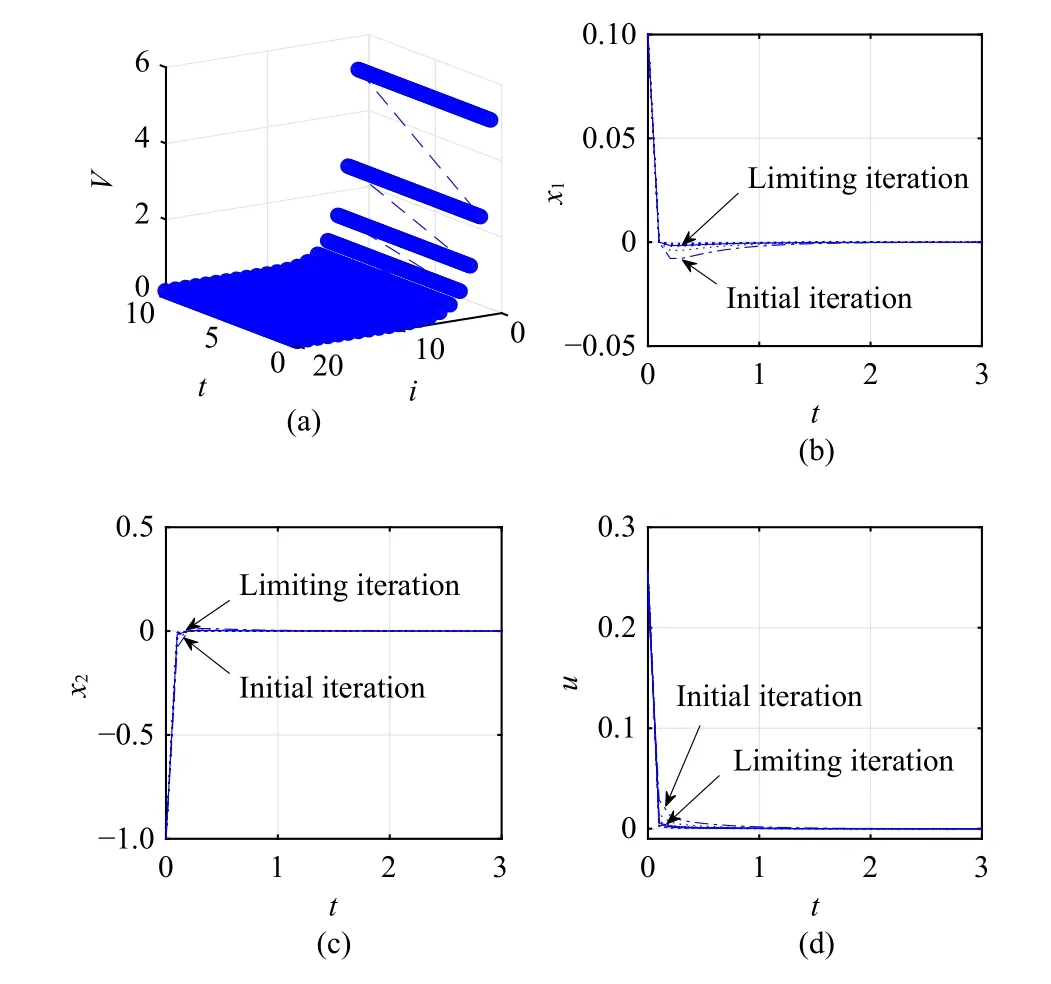
Fig.5.Numerical results for Case 1.(a) Iterative value function; (b) Statex1; (c) State x2; (d) Control.


Fig.6.Numerical results for Case 2.(a) Iterative value function; (b) Statex1; (c) State x2; (d) Control.
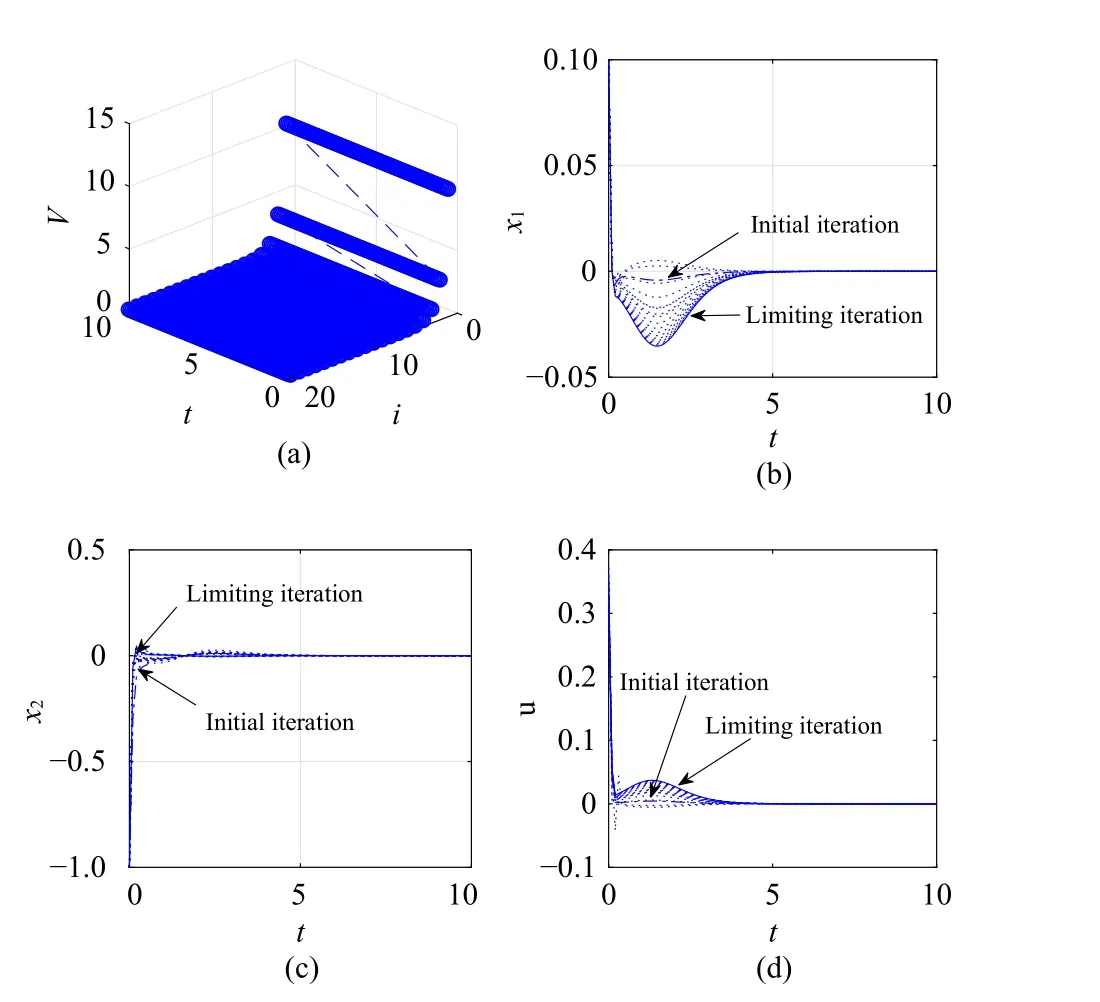
Fig.7.Numerical results for Case 3.(a) Iterative value function; (b) Statex1; (c) State x2; (d) Control.

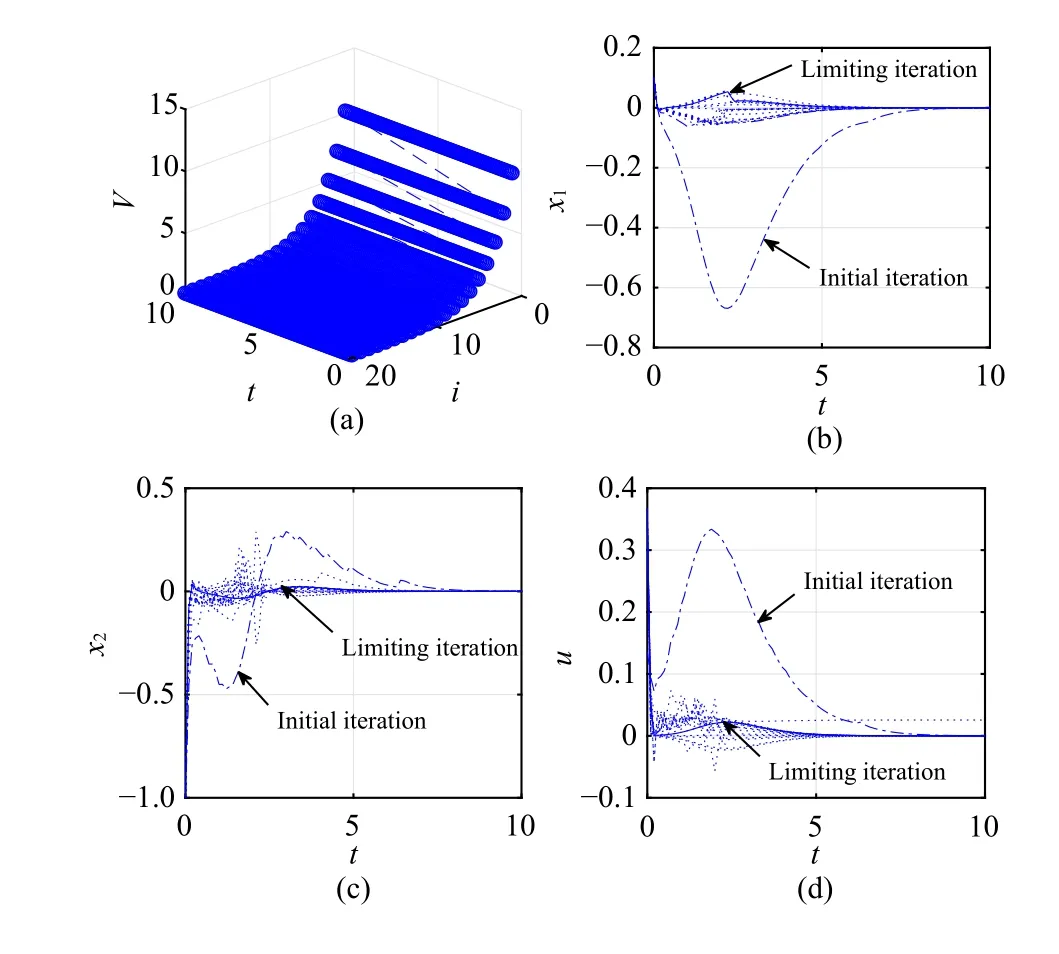
Fig.8.Numerical results for Case 4.(a) Iterative value function; (b) Statex1; (c) State x2; (d) Control.
Compared with the time-invariant system in Case 1, it is shown that the convergence processes in Cases 2–4 for the time-varying systems are obviously different.The optimal performance index functions and optimal control laws for time-varying systems are also different from the ones for the time-invariant system.On the other hand, it is shown that for different time-varying systems in Cases 2–4, the convergence processes are also different.However, it is declared that using the DTTV policy iteration algorithm, the iterative value function is non-increasing and converges to the optimum.Furthermore, it is shown that the iterative control law is admissible.Hence, for the developed DTTV policy iteration algorithm,the convergence, optimality, and admissibility properties can be verified.
VI.CONCLUSIONS
A novel iterative ADP algorithm, called the“discrete-time time-varying (DTTV) policy iteration”algorithm, is presented in this paper.For discrete-time time-varying nonlinear systems, the developed algorithm is used to solve optimal control problems with an infinite horizon.An admissible control law is used in the initialization of the DTTV policy iteration algorithm.Two iteration procedures are introduced for the algorithm.According to the iterative value function, the iterative control law is updated in the policy update step.Next, the iterative value function is improved via the updated iterative control law in the policy improvement step.It is shown that the iterative value function converges to the optimum and is non-increasing.The DTTV policy iteration algorithm is implemented by neural networks, where detailed training rules of the networks are presented.Then, the optimal control laws for torsional pendulum and inverted pendulum systems are obtained by using the DTTV policy iteration ADP algorithm,where the mass and pendulum bar length are permitted to be time-varying parameters.Finally, the performance of the presented method is illustrated by the numerical results and comparisons.Some interesting future work are to extented the time-varying policy iteration method to optimal control problems with finite-horizon performance index functions and optimal control problems of periodic systems.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Meta-Energy: When Integrated Energy Internet Meets Metaverse
- Cooperative Target Tracking of Multiple Autonomous Surface Vehicles Under Switching Interaction Topologies
- Distributed Momentum-Based Frank-Wolfe Algorithm for Stochastic Optimization
- A Survey on the Control Lyapunov Function and Control Barrier Function for Nonlinear-Affine Control Systems
- Squeezing More Past Knowledge for Online Class-Incremental Continual Learning
- Group Hybrid Coordination Control of Multi-Agent Systems With Time-Delays and Additive Noises