Parallel Learning: Overview and Perspective for Computational Learning Across Syn2Real and Sim2Real
2023-03-27QinghaiMiaoYishengLvMinHuangXiaoWangandFeiYueWang
Qinghai Miao,, Yisheng Lv,, Min Huang,, Xiao Wang,, and Fei-Yue Wang,
Abstract—The virtual-to-real paradigm, i.e., training models on virtual data and then applying them to solve real-world problems,has attracted more and more attention from various domains by successfully alleviating the data shortage problem in machine learning.To summarize the advances in recent years, this survey comprehensively reviews the literature, from the viewport of parallel intelligence.First, an extended parallel learning framework is proposed to cover main domains including computer vision, natural language processing, robotics, and autonomous driving.Second, a multi-dimensional taxonomy is designed to organize the literature in a hierarchical structure.Third, the related virtual-toreal works are analyzed and compared according to the three principles of parallel learning known as description, prediction,and prescription, which cover the methods for constructing virtual worlds, generating labeled data, domain transferring, model training and testing, as well as optimizing the strategies to guide the task-oriented data generator for better learning performance.Key issues remained in virtual-to-real are discussed.Furthermore, the future research directions from the viewpoint of parallel learning are suggested.
I.INTRODUCTION
BIG data, algorithms, and computing capability, are well known as three driving forces that push deep learning to the current prosperity.Algorithms, as well as a variety of neural models, have kept refreshing the state-of-art (SOTA) during the last decade, boosted by powerful computing hardware.ResNet (residual neural network), YOLO (you only look once), Mask R-CNN (region convolutional neural network),transformer, and GAN (generative adversarial network) are such outstanding models/methods.
Besides many achievements from both academia and industry, deep learning is obstructed in some areas because of data scarcity.Factors that affect the data for deep learning mainly come from three aspects.First, for specific tasks like visual perception in autonomous driving, data imbalance is a typical problem.While most of cases can be collected through daily driving across the city, corner cases including vital accidents occur at extremely low frequency, which is known as long tail distribution.In such a situation, data acquisition methods cannot make sure the training data appropriately represent the data distribution supposed to be covered by deep learning models.Second, data labeling for supervised methods is laborintensive and time-consuming, and the quality of labeled data is not always guaranteed due to human mistakes.Third, data privacy is an essential factor that cannot be neglected.For example, biometric data that are related to facial identification and health examinations are not publicly available for deep learning in order to protect them from malicious use.
To address these data problems, people have proposed methods either augmenting existing data or transferring models trained on plenty of data to domains with few data available.Particularly, virtual data generated by synthetization or simulation have attracted increasing attention in recent years.The main feature is using image processing tools, computer graphics tools, and simulation toolkit to automatically generate labeled data for deep models to get better performance and generalization in real applications.Taking visual tasks as an example, works on sub-tasks like classification, recognition,detection, segmentation, estimation, reported improvements on performance with the help of virtual data.People from domains like computer vision, autonomous driving, robotics control, as well as natural language processing have taken advantage of virtual data to address data scarcity problems in their applications.These methods are referred as the virtualto-real paradigm, or V2R in short.
During the last five years, numerous methods have been proposed to generate virtual data for machine learning.As a fast-developing topic, reviews on recent progress are essential for further development.There have been several related surveys.Nikolenko [1] conducted a review on synthetic data for deep learning, covering data synthetization within and outside computer vision tasks, synthetic-to-real domain adaptation problems and privacy-related applications.Shorten and Khoshgoftaar [2] and Tsirikoglouet al.[3] emphasized on image augmentation and image synthesis respectively.Zhaoet al.[4] and Muratoreet al.[5] focused on domain randomization in sim-to-real dedicated to robotic control.Although these surveys reviewed the virtual-to-real methods from different aspects, it is still necessary to review new advancements from a comprehensive viewport.First, most the existing surveys mainly focused on specific sub-domain, like computer vision and robotics control, etc.Lacking of high level virtual-to-real theory makes it difficult for readers to compare methods and borrow better ideas from different domains.It is highly necessary to summarize the common issues and techniques of virtual-to-real methods across sub-domains in machine learning.Second, the existing taxonomy is too simple to help readers from different domains to find the most related works.A comprehensive taxonomy with hierarchical dimensions is more appreciated.In addition, since these surveys published, much of the work has made incremental advances to state-of-the-art, so establishing a baseline for future work remains important.
To overcome these constraints, in this paper, we provide a survey on virtual-to-real methods at the level of machine learning, under the framework of parallel intelligence [6], [7].We try our best to cover new advancements in recent years, in multiple machine learning sub-domains including computer vision (CV), natural language processing (NLP), robotics, and autonomous driving (AD), as shown in Fig.1.We propose a multi-dimensional taxonomy according to the three key components of parallel learning, i.e., description, prediction, and prescription.
This paper is organized as follows.The related background is introduced in Section II.A new taxonomy with multiple dimensions is presented in Section III.Methodologies are reviewed in Section IV succeeded by discussion in Section V.The paper is summarized with the remaining problems and future directions in Section VI.
This survey provides the following contributions:
1) An extended Parallel Learning framework covering main machine learning tasks including computer vision, natural language processing, robotics and autonomous driving.
2) A systematical survey of the existing methods via virtualto-real paradigm from the viewpoints of parallel learning.
3) A multi-dimensional and multi-level taxonomy of virtualto-real methods.
4) A discussion about the current situation, and the main challenges and opportunities for future work.
II.BACKGROUND
In this section, we give a background of virtual-to-real in machine learning.We start with parallel intelligence [6],which is a theory on interactions between the virtual and real worlds to form a closed-loop artificial intelligence (AI) system.We then introduce related techniques for virtual data generation, including domain augmentation, domain randomization, and domain adaptation.We also have a look at the challenges in syn-to-real or sim-to-real applications.
A.Parallel Intelligence
Though the virtual data used in machine learning can be traced back to a very early age, it was regarded as a trick to alleviate data shortage problems.There was not a theory to guide the use of real and virtual data until 2004 when Fei-Yue Wang proposed the theory of parallel intelligence (PI), with three principles known as artificial systems, computing experiments and parallel execution (ACP) [6]−[10].The parallel intelligence theory has been successfully applied to various domains like [11]−[14], etc.Further in 2017, Liet al.[15]proposed the parallel learning (PL) framework that searches for optimized policy with virtual-real interactions.The PL framework comprises three components known as description,prediction, and prescription, as shown in Fig.2.
Given a machine learning task in real world, the description in PL stands for the process to construct corresponding artificial system from which virtual data are derived with labels.A typical way is taking off-the-shell computer graphics tools to reconstruct three-dimensional virtual scenes, aiming to generate virtual data that approaches the real data distribution.In the case of reinforcement learning (RL), system identification is required to reconstruct the real world with high fidelity not only on appearance but also on dynamic parameters.
The prediction in PL is to train models with the generated virtual data aiming for better generalization, or train intelligent agents within the virtual environment aiming for better policy.Succeeding tests on the real data or in the real world are fulfilled to evaluate the learning performance.The training and testing form the pipeline of computational experiments.
Due to the domain gap between the virtual and real world,multiple trials are required to repeat the phases of description and prediction, which results in computational overhead.To deal with this issue, the prescription in PL is essential for better reconstruction of the virtual environment, by feeding back the errors from Prediction to the description.This closed-loop connecting both the real and virtual system iteratively improves the efficiency of the learning process.
B.Digital Twin
The concept of the digital twin was introduced by Grieves[16] around 2003 for product lifecycle management, while the term digital twin was coined by National Aeronautics and Space Administration (NASA), USA in 2010 [17] and has since become a hot topic in recent years, driven by both industry and academia.The principle of the digital twin is to create a digital model (usually three-dimensional) of a physical entity (usually a product) and to evaluate, optimize and manage the physical entity through the interaction between reality and reality.Although parallel intelligence and the digital twin share some common features such as virtual-real interaction,they differ in several ways.Influenced by cybernetics, parallel intelligence covers a broader field of study, including not only physical products but also social systems.Inspired by the Merton’s theory, parallel intelligence places more emphasis on the three principles of description, prediction, and especially prescription.For the virtual-to-reality paradigm discussed in this paper, AI applications using digital twins, e.g.,[18] and [19], focus on the construction of accurate 3-dimensional digital models through evaluation, prediction, and simulation to improve physical entities.Thus, the principles of AI applications through digital twins have been incorporated into an extended parallel intelligence framework.The related literature can be classified into the taxonomy introduced in this paper.
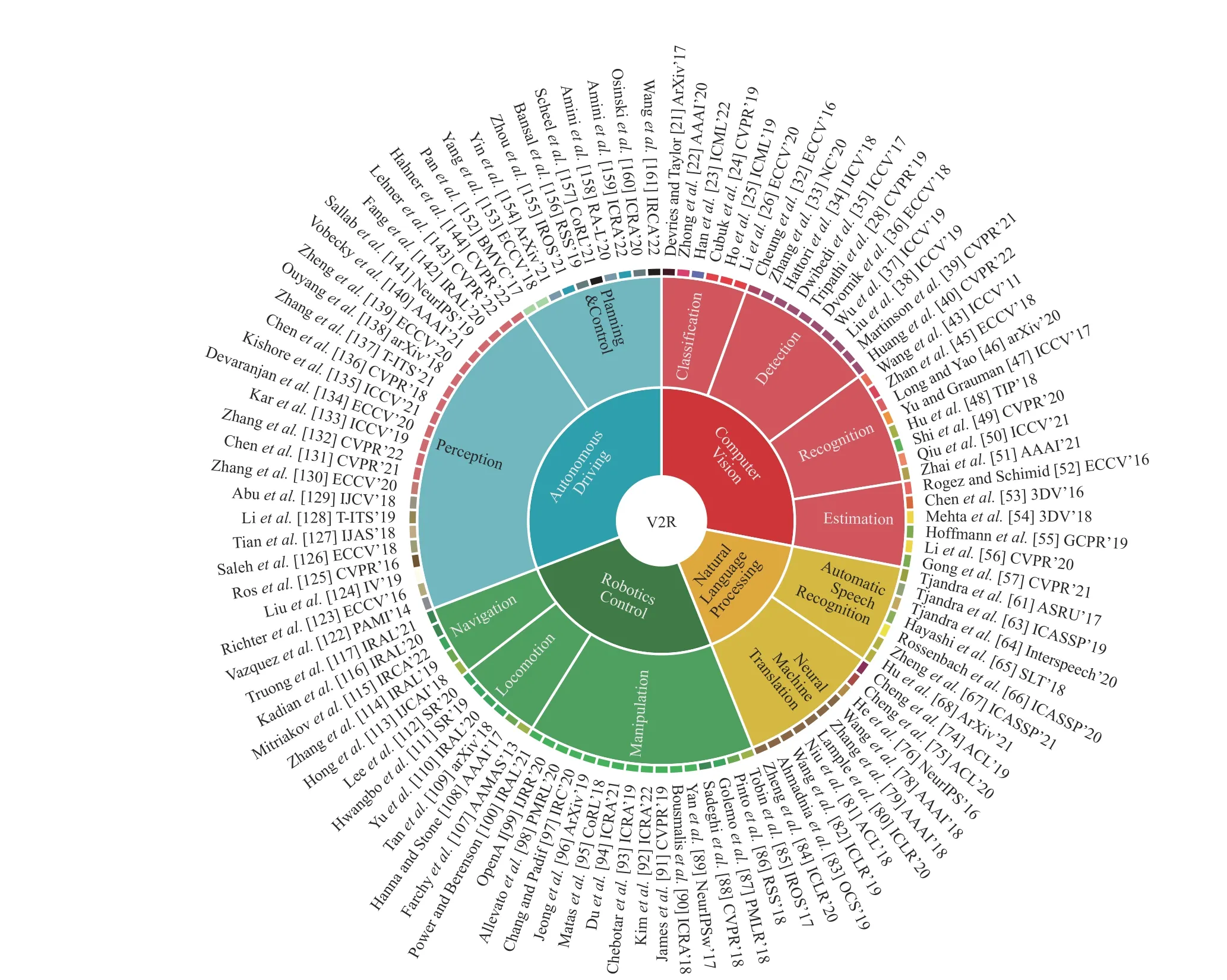
Fig.1.Overall picture of the survey.
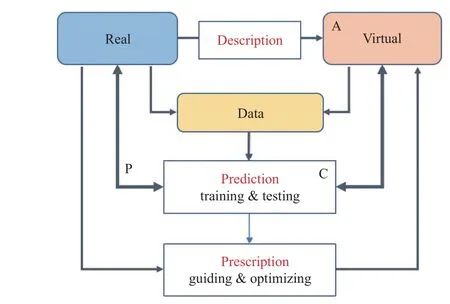
Fig.2.A brief illustration of parallel learning under the ACP framework.
C.Virtual-to-Real in Machine Learning
From Deep Blue to AlphaGo, data play an essential role in the breakthrough of artificial intelligence.The AlphaGo paradigm indicates that, we can find a proper way to generate data if the real labeled data are insufficient.Games like Chess and Go are ideal cases where the rules can be used to run rollouts for the purpose of data collecting.In practical applications of machine learning, there are two types of methods working similarly to AlphaGo paradigm, i.e., syn-to-real and sim-to-real, or virtual-to-real as the unified name.
1) Syn-to-Real:Data synthesis is the most popular method to generate virtual data, especially images for deep visual tasks.There is a variety of ways to generate synthetic images.According to sources from which synthetic images are derived, we can divide synthetic methods into two types:3D−2D and 2D−2D.The 3D−2D is firstly constructing virtual 3D scenes with objects and then rendering images with configurations of camera pose, lighting, and post processing.Both foreground and background of generated images are fully configurable.Unlike 3D−2D, the 2D−2D method tries to insert new objects into background images, followed by an additional fusing process to reduce artefacts.Some popular methods include data augmentation (DA) that modifies the initial image by translating/rotating the objects, image composition that inserts new objects, and image translation that converts the images to target styles.
2) Sim-to-Real:Intelligent agents usually learn to navigate or manipulate in a given environment.As running experiments in the real world is both dangerous and expensive, people turn to take advantage of simulations.Intelligent agents interact with the virtual environment reconstructed in a simulator, supported by including numerical simulation, rendering simulation, and mechanical simulation.The goal is transferring the policy learned in virtual environment to real world with satisfied performance.Domain randomization (DR) is the most popular method in Sim2Real application, including visual domain randomization and dynamic randomization.
D.Challenges
1) Challenges of Description (Data Generation)
a) Virtual world reconstruction:The first step for a virtualto-real application is to build a system to generate virtual data.Building such a system, whether virtual 3D scenes or directly composing on 2D images, is nontrivial and sometimes requires intensive human interventions.
b) Domain gap:It is well known that two datasets sampled under different conditions have domain gaps in distribution.A learning model trained and tested well on one dataset usually cannot generalize well on the other one.Such a domain gap is also inevitable between virtual and real datasets.
2) Challenges of Prediction
To verify the effeteness of virtual data, multiple rounds of training and testing are required to get satisfying performance.However, training deep learning models on big data is time consuming.A large number of generated virtual data make the situation even worse.
3) Challenges of Prescription
A large number of virtual data can be generated at a low cost by image augmentation or domain randomization.However, experiments have indicated that randomly generated virtual data may be harmful to the learning process.Methods to ensure data quality are essential in virtual-to-real applications.To this end, there is much work to be done, albeit some recent works have realized this and tried to improve the quality of virtual data.
III.TAXONOMY OF VIRTUAL-TO-REAL PARALLEL LEARNING METHODS
To give readers a comprehensive overview of the virtual-toreal methodology, we present a hierarchical taxonomy from the viewpoint of parallel intelligence.
A.Classification by Application Domains and Tasks
Researchers on machine learning may come from different domains with different academic backgrounds.It is better to classify the literature according to research domains at the top level.This paper covers four popular domains known as computer vision (CV), natural language processing (NLP),robotics control and autonomous driving (AD), as illustrated in Fig.1.
The first category is computer vision (CV), which achieved great improvements during the last decade.We further classify the related works according to visual tasks including classification, detection, recognition, and estimation.
Natural language processing (NLP) has become a hot domain with the introduction of transformer in recent years.Sequential data like text can be regarded as another type of perception of real world, as essential as images.The training of NLP models also requires a huge number of labeled data,where the virtual-to-real paradigm can take its role.
Robotics is a comprehensive domain that heavily depends on simulation environment due to the high cost of real robotic experiments.The main challenge is finding optimized policy in a simulated environment and then transferring it to the real world.
Autonomous driving (AD) is another domain covering a large number of virtual-to-real applications.Though sharing some common perception and control tasks in CV and robotics, AD has more challenges including multiple sensors fusion, planning under complex environments, and high safety requirements.
B.Classification According to Parallel Learning
At the second level, we analyze each specific virtual-to-real case according to the three aspects of parallel learning, i.e.,description, prediction, and prescription.
1) Description:For the description, we aim to summarize the methods to construct a virtual system from which we can generate virtual data with labels.We design an array whose elements represent the main features of a virtual-to-real task including dimensional mapping type, software to generate virtual data or environment, name of real dataset, name and size of generated virtual dataset, domain adaptation methods, etc.
a) Real-virtual mapping:We regard building a virtual system as a mapping from the real world to virtual world, as shown in Fig.3.Both real data and generated virtual data may have a shape of one (1D), two (2D), three (3D) or four (4D)dimensions.Specifically, text and audio are 1D data with sequential representations, image is in the popular 2D shape,video and point cloud are typical 3D data, while simulations in 3D space are 4D data.
A dimensional mapping from real to virtual reflects how we build a virtual system.For example, image augmentation,image composition and style transfer are all 2D−2D mappings that take real images as input and give modified images as output.The 2D−2D mapping usually edits the foreground while keeping the background of the input image unchanged so that the domain gap is small.
3D−2D mapping is another popular style.To this end, a virtual 3D scene is firstly constructed as a source with an off-theshell software then rendered 2D images as output.This method does not depend on real images and can generate a set of images by projecting from a camera with various configurations.
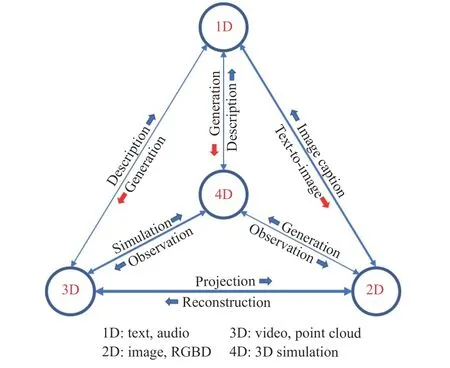
Fig.3.Dimensional data type mapping of virtual data generation.
3D−3D mapping is usually seen in domain of autonomous driving where laser radar (LiDAR) acts as an essential sensor.Virtual 3D cloud points can be generated from 3D virtual scenes.
3D−4D mapping means conducting dynamic simulations in a 3D virtual environment where an agent, e.g., a robot or an autonomous vehicle, can learn policies.
We refer to sequential data, including text and audio, as 1D data.Though in the minority, mappings from 1D source to high dimensional target are emerging.Examples of 1D−1D mapping include augmenting text in NLP, or synthetizing sound in speech recognition.1D−2D or 1D−3D mapping,which means generating images or 3D scenes from a sentence,has become a new frontier in MultiModal machine learning,like DALL-E [20] and its succeed versions.
b) Domain adaption methods:Domain adaption to minimize the gap between the virtual and real data distributions is essential to the success of virtual-to-real transfer.There are various domain adaptation methods, including data augmentation, realistic rendering, style translation, image composition,domain randomization, dynamic randomization, feature alignment, pretraining and finetuning, etc.
2) Prediction:For prediction, we first introduce the type of learning models for the specific task.virtual-to-real applications cover most machine learning models, e.g., Faster RCNN for object detection tasks, mask R-CNN for segmentation tasks, or quantum CNN (QCNN) of reinforcement learning for robots.We also select representative evaluation results to show their performance improvements after training with virtual data.
Training-testing strategy:To utilize virtual data, there are different choices according to the availability of real data.First, we can train a model purely on virtual dataset and apply it to real world in zero-shot manner, in case of no real data available.Second, we can mix real and virtual data by a certain ratio to train the models and then test on real data.Third,we can train a model purely on virtual data then finetune it on a small part of real data, or optimize a policy with a few real rollouts.
3) Prescription:For prescription, we emphasize on the formats to improve the quality and efficiency of virtual data generation.Typical formats include open-loop, knowledgeguided, adversarial, and feed-back.
a) Open-loop:The open-loop means a stepwise pipeline of training and testing, a common procedure for most of machine learning applications.For virtual-to-real, this means training on virtual data, usually synthetic images, then testing on real data.Or, training an agent, e.g., a robot or an autonomous vehicle, in simulation and then applying it to a real environment.There is no feedback from testing to training step.
b) Guided:There is no guarantee that the randomly generated virtual data help in boosting learning performance.Cues(knowledge) drawn from additional experiments or human heuristic experiences can be used as guidance to improve the data quality with higher efficiency.
c) Feed-back:While the open-loop and guided formats have been approved to be effective in some works, they are limited by laborious human interventions that also inevitably introduce bias in virtual data distribution.Feed-back, on the contrary, is regarded a better choice that combines virtual data generator, domain adaptor and the learning model into one closed loop wiping out human interventions.One typical strategy is to feed back the test errors of learning model on validation dataset to the data generator as guiding signals.Two forms of the closed loops, for different learning tasks, are shown in Fig.4.
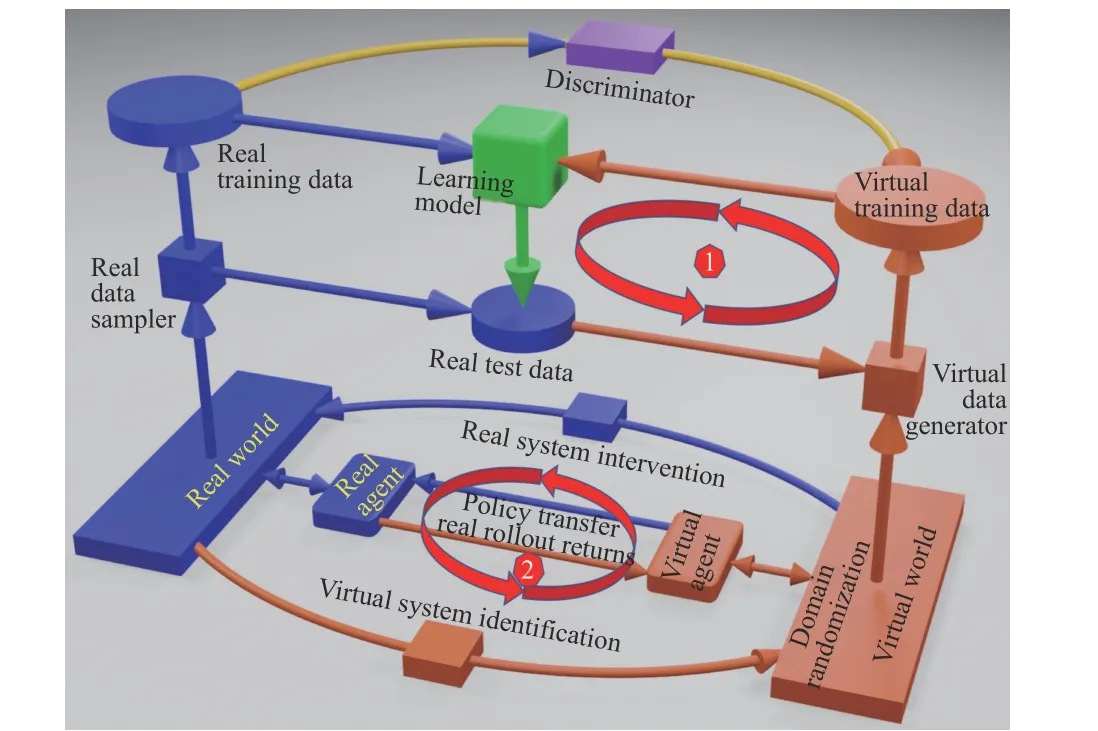
Fig.4.Extended parallel learning framework.The cycles 1 and 2 indicate prescriptive learning process.
d) Adversarial:Another commonly used strategy is to organize the data generator and learning model into an adversarial framework by introducing one or multiple discriminators, as shown in upper side of Fig.4.This method takes advantages of GANs and works well when a part of real data are available.
IV.VIRTUAL-TO-REAL LEARNING METHODS OVERVIEW
In this section, we give an overview of virtual-to-real methods according to the taxonomy described in Section III.For each domain of computer vision, natural language processing,robotics and autonomous driving, typical solutions are presented with their features and highlights in tables, where readers can quickly get the differences and similarities of thesemethods.Please note that the items in the tables are partially selected from the original papers.For complete information,please refer to the original papers for more details.For a better understanding, some figures are taken from the literature and grouped for comparison.
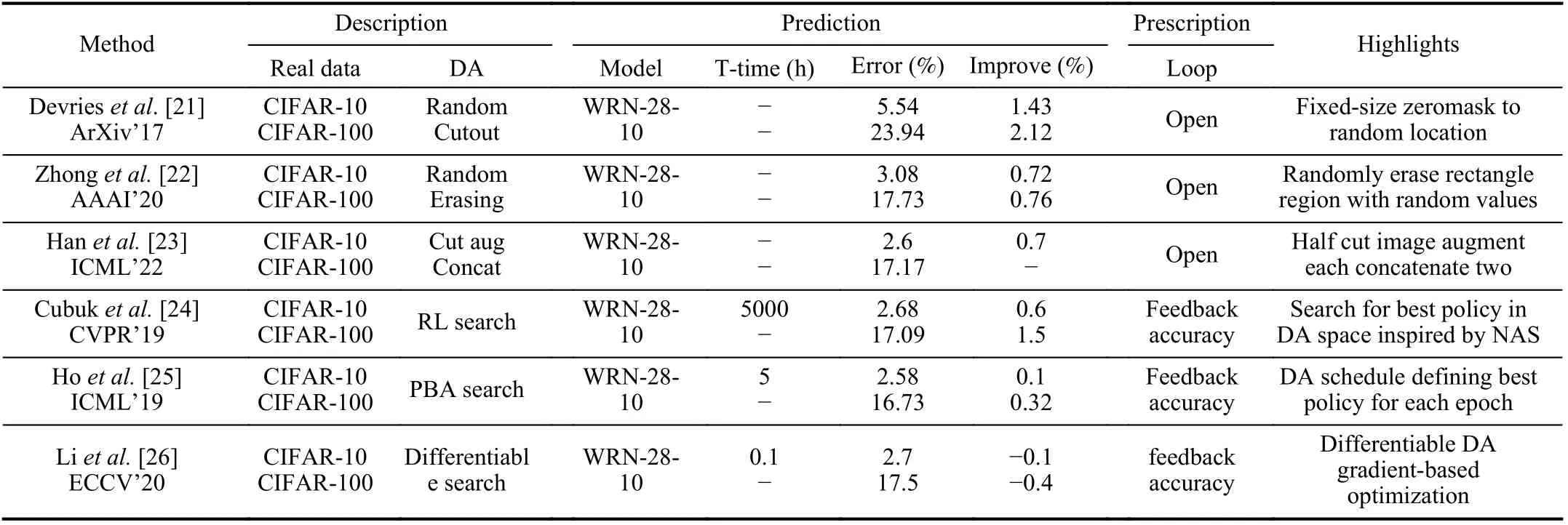
TABLE I COMPARISON OF SELECTED WORKS ON VIRTUAL-TO-REAL IN CLASSIFICATION
A.Virtual-to-Real in Computer Vision
Though computer vision is the most prosperous AI domain in the last decades, deep learning models are suffering from shortage of high-quality data for training.To alleviate this problem, people have applied the virtual-to-real paradigm in all visual tasks including classification, detection, segmentation, estimation, etc.In this part, we focus V2R solutions on classification, detection, recognition, and estimation.
1) Classification:Classification is one of the most fundamental tasks in machine learning.It is also one of the earliest areas using synthetic images.Specifically, we summarize the related literature from the viewport of parallel learning with prescription, prediction and prescription shown in Table I.Selected synthetic samples refer to Fig.5.
Data augmentation (DA) is a popular virtual-to-real method that exerts operations on the original images to generate new label-preserving samples.These image operations, like translation, rotation, scaling, cutout, erasing, cut-and-combine,color-changing, and so on, are simple yet effective.In this part, we emphasize on two types of DA, i.e., the random DA and the automatic DA.For better comparison of different DAs, we select methods that share a common classifier WRN-28-10 and test on common dataset CIFAR-10 (100), as listed in Table I.
The random DA methods usually take an open-loop pipeline that applies simple operations on input images and generates augmented images to train classifiers.Devries and Taylor [21]proposed to randomly cutout patch from the original image,Zhonget al.[22] proposed to randomly erase area from the original image, while Hanet al.[23] proposed a slightly complex operation to equally cut the image into two parts, change color of one part, and then combine the two parts into one image.Improvements on the evaluation metric of error rate of each method are list in the Table I, the later the better with same size of augmentation.

Fig.5.Selected examples of virtual-to-real methods for classification.(a) random cutout; (b) random erasing; (c) cut-aug-concat; (d) RL search;(e) PBA search; and (f) differentiable search.
While random augmentations take effects, they have shortcomings that generate out-of-domain samples which result in low efficiency for training and low performance in testing.To overcome this problem, Fawziet al.[27] proposed an automatic and adaptive method to choose effective transformations among huge number of possible choices.The virtual data generation is modeled as an optimization process trying to find a slight transformation that results in maximal classification loss on each transformed sample.The authors implemented a trust-region optimization strategy and integrated it into the stochastic gradient descent algorithm to train deep neural networks.This is one of the earliest works of full parallel learning with prescription for high effective data generation.Tripathiet al.[28] proposed a task-oriented synthesizer which is a trainable network that can be optimized to produce informative training samples based on output of the classifier.To ensure the synthesizer generating realistic data, the networks of both synthesizer and classifier are trained in an adversarial manner with a discriminator trained on real-world images.The proposed approach achieved baseline (classifier trained on MNIST) accuracy with less than half size of the original training data.Tranet al.[29] proposed a Bayesian formulation that treats new annotated training points as missing variables which can be generated according to the real data distribution.This method adaptively teaches a data generator as the training of classifier progresses by iteratively generating new training samples.The authors introduced a generalized Monte Carlo expectation maximization (GMCEM) for learning and gave an implementation by extending the generative adversarial network (GAN).
In addition to these adversarial methods, some works treat the DA as optimization problem solved by searching algorithms.Inspired by neural architecture search (NAS), Cubuket al.[24] proposed AutoAugment.Instead of searching for optimized neural architecture, AutoAugment aims to automatically search for improved data augmentation policy for a target dataset with a fixed neural architecture.The search space is designed with 16 image operations including translation,rotation, shear, etc.The reinforcement learning is used to search best policies to augment the images and train a neural network whose validation accuracy is sent back as rewards to update the controller.AutoAugment achieved SOTA classification accuracy on several datasets, including ImageNet, but at the cost of hundreds of GPU hours.To reduce the computational cost, Hoet al.[25] proposed to apply the population based algorithm (PBA) to optimize the searching procedure in parallel, getting a 1000 × speedup compared to AutoAugment while keeping on-par accuracy.Further, Liet al.[26] proposed differentiable automatic data augmentation (DADA), a high efficiency pipeline by modeling the DA policy selection as a differentiable optimization problem solved with an unbiased gradient estimator, whose training time was reduced to only 0.1 h on CIFAR-10 with almost equal accuracy of the two former solutions.Comparing key factors of random DA with automatic DA as listed in Table I, we can conclude that automatic DA with prescriptions outperforms random DA in both accuracy and efficiency.A common feature of automatic methods is the closed-loop that adaptively improves the virtual data quality by introducing prescriptive signals like classification errors, discriminator outputs, or losses defined on distribution discrepancy.
Over-sampling (OS) is another commonly used method in addition to data augmentation, especially in the imbalanced dataset containing very few samples of minority classes.To balance the number of samples in different classes, Yanet al.[30] presented their work on synthetization of minority class samples.To overcome distribution mismatching between real and synthetic data, the authors proposed to take use of global geometric information based on optimal transport, so that the generated data follow a similar distribution to that of minority class samples.Loss value is used as feedback to guide efficient sampling, which forms a closed loop in the style as shown in Fig.4.Heet al.[31] proposed a novel oversampling approach by leveraging the GAN to model the data generating mechanism with non-linear latent representations.A Bayesian regularization guides the GAN to extract salient features controlled by a predefined structure in a human-in-theloop manner.
2) Detection:Detection is a basic visual task of identifying and correctly labeling objects at the pixel level.In this part,we look into the virtual-to-real methods from the viewport of parallel learning.We list related works in Table II for comparison, with selected examples shown in Fig.6.
A group of methods use 3D models to avoid manually labeling the training data.3D models were collected and then imported into 3D software like 3DS Max and Blender3D.Within 3D software, parameters including 3D model pose,camera pose, lighting, texture, and background, were randomly or intendedly configured to increase variations.From these 3D scenes, virtual 2D images with labels can be rendered out easily.This procedure provides authors convenience to generate virtual images on demand.For example,Penget al.[41] proposed to train a few-shot deep CNN detector by augmenting the real data with synthetic images generated from 3D CAD models.They also introduced low-level cues, like color and shape, to further study the feature invariance of the representation.Cheunget al.[32] presented LCrowdV, a framework based on the unreal engine to generate videos of crowd with labels.The crowd movements were generated through simulation by altering number of pedestrians, density, behavior, flow, as well as lighting, viewpoint,etc.Detectors of both HOG (histogram of oriented gradient)-SVM (support vector machine) and Faster R-CNN were trained on the virtual data, combined with small part of real data.To deal with the zero-shot person detection, Hattoriet al.[42] tried to generate training data through a 3D virtual environment, for a scene-specific scenario with a fixed camera in 3DS Max.In order to put virtual pedestrians in the reasonable regions, the authors manually labeled walls and obstacles in the scene.Images with pedestrians were generated through the camera with consideration of distortions to mimic the real surveillance cameras.Then an HOG + SVM pedestrian detector is trained on the virtual data and tested on real dataset.Their results show that learning model trained purely on virtual data outperforms models trained on real data or virtual-real mixed data.Later in [34], Hattoriet al.generated a large virtual dataset by controlling variations in human appearance including gender, height, pose, and orientation based on only 139 different human models.In addition to the traditional classifier based detector, the authors proposed to use deep convolutional neural network, named as ScenePoseNet, for multiple tasks including detection, pose estimation and segmentation.
Instead of using 3D models, Dwibediet al.[35] and Dvorniket al.[36] generated virtual data by 2D image editing and composition.The first step is collecting images from real datasets for both foreground and background (context).A mask of foreground was predicted and placed on background images to help paste instances into scenes with minimized pixel discrepancies at the boundaries.Dvorniket al.[36] pro-posed to learn a context model firstly using box annotation and applied it to determine what object to be inserted and where to be placed in the original image automatically.Data augmentation was used to ensure a diverse viewpoint or scale coverage.Martinsonet al.[39] introduced a 3D−2D−2D method that firstly rendered the foreground from 3D models and then did image composition with a scene from satellite images as background.A further step was taken to input the composed image into a trained CycleGAN for improvement.
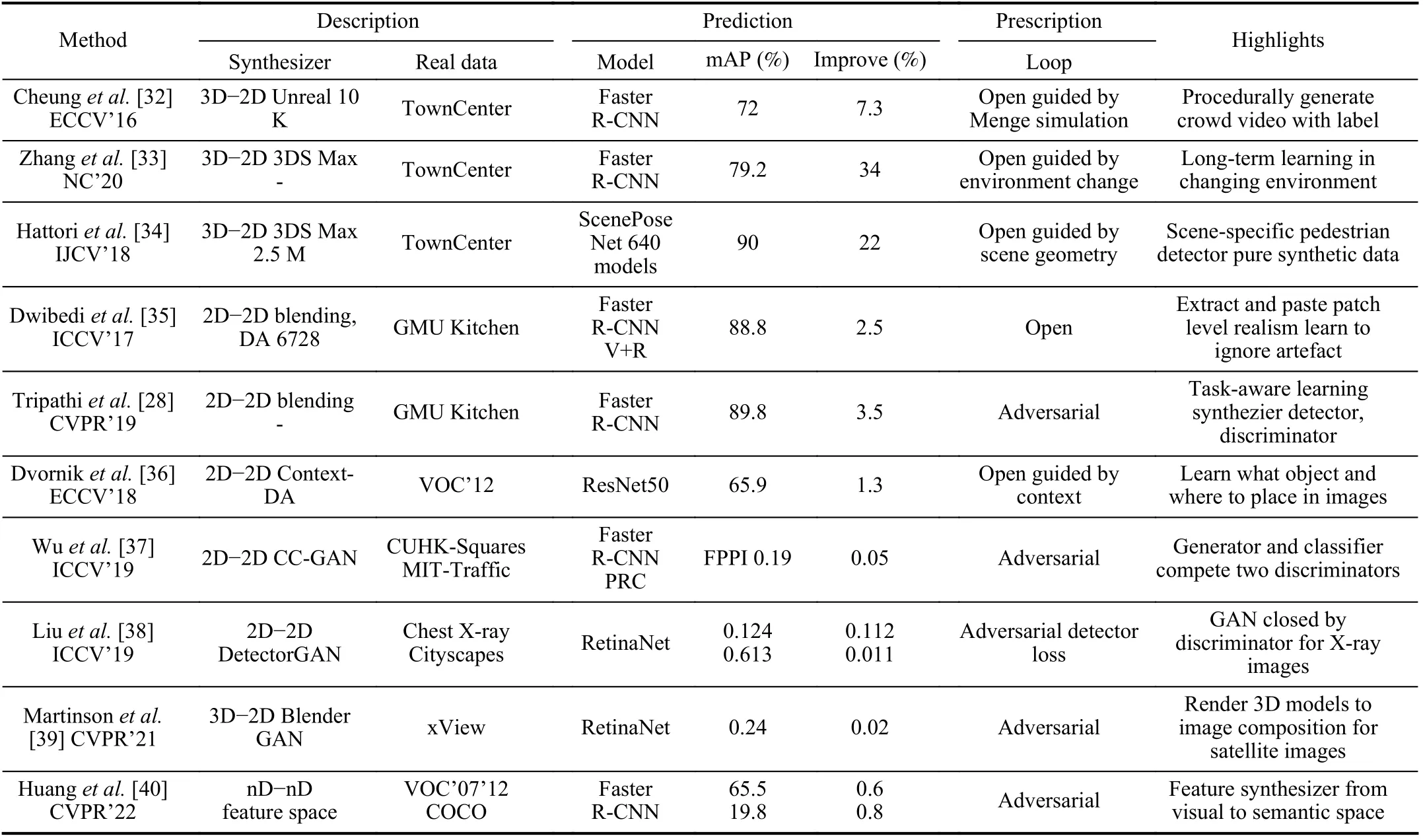
TABLE II COMPARISON OF TWO CLOSE RELATED WORKS ON VIRTUAL-TO-REAL IN OBJECT DETECTION

Fig.6.Examples of synthetic images for object detection.
The aforementioned methods took a sequential pipeline:once a virtual data set was generated, the following steps are training a detector on the virtual data and testing the trained detector on real data set.On the contrary, Liuet al.[38] and Tripathiet al.[28] introduced a learnable adversarial framework that integrated data synthesizer, detector, and discriminators.With detector loss as feedback, the synthesizer is guided to generate hard examples that improve the detector in an adversarial style.The discriminator helps to improve realism and make the generated images conform to the real image distribution.The three components, synthesizer, detector and discriminator, are trained similarly to typical GANs.Real images are necessary to train the discriminators.The GAN framework enforces the synthesizer to generate images more effectively to improve detection performance.Here effectively means generating harder examples and neglecting normal examples without contribution to improve detector performance.The experiments in [28] showed that the detector got better accuracy with only half number of images compared to previous work.
In order to generate more realistic virtual images, Wuet al.[37] also proposed an adversarial framework in which a postrefinement classifier (PRC) is introduced following the Faster R-CNN detector.The PRC and the synthesizer work together to compete with a class-conditional discriminator and a classspecific discriminator.These four networks are trained in a manner that facilitates both pedestrian synthesis and detection in semi-supervised setting.Experiments validated the proposed model by significantly improving the detector performance with state-of-the-art results on multiple real dataset.Zhanget al.[33] construct a prescriptive learning connecting virtual and real world dealing with long term learning problem that environment changing cannot be neglected.The virtual world is a 3D scene in 3DS Max with configurable parameters including lighting.The difference between the virtual and real background, for example changes in day and night, was fed back to update virtual scene in order to approach the real world.
The image composition procedure inserting the foreground into background will inevitably introduce boundary artefacts,which may be recognized as a feature by the detector.That is,the virtual data introduced artificial features that does not belong to real data, which have been verified to be harmful to the performance of detector.Pixel blending along foreground boundary is a common solution to reduce artefacts.Tripathiet al.[28] proposed another strategy by generating additional hallucinated artefacts in the background images, making the detector invariant to artefacts in the synthesized images.
Instead of augmenting images, a new way is to synthesize at feature level.Huanget al.[40] proposed a robust region feature synthesizer with two components, i.e., an intra-class semantic diverging component to obtain diverse visual features, and an inter-class structure preserving component to avoid the synthesized features too scattered.On PASCAL VOC and COCO dataset, this approach achieved the state-ofthe-art performance for zero-shot object detection.
3) Recognition:For virtual-to-real in visual task of recognition, we include text recognition and face recognition respectively as follows.
a) Text recognition:In this part, we summarize works on text/word recognition in natural images, examples can be found in Fig.7.

Fig.7.Examples of synthetic text in natural scenes.
We start with an early work in 2011, when Wanget al.[43]proposed a pipeline based on SVM training on SYNTH, a synthesized dataset that containing 1000 images per character of 40 font types.Gaussian noise and random affine deformation were also applied to add divergency.In recent years, deep neural networks have been used as task models instead of SVMs.The key problem to generate virtual text in natural background is to determine the proper place and pose of the text.Semantic priors, from both object segmentation and 3D scene structure, may help to generate virtual dataset.Guptaet al.[44] designed an engine that adds text to images with natural backgrounds.Their sample texts, collected through Google search, were placed into the image according to estimated depth and geometry, then blended into the background using Poisson image editing.8000 high realistic images were synthetized automatically as a dataset called SynthText.Zhanget al.[45] proposed to improve text placement according to semantic coherence and visual saliency, which were provided as prior from semantic segmentation.In addition, the color and brightness of embedded texts were determined by learning from real scene in an adaptive manner.Experiments on five public datasets show its superior performance.Differently from aforementioned methods, Long and Yao [46] introduced an image synthesis method named as UnrealText.The process begins with a 3D scene in which the region is proposed to place the sampled text.A camera moving around in the 3D scene produced a virtual dataset with 600 K text images.Using the 3D graphics engine unreal, the scene and the text can be rendered as a whole not only for realistic appearance but also with annotations.
b) Face recognition:Face recognition is another visual task intensively taking advantages of synthetic images.We list related works in Table III for comparison, and show typical samples in Fig.8 for brief overview.
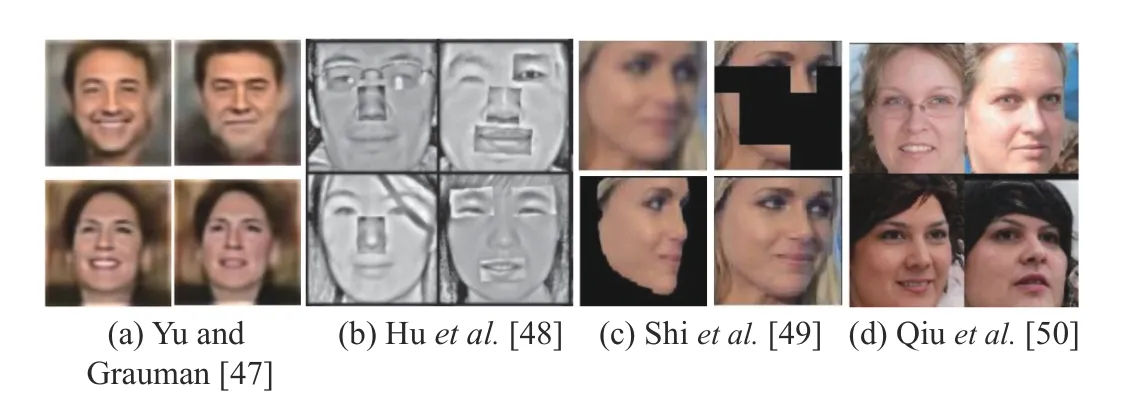
Fig.8.Examples of synthetic faces.
A partial work of [47] is to densify supervision for face recognition with synthetic images.The main idea is generating identities, i.e., similar faces but with slight difference, of real sample by modifying attributes through the Attribute2-Image engine.Huet al.[48] proposed to generate new face images by composing different face parts of one or multiple persons based on a given real dataset.The experiments showed that a model trained on 10 K images with the proposed method had similar performance as it was trained on 500 K images.
Shiet al.[49] proposed URFace with the ability to learn universal representation.URFace firstly augmented the training data by introducing variations of blur, occlusion and head pose.A confidence-aware identification loss was designed to encourage the model to learn from hard examples, through sub-embeddings spilt from feature vectors.Qiuet al.[50] proposed SynFace with identity mixup (IM) and domain mixup(DM) as two features.IM is based on DiscoFaceGAN with purpose to enlarge intra-class variations, while DM utilizes a large number of virtual data with a small number of real data,aiming to reduce domain gap between synthetic and real face data.On the observation that virtual data and real data have a natural discriminability in fixed form, denoted as modality,Zhaiet al.[51] proposed three methods to remove the modality for better performance when utilizing virtual data.
4) Estimation:Estimation from 2D images is a broad topic covering various specific tasks, e.g., pose estimation and depth estimation.In this part, we mainly focus on human/animal pose estimation from monucular camera, related works are list in Table IV, samples are shown in Fig.9.
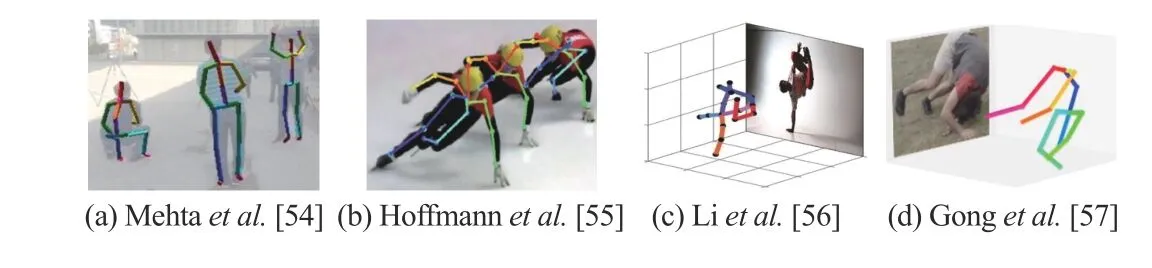
Fig.9.Examples of pose estimation using synthetic data.
Rogez and Schmid [52] proposed an image synthesis engine that took in both images with 2D pose annotations and 3D motion capture data.The core to this method is that, given a 3D pose, a set of image patches whose 2D pose locally matches the projected 3D pose for all joints are collected and then combined as a new image by stitching local patches constrained by kinematical rules.The output images, with 3D pose annotations, are used to train CNN for 3D pose estimation.Chenet al.[53] also took use of MoCap data and 2D annotated pose images, but instead of compositing 3D annotated images directly, the authors firstly built a statistical human model based on the available data.Then a large scale virtual images dataset with pose annotations was generated by sampling from the statistical model, which was rendered into background with clothes.A further domain adaptation was introduced during training CNN models by extracting common features of both virtual and real data.Focusing on multiperson estimation with occlusions, Mehtaet al.[54] created MuCo-3DHP, a synthetic data set by compositing multiple 2D person images with 3D pose annotations from multi-view motion captures.Deep models trained on this dataset achieved state-of-the-art performance when tested on the 3D annotated multi-person test dataset MuPoTs-3D.
All aforementioned works generated a number of virtual data with annotations and trained their deep models with performance improvement.However, people may have questions.The first, which kind of virtual data is better, purely synthetic or composed? And second, does every generated image contribute to the improvement of leaning model equally? Or in other words, is there any redundancy in the virtual dataset? To answer these questions, Hoffmannet al.[55] designed experiments for pose estimation.For the first question, the authors created two datasets, one for purely synthetic humans and the other one with real data augmented by synthetic humans.Experiments showed that models trained on mixed data with domain stylization get best generalization performance.For the second question, the authors found that, through experiments, some data contribute more than others in different training stages.Based on this observation, an adversarial training method with a teacher and a student was designed to optimize the sampling process when generating virtual humans.From viewpoint of parallel learning, this method introduces prescriptive learning with feedback from estimator to virtual data generator, a closed loop for more efficient learning.
Taking a non-stationary view toward training data, Liet al.[56] proposed an augmentation method by generating human data evolutionally.A human skeleton was represented as a hierarchical tree structure that each joint is a node with mutable parameters.An evolutional process including crossover,mutation and natural selection was operated to augment the Human3.6M dataset with a binary fitness function.A dedicated 3D pose estimator network called TAG-Net was trained on evolved dataset and achieved not only SOTA accuracy on public benchmark but also generalized better on unseen dataset.Results also showed that this evolutional method can reduce data bias efficiently.
Gonget al.[57] presented PoseAug, a framework that automatically learns to generate virtual training data taking pose estimator errors as guiding signals.The human body was represented by parameters adjusted through differentiable operations.The data generator took in estimation errors as feedback to generate rare poses based on this differentiable pipeline.In this way, the data generator and estimator were jointly trained in a closed loop, which becomes a typical closed-loop prescriptive learning.Discriminators were necessary to ensure that the generated human poses fall in a plausible range by measuring local joint-angle defined in kinematic chain space (KCS).
5) Summary:CV is the most mature area of V2R, spanning traditional machine learning and deep learning models, and the methods involved are relatively diverse, with deeper perspectives and more adequate experiments.DA based on image processing has become a standard operation in deep learning.3D−2D methods were more common in the early days, but with the development of generative models in deep learning,especially the widespread use of adversarial generative networks, 2D−2D high quality image generation has also taken an important place.In aspect of prescription, early open-loop DA methods have demonstrated the effectiveness of data augmentation, while the rapidly developing differentiable closedloop feedback, prior knowledge-based bootstrapping, and adversarial generative networks have gradually shown advantages in recent years.
B.Virtual-to-Real in Natural Language Processing
Unlike CV, natural language processing (NLP) deals with 1D data such as audio, speech, and text, which has a discrete and structural nature compared with images.Like CV, the success of NLP tasks depends on deep neural models and a large number of labeled data.NLP tasks are also hindered by data scarcity in practice, where synthetic data are essential in complementary to the real data.In this section, we firstly look into virtual-to-real methods by summarizing popular data augmentation techniques in NLP, then introduce selected applications.
1) Overview of Data Augmentation Methods in NLP:A number of data augmentation methods in NLP have emerged in recent years and there are different viewpoints to categorize them.Chenet al.[58] summarized augmentation methods as four types, i.e., token-level, sentence level, adversarial and hidden-space augmentations.Fenget al.[59] classified representative augmentation techniques into three groups, i.e.,rule-based techniques, example interpolation techniques and model-based techniques.While Liet al.[60] divided augmentation methods into three categories including noising-based methods, paraphrasing-based methods and sampling-based methods.
These techniques have been used to alleviate low resources problems in NLP tasks ranging from audio recognition, text classification, to machine translation, abstractive summarization, question and answering, dialogue, etc.It is impossible tocover the tremendous literature in one single paper, so that we select two tasks, automatic speech recognition (ASR) and neural machine translation (NMT), that typically represent the virtual-to-real NLP paradigm from viewpoint of parallel learning.
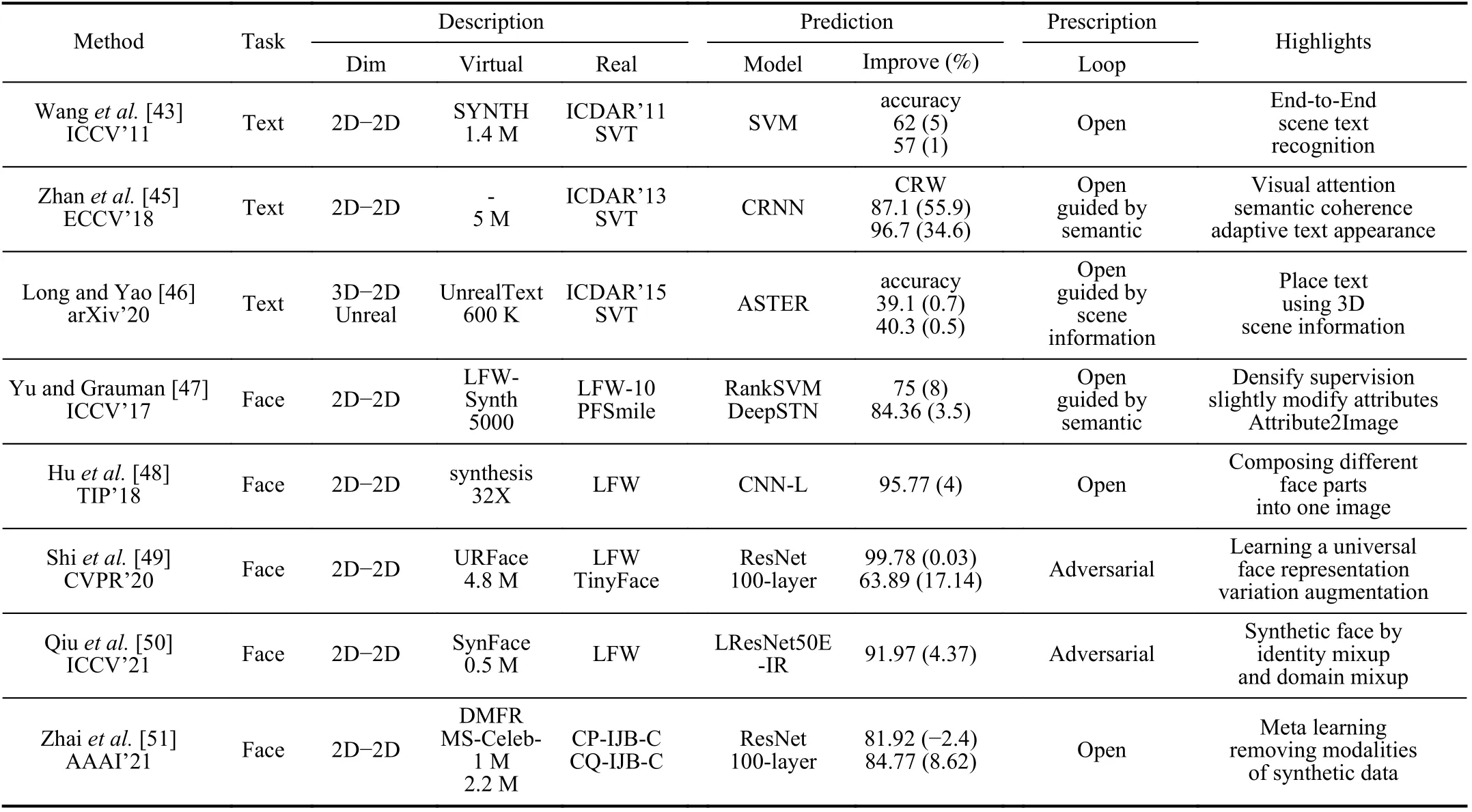
TABLE III COMPARISON OF FACE RECOGNITION USING SYNTHETIC DATA
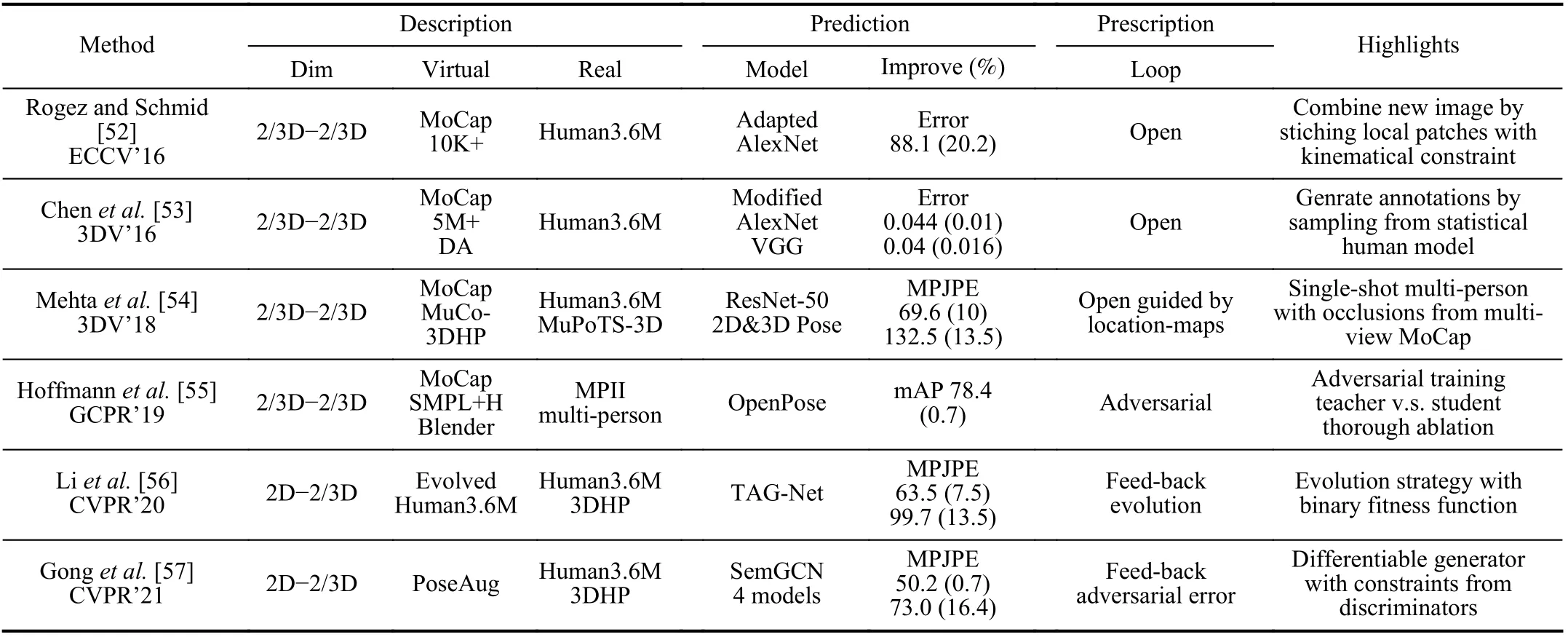
TABLE IV COMPARISON OF POSE ESTIMATION USING SYNTHETIC DATA
2) Selected Virtual-to-Real Applications in NLP:
a) Automatic speech recognition (ASR):We list related works in Table V and start from the pioneering work of Tjandraet al.[61] who put forward a sequence-to-sequence deep learning framework that integrates both listening and speaking, inspired by the closed-loop speech chain mechanism [62].Specifically, an automatic speech recognition (ASR) model responses for listening, i.e., transcribes the unlabeled speech features, and a text-to-speech synthesis (TTS) model takes charge of speaking, i.e., reconstructs the original speech waveform based on the text output from ASR.The ASR also tries to reconstruct the original text transcription based on synthesized speech from TTS, which iteratively forms a closed-loop that simultaneously improves both speech perception and production, as shown in Fig.10.This work provides a way to utilize unlabeled data in speech recognition task.Further in [63],[64], Tjandraet al.introduced a straight-through estimator in ASR so that reconstruction loss can be back-propagated the same way as in TTS.This solved the non-differentiable problem of discrete tokens output by ASR and resulted in a full end-to-end framework.
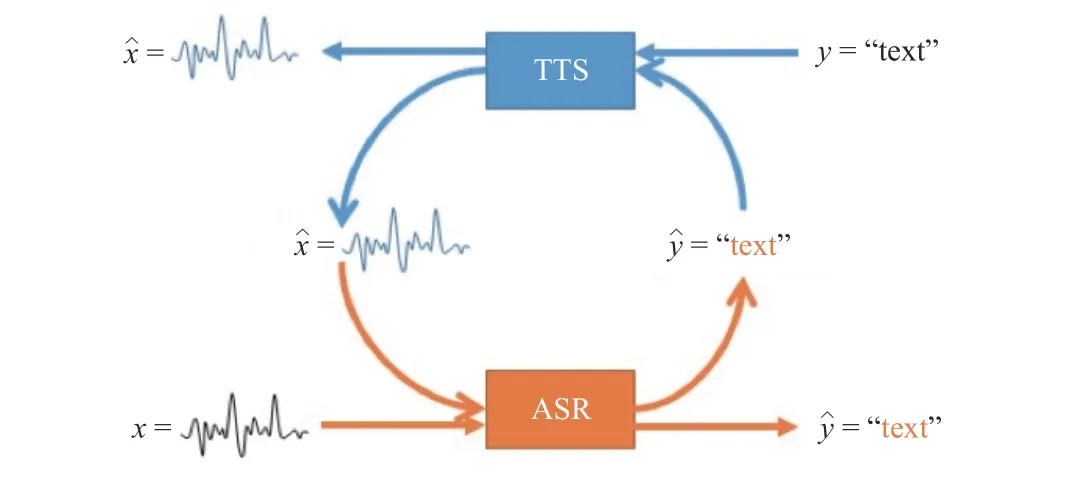
Fig.10.Principle of closed loop by integration of ASR and TTS (Tjandraet al.[61]).
Instead of converting between source and target, Hayashiet al.[65] proposed to use hidden states by training a text-toencoder, in scenarios of ASR given a large number of unpaired texts.Using hidden states, instead of acoustic features, has advantages of fast attention learning and avoiding speaker dependencies.
Other works tried to improve the closed-loop with different concerns.Rossenbachet al.[66] presented a work extending the state-of-the-art attention-based ASR with a TTS trained only on the ASR outputs.Zhenget al.[67] proposed to provide synthetic audio for out-of-vocabulary (OOV) words by a TTS.In such a way, the authors boosted the recognition accuracy of a recurrent neural network transducer (RNN-T) on OOV words by using the extra audio-text pairs, while maintaining the performance on the non-OOV words.Huet al.[68]paid attention to the gap between synthetic and real data distributions.The authors proposed a rejection sampling algorithm with batch normalization for both real and synthetic samples,which improves the ASR performance compared with simply using synthetic data.Horiet al.[69] introduced a cycleconsistency loss based on the Text-To-Encoder reconstruction error,instead of the raw speech.Wanget al.[70] improved training on synthetic data by promoting consistent predictions in response to real and synthesized speech.With this method,models trained on 460 h of LibriSpeech augmented with 500 h of transcripts (without audio) perform on par with a system trained on 960 h of transcribed audio.This suggests that reliance on transcribed audio can be cut nearly in half when sufficient text is available.Chenet al.[71] proposed to improve acoustic diversity of TTS outputs by combining the GAN and multi-style training (MTR).The authors also presented a contrastive language model-based data selection technique to improve the efficiency of learning from unspoken text.Du and Yu [72] proposed to train a TTS system with speaker representations from a variational auto-encoder(VAE).Such a speaker augmentation method enables TTS to generate unseen new speakers via sampling from the trained latent distribution.Fazelet al.[73] proposed SynthASR with a multi-stage training strategy to avoid catastrophic forgetting by mixing of weighted techniques, including multi-style training, data augmentation, encoder freezing, and parameter regularization.SynthASR showed good transferability to new applications.
b) Neural machine translation (NMT):Neural machine translation (NMT) has dominated in machine translation in recent years, but it still struggles in low-resource or out-ofdomain scenarios.There are several good methods to address this problem, e.g., DADA [74] which takes an attack-defend adversarial method to improve robustness of NMT models,and AdvAug [75] which trains NMT models using virtual sentence’s embeddings in seq2seq learning, etc.Here we intend to focus on a group of Paraphrasing-based methods as follows.
Translation has a feature of duality that translates from target to source language is an inverse process of translating from source to target.To take use of this feature, Heet al.[76]published an impressive work of dual learning for machine translation in 2016.Dual learning regards translation as a game between two agents.One agent responds for primal task to translate from source to target, and the other agent responds for a dual task to translate from target to source.The primal and dual tasks form a closed loop that each side updates iteratively based on the reconstruction error feedback from the other side.In such a way, the two agents teach each other through reinforcement learning using policy gradient method.Dual learning can be regarded as a special parallel learning case involving mutual prescriptive learning process.We add a figure according to the original paper as shown in Fig.11.
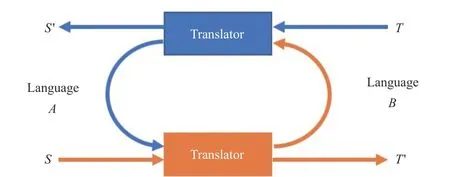
Fig.11.Principle of closed loop by integration of bi-directional translation.
In a following work [77], the authors extracted the dual learning as general paradigm that is suitable for paired tasks like speech recognition v.s.text-to-speech, and image classification v.s.image generation, in addition to language translation.To improve the training efficiency of RL based dual learning translation [76], Wanget al.[78] proposed to connect the probability of a given target-side monolingual sentence to the conditional probability of translating from a source sentence to the target one, by leveraging the dual learning translation model to sample several most likely sourceside sentences, thus avoid enumerating all possible candidate sentences of source language.This can be viewed as a transfer learning that transfers the knowledge in the dual model(target-to-source) to boost the training of the primal model(source-to-target).
Zhanget al.[79] also presented methods by jointly training source-to-target and target-to-source NMT models with a joint EM optimization.In a similar way, Lampleet al.[80] alsoproposed a dual framework but mapping both source and target domains into a latent space where back-translations are applied from both sides to get reconstruction error.Niuet al.[81] proposed to combine both the primal and dual model into a single model for bi-directional translations with much higher efficiency than two uni-directional models.Wanget al.[82]extended the dual learning to multi-agents framework that translates between multiple languages instead of one pair of source and target language.Ahmadnia and Dorr [83] presented a round-trip training approach that shares a similar idea with dual learning.Zhenget al.[84] presented mirror-generative NMT (MGNMT) which is also a single unified model like[81] but additionally introduced two language models to collaborate with the unified model during decoding.
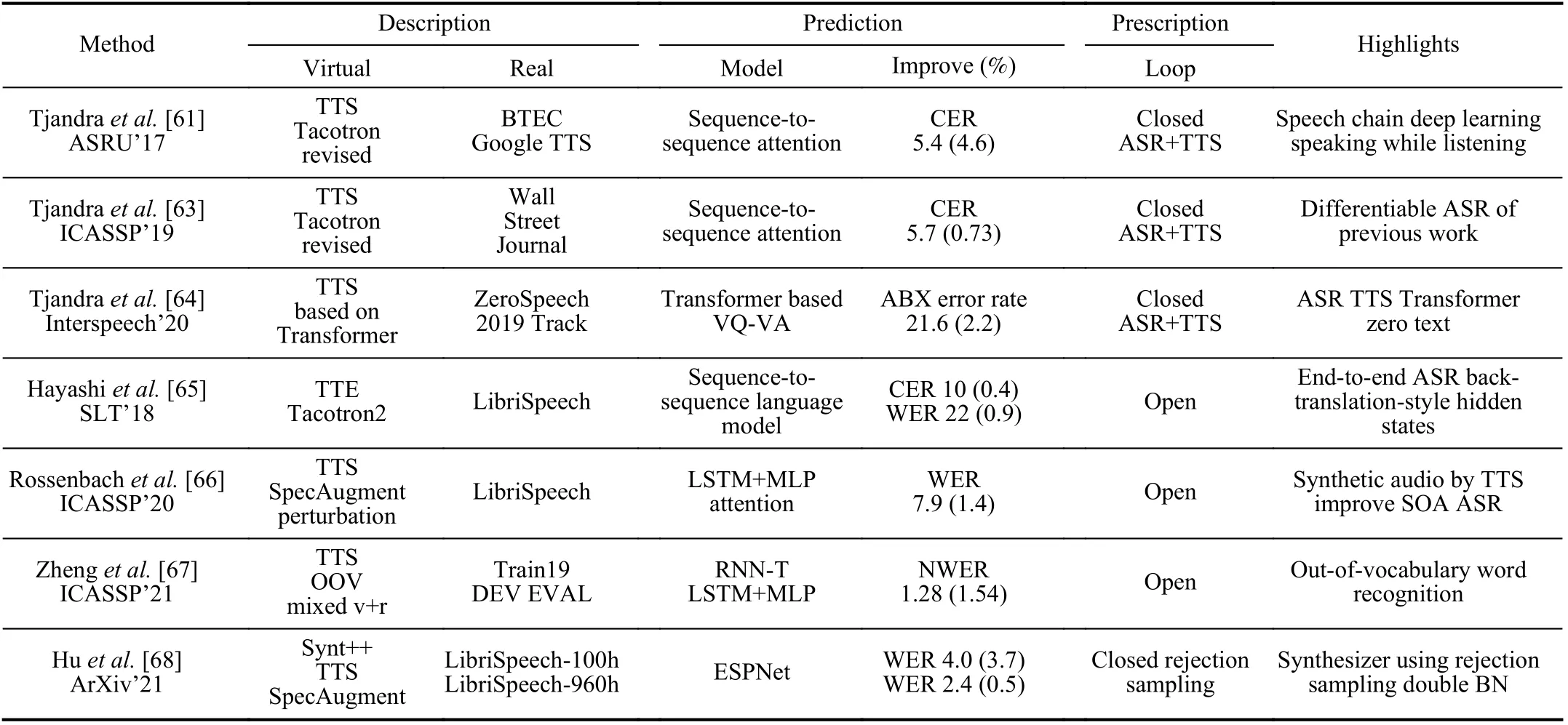
TABLE V COMPARISON OF SELECTED WORKS ON VIRTUAL-TO-REAL IN SPEECH RECOGNITION
3) Summary:In the field of NLP, the complementarity between tasks provides for the construction of closed-loop, bidirectional guidance.Dual learning for NMT tasks is the representative approach.This idea has been further extended and is now applied to multimodal scenarios, e.g., image caption and image generation are cross-modal complementary tasks.In recent years, pre-trained big models in the field of NLP have developed rapidly, using unsupervised learning to extract knowledge from massive number of unlabeled data for several tasks such as recognition and generation.It is foreseeable that pre-trained big models will play an important role in V2R applications.
C.Virtual-to-Real in Robotics
Learning a policy for robotic control is another area that deeply involves virtual-real interactions, for the same reason to get more data efficiently in a safe manner.Differently from syn-to-real, the paradigm used in robotic control is referred as sim-to-real, where dynamic simulations instead of static synthetic images are defined as source domain.The dynamic control is usually modeled as a partially observable Markov decision process (POMDP) that is solved by methods including imitation learning and reinforcement learning.Same as syn-toreal, closing the domain gap between the simulation and real world is a key research topic yet remains as an open problem.Nevertheless, many progresses in sim-to-real have been reported.
In this section, we summarize sim-to-real works on robotic control reported in recent years from viewpoint of parallel learning.According to the type of control tasks, we organize the related literature in two categories, i.e., manipulation and navigation (including locomotion), with selected examples shown in Fig.12.
1) Manipulation:In this part, we introduce sim-to-real methods in zero-shot scenarios, succeeded by one-shot and few-shot settings.Selected works are listed in Table VI for comparison.
With zero-shot settings, Tobinet al.[85] proposed to generate simulated images by randomizing rendering configurations.For a task of grasping tiny sphere, the proposed method successfully transfers a deep neural network (DNN) trained only with simulated RGB images to real world robotic control.For vision-based robotic tasks, the controller makes decisions depending on results of visual process.To take advantages of this two-step pipeline, Yanet al.[89] proposed a framework which comprises a vision module succeeded by a control module.The vision module performs object segmentation, and the control module, which is a closed-loop DNN controller,takes in binary segmentation mask to train the control policy by imitation learning.This decoupled manner equals mapping both virtual and real images into a common space, bridging the gap between virtual and real environment.The method achieved a 90% success rate in grasping a tiny sphere and the controller can generalize to unseen scenarios with moving targets.

Fig.12.Selected examples of robotic Sim2Real for locomotion (a) and (b), navigation (c), and manipulation (d) and (e).The upper are real robots and the lower are the corresponding virtual worlds.
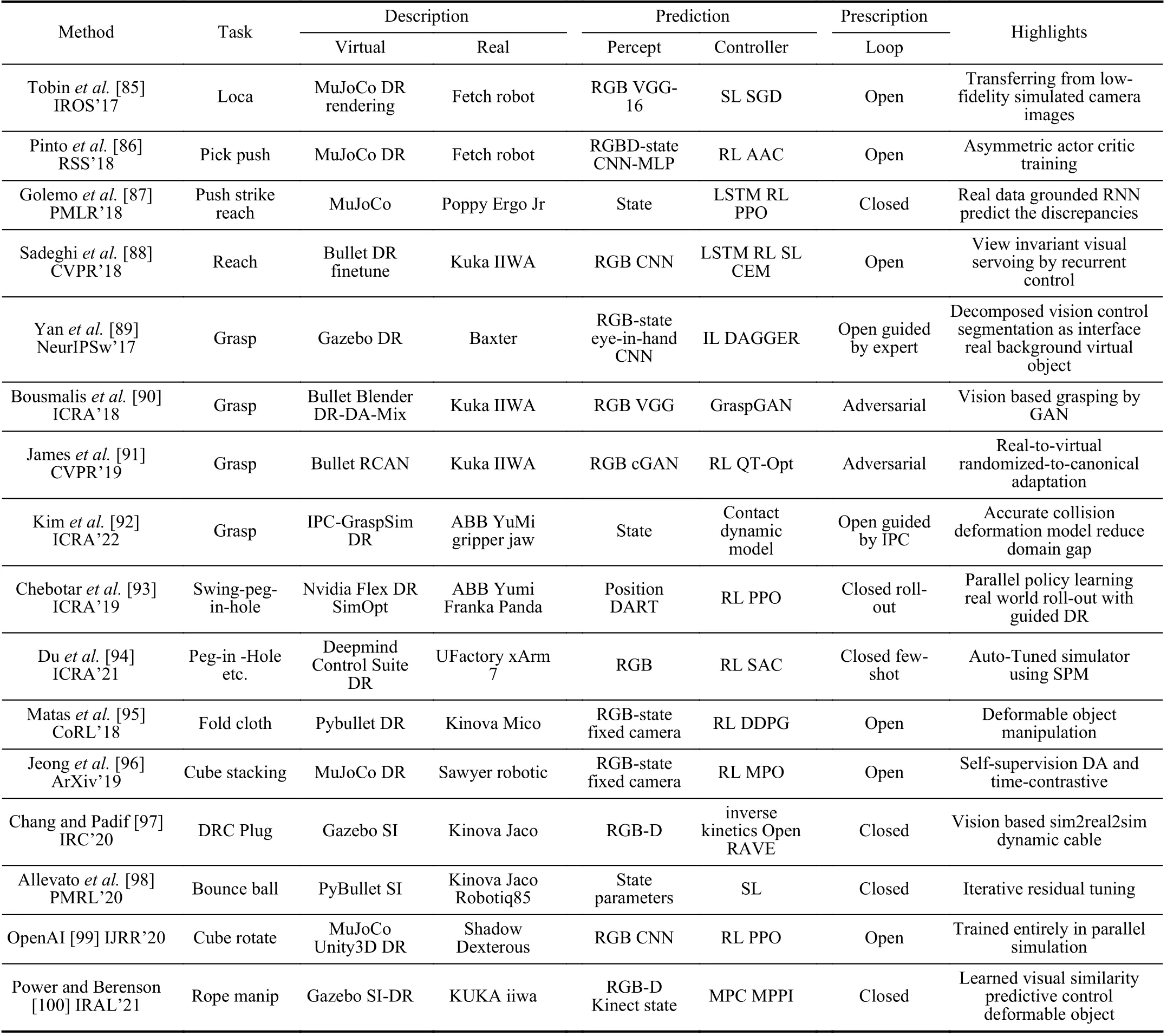
TABLE VI COMPARISON OF SELECTED WORKS ON VIRTUAL-TO-REAL IN ROBOTIC MANIPULATION
Sadeghiet al.[88] focused on learning viewport invariant visual servo.They presented a framework which also disentangled perception from a memory-based recurrent controller learned from synthetic images.The model adapted from virtual side enables a real robotic arm to interact with unseen objects from novel viewpoints.Pintoet al.[86] introduced the asymmetric actor critic algorithm in which the critic is trained on full states while the actor (or policy) is trained on images,to speed up learning process.Combined with domain randomization, this method achieved sim-to-real transfer in zero-shot scenarios.In [90], Bousmaliset al.proposed GraspGAN, a method by extending domain adaptation and randomization to train a grasping robot based on raw monocular RGB images.Using unlabeled real data, this method is comparable with those using millions of labeled real-world samples.
Generalizing to new environments and crossing various robot configurations are important goals for sim-to-real applications.Scherzingeret al.[101] proposed to learn contact skills from human demonstrations through simulation, using an LSTM (long short-term memory) network.This framework comprised a real robot and its virtual twin to solve inverse kinematics problem.The generated sequences of forces and torques in task space can be generalized to new tasks across different joint configurations of the robot.OpenAI [102] proposed a zero-shot automatic domain randomization (ADR) method that transfers from simulation to unprecedented complex real world, by increasing difficulty of distribution over randomized environments.The ADR method solved a Rubik’s cube with a humanoid robot hand.The randomized-to-canonical adaptation networks (RCANs) proposed by Jameset al.[91] is also a zero-shot method to cross the visual-reality gap by translating randomized rendered images, as well as real images, into their equivalent canonical versions.Using RCAN and QT-opt, they improved the performance from 36% to 70% for grasping unseen objects.
While most work focused on manipulating rigid objects,Mataset al.[95] introduced deformable object manipulation from sim-to-real, which overcame the problem of large configuration space of deformable objects.Trained fully in simulation with randomization, the agent was successfully deployed in the real world in a zero-shot manner.Kimet al.[92] proposed IPC-GraspSim, that introduced an accurate contact algorithm IPC (incremental potential contact) into the simulation for sim-to-real transfer.They testified through experiments that more accurate contact simulation with proper deformation parameters helps to reduce reality gap for grasping objects, improving F1 score by 0.09 over Isaac Gym.
One-shot or few-shot strategy brings further benefits when real environments are available during training stage.Golemoet al.[87] proposed neural-augmented simulation (NAS), a method that augments the simulator by training an RNN based on the differences between simulated and real robot trajectories.This can be viewed as a system identification (SI)method that closed the domain gap for a better sim-to-real transfer.Chebotaret al.[93] proposed a few-shot method to match the simulation with real world by adapting the simulation parameters through real world rollouts during training.The training process is in a distributed manner with randomized parameters.Allevatoet al.[98], [103] presented TuneNet, an efficient system identification method that tunes the simulator parameters to match real world using iterative residual tuning (IRT).The system was trained via supervised learning over an auto-generated simulated dataset, with minimal real-world observations.Experiments showed that TuneNet helped a robot in real world to perform a dynamic manipulation with a new object, after one-shot observation.
Chang and Padif [97] proposed simulation-to-real-to-simulation (Sim2Real2Sim), a new strategy to bridge reality gap.For a manipulation task, this strategy starts training with simulation using rough virtual environment with estimated models.Then, sim-to-real transfer is taken to compare the performance between virtual and real robots.Finally, models in simulation is updated based on the differences between simulated and real worlds.Such a closed-loop pipeline realized the prescriptive learning in parallel learning.Heidenet al.[104] also made efforts to identify parameters of highly nonlinear and underactuated systems.The authors proposed to approximate a posterior distribution over simulation parameters given real sensor measurements based on Bayesian inference.Physical experiments demonstrated that this technique could identify symmetries between the parameters and provide highly accurate predictions.
Domain randomization depends on prior knowledge and engineering efforts to decide how much to randomize the parameters for robust sim-to-real transfer.Breyeret al.[105]introduced an adaptive learning mechanism that learns gradually from simple to complex tasks, with prioritized sampling scheme.Duet al.[94] proposed search param model (SPM), a method to automatically tune simulator parameters to match the real world using only raw RGB images from real world.Given a sequence of observations, SPM predicts whether the parameters are higher or lower than the true values.Experiments on robotic control in real world demonstrated improvement over simple domain randomization.Shashuaet al.[106]also demonstrated a strategy to learn from both simulation and real environments simultaneously, by maintaining a replay buffer for each environment with which the agent interacts.Power and Berenson [100] proposed learned visual similarity predictive control (LVSPC), a data-efficient online learning method to control systems with complex dynamics and highdimensional state spaces from images.Experiments of both rigid and deformable objects showed comparable performance to state-of-the-art reinforcement learning methods but with much fewer data.
2) Navigation:In mobile tasks like navigation and locomotion, robots face more complex environments, which makes sim-to-real transfer more challenging.For better comparisons,we select typical works and list key features in Table VII.
For bipedal locomotion, efforts to cross the domain gap between virtual and real domains can be traced back to Farchyet al.[107] who introduced grounded simulation learning(GSL).GSL tries to improve robot learning in virtual world by transferring physical state from the real system to update the virtual system such that the updated virtual system becomes closer to the real system.The method to make the simulator approach the real world is referred to as grounding.GSL starts with an imperfect simulator in which a policy islearned then tested on real robots.Discrepancy between simulated and real performances is used to improve the initial simulator to be grounded as reality.This method helps a real humanoid robot, Nao, to increase walking speed by 25% with only four iterations starting from hand-coded walk parameters.From the viewpoint of parallel learning, GSL can be regarded as off-line prescriptive learning with iterative virtual-real interaction.But a constraint of GSL is the requirement of a human expert in loop.Later work of Hanna and Stone [108]proposed grounded action transformation, an optimization method based on the covariance matrix adaption evolutionary strategy (CMA-ES) algorithm, to alter the simulator for better matching to real world.Results on real robot outperform the SOTA hand-coded method to improve walk velocity by 43%.
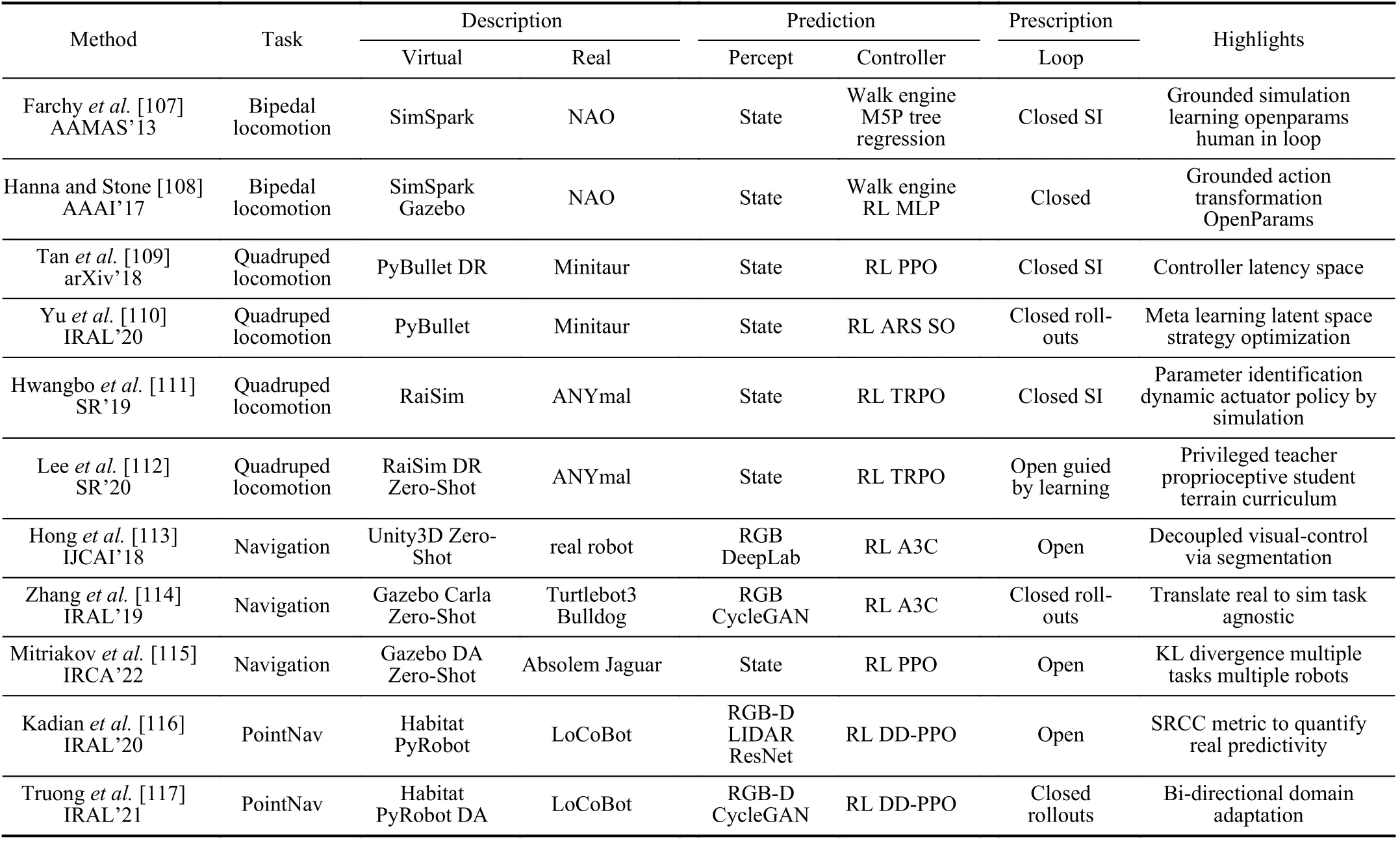
TABLE VII COMPARISON OF SELECTED WORKS ON VIRTUAL-TO-REAL IN ROBOTIC NAVIGATION
For training agile locomotion of quadrupedal robots, Tanet al.[109] proposed to narrow the virtual-real gap by improving the simulator through system identification (SI) to get an accurate actuator model with latency.Randomization and perturbation also played essential roles in learning a robust controller.After learning in simulation, a quadruped robot Minitaur can successfully trot and gallop in real world with higher speed and lower power cost compared to a handcrafted robot.Yuet al.[110] proposed a meta-learning algorithm, Meta strategy optimization.By utilizing latent variables with a few(75) of trials in real word, the learned policies can quickly adapt to new target environment.Evaluation on a real quadruped robot demonstrates successful adaptation to various scenarios and outperforms two baseline methods.Hwangboet al.[111] introduced a method to learn policies with an in-house rigid-body simulator and transfer to a sophisticated medium-dog-sized quadrupedal robot, ANYmal, who achieved skills recovering from falling which goes beyond that learned with prior methods.Leeet al.[112] presented an impressive work for learning a robust quadrupedal locomotion controller for legged robots in challenging natural environment like mud and snow, or thick vegetation and gushing water over ground.In addition to domain randomization of physical parameters, their training strategy includes a teacher policy and a student policy through simulation.The learning of the teacher policy has access to privileged information, e.g.,ground-truth of the terrain and the robot’s contact with it.The learning of student policy is based on a temporal convolutional network such that it produces actuation based on an extended history of proprioceptive states.Both learning process involves an automated curriculum that synthesizes terrains adaptively according to the robot’s performance.This approach demonstrates zero-shot generalization from simulation to a variety of natural environments.
For tasks of navigation, Honget al.[118] proposed a modular architecture separating the learning model into a perception and a control policy module, using semantic segmentation as mutual interface.Zero-shot real world experiments showed that the proposed method outperformed several baselines with high success rate.In addition, using semantic segmentation brings advantages of better efficiency and less noise.Instead of tuning the simulator to match reality, or mapping the virtual and real into a common segmentation space,Zhanget al.[114] proposed to close the reality gap in an opposite direction by translating the real-world images backwards to the virtual domain.Both indoor and outdoor experiments, with real robot and vehicle, validated this method as a flexible and efficient solution for visual control.Mitriakovet al.[115] studied a reinforcement learning based staircase negotiation method through simulation and transferred to reality in a zero-shot setting.By comparing different robots and task variants via Kullback-Leibler (KL) policy divergence, the proposed method has high scalability and portability.

Fig.13.Selected examples of virtual-to-real for autonomous driving.
Aiming for a PointGoal navigation task, Kadianet al.[116]built a virtual environment by 3D-scanning a physical lab and run parallel tests with 9 different models.The authors proposed sim-vs-real correlation coefficient (SRCC) as a new metric to quantify sim-to-real predictivity.Experiments using LoCoBot showed that they can improve sim2real predictivity by tuning simulation parameters to increase SRCC.Furthermore, Truonget al.[117] proposed bi-directional domain adaptation (BDA) to bridge sim-real gap in both directions,i.e., real2sim to bridge the visual domain gap and sim2real to bridge the dynamics domain gap.A policy based on BDA took only 5 k real-world (state, action, next-state) samples and performed on par with a policy fine-tuned with 600 k samples,showing much improvement on data efficiency, using 117X less real data.
3) Other Tasks:Beyond robotic navigation and locomotion,there are many sim-to-real applications related to mobile robots like [119] and [120], to mention a few.Sadeghi and Levine [119] focused on controlling the collision-free indoor flight.They proposed CAD2RL, a method that transfers a control policy to real world after training entirely on 3D CAD models from which RGB images are rendered as input to CNN for visual processing.With randomized rendering settings in simulation during training, experiments by flying a real quadrotor across indoor environments showed the learned policy could generalize to real world.Duet al.[120] presented a method to control an underwater soft robot, Starfish,with a differentiable simulator coupled with an analytical hydrodynamic model.This method initializes the simulator with data from real robot, then alternates between simulation and real rollouts.Specifically, the simulation step uses gradients from a differentiable simulator to run system identification and trajectory optimization, and the experiment step executes the optimized trajectory on the robot to collect new data to be fed into simulation.Experiments with Starfish showed that using gradients from the differentiable simulator not only narrows down the reality gap but also improves the performance of the open-loop controller in real world.This is also a typical prescriptive learning method in the same manner as the method introduced in [121].
4) Summary:Reinforcement learning is the predominant approach in robotics, and simulation and domain randomization (DR) are the typical combination indispensable to assist the training of autonomous driving vehicles.Zero-shot transfer is the ideal goal to pursue, but considering the high cost and low safety of try-error, few-shot learning or approaches based on system identification (SI) are more popular with better performance.
D.Virtual-to-Real in Autonomous Driving
In recent years, autonomous driving (AD) and advanced driver assistance system (ADAS) have become hot research topics, where deep learning models play essential roles throughout the whole process including perception, planning and control.However, due to safety and cost concerns, it is difficult to collect enough labeled data covering all scenarios by driving real cars along roads across the city.To solve this problem, researchers turned to simulation for help and achieved great progress on perception, planning and control.Selected examples refer to Fig.13.
1) Perception:Given the facts that both perception in AD(P-AD) and computer vision (CV) share some common tasks like detection, segmentation, estimation, etc., they differ from each other in three aspects.First, the objects to detect are different.CV tries to detect various objects we concern in our daily life, while P-AD focuses on traffic related objects like pedestrian, vehicle, signs, lanes, etc.Second, the backgrounds are different.CV usually works in a specific view, while PAD has to detect objects with varying backgrounds as the vehicle driving along the road.Third, P-AD involves multimodal sensors like LiDAR, Radar, and event camera, in addition to normal camera.In this part, we mainly focus on virtual-to-real methods (Table VIII) on detection, segmentation,and multi-tasks within one framework in AD.
Works using 3D game engine to generate synthetic traffic data can be traced back to early 2010s, when Marinet al.[145] presented an approach based on half-life 2.Synthetic datasets through cameras on a car driving around the virtual city.An HOG/linear-SVM model is trained on the virtual data then tested on the real Daimler dataset, showing improvement with evaluation metric of mean average precision (mAP).This is a straight forward pipeline from virtual to real without feedback.Later, Vazquezet al.[122] extended the work by introducing a domain adaptation module named V-AYLA, which achieves the same accuracy as training on many humanlabeled data and testing with real-world images.
The virtual KITTI by Gaidonet al.[146] is one of the pioneering virtual datasets generated from a dynamic and realistic virtual world using the Unity3D game engine built through a real-to-virtual cloning method.The dataset came with ground truth for training models on multiple tasks including detection, segmentation, depth and optical flow estimation.Similarly, SYNTHIA proposed by Roset al.[125] is a synthetic dataset of diverse urban images with automatically generated annotations based on the Unity3D and verified on segmentation tasks.Considering the domain shift problem, Salehet al.[126] proposed treating foreground and background separately in Unity3D, based on the observation that they are not affected in the same way.The core feature is keeping shapes of objects look natural but not devoting too much efforts to make their textures photorealistic.Tianet al.[127] proposed to train a deep neural detector, Faster R-CNN, with virtual images generated by a tool-kit including Unity3D, CityEngine and OpenStreetMap.Totally 15 931 images of car, bus and truck were generated with automatic annotations.Experiments showed that a mixed training setting with both real and virtual data outperforms training with pure real data of KITTI.Liet al.[147] proposed ParallelEye based on [127], an automatically generated virtual image dataset with precise annotations for multi-tasks.Experiments showed that, by combining ParallelEye with real-world datasets during training, the performance of models can be significantly improved.
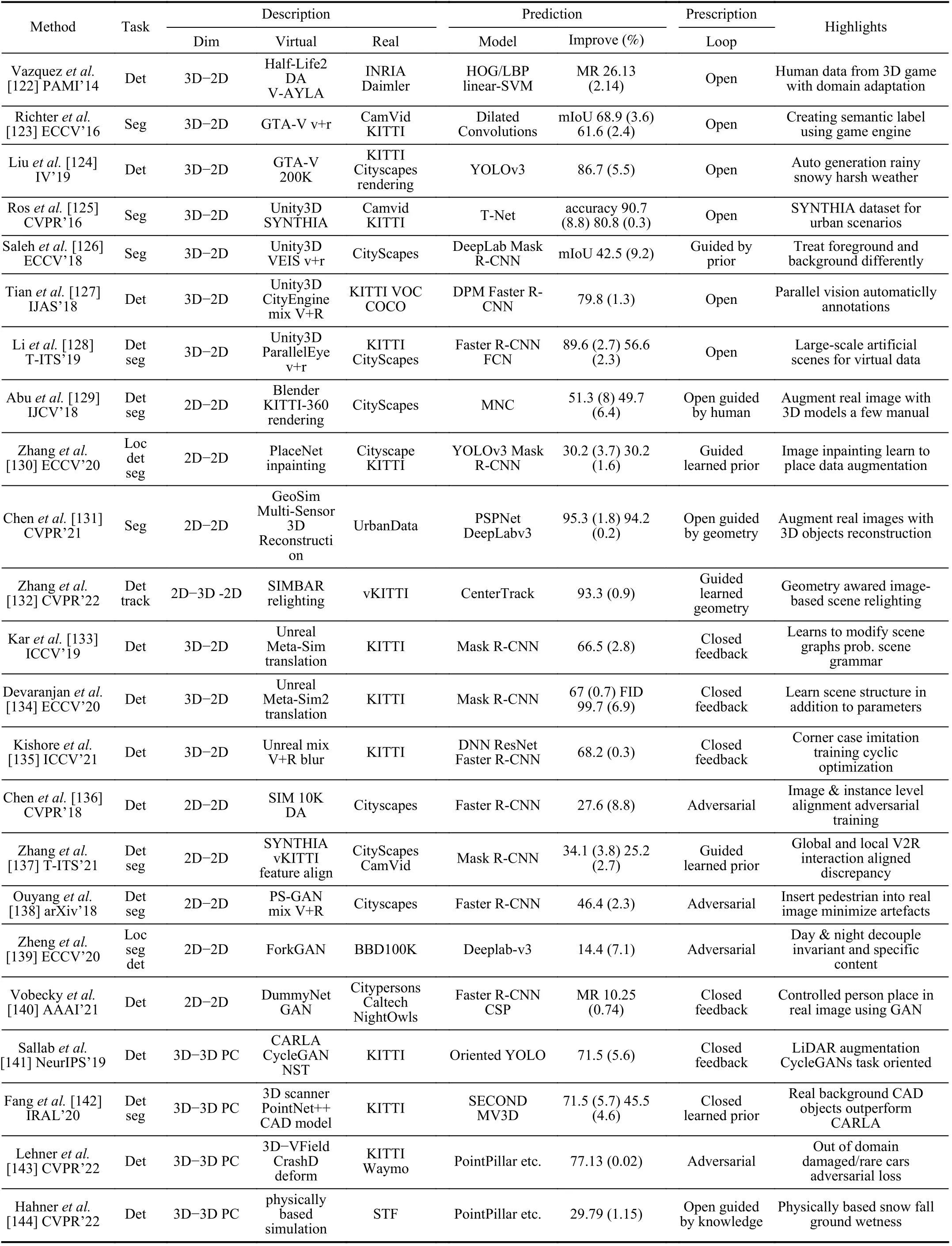
TABLE VIII COMPARISON OF SELECTED WORKS ON VIRTUAL-TO-REAL PERCEPTION FOR AUTONOMOUS DRIVING
Richteret al.[123] introduced a typical virtual-to-real approach, wherein 2D images were collected by driving through a virtual city in the high-realism video game GTA-V.Totally 25 K photorealistic images with pixel-level annotations were generated to train a dilated convolutional network for semantic segmentation.The authors reported that task networks trained on generated virtual data with 1/3 real CamVid data outperformed models trained completely on real data.Aiming to handle corner cases in object detection for AD, Liuet al.[124] introduce an automated pipeline to generate synthetic images under harsh weather conditions through GTA-V.A large dataset with 200 K virtual images helps the YOLO v3 outperform its counterparts training and testing on both rainy and snowy validation images from real dataset Cityscapes and KITTI.
All these aforementioned works are based on open pipeline that the settings to generate virtual images depend on human priors.On the contrary, Kishoreet al.[135] proposed an imitation training pipeline to guide synthetic data generation.The pipeline has a circular loop that comprises three phases, i.e.,finding failure cases using the existing system first, synthesizing data to imitate failure cases, and training the detector with new synthetic data.This is a typical prescriptive learning that iteratively updates the synthesizer through the closed-loop with feedback from detector, until the evaluation metric converges.Experiments on real dataset Waymo and KITTI show its advantages over an SOTA detector.Karet al.[133] argues that domain gap results from not only appearance but also scene content, e.g., layout and types of objects.To address this issue, the authors introduced Meta-Sim, a framework aiming to generate virtual data with minimized domain gap both in appearance and scene contents based on the Unreal engine.Firstly, an initial 3D scene graph, sampled from probabilistic scene grammar, is setup with objects whose parameters (e.g.,positions, pose, color) are learnable.Secondly, Meta-Sim presented a training strategy with two loops.The inner loop aims to minimize the maximum mean discrepancy (MMD) in InceptionV3 feature space between generated virtual images and real images, by backpropagating through finite difference.The outer loop takes in task performance on real test data by defining a loss function and optimizing it by a REINFORCE score estimator.From the viewpoint of parallel learning, this is a work with prescriptive iterations to optimize virtual data generation that aims to improve performance of task model in a closed loop.However, the learnable parameters in Meta-Sim are limited to object attributes like positions and poses, while the scene structure parameters, like number of vehicles, are fixed during training.To address this issue, Devaranjanet al.[134] proposed Meta-Sim2, which emphasized on learning the scene structures.The authors regarded the construction of scene graph as sequentially sampling from probabilistic scene grammar, and trained the proposed model using reinforcement learning with a feature space divergence between virtual and real data.Experiments with a task model of Mask R-CNN tested on KITTI dataset showed that the Meta-Sim framework can generate both quantitatively and qualitatively better samples verified by improvement of the task model.
Instead of using 3D game engines, a group of methods directly augment images in 2D space in adversarial manner.Abualhaijaet al.[129] tried to use background from easily available real images while placing virtual objects, manually or automatically, into real background through Blender for training segmentation models.Zhanget al.[130] proposed PlaceNet to place foreground objects into images without human interactions, for detection and instance segmentation.Chenet al.[131] proposed GeoSim, a geometry-aware image processing approach that inserts dynamic objects into existing images at plausible locations with novel poses, by exploiting the 3D HD maps and LiDAR data.A segmentation model trained with 9879 examples obtained by GeoSim based on 2 K labeled data got performance gains of 3.4% for cars.
Chenet al.[136] proposed a framework to address domain gaps on both image level and instance level according to Hdivergence theory.By learning a domain classifier and a augmented Faster R-CNN detector simultaneously in an adversarial manner, experiments of car detection on the Cityscapes validation set showed that the detector gets a significant 7.7%improvement with evaluation metric of average precision(AP).For instance segmentation task, Zhanget al.[137] proposed a virtual-real interaction method that uses discrepancy between the two domains.Similarly to [136], the authors designed two components to align discrepancies from both global-level and local-level, as well as a consistency alignment component to encourage the consistency between them.
Ouyanget al.[138] proposed pedestrian-synthesis-GAN(PS-GAN), a synthesizer based on GAN with multiple discriminators.Instead of building 3D virtual scenes, PS-GAN tries to insert pedestrians into the background of a real image with minimized artefacts.The authors reported a Faster RCNN detector trained with mixed real and virtual data got best performance.Zhenget al.[139] presented ForkGAN to boost performance for multiple visual tasks including localization,object detection and semantic segmentation in autonomous driving, with night-to-day image translation.Vobeckyet al.[140] proposed a controlled pedestrian augmentation frame-work for automotive scenario, called DummyNet, which is also a GAN architecture to improve data diversity.The DummyNet takes appearance, pose in key point and target background as input, and outputs an image with composited people smoothly aligned with background.Specifically, a pretrained variational autoencoder (VAE) takes charge of appearance and the OpenPose is used to extract key point of a given pose.The authors augmented CityPersons and Caltech dataset using DummyNet, and conducted experiments with the CSP detector.An experiment with Faster-RCNN detector trained on augmented CityPersons then tested on NightOwls dataset showed DummyNet’s ability to generate various data covering day-to-night changes.Other works including [148]−[150]also utilized adversarial training with generative network to synthesize realistic data for pedestrian detection.They all took effects on closing the domain gap between real and virtual data.
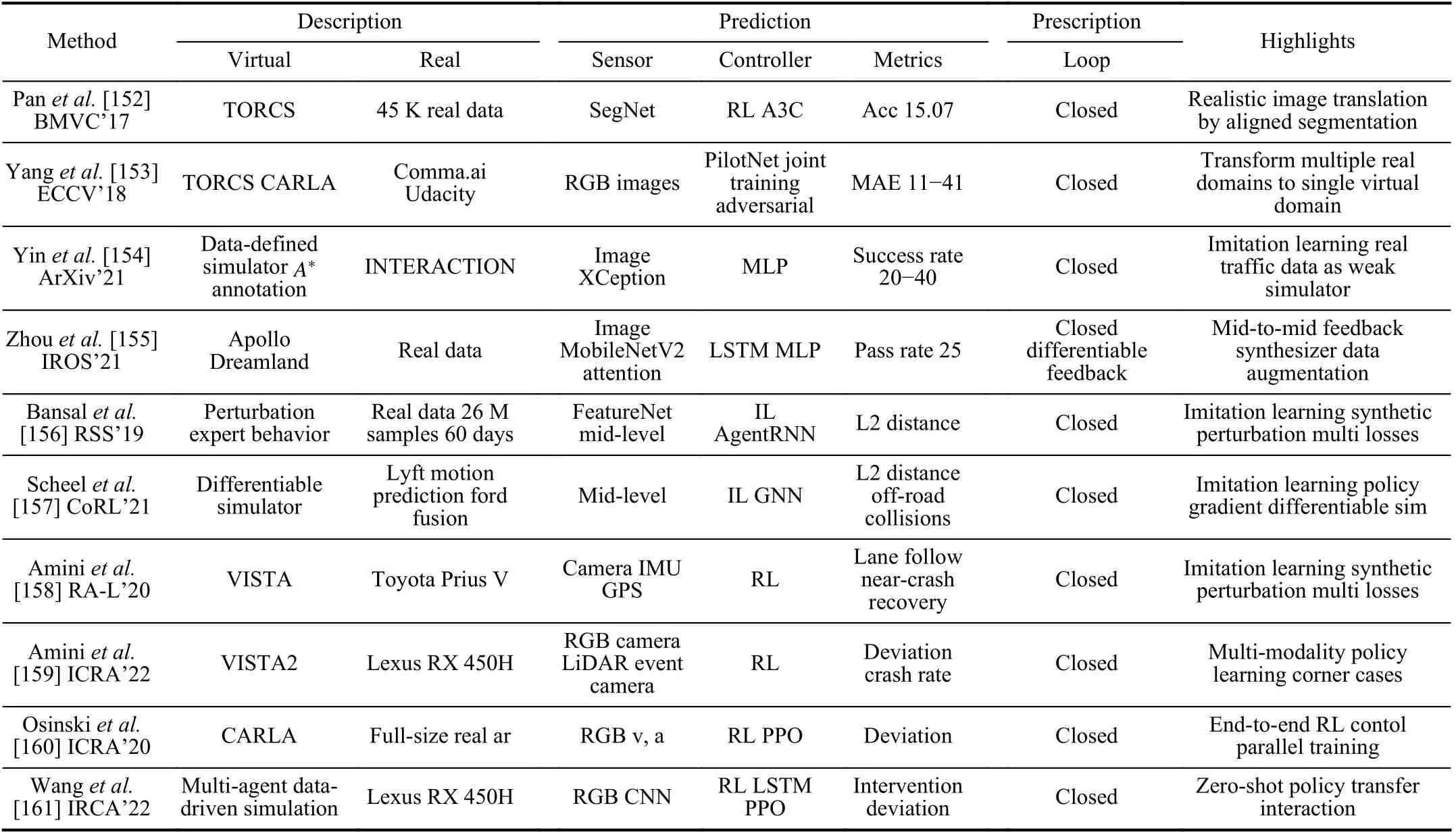
TABLE IX COMPARISON OF SELECTED VIRTUAL-TO-REAL WORKS ON CONTROL OF AUTONOMOUS DRIVING WITH REAL DATA
In addition to images, point clouds from LiDAR are another type of data widely used in AD.However, point clouds are very hard to annotate.To address this problem, Sallabet al.[141] presented their work learning on virtual LiDAR point clouds with annotation generated from CARLA.The framework takes CycleGANs and style transfer techniques to adapt domain from virtual to the real KITTI dataset.The virtual data generation is guided by evaluation of detection task, which forms a prescriptive loop.Fanget al.[142] proposed a LiDAR simulator that augments real point clouds with synthetic obstacles (e.g., vehicles, pedestrians, and other movable objects).By placing the synthetic obstacles properly into the background, detectors trained purely on simulated LiDAR point clouds outperform those trained with real data.Manivasagamet al.[151] presented LiDARsim, a method to generate LiDAR point clouds.LiDARsim first built a virtual world by configuring static maps and dynamic objects, then utilized ray-casting over the 3D scene to produce realistic LiDAR point clouds.The generated data were used to train models in case of real data with long-tail problem.To generate corner cases under harsh weather, Hahneret al.[144] proposed to generate the effect of snowfall on real clearweather LiDAR point clouds based on physically simulation.Lehneret al.[143] tried to generalize detectors to detect out-of-domain 3D objects 3D-VField, an augmentation method that plausibly deforms objects via vector fields learned in an adversarial fashion without adding new objects.
2) Planning and Control:Autonomous vehicles need to plan the route based on perceptions and then control the steering system to drive smoothly and safely on the road.Learning a robust control policy in dynamic environment is much more challenging than training perception models based on datasets.Considering safety issues, some works tried to train driving policy based on datasets collected from real traffic scenarios.However, collecting real data on road is not only expensive but also time consuming.Training with virtual environment has shown advantages.Related works on planning and control with real data, or real vars, are listed in Table IX.
Panet al.[152] proposed to train driving policy in virtual environment with realistic frames then apply it to the real world.The key is a two-phase translation network that firstly converts non-realistic virtual image into a middle representation (e.g., segmentation) then converts into realistic images while keeping the scene structure constant.Policies learned by reinforcement learning using translated images outperform the policies trained with original virtual images.Instead of converting virtual image to realistic ones, Yanget al.[153] presented DU-drive, an unsupervised framework for real-to-virtual domain unification to reduce domain gap.Through DUdrive, real images are converted into simplified virtual domain, where policies are trained to predict driving commands more easily.This method, avoiding intermediate representation and utilizing unlimited virtual images, showed superior performance on real driving datasets.Yuanet al.[162]proposed VRDriving, which is also an end-to-end framework based on adversarial learning.Similarly to DU-drive, an encoder is introduced to transform the real image into the virtual domain at feature map level.This encoder, the estimation model, and a discriminator are trained together with cost-sensitive loss function to get SOTA estimation accuracy.
The following three works are all based on imitation learning but differ in how data are used.Imitation learning is a data driven method that mimics expert’s driving behavior and takes advantages of supervised learning.it can be trained directly on the collected real traffic data avoiding the simulator designing issue compared with reinforcement learning based methods.It can integrate perception and control into an end-to-end trainable model.However, IL has covariate shift problem that results in accumulated errors when applying imitation learning to real world.To address this problem, Bansalet al.[156]proposed ChauffeurNet to improve performance of behavior cloning based on synthetic data by perturbating demonstrated driving behavior from experts, other than rolling out policies through simulation.In addition, the imitation loss is augmented with losses that penalize undesirable actions like driving off-road or collisions, leading to robust policy.Chauffeur-Net was tested under complex situations in simulation, and a real car at the test facility.Yinet al.[154] proposed to learn a behavioral cloning policy with interactions to real data in an iterative manner.Specifically, a weak simulator is created with surrounding vehicles following the trajectory provided by the real dataset, and anA∗planner is introduced to provide expert-like demonstration.This method alleviates both the difficulties to run real world rollouts and the tedious labeling work of human experts.While Zhouet al.[155] proposed a feedback synthesizer to address the distributional shift issue,generating and perturbing on-policy data in a mid-to-mid framework, illustrated in Fig.14.The synthesizer works in a prescriptive manner that it is guided to produce unseen environments to improve overall performance.In addition to imitating, this method utilized losses that penalize undesirable behaviors by introducing a differentiable vehicle rasterizer that directly converts the waypoints output into images, avoiding heavy-weight ConvLSTM networks.The authors also exploited attention mechanism to reason critical objects and a post-processing planner to improve driving comfort.By the metric of pass rate, the proposed method achieved a 70% that outperforms pure IL’s 15% with a large leap.Scheelet al.[157] presented a differentiable simulator, based on top of perception outputs and high-fidelity HD maps, so that an offline policy gradient method can be used in imitation learning of driving policy.Using mid-level representations, this method augmented existing demonstrations by synthesizing new driving experiences.Experiments showed that policies trained on generated data generalized well to real world cars without the need to collect additional on-policy data or introduce state perturbations during training.
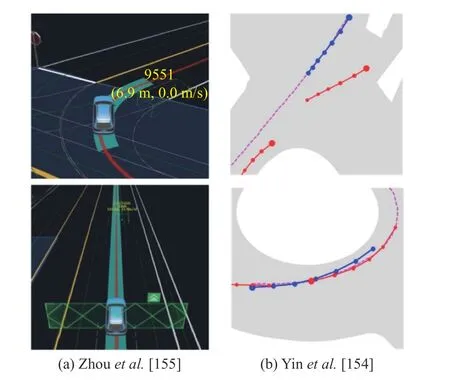
Fig.14.Selected examples of mid-mid control in autonomous driving using virtual data.
There are works taking advantages of virtual LiDAR data,e.g., Sallabet al.[163] proposed to produce realistic LiDAR from simulation (sim2real) and generate high-resolution, realistic LiDAR from lower resolution one (real2real) by employing CycleGANs.Saputraet al.[164] proposed detecting casualty involving human body lying on ground using point cloud.
3) Decision and Control With Real Car on Road:While there are risks to test autonomous vehicles on real roads,researchers have been trying to take advantages of both simulation and real rollouts to learn better driving policies more efficiently.
For end-to-end reinforcement learning, Aminiet al.[158]proposed to render virtual scenes based on human collected real trajectories.Through a simulator, VISTA, a single real trajectory was synthesized into a space of new possible trajectories.Virtual agents are trained by driving new trajectories along the road with consistent appearance and semantics.Experiments showed good generalization to unseen real-world roads with a full-size autonomous car, with better performance in metrics of lane following and near-crash recovery.Later in [159], the authors enhanced the VISTA to its 2.0 version as a multi-modality simulator, supporting sensors of RGB camera, LiDAR and Event camera.
Osinskiet al.[160] presented reinforcement learning for driving policy of a full-size real car through simulation.The driving controller was trained with synthetic images and their semantic segmentation, but the segmentation network was trained with labeled real-world data.
Focusing on learning driving policies in challenging scenarios involving multi-agents interactions, Wanget al.[161] proposed using in-painted ado vehicles for learning robust driving policies in simulation.Experiments showed that the trained policies can be transferred to a full-scale autonomous vehicle directly in a Sero-Shot setting, with better performance under test scenarios of car following and over-taking.
Full-size cars in real-world are not always available for machine learning due to cost and safety considerations, there are sim-to-real works utilizing small-scaled cars with simulations.For RL in shared space with potential collisions,Mitchellet al.[165] proposed a sim2real approach that uses real-world online policy adaptation.This mixed-reality setup,where a real car with other virtual vehicles and static obstacles, enables to learn by virtual collisions between the real car and other virtual objects.Stoccoet al.[166] conducted an empirical study on sim-to-real adaptation with a small-scaled physical donkey car and its virtual counterpart in a simulation environment.The transferability of behavior and failure exposure between the virtual and real-world environments were investigated in vast set of experimental settings.
4) Summary:An autonomous driving (AD) system includes perception, planning and control.AD deeply intersects with both computer vision and robotics domains.To avoid the high cost and danger associated with learning on real city roads,people have to find safe and efficient methods.Imitation learning based on expert experience greatly reduces the danger, but suffers from covariate shift problems.Therefore, reinforcement learning relying on 3D dynamic simulation (4D) in a virtual environment has become the mainstream approach.The generation and fusion of multi-sensor virtual data including LiADR data is also an important challenge.Nevertheless,some work has been done to perform validation tests based on real vehicles on restricted real roads.Overall, V2R has made an indispensable contribution to the move towards L5 autonomous driving.
V.ANALYSIS AND DISCUSSION
Virtual-to-real has become a popular paradigm across machine learning during last five years.We counted the number of papers whose title contains key words“augment”,“synthetic”and“sim2real”from related top annual conferences including ICML, AAAI, CVPR, NeurIPS, ACL, EMNLP,ICASSP, IROS, and IRCA.As shown in Fig.15, the number of virtual-to-real works of CV, NLP, Robotics and AD keeps increasing during the last 5 years.Although virtual-to-real has kept attracting attention, it is still under developing.In this part, we analyze the current issues and discuss the problems that remain to be studied in the future, from the viewport of parallel learning.

Fig.15.The number of virtual-to-real works keeps increasing during the recent five years.
A.Current Situation
1) Discussion of Virtual-to-Real Evaluation Metric:In Section IV, we reviewed more than one hundred of virtual-to-real works in machine learning.Readers should have no doubts that the V2R paradigm helps to improve learning performance.But when we try to compare V2R methods in a specific domain, we are facing difficulties to make fair comparisons because of the lacking of benchmarks and common evaluation metrics.Taking CV for example, all V2R methods try to generate images that help to improve the performance learning models, but few of them share common settings including tasks, learning models, usage of validation and testing data, baselines, and evaluation metrics.The situations are even worse for robotics and AD.
To address this issue, we propose to evaluate a virtual-toreal method from three levels, as shown in Table X.The first level includes metrics to measure distribution similarity between the virtual and real dataset, known as the frechet inception distance (FID) and the kernel inception distance(KID).These metrics are general and task-agnostic.The second level includes metrics for evaluation of learning performance.These metrics are widely adopted in machine learning and depend on specific learning tasks, e.g., mAP in detection and mIoU in segmentation.The third level aims for evaluation of efficiency, by which we want to know the cost in training time and dataset size to obtain performance improvements.
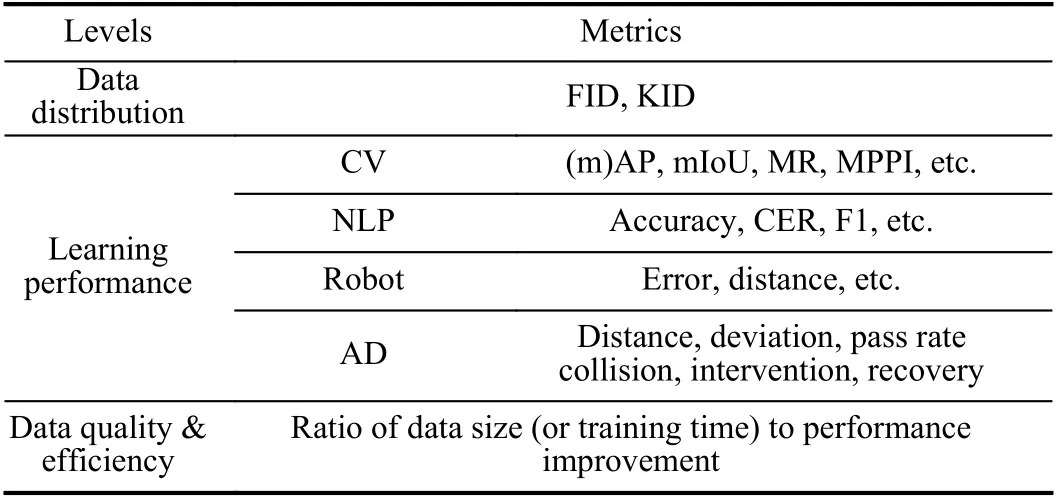
TABLE X EVALUATION METRICS
2) Discussion on Description of Real World:Description in parallel learning means creating the virtual opponent of the real world.Description covers a variety of techniques including text/voice generation, image composition, 3D reconstruction and dynamic simulation, etc.We try to summarize some common questions and analyze the possible reasons.
a) 2D−2D v.s.3D−2D:A large percent of machine learning tasks take 2D data (images or frames in a video) as input,including all vision tasks and most robotic and autonomous driving tasks.There are two typical methods to generate virtual images in practical virtual-to-real applications, i.e., image composition based on real images and image projection from 3D virtual environments.What are the pros and cons of them?Which one prefers the other? We summarize their pros and cons in Table XI and discuss as follows.
3D−2D methods construct a virtual world firstly then generate images by projecting through a virtual camera.3D−2D format mainly has two advantages.First, it is flexible for theusers to setup varieties of 3D scenes and control the rendering parameters like camera pose, texture of objects and backgrounds, intensity of illumination, etc.Second, it is a choice when real data is not available, i.e., zero-shot scenarios where 3D scenes can be reconstructed based on prior knowledge.However, the 3D−2D format is a double-blade sword.First,though there is out-of-shelf software to aid the 3D construction process, it is still labor intensive and time consuming to setup 3D scenes and configure proper rendering parameters.Second, sometimes the human priors may introduce noise(bias) that is discrepant from the distribution of real data.

TABLE XI COMPARISON OF DIMENSIONAL DATA GENERATION
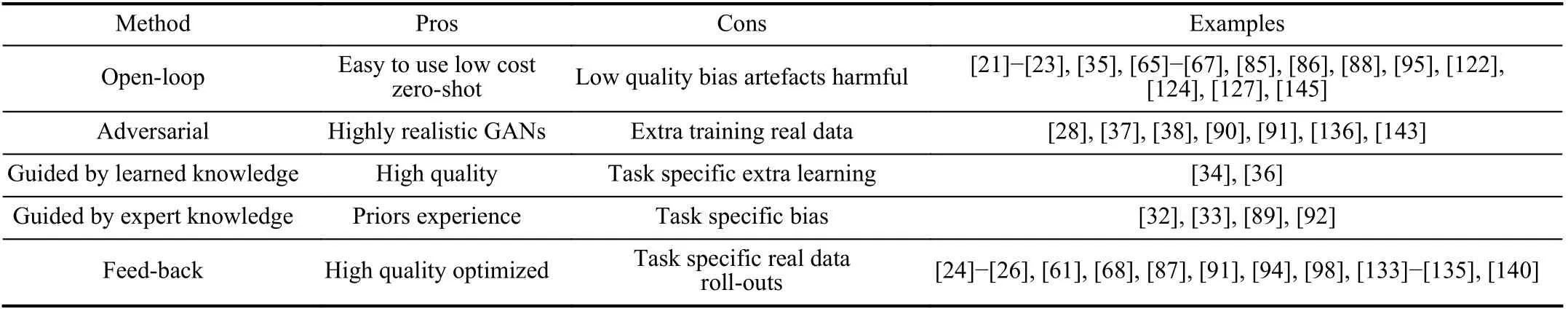
TABLE XII COMPARISON OF PRESCRIPTION METHODS
2D−2D methods generate virtual images based on real images, through augmentation, composition, stylization, rendering, etc.This kind of methods avoid tedious works of constructing and configuring 3D environments, so that the whole learning process can be done end-to-end.In addition, 2D−2D methods only modify objects of interesting in the image while keeping the background unchanged, which maintains the data distribution similar to the original dataset with minimal shift.On the other hand, 2D−2D methods have less flexibility because the view port is fixed when taking the picture in the real world.Furthermore, the prelimited condition is that there must be plenty of unlabeled real data.
Historically, 3D−2D methods were proposed earlier than 2D−2D methods, but the latter has dominated in recent years because of higher efficiency and plenty of image processing techniques.Nevertheless, 3D−2D methods have much space to be improved, especially after the introduction of learnable 3D scene construction and differentiable rendering engine.
b) 1D−2D generation:Recently, the large-scale generative models have attracted attention in the area of image generation.For example, DALL-E2 [20] has shown promise to generate/edit realistic images from a description in natural language, which makes 1D−2D data generation feasible.Methods like diffusion model behind the impressive images have potential power to help in virtual-to-real applications.
c) 4D dynamic simulation:For robotics and autonomous driving, dynamic simulator is essential to the success of virtual-to-real.To this end, the differentiable physics engines have been integrated into the pipeline to realize the end-to-end learning process.However, there is a long way to go before the physics engines simulate the natural world perfectly, especially rare phenomenon.
d) Photo realistic v.s.coarse realistic:Ideally, we want the virtual and real data to be twins of each other.Some works laid a lot of efforts to generate photo realistic images or data with same distribution as real data, at the cost of laborious tuning and sophisticated techniques.With the advancement of computer graphics, we have better tools to generate much more realistic data with less efforts.However, the domain gap between virtual and real datasets remains as an open problem.
While some people try to approach the real world with efforts, others argue that making the virtual data photo realistic is unnecessary.Instead, experiments had shown that deep models trained on randomly composed non-realistic images have better generalization compared with models trained on real dataset.Specifically, in robotics and AD planning and control, mid-level representations are more popular formats than high-realistic images.Currently, there is no common agreement on how realistic the virtual should be to get better performance for downstream tasks.
3) Discussion on Prescription for Better Virtual World:The concept of prescription in parallel learning suggests to update the virtual world to generate better dataset to boost learning performance.Instead of simple data augmentation or domain randomization, prescription tries to improve both data generator and task model (predictor) simultaneously.According to the way to improve the data generator, we categorize the prescription methods into four types, including open-loop, adversarial, guided (by learnt or expert knowledge), and feed-back,with their pros and cons summarized in Table XII.
a) Open-loop:The open-loop pipeline, i.e., training on virtual and then testing on real data, is popular in most domains.The word“open-loop”indicates the generation of virtual data is task agnostic, whether by synthesizing or simulation.This means human priors or domain specific knowledge are necessary to ensure the generated virtual data are consistent with the distribution of real data.Random domain augmentationand domain randomization usually introduce noise into visual data that harms the performance of predictor.A large number of such kind of virtual data result in low efficiency because a big ratio of dataset would not contribute to the optimization of learning process.Nevertheless, open-loop pipeline is preferred in some applications due to easy implementation.More importantly, it is the only choice in the case of zero-shot scenario where real data or real environments are not accessible.

TABLE XIII DEVELOPING TRENDS
b) Adversarial:Naive open-loop pipeline cannot generate high quality efficiently.People have tried to address this problem and found that it can achieve better performance by constraining the virtual data generator.Adversarial training and GANs are popular frameworks in which one or multiple discriminators are used to reject data out of distribution of real data.This type requires that there are at least a small number of real data to train the discriminators.
c) Guided:Most successful machine learning models are deep neural networks driven by labeled big data.While in case of data scarcity, we use knowledge to compensate the data shortage.When we have experts, whose experience can be utilized to generate data for learning, we denote the prescription as guided by expert’s knowledge.When there are no experts in a specific domain, we manage to learn the knowledge from a small number of unlabeled real data.With the learnt knowledge, we generate a large number of labeled data to train a better model.
d) Feed-back:In recent years, researchers have kept pursuing better data generation methods.One of promising methods is regarding the virtual data generation as an optimization problem by introducing feedback from the downstream task.However, due to the complexity of tasks, forming a closed loop that iteratively converges to an optimized solution is more difficult than open-loop methods.Searching methods are well known to solve optimal problem but suffer from low efficiency.For some tasks, reinforcement learning is a better choice by defining the feedback as rewords.To further improve the efficiency, people have tried to make the whole pipeline differentiable so that gradient descent methods can be used with massive processors.Thanks to the fast development of differentiable rendering engines and differentiable physics engines, the closed-loop pipeline can be updated automatically in which the data generator and predictor are trained simultaneously.Closed-loop pipeline iteratively minimizes the domain gap in an implicit manner, and effectively boosts the performance of learning models.
B.Problems and Trends
The virtual-to-real paradigm has become an essential way to boost learning performance in data scarcity scenarios.However, it is still under developing.Many people in the machine learning community keep trying to find better methods to solve the problems both in theory and in practice.
1) Problems:We emphasize on two typical problems.
a) Domain gap:The first problem is the domain gap (reality gap) between the real and virtual data, which is well known as an open problem.Though a variety of domain adaptation methods have been proposed to minimize the gap for better transfer from virtual to real world, it is still a hot research topic that is far from solved in recent years.
b) Benchmark:The second problem is the requirement of benchmarks.In addition to the performance of learning task,the quality of virtual data is also an essential factor for virtualto-real applications.However, the lacking of benchmarks makes it difficult to fairly compare the existing methods and comprehensively evaluate new methods.We have proposed a three-level evaluation metric, and we also suggest to setup benchmarks in each machine learning subdomain accordingly.
2) Trends:Based on the review and analysis, we conclude that the following trends listed in Table XIII deserve more attention in the following years.The first promising direction is the efforts to use diffusion models to make the virtual world closer to the real world.The diffusion model has shown its power in text-to-image, text-to-video, and text-to-mesh, yet not used in virtual-to-real.The second promising direction is the introduction of differentiable rendering and physics engines that enable end-to-end pipeline for simultaneously learning data generator and machine learning models.The third direction is to use knowledge, learned from data or from human experts, to guide the virtual data generation.The parallel learning framework offers a good interface to fuse knowledge into the pipeline of machine learning, which is regarded as the feature of the 3rd generation of artificial intelligence.
VI.CONCLUSION
High quality data are essential to the performance of machine learning algorithms.However, the requirement of qualified data is not always satisfied in practice.To address this problem, the virtual-to-real becomes a promising paradigm that tries to generate virtual training data whenever real data are unavailable.As a fast-developing research area, it is essential to give an overview of the advances in recent years and clarify the problems that remain to be solved, as well opportunities in the future.
In this paper, we firstly extended the parallel learning.In the extended framework of parallel learning, we presented an overview of virtual-to-real methods mainly covering four domains including computer vision, natural language processing, robotic control, and autonomous driving.A taxonomy was proposed to organize the related literature systematically based on parallel learning.Specifically, for each of included method, we gave a brief analysis according to the three principles, i.e., description, prediction and prescription.Features of similar methods were listed as adjacent tuples in one table for comparison.We also summarized common features across domains with emphasis on prescription which iteratively improves the generation of virtual data in a task-oriented closed loop.
For future development of virtual-to-real, we foresee increases in three aspects.The first is about description.Large scale pre-trained models will take their role in virtual data generation, especially in CV and NLP.Knowledges entailed in the pre-trained models will improve the quality of generated data without human interventions.The second is about prediction.Massively distributed training and testing based on virtual environments are efficient ways to accelerate the learning process, especially in the cases of learning policy for robots and autonomous vehicles.The last is on prescription.Generating virtual data in a task-oriented closed loop pipeline has shown advantages over open-loop formats.With the development of differentiable rendering engine and physics engines, end-to-end prescriptive learning is promising in more applications.In addition, the parallel learning framework offers an interface to realize machine learning driven by both data and knowledge.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Current-Aided Multiple-AUV Cooperative Localization and Target Tracking in Anchor-Free Environments
- Event-Triggered Asymmetric Bipartite Consensus Tracking for Nonlinear Multi-Agent Systems Based on Model-Free Adaptive Control
- UltraStar: A Lightweight Simulator of Ultra-Dense LEO Satellite Constellation Networking for 6G
- Multi-AUV Inspection for Process Monitoring of Underwater Oil Transportation
- Process Monitoring Based on Temporal Feature Agglomeration and Enhancement
- Finite-Horizon l2–l∞State Estimation for Networked Systems Under Mixed Protocols